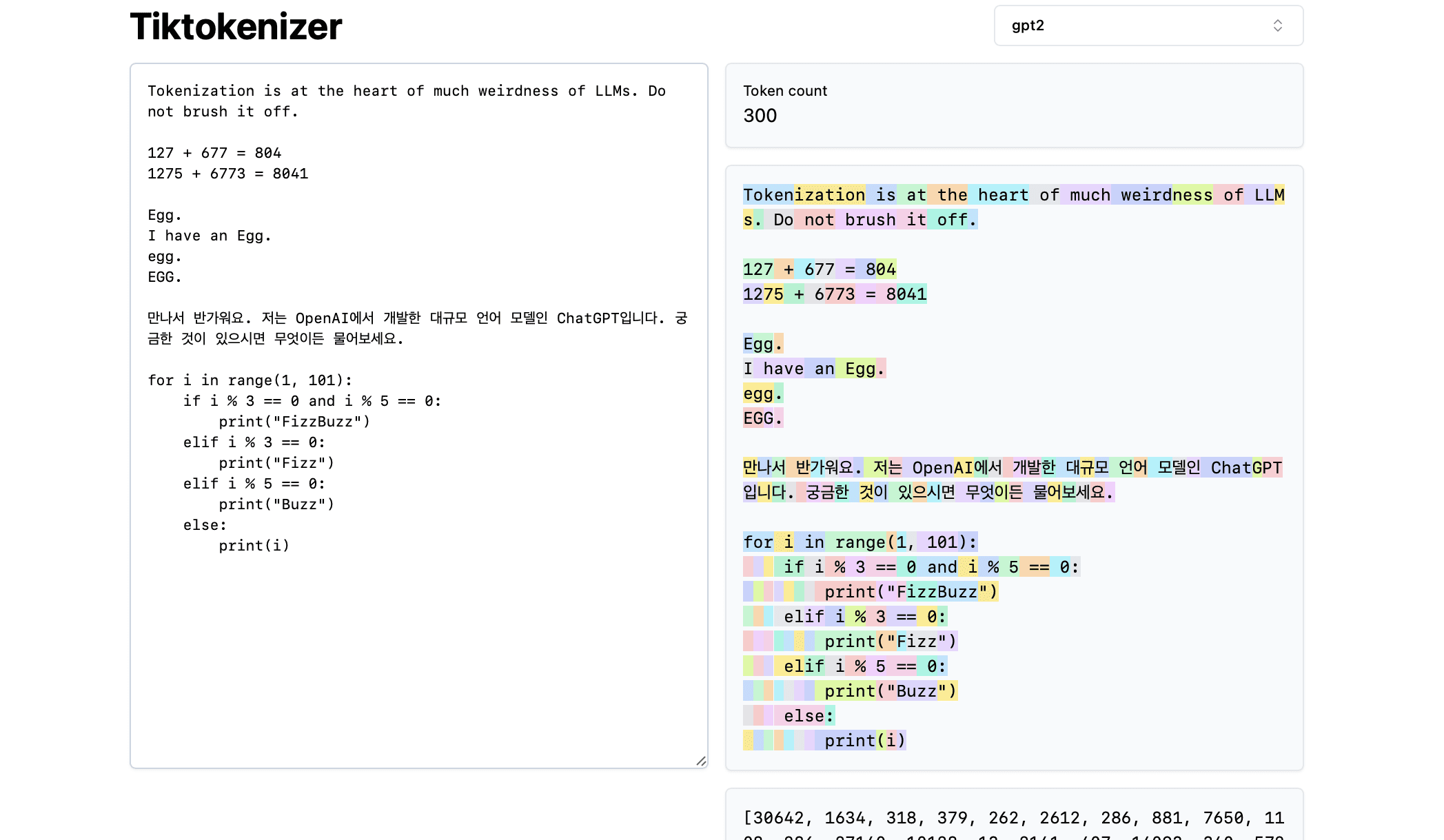
2024 Inventaire des BVR, stratégie d'application des BVR 100+

En 2024, les grands modèles changent de jour en jour et des centaines d'organismes intelligents sont en concurrence. En tant qu'élément important des applications d'IA, RAG est également un "groupe de héros et de vassaux". Au début de l'année, ModularRAG continue de chauffer, GraphRAG brille, au milieu de l'année, les outils open source sont en plein essor, les graphes de connaissance créent de nouvelles opportunités, et à la fin de l'année, la compréhension des graphes et les RAG multimodaux entament un nouveau voyage, de sorte que c'est presque comme si "vous chantiez et que j'apparaisse sur la scène", et des techniques étranges font leur apparition, et la liste est encore longue !
J'ai sélectionné des systèmes et des documents RAG typiques pour 2024 (avec des notes, des sources et des informations sommaires sur l'IA), et j'ai inclus une vue d'ensemble des RAG et du matériel d'analyse comparative des tests à la fin du document, et j'espère mettre en œuvre ce document, qui compte 16 000 mots, pour vous aider à passer rapidement à travers les RAG.
Le texte intégral de 72 articles, mois par mois sous la forme d'un canevas, fortement appelé "RAG seventy-two styles", afin de vous offrir...
Remarques :
Tout le contenu de cet article a été hébergé dans le dépôt open source Awesome-RAG, n'hésitez pas à soumettre des PRs pour vérifier les lacunes.
Adresse GitHub : https://github.com/awesome-rag/awesome-rag
(01) GraphReader [Expert graphique]
Experts graphiquesC'est comme un tuteur qui sait faire des cartes mentales, transformant un texte long en un réseau de connaissances clair, de sorte que l'IA puisse facilement trouver les points clés nécessaires à la réponse, comme si elle explorait une carte, surmontant ainsi efficacement le problème de "se perdre" lorsqu'on traite un texte long.
- Heure : 01.20
- Thèse : GraphReader : construction d'un agent basé sur les graphes pour améliorer les capacités des grands modèles linguistiques en matière de contexte long
GraphReader est un système de corps intelligent basé sur un graphe, conçu pour traiter de longs textes en les construisant sous forme de graphe et en utilisant le corps intelligent pour explorer le graphe de manière autonome. Lorsqu'il reçoit un problème, le corps intelligent effectue d'abord une analyse étape par étape et élabore un plan raisonnable. Ensuite, il appelle un ensemble de fonctions prédéfinies pour lire le contenu des nœuds et les voisins, facilitant ainsi une exploration grossière à fine du graphe. Tout au long du processus d'exploration, l'organisme intelligent enregistre en permanence de nouvelles idées et réfléchit à la situation actuelle afin d'optimiser le processus jusqu'à ce qu'il ait recueilli suffisamment d'informations pour générer une réponse.

(02) MM-RAG [à facettes multiples]
personne polyvalenteIl s'agit d'un appareil polyvalent capable de maîtriser à la fois la vue, l'ouïe et le langage. Il peut non seulement comprendre différentes formes d'informations, mais aussi passer de l'une à l'autre et établir des corrélations entre elles en toute liberté. Grâce à la compréhension globale de diverses informations, il peut fournir des services plus intelligents et plus naturels dans divers domaines tels que la recommandation, l'assistance et les médias.
Les développements en matière d'apprentissage automatique multimodal sont présentés, notamment l'apprentissage comparatif, la recherche modale arbitraire mise en œuvre par l'intégration multimodale, la génération augmentée de recherche multimodale (MM-RAG) et la manière d'utiliser les bases de données vectorielles pour construire des systèmes de production multimodaux. Les tendances futures de l'IA multimodale sont également explorées, soulignant ses applications prometteuses dans des domaines tels que les systèmes de recommandation, les assistants virtuels, les médias et le commerce électronique.

(03) CRAG [autocorrection]
autocorrectionRAG est un système de contrôle de la qualité : comme un rédacteur chevronné, il passe au crible les informations préliminaires d'une manière simple et rapide, puis élargit les informations en effectuant des recherches sur le web, et enfin s'assure que le contenu final présenté est à la fois précis et fiable en le désassemblant et en le réorganisant. C'est comme si RAG était doté d'un système de contrôle de la qualité qui rend le contenu qu'il produit plus digne de confiance.
- Heure : 01.29
- Thèse : Corrective Récupération Génération augmentée
- Projet : https://github.com/HuskyInSalt/CRAG
CRAG améliore la qualité des documents récupérés en concevant un évaluateur de récupération léger et en introduisant la recherche sur le web à grande échelle, et affine encore les informations récupérées grâce à des algorithmes de décomposition et de réorganisation afin d'améliorer la précision et la fiabilité du texte généré.CRAG est un complément et une amélioration utiles de la technique RAG existante, qui renforce la robustesse du texte généré en auto-corrigeant les résultats de la récupération.

(04) RAPTOR [généralisation hiérarchique]
résumé hiérarchiqueÀ l'instar d'un bibliothécaire bien organisé, le contenu du document est structuré en arborescence, de bas en haut, ce qui permet à la recherche d'informations de passer avec souplesse d'un niveau à l'autre, à la fois pour obtenir une vue d'ensemble et des détails plus approfondis.
- Heure : 01.31
- Thèse : RAPTOR : Recursive Abstractive Processing for Tree-Organised Retrieval (Traitement abstrait récursif pour la recherche organisée par arbre)
- Projet : https://github.com/parthsarthi03/raptor
RAPTOR (Recursive Abstractive Processing for Tree-Organised Retrieval) introduit une nouvelle méthode d'intégration récursive, de regroupement et de résumé de blocs de texte pour construire des arbres avec différents niveaux de résumé de bas en haut. Au moment de l'inférence, le modèle RAPTOR récupère des informations à partir de cet arbre, en intégrant des informations provenant de longs documents avec différents niveaux d'abstraction.

(05) T-RAG [conseiller privé]
conseiller privéIl est capable d'organiser l'information à l'aide d'une structure arborescente afin de fournir des services localisés de manière efficace et rentable tout en protégeant la vie privée, à l'instar d'un consultant interne connaissant les structures organisationnelles.
- Thèse : T-RAG : leçons tirées des tranchées du LLM
T-RAG (Tree Retrieval Augmentation Generation) combine RAG avec des LLM open source finement ajustés utilisant des structures arborescentes pour représenter les hiérarchies d'entités dans des contextes d'augmentation des organisations, en s'appuyant sur des modèles open source hébergés localement pour répondre aux préoccupations en matière de confidentialité des données tout en tenant compte de la latence de l'inférence, des coûts d'utilisation des jetons et des problèmes de disponibilité régionale et géographique.

(06) RAT [Penseur]
penseurLe tuteur réfléchi : Au lieu d'arriver à une conclusion d'un seul coup, vous commencez par des idées initiales, puis vous utilisez les informations pertinentes récupérées pour revoir et affiner continuellement chaque étape du processus de raisonnement afin de rendre la chaîne de pensée plus serrée et plus fiable.
- Thèse : RAT : Retrieval Augmented Thoughts (pensée augmentée) Éliciter Raisonnement tenant compte du contexte dans la génération à long terme
- Projet : https://github.com/CraftJarvis/RAT
RAT (Retrieval Augmented Thinking) Après avoir généré une chaîne de pensée initiale de zéro échantillon, chaque étape de la pensée est révisée individuellement à l'aide d'informations récupérées liées à la requête de la tâche, aux étapes de la pensée actuelles et passées, et RAT améliore de manière significative les performances sur une grande variété de tâches de génération de temps long.

(07) RAFT [maître du livre ouvert]
maître de l'ouverture des livresLa réponse à la question de savoir s'il est possible de trouver les bonnes références : Comme un bon candidat, vous ne vous contenterez pas de trouver les bonnes références, mais vous citerez également les éléments clés avec précision et expliquerez clairement le processus de raisonnement afin que la réponse soit à la fois fondée sur des preuves et sensée.
- Thèse : RAFT : Adaptation d'un modèle linguistique à un domaine spécifique RAG
RAFT vise à améliorer la capacité d'un modèle à répondre à des questions dans un environnement "à livre ouvert" spécifique à un domaine en formant le modèle à ignorer les documents non pertinents et à répondre aux questions en citant mot pour mot les séquences correctes des documents pertinents, ce qui, en combinaison avec les réponses par chaînage de pensées, améliore considérablement la capacité de raisonnement du modèle.

(08) Adaptive-RAG [Atteindre la bonne personne pour le bon emploi]
(idiome) enseigner en fonction des capacités de l'élèveL'outil d'aide à la décision : Face à des questions de difficultés différentes, il choisira intelligemment la réponse la plus appropriée. Les questions simples recevront une réponse directe, tandis que les questions complexes recevront une réponse plus détaillée ou un raisonnement étape par étape, tout comme un enseignant expérimenté qui sait ajuster sa méthode d'enseignement en fonction des problèmes spécifiques des étudiants.
- Thèse : Adaptive-RAG : Apprendre à adapter les grands modèles linguistiques renforcés par la recherche en fonction de la complexité des questions
- Projet : https://github.com/starsuzi/Adaptive-RAG
Adaptive-RAG sélectionne dynamiquement la stratégie d'amélioration de la recherche la plus appropriée pour le LLM en fonction de la complexité de la requête, en sélectionnant dynamiquement la stratégie la plus appropriée pour le LLM, de la plus simple à la plus complexe. Ce processus de sélection est mis en œuvre par le biais d'un petit modèle de classification linguistique qui prédit la complexité de la requête et collecte automatiquement des étiquettes pour optimiser le processus de sélection. Cette approche fournit une stratégie équilibrée qui s'adapte de manière transparente entre les LLM itératifs et les LLM à récupération en une seule étape ainsi que les méthodes sans récupération pour une gamme de complexités d'interrogation.

(09) HippoRAG [hippocampe]
hippocampeLes connaissances anciennes et nouvelles sont habilement tissées en une toile, à l'instar du corps équin de l'esprit humain. Il ne s'agit pas simplement d'empiler des informations, mais de permettre à chaque nouvel élément de connaissance de trouver la place qui lui convient le mieux.
- Thèse : HippoRAG : Mémoire à long terme d'inspiration neurobiologique pour les grands modèles linguistiques
- Projet : https://github.com/OSU-NLP-Group/HippoRAG
HippoRAG est un nouveau cadre de recherche inspiré de la théorie de l'indexation hippocampique de la mémoire à long terme humaine, visant à permettre une intégration plus profonde et plus efficace des nouvelles expériences. HippoRAG orchestre de manière synergique les LLM, les graphes de connaissances et les algorithmes PageRank personnalisés pour imiter les différents rôles du néocortex et de l'hippocampe dans la mémoire humaine.

(10) RAE [édition intelligente]
éditeur intelligent (logiciel)Comme un rédacteur en chef attentif, il ou elle ne se contentera pas d'approfondir les faits pertinents, mais trouvera également les informations clés qui peuvent être facilement négligées par un raisonnement en chaîne, et saura en même temps couper le contenu redondant pour s'assurer que les informations finales présentées sont à la fois exactes et concises, évitant ainsi le problème de "parler beaucoup mais pas de manière fiable".
- Thèse : Édition de connaissances améliorée par la recherche dans les modèles linguistiques pour la réponse aux questions multi-sauts.
- Projet : https://github.com/sycny/RAE
RAE (Multi-hop Q&A Retrieval Enhanced Model Editing Framework) récupère d'abord les faits édités, puis optimise le modèle linguistique grâce à l'apprentissage contextuel. L'approche de recherche basée sur la maximisation de l'information mutuelle exploite le pouvoir de raisonnement du grand modèle linguistique pour identifier les faits enchaînés qui pourraient être manqués par les recherches traditionnelles basées sur la similarité. En outre, le cadre comprend une stratégie d'élagage pour éliminer les informations redondantes des faits récupérés, ce qui améliore la précision de l'édition et atténue le problème de l'illusion.

(11) RAGCache [Entreposeur]
magasinierLes connaissances : Comme dans un grand centre logistique, placez les connaissances fréquemment utilisées sur les étagères les plus faciles à ramasser. Sachez comment placer les colis fréquemment utilisés à la porte et ceux qui le sont moins dans les bacs du fond pour maximiser l'efficacité du ramassage.
- Thèse : RAGCache : mise en cache efficace des connaissances pour la génération améliorée par la recherche.
RAGCache est un nouveau système de mise en cache dynamique à plusieurs niveaux adapté à RAG qui organise les états intermédiaires des connaissances récupérées dans un arbre de connaissances et les met en cache dans les hiérarchies de mémoire du GPU et de l'hôte. RAGCache propose une stratégie de substitution qui prend en compte les caractéristiques de raisonnement LLM et les modèles de recherche RAG. Il chevauche aussi dynamiquement les étapes de recherche et de raisonnement pour minimiser la latence de bout en bout.

(12) GraphRAG [résumé communautaire]
Résumés communautairesL'objectif est de créer un réseau de résidents dans le quartier, puis d'attribuer un profil à chaque cercle de voisinage. Lorsque quelqu'un demande son chemin, chaque cercle de quartier fournit des indices qui sont finalement intégrés dans la réponse la plus complète.
- Thèse : From Local to Global : A Graph RAG Approach to Query-Focused Summarization (Du local au global : une approche graphique RAG pour un résumé axé sur les requêtes)
- Projet : https://github.com/microsoft/graphrag
GraphRAG construit des index de texte basés sur des graphes en deux étapes : tout d'abord, un graphe de connaissance des entités est dérivé des documents sources, puis des résumés de communautés sont pré-générés pour tous les groupes d'entités étroitement liés. Face à un problème, chaque résumé de communauté est utilisé pour générer une réponse partielle, puis toutes les réponses partielles sont à nouveau résumées dans la réponse finale à l'utilisateur.

(13) R4 [Maître chorégraphe]
maître arrangeurLa qualité de la production est améliorée par l'optimisation de l'ordre et de la présentation du matériel, ce qui rend le contenu plus organisé et plus ciblé sans qu'il soit nécessaire de modifier le modèle de base.
- Thèse : R4 : Renforcement du système Retriever-Reorder-Responder pour les grands modèles linguistiques enrichis par la recherche.
R4 (Reinforced Retriever-Reorder-Responder) est utilisé pour apprendre l'ordre des documents pour un grand modèle linguistique amélioré par la recherche, améliorant ainsi les capacités génératives du grand modèle linguistique alors qu'un grand nombre de ses paramètres restent gelés. Le processus d'apprentissage du réordonnancement est divisé en deux étapes en fonction de la qualité des réponses générées : l'ajustement de l'ordre des documents et l'amélioration de la représentation des documents. Plus précisément, l'ajustement de l'ordre des documents vise à organiser l'ordre des documents récupérés en positions de début, de milieu et de fin sur la base de l'apprentissage par attention graphique afin de maximiser la récompense de renforcement pour la qualité de la réponse. L'amélioration de la représentation des documents permet d'affiner les représentations des documents récupérés pour les réponses de mauvaise qualité grâce à l'apprentissage contradictoire par gradient au niveau des documents.

(14) IM-RAG [se parler à soi-même]
se parler à soi-mêmeLorsqu'ils rencontrent un problème, ils calculent dans leur esprit "quelles informations dois-je vérifier" et "ces informations sont-elles suffisantes", et affinent la réponse par un dialogue interne continu. Cette capacité de "monologue" est semblable à celle d'un expert humain, capable de réfléchir en profondeur et de résoudre des problèmes complexes étape par étape.
- Thèse : IM-RAG : Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues (Génération améliorée par l'apprentissage des monologues intérieurs)
IM-RAG prend en charge plusieurs cycles d'amélioration de la recherche d'informations par l'apprentissage de monologues intérieurs afin de relier les systèmes de recherche d'informations aux modèles linguistiques. L'approche intègre le système de recherche d'informations avec de grands modèles de langage pour prendre en charge plusieurs cycles de génération d'amélioration de la recherche par l'apprentissage de monologues internes. Pendant le monologue intérieur, le grand modèle de langage fait office de modèle de raisonnement central, qui peut soit poser une question au récupérateur pour recueillir davantage d'informations, soit fournir une réponse finale basée sur le contexte du dialogue. Nous introduisons également un optimiseur qui améliore les résultats du récupérateur, comblant ainsi le fossé entre le raisonneur et les modules de recherche d'informations dont les capacités varient, et facilitant la communication à plusieurs tours. L'ensemble du processus de monologue intérieur est optimisé via l'apprentissage par renforcement (RL), où un suivi de la progression est également introduit pour fournir des récompenses d'étape intermédiaires, et les prédictions de réponse sont encore optimisées individuellement via le réglage fin supervisé (SFT).

(15) AntGroup-GraphRAG [Des centaines d'experts]
cent écoles de penséeL'entreprise réunit les meilleurs éléments du secteur, spécialisés dans divers moyens de localiser rapidement des informations, de fournir des recherches précises et de comprendre les requêtes en langage naturel, ce qui rend les recherches de connaissances complexes à la fois rentables et efficaces.
- Projet : https://github.com/eosphoros-ai/DB-GPT
L'équipe de Ant TuGraph a construit le cadre open source GraphRAG basé sur DB-GPT, qui est compatible avec une variété de pédales d'indexation de bases de connaissances telles que le vecteur, le graphe, le texte intégral, etc., et prend en charge l'extraction de connaissances à faible coût, le mappage de la structure du document, l'abstraction de la communauté de graphe et la récupération hybride pour résoudre les problèmes de QFS Q&R. Il prend également en charge diverses capacités d'extraction telles que les mots-clés, les vecteurs et le langage naturel.

(16) Kotaemon [LEGO]
Lego (jouets)Un ensemble prêt à l'emploi de blocs de construction Q&A qui peuvent être utilisés directement ou librement désassemblés et remodelés. Les utilisateurs peuvent les utiliser comme ils le souhaitent et les développeurs peuvent les modifier à leur guise.
- Projet : https://github.com/Cinnamon/kotaemon
Une interface utilisateur RAG open source, propre et personnalisable, pour construire et personnaliser votre propre système de questions-réponses. Les besoins des utilisateurs finaux et des développeurs sont pris en compte.

(17) FlashRAG [coffre au trésor]
coffre au trésorLa mise en place des différents artefacts RAG dans une boîte à outils qui permet aux chercheurs de construire leurs propres modèles de recherche au fur et à mesure, comme s'ils choisissaient des blocs de construction.
- Thèse : FlashRAG : une boîte à outils modulaire pour une recherche efficace sur la génération augmentée par la recherche.
- Projet : https://github.com/RUC-NLPIR/FlashRAG
FlashRAG est une boîte à outils open source efficace et modulaire conçue pour aider les chercheurs à reproduire les méthodes RAG existantes et à développer leurs propres algorithmes RAG dans un cadre unifié. Notre boîte à outils met en œuvre 12 méthodes RAG de pointe et recueille et rassemble 32 ensembles de données de référence.

(18) GRAG [Détective]
faire du travail de détectiveL'analyse de l'information : ne pas se contenter d'indices superficiels, creuser plus profondément dans le réseau de connexions entre les textes, traquer la vérité derrière chaque élément d'information comme un crime pour rendre la réponse plus précise.
- Thèse : GRAG : Graph Retrieval-Augmented Generation (Génération augmentée de recherche de graphes)
- Projet : https://github.com/HuieL/GRAG
Les modèles RAG traditionnels ignorent les connexions entre les textes et les informations topologiques de la base de données lorsqu'ils traitent des données complexes structurées en graphe, ce qui entraîne des goulets d'étranglement au niveau des performances. GRAG améliore considérablement les performances et réduit les illusions du processus de recherche et de génération en soulignant l'importance des structures sous-graphiques.

(19) Camel-GraphRAG [gauche et droite]
gifler d'une main, puis de l'autre, en succession rapideL'œil gauche et l'œil droit travaillent ensemble pour trouver des similitudes et suivre le fil du temps, ce qui rend la recherche plus complète et plus précise. Lors d'une recherche, l'œil gauche et l'œil droit travaillent ensemble pour trouver des similitudes et suivre la carte des pistes, ce qui rend la recherche plus complète et plus précise.
- Projet : https://github.com/camel-ai/camel
Camel-GraphRAG s'appuie sur le modèle Mistral pour extraire les connaissances d'un contenu donné et construire des structures de connaissances, puis stocker ces informations dans une base de données de graphes Neo4j. Une approche hybride combinant la recherche vectorielle et la recherche de graphes de connaissances est ensuite utilisée pour interroger et explorer les connaissances stockées.

(20) G-RAG [Stringer]
lit. frappeur de porte (idiome) ; fig. un remède miracle pour les problèmes des gensAu lieu de rechercher des informations seul, vous construisez un réseau de relations pour chaque point de connaissance. Comme un mondain, non seulement vous savez ce que chacun de vos amis sait faire, mais vous savez aussi qui est ami avec qui, ce qui vous permet de suivre la piste directement lorsque vous cherchez des réponses.
- Article : N'oubliez pas de vous connecter ! Améliorer le RAG avec le Reranking basé sur les graphes
Le modèle peut ne pas être en mesure d'utiliser efficacement les documents lorsque leur pertinence par rapport à la question n'est pas évidente ou lorsqu'ils ne contiennent que des informations partielles. G-RAG met en œuvre un réarrangeur basé sur un réseau neuronal graphique (GNN) entre l'extracteur RAG et le lecteur. La méthode combine les informations de connexion entre les documents et les informations sémantiques (via un graphe de représentation sémantique abstrait) pour fournir un classificateur basé sur le contexte pour le RAG.

(21) LLM-Graph-Builder [Mover] (Constructeur de graphe LLM)
un porteurLa première chose à faire est de donner au texte chaotique un foyer compréhensible. Ne pas simplement le transporter, mais comme une personne obsessionnelle-compulsive, étiqueter chaque point de connaissance, dessiner des lignes de relation, et finalement construire un bâtiment de connaissance bien ordonné dans la base de données de Neo4j.
- Projet : https://github.com/neo4j-labs/llm-graph-builder
Neo4j open source LLM-based knowledge graph extraction generator that can convert unstructured data into a knowledge graph in Neo4j . Utilisation de grands modèles pour extraire les noeuds, les relations et leurs attributs à partir de données non structurées.

(22) MRAG [Pieuvre]
pieuvreAu lieu de faire pousser une seule tête pour résoudre le problème, elle fait pousser plusieurs tentacules comme une pieuvre, chacun étant chargé de saisir un angle. En d'autres termes, il s'agit de la version IA du "multitâche".
- Thèse : RAG à plusieurs têtes : résolution de problèmes à plusieurs aspects à l'aide de LLM
- Projet : https://github.com/spcl/MRAG
Les solutions RAG existantes ne se concentrent pas sur les requêtes qui peuvent nécessiter l'accès à de multiples documents au contenu sensiblement différent. Ces requêtes sont fréquentes, mais elles posent des problèmes car les documents intégrés peuvent être très éloignés les uns des autres dans l'espace d'intégration, ce qui rend difficile leur récupération. Cet article présente Multihead RAG (MRAG), un nouveau schéma qui vise à combler cette lacune avec une idée simple mais puissante : l'utilisation de l'espace d'encastrement des documents. Transformateur L'activation d'une couche d'attention à têtes multiples, plutôt que d'une couche de décodage, sert de clé pour capturer des documents à multiples facettes. La motivation principale est que différentes têtes d'attention peuvent apprendre à capturer différents aspects des données. L'utilisation des activations correspondantes produit des encastrements représentant les éléments de données et les divers aspects de la requête, ce qui améliore la précision de la recherche des requêtes complexes.

(23) PlanRAG [stratège]
un stratègeLe plan de bataille : Un plan de bataille complet est élaboré, puis la situation est analysée en fonction des règles et des données, et enfin les meilleures décisions tactiques sont prises.
- Thèse : PlanRAG : A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers (Génération puis récupération augmentée pour les modèles génératifs à grand langage en tant que décideurs)
- Projet : https://github.com/myeon9h/PlanRAG
PlanRAG étudie comment utiliser des modèles de langage à grande échelle pour résoudre des problèmes décisionnels complexes d'analyse de données en définissant la tâche d'AQ décisionnelle, c'est-à-dire la détermination de la meilleure décision en fonction du problème décisionnel Q, des règles commerciales R et de la base de données D. PlanRAG génère d'abord un plan décisionnel, puis le récupérateur génère des requêtes pour l'analyse de données.

(24) FoRAG [écrivain]
écrivainL'essai est rédigé dans un plan qui encadre l'essai et qui est ensuite développé et affiné paragraphe par paragraphe. Un "rédacteur" aide à perfectionner chaque détail et à garantir la qualité du travail en vérifiant soigneusement les faits et en suggérant des modifications.
- Thèse : FoRAG : Factuality-optimised Retrieval Augmented Generation for Web-enhanced Long-form Question Answering (Génération augmentée de recherche optimisée pour les faits pour la réponse aux questions en ligne)
FoRAG propose un nouveau générateur d'amélioration des contours, dans lequel le générateur utilise des modèles de contours pour rédiger des contours de réponse basés sur la requête de l'utilisateur et le contexte dans la première étape, et étend chaque point de vue basé sur le contour généré dans la deuxième étape pour construire la réponse finale. Une approche d'optimisation factuelle basée sur un cadre RLHF à double grain fin bien conçu est également proposée, qui fournit des signaux de récompense plus denses en introduisant une conception à grain fin dans les deux étapes centrales de l'évaluation factuelle et de la modélisation de la récompense.

(25) Multi-Meta-RAG [méta-screener]
méta-filtreComme un gestionnaire de données expérimenté, il utilise de multiples mécanismes de filtrage pour identifier le contenu le plus pertinent parmi une grande quantité d'informations. Il ne se contente pas de regarder la surface, il analyse les "étiquettes d'identité" (métadonnées) des documents pour s'assurer que chaque élément d'information qu'il trouve est réellement en rapport avec le sujet.
- Thèse : Multi-Meta-RAG : Amélioration du RAG pour les requêtes multi-sauts en utilisant le filtrage de base de données avec des métadonnées extraites du LLM
- Projet : https://github.com/mxpoliakov/multi-meta-rag
Multi-Meta-RAG utilise le filtrage des bases de données et les métadonnées extraites du LLM pour améliorer la sélection par le RAG des documents pertinents provenant de diverses sources et se rapportant au problème.

(26) RankRAG [All Rounder] (en anglais)
polyvalentLe juge : Avec un peu d'entraînement, vous pouvez être à la fois "juge" et "compétiteur". Comme un athlète doué, avec un peu d'entraînement, vous pouvez surpasser les professionnels dans plusieurs disciplines tout en maîtrisant toutes vos compétences.
- Thèse : RankRAG : Unifier le classement contextuel avec la génération augmentée par la recherche dans les LLMs
RankRAG's affine un LLM unique avec des instructions pour effectuer à la fois le classement contextuel et la génération de réponses. En ajoutant une petite quantité de données de classement aux données d'apprentissage, le LLM affiné par des instructions fonctionne étonnamment bien et surpasse même les modèles de classement d'experts existants, y compris le même LLM spécifiquement affiné sur une grande quantité de données de classement. Cette conception simplifie non seulement la complexité des modèles multiples dans les systèmes RAG traditionnels, mais améliore également le jugement de la pertinence contextuelle et l'efficacité de l'utilisation des informations en partageant les paramètres du modèle.

(27) GraphRAG-Local-UI [Modificateur]
accordeur: Transformer une voiture de sport en une voiture pratique pour les routes locales, avec un tableau de bord convivial pour que tout le monde puisse la conduire facilement.
- Projet : https://github.com/severian42/GraphRAG-Local-UI
GraphRAG-Local-UI est une version adaptée au modèle local de GraphRAG, basé sur Microsoft, avec un riche écosystème d'interfaces utilisateur interactives.

(28) ThinkRAG [petit secrétaire]
secrétaire juniorLe livre de poche : il condense un énorme corpus de connaissances dans une version de poche, comme un petit secrétaire en déplacement, prêt à vous aider à trouver des réponses sans avoir besoin d'un appareil volumineux.
- Projet : https://github.com/wzdavid/ThinkRAG
Le système ThinkRAG Big Model Retrieval Enhanced Generation peut être facilement déployé sur des ordinateurs portables pour permettre une interrogation intelligente des bases de connaissances locales.

(29) Nano-GraphRAG [charge légère]
lit. faire ses valises et partir au combat (idiome) ; fig. voyager avec aisanceL'Europe de l'Est : Comme un athlète légèrement armé, l'équipement élaboré a été simplifié, mais les compétences de base ont été conservées.
- Projet : https://github.com/gusye1234/nano-graphrag
Le Nano-GraphRAG est un GraphRAG plus petit, plus rapide et plus concis, tout en conservant les fonctionnalités de base.
(30) RAGFlow-GraphRAG [Navigateur]
navigateur (dans un avion ou un bateau)La carte de l'Union européenne est une carte qui permet de prendre des raccourcis dans le labyrinthe des questions et des réponses en dessinant d'abord une carte pour marquer tous les points de connaissance, en fusionnant les panneaux de signalisation qui font double emploi et en réduisant spécifiquement la carte pour que les personnes qui demandent leur chemin ne prennent pas le chemin le plus long.
- Projet : https://github.com/infiniflow/ragflow
RAGFlow s'appuie sur la mise en œuvre de GraphRAG pour introduire la construction de graphes de connaissances en tant qu'option facultative dans la phase de prétraitement des documents afin de servir les scénarios QFS Q&A, et introduit des améliorations telles que la dépondération des entités et l'optimisation des tokens.

(31) Medical-Graph-RAG [Médecin numérique]
médecin numériqueLes propositions de diagnostic ne sont pas inventées de toutes pièces, mais sont justifiées, de sorte que le médecin et le patient puissent comprendre le raisonnement qui sous-tend chaque diagnostic.
- Thèse : Medical Graph RAG : Towards Safe Medical Large Language Model via Graph Retrieval-Augmented Generation (en anglais)
- Projet : https://github.com/SuperMedIntel/Medical-Graph-RAG
MedGraphRAG est un cadre conçu pour relever les défis de l'application du LLM en médecine. Il utilise une approche basée sur les graphes pour améliorer la précision des diagnostics, la transparence et l'intégration dans les flux de travail cliniques. Le système améliore la précision du diagnostic en générant des réponses étayées par des sources fiables, en s'attaquant à la difficulté de maintenir le contexte dans de grands volumes de données médicales.

(32) HybridRAG [combinaison de médecine chinoise]
Prescription de la médecine chinoiseÀ l'instar de la médecine traditionnelle chinoise (MTC), un seul médicament n'est pas aussi efficace qu'une combinaison de plusieurs médicaments. Les bases de données vectorielles sont responsables de la rapidité de la recherche, et les graphes de connaissances complètent la logique relationnelle, en complétant leurs forces respectives.
- Thèse : HybridRAG : Intégration des graphes de connaissances et de la génération vectorielle augmentée pour une extraction efficace de l'information.
Une nouvelle approche basée sur une combinaison des techniques Knowledge Graph RAG (GraphRAG) et VectorRAG, appelée HybridRAG, afin d'améliorer les systèmes de questions-réponses pour l'extraction d'informations à partir de documents financiers, permet de générer des réponses précises et pertinentes sur le plan contextuel. Dans les phases d'extraction et de génération, HybridRAG pour l'extraction de contexte à partir de bases de données vectorielles et de graphes de connaissances est plus performant que VectorRAG et GraphRAG traditionnels en termes de précision d'extraction et de génération de réponses.

(33) W-RAG [Recherche évolutive]
Recherche sur l'évolutionLe moteur de recherche : Comme un bon moteur de recherche auto-évolutif, il apprend ce qu'est une bonne réponse en notant des paragraphes d'articles dans un grand modèle, améliorant ainsi progressivement sa capacité à trouver des informations clés.
- Thèse : W-RAG : Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering (Récupération dense faiblement supervisée dans RAG pour la réponse à des questions ouvertes)
- Projet : https://github.com/jmnian/weak_label_for_rag
Les techniques d'extraction dense faiblement supervisée dans le domaine ouvert des quiz exploitent les capacités de classement des grands modèles de langage pour créer des données faiblement étiquetées pour l'entraînement des extracteurs denses. En évaluant la probabilité que le grand modèle de langage génère la bonne réponse sur la base de la question et de chaque paragraphe, la probabilité de réussir l'épreuve de BM25 Les K premiers passages retrouvés sont reclassés. Les passages les mieux classés sont ensuite utilisés comme exemples d'entraînement positifs pour la recherche intensive.

(34) RAGChecker [inspecteur de la qualité]
inspecteur de la qualitéLa réponse n'est pas simplement bonne ou mauvaise, mais sera examinée en profondeur, de la recherche d'informations à la production de la réponse finale, comme le ferait un examinateur rigoureux, qui donnerait un rapport de notation détaillé et indiquerait les points à améliorer.
- Thèse : RAGChecker : un cadre fin pour diagnostiquer la génération améliorée par la recherche.
- Projet : https://github.com/amazon-science/RAGChecker
L'outil de diagnostic de RAGChecker fournit des rapports de diagnostic précis, complets et fiables sur le système RAG et donne des indications utiles pour améliorer les performances. Il évalue non seulement la performance globale du système, mais fournit également une analyse approfondie de la performance des deux modules principaux, la récupération et la génération.

(35) Méta-connaissances-RAG [Chercheur]
académieIl ne se contente pas de collecter des informations, mais réfléchit activement au problème, annote et résume chaque document, et envisage même les problèmes possibles à l'avance. Il relie les points de connaissance connexes pour former un réseau de connaissances, de sorte que la requête gagne en profondeur et en étendue, tout comme un universitaire vous aide à faire une synthèse de la recherche.
- Thèse : Métaconnaissance pour l'extraction de modèles de langage élargis et augmentés
Meta-Knowledge-RAG (MK Summary) présente un nouveau flux de travail RAG centré sur les données qui transforme le système traditionnel de "récupération-lecture" en un cadre plus avancé de "préparation-réécriture-réécriture-lecture" afin d'obtenir une meilleure compréhension de la base de connaissances au niveau de l'expert du domaine. "afin d'obtenir une compréhension de la base de connaissances à un niveau d'expertise plus élevé. Notre approche repose sur la génération de métadonnées et de questions et réponses synthétiques pour chaque document, ainsi que sur l'introduction d'un nouveau concept de résumé de méta-connaissances pour le regroupement de documents basé sur les métadonnées. Les innovations proposées permettent d'améliorer les requêtes personnalisées des utilisateurs et de rechercher des informations approfondies dans les bases de connaissances.

(36) CommunityKG-RAG [Exploration communautaire]
Exploration communautaireIl est capable d'exploiter les associations entre les connaissances et les caractéristiques du groupe pour trouver des informations pertinentes avec précision et vérifier leur fiabilité sans étude particulière.
- Thèse : CommunityKG-RAG : Exploitation des structures communautaires dans les graphes de connaissances pour une génération améliorée en matière de recherche et de vérification des faits. vérification
CommunityKG-RAG est un nouveau cadre à zéro échantillon qui combine les structures communautaires du graphe de connaissances avec un système RAG pour améliorer le processus de vérification des faits. CommunityKG-RAG est capable de s'adapter à de nouveaux domaines et requêtes sans formation supplémentaire, et il exploite la nature multi-sauts des structures communautaires du graphe de connaissances pour améliorer de manière significative la précision et la pertinence de la recherche d'informations. de l'information et la pertinence.

(37) TC-RAG [Bloqueur de mémoire]
artiste mnémotechniqueLe LLM : Mettre un cerveau avec une fonction d'auto-nettoyage sur le LLM. Tout comme nous résolvons des problèmes, nous écrirons les étapes importantes sur le brouillon et les barrerons lorsque nous aurons terminé. Il ne s'agit pas d'un apprentissage par cœur, il se souvient de ce qui doit être mémorisé et vide ce qui doit être oublié à temps, comme une brute à l'école qui peut ranger sa chambre.
- Thèse : TC-RAG : Turing-Complete RAG's Case study on Medical LLM Systems (Étude de cas sur les systèmes LLM médicaux)
- Projet : https://github.com/Artessay/TC-RAG
L'introduction d'un système Turing-complet pour gérer les variables d'état permet d'obtenir une récupération des connaissances plus efficace et plus précise. En utilisant un système de pile de mémoire avec des capacités adaptatives de récupération, de raisonnement et de planification, TC-RAG assure non seulement l'arrêt contrôlé du processus de récupération, mais atténue également l'accumulation de connaissances erronées par le biais d'opérations Push et Pop.

(38) RAGLAB [Arena]
arèneLa Commission européenne a adopté le principe d'une concurrence loyale entre les algorithmes, selon les mêmes règles, à l'instar d'un processus d'essai normalisé dans un laboratoire scientifique, afin que chaque nouvelle méthode soit évaluée de manière objective et transparente.
- Thèse : RAGLAB : un cadre unifié modulaire et orienté vers la recherche pour la génération assistée par la recherche.
- Projet : https://github.com/fate-ubw/RAGLab
Il y a un manque croissant de comparaisons complètes et équitables entre les nouveaux algorithmes RAG, et l'abstraction de haut niveau des outils open-source conduit à un manque de transparence et limite la capacité à développer de nouveaux algorithmes et métriques d'évaluation.RAGLAB est une bibliothèque modulaire, orientée vers la recherche et open-source qui reproduit les 6 algorithmes et construit un écosystème de recherche complet. Avec RAGLAB, nous comparons équitablement les 6 algorithmes sur 10 points de référence, aidant ainsi les chercheurs à évaluer efficacement et à innover en matière d'algorithmes.

(39) MemoRAG.
ont une mémoire très réactiveIl ne se contente pas de rechercher des informations à la demande, il comprend et mémorise l'ensemble de la base de connaissances. Lorsque vous posez une question, il extrait rapidement les souvenirs pertinents de ce "super cerveau" et donne une réponse précise et perspicace, à l'instar d'un expert chevronné.
- Projet : https://github.com/qhjqhj00/MemoRAG
MemoRAG est un cadre innovant de génération augmentée de récupération (RAG) construit sur la base d'un modèle efficace de mémoire ultra-longue. Contrairement aux RAG standard qui traitent principalement des requêtes avec des besoins d'information explicites, MemoRAG utilise son modèle de mémoire pour parvenir à une compréhension globale de l'ensemble de la base de données. En rappelant de la mémoire des indices spécifiques à la requête, MemoRAG améliore l'extraction des preuves, ce qui permet de générer des réponses plus précises et plus riches en contexte.

(40) OP-RAG [gestion de l'attention]
Gestion de l'attentionC'est comme lire un livre très épais, on ne peut pas se souvenir de tous les détails, mais ce sont ceux qui savent marquer les chapitres clés qui sont les maîtres. Il ne s'agit pas de lire sans but, mais comme un lecteur chevronné, tout en lisant et en notant les points clés, de passer directement à la page marquée lorsque c'est nécessaire.
- Thèse : Défense du RAG à l'ère des modèles linguistiques à contexte long
Les contextes extrêmement longs dans les LLM conduisent à une réduction de l'attention portée aux informations pertinentes et à une dégradation potentielle de la qualité de la réponse. En réexaminant le RAG dans la génération de réponses à des contextes longs, nous proposons un mécanisme de génération d'amélioration de la recherche préservant l'ordre, OP-RAG, qui améliore de manière significative les performances du RAG dans les applications de questions et réponses à des contextes longs.

(41) AgentRE [Extraction intelligente]
Extraction intelligenteComme un sociologue qui observe bien les relations, il ne se contente pas de retenir les informations clés, mais prend l'initiative de les vérifier et d'y réfléchir en profondeur, afin de comprendre avec précision le réseau complexe des relations. Même face à des relations complexes, il est capable de les analyser sous de multiples angles afin d'en clarifier le sens et d'éviter de faire du sens avec des mots.
- Thèse : AgentRE : un cadre basé sur des agents pour naviguer dans des paysages d'information complexes dans l'extraction de relations
- Projet : https://github.com/Lightblues/AgentRE
En intégrant les capacités de mémoire, de récupération et de réflexion des modèles de langage à grande échelle, AgentRE relève efficacement les défis posés par les différents types de relations dans l'extraction de relations de scènes complexes et les relations ambiguës entre les entités dans une seule phrase.AgentRE se compose de trois modules principaux qui permettent aux agents d'acquérir et de traiter efficacement les informations et d'améliorer considérablement les performances de l'ER.

(42) iText2KG [Architecte]
architectesIl ne nécessite pas la préparation préalable de plans architecturaux détaillés et peut être étendu et amélioré de manière flexible en fonction des besoins.
- Thèse : iText2KG : Construction incrémentale de graphes de connaissances à l'aide de grands modèles linguistiques
- Projet : https://github.com/AuvaLab/itext2kg
iText2KG (Incremental Knowledge Graph Construction) utilise de grands modèles de langage (LLM) pour construire des graphes de connaissances à partir de documents bruts et permet la construction incrémentale de graphes de connaissances grâce à quatre modules (Document Refiner, Incremental Entity Extractor, Incremental Relationship Extractor et Graph Integrator) sans qu'il soit nécessaire de définir au préalable des ontologies ou de dispenser une formation supervisée approfondie.

(43) GraphInsight [interprétation graphique]
interprétation de l'atlasIl sait placer les informations importantes aux endroits les plus visibles, tout en consultant des références pour ajouter des détails si nécessaire, et raisonner étape par étape à travers des graphiques complexes afin que l'IA ait une vue d'ensemble sans perdre de vue les détails.
- Thèse : GraphInsight : Exploiter les possibilités offertes par les grands modèles linguistiques pour la compréhension de la structure des graphes
GraphInsight est un nouveau cadre visant à améliorer la compréhension par les LLM des informations graphiques de niveau macro et micro. GraphInsight est basé sur deux stratégies clés : 1) placer les informations graphiques clés dans des endroits où les LLM ont une forte performance de mémoire, et 2) introduire des bases de connaissances externes légères pour les régions ayant une faible performance de mémoire, en s'inspirant de l'idée de Retrieval Augmented Generation (RAG). En outre, GraphInsight explore l'intégration de ces deux stratégies dans le processus de l'agent LLM pour les tâches de graphes composites qui nécessitent un raisonnement en plusieurs étapes.

(44) LA-RAG [Dialecte Passé]
livre de dialecteL'IA est capable d'identifier avec précision non seulement le mandarin standard, mais aussi de comprendre les accents locaux grâce à une analyse méticuleuse de la parole et à une compréhension du contexte, ce qui lui permet de communiquer avec des personnes de différentes régions sans aucune barrière.
- Thèse : LA-RAG : Amélioration de la précision de l'ASR basée sur la LLM avec une génération augmentée par la recherche.
LA-RAG, un nouveau paradigme de génération augmentée de récupération (RAG) pour l'ASR basé sur le LLM. LA-RAG utilise un stockage de données vocales au niveau du jeton et des mécanismes de récupération de la parole pour améliorer la précision de l'ASR grâce à la fonctionnalité de l'apprentissage contextuel du LLM (ICL).

(45) SFR-RAG [recherche affinée]
Recherche simplifiéeIl est comme un conseiller de référence raffiné, petit par la taille mais précis par la fonction, il comprend les besoins et sait comment chercher de l'aide extérieure, en veillant à ce que les réponses soient à la fois précises et efficaces.
- Thèse : SFR-RAG : vers des LLM fidèles au contexte
SFR-RAG est un petit modèle de langage affiné avec des instructions axées sur la génération basée sur le contexte et la minimisation des illusions. En se concentrant sur la réduction du nombre d'arguments tout en maintenant des performances élevées, le modèle SFR-RAG inclut une fonctionnalité d'appel de fonction qui lui permet d'interagir dynamiquement avec des outils externes pour récupérer des informations contextuelles de haute qualité.

(46) FlexRAG [Expert en compression]
Spécialiste de la compressionCondensez un long discours en un résumé concis, et le taux de compression peut être ajusté de manière flexible en fonction des besoins, de sorte que les informations clés ne soient pas perdues et que les coûts de stockage et de traitement puissent être économisés. C'est comme transformer un livre épais en une note de lecture concise.
- Thèse : Lighter And Better : Towards Flexible Context Adaptation For Retrieval Augmented Generation (Plus léger et meilleur : vers une adaptation flexible du contexte pour une génération améliorée de la recherche)
Les contextes récupérés par FlexRAG sont compressés dans des encastrements compacts avant d'être encodés par les LLM. L'une des principales caractéristiques de FlexRAG est sa flexibilité, qui lui permet de prendre en charge efficacement différents taux de compression et de conserver sélectivement les contextes importants. Grâce à ces conceptions techniques, FlexRAG atteint une qualité de génération supérieure tout en réduisant de manière significative les coûts opérationnels. Des expériences approfondies sur divers ensembles de données Q&A valident notre approche en tant que solution rentable et flexible pour les systèmes RAG.

(47) CoTKR [traduction de l'atlas]
traduction de l'atlasComme un enseignant patient, il ou elle comprend le contexte de la connaissance et l'explique ensuite étape par étape, ne se contentant pas de la répéter, mais la transmettant en profondeur. Parallèlement, en recueillant les réactions des étudiants, vous pouvez améliorer votre propre façon d'expliquer, afin de transmettre les connaissances de manière plus claire et plus efficace.
- Thèse : CoTKR : Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering (Réécriture de connaissances améliorée par la chaîne de pensée pour la réponse aux questions des graphes de connaissances complexes)
- Projet : https://github.com/wuyike2000/CoTKR
La méthode CoTKR (Chain-of-Thought Enhanced Knowledge Rewriting) alterne entre la génération de chemins d'inférence et les connaissances correspondantes, surmontant ainsi la limitation de la réécriture des connaissances en une seule étape. En outre, pour combler la différence de préférences entre le réécrivain de connaissances et le modèle d'assurance qualité, nous proposons une stratégie de formation qui aligne les préférences à partir du retour d'information des questions et réponses afin d'optimiser davantage le réécrivain de connaissances en exploitant le retour d'information du modèle d'assurance qualité.

(48) Open-RAG [Groupe de réflexion]
dépôtLa recherche de l'information : la décomposition d'énormes modèles linguistiques en groupes d'experts capables de réfléchir de manière indépendante et de travailler ensemble, et particulièrement aptes à distinguer les informations vraies des fausses, à savoir s'il faut ou non rechercher des informations à des moments critiques, comme le ferait un groupe de réflexion chevronné.
- Thèse : Open-RAG : Amélioration de la recherche et du raisonnement à l'aide de grands modèles linguistiques en libre accès
- Projet : https://github.com/ShayekhBinIslam/openrag
Open-RAG améliore le raisonnement dans RAG en ouvrant de grands modèles de langage, en convertissant de grands modèles de langage arbitrairement denses en modèles de mélange d'experts (MoE) clairsemés et efficaces en termes de paramètres, capables de traiter des tâches de raisonnement complexes, y compris des requêtes à saut unique et à sauts multiples.OPEN-RAG forme de manière unique les modèles à faire face à des termes interférents difficiles qui semblent pertinents mais qui sont trompeurs.

(49) TableRAG [Expert Excel]
Spécialiste ExcelLes tableaux croisés dynamiques : Allez au-delà de la simple visualisation de données tabulaires et sachez comprendre et extraire des données dans les dimensions de l'en-tête et de la cellule, tout en utilisant un tableau croisé dynamique pour localiser et extraire rapidement les informations clés dont vous avez besoin.
- Article : TableRAG : compréhension d'un million de mots à l'aide de modèles linguistiques
TableRAG a conçu un cadre de génération amélioré par la recherche, spécifiquement pour la compréhension des tableaux, combinant la recherche de schémas et de cellules par l'expansion des requêtes afin d'identifier les données clés avant de fournir des informations au modèle linguistique, ce qui permet un encodage des données plus efficace et une recherche plus précise, réduisant considérablement la longueur des indices et la perte d'informations.

(50) LightRAG [Spider-Man]
spidermanL'auteur de ces lignes est un bibliothécaire clairvoyant : il navigue avec agilité dans la toile du savoir, attrape les filaments entre les points, mais se sert aussi de la toile pour suivre les fils. Comme un bibliothécaire clairvoyant, non seulement vous savez où se trouve chaque livre, mais vous savez aussi quels livres lire ensemble.
- Thèse : LightRAG : Génération simple et rapide augmentée par la recherche
- Projet : https://github.com/HKUDS/LightRAG
Ce cadre intègre les structures graphiques dans le processus d'indexation et de recherche de texte. Ce cadre innovant utilise un système de recherche à deux niveaux qui améliore la recherche d'informations complètes à partir de la découverte de connaissances de bas niveau et de haut niveau. En outre, la combinaison de structures graphiques et de représentations vectorielles facilite la recherche efficace d'entités pertinentes et de leurs relations, ce qui améliore considérablement les temps de réponse tout en maintenant la pertinence contextuelle. Cette capacité est encore renforcée par un algorithme de mise à jour incrémentielle qui garantit l'intégration en temps utile de nouvelles données, ce qui permet au système de rester efficace et réactif dans un environnement de données en évolution rapide.

(51) AstuteRAG [Sage juge]
Un juge senséLe juge : rester vigilant face aux informations externes, ne pas se fier aux résultats des recherches, faire bon usage de ses propres connaissances, vérifier l'authenticité des informations et peser les preuves de plusieurs parties pour parvenir à une conclusion, tout comme un juge de haut niveau.
- Thèse : Astute RAG : Surmonter l'augmentation imparfaite de la recherche et les conflits de connaissances pour les grands modèles linguistiques
La robustesse et la fiabilité du système sont améliorées par l'extraction adaptative d'informations à partir des connaissances internes des MFR, leur combinaison avec des résultats de recherche externes et la finalisation de la réponse sur la base de la fiabilité des informations.

(52) TurboRAG [maître de la sténographie]
maître sténographeLes questions les plus fréquentes sont les suivantes : faites vos devoirs à l'avance et notez toutes les réponses dans un petit carnet. Comme une brute de l'école de raid avant l'examen, pas le fermoir clinique, mais les questions courantes à l'avance dans le mauvais livre. Lorsque vous avez besoin d'utiliser directement, économisez chaque fois que vous devez déduire une fois sur place.
- Thèse : TurboRAG : Accélération de la génération augmentée par la recherche avec des caches KV précalculés pour le texte fragmenté.
- Projet : https://github.com/MooreThreads/TurboRAG
TurboRAG optimise le paradigme de raisonnement du système RAG en pré-calculant et en stockant les caches KV des documents hors ligne. Contrairement aux approches traditionnelles, TurboRAG ne calcule plus ces caches KV à chaque inférence, mais récupère les caches précalculés pour un prépeuplement efficace, éliminant ainsi la nécessité d'un calcul en ligne répétitif. Cette approche réduit considérablement les frais généraux de calcul et accélère le temps de réponse tout en maintenant la précision.

(53) StructRAG [Organisateur]
organisateurLes informations sont classées par catégories, comme dans une garde-robe bien rangée. Comme un instituteur imitant l'esprit humain, au lieu de mémoriser par cœur, dessinez d'abord une carte mentale.
- Thèse : StructRAG : stimuler le raisonnement intensif en connaissances des LLM via la structuration hybride de l'information à l'heure de l'inférence
- Projet : https://github.com/Li-Z-Q/StructRAG
Inspiré par la théorie cognitive selon laquelle les humains convertissent les informations brutes en connaissances structurées lorsqu'ils traitent des raisonnements à forte intensité de connaissances, le cadre introduit un mécanisme hybride de structuration de l'information qui construit et utilise des connaissances structurées dans le format le plus approprié en fonction des exigences spécifiques de la tâche à accomplir. En imitant des processus de pensée semblables à ceux de l'homme, il améliore les performances du LLM pour les tâches de raisonnement à forte intensité de connaissances.

(54) VisRAG [yeux de feu]
des yeux perspicacesJ'ai enfin compris que les mots ne sont qu'une forme particulière d'expression des images. Comme un lecteur qui a ouvert les yeux, il n'insiste plus sur l'analyse mot par mot, mais "voit" directement l'image dans son ensemble. Au lieu de l'OCR, j'ai utilisé un appareil photo et j'ai appris l'essence de l'expression "une image vaut mille mots".
- Thèse : VisRAG : Vision-based Retrieval-augmented Generation on Multi-modality Documents (en anglais)
- Projet : https://github.com/openbmb/visrag
La génération est améliorée par la construction d'un processus RAG basé sur un modèle visuel et linguistique (VLM) qui incorpore et récupère directement les documents sous forme d'images. Par rapport au RAG textuel traditionnel, VisRAG évite la perte d'informations lors de l'analyse syntaxique et préserve les informations du document original de manière plus complète. Les expériences montrent que VisRAG est plus performant que le RAG traditionnel à la fois dans les phases d'extraction et de génération, avec une amélioration des performances de bout en bout de 25-391 TP3 T. VisRAG utilise non seulement efficacement les données d'apprentissage, mais fait également preuve de fortes capacités de généralisation, ce qui en fait un choix idéal pour le RAG de documents multimodaux.

(55) AGENTiGraph [Gestionnaire de connaissances]
gestionnaire des connaissancesIl vous aide à organiser et à présenter vos connaissances par le biais d'une communication quotidienne, avec une équipe d'assistants prêts à répondre aux questions et à mettre à jour les informations, rendant ainsi la gestion des connaissances facile et naturelle.
- Thèse : AGENTiGraph : une plateforme interactive de graphes de connaissances pour les chatbots basés sur le LLM et utilisant des données privées
AGENTiGraph est une plateforme de gestion des connaissances par interaction avec le langage naturel. AGENTiGraph utilise une architecture multi-intelligence pour interpréter dynamiquement les intentions de l'utilisateur, gérer les tâches et intégrer de nouvelles connaissances, ce qui lui permet de s'adapter à l'évolution des besoins de l'utilisateur et des contextes de données.

(56) RuleRAG [Suivi des règles]
suivre la boussole et l'équerre (idiome) ; suivre les règles de manière inflexibleL'IA : Apprendre à l'IA à faire des choses avec des règles, c'est comme faire entrer une nouvelle personne dans l'entreprise et lui donner d'abord un manuel de l'employé. Au lieu d'apprendre sans but, c'est comme un professeur strict qui explique d'abord les règles et les exemples, puis laisse les étudiants faire par eux-mêmes. De plus, ces règles deviennent une mémoire musculaire, et la prochaine fois que vous rencontrerez des problèmes similaires, vous saurez naturellement comment y faire face.
- Thèse : RuleRAG : Génération augmentée de recherche guidée par des règles avec des modèles de langage pour la réponse aux questions.
- Projet : https://github.com/chenzhongwu20/RuleRAG_ICL_FT
RuleRAG propose une approche de génération assistée par des règles, basée sur un modèle de langage, qui introduit explicitement des règles symboliques comme exemples d'apprentissage contextuel (RuleRAG - ICL) pour guider un extracteur à extraire des documents logiquement pertinents dans le sens des règles et guider uniformément un générateur à produire des réponses informées guidées par le même ensemble de règles. En outre, la combinaison des requêtes et des règles peut être utilisée comme données de mise au point supervisée pour mettre à jour les extracteurs et les générateurs (RuleRAG - FT) afin d'obtenir un meilleur respect des instructions basées sur les règles, ce qui permet d'extraire des résultats plus pertinents et de générer des réponses plus acceptables.

(57) Classe-RAG [juges]
jugeLe juge de la Cour européenne des droits de l'homme : Plutôt que de s'appuyer sur des dispositions rigides pour trancher les affaires, il examine le jugement à travers une bibliothèque de jurisprudence qui ne cesse de s'enrichir. Comme un juge expérimenté, il tient à la main un codex à feuilles mobiles et lit à tout moment les derniers arrêts, de sorte que le jugement prend à la fois la température et l'échelle.
- Thèse : Class-RAG : Modération de contenu avec génération augmentée de recherche
Les classificateurs de contrôle du contenu sont essentiels à la sécurité de l'IA générative. Cependant, il est souvent difficile de distinguer les nuances entre un contenu sûr et un contenu non sûr. À mesure que les technologies se généralisent, il devient de plus en plus difficile et coûteux d'affiner continuellement les modèles pour faire face aux risques. C'est pourquoi nous proposons l'approche Class-RAG, qui permet d'atténuer immédiatement les risques en mettant à jour dynamiquement la base de recherche. Class-RAG est plus souple et plus transparent que les modèles traditionnels de mise au point, et donne de meilleurs résultats en termes de classification et de résistance aux attaques. Il est également démontré que l'élargissement de la base de recherche peut améliorer efficacement les performances de l'audit à faible coût.

(58) Self-RAG [Réflecteur]
penseurLorsqu'il répond à des questions, il ne se contente pas de consulter des informations, mais réfléchit et vérifie l'exactitude et l'exhaustivité de ses réponses. En "réfléchissant tout en parlant", comme un érudit prudent, il s'assure que chaque point de vue est étayé par des preuves solides.
- Thèse : Self-RAG : Apprendre à retrouver, générer et critiquer par l'autoréflexion
- Projet : https://github.com/AkariAsai/self-rag
Self-RAG améliore la qualité et la précision des modèles linguistiques grâce à la récupération et à l'autoréflexion. Le cadre forme un modèle de langage arbitraire unique qui peut récupérer des passages à la demande de manière adaptative et utiliser des marqueurs spéciaux appelés marqueurs de réflexion pour générer et réfléchir aux passages récupérés et à leur propre contenu généré. La génération de marqueurs réfléchissants rend le modèle linguistique contrôlable dans la phase de raisonnement, ce qui lui permet d'adapter son comportement aux différentes exigences de la tâche.

(59) SimRAG [autodidacte]
un génie autodidacteLes étudiants se familiarisent avec leurs connaissances professionnelles en faisant des exercices répétés.
- Thèse : SimRAG : Self-Improving Retrieval-Augmented Generation for Adapting Large Language Models to Specialised Domains (Génération auto-améliorée pour la recherche et l'adaptation de grands modèles linguistiques à des domaines spécialisés)
SimRAG est une méthode d'auto-formation qui dote les LLM des capacités combinées de questions-réponses et de génération de questions pour s'adapter à des domaines spécifiques. De bonnes questions ne peuvent être posées que si les connaissances sont réellement comprises. Ces deux capacités se complètent pour aider le modèle à mieux comprendre l'expertise. Le LLM est d'abord affiné en termes de suivi des instructions, de questions et réponses et de recherche de données pertinentes. Il invite ensuite le même LLM à générer une variété de questions pertinentes pour le domaine à partir d'un corpus non étiqueté, avec des stratégies de filtrage supplémentaires pour conserver des exemples synthétiques de haute qualité. En utilisant ces exemples synthétiques, le LLM peut améliorer ses performances sur des tâches RAG spécifiques à un domaine.

(60) ChunkRAG [extraits du maître]
personne qui tire des extraits d'un livreLes articles longs sont divisés en petits paragraphes, puis les éléments les plus pertinents sont sélectionnés avec un œil professionnel, sans passer à côté de l'essentiel ou se laisser distraire par un contenu non pertinent.
- Thèse : ChunkRAG : Nouvelle méthode de filtrage LLM-Chunk pour les systèmes RAG
ChunkRAG propose une approche de filtrage de morceaux pilotée par LLM pour améliorer le cadre des systèmes RAG en évaluant et en filtrant les informations récupérées au niveau des morceaux, où les "morceaux" représentent des parties cohérentes plus petites d'un document. Notre approche utilise le découpage sémantique pour diviser le document en parties cohérentes et utilise une notation de la pertinence basée sur un grand modèle linguistique pour évaluer dans quelle mesure chaque morceau correspond à la requête de l'utilisateur. En filtrant les morceaux les moins pertinents avant la phase de génération, nous réduisons considérablement les illusions et améliorons la précision des faits.

(61) FastGraphRAG [Radar]
radar (mot d'emprunt)Les points de connaissance : Comme le Page Rank de Google, donnez aux points de connaissance une liste d'actualité. C'est comme un leader d'opinion dans un réseau social, plus les gens le suivent, plus il est facile d'être vu. Au lieu de chercher sans but, c'est comme un éclaireur avec un radar, qui cherche là où le signal est fort.
- Projet : https://github.com/circlemind-ai/fast-graphrag
FastGraphRAG fournit un cadre efficace, interprétable et très précis de génération augmentée de recherche rapide de graphes (FastGraphRAG). Il applique l'algorithme PageRank au processus de traversée du graphe de connaissances afin de localiser rapidement les nœuds de connaissances les plus pertinents. En calculant le score d'importance d'un nœud, PageRank permet à GraphRAG de filtrer et de trier les informations dans le graphe de connaissances de manière plus intelligente. Cela revient à équiper GraphRAG d'un "radar d'importance", qui permet de localiser rapidement les informations clés dans l'immense quantité de données.

(62) AutoRAG [Tuner]
accordeurLe RAG est un accordeur expérimenté qui trouve le meilleur son non pas en devinant, mais en effectuant des tests scientifiques. Il essaie automatiquement diverses combinaisons de RAG, tout comme un mixeur teste différents équipements audio pour trouver la "solution de jeu" la plus harmonieuse.
- Thèse : AutoRAG : Automated Framework for optimisation of Retrieval Augmented Generation Pipeline (Cadre automatisé pour l'optimisation du pipeline de génération augmentée de recherche)
- Projet : https://github.com/Marker-Inc-Korea/AutoRAG_ARAGOG_Paper
Le cadre AutoRAG identifie automatiquement les modules RAG appropriés pour un ensemble de données donné et explore et approxime la combinaison optimale de modules RAG pour cet ensemble de données. En évaluant systématiquement différents paramètres RAG pour optimiser le choix des techniques, le cadre est similaire à la pratique de l'AutoML dans l'apprentissage automatique traditionnel, où des expériences approfondies sont menées pour optimiser le choix des techniques RAG et améliorer l'efficacité et l'évolutivité du système RAG.

(63) Plan x RAG [Chef de projet]
chef de projetPlanifier avant d'agir, en divisant les tâches importantes en tâches plus petites et en organisant le travail en parallèle de plusieurs "experts". Chaque expert est responsable de son propre domaine et le chef de projet est chargé de résumer les résultats à la fin. Cette approche est non seulement plus rapide et plus précise, mais elle permet également d'expliquer clairement la source de chaque conclusion.
- Thèse : Plan × RAG : Génération augmentée de recherche guidée par la planification
Plan×RAG est un nouveau cadre qui étend le paradigme "recherche - raisonnement" des cadres RAG existants à un paradigme "plan - recherche".Plan×RAG formule les plans de raisonnement sous forme de graphes acycliques dirigés (DAG) qui décomposent les requêtes en sous-requêtes atomiques interdépendantes. Plan×RAG formule le plan de raisonnement sous la forme d'un graphe acyclique dirigé (DAG) et décompose la requête en sous-requêtes atomiques interdépendantes. La génération des réponses suit la structure du DAG, ce qui améliore considérablement l'efficacité grâce à la recherche et à la génération parallèles. Alors que les solutions RAG les plus récentes nécessitent une génération de données extensive et un réglage fin des modèles de langage (LM), Plan×RAG incorpore des LM congelés en tant qu'experts prêts à l'emploi pour générer des réponses de haute qualité.

(64) Sous-grapheRAG [localisateur]
positionneurAu lieu de chercher une aiguille dans une botte de foin, une petite carte des connaissances est dessinée avec précision afin que l'IA puisse trouver rapidement des réponses.
- Thèse : Simple is Effective : The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation (La simplicité est efficace : les rôles des graphes et des grands modèles de langage dans la recherche basée sur les graphes de connaissances - Génération augmentée)
- Projet : https://github.com/Graph-COM/SubgraphRAG
SubgraphRAG étend le cadre RAG basé sur KG en récupérant des sous-graphes et en utilisant LLM pour l'inférence et la prédiction de réponse. Un perceptron multicouche léger est combiné à un mécanisme de notation ternaire parallèle pour une récupération efficace et flexible des sous-graphes, tout en encodant la distance de structure dirigée pour améliorer l'efficacité de la récupération. La taille des sous-graphes récupérés peut être ajustée de manière flexible pour répondre aux exigences de la requête et à la capacité du LLM en aval. Cette conception établit un équilibre entre la complexité du modèle et la capacité d'inférence, ce qui permet un processus d'extraction évolutif et polyvalent.

(65) RuRAG [Alchimiste]
alchimisteL'IA est un outil d'aide à la décision : tel un alchimiste, elle peut distiller des quantités massives de données en règles logiques claires et les exprimer en langage simple, rendant ainsi l'IA plus intelligente dans les applications pratiques.
- Thèse : RuAG : Learned-rule-augmented Generation for Large Language Models (Génération à base de règles apprises pour de grands modèles de langage)
vise à améliorer les capacités de raisonnement des modèles de langage à grande échelle (LLM) en distillant automatiquement de grandes quantités de données hors ligne en règles logiques du premier ordre interprétables et en les injectant dans les LLM. Le cadre utilise la recherche d'arbres de Monte Carlo (MCTS) pour découvrir les règles logiques et les transformer en langage naturel, ce qui permet l'injection de connaissances et l'intégration transparente pour les tâches en aval du LLM. L'article évalue l'efficacité du cadre sur des tâches industrielles publiques et privées, démontrant son potentiel d'amélioration des capacités LLM dans diverses tâches.

(66) RAGViz [œil transparent]
vision en tunnelRendre le système RAG transparent, voir quelle phrase le modèle est en train de lire, comme un médecin qui regarde une radiographie, et voir ce qui ne va pas d'un seul coup d'œil.
- Thèse : RAGViz : Diagnostiquer et visualiser la génération assistée par ordinateur
- Projet : https://github.com/cxcscmu/RAGViz
RAGViz fournit des visualisations des documents récupérés et de l'attention portée au modèle pour aider les utilisateurs à comprendre l'interaction entre le balisage généré et les documents récupérés, et peut être utilisé pour diagnostiquer et visualiser les systèmes RAG.

(67) AgenticRAG [Assistant intelligent]
assistant intelligentIl ne s'agit plus d'une simple recherche et d'une copie, mais d'un assistant qui peut jouer le rôle de secrétaire confidentiel. Comme un administrateur compétent, il sait non seulement rechercher des informations, mais aussi passer un coup de fil, organiser une réunion et demander des instructions.
AgenticRAG décrit un RAG basé sur la mise en œuvre d'intelligences IA. Plus précisément, il incorpore des intelligences IA dans le processus RAG pour coordonner ses composants et effectuer des actions supplémentaires au-delà de la simple recherche et génération d'informations afin de surmonter les limites des processus corporels non intelligents.

(68) HtmlRAG [Typographe]
typographeLa connaissance n'est pas tenue comme un compte-rendu, mais comme la mise en page d'un magazine, avec du gras là où il faut du gras et du rouge là où il faut du rouge. C'est comme un rédacteur en chef pointilleux qui estime que le contenu ne suffit pas, mais qu'il faut aussi la mise en page, afin que les points clés puissent être vus d'un seul coup d'œil.
- Thèse : HtmlRAG : HTML est meilleur que le texte brut pour modéliser les connaissances acquises dans les systèmes RAG
- Projet : https://github.com/plageon/HtmlRAG
HtmlRAG utilise HTML plutôt que du texte brut comme format pour récupérer des connaissances dans RAG, HTML est meilleur que le texte brut lorsqu'il s'agit de modéliser des connaissances à partir de documents externes et la plupart des LLM ont une bonne compréhension de HTML.

(69) M3DocRAG [Sensualiste]
personne sensorielleIl est capable non seulement de lire, mais aussi de lire des images et d'écouter des voix. Comme un candidat polyvalent dans une émission de variétés, il peut lire des images, comprendre des mots, sauter quand il faut sauter, se concentrer sur les détails quand il faut se concentrer, et ne peut pas être vaincu par toutes sortes de défis.
- Thèse : M3DocRAG : Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding (M3DocRAG : la recherche multimodale est ce dont vous avez besoin pour la compréhension de documents multiples)
M3DocRAG est un nouveau cadre RAG multimodal qui s'adapte de manière flexible à une variété de contextes documentaires (domaines fermés et ouverts), de sauts de questions (uniques et multiples) et de modes de preuve (texte, tableaux, graphiques, etc.). M3DocRAG utilise un extracteur multimodal et un MLM pour trouver les documents pertinents et répondre aux questions, et en tant que tel, il peut traiter efficacement des documents uniques ou multiples tout en préservant les informations visuelles. visuelle.

(70) KAG [Maîtrise en logique]
maître logiqueLe travail de l'enseignant : Il ne s'agit pas seulement de trouver des réponses similaires au feeling, mais aussi d'établir une relation de cause à effet entre les connaissances. Comme un professeur de mathématiques rigoureux, vous devez non seulement connaître la réponse, mais aussi expliquer comment cette réponse a été obtenue étape par étape.
- Thèse : KAG : Renforcer les LLM dans les domaines professionnels via la génération augmentée de connaissances
- Projet : https://github.com/OpenSPG/KAG
L'écart entre la similarité des vecteurs et la pertinence du raisonnement sur les connaissances dans le RAG, ainsi que l'insensibilité aux logiques de connaissances (par exemple, les valeurs numériques, les relations temporelles, les règles d'experts, etc.) entravent l'efficacité des services d'expertise.KAG est conçu pour tirer parti des forces du graphe de connaissances (KG) et de la recherche vectorielle afin de relever les défis ci-dessus, et améliore de manière bidirectionnelle les modèles de langage à grande échelle (LLM) et le graphe de connaissances à travers cinq aspects clés pour améliorer les performances de génération et d'inférence : (1) représentation des connaissances adaptée aux LLM, (2) indexation croisée entre le graphe de connaissances et les morceaux bruts, (3) moteur d'inférence hybride guidé par la forme logique, (4) alignement des connaissances avec l'inférence sémantique, et (5) amélioration de la capacité de modélisation du KAG.

(71) FILCO [Filtre]
criblesLe rédacteur : Comme un rédacteur rigoureux, il est capable d'identifier et de retenir les informations les plus précieuses dans de grandes quantités de texte, en veillant à ce que chaque élément de contenu fourni à l'IA soit exact et pertinent.
- Thèse : Apprendre à filtrer le contexte pour une génération optimisée pour la recherche d'information
- Projet : https://github.com/zorazrw/filco
FILCO améliore la qualité du contexte fourni au générateur en identifiant les contextes utiles sur la base d'approches lexicales et de la théorie de l'information, et en entraînant un modèle de filtrage du contexte pour filtrer les contextes récupérés.

(72) LazyGraphRAG [actuaire]
actuairesLes grands modèles onéreux peuvent être utilisés à bon escient, mais un pas est un pas si on peut l'économiser. Comme une ménagère qui sait vivre, on n'achète pas quand on voit les soldes au supermarché, on compare avant de décider où dépenser son argent pour le meilleur rapport qualité-prix.
- Projet : https://github.com/microsoft/graphrag
Une nouvelle approche de la génération de recherche améliorée par les graphes (RAG). Cette approche réduit considérablement les coûts d'indexation et d'interrogation tout en maintenant ou en surpassant les concurrents en termes de qualité des réponses, ce qui la rend hautement évolutive et efficace dans un large éventail de cas d'utilisation.LazyGraphRAG retarde l'utilisation du LLM. Pendant la phase d'indexation, LazyGraphRAG n'utilise que des techniques NLP légères pour traiter le texte, en retardant l'invocation du LLM jusqu'à la requête proprement dite. Cette stratégie "paresseuse" permet d'éviter des coûts d'indexation initiaux élevés et d'utiliser efficacement les ressources.
| Graphique traditionnelRAG | LazyGraphRAG | |
| étape d'indexation | - Extraction et description d'entités et de relations à l'aide de LLM - Générer des résumés pour chaque entité et chaque relation - Résumer le contenu d'une communauté à l'aide de LLM - Générer des vecteurs d'intégration - Générer des fichiers Parquet | - Extraction de concepts et de relations cooccurrentes à l'aide de techniques NLP - Construire des cartes conceptuelles - Extraction des structures communautaires - LLM n'est pas utilisé dans la phase d'indexation |
| Phase d'enquête | - Répondre aux questions directement à l'aide des résumés de la communauté - Manque d'affinement des requêtes et de concentration sur les informations pertinentes | - Utilisation de LLM pour affiner les requêtes et générer des sous-requêtes - Sélection de segments de texte et de communautés en fonction de leur pertinence - Extraction et génération de réponses à l'aide de LLM - Un contenu plus pertinent, des réponses plus précises |
| Appel LLM | - Utilisation intensive tant dans la phase d'indexation que dans la phase d'interrogation | - LLM n'est pas utilisé dans la phase d'indexation - Appeler le LLM uniquement dans la phase d'interrogation - L'apprentissage tout au long de la vie est utilisé plus efficacement |
| rentabilité | - Coût élevé et indexation fastidieuse - Performances des requêtes limitées par la qualité de l'index | - Le coût d'indexation n'est que de 0,1% par rapport au GraphRAG traditionnel. - Efficacité élevée des requêtes et bonne qualité des réponses |
| stockage des données | - Les fichiers Parquet sont générés à partir de données indexées et conviennent au stockage et au traitement de données à grande échelle. | - Les données indexées sont stockées dans des formats légers (par exemple JSON, CSV), qui conviennent mieux à un développement rapide et à des données de petite taille. |
| Scénarios d'utilisation | - Pour les scénarios qui ne sont pas sensibles aux ressources informatiques et au temps - Le graphe de connaissances complet doit être construit à l'avance et stocké sous forme de fichier Parquet pour être ensuite importé dans la base de données en vue d'analyses complexes | - Pour les scénarios nécessitant une indexation et une réponse rapides - Idéal pour les requêtes ponctuelles, les analyses exploratoires et le traitement de données en continu |
Enquête RAG
- Enquête sur la génération de textes enrichis par la recherche d'information
- Recherche d'informations multimodales pour la génération augmentée : une enquête
- Génération améliorée en fonction de la recherche pour les grands modèles de langage : une étude
- Génération assistée par la recherche pour le contenu généré par l'IA : une enquête
- Étude sur la génération de textes enrichis par la recherche pour les grands modèles de langage
- RAG et RAU : une étude sur le modèle de langage amélioré par la recherche dans le traitement du langage naturel
- Une enquête sur les LLMs de la réunion du RAG : vers des grands modèles linguistiques améliorés par la recherche d'information
- Évaluation de la génération améliorée par la recherche : une enquête
- Génération assistée par la recherche pour le traitement du langage naturel : une enquête
- Génération améliorée par la recherche de graphes : une étude
- Une étude complète de la génération assistée par la recherche (RAG) : évolution, paysage actuel et orientations futures
- Retrieval Augmented Generation (RAG) et au-delà : une enquête complète sur la manière d'amener vos stagiaires à utiliser plus judicieusement les données externes
RAG Benchmark
- Analyse comparative de grands modèles de langage dans la génération assistée par la recherche d'information
- RECALL : une référence pour la robustesse des LLM par rapport à la connaissance contrefactuelle externe
- ARES : un cadre d'évaluation automatisé pour les systèmes de génération assistée par ordinateur (Retrieval-Augmented Generation Systems)
- RAGASÉvaluation automatisée de la génération augmentée de la recherche d'information
- CRUD-RAG : un banc d'essai chinois complet pour la génération de grands modèles linguistiques améliorés par la recherche d'information
- FeB4RAG : évaluation de la recherche fédérée dans le contexte de la génération augmentée de la recherche.
- Banc d'essai CodeRAG : la recherche peut-elle améliorer la génération de code ?
- Long2RAG : Évaluation de la génération améliorée de la recherche de contexte et de forme longue avec rappel des points clés
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...