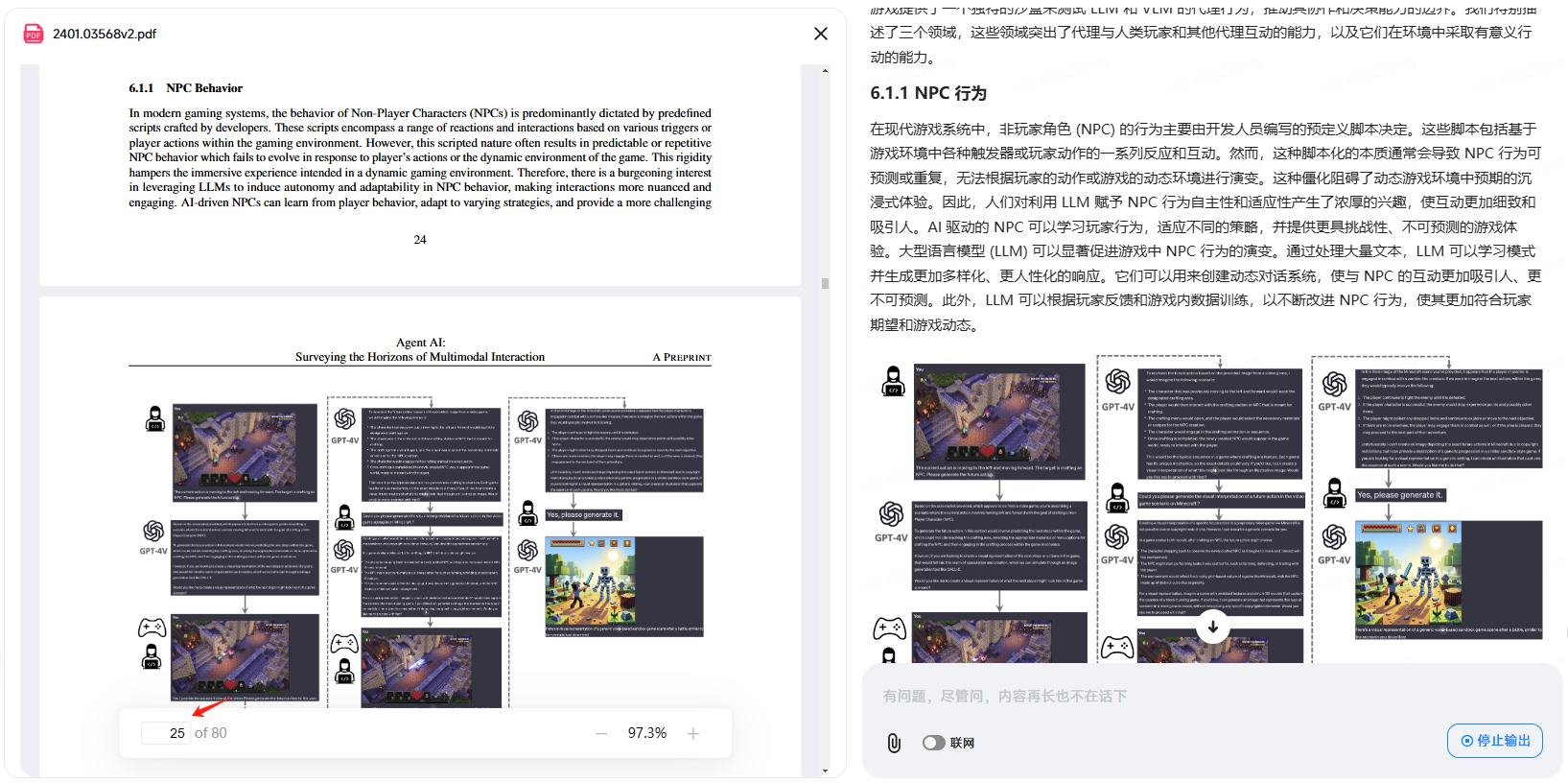
Qué es el aumento de datos (Data Augmentation), un artículo para ver y entender

Definición de mejora de datos
El aumento de datos (Data Augmentation) es un método técnico para ampliar el conjunto de datos de entrenamiento mediante la creación artificial de nuevos datos, cuyo núcleo, bajo la premisa de mantener las características esenciales de los datos, lleva a cabo una serie de transformaciones y modificaciones en los datos originales para generar nuevas muestras con diversidad, lo que es aplicable a los escenarios de escasez de datos o alto coste de adquisición, y puede mejorar eficazmente la capacidad de generalización y la robustez del modelo. En el campo del tratamiento de imágenes, las operaciones más comunes son la rotación, el giro, la escala, el recorte, el ajuste del color, etc.; en los datos de texto, el aumento de datos puede lograrse mediante técnicas como la sustitución de sinónimos, la conversión de frases, la traducción inversa, etc. El aumento de datos no solo aumenta el número de muestras de entrenamiento, sino que, lo que es más importante, mejora la diversidad de los datos, lo que permite al modelo aprender más características esenciales en lugar de depender excesivamente de patrones específicos en el conjunto de entrenamiento. Esta técnica se ha convertido en un estándar en el entrenamiento de modelos de aprendizaje profundo y desempeña un papel clave especialmente en áreas de investigación basadas en datos, como la visión por ordenador y el procesamiento del lenguaje natural. El uso adecuado de las técnicas de aumento de datos puede mejorar significativamente el rendimiento de los modelos en aplicaciones del mundo real sin aumentar el coste de la recopilación de datos.

Ideas básicas para mejorar los datos
- Creación de diversidad de datosEl modelo de entrenamiento: introduce variaciones y perturbaciones razonables para aumentar la riqueza de los datos de entrenamiento. Esta diversidad ayuda al modelo a aprender una representación de características más robusta.
- Mantenimiento de las características esencialesEl objetivo: garantizar que la información semántica y las características clave de los datos no se destruyan al aplicar las distintas transformaciones. Los datos transformados deben seguir manteniendo los atributos de categoría originales.
- Mecanismo de prevención del sobreajusteProporcionan muestras de entrenamiento más diversas y reducen la dependencia excesiva del modelo de características específicas del conjunto de entrenamiento. Este mecanismo mejora eficazmente el rendimiento de generalización del modelo.
- Simulación de escenarios realistasPermite simular, mediante el aumento de datos, los distintos cambios y perturbaciones que pueden producirse en el mundo real. Permite que los modelos se adapten a entornos de aplicación complejos y cambiantes del mundo real.
- Extensión de la distribución de datosAmpliación razonable de la gama de variabilidad de los datos basada en la distribución original de los datos. Esta ampliación permite al modelo manejar una gama más amplia de situaciones de entrada.
Enfoque técnico de la mejora de datos
- técnica de transformación geométricaTransformación espacial: incluye operaciones de transformación espacial como rotación, traslación, escalado y volteo. Estos métodos cambian la posición espacial y la forma de una imagen, pero mantienen la esencia de su contenido.
- Transformaciones del espacio de colorAjuste las propiedades del color, como el brillo, el contraste, la saturación y el tono de una imagen. Simula los cambios de la imagen en diferentes condiciones de iluminación y entornos de disparo.
- Método de inyección de ruido: Añade ruido aleatorio o tipos específicos de perturbaciones a los datos. Mejora la resistencia del modelo al ruido y las interferencias.
- Tecnología de muestras mixtasMezcla de diferentes muestras para generar nuevos datos de entrenamiento. Por ejemplo, en el ámbito de la imagen se utilizan métodos como MixUp y CutMix.
- Generación de aprendizaje profundoGeneración de nuevas muestras de entrenamiento mediante redes generativas adversariales o autocodificadores variacionales. Este enfoque crea nuevos datos más naturales y diversos.
Proceso de aplicación de la mejora de datos
- Fase de análisis de datosComprender en profundidad la distribución de las características y las limitaciones de los datos originales. Definir el tipo de datos que se van a mejorar y la dirección de la mejora.
- Proceso de selección metodológicaElección de las técnicas adecuadas de mejora de datos en función del tipo de datos y de los requisitos de la tarea. Considere el efecto de utilizar diferentes métodos en combinación.
- Pasos de ajuste de parámetros: Determinar los parámetros de intensidad y el rango de aplicación para diversas operaciones de mejora. La configuración óptima de los parámetros se halla experimentalmente.
- Mecanismos de control de calidadGarantizar que los datos generados cumplen los requisitos de autenticidad y razonabilidad. Establecer criterios para evaluar la calidad de los datos.
- Ciclo iterativo de optimizaciónAjustar continuamente la estrategia de mejora en función del efecto de la formación del modelo. Formar una interacción benigna entre la mejora de datos y el entrenamiento del modelo.
Ventajas de la mejora de datos
- Rentabilidad significativaReducir considerablemente los costes económicos y temporales de la recogida de datos y el etiquetado. Consiga mejorar el rendimiento de los modelos con un presupuesto limitado.
- Mejora de la solidez del modeloHacer que el modelo sea más adaptable a diversas perturbaciones y cambios. Mejorar la estabilidad del modelo en entornos complejos.
- Eficaz para evitar el sobreajusteReducir la dependencia del modelo de patrones específicos en el conjunto de entrenamiento aumentando la diversidad de datos. Mejorar el rendimiento del modelo en el conjunto de pruebas.
- Tratamiento de datos no equilibradosMejora centrada en un pequeño número de muestras de categorías para mejorar el desequilibrio de categorías. Mejora de la capacidad del modelo para reconocer muestras poco comunes.
- Mejorar el rendimiento de la generalizaciónPermitir que los modelos aprendan más características y patrones esenciales de los datos. Mejorar la aplicabilidad del modelo en nuevos escenarios.
Escenarios para la mejora de los datos
- Pequeñas muestras de tareas de aprendizajeAmpliar el conjunto de entrenamiento efectivo mediante el aumento de datos en caso de datos de entrenamiento limitados. Resolver las dificultades de modelización causadas por la escasez de datos.
- Aplicaciones con elevados requisitos de tiempo realPara los modelos que deben iterarse y desplegarse rápidamente, el aumento de datos ofrece una forma eficaz de mejorar el rendimiento.
- Reconocimiento en entornos complejosLa ampliación de datos ayuda a los modelos a adaptarse a la diversidad del entorno en los escenarios de aplicación reales, en los que existe una gran variedad de perturbaciones y cambios.
- Problemas de adaptación de los dominiosLa modelización de las propiedades del dominio de destino mediante el aumento de datos mejora el rendimiento del modelo en el nuevo dominio.
- Sistemas con altos requisitos de seguridadLa ampliación de datos ayuda a mejorar la fiabilidad y estabilidad de los modelos en ámbitos clave como las finanzas y la sanidad.
Consideraciones sobre la mejora de los datos
- principio de conservación semántica (en lógica)Garantizar que los datos mejorados no cambien su significado semántico original. Evitar la producción de muestras de entrenamiento engañosas.
- Mayor control de la fuerzaAjuste la intensidad y el rango de realce de los datos de forma razonable para evitar un realce excesivo que provoque la distorsión de los datos.
- Consideraciones sobre la pertinencia del mandatoLa selección de mejoras pertinentes para la tarea específica garantiza la eficacia práctica de la operación de mejora.
- Balance de recursos computacionales: Encuentre el equilibrio adecuado entre mejora y coste calculado. Evitar aumentos excesivos del tiempo de formación.
- Mecanismo de evaluación establecido: Establecer métodos eficaces de evaluación de la eficacia de las mejoras de los datos para garantizar el valor real de las estrategias de mejora.
Ejemplos prácticos de mejora de datos
- Aplicaciones de clasificación de imágenesEn tareas de clasificación de imágenes como ImageNet, la precisión del modelo se mejora mediante el recorte aleatorio, la rotación y el ajuste del color. Estas técnicas se convirtieron en un proceso estándar para entrenar modelos de aprendizaje profundo.
- Escenarios de categorización de textosMejora de datos de texto mediante sustitución de sinónimos, transformación de frases, traducción inversa, etc. en tareas de procesamiento del lenguaje natural. Mejora de la capacidad de generalización de los modelos de clasificación de textos.
- sistema de reconocimiento de vozMejora de los datos de audio añadiendo ruido de fondo, cambiando la velocidad del habla y ajustando el tono en el procesamiento de datos del habla. Mejora el rendimiento de los sistemas de reconocimiento de voz en entornos ruidosos.
- Análisis de imágenes médicasAmpliar los datos de formación mediante técnicas racionales de mejora de la imagen en el diagnóstico por imagen médica. Resolver el problema del difícil acceso a los datos médicos.
- Visión de la conducción autónomaMejora de los datos de entrenamiento mediante la simulación de diversas condiciones meteorológicas y de iluminación en un sistema de conducción autónoma. Mejora de la percepción del sistema en distintos entornos.
Tendencias en la mejora de datos
- Tecnología de mejora de la automatizaciónDesarrollar métodos inteligentes de búsqueda de estrategias de mejora de datos. Encuentre automáticamente las soluciones de mejora que mejor se adapten a conjuntos de datos y tareas específicas.
- Mejoras específicas de dominioDesarrollar métodos especializados de mejora de datos para distintos ámbitos de aplicación. Proporcionar estrategias de mejora más precisas y eficaces.
- Generación de modelos vinculantesIntegrar en profundidad técnicas de modelización generativa y de aumento de datos. Crear muestras aumentadas de mayor calidad y diversidad.
- Estudio teórico en profundidadReforzar la base teórica y los principios de la investigación sobre la mejora de datos. Proporcionar una orientación técnica más científica y sistemática.
- Integración total de procesosIntegrar profundamente la mejora de los datos en todo el proceso de aprendizaje automático. Forme un bucle cerrado completo de preparación de datos, formación de modelos, evaluación y optimización.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...