
Un artículo que le llevará a comprender RAG (Retrieval Augmented Generation), el concepto de introducción teórica + código práctico
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 47.9K 00

I. Los LLM ya tienen grandes capacidades, ¿por qué necesitamos RAG (Retrieval Augmentation Generation)?
Aunque el LLM ha demostrado importantes capacidades, siguen existiendo varios retos preocupantes:
- El problema de la ilusión: LLM utiliza un enfoque probabilístico basado en estadísticas para generar texto palabra por palabra, un mecanismo que lleva intrínsecamente a la posibilidad de obtener resultados que parecen ser lógicamente rigurosos pero que no se basan en hechos, las llamadas "grandiosas declaraciones ficticias";
- (a) Problemas de puntualidad: a medida que el LLM se amplía, aumentan el coste y la duración del ciclo de formación. Como resultado, los datos que contienen información actualizada son difíciles de incorporar al proceso de entrenamiento del modelo, lo que hace que el LLM sea menos capaz de hacer frente a cuestiones sensibles al tiempo como "por favor, sugiera la película favorita actual";
- Cuestiones de seguridad de los datos: el LLM genérico no tiene datos internos de la empresa ni datos de los usuarios, entonces las empresas quieren utilizar el LLM bajo la premisa de garantizar la seguridad, la mejor manera es poner todos los datos localmente, y todos los cálculos de negocio de los datos de la empresa se hacen localmente. El gran modelo en línea sólo cumple una función de resumen;
II. ¿Presentación del GAR?
RAG (Retrieval Augmented Generation) es un marco tecnológico cuyo núcleo radica en que, cuando el LLM se enfrenta a la tarea de responder a una pregunta o crear un texto, primero busca en la biblioteca de documentos a gran escala y filtra los materiales que están estrechamente relacionados con la tarea, para después guiar con precisión el posterior proceso de generación de respuestas o construcción de textos basado en estos materiales, con el objetivo de mejorar de esta forma la precisión y fiabilidad de la salida del modelo. El objetivo es mejorar de este modo la precisión y la fiabilidad del resultado del modelo.
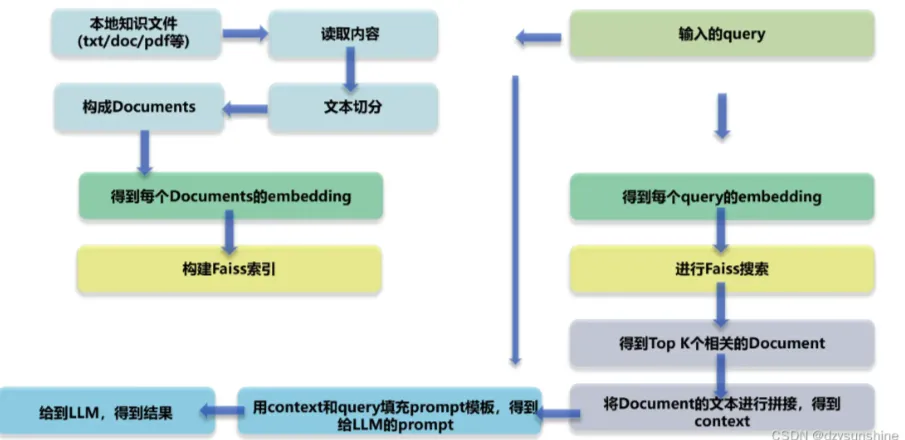
RAG Diagrama de arquitectura técnica
III. ¿Cuáles son los principales módulos del GAR?
- Módulo 1: Análisis del trazado
- Lectura de archivos de conocimiento local (pdf, txt, html, doc, excel, png, jpg, voz, etc.)
- Recuperación de documentos de conocimiento
- Módulo II: Construir la base de conocimientos
- Segmentación de textos de conocimiento y construcción de textos documentales
- Incrustación de texto en documentos
- Doc Texto Construir Índice
- Módulo 3: Puesta a punto del Gran Modelo
- Módulo IV: Cuestionario de conocimientos basado en GAR
- Incorporación de la consulta del usuario
- consulta Recall
- ordenar consulta
- Los K documentos más relevantes se unieron para construir el contexto.
- Creación de instrucciones basadas en la consulta y el contexto
- Alimentar el modelo grande para generar la respuesta
¿Cuáles son las ventajas del GAR sobre el uso directo de los LLM para el cuestionario?
El enfoque RAG (Retrieval Augmented Generation) ofrece a los desarrolladores la posibilidad de mejorar significativamente la precisión de sus respuestas sin tener que volver a entrenar grandes modelos para cada tarea específica, simplemente conectándose a una base de conocimientos externa a la que se pueden inyectar recursos de información adicionales. Este enfoque es especialmente adecuado para tareas que dependen en gran medida de los conocimientos especializados. A continuación se exponen las principales ventajas del modelo GAR:
- Escalabilidad: Reduzca el tamaño del modelo y los gastos generales de formación, al tiempo que simplifica el proceso de ampliación y actualización de la base de conocimientos.
- Precisión: al citar las fuentes, los usuarios pueden verificar la credibilidad de las respuestas, lo que a su vez aumenta su confianza en los resultados del modelo.
- Controlabilidad: admite la actualización flexible y la configuración personalizada de los contenidos de conocimiento.
- Interpretabilidad: mostrar las entradas de búsqueda de las que dependen las predicciones del modelo, mejorando la comprensión y la transparencia.
- Versatilidad: RAG puede ajustarse y personalizarse para adaptarse a una amplia gama de escenarios de aplicación, abarcando áreas como las preguntas y respuestas, el resumen de textos y los sistemas de diálogo.
- Puntualidad: el uso de técnicas de recuperación para captar los últimos avances informativos garantiza que las respuestas sean inmediatas y precisas, una clara ventaja sobre los modelos lingüísticos que sólo se basan en datos de entrenamiento intrínsecos.
- Personalización de dominios: mediante la asignación de conjuntos de datos de texto a sectores o dominios específicos, RAG puede proporcionar apoyo especializado específico.
- Seguridad: Al aplicar la segmentación de roles y el control de seguridad a nivel de base de datos, RAG refuerza eficazmente la gestión del uso de los datos, demostrando una mayor seguridad que la posible ambigüedad de los modelos de ajuste fino para la gestión de derechos de datos.
V. Compare y contraste la GAR y la SFT y díganos cuáles son las diferencias.
De hecho, la SFT es una de las soluciones más comunes y básicas a los problemas anteriores del LLM, y también es un paso fundamental en la realización de aplicaciones del LLM. A continuación, es necesario comparar los dos enfoques en varias dimensiones:
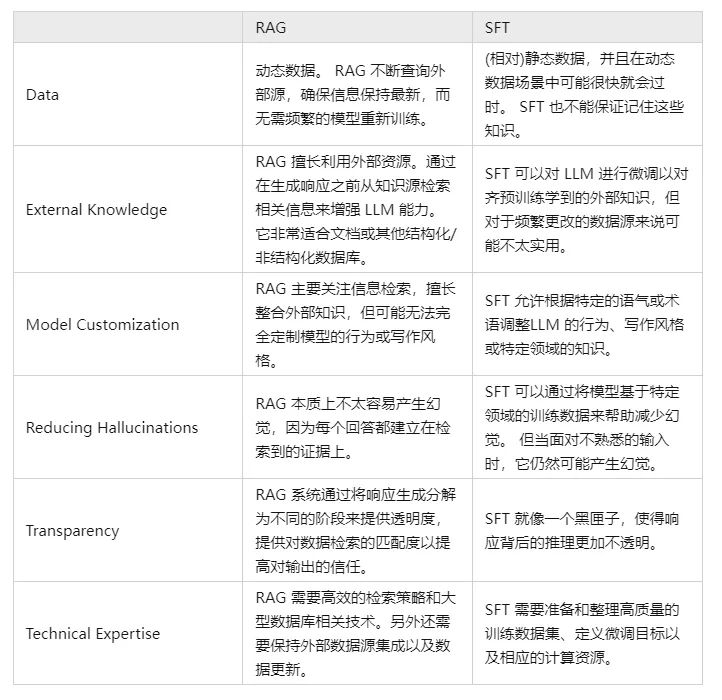
Por supuesto, estos dos métodos no son lo uno o lo otro, y es razonable y necesario combinar las necesidades empresariales con las ventajas de ambos métodos y utilizarlos de forma razonable.
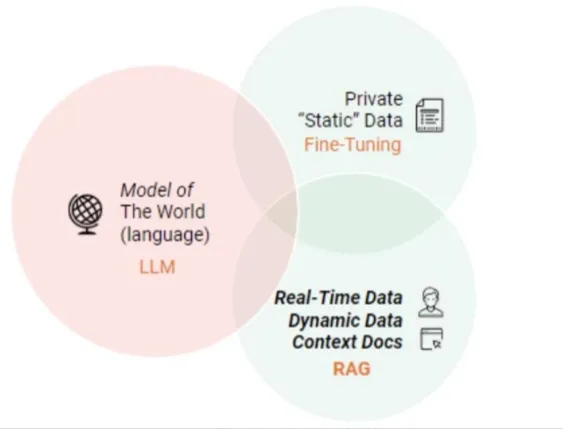
Módulo 1: Análisis del trazado
¿Por qué necesito un análisis del trazado?
Aunque el valor fundamental de la tecnología RAG (Retrieval Augmented Generation) reside en su combinación de recuperación y generación para mejorar la precisión y coherencia del contenido textual, sus límites funcionales pueden ampliarse para incluir el análisis de la disposición en dominios de aplicación específicos, como el análisis sintáctico de documentos, la autoría inteligente y la construcción de diálogos, especialmente cuando se enfrenta a la necesidad de procesar información estructurada o semiestructurada.
Esto se debe a que este tipo de información suele estar incrustada en una estructura de diseño específica que requiere un profundo conocimiento de los elementos de la página y sus interrelaciones.
Además, cuando el modelo GAR se enfrenta a fuentes de datos que contienen ricos componentes multimedia o multimodales, como páginas web, archivos PDF, registros de texto enriquecido, documentos de Word, datos de imágenes, clips de voz, datos tabulares y otros contenidos complejos, resulta crucial disponer de una capacidad básica de análisis del diseño para poder ingerir y utilizar eficazmente esa información no textual. Esta capacidad ayuda al modelo a analizar con precisión las distintas unidades de información e integrarlas con éxito en una interpretación global significativa.
paso 1: adquisición de documentos sobre conocimientos locales
q1: ¿Cómo adquirir documentos sobre conocimientos locales?
El acceso local a archivos de conocimiento implica el proceso de extraer información de múltiples fuentes de datos (por ejemplo, .txt, .pdf, .html, .doc, .xlsx, .png, .jpg, archivos de audio, etc.). Para los distintos tipos de archivos se necesitan estrategias específicas de acceso y análisis sintáctico que permitan obtener eficazmente el conocimiento contenido en ellos. A continuación, presentaremos los métodos de acceso y las dificultades de las distintas fuentes de datos.
q2: ¿Cómo obtener el contenido de texto enriquecido txt?
- Introducción: texto enriquecido se almacena principalmente en el archivo txt, porque el diseño es relativamente limpio, por lo que la manera de conseguir relativamente simple
- Habilidades prácticas:
- [Análisis del diseño - lectura de texto enriquecido txt]
q3: ¿Cómo obtener el contenido del documento PDF?
- ¡Introducción: documentos PDF en los datos es más compleja, incluyendo texto, imágenes, tablas y otros estilos diferentes de datos, por lo que el proceso de análisis será más complejo!
- Habilidades prácticas:
- [Análisis de diseño--PDF parsing magic pdfplumber
- Análisis de diseño--PDF Parser PyMuPDF
q4: ¿Cómo obtener el contenido de un documento HTML?
- ¡Introducción: documentos PDF en los datos es más compleja, incluyendo texto, imágenes, tablas y otros estilos diferentes de datos, por lo que el proceso de análisis será más complejo!
- Habilidades prácticas:
- Análisis del diseño - Análisis sintáctico de HTML BeautifulSoup
q5: ¿Cómo obtener el contenido del documento Doc?
- Introducción: los datos de los documentos Doc son más complejos, ya que incluyen texto, imágenes, tablas y otros estilos de datos diferentes, por lo que el proceso de análisis sintáctico será más complejo.
- Habilidades prácticas:
- Layout analysis--Docx parsing artifact python-docx]
q6: ¿Cómo utilizar el OCR para obtener el contenido de una imagen?
- Introducción: reconocimiento óptico de caracteres (óptico) Carácter Recognition, OCR) es el proceso de análisis y reconocimiento de archivos de imagen de información textual para obtener información textual y de diseño. También significa que el texto de la imagen se reconoce y se devuelve en forma de texto.
- Pensamientos:
- Reconocimiento de texto: reconocimiento de áreas de texto bien localizadas, el problema principal es resolver el problema de qué es cada texto, el área de texto de la imagen en la conversión de la información de caracteres.
- Detección de texto: el problema resuelto es dónde hay texto y cuánto abarca;
- Proyecto actual de OCR de código abierto
- Tesseract
- PádelOCR
- EasyOCR
- chineseocr
- chinocr_lite
- TrWebOCR
- cnocr
- hn_ocr
- Estudios teóricos:
- Análisis de trazado - Herramienta de análisis sintáctico de imágenes OCR].
- Habilidades prácticas:
- [Análisis del diseño - OCR tesseract]
- [Análisis del diseño - OCR Magic PaddleOCR]
- [Análisis del diseño - Artefactos OCR hn_ocr]
q7: ¿Cómo utilizar ASR para obtener el contenido del habla?
- Alias: Reconocimiento automático del habla Reconocimiento automático del habla, (ASR)
- Introducción: La conversión de una señal vocal en un mensaje de texto correspondiente es como el "sistema auditivo de una máquina", que permite a ésta transformar la señal vocal en un texto o comando correspondiente mediante el reconocimiento y la comprensión.
- Objetivo: convertir el contenido léxico del habla humana en entradas legibles por ordenador (por ejemplo, pulsaciones de teclas, códigos binarios o secuencias de caracteres).
- Pensamientos:
- Preprocesamiento de la señal acústica: para extraer características de forma más eficaz, a menudo también es necesario capturar la señal de sonido filtrándola, enmarcándola y realizando otros trabajos de preprocesamiento, la señal que se va a analizar a partir de la extracción de la señal original;
- Extracción de características: conversión de la señal sonora del dominio temporal al dominio de la frecuencia para proporcionar vectores de características adecuados para el modelo acústico.
- Modelización acústica: cálculo de una puntuación para cada vector de características acústicas basada en las propiedades acústicas; la
- Modelización lingüística: cálculo de la probabilidad de que la señal sonora corresponda a una secuencia de frases posibles, basándose en teorías lingüísticamente relevantes.
- Diccionario y descodificación: a partir del diccionario existente, se descodifica la secuencia de frases para obtener la representación textual final posible.
- Teoría Tutorial:
- Reconocimiento de voz para el análisis de trazados
- Habilidades prácticas:
- [Análisis del diseño de voz a texto]
- Análisis del diseño de WeTextProcessing
- [Análisis del trazado - Herramienta ASR Wenet]
- Análisis del trazado Formación ASR
paso 2: recuperación de documentos de conocimiento
p1: ¿Por qué es necesaria la recuperación de documentos de conocimiento?
La adquisición de documentos de conocimiento local contiene después de la lectura de datos de múltiples fuentes (txt, pdf, html, doc, excel, png, jpg, voz, etc.), es fácil dividir un párrafo de varias líneas en varios párrafos, lo que conduce a encuentros de párrafos para dividir, por lo que es necesario reorganizar los párrafos de acuerdo con la lógica de contenido.
q2: ¿Cómo puedo recuperar documentos de conocimiento?
- Metodología I: recuperación de documentos de conocimiento basada en reglas
- Método 2: Empalme contextual basado en Bert NSP
Paso 3: Análisis del trazado - Estrategias de optimización
- Estudios teóricos:
- [Análisis del trazado - Estrategias de optimización]
paso 4: deberes
- Descripción de la tarea: Utilice la metodología anterior para analizar el diseño del [ChatGLM Evaluation Challenge - Finance Track dataset] del [SMP 2023 ChatGLM Finance Big Model Challenge].
- Eficacia de la tarea: analizar la eficacia y el rendimiento de los distintos métodos.
Módulo II: Construir la base de conocimientos
¿Por qué es necesario crear una base de conocimientos?
Construir una base de conocimientos en RAG (Retrieval-Augmented Generation) es fundamental por varias razones, entre las que se incluyen las siguientes:
- Ampliación de las capacidades del modelo: aunque los modelos lingüísticos a gran escala, como la familia GPT, tienen potentes capacidades de generación y comprensión del lenguaje, están limitados por la cobertura del conjunto de datos de entrenamiento, y puede que no sean capaces de responder con precisión a algunas preguntas basadas en hechos concretos o en información de fondo detallada. Al construir una base de conocimientos, la RAG puede complementar las limitaciones de conocimiento propias del modelo, permitiendo que éste recupere la información más actualizada y precisa para generar respuestas.
- Actualización de la información en tiempo real: la base de conocimientos puede actualizarse y ampliarse en tiempo real para garantizar que el modelo tenga acceso a los contenidos de conocimiento más recientes, lo que resulta especialmente crítico para tratar información sensible al tiempo, como noticias, avances científicos y tecnológicos, etc.
- Mayor precisión: el GAR combina los procesos de recuperación y generación para mejorar la precisión a la hora de responder a las preguntas, ya que recupera los documentos pertinentes antes de generar las respuestas. De este modo, las respuestas generadas por el modelo se basan no sólo en su conocimiento interno parametrizado, sino también en una base de conocimiento externa de fuentes fiables.
- Reducción del sobreajuste y las alucinaciones: los grandes modelos pueden a veces depender en exceso de patrones intrínsecos y sufrir alucinaciones, es decir, generar respuestas que parecen razonables pero no lo son. El GAR puede reducir la probabilidad de tales errores citando pruebas definitivas de la base de conocimientos.
- Mayor interpretabilidad: el GAR no sólo proporciona la respuesta, sino que también señala la fuente de la misma, lo que aumenta la transparencia y la credibilidad de los resultados generados por el modelo.
- Apoyo a las necesidades de personalización y privatización: las empresas o los usuarios individuales pueden crear bases de conocimiento exclusivas para satisfacer las necesidades de áreas específicas o de personalización privada, con lo que el gran modelo se adapta mejor a escenarios y negocios concretos.
En resumen, la construcción de una base de conocimientos es uno de los mecanismos fundamentales para que los modelos GAR logren una recuperación y generación de respuestas eficientes y precisas, lo que mejora enormemente el rendimiento y la fiabilidad del modelo en aplicaciones prácticas.
paso 1: agrupación de textos de conocimiento
- ¿Por qué necesito trocear el texto?
- Riesgo de omitir información: al intentar extraer los vectores de incrustación de todo el documento a la vez, aunque se capta el contexto general, también se puede omitir mucha información importante que es específica del tema, lo que puede dar lugar a que se genere información menos precisa o que falte.
- Limitación del tamaño de los trozos: el tamaño de los trozos es un factor clave que limita el uso de modelos como OpenAI. Por ejemplo, el modelo GPT-4 tiene un límite de tamaño de ventana de 32K. Aunque este límite no supone un problema en la mayoría de los casos, es importante tener en cuenta el tamaño del chunk desde el principio.
- Hay que tener en cuenta dos factores principales:
- Caso de restricción de fichas para modelos de incrustación;
- El efecto de la integridad semántica en la eficacia general de la recuperación;
- Habilidades prácticas:
- [Construcción de bases de conocimiento - agrupación de textos de conocimiento]
- [Construcción de bases de conocimiento - Estrategias de optimización del troceado de documentos].
paso 2: vectorización de documentos (embdeeing)
q1: ¿Qué es la vectorización de Docs (embdeeing)?
La incrustación es también una representación intensiva en información del significado semántico de un texto, donde cada incrustación es un vector de números en coma flotante tal que la distancia entre dos incrustaciones en el espacio vectorial se correlaciona con la similitud semántica entre las dos entradas en el formato original. Por ejemplo, si dos textos son similares, sus representaciones vectoriales también deben serlo, y este conjunto de representaciones en el espacio vectorial describe las sutiles diferencias entre los textos. En pocas palabras, el embebido ayuda a los ordenadores a entender el "significado" de la información humana. El embebido puede utilizarse para obtener la "relevancia" de las características en texto, imágenes, vídeos u otra información, lo que suele emplearse a nivel de aplicación en búsqueda, recomendación, clasificación y otras aplicaciones. Este tipo de correlación se utiliza habitualmente en la búsqueda, la recomendación, la clasificación y la agrupación.
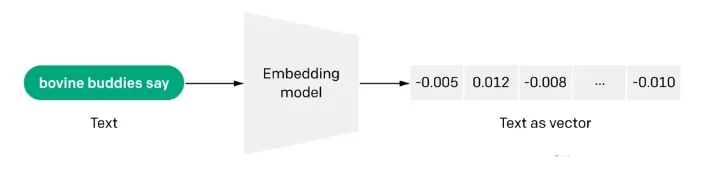
p2: ¿Cómo funciona la incrustación?
A modo de ejemplo, he aquí tres frases:
- "El gato persigue al ratón".
- "El gatito caza roedores".
- "Me gustan los bocadillos de jamón." Me gustan los bocadillos de jamón.
Si los seres humanos clasificaran estas tres frases, la frase 1 y la frase 2 tendrían casi el mismo significado, mientras que la frase 3 sería completamente diferente. Pero vemos que en las frases originales en inglés, sólo "The" es igual en la frase 1 y en la frase 2, y ninguna otra palabra es igual. ¿Cómo puede un ordenador entender la relevancia de las dos primeras frases? La incrustación comprime información discreta (palabras y símbolos) en datos distribuidos de valor continuo (vectores). Si trazáramos la frase anterior en un gráfico, podría tener este aspecto:
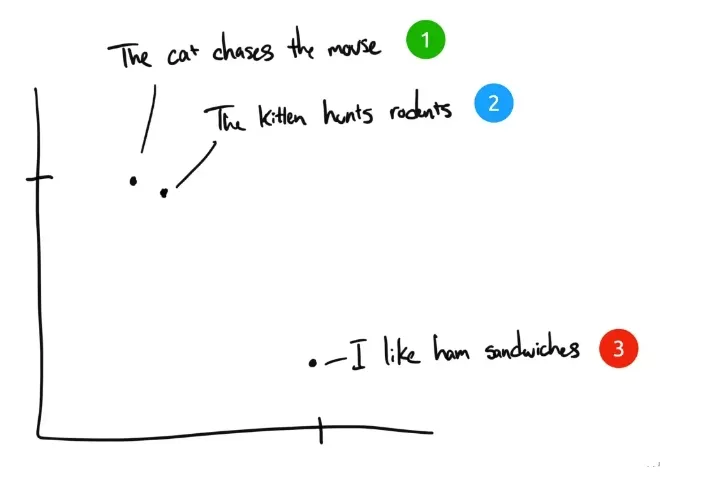
Después de comprimir el texto con Embedding en un espacio vectorial multidimensional comprensible para el ordenador, las frases 1 y 2 se representan cerca unas de otras porque tienen significados similares. La frase 3 está más alejada porque no está relacionada con ellas. Si tuviéramos una cuarta frase, "Sally comió queso suizo", probablemente estaría en algún lugar entre la frase 3 (el queso se pone en los bocadillos) y la frase 1 (a los ratones les gusta el queso suizo).
p3: ¿Ventajas del enfoque de recuperación semántica de Embedding sobre la recuperación por palabras clave?
- Comprensión semántica: los métodos de recuperación basados en la incrustación representan el texto mediante vectores de palabras, lo que permite al modelo captar las asociaciones semánticas entre palabras, a diferencia de la recuperación basada en palabras clave, que tiende a centrarse en la coincidencia literal y puede ignorar las conexiones semánticas entre palabras.
- Tolerancia de errores: dado que los métodos basados en la incrustación son capaces de comprender la relación entre las palabras, son más ventajosos a la hora de tratar casos como errores ortográficos, sinónimos y casi sinónimos. En cambio, los métodos de recuperación basados en palabras clave son relativamente poco eficaces en estos casos.
- Compatibilidad con varios idiomas: muchos métodos de incrustación son compatibles con varios idiomas, lo que ayuda a recuperar textos en varios idiomas. Por ejemplo, se puede utilizar una entrada en chino para consultar un texto en inglés, mientras que los métodos de recuperación basados en palabras clave tienen dificultades para hacerlo.
- Comprensión contextual: los métodos basados en la incrustación son más ventajosos en el caso de los significados múltiples de una palabra, ya que son capaces de asignar diferentes representaciones vectoriales a las palabras en función del contexto. Mientras que los métodos de recuperación basados en palabras clave pueden no ser capaces de distinguir bien el significado de la misma palabra en diferentes contextos.
q4: ¿Cuáles son las limitaciones de la búsqueda por incrustación?
- Restricciones en el recuento de palabras de entrada: aunque los fragmentos de texto que mejor se ajustan a la consulta se seleccionen con ayuda de la tecnología Embedding para la referencia del modelo a gran escala, sigue existiendo la restricción del recuento de vocabulario. Cuando la recuperación abarca una amplia gama de textos, para controlar la cantidad de vocabulario contextual inyectado en el modelo, se suele fijar un umbral TopK K para los resultados de la recuperación, pero esto desencadena inevitablemente el problema de la omisión de información.
- Sólo datos de texto: GPT-3.5 y muchos modelos lingüísticos a gran escala en esta fase aún no tienen capacidad de reconocimiento de imágenes. Sin embargo, en el proceso de recuperación de conocimientos, muchas informaciones clave dependen a menudo de la combinación de gráficos y texto para comprenderlas plenamente. Por ejemplo, es difícil captar con precisión el significado de los diagramas esquemáticos de los artículos académicos y los gráficos de datos de los informes financieros basándose sólo en el texto.
- (b) Improvisación de un gran modelo: cuando la bibliografía pertinente recuperada es insuficiente para que un gran modelo responda con precisión a una pregunta, el modelo puede estar sujeto a cierto grado de "improvisación", es decir, a especulaciones y adiciones basadas en información limitada, con el fin de completar la respuesta lo mejor posible.
- Estudios teóricos:
- [Construcción de bases de conocimiento - Vectorización de documentos]
- Habilidades prácticas:
- [Vectorización de documentos - Vector de palabras Tencent]
- [Docs vectorización - sbt]
- [Docs vectorización - SimCSE]
- [Docs vectorización - text2vec]
- [Docs vectorización - SGPT]
- [Docs vectorización -- BGE -- Smart Source open source el modelo de vector semántico más sólido].
- [Docs vectorización - M3E: una incrustación híbrida a gran escala].
paso 3: Docs build index
- presentar (a algn. para un trabajo, etc.)
- Habilidades prácticas:
- [Docs build index - Faiss]
- [Docs build index - milvus]
- [Docs Creación de índices - Elasticsearch]
Módulo 3: Puesta a punto del Gran Modelo
¿Por qué necesitamos afinar los grandes modelos?
Normalmente, hay varias razones para afinar un modelo grande:
- La primera razón es que, como el número de parámetros de un gran modelo es muy grande, el coste de entrenarlo es muy elevado, y cada empresa sale a entrenar un gran modelo propio desde cero, algo que resulta muy rentable;
- La segunda razón es que el enfoque de Ingeniería Prompt es una manera relativamente fácil de comenzar con modelos grandes, pero tiene desventajas obvias. Debido a que normalmente los principios de implementación de modelos grandes tienen restricciones en la longitud de la secuencia de entrada, el enfoque de Ingeniería Prompt puede hacer que el Prompt sea muy largo.
Cuanto más largo sea el Prompt, mayor será el coste de inferencia del modelo grande, porque el coste de inferencia está positivamente correlacionado con el cuadrado de la longitud del Prompt. Además, una Prompt demasiado larga será truncada porque excede el límite, lo que a su vez lleva a que la calidad de salida del modelo grande sea descontada. Para los usuarios individuales, si están resolviendo algunos problemas en su vida diaria y en el trabajo, por lo general no es un gran problema utilizar Prompt Engineering directamente. Sin embargo, para las empresas que prestan servicios al exterior, para acceder a la capacidad de los grandes modelos en sus propios servicios, el coste de razonamiento es un factor que hay que tener en cuenta, y el ajuste fino es relativamente una solución mejor.
- La tercera razón es que el efecto de Prompt Engineering no está a la altura de las necesidades, y la empresa dispone de mejores datos propios, que pueden utilizarse para mejorar la capacidad del gran modelo en el dominio específico. Aquí es cuando el ajuste fino es muy aplicable.
- La cuarta razón es utilizar la potencia de los grandes modelos en servicios personalizados, cuando entrenar un modelo ligero y afinado para los datos de cada usuario es una buena solución.
- La quinta razón es la seguridad de los datos. Si los datos no se van a pasar a un servicio de big model de terceros, es muy necesario construir un big model propio. Por lo general, estos big models de código abierto deben ajustarse con sus propios datos para satisfacer las necesidades de la empresa.
¿Cómo se afina un modelo grande?
q1: La cuestión de la puesta a punto de las vías técnicas para los grandes modelos
La puesta a punto de grandes modelos desde la perspectiva de la escala de parámetros se divide en dos vías técnicas:
- Ruta técnica 1: Para toda la cantidad de parámetros, toda la cantidad de entrenamiento, esta ruta se denomina sintonización fina completa FFT (Full Fine Tuning).
- Ruta técnica II: Sólo se entrenan algunos de los parámetros, esta ruta se denomina PEFT (Parameter-Efficient Fine Tuning).
p2: ¿Cuáles son los problemas de la técnica FFT de ajuste fino completo para modelos de gran tamaño?
La FFT también conlleva algunos problemas, los más impactantes, los dos principales son los siguientes:
- Problema 1: El coste del entrenamiento será mayor porque el número de parámetros para el ajuste fino es el mismo que para el pre-entrenamiento;
- Problema 2: el olvido catastrófico (Catastrophic Forgetting), en el que el ajuste con datos de entrenamiento específicos puede mejorar el rendimiento en ese dominio, pero también puede empeorar la capacidad en otros dominios en los que se estaba obteniendo un buen rendimiento.
p3: ¿Qué problemas resuelve PEFT (Parameter-Efficient Fine Tuning) en modelos de gran tamaño?
El principal problema que pretende resolver PEFT son los dos anteriores de la FFT, y PEFT es también el programa de ajuste más generalizado en la actualidad. Desde la perspectiva de la fuente de datos de entrenamiento, así como del método de entrenamiento, existen varias vías técnicas para el ajuste fino de grandes modelos, a saber:
- Ruta técnica 1: Ajuste fino supervisado SFT (Supervised Fine Tuning), este esquema se centra en el ajuste fino de grandes modelos con datos etiquetados manualmente utilizando el enfoque tradicional de aprendizaje supervisado en el aprendizaje automático;
- Ruta técnica II: Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF), la principal característica de este esquema es introducir la retroalimentación humana, mediante el aprendizaje por refuerzo, en el ajuste fino del gran modelo, de modo que los resultados generados por el gran modelo puedan ajustarse más a algunas de las expectativas humanas;
- Ruta Tecnológica III: Aprendizaje por Refuerzo con Retroalimentación de IA (RLAIF), el principio es más o menos similar a RLHF, pero la fuente de retroalimentación es la IA. aquí se está tratando de resolver el problema de eficiencia del sistema de retroalimentación, porque la recolección de retroalimentación humana, relativamente hablando, el costo será más alto y menos eficiente.
Las distintas perspectivas de clasificación son simplemente distintos énfasis, y el ajuste fino del mismo gran modelo no se limita a un escenario concreto, sino que pueden ser múltiples escenarios juntos. El objetivo último del ajuste fino es poder mejorar al máximo las capacidades del gran modelo en un dominio específico, manteniendo los costes bajo control.
¿Qué aprenden los grandes modelos LLM cuando realizan operaciones SFT?
- Pre-entrenamiento -> pre-entrenamiento en grandes cantidades de datos no supervisados para obtener un modelo base -> utilizar el modelo pre-entrenado como punto de partida para SFT y RLHF.
- SFT --> Realizar el entrenamiento SFT en conjuntos de datos supervisados y optimizar aún más el modelo utilizando señales supervisadas como la información contextual --> Utilizar el modelo entrenado SFT como punto de partida para RLHF.
- RLHF --> Aprendizaje por refuerzo utilizando la retroalimentación humana para optimizar el modelo y ajustarlo mejor a las intenciones y preferencias humanas --> Evaluación y validación del modelo entrenado con RLHF y realización de los ajustes necesarios.
paso 1: construcción de datos de entrenamiento para el ajuste fino de grandes modelos
- Introducción: ¿Cómo crear datos de formación?
- Habilidades prácticas:
- [Modelos a gran escala (LLM) Metodología LLM para generar datos SFT].
Paso 2: Ajuste de las instrucciones del modelo grande
- Introducción: ¿Cómo crear datos de formación?
- Habilidades prácticas:
- [Continuación del preentrenamiento de grandes modelos (LLM)].
- [Ajuste fino de las instrucciones LLM]
- [LLMs Recompensa Modelo Formación]
- Aprendizaje por refuerzo para modelos de gran tamaño (LLM) - PPO Training Chapter
- Aprendizaje por refuerzo para modelos de gran tamaño (LLM) - Capítulo de formación del RPD
Módulo 4: Recuperación de documentos
¿Por qué necesita la recuperación de documentos?
Recuperación de documentos Al ser el núcleo del trabajo del GAR, su eficacia es crucial para el trabajo posterior. Aunque es posible mejorar la calidad de la respuesta del modelo recuperando fragmentos de documentos relacionados con las preguntas del usuario del repositorio de documentos mediante la recuperación vectorial e introduciéndolos en el LLM al mismo tiempo. Una forma habitual de recuperar documentos es utilizar directamente la pregunta del usuario. Sin embargo, muy a menudo, la pregunta del usuario es muy coloquial y está vagamente descrita, lo que afecta a la calidad de la recuperación vectorial y, por tanto, a la respuesta del modelo. Este capítulo presenta principalmente algunos problemas y sus correspondientes soluciones en el proceso de recuperación de documentos.
paso 1: recuperación de documentos extracción de muestras negativas
- INTRODUCCIÓN: En todo tipo de tareas de recuperación, para entrenar un modelo de recuperación de buena calidad, a menudo es necesario muestrear ejemplos negativos de alta calidad a partir de un gran conjunto de muestras candidatas, junto con ejemplos positivos.
- Habilidades prácticas:
- [Document Retrieval - Negative Sample Sample Mining Chapter]
paso 2: estrategia de optimización de la recuperación de documentos
- Introducción: estrategias de optimización de la recuperación de documentos
- Habilidades prácticas:
- Recuperación de documentos - Estrategias de optimización para la recuperación de documentos
Módulo V: Reranker
¿Por qué necesitas Reranker?
La aplicación básica del GAR consta de cuatro componentes técnicos clave:
- Modelos de incrustación: se utilizan para transformar documentos externos y consultas de los usuarios en vectores de incrustación.
- base de datos vectorialVectores de incrustación: se utilizan para almacenar vectores de incrustación y realizar búsquedas de similitud de vectores (recuperar las piezas de información Top-K más relevantes).
- Ingeniería de preguntas: entradas para combinar las preguntas de los usuarios y los contextos recuperados en modelos más amplios.
- Large Language Modelling (LLM): para generar respuestas
La arquitectura básica del GAR descrita anteriormente resuelve eficazmente el problema de los LLM que crean "ilusiones" y generan contenidos poco fiables. Sin embargo, algunos usuarios empresariales requieren arquitecturas más sofisticadas para la relevancia contextual y la precisión de las preguntas y respuestas. Un enfoque probado y popular consiste en integrar Reranker en las aplicaciones GAR.
¿Qué es Reranker?
El Reranker es una parte importante del ecosistema de la Recuperación de Información (IR) para evaluar los resultados de búsqueda y reordenarlos para mejorar la relevancia de la consulta. En las aplicaciones RAG, el Reranker se utiliza principalmente después de obtener los resultados de una consulta vectorial (RNA), lo que permite determinar de forma más eficaz la relevancia semántica entre documentos y consultas, reordenar de forma más precisa los resultados y, en última instancia, mejorar la calidad de la búsqueda.
paso 1: Reranker de piezas
- Estudios teóricos:
- Búsqueda de documentación RAG - Sección Reranker
- Habilidades prácticas:
- [Reranker - bge-reranker capítulo]
Módulo 6: Superficies de evaluación RAG
¿Por qué tengo que revisar el GAR?
En la exploración y optimización de los GAR (Generadores de Aumento de Recuperación), la cuestión de cómo evaluar eficazmente su rendimiento se ha vuelto crítica.
paso 1: revisión RAG
- Estudios teóricos:
- [RAG Review]
Módulo 7: Proyecto de código abierto RAG Aprendizaje recomendado
¿Por qué necesito el Aprendizaje Recomendado de Proyectos de Código Abierto RAG?
Después de haberles guiado a través de los diversos procesos de RAG, he aquí algunos proyectos de código abierto RAG recomendados para ayudar a los grandes a digerir y aprender.
Recomendaciones del proyecto de código abierto RAG - Artículo sobre RAGFlow
- Introducción: RAGFlow es un motor de código abierto de Generación Mejorada de Recuperación (RAG) basado en un profundo conocimiento de los documentos. RAGFlow proporciona un conjunto racionalizado de flujos de trabajo RAG para empresas e individuos de todos los tamaños, combinado con un Gran Modelo de Lenguaje (LLM) para proporcionar preguntas fiables, respuestas y citas justificadas para una amplia gama de formatos de datos complejos. RAGFlow proporciona un flujo de trabajo RAG racionalizado para empresas y particulares de todos los tamaños, combinado con un Large Language Model (LLM) para proporcionar preguntas, respuestas y citas justificadas fiables para una amplia gama de formatos de datos complejos.
- Proyecto de aprendizaje:
- RAG Project Recommendations - RagFlow Part I - RagFlow docker deployment].
- Recomendación del proyecto RAG - RagFlow Parte (II) - Construcción de la base de conocimientos RagFlow].
- Recomendación del proyecto RAG - RagFlow Parte (3) - Selección del proveedor del modelo RagFlow
- Recomendación del Proyecto RAG - RagFlow Parte (4) - Diálogo RagFlow].
- RAG Project Recommendation - RagFlow Part (V) - RAGFlow Api Access (to) ollama (por ejemplo)]
- Recomendación del proyecto RAG - RagFlow Parte (VI) - Aprendizaje del código fuente de RAGFlow
Recomendaciones del proyecto de código abierto RAG - QAnything
- Introducción: QAnything (Question and Answer based on Anything) es un sistema local de preguntas y respuestas de base de conocimientos diseñado para soportar una amplia gama de formatos de archivo y bases de datos, permitiendo su instalación y uso offline. Usando QAnything, usted puede simplemente borrar archivos almacenados localmente en cualquier formato y obtener respuestas precisas, rápidas y confiables.QAnything actualmente soporta formatos de archivos de base de conocimiento incluyendo: PDF(pdf) , Word(docx) , PPT(pptx) , XLS(xlsx) , Markdown(md) , Email (eml) , TXT (txt), Imagen (jpg, jpeg, png), CSV (csv), enlaces web (html), etc.
- Proyecto de aprendizaje:
- [Recomendaciones del proyecto de código abierto RAG QCualquier cosa [Escrito]
Recomendaciones del proyecto de código abierto RAG -- Artículo sobre ElasticSearch-Langchain
- INTRODUCCIÓN: Inspirado en el proyecto langchain-ChatGLM, dado que Elasticsearch puede realizar consultas mixtas tanto de texto como vectoriales y su uso está más extendido en escenarios empresariales, este proyecto sustituye Faiss por Elasticsearch como repositorio de conocimiento, y utiliza Langchain+Chatglm2 para implementar un cuestionario inteligente basado en las Cuestionario inteligente basado en la propia base de conocimiento utilizando Langchain+Chatglm2.
- Proyecto de aprendizaje:
- [LLMs Getting Started] Efficient 🤖ElasticSearch-Langchain-Chatglm2 Based on Local Knowledge Base]
Recomendaciones del proyecto de código abierto RAG - Artículo de Langchain-Chatchat
- Introducción: Langchain-Chatchat (antes Langchain-ChatGLM) QA app with local knowledge based LLM (like ChatGLM) | Langchain-Chatchat (antes langchain-ChatGLM), local LLM basado en conocimiento local (como ChatGLM) con langchain
- Proyecto de aprendizaje:
- [LLMs Getting Started] Efficient 🤖Langchain-Chatchat Based on Local Knowledge Base]
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...