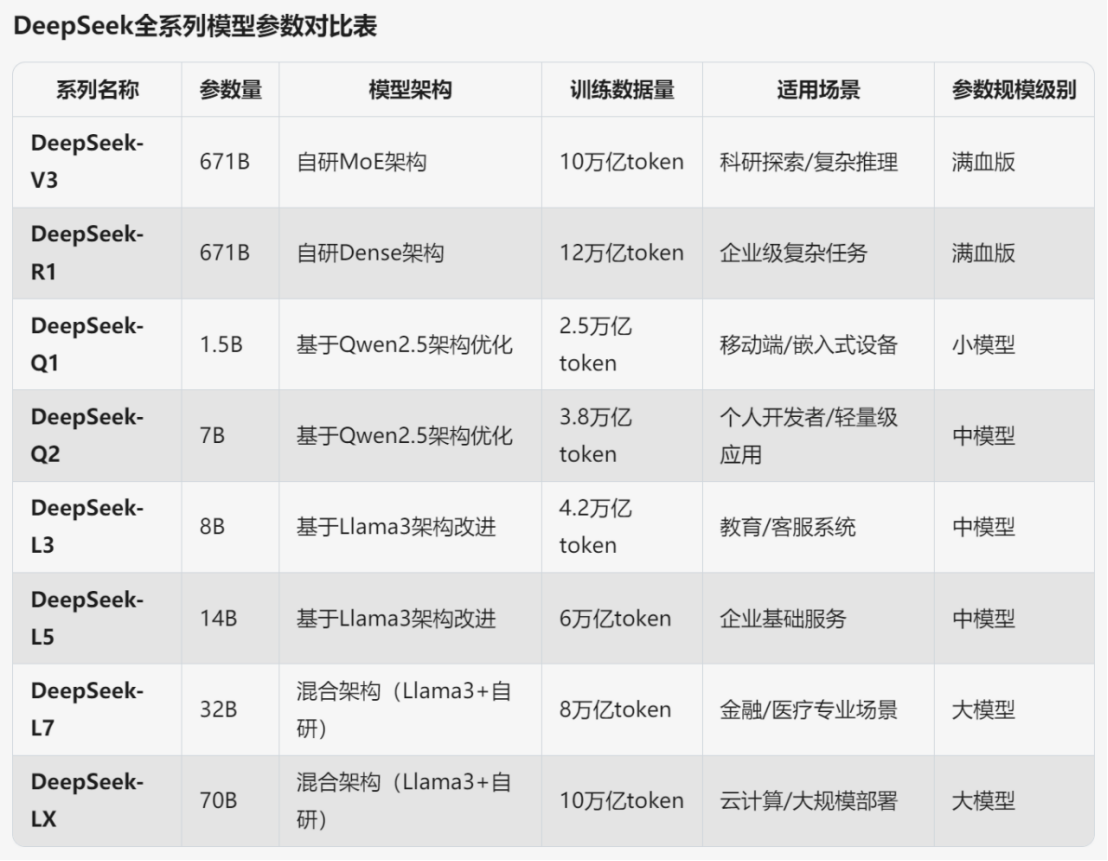
¿Qué es el aprendizaje federado en un artículo?

Definición de aprendizaje federal
El aprendizaje federado es un enfoque innovador de aprendizaje automático, propuesto por primera vez por un equipo de investigadores de Google en 2016, para hacer frente a los retos de la privacidad de los datos y la informática distribuida. A diferencia del aprendizaje automático tradicional, el aprendizaje federado no requiere que los datos brutos se centralicen en un servidor central para su procesamiento, lo que permite que los datos permanezcan en dispositivos locales como teléfonos inteligentes, sensores IoT o nodos informáticos periféricos. El proceso principal implica la colaboración de varios dispositivos cliente para entrenar un modelo compartido: un servidor central inicializa un modelo global y lo distribuye a los dispositivos participantes; cada dispositivo entrena el modelo utilizando datos locales para generar actualizaciones del modelo (por ejemplo, cambios de gradiente o de peso); estas actualizaciones se cifran y se envían de vuelta al servidor; y el servidor agrega todas las actualizaciones para optimizar el modelo global sin tocar ninguno de los datos en bruto. Este enfoque reduce significativamente el riesgo de filtración de datos y cumple con las normativas modernas de protección de datos, como el GDPR. El nombre de Federated Learning se inspira en el concepto de federalismo en ciencias políticas, que hace hincapié en la colaboración entre entidades manteniendo la autonomía. Entre las áreas de aplicación se incluyen la sanidad, los servicios financieros y los dispositivos inteligentes, donde la sensibilidad y la privacidad de los datos son fundamentales. El aprendizaje federado no sólo es compatible con tareas de aprendizaje supervisado, sino que también se aplica a escenarios de aprendizaje no supervisado y de refuerzo, impulsando la IA en la dirección de la protección de la privacidad.

Cómo funciona el aprendizaje federal
El aprendizaje federado se basa en la combinación de la informática distribuida y las técnicas de preservación de la privacidad para lograr la optimización global de los modelos a través de múltiples rondas de entrenamiento colaborativo.
- Inicialización de la coordinación del servidor central:El servidor central genera primero un modelo global inicial (por ejemplo, una estructura de red neuronal), que se distribuye a los dispositivos participantes como punto de partida para el entrenamiento. El servidor se encarga de coordinar el proceso de entrenamiento, pero no tiene acceso directo a ningún dato local.
- Formación local del dispositivo cliente:Después de que los dispositivos elegibles (por ejemplo, teléfonos móviles, terminales IoT) descarguen el modelo global, los datos no públicos almacenados localmente se utilizan para el entrenamiento del modelo. Todos los cálculos se realizan en el dispositivo, y los datos en bruto se mantienen localmente en todo momento, evitando fundamentalmente la salida de datos.
- Carga cifrada de actualizaciones:El dispositivo sólo carga en el servidor la información de actualización del modelo cifrada y comprimida (por ejemplo, la cantidad de gradiente o de ajuste de parámetros). Este diseño reduce significativamente los gastos generales de comunicación al tiempo que evita la fuga de información en puntos intermedios mediante el cifrado.
- Mecanismo de agregación seguro:El servidor consolida las actualizaciones procedentes de varios dispositivos mediante algoritmos de agregación seguros, como el promediado federal. Este proceso admite la fusión de parámetros en un estado cifrado, lo que garantiza que el servidor no pueda rastrear el contenido de las actualizaciones de dispositivos individuales.
- Múltiples rondas de optimización iterativa:Los modelos se optimizan en un proceso iterativo continuo mediante el ciclo "distribuir-local-entrenar-cargar-agrupar". La condición de finalización del entrenamiento suele establecerse en función del rendimiento del modelo o de la convergencia, y finalmente se genera un modelo global con capacidad de generalización.
- Mecanismos de asignación diferenciados:El sistema admite el ajuste dinámico de parámetros como el número de dispositivos participantes y el número de rondas locales de entrenamiento para adaptarse a diferentes entornos de red y potencia de cálculo y garantizar así la estabilidad y eficacia del proceso de entrenamiento.
Ventajas del aprendizaje federal
El aprendizaje federado ofrece varias ventajas sobre los métodos tradicionales, especialmente en términos de privacidad de datos y eficiencia.
- Mejora de la privacidad:Los datos sin procesar se conservan siempre en el dispositivo local, lo que evita el riesgo de fuga asociado al almacenamiento centralizado y cumple la estricta normativa sobre datos.
- Reducción de los costes de comunicación:Transmitir sólo actualizaciones del modelo y no datos sin procesar reduce los requisitos de ancho de banda de la red, especialmente para dispositivos móviles o entornos con limitaciones de ancho de banda.
- Uso de datos descentralizados:La capacidad de integrar datos de múltiples fuentes mejora la generalización de los modelos sin necesidad de compartir o centralizar los datos.
- Mejorar la escalabilidad:Admite el entrenamiento en paralelo de un gran número de dispositivos y se adapta a escenarios de IoT y edge computing para permitir despliegues de aprendizaje automático a gran escala.
- Aumentar la confianza de los usuarios:Al ser transparentes y respetuosos con la privacidad, los usuarios están más dispuestos a participar en servicios basados en datos que promueven la popularización de las aplicaciones de IA.
Escenarios de aplicación del aprendizaje federado
El aprendizaje federado está encontrando aplicaciones prácticas en múltiples industrias para abordar los silos de datos y los problemas de privacidad.
- Sanidad:Los hospitales o institutos de investigación colaboran para entrenar modelos de diagnóstico de enfermedades, conservando los datos de los pacientes en la institución original para evitar compartir información médica sensible.
- Servicios financieros:Los bancos utilizan el aprendizaje federado para la detección de fraudes, integrando datos de distintas sucursales sin exponer los detalles de las transacciones de los clientes y mejorando la precisión de los modelos.
- Método de entrada del smartphone:El Teclado de Google utiliza el aprendizaje federado para mejorar los modelos predictivos, y los hábitos de entrada del usuario se entrenan localmente en el dispositivo para proteger la privacidad personal.
- Internet de los objetos y el hogar inteligente:Dispositivos como altavoces inteligentes o sensores colaboran para optimizar la gestión de la energía o el reconocimiento de voz, y los datos se procesan en el borde, reduciendo la dependencia de la nube.
- Coches autónomos:Los vehículos comparten las actualizaciones de los modelos para mejorar los sistemas de navegación, pero no cargan los datos de conducción para garantizar el cumplimiento de las normas de seguridad y privacidad.
Retos federales de aprendizaje
A pesar de sus ventajas, el aprendizaje federal también se enfrenta a una serie de retos técnicos y administrativos.
- Heterogeneidad de los datos:Las distribuciones de datos procedentes de distintos dispositivos pueden estar distribuidas de forma no idéntica (Non-IID), lo que provoca sesgos en el entrenamiento de los modelos o dificultades de convergencia, que requieren técnicas avanzadas de agregación.
- Cuellos de botella en las comunicaciones:La transmisión frecuente de actualizaciones del modelo puede consumir recursos de la red, especialmente en zonas rurales o con poco ancho de banda, lo que afecta a la eficacia del entrenamiento.
- Limitaciones de recursos de equipamiento:Los dispositivos cliente, como los teléfonos móviles, pueden tener una potencia de cálculo, una duración de la batería o un espacio de almacenamiento limitados, lo que restringe la profundidad y el compromiso de la formación.
- Amenazas a la seguridad:Los datos no están centralizados, las actualizaciones de los modelos pueden seguir filtrando información y enfrentarse a ataques de inferencia o a participantes malintencionados, por lo que es necesario reforzar los mecanismos de cifrado y autenticación.
- Complejidad de la coordinación:La gestión de un gran número de dispositivos asíncronos requiere una arquitectura de servidor robusta y mecanismos de resolución de problemas, lo que aumenta los costes de diseño y mantenimiento del sistema.
Mecanismos de seguridad para el aprendizaje federado
Para garantizar la seguridad del proceso de aprendizaje federal, se integran múltiples tecnologías en el marco.
- Privacidad diferencial:Al añadir ruido a las actualizaciones de los modelos se evita inferir información de datos individuales a partir de las actualizaciones, lo que equilibra la privacidad y la utilidad de los modelos.
- Computación multipartita segura (SMC):Permite que varios dispositivos colaboren en el cálculo de agregaciones de modelos sin exponer sus respectivas actualizaciones, lo que se consigue mediante protocolos criptográficos.
- Cifrado homomórfico:El servidor realiza la operación de agregación directamente sobre las actualizaciones cifradas y descifra sólo el resultado final para evitar la fuga de datos intermedios.
- Autenticación de dispositivos y control de acceso:Sólo los dispositivos autorizados pueden participar en la formación, lo que impide que se unan nodos maliciosos y refuerza la autenticación mediante certificados digitales o tecnología blockchain.
- Auditoría y registro:Supervisar el proceso de formación para detectar comportamientos anómalos, como ataques de envenenamiento de modelos, y garantizar la integridad y transparencia del sistema.
Evolución del aprendizaje federal
El concepto y la práctica del aprendizaje federal han evolucionado desde su infancia hasta su madurez.
- Germinación y exploración temprana:La base teórica del aprendizaje federado procede de la investigación en la intersección del aprendizaje automático distribuido y la criptografía. Con la popularización de los dispositivos de computación periférica, los investigadores han empezado a explorar la posibilidad de entrenar modelos directamente en los dispositivos finales, sentando las bases de las arquitecturas de aprendizaje federado.
- Concepto de tecnología formalizado (2016):Por primera vez, el equipo de investigación de Google propuso sistemáticamente el término "aprendizaje federado" y verificó su viabilidad a través de casos reales como la predicción de métodos de introducción de datos en teléfonos móviles. Este trabajo pionero ha atraído la atención generalizada de la industria y el mundo académico, y ha dado lugar a una oleada de investigaciones sistemáticas.
- Optimización de algoritmos y avances (2017-2019):El enfoque de la investigación se ha desplazado hacia la resolución de retos prácticos de despliegue, incluidos los retos que plantean los datos no independientes y codistribuidos, la optimización de la eficiencia de las comunicaciones, etc. Los algoritmos centrales propuestos, como el algoritmo de promediado federado, mejoran significativamente la eficiencia del entrenamiento, lo que permite aplicar el aprendizaje federado en diversos escenarios.
- Ecología de código abierto y desarrollo de marcos (2020-presente):La aparición de marcos de código abierto como TensorFlow Federated, PySyft y otros ha reducido drásticamente el umbral de utilización de esta tecnología. Diversos sectores han empezado a intentar implantar sistemas de aprendizaje federado en la sanidad, las finanzas y otros campos, llevando la tecnología del laboratorio a las aplicaciones prácticas.
- Normalización y construcción ecológica (en esta fase):Organizaciones de normalización como el IEEE han empezado a desarrollar marcos tecnológicos de aprendizaje federal y normas de evaluación, centrándose en especificaciones de seguridad, métricas de rendimiento y compatibilidad de sistemas. Estos esfuerzos están sentando unas bases sólidas para la aplicación industrial a gran escala de la tecnología.
Aprendizaje federal frente a centralizado
El aprendizaje federal y el centralizado tradicional difieren en varias dimensiones.
- Ubicación de los datos:Los datos de aprendizaje federados están descentralizados en el cliente y los centralizados en el servidor; los primeros tienen una mayor privacidad pero una coordinación más compleja.
- Modo de comunicación:El aprendizaje federado requiere la transmisión frecuente de actualizaciones del modelo en sentido ascendente y descendente, mientras que el aprendizaje centralizado carga los datos de una sola vez, y los modos de comunicación afectan al coste y la latencia.
- Escalabilidad:El aprendizaje federado es más adecuado para entornos distribuidos a gran escala; el centralizado está limitado por la capacidad del servidor y es menos escalable.
- Conformidad:El aprendizaje federal cumple de forma natural la normativa sobre localización de datos, mientras que el aprendizaje centralizado requiere medidas adicionales para cumplir los requisitos de privacidad y aumenta la carga que supone el cumplimiento de la normativa.
Tendencias futuras del aprendizaje federal
La dirección de Federated Learning se centra en la innovación tecnológica y en aplicaciones más amplias.
- Progreso algorítmico:Investigación sobre métodos de agregación más eficaces y algoritmos adaptados a los datos no procedentes de IID para mejorar la velocidad de convergencia y la precisión de los modelos.
- Integración de hardware:Combinado con chips de computación edge y redes 5G, permite un entrenamiento de baja latencia y admite aplicaciones en tiempo real como la realidad aumentada.
- Integración transversal:Combínalo con blockchain para mejorar las capacidades de auditoría o colabora con bases de datos federales para abordar los silos de datos.
- Normalización y reglamentación:Las organizaciones del sector establecen normas uniformes y los gobiernos introducen políticas de orientación para facilitar el despliegue del cumplimiento de las normas federales de aprendizaje.
- Optimización de la experiencia del usuario:Las herramientas de desarrollo y las interfaces simplificadas facilitan la implantación a los no expertos y aceleran la penetración en las PYME.
Ejemplos prácticos de aprendizaje federal
En el mundo real, el aprendizaje federado se ha aplicado con éxito en varios proyectos.
- Proyecto Teclado Google:Millones de dispositivos de usuarios colaboran para entrenar modelos de predicción de texto y procesar miles de millones de entradas al día sin cargar datos de entrada personales.
- Análisis de imágenes médicas:Varios hospitales utilizan el aprendizaje federado para entrenar modelos de detección del cáncer, conservando los datos en cada hospital para mejorar la precisión del diagnóstico y proteger la privacidad del paciente.
- Sistema de control de riesgos financieros:Un consorcio bancario crea modelos antifraude mediante el aprendizaje federado, compartiendo modelos de riesgo sin intercambiar datos de clientes para mejorar la seguridad general.
- Proyecto Ciudad Inteligente:Los sensores de tráfico colaboran para optimizar el control de las señales, las actualizaciones de los modelos se comparten para reducir la congestión y los datos se procesan localmente.
- Internet industrial de los objetos:Los equipos de fabricación predicen las necesidades de mantenimiento y comparten información sobre los modelos entre las plantas para evitar tiempos de inactividad, al tiempo que protegen los datos operativos patentados.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...