Xiaomi-MiMo-Audio: el primer modelo nativo de voz de extremo a extremo de código abierto de Xiaomi
Últimos recursos sobre IAActualizado hace 6 meses Círculo de intercambio de inteligencia artificial 39K 00

¿Qué es Xiaomi-MiMo-Audio?
Xiaomi-MiMo-Audio es un macromodelo de voz de Xiaomi de código abierto con 7.000 millones de parámetros de extremo a extremo y potentes funciones como el diálogo multilingüe, la continuación del habla, la generalización con menos muestras y la comprensión de audio, capaz de alcanzar el nivel SOTA en pruebas comparativas de inteligencia del habla y comprensión de audio, superando a modelos como Google Gemini-2.5-Flash. Las innovadoras técnicas de preentrenamiento de compresión sin pérdidas y preentrenamiento generativo del habla permiten al modelo obtener buenos resultados en tareas como la conversión del habla y la migración de estilos. Xiaomi ha puesto a disposición del público el modelo de preentrenamiento MiMo-Audio-7B-Base, el modelo de ajuste de comandos MiMo-Audio-7B-Instruct, el modelo MiMo-Audio Tokenizer, el informe técnico y el marco de evaluación, para contribuir a la investigación de grandes modelos de voz y al desarrollo de AGI de voz.
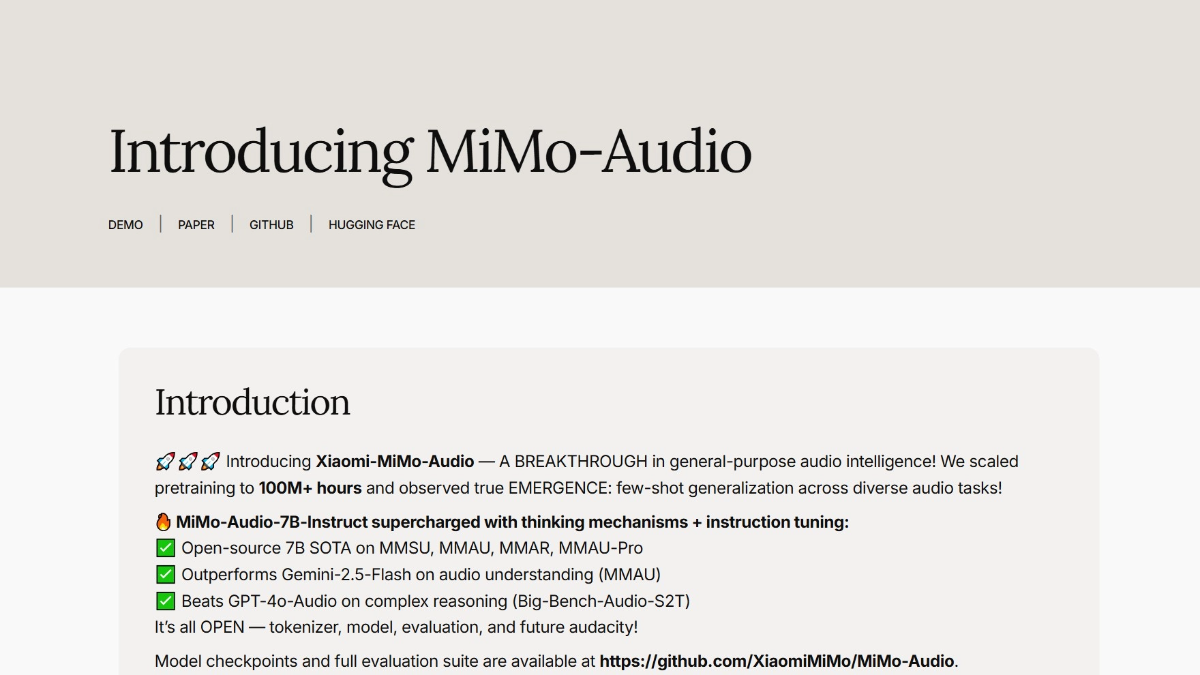
Características de Xiaomi-MiMo-Audio
- diálogo multilingüeFacilita la comunicación fluida con los usuarios y abarca una amplia gama de temas, como filosofía, ideales de vida, etc., y permite aprender temas candentes de Internet e inglés hablado.
- secuela fonológica: Genera contenidos discursivos de gran realismo para comedias, recitados, retransmisiones en directo y debates, conservando características acústicas clave como la identidad del orador, el ritmo y los sonidos ambientales.
- Muestra menos generalizaciónLa ausencia de determinadas tareas en los datos de entrenamiento (por ejemplo, conversión del habla, migración de estilo, edición del habla) puede afrontarse fácilmente, lo que demuestra una gran capacidad de generalización.
- Comprensión de audio: Incluye subtítulos de audio, razonamiento de audio y comprensión de audio de larga duración para procesar y analizar largas secuencias de audio, proporcionando descripciones detalladas y análisis en profundidad.
Principales ventajas de MiMo-Audio
- Datos de preentrenamiento a gran escalaEl preentrenamiento basado en más de 100 millones de horas de datos de voz confiere al modelo una gran capacidad de generalización y le permite destacar en tareas complejas que no aparecen en los datos de entrenamiento.
- Tecnología original de preentrenamiento de compresión de voz sin pérdidasUn gran avance en la generalización entre tareas del habla, que permite a los modelos mostrar un comportamiento "emergente" en el aprendizaje con pocas muestras para mejorar la eficacia.
- Primera capacidad de continuación de voz de código abiertoEl primer modelo de código abierto con funciones de continuación del habla, puede generar contenidos de habla realistas, como la comedia stand-up y el recitado, lo que ofrece nuevas posibilidades de creación.
- Potente comprensión de audio: destaca en subtitulado de audio, inferencia y comprensión de audio de larga duración, procesando largas secuencias de audio y proporcionando análisis precisos para ayudar a automatizar la anotación y el análisis de contenidos de audio.
- Introducción del modelo de pensamientoPor primera vez, se introduce el modo de pensamiento para la comprensión del habla y el proceso de generación, y se admite el pensamiento híbrido, lo que hace que el modelo sea más flexible y natural en la interacción del habla y se adapte a diferentes escenarios y necesidades.
¿Cuál es el sitio web oficial de Xiaomi-MiMo-Audio?
- Página web del proyecto:: https://xiaomimimo.github.io/MiMo-Audio-Demo/
- Repositorio GitHub:: https://github.com/XiaomiMiMo/MiMo-Audio
- Biblioteca de modelos HuggingFace:: https://huggingface.co/collections/XiaomiMiMo/mimo-audio-68cc7202692c27dae881cce0
- Documentos técnicos:: https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf
¿A quién va dirigido Xiaomi-MiMo-Audio?
- Desarrolladores de tecnologías del habla: Proporcionar a los desarrolladores potentes modelos de voz para su uso en el desarrollo de asistentes de voz, aplicaciones de interacción por voz, etc., acelerando el desarrollo y la innovación de productos de tecnología de voz.
- Creadores de contenidos de voz: Ayudar a los creadores a generar eficazmente contenidos de voz para audiolibros, podcasts, programas de entrevistas, etc., y mejorar la eficacia y la calidad de la creación.
- estudiante de idiomasEl aprendizaje de idiomas: como herramienta de aprendizaje de idiomas, facilita el aprendizaje de idiomas proporcionando a los alumnos un entorno simulado para la práctica oral y la comunicación lingüística.
- desarrollador de juegosSe utiliza para la generación de diálogos de voz en el juego para dar una interpretación de voz vívida a los personajes del juego y mejorar la inmersión en el juego.
- educadorConversión de contenidos didácticos en conferencias de audio, producción de cursos de audio y conferencias en línea, enriquecimiento de la forma de enseñanza y mejora de la eficacia docente.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...