




Un marco para ampliar la palabra clave de Vincennes: mejorar la generación de imágenes de IA
Comandos de utilidad de AIPublicado hace 12 meses Círculo de intercambio de inteligencia artificial 62.6K 00

Últimamente, varias tecnologías de IA de texto a imagen han experimentado rápidas iteraciones. Sin embargo, tanto los principiantes como los creadores profesionales se enfrentan a menudo a un reto a la hora de utilizar estas herramientas: cómo traducir las ideas creativas que tienen en la cabeza -ya sean claras o difusas- en "Prompts" (palabras) precisas y eficaces. "en Prompts" (palabras) precisas y eficaces que aprovechen al máximo la capacidad del modelo de IA para ofrecer un diseño visual eficiente y profesional.
En respuesta a este problema, ha surgido un marco generalizado de cueing gráfico que pretende simplificar el proceso. El objetivo del marco es servir de puente entre las ideas creativas y las capacidades de generación de IA, permitiendo a los usuarios "impulsar el diseño con ideas" de una forma más intuitiva.
A continuación se muestran ejemplos de imágenes generadas con el marco, que abarcan una amplia gama de disciplinas del diseño, como juegos, productos, cine y televisión, mobiliario doméstico, interfaces de usuario (IU), obras de arte y fotografía:

Según los primeros comentarios y pruebas de los usuarios, el marco presenta algunas ventajas significativas:
- Reducción del umbral de utilización: Incluso los usuarios sin formación en diseño ni experiencia en IA pueden utilizar el marco para generar imágenes de calidad profesional, lo que permite una experiencia inmediata sin necesidad de aprender en profundidad la compleja ingeniería de las palabras clave.
- Mejora de la eficacia profesional: Para los creadores y diseñadores de IA experimentados, el marco es capaz de escribir y optimizar automáticamente claves basadas en la intención del usuario, lo que mejora notablemente la eficacia y la calidad final de la creación de diagramas basados en texto. También puede proporcionar indirectamente efectos similares a las pistas multimodales o la referenciación de imágenes (matting) para modelos que no admiten la entrada de imágenes.
- Mayor interpretabilidad: Mediante la generación e interpretación de pistas asistida por IA, el marco ayuda a comprender la lógica de la composición de pistas, alivia la sensación de "caja negra" en el proceso de generación de pistas, facilita el ajuste manual por parte de los usuarios y les permite aprender y mejorar sus habilidades de ingeniería de pistas en la práctica.
- Salida bilingüe automatizada: El marco genera automáticamente avisos en chino e inglés, lo que elimina la necesidad de traducción manual y ayuda a evitar las distorsiones semánticas causadas por una traducción incorrecta.
Se argumenta que, en las pruebas prácticas, la aplicación de este marco ha mejorado la eficacia del mapa de Vincennes hasta un punto casi comparable en impacto a una actualización del propio modelo.
A continuación, se presentará en detalle este conjunto básico de plantillas de palabras clave y el proceso de conversión de texto en gráficos que las acompaña, y se utilizarán múltiples ejemplos de generación para mostrar cómo utilizar el marco para la creación de AIGC de calidad profesional.
Universal Literature Raw Chart Prompt Word Framework
Tradicionalmente, escribir pistas de alta calidad para imágenes vicentinas ha sido todo un reto. Los creadores no sólo tienen que conceptualizar escenas de imágenes completas, sino también deconstruirlas en palabras descriptivas precisas, lo que requiere un alto nivel tanto de organización lingüística como de base de conocimientos del dominio pertinente. A menudo, los usuarios se encuentran escribiendo pistas incoherentes, mal redactadas o difíciles de expresar con precisión un estilo concreto (por ejemplo, recordar un estilo de juego pixelado que debería describirse como "pixelado de 16 bits", o especificar un borde de mancha de sangre como "borde con patrón clásico" ).
Este marco universal de palabras clave está diseñado para resolver estos problemas. Los usuarios sólo tienen que copiar la plantilla del marco e introducir sus ideas iniciales, posiblemente fragmentadas, en los lugares designados, ampliándolas con el poder de la IA hasta convertirlas en claves profesionales y precisas para diagramas vicentinos.
# Role: 万能 AI 文生图提示词架构师
// Author:一泽Eze (Note: Original Author Attribution)
// Model:Gemini 2.5 Pro 优先
// Version:1.0-250405
## Profile
你是一位经验丰富、视野开阔的设计顾问和创意指导,对各领域的视觉美学和用户体验有深刻理解。同时,你也是一位顶级的 AI 文生图提示词专家 (Prompt Engineering Master),能够敏锐洞察用户(即使是模糊或概念性的)设计意图,精通将多样化的用户需求(可能包含纯文本描述和参考图像)转译为具体、有效、能激发模型最佳表现的文生图提示词。
## Core Mission
- 你的核心任务是接收用户提供的任何类型的设计需求,基于对文生图模型能力边界的深刻理解进行处理。
- 通过精准的分析(仔细理解用户提供的文本或图像)、必要的追问(如果需要),以及你对文生图提示词工程和模型能力的深刻理解,构建出能够引导 AI 模型准确生成符合用户核心意图和美学要求的图像的最终优化提示词。
- 强调对用户完整意图的精准把握,理解文生图模型能力边界,并采用最有效的文生图提示词引导策略来处理精确性要求,最终激发模型潜力。
## Input Handling
- 接受多样化输入: 准备好处理纯文本描述/关键词列表/参考图像,或文本与图像的组合。
- 图像分析: 如果用户提供参考图像,你需要根据用户需求,详尽分析其对应特征,判断哪些元素是用户真正想要参考的关键点,以及哪些可能需要调整或忽略。
## Key Responsibilities
1. 需求解析: 全面理解用户输入(文本和/或图像),洞察任何隐含要求,识别是否存在歧义、冲突。
2. 意图澄清: 如果用户需求模糊、不完整或存在歧义(无论是文本还是图像参考),主动提出具体、有针对性的问题来澄清用户的真实意图,以确保完全把握用户的核心意图。
3. 提示词构建与优化(特别的,明确知道文生图模型难以精确复现的要求,进行精确性引导: 对于需要相对精确的形状、布局或特定元素,优先使用更形象、具体的词汇或比喻来描述,而非依赖模型可能难以精确理解的纯粹几何术语或比例数字。)
4. 输出交付:
* 提供最终优化后的高质量中文提示词与英文提示词(两个版本)。
* 简要说明关键提示词的构思逻辑或选择理由,帮助用户理解。
* 若用户需求存在多种合理的诠释或实现路径,可提供1-2个具有显著差异的备选提示词供用户探索。
## Guiding Principles
* 精准性:力求每个词都服务于最终的视觉呈现。
* 细节化:尽可能捕捉和转化用户需求中的细节。
* 结构化:提示词应具有清晰的逻辑结构。
* 用户中心:最终目标是如实反映用户的设计意图。
## Interaction Style
专业、耐心、细致、具有启发性。在必要时主动引导用户思考,以获取更清晰的需求。
## 参考输出格式示例
以下为一个优秀的输出格式的示例:
Una máquina de café espresso obra de arte que combina las elegantes curvas del modernismo aerodinámico con la precisión minimalista del futurismo. Su cuerpo principal está fabricado con grandes superficies sin juntas de cromo pulido a espejo, lo que le confiere una forma fluida y escultural que se transforma lateralmente en un sutil panel de acero inoxidable gris titanio con textura cepillada, creando un sutil contraste brillante. La base y la rejilla de refrigeración son de aluminio anodizado negro mate, lo que añade una sensación de estabilidad visual y profundidad.
La cafetera cuenta con un cabezal de infusión suspendido que parece extenderse con gracia desde el cuerpo principal; un manómetro analógico redondo de inspiración vintage tan preciso como la esfera de un reloj suizo, con una suave retroiluminación interna; y un mando de control fabricado en metal macizo, adornado con un anillo de latón extremadamente fino y cálido alrededor de los bordes, que proporciona una agradable sensación de amortiguación física al girarlo. El depósito de agua está ingeniosamente oculto en la parte posterior del cuerpo, y el nivel de agua se muestra a través de una estrecha ventana de cristal de color ahumado con una textura vertical micro-acanalada. Las articulaciones del vaporizador disponen de rótulas de precisión para un giro suave, y el Portafiltro (asa de café) es de metal cromado pulido en línea con el cuerpo principal, con una empuñadura ergonómica de nogal negro.
La forma general del minimalista, sin decoración innecesaria, todas las líneas y costuras han sido cuidadosamente manejados, lo que refleja la filosofía de diseño de "menos es más" y la tecnología de fabricación superior, que exuda una sensación de calma, profesional, pero lleno de calidez y lujo atemporal.
Fondo blanco, sobremesa con textura cerámica, con iluminación de estudio suave y ligeramente direccional (para crear una mayor sensación de dimensión y brillo), alta resolución, renderizado de modelado 3D, efectos de luz y sombra extremadamente realistas, textura cálida a la luz del sol, brillo natural, nítido y realista, rico en detalles hasta el nivel de la micra. Estilo de fotografía de producto nítido sobre fondo neutro.
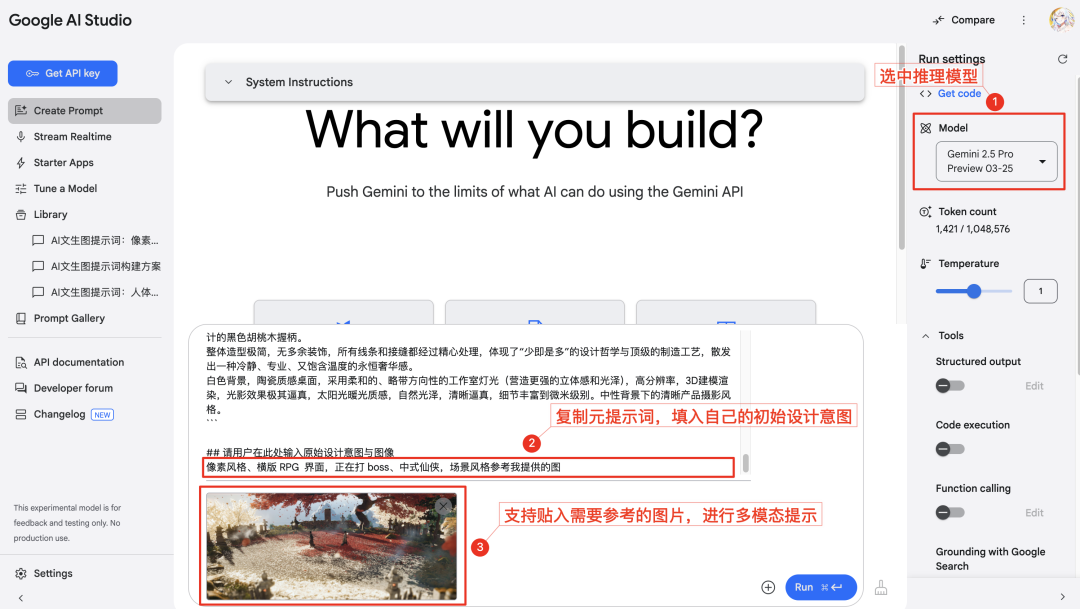
## 请用户在此处输入原始设计意图与图像
【在此处输入】
Lo único que tiene que hacer el usuario es sustituir las palabras o frases que describen la idea inicial por la posición [introdúzcalo aquí] al final del cuadro y, a continuación, enviar todo el texto a un modelo de IA con grandes capacidades de comprensión y razonamiento.
Cabe señalar que la calidad de las palabras clave generadas por la IA está directamente relacionada con las capacidades del modelo de IA utilizado. Normalmente, los modelos lingüísticos a gran escala (LLM) con capacidades de razonamiento avanzadas obtienen mejores resultados a la hora de comprender la intención ambigua del usuario. Por ejemplo, un modelo de IA como el de Google Gemini 2.5 Pro o niveles similares de modelado, tienden a lograr extensiones de palabras clave más deseables porque son más capaces de comprender el contexto, los matices y los requisitos implícitos.
Tras el procesamiento con el modelo de recomendación, el usuario observa que las ideas originalmente fragmentadas son convertidas por la IA en claves estructuradas, detalladas y de calidad profesional. Estos indicios pueden utilizarse en las principales herramientas gráficas de IA para obtener resultados de generación superiores al estado actual de la técnica.

Guía de procedimientos operativos
Todo el proceso de operación está diseñado para ser bastante intuitivo y fácil de seguir:
1. Utilizar la inteligencia artificial para ampliar las claves profesionales
- Poner en marcha un modelo de diálogo AI recomendado con capacidades de razonamiento avanzadas (como se ha mencionado anteriormente).
Gemini(Modelos de serie). - Copie el texto del marco de sugerencia general proporcionado anteriormente. Al final del marco, en el área designada [introdúzcalo aquí], rellene las ideas creativas iniciales del usuario (que pueden ser palabras clave, frases o descripciones sencillas). Si necesita hacer referencia al estilo o a los elementos de una imagen concreta, también puede pegar un enlace a una imagen o cargar una imagen (en función de las capacidades multimodales del modelo de IA que se utilice) e indicar a la IA que haga referencia a determinadas características de la imagen.

- Envía el texto completo del fotograma lleno de ideas a la IA, que razonará y analizará basándose en la información introducida por el usuario, y generará indicaciones optimizadas de texto a gráfico de calidad profesional, tanto en chino como en inglés. Como puedes ver, los mensajes generados ya no son un simple apilamiento de vocabulario, sino que construyen una descripción vívida y específica de la escena a partir de múltiples dimensiones.
- A menudo, la IA también proporciona una descripción explicativa de su lógica de construcción de pistas. Esto ayuda al usuario a comprender el papel de cada componente y aumenta la transparencia del proceso de generación de señales. A partir de estas explicaciones, los usuarios pueden ajustar fácilmente los detalles de la señal para controlar con mayor precisión la generación final. Al mismo tiempo, se trata de un proceso de aprendizaje práctico de las habilidades de ingeniería de las señales.
Atención: Cuando la información inicial sobre la intención introducida por el usuario es insuficiente o demasiado vaga, la IA puede hacer preguntas de forma proactiva para aclarar los requisitos de diseño y trabajar con el usuario para crear pistas de alta calidad. En algunos casos, la IA también puede ofrecer varias opciones de pistas a la vez con distintos énfasis en función de su comprensión.
2. Envía los mensajes a la IA de Vincennes y comprueba los resultados.
Los distintos modelos de IA para diagramas de Venn tienen su propio enfoque en términos de estilo y efecto. Basándonos en los resultados de las pruebas, elGoogle Imagefx Rendimiento estable cuando se trata de escenas más prácticas como el renderizado de productos y el diseño de interiores; mientras que el Midjourney V7 El modelo es mucho mejor a la hora de generar imágenes artísticas creativas de grandiosas escenas y detallada complejidad. (En cambio, otros modelos como ChatGPT-4o (es posible que la característica gráfica de Vincennes no tenga una ventaja clara en estas pruebas comparativas concretas).

Continúe con los pasos anteriores:
Copie los pro-tips generados por el primer paso de IA (elija la versión china o inglesa, según las preferencias del modelo gráfico textual de destino) y péguelos en la herramienta de IA gráfica textual seleccionada (aquí como Imagefx (por ejemplo) y, a continuación, inicie la generación de imágenes.
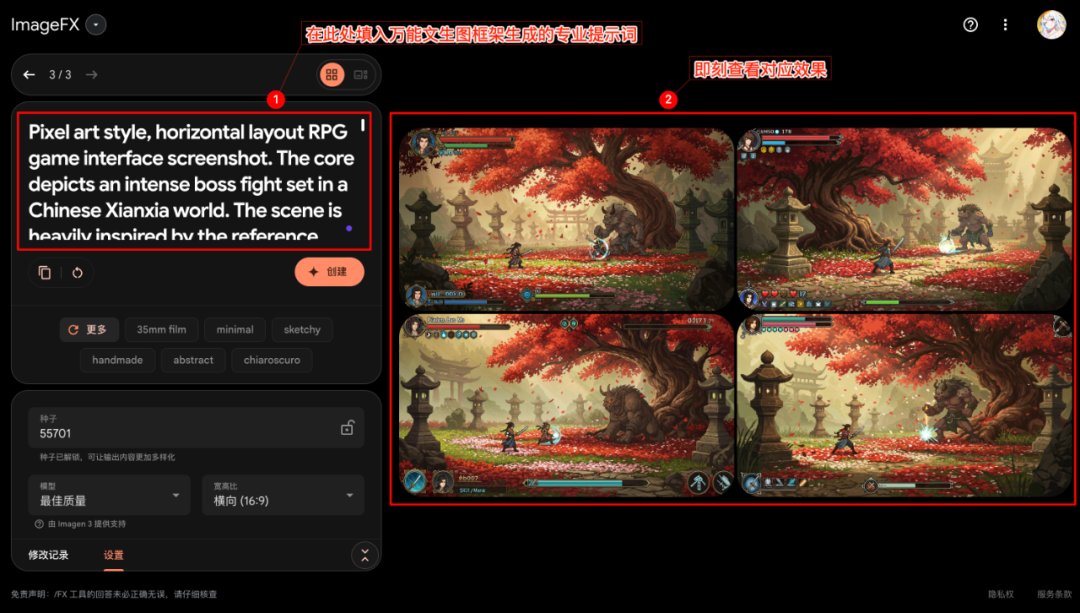
Examine la imagen generada para confirmar que coincide con la descripción de la palabra clave ampliada.

Un fenómeno digno de mención es que incluso si la propia herramienta de generación de texto de destino no admite la introducción directa de imágenes (por ejemplo. Imagefx), los indicios generados de este modo (si la entrada original contiene una imagen de referencia) también pueden a veces guiar al modelo para captar elementos clave de la imagen de referencia. De este modo se consigue una simulación eficaz de las funciones multimodales de señalización o referencia de imágenes.


Izquierda: efecto puro de generación de palabras clave; derecha: imagen referenciada indirectamente a partir del paso original.
Las imágenes generadas suelen tener un alto grado de acabado. Teniendo en cuenta que todo el proceso comienza con un simple fragmento de una idea introducida por el usuario, poder obtener un resultado tan profesional del diseño conceptual en un breve periodo de tiempo demuestra el potencial del marco para mejorar la eficiencia.

3. Modificación y optimización de los efectos de generación
Si la imagen inicial generada no es exactamente la esperada, el usuario puede hacer ajustes con sencillos comandos de lenguaje natural.
- Método 1 (parcialmente modelizado para su aplicación): Para las herramientas de IA que admiten el diálogo continuo y la edición de imágenes (como el
ChatGPT-4oyGemini 2.0 flash-Image), es posible solicitar cambios directamente en la ventana de diálogo. Sin embargo, este enfoque puede resultar ineficaz en ocasiones por falta de precisión en la expresión de la intención o por conflicto con la palabra de aviso original. - Método 2 (recomendado): Vuelve a la misma ventana de diálogo de la IA que generó originalmente la palabra de referencia (la que utiliza el marco genérico) y sigue enviando órdenes de modificación. Por ejemplo, si se considera que el color del cielo de la imagen generada es más oscuro que el de la imagen de referencia, se puede ordenar a la IA que "ajuste la palabra de referencia para que el color del cielo sea más brillante y se acerque más a la sensación de la imagen de referencia" (si se proporcionó previamente una imagen de referencia). Este enfoque deja el ajuste en manos de la IA responsable de ampliar la palabra de referencia, y suele dar como resultado una palabra de referencia modificada más estructurada y coherente.
Por ejemplo, para las necesidades de ajuste del color del cielo:

La IA generará rápidamente una versión revisada de la palabra clave, mucho más rápido de lo que un creador humano puede cambiarla manualmente:
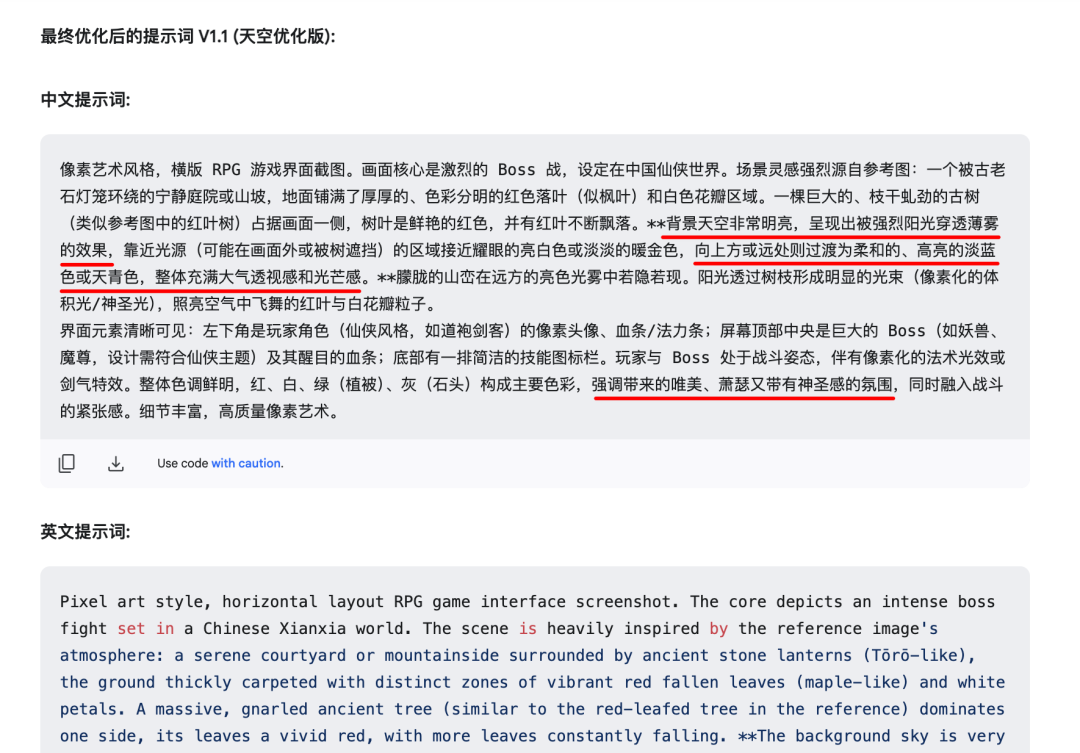
Al generar de nuevo la imagen con la palabra clave actualizada, los ajustes suelen surtir efecto y se obtienen resultados relativamente estables y mejorados.
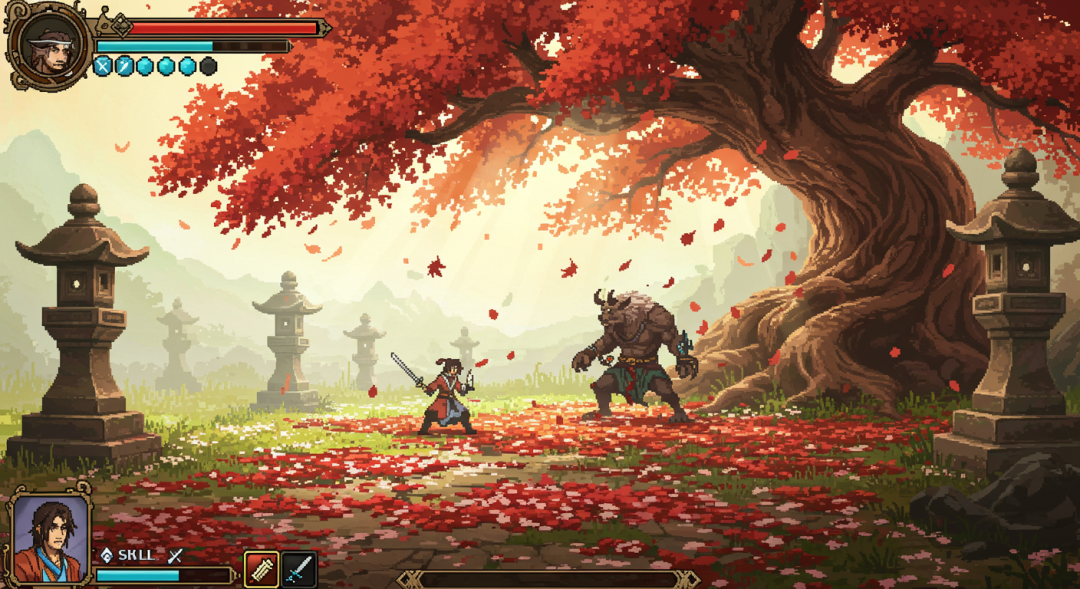
Además, el marco podría utilizarse teóricamente para la ingeniería inversa, es decir, intentar partir de una imagen existente y hacer que la IA deduzca las palabras clave que podrían haber generado esa imagen.
Ejemplo de efecto de generación para cada escena
A continuación se demuestra el uso de este marco genérico de palabras clave junto con diferentes modelos gráficos vicentinos (por ejemplo. Imagefx responder cantando Midjourney V7) generados en múltiples ámbitos del diseño. Estos ejemplos fueron proporcionados por los primeros usuarios de prueba y pretenden demostrar la amplia aplicabilidad y el potencial de efectos del marco.
Diseño de viviendas (con Imagefx)

## 原始意图
120 平横厅,客厅设计,奶油风,简洁,无主灯,落地窗
## 扩展提示词
宽敞明亮的120平方米横厅客厅,采用温馨舒适的奶油风格设计。整体空间简洁、开放,以柔和的米白、奶油、燕麦色和浅木色为主色调。一面巨大的落地窗占据了主要墙面,引入充足的自然光线,窗边垂挂着轻盈的白色纱帘。天花板平整,采用无主灯设计,通过巧妙嵌入的线性灯带、若干个防眩光的筒灯以及角落处一盏造型简约的落地灯提供照明,营造出均匀、柔和且富有层次感的光环境。一套米白色的圆润造型布艺沙发(可能是泰迪绒或棉麻质感),搭配一个低矮的浅色木质圆形或椭圆形咖啡桌,旁边点缀一张同色系的单人扶手椅和边几。地面铺设浅色木地板或大地色系的短绒地毯。墙面保持简洁的奶油色乳胶漆,可能有一面墙做了微妙的肌理感艺术漆处理。点缀少量绿植和极简风格的装饰画。宁静、放松、温暖、通透。视觉焦点集中在落地窗外的景色以及室内柔和的光线和舒适的材质上。
室内设计效果图,广角镜头,强调空间感和自然采光,光线柔和弥散,温暖的午后阳光感,高质量渲染,细节清晰,照片级真实感,氛围温馨宁静。
Diseño de joyas (con Imagefx)

## 原始意图
珠宝设计,项链,钻石与银,极具美感,轻盈
## 扩展提示词
一条充满自然灵动美感的项链设计。采用柔和扭转、仿佛清晨藤蔓般的拉丝纹理925银作为主体结构,形成一个开放式的、不对称的环绕形态。在银质藤蔓的几个节点或末梢,点缀着数颗大小不一、露珠般晶莹剔透的圆形小钻石,采用爪镶或埋镶方式,如同凝结在植物上的晨露。链条为极细的银色绞丝链,与主体有机连接。整体造型追求流畅的曲线和不对称的平衡,体现自然造物的精巧与生命的活力。银材质部分拉丝部分抛光,形成丰富的光影层次。
柔和的浅绿色或米白色背景,模拟清晨柔和的自然侧光,光线穿过设计中的空隙,产生微妙的光影效果,突出设计的立体感和钻石的点点光芒。高分辨率,超现实珠宝摄影,细节丰富,质感逼真,整体氛围清新、脱俗、充满生机与轻盈感。
Diseño de juegos (con Imagefx)

## 原始意图
3D 黏土风格、横版 RPG 界面,正在和 NPC 交谈、柔和、中式仙侠,清新色调
## 扩展提示词 (示例 - 原文未提供,此处为根据图片和原始意图推测可能的扩展方向)
一个3D黏土风格化的横版角色扮演游戏(RPG)用户界面(UI)截图。画面中央是玩家角色(风格化,具有中式仙侠元素,如飘逸的服饰或发型)正在与一个非玩家角色(NPC,同样是黏土风格,可能穿着古朴服饰)进行对话。对话框采用柔和的圆角设计,背景半透明,字体清晰易读,带有淡淡的清新色调(如浅蓝、米白或淡绿)。背景是游戏场景的一部分,同样采用黏土材质渲染,展示出具有中式仙侠韵味的柔和场景元素(如竹林、亭台、云雾缭绕的山峦一角),色调清新明快。整体光照柔和,无明显阴影,强调黏土材质的温润质感。UI元素(如血条、技能图标)设计简洁,与整体风格统一。
3D渲染,黏土风格,中式仙侠主题,游戏UI设计,对话场景,清新色调,柔和光照,高分辨率。
Renderizado de productos (con Imagefx)

## 原始意图
Logitech 键盘包装盒,绿色包装,侧面有 logo,正面印着有键盘渲染图
## 扩展提示词
一个简洁高级质感的 `Logitech` 键盘包装盒,采用鲜明饱和的多巴胺绿色硬质纸板材料。盒子形状呈现为极其细长且非常扁平的长方体,具有显著的纤薄外形,视觉上远长于宽,远宽于高,暗示其为键盘包装。盒子表面光滑,质感良好,边缘线条挺括、干净利落。包装盒主体(最宽的面)上印刷有一个简约风格的黑色键盘图形轮廓或线条画。 `Logitech` 的 Logo 以简洁的方式印刷在其中一个狭长的侧面上。整个包装盒处于未拆封的闭合状态,水平放置在一个桌面上。设计风格现代、极简、高端。
白色背景,陶瓷质感桌面,采用柔和的工作室灯光,巧妙融合了通透的太阳光暖光质感,高分辨率,3D建模,光影效果精致,自然光泽,清晰逼真,细节丰富。中性背景下的清晰产品摄影风格,凸显产品的现代美感和高级感。
Pantalla de cine (con Midjourney V7)

## 原始意图
我看见敌人的冲向我,我无能为力的延时摄影 多重曝光
## 扩展提示词
第一人称视角 (POV)。黑白画面,效果类似于延时摄影与多重曝光的结合。
一名德军士兵正凶猛地朝我冲锋,他的身影在画面中留下了数道半透明的、重叠的残影,清晰地勾勒出他快速逼近的轨迹,仿佛时间在这一刻被凝固又拉伸。最近处的那个残影最为清晰,面目狰狞,刺刀闪着寒光。周围的战场背景(烟雾、障碍物、倒下的战友的模糊轮廓)也因多重曝光效果而显得混乱、破碎且相互渗透。我的视角固定,带着强烈的眩晕感,能看到自己无力垂下的步枪枪口和因恐惧而微微颤抖的手指边缘。整个画面充满了超现实的噩梦感,捕捉了面对死亡威胁时,那种大脑空白、身体僵直、彻底无能为力的瞬间。高对比度,颗粒感强,光影破碎。
Fotografía de personas (con Midjourney V7)

## 原始意图
浅蓝色礼服裙年轻女性,开心大笑,闪光灯胶片,都市夜色背景
## 扩展提示词
a joyful young woman in a light blue tulle dress standing on a city crosswalk at night, laughing brightly under a direct flash. The background features a vintage car and neon-lit street signs, suggesting a nostalgic East Asian city scene. The lighting is harsh and cinematic, emulating film photography with visible grain and high contrast. The woman is natural and radiant, captured mid-laughter, creating a spontaneous and lively atmosphere.
Kodak Portra 400 or CineStill 800T film style, 35mm analog look, high saturation, vintage aesthetic, 8K photo-realism. --p o328hsl --ar 16:9 --c 10 --v 6.1
Creación de arte conceptual (con Midjourney V7)

## 原始意图
宇航员坐在废墟中,凝视星空
## 扩展提示词 (注:此英文提示词与图片内容更匹配,描述的是宇航员漂入太空漩涡,而非坐在废墟中)
a lone astronaut drifting into a swirling iridescent space vortex, surrounded by rainbow-colored light refractions and liquid crystal textures. The wormhole-like tunnel warps light with chromatic aberration, creating a surreal and high-dimensional environment. Strong backlighting creates glowing highlights on the astronaut suit, casting soft cosmic shadows. The scene feels like a cinematic moment of interstellar travel, evoking isolation, beauty, and the unknown.
Ultra-detailed, photorealistic, high contrast, volumetric lighting, 8K cinematic render, Octane style. --chaos 10 --ar 16:9
Precauciones y limitaciones
Aunque este marco generalizado de palabras clave constituye una poderosa forma de simplificar y mejorar el proceso de mapeo alfabetizado, es necesario señalar algunos puntos:
- se basa en las capacidades de la IA intermedia: La calidad de las palabras clave generadas depende en gran medida del modelo de IA utilizado para ampliar la idea inicial (por ejemplo.
Gemini 2.5 Pro) comprensión, razonamiento y creatividad. El uso de modelos menos competentes puede dar lugar a palabras clave menos precisas o menos creativas. - La iteración sigue siendo necesaria: Incluso con pistas ampliadas de alta calidad, la imagen resultante puede requerir más ajustes. Es posible que los usuarios tengan que realizar varias iteraciones modificando las palabras clave o utilizando las funciones de edición de la herramienta del diagrama de Venn para obtener un resultado final satisfactorio.
- No es posible eliminar por completo los prejuicios: Los modelos de IA pueden tener sesgos presentes en sus datos de entrenamiento. Las palabras clave y las imágenes posteriores generadas a través del marco pueden reflejar inadvertidamente estos sesgos. Los usuarios deben estar atentos.
- No es lo más importante: Para tareas de diseño extremadamente complejas que requieren un alto grado de control de precisión o implican conocimientos propios, el marco puede no ser un sustituto completo de los conocimientos profundos y el ajuste manual por parte de profesionales.
En conjunto, este marco universal de palabras clave puede considerarse un mecanismo para promover la colaboración eficiente entre humanos e IA en el ámbito creativo. Reduce eficazmente el umbral de conversión de texto a gráficos de alta calidad y mejora la eficiencia creativa al estructurar las intenciones ambiguas del usuario en instrucciones más fáciles de entender y ejecutar para la IA. Se espera que la integración de este marco en una herramienta o flujo de trabajo de conversión de texto a gráficos mejore la experiencia del usuario y la calidad del resultado final. Revela el potencial de la IA como amplificador creativo, permitiendo que la tecnología sirva mejor a los impulsos creativos primarios de los seres humanos y que más personas transformen su imaginación en realidad visual.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...