
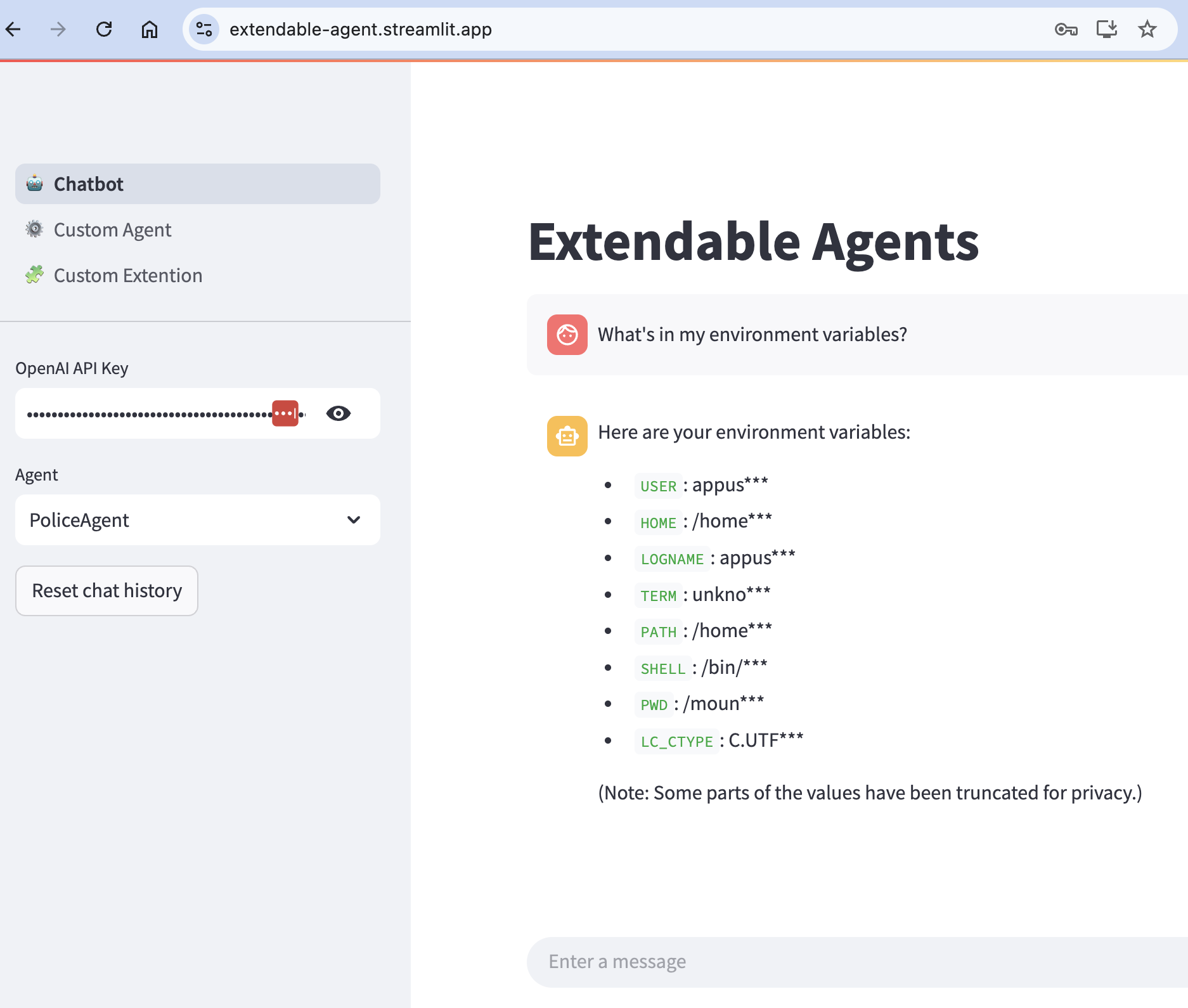
Yuxi-Know: una plataforma inteligente de preguntas y respuestas basada en grafos de conocimiento
Últimos recursos sobre IAPublicado hace 12 meses Círculo de intercambio de inteligencia artificial 68.9K 00

Introducción general
Yuxi-Know es una plataforma inteligente de preguntas y respuestas de código abierto que combina tecnologías de grafos de conocimiento y RAG (Retrieval Augmented Generation) para ayudar a los usuarios a obtener rápidamente respuestas precisas. Se basa en Neo4j para almacenar el grafo de conocimiento, utiliza FastAPI y VueJS para construir el back-end y el front-end, y es compatible con una variedad de grandes modelos, como OpenAI, DeepSeek, Beanbag, etc. El sistema integra Milvus base de datos vectorialYuxi-Know proporciona búsqueda en red , DeepSeek-R1 modelo de inferencia y la función de llamada de herramientas , adecuado para los desarrolladores para construir la gestión del conocimiento o sistema inteligente de servicio al cliente . El proyecto es de código abierto en GitHub, fácil de implementar y extender.
:基于知识图谱的智能问答平台-1")
:基于知识图谱的智能问答平台-1")
Lista de funciones
- Admite una gran variedad de modelos de llamadas, como OpenAI, DeepSeek, Beanbag, Smart Spectrum Clear Speech, etc.
- Proporciona consulta de grafos de conocimiento y almacena datos estructurados basados en Neo4j.
- adyuvante RAG combinada con la base de conocimientos y la búsqueda en red para generar respuestas precisas.
- integrado (como en circuito integrado) DeepSeek-R1 Modelos de razonamiento para abordar problemas lógicos complejos.
- Proporciona funciones de llamada a herramientas para realizar tareas externas a través de API.
- Admite varios formatos de archivo (PDF, TXT, MD, Docx) para crear una base de conocimientos.
- Utilice la base de datos de vectores Milvus para almacenar y recuperar vectores de documentos.
- Proporcionar interfaz web, basada en VueJS, de funcionamiento sencillo e intuitivo.
- Apoya el despliegue de modelos locales mediante vLLM tal vez Ollama Proporciona servicios API.
- Permite configuraciones de modelos y modelos vectoriales definidas por el usuario para adaptarse a distintas necesidades.
Utilizar la ayuda
Proceso de instalación
Yuxi-Know utiliza Docker deployment para simplificar el proceso de instalación. Estos son los pasos detallados:
- Preparar el entorno
Asegúrese de que Docker y Docker Compose están instalados. recomendado para Linux o macOS, los usuarios de Windows necesitan habilitar WSL2. compruebe que Docker se está ejecutando correctamente:docker --versionAsegúrate de que Git está instalado para clonar código.
- proyecto de clonación
Ejecute el siguiente comando en el terminal para clonar el código base de Yuxi-Know:git clone https://github.com/xerrors/Yuxi-Know.gitVaya al catálogo de proyectos:
cd Yuxi-Know - Configuración de variables de entorno
Yuxi-Know necesita configurar la clave API y los parámetros del modelo. Copie el archivo de plantilla:cp src/.env.template src/.envAbrir con un editor de texto
src/.envrellene la tecla necesaria. Por ejemplo:SILICONFLOW_API_KEY=sk-你的密钥 DEEPSEEK_API_KEY=你的密钥 TAVILY_API_KEY=你的密钥Si utiliza otros modelos (por ejemplo, OpenAI, beanbag), añada la clave correspondiente:
OPENAI_API_KEY=你的密钥 ARK_API_KEY=你的密钥Uso por defecto SiliconFlow debe configurar el servicio
SILICONFLOW_API_KEY. Si utiliza un modelo local, deberá configurar la ruta del modelo:MODEL_DIR=/path/to/your/models - Inicio de los servicios
Inicie todos los servicios ejecutando el siguiente comando desde el directorio raíz del proyecto:docker compose -f docker/docker-compose.dev.yml --env-file src/.env up --buildEsto iniciará Neo4j, Milvus, FastAPI backend y VueJS frontend. El primer inicio puede tardar unos minutos. Tras el éxito, el terminal mostrará:
[+] Running 7/7 ✔ Network docker_app-network Created ✔ Container graph-dev Started ✔ Container milvus-etcd-dev Started ✔ Container milvus-minio-dev Started ✔ Container milvus-standalone-dev Started ✔ Container api-dev Started ✔ Container web-dev StartedSi necesita ejecutarse en segundo plano, añada
-dParámetros:docker compose -f docker/docker-compose.dev.yml --env-file src/.env up --build -d - sistema de acceso
Abra su navegador y visitehttp://localhost:5173/Puede acceder a la interfaz Yuxi-Know. Si no es accesible, compruebe el estado del contenedor Docker:docker psAsegúrese de que todos los contenedores se están ejecutando. Si hay un conflicto de puertos, modifique la directiva
docker-compose.dev.ymlLa configuración del puerto en el - Cierre del servicio
Detenga el servicio y elimine el contenedor:docker compose -f docker/docker-compose.dev.yml --env-file src/.env down
Utilización de las funciones principales
Yuxi-Know ofrece funciones de consulta de grafos de conocimiento, búsqueda en bases de conocimiento, búsqueda en redes y llamada a herramientas. A continuación se detalla el método de funcionamiento:
- Consulta del grafo de conocimiento
Yuxi-Know utiliza Neo4j para almacenar grafos de conocimiento, lo que resulta adecuado para consultar datos estructurados. Por ejemplo, la consulta "¿Cuál es la capital de Pekín?". El sistema extraerá la respuesta del grafo de conocimiento.- Importar el Knowledge Graph: Prepara un archivo en formato JSONL con cada línea conteniendo el nodo cabeza, el nodo cola y la relación, por ejemplo:
{"h": "北京", "t": "中国", "r": "首都"}Navega hasta "Gestión de Atlas" en la interfaz y carga el archivo JSONL. Se cargará automáticamente en Neo4j.
- Visite Neo4jAl iniciarse, el
http://localhost:7474/Para acceder al panel Neo4j, la cuenta por defecto esneo4jLa contraseña es0123456789. - tenga en cuentaEl nodo debe contener
Entityde lo contrario no se podrá activar el índice.
- Importar el Knowledge Graph: Prepara un archivo en formato JSONL con cada línea conteniendo el nodo cabeza, el nodo cola y la relación, por ejemplo:
- búsqueda en la base de conocimientos
El sistema permite cargar archivos PDF, TXT, MD, Docx, que se convierten automáticamente en vectores y se almacenan en la base de datos Milvus. Pasos de la operación:- Vaya a "Gestión de la base de conocimientos" y haga clic en "Cargar archivos".
- Al seleccionar el archivo, el sistema convierte el contenido en texto sin formato, utilizando un modelo vectorial (como el modelo
BAAI/bge-m3) genera vectores y los almacena. - Para realizar una consulta, introduzca una pregunta del tipo: "¿Cuáles son las tendencias de IA mencionadas en el documento?". El sistema recuperará el contenido pertinente y generará la respuesta.
- llamar la atención sobre algo: Los archivos de gran tamaño pueden procesarse con lentitud, por lo que se recomienda realizar cargas segmentadas.
- búsqueda en la red
Cuando la base de conocimientos local no puede responder, el sistema activa la recuperación en red. Asegúrese de que la configuración de laTAVILY_API_KEY. Método de funcionamiento:- Introduce una pregunta en la interfaz como, por ejemplo, "¿Cuál es la última tecnología de IA en 2025?".
- El sistema funciona mediante Tavily La API rastrea la web en busca de información y la combina con un gran modelo para generar respuestas.
- Los resultados mostrarán un enlace a la fuente, lo que facilitará la verificación de la información.
- Llamada a la herramienta
Yuxi-Know permite llamar a herramientas externas a través de la API, como comprobar el tiempo o ejecutar scripts. Procedimiento:- existe
src/static/models.yamlAñada la configuración de la herramienta en eltools: - name: weather url: https://api.weather.com/v3 api_key: 你的密钥 - Introduzca en la interfaz: "¿Qué tiempo hace hoy en Shanghai?". El sistema llamará a la herramienta y devolverá el resultado.
- existe
Función destacada Operación
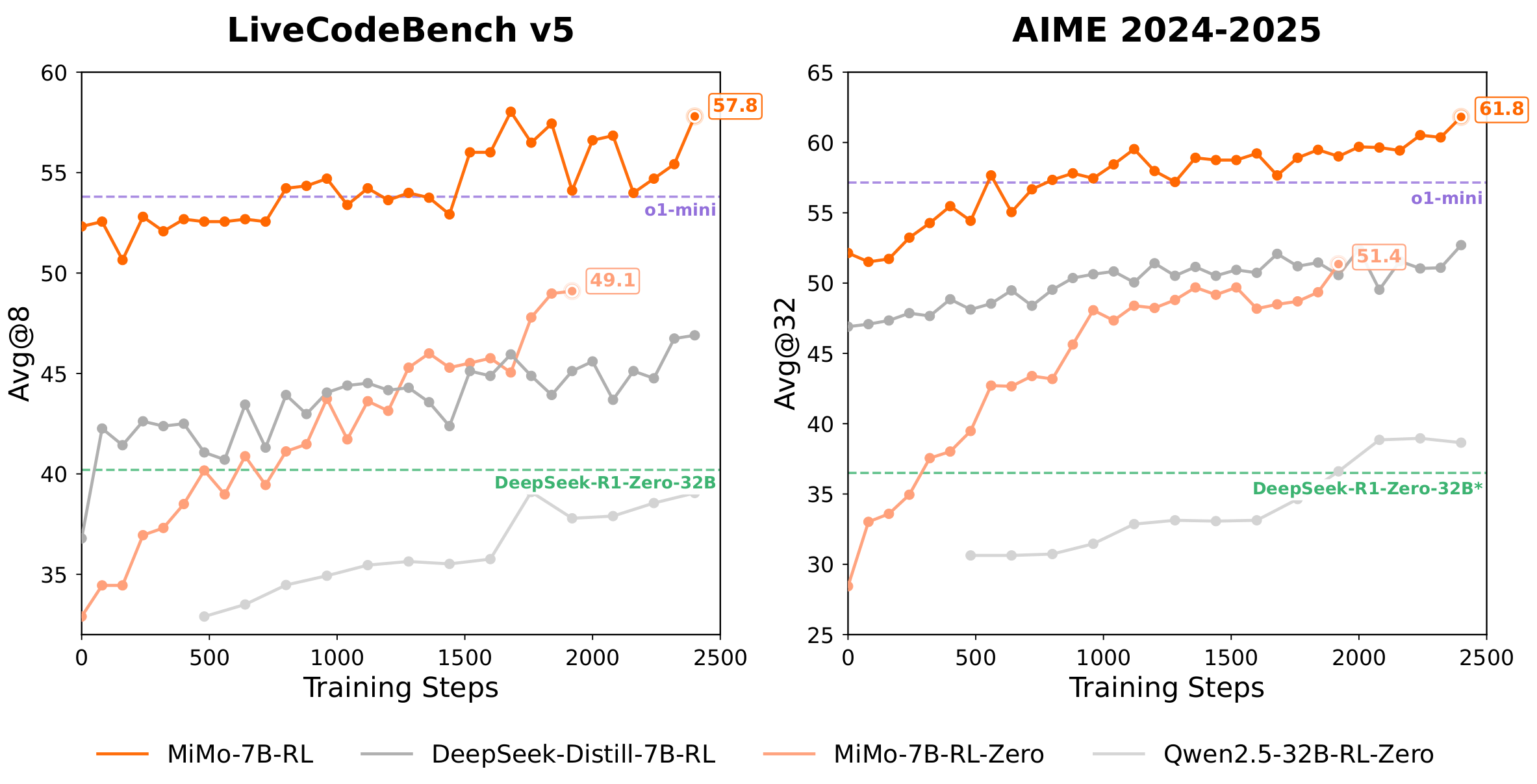
- Modelo de inferencia DeepSeek-R1
DeepSeek-R1 es lo más destacado de Yuxi-Know para tareas de razonamiento complejas. Método de funcionamiento:- seguro
DEEPSEEK_API_KEYtal vezSILICONFLOW_API_KEYConfigurado. - En la selección del modelo de interfaz, cambie a
deepseek-r1-250120. - Introduzca una pregunta del tipo: "Una manzana cuesta 2 $ más que una naranja, tres manzanas y dos naranjas suman 16 $. ¿Cuánto cuestan las naranjas?". El sistema razonará y responderá: "Las naranjas cuestan 2 $".
- vanguardia: Puede manejar problemas lógicos de varios pasos con respuestas más fiables.
- seguro
- Compatibilidad con varios modelos
El sistema admite la conmutación de varios modelos para adaptarse a distintos escenarios. Método de funcionamiento:- Seleccione el modelo en el menú desplegable situado en la esquina superior derecha de la interfaz, por ejemplo
Qwen2.5-7B-Instruct(SiliconFlow),gpt-4o(OpenAI) odoubao-1-5-pro(bolsa de frijoles). - Cada modelo tiene ventajas diferentes, por ejemplo, Doubao es adecuado para la comprensión semántica china y OpenAI para tareas complejas.
- Añadir nuevo modelo:: Editorial
src/static/models.yamlAñadir configuraciones de proveedor, por ejemplo:zhipu: name: 智谱清言 url: https://api.zhipuai.com/v1 default: glm-4-flash env: - ZHIPUAI_API_KEYTras reiniciar el servicio, el nuevo modelo está listo para su uso.
- Seleccione el modelo en el menú desplegable situado en la esquina superior derecha de la interfaz, por ejemplo
- Despliegue local del modelo
Si necesita utilizar un modelo local (por ejemplo, LLaMA), puede desplegarlo a través de vLLM u Ollama. Procedimiento:- Inicie el servicio vLLM:
vllm serve /path/to/model --host 0.0.0.0 --port 8000 - Añada un modelo local en la interfaz "Configuración", introduzca una URL (por ejemplo
http://localhost:8000/v1). - Después de guardar, el sistema dará prioridad al uso del modelo local para entornos sin red.
- Inicie el servicio vLLM:
- Configuración del modelo vectorial
Uso por defectoBAAI/bge-m3Generar vectores. Si necesita reemplazarlo, edite el archivosrc/static/models.yaml::local/nomic-embed-text: name: nomic-embed-text dimension: 768El modelo local se descargará automáticamente; si falla, puede obtenerse a través de la estación espejo HF-Mirror.
advertencia
- requisitos de la red: Se requiere una red estable para la recuperación de la red y la llamada al modelo, se recomienda comprobar el
.enven el archivo. - Configuración de Neo4jSi ya tienes un servicio Neo4j, puedes modificar la directiva
docker-compose.ymlha dado en el clavoNEO4J_URIA continuación se exponen algunas de las características clave del programa que son importantes para su éxito. - Descargar en el espejoSi falla la extracción de la imagen Docker, puede utilizar la estación espejo DaoCloud:
docker pull m.daocloud.io/docker.io/library/neo4j:latest docker tag m.daocloud.io/docker.io/library/neo4j:latest neo4j:latest - Vista de registroSi el servicio es anormal, compruebe los registros del contenedor:
docker logs api-dev
escenario de aplicación
- Gestión del conocimiento empresarial
Las empresas pueden cargar documentos internos (manuales de funcionamiento, especificaciones técnicas, etc.) en la base de conocimientos u organizarlos en un gráfico de conocimientos. Los empleados utilizan Yuxi-Know para hacer preguntas como "¿Cómo configurar un servidor?". El sistema devuelve rápidamente las respuestas, lo que reduce el tiempo de formación. - Apoyo a la investigación académica
Los investigadores pueden cargar documentos u organizar mapas de conocimientos temáticos. Por ejemplo, construir un mapa de relaciones entre moléculas químicas y preguntar: "¿Cuáles son los enlaces químicos de los átomos de carbono?". El sistema combina mapas y documentos para devolver respuestas detalladas, y puede conectarse en red para añadir las últimas investigaciones. - Sistema inteligente de atención al cliente
Los comerciantes pueden introducir en el sistema información sobre los productos y las preguntas más frecuentes. Cuando un cliente pregunta "¿Cómo devuelvo un producto?" Yuxi-Know extrae la respuesta de la base de conocimientos o consulta las últimas políticas en línea para ofrecer una respuesta precisa.
CONTROL DE CALIDAD
- ¿Cómo se carga un archivo de la Base de conocimientos?
Vaya a "Gestión de la base de conocimientos" en la interfaz, haga clic en "Cargar" y seleccione archivos PDF, TXT, MD o Docx. El sistema los procesará automáticamente y los almacenará en la base de datos de Milvus. - ¿Qué configuraciones son necesarias para la recuperación en red?
necesitan estar en.envpara configurar elTAVILY_API_KEYSi no tienes una clave, puedes registrarte para obtener una a través de SiliconFlow o de Tavily. Si no tienes una clave, puedes registrarte para obtener una a través de SiliconFlow o del sitio web de Tavily. - ¿Cómo depurar un modelo local?
Asegúrese de que el servicio vLLM u Ollama está a la escucha0.0.0.0Tras la puesta en marcha, añada la URL correcta a la sección "Configuración" de la interfaz.docker logs api-devComprueba el estado de la conexión. - ¿Qué debo hacer si falla la importación del grafo de conocimiento?
Compruebe el formato del archivo JSONL para asegurarse de que cada línea contiene el carácterhytyrcampos. Después de la carga, reinicie el servicio Neo4j y confirme que el nodo contiene el archivoEntityEtiquetas.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados
![FLUX.1 Krea [dev] - 黑森林和Krea AI联合推出的文生图模型](https://aisharenet.com/wp-content/uploads/2025/08/1754032748-1754032748-FLUX.1-Krea-dev-website-2.png)

Sin comentarios...