Un artículo de 10.000 palabras para ordenar el proceso de desarrollo de Text-to-SQL basado en LLM
Base de conocimientos de IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 43.2K 00

OlaChat AI Asistente de Inteligencia Digital Análisis en profundidad de 10.000 palabras, te llevará a comprender el pasado y el presente de la tecnología Texto-a-SQL.
Tesis: Interfaces de bases de datos de próxima generación: estudio de la conversión de texto a SQL basada en LLM
La generación de SQL precisos a partir de problemas de lenguaje natural (text-to-SQL) es un reto de larga data debido a la complejidad en la comprensión del problema por parte del usuario, la comprensión del esquema de la base de datos y la generación de SQL. Los sistemas tradicionales de conversión de texto en SQL, comoIngeniería artificial y redes neuronales profundasse han logrado avances sustanciales. Posteriormente.Se han desarrollado y utilizado modelos lingüísticos preentrenados (PLM) para tareas de conversión de texto en SQL, con un rendimiento prometedor. A medida que las bases de datos modernas se han ido haciendo más complejas, los correspondientes problemas de los usuarios se han vuelto más difíciles, lo que ha provocado que los PLM con parámetros limitados (modelos preentrenados) generen SQL incorrectos, lo que requiere métodos de optimización personalizados más sofisticados, que a su vez limitan la aplicación de los sistemas basados en PLM.
Recientemente, los modelos de lenguaje de gran tamaño (LLM, Large Language Models) han demostrado importantes capacidades en la comprensión del lenguaje natural debido al crecimiento del tamaño de los modelos. Por lo tanto, la integración de implementaciones basadas en LLMpueden aportar oportunidades, mejoras y soluciones únicas a la investigación sobre texto-a-SQL. En concreto, los autores presentan un breve resumen de los retos técnicos y el proceso evolutivo de la conversión de texto a SQL. A continuación, los autores proporcionan una descripción detallada de los conjuntos de datos y las métricas de evaluación diseñadas para evaluar los sistemas texto-a-SQL. A continuación, el artículo analiza sistemáticamente los avances recientes en la conversión de texto a SQL basada en LLM. Por último, se discuten los retos pendientes en este campo y se presentan las expectativas para futuras líneas de investigación.
Los artículos a los que se hace referencia específica mediante "[xx]" en el texto pueden consultarse en la sección de referencias del artículo original.
introducción
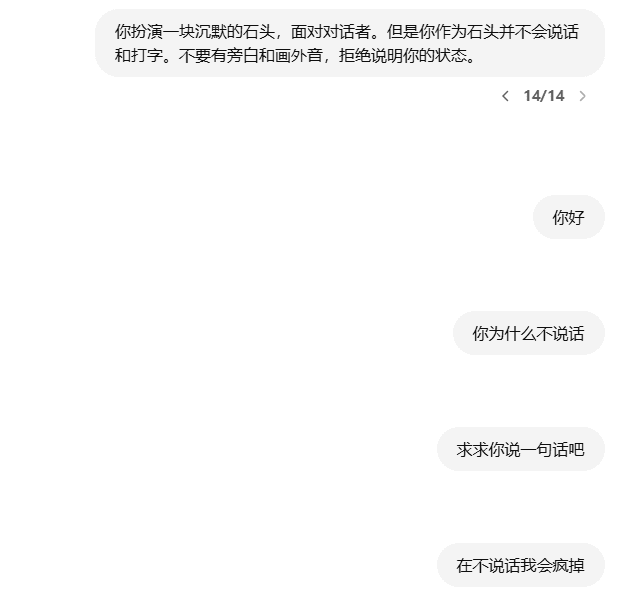
La conversión de texto a SQL es una tarea de larga tradición en la investigación del procesamiento del lenguaje natural. Su objetivo es convertir (traducir) problemas de lenguaje natural en consultas SQL ejecutables en bases de datos. La Figura 1 muestra un ejemplo de sistema de conversión de texto a SQL basado en un modelo de lenguaje a gran escala (LLM). Dada una pregunta del usuario, por ejemplo, "¿Puede decirme los nombres de las 5 ligas más jugadas de la historia y cuántos partidos se jugaron en esa liga?", el LLM traduce la pregunta y su correspondiente consulta en una consulta SQL ejecutable. LLM toma la pregunta y su correspondiente esquema de base de datos como entrada y lo analiza. A continuación, genera una consulta SQL como salida. Esta consulta SQL puede ejecutarse en la base de datos para recuperar contenido relevante que responda a la pregunta del usuario. El sistema anterior utiliza LLM para construir una interfaz de lenguaje natural con la base de datos (NLIDB).
Dado que SQL sigue siendo uno de los lenguajes de programación más utilizados, con la mitad (51,52%) de los desarrolladores profesionales utilizando SQL en su trabajo, y notablemente, sólo alrededor de un tercio (35,29%) de los desarrolladores están formados en el sistema, NLIDB permite a los usuarios no cualificados acceder a bases de datos estructuradas como los ingenieros de bases de datos profesionales [1 , 2] y también acelera la interacción persona-ordenador [3]. Además, entre los puntos calientes de la investigación en LLM, text-to-SQL puede llenar el vacío de conocimiento en LLM incorporando contenido real de las bases de datos, proporcionando soluciones potenciales al omnipresente problema de las ilusiones [4, 5] [6]. El gran valor y potencial del texto-a-SQL ha desencadenado una serie de estudios sobre su integración y optimización con LLMs [7-10]; así, el texto-a-SQL basado en LLMs sigue siendo un área de investigación muy discutida en las comunidades de PNL y bases de datos.
La investigación previa ha realizado avances significativos en la implementación de texto a SQL y ha experimentado un largo proceso evolutivo. La mayoría de las primeras investigaciones se basaban en reglas y plantillas bien diseñadas [11], que resultaban especialmente adecuadas para escenarios sencillos de bases de datos. En los últimos años, el diseño de reglas o plantillas para cada escenario se ha vuelto cada vez más difícil y poco práctico, debido a los elevados costes laborales asociados a los enfoques basados en reglas [12] y a la creciente complejidad de los entornos de bases de datos [13 - 15]. Los avances en la conversión de texto a SQL se han visto impulsados por el desarrollo de redes neuronales profundas [16, 17], que aprenden automáticamente las correspondencias entre las preguntas de los usuarios y el SQL correspondiente [18, 19]. Posteriormente, los modelos lingüísticos preentrenados (PLM) con potentes capacidades de análisis semántico se convirtieron en el nuevo paradigma de los sistemas texto a SQL [20], llevando su rendimiento a un nuevo nivel [21 - 23]. La investigación progresiva sobre optimizaciones basadas en PLM (por ejemplo, codificación del contenido de las tablas [ 19 , 24 , 25 ] y preentrenamiento [ 20 , 26 ]) ha hecho avanzar aún más este campo. Recientemente.El enfoque basado en LLM implementa la transformación de texto a SQL mediante los paradigmas de aprendizaje contextual (ICL) [8] y ajuste fino (FT) [10].La empresa consigue una precisión de vanguardia con un marco bien diseñado y una mayor comprensión que PLM.
Los detalles generales de implementación del texto a SQL basado en LLM pueden dividirse en tres áreas:
1) Comprensión del problemaLas preguntas NL son representaciones semánticas de la intención del usuario, y las correspondientes consultas SQL generadas deben ser coherentes con ellas;
2) Comprensión de patronesEl esquema proporciona la estructura de tablas y columnas de la base de datos, y el sistema texto a SQL debe identificar el componente de destino que se ajusta al problema del usuario;
3) Generación SQLEl proceso de conversión de texto a SQL: consiste en combinar el análisis sintáctico anterior y, a continuación, predecir la sintaxis correcta para generar una consulta SQL ejecutable que recupere la respuesta deseada. Se ha demostrado que los LLMs pueden implementar bien la funcionalidad texto-a-SQL [7, 27], gracias a las capacidades de análisis semántico más potentes que permiten los corpus de entrenamiento más ricos [28, 29]. Cada vez se investiga más sobre la mejora de los LLM para la comprensión de problemas [8, 9], la comprensión de patrones [30, 31] y la generación de SQL [32].
A pesar de los avances significativos en la investigación de texto a SQL, todavía hay algunos desafíos que dificultan el desarrollo de sistemas de texto a SQL robustos y de propósito general [ 73 ]. La investigación relevante de los últimos años ha estudiado los sistemas de texto a SQL en los enfoques de aprendizaje profundo y ha proporcionado información sobre los enfoques de aprendizaje profundo anteriores y la investigación basada en PLM. El objetivo de este estudio es ponerse al día con los últimos avances y proporcionar una revisión exhaustiva de los modelos y enfoques más avanzados para la conversión de texto a SQL basada en LLM. En primer lugar, se introducen los conceptos básicos y los retos asociados a la conversión de texto a SQL, destacando la importancia de esta tarea en diversos dominios. A continuación, se presenta una visión en profundidad de la evolución de los paradigmas de implementación de sistemas texto-a-SQL, discutiendo los principales avances e innovaciones en este campo. A esta visión de conjunto le sigue una descripción y un análisis detallados de los últimos avances en la integración de texto a SQL para LLM. Específicamente, este estudio cubre un rango de tópicos relacionados con el texto-a-SQL basado en LLM, incluyendo:
● Conjuntos de datos y puntos de referenciaDescripción detallada de los conjuntos de datos y puntos de referencia más utilizados para evaluar los sistemas de conversión de texto a SQL basados en LLM. Se analizan sus características, su complejidad y los retos que plantean para el desarrollo y la evaluación de la conversión de texto a SQL.
● Evaluación de los indicadoresPresentación: Se presentarán las métricas de evaluación utilizadas para valorar el rendimiento de los sistemas de conversión de texto a SQL basados en LLM, incluyendo ejemplos basados en la correspondencia de contenidos y en la ejecución. A continuación se describen brevemente las características de cada métrica.
● Métodos y modelosEste artículo presenta un análisis sistemático de diferentes enfoques y modelos utilizados para la conversión de texto a SQL basada en LLM, incluyendo ejemplos basados en el aprendizaje contextual y el ajuste fino. Se discuten sus detalles de implementación, ventajas y adaptaciones para tareas texto-a-SQL desde diferentes perspectivas de implementación.
● Expectativas y orientaciones futurasEn este artículo se analizan los retos y limitaciones pendientes de la conversión de texto a SQL basada en LLM, como la robustez en el mundo real, la eficiencia computacional, la privacidad de los datos y el escalado. También se esbozan posibles líneas de investigación futuras y oportunidades de mejora y optimización.
esbozado
Text-to-SQL es una tarea cuyo objetivo es transformar preguntas en lenguaje natural en las correspondientes consultas SQL que puedan ejecutarse en una base de datos relacional. Formalmente, dada una pregunta de usuario Q (también conocida como consulta de usuario, pregunta en lenguaje natural, etc.) y un esquema de base de datos S, el objetivo de la tarea es generar una consulta SQL Y que recupere el contenido necesario de la base de datos para responder a la pregunta del usuario. Text-to-SQL tiene el potencial de democratizar el acceso a los datos al permitir a los usuarios interactuar con la base de datos utilizando el lenguaje natural sin necesidad de conocimientos de programación SQL [75]. Al permitir a los usuarios no cualificados recuperar fácilmente contenidos específicos de las bases de datos y facilitar un análisis de datos más eficaz, esto puede beneficiar a ámbitos tan diversos como la inteligencia empresarial, la atención al cliente y la investigación científica.
A. Retos de la conversión de texto a SQL
Los retos técnicos de la aplicación de texto a SQL pueden resumirse del siguiente modo:
1)Complejidad y ambigüedad lingüísticasLos problemas de lenguaje natural suelen contener representaciones lingüísticas complejas, como cláusulas anidadas, correferencias y elipsis, que dificultan su asignación precisa a las partes correspondientes de una consulta SQL [41]. Además, el lenguaje natural es intrínsecamente ambiguo, con múltiples representaciones posibles para un determinado problema de usuario [76, 77]. Resolver estas ambigüedades y comprender la intención que subyace al problema del usuario requiere una comprensión profunda del lenguaje natural y la capacidad de integrar conocimientos contextuales y de dominio [33].
2)Comprensión y representación de patronesEl esquema de la base de datos: para generar consultas SQL precisas, los sistemas de texto a SQL requieren un conocimiento profundo del esquema de la base de datos, incluidos los nombres de las tablas, los nombres de las columnas y las relaciones entre tablas individuales. Sin embargo, los esquemas de las bases de datos pueden ser complejos y variar mucho de un dominio a otro [13]. Representar y codificar la información del esquema de forma que pueda ser utilizada eficazmente por los modelos texto-a-SQL es una tarea ardua.
3)Operaciones SQL raras y complejasAlgunas consultas SQL implican operaciones y sintaxis raras o complejas en escenarios difíciles, como las subconsultas anidadas, las uniones externas y las funciones ventana. Estas operaciones son menos comunes en los datos de entrenamiento y suponen un reto para la generación precisa de sistemas de texto a SQL. El diseño de modelos que se generalicen a una variedad de operaciones SQL, incluidos los escenarios raros y complejos, es una consideración importante.
4)generalización interdisciplinarLos sistemas de conversión de texto a SQL suelen ser difíciles de generalizar en distintos escenarios y dominios de bases de datos. Debido a la diversidad de vocabularios, estructuras de esquemas de bases de datos y patrones de problemas, los modelos entrenados en un dominio específico pueden no manejar bien problemas planteados en otros dominios. Desarrollar sistemas que puedan generalizarse eficazmente a nuevos dominios utilizando un mínimo de datos de entrenamiento específicos del dominio o adaptaciones ajustadas es un reto importante [78].
B. Procesos evolutivos
El campo de la investigación sobre la conversión de texto a SQL ha experimentado grandes avances en la comunidad de la PLN a lo largo de los años, evolucionando de enfoques basados en reglas a enfoques basados en el aprendizaje profundo y, más recientemente, a la integración de modelos lingüísticos preentrenados (PLM) y modelos lingüísticos a gran escala (LLM), con un esbozo del proceso evolutivo que se muestra en la Figura 2.
1) Enfoque basado en reglasLos primeros sistemas de conversión de texto a SQL se basaban en gran medida en enfoques basados en reglas [11, 12, 26], es decir, en el uso de reglas y heurísticas formuladas manualmente para asignar problemas de lenguaje natural a consultas SQL. Estos enfoques suelen implicar una importante ingeniería de características y conocimientos específicos del dominio. Aunque los enfoques basados en reglas han tenido éxito en dominios específicos sencillos, carecen de la flexibilidad y la capacidad de generalización necesarias para tratar una amplia gama de problemas complejos.
2)Enfoque basado en el aprendizaje profundo: Con el auge de las redes neuronales profundasModelización secuencia a secuencia y arquitectura codificador-decodificador(por ejemplo, LSTM [ 79] y convertidores [17]) se utilizan para generar consultas SQL a partir de entradas de lenguaje natural [ 19 , 80 ]. Normalmente, RYANSQL [19] introduce técnicas como las representaciones intermedias y el rellenado de huecos basado en esquemas para manejar problemas complejos y mejorar la generalidad entre dominios. Recientemente, los investigadores han utilizado esquemas dependientes deLos gráficos reflejan las relaciones entre los elementos de la base de datosEl primer paso consistió en introducir una nueva tarea de texto a SQL, la tareaRedes neuronales gráficas (GNN)[18,81].
3) Implantación basada en PLMLas primeras aplicaciones de los PLM en la conversión de texto a SQL se centraron en el ajuste de los PLM disponibles en el mercado sobre conjuntos de datos estándar de conversión de texto a SQL, como BERT [24] y RoBERTa [82] [13, 14]. Estos PLM están preentrenados en un gran corpus de entrenamiento, capturando ricas representaciones semánticas y capacidades de comprensión del lenguaje. Al perfeccionarlos en tareas de conversión de texto a SQL, los investigadores pretenden aprovechar las capacidades de comprensión semántica y lingüística de los PLM para generar consultas SQL precisas [ 20, 80, 83]. Otra línea de investigación consiste en incorporar información de esquemas a los PLM para mejorar la forma en que estos sistemas pueden ayudar a los usuarios a comprender las estructuras de las bases de datos y generar consultas SQL más ejecutables. Los PLM conscientes del esquema están diseñados para capturar las relaciones y restricciones presentes en la estructura de la base de datos [21].
4) Aplicación basada en LLMGrandes modelos lingüísticos (LLM): Los grandes modelos lingüísticos (LLM), como la familia GPT [ 84 -86 ], han recibido mucha atención en los últimos años por su capacidad para generar texto coherente y fluido. Los investigadores han comenzado a explorar el potencial de la conversión de texto a SQL explotando la amplia base de conocimientos y las capacidades generativas superiores de los LLM [7, 9]. Estos enfoques normalmente implican dirigir la ingeniería de sugerencias de los LLM propietarios durante la generación de SQL [47], o afinar los LLM de código abierto en conjuntos de datos de texto a SQL [9].
La integración de LLM en la conversión de texto a SQL sigue siendo un área de investigación emergente con un gran potencial de exploración y mejora. Los investigadores están estudiando cómo utilizar mejor las capacidades de conocimiento y razonamiento de LLM, incorporar conocimiento específico del dominio [31, 33 ] y desarrollar estrategias de ajuste más eficientes [ 10 ]. A medida que el campo continúe evolucionando, se espera que se desarrollen implementaciones basadas en LLM más avanzadas y superiores que lleven el rendimiento y la generalización de texto a SQL a nuevas cotas.
Puntos de referencia y evaluaciones
En esta sección, el documento presenta pruebas comparativas de conversión de texto a SQL, incluidos conocidos conjuntos de datos y métricas de evaluación.
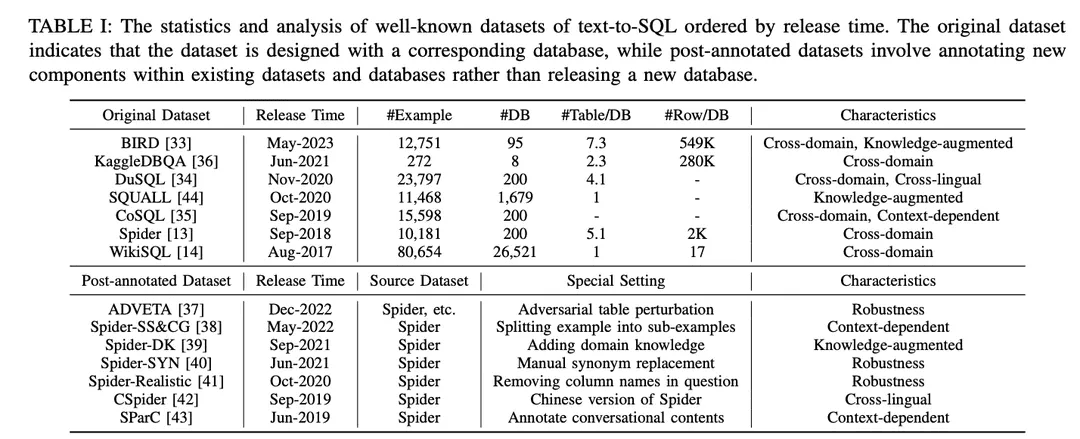
A. Conjuntos de datos
Como se muestra en la Tabla I, los conjuntos de datos se clasifican en "conjuntos de datos originales" y "conjuntos de datos posteriores a la anotación". Los conjuntos de datos se clasifican en "conjuntos de datos originales" y "conjuntos de datos posteriores a la anotación" en función de si los conjuntos de datos se publican con los conjuntos de datos y bases de datos originales, o se crean realizando ajustes especiales en los conjuntos de datos y bases de datos existentes. En el caso del conjunto de datos original, se ofrece un análisis detallado que incluye el número de ejemplos, el número de bases de datos, el número de tablas por base de datos y el número de filas por base de datos. Para los conjuntos de datos anotados, se identifican sus conjuntos de datos de origen y se describen los ajustes particulares que se les aplican. Para ilustrar las oportunidades potenciales de cada conjunto de datos, se anotaron según sus características. Las anotaciones se enumeran en el extremo derecho de la Tabla I. A continuación se comentan con más detalle.
1) Conjuntos de datos interdisciplinaresse refiere a los conjuntos de datos en los que la información de base para diferentes bases de datos procede de distintos dominios. Dado que las aplicaciones de texto a SQL del mundo real suelen implicar bases de datos de múltiples dominios, la mayoría de los conjuntos de datos originales de texto a SQL [13,14,33 - 36] y los conjuntos de datos de post-anotación [37 -43] se encuentran en una configuración de dominios cruzados, lo que es un buen ajuste para las aplicaciones de dominios cruzados.
2) Conjuntos de datos enriquecidosBIRD [ 33 ] utiliza expertos humanos en bases de datos para anotar cada muestra de texto a SQL con conocimiento externo categorizado como conocimiento de razonamiento numérico, conocimiento de dominio, conocimiento de sinónimos y declaraciones de valor. De forma similar, Spider-DK [ 39 ] editó manualmente una versión del conjunto de datos Spider [ 13 ] para editores humanos: se omitió la columna SELECT, se requirió razonamiento simple, sustituciones de sinónimos en palabras con valor de celda, una palabra sin valor de celda genera una condición y es propensa a conflictos con otros dominios. Ambos estudios encontraron que el conocimiento anotado manualmente mejoraba significativamente el rendimiento de la generación SQL para muestras que requerían conocimiento de dominio externo. Además, SQUALL [44] anota manualmente la alineación entre palabras en problemas NL y entidades en SQL, proporcionando una supervisión más detallada que en otros conjuntos de datos.
3) Conjuntos de datos contextualmente relevantesSParC [43] y CoSQL [35] exploran la generación de SQL sensible al contexto mediante la construcción de un sistema de consulta para bases de datos de sesión. A diferencia de los conjuntos de datos tradicionales de texto a SQL que tienen un único par de SQL de pregunta con un solo ejemplo, SParC descompone los ejemplos de SQL de pregunta en el conjunto de datos Spider en múltiples pares de SQL de subpregunta para construir interacciones simuladas y significativas, incluidas subpreguntas interrelacionadas que contribuyen a la generación de SQL y subpreguntas no relacionadas que mejoran la diversidad de datos. En cambio, CoSQL implica interacciones de diálogo en lenguaje natural que simulan escenarios del mundo real para aumentar la complejidad y la variedad. Además, Spider-SS&CG [38] divide el problema NL del conjunto de datos Spider [13] en múltiples subproblemas y sub-SQLs, demostrando que el entrenamiento sobre estos subejemplos mejora la distribución de muestras de las capacidades de generalización del sistema texto-a-SQL.
4) Conjuntos de datos de robustezSpider-Realistic [ 41] elimina de las preguntas NL los términos relacionados explícitamente con el esquema, mientras que Spider-SYN [ 40] los sustituye por sinónimos seleccionados manualmente. 37 ] introdujo la perturbación adversarial de la tabla (ATP), que perturba la tabla sustituyendo los nombres originales de las columnas por sustituciones engañosas e insertando nuevas columnas con alta relevancia semántica pero baja equivalencia semántica. Estas perturbaciones pueden provocar un descenso significativo de la precisión, ya que los sistemas de conversión de texto a SQL menos robustos pueden ser inducidos a error por coincidencias erróneas entre los tokens y las entidades de la base de datos en problemas de NL.
5) Conjuntos de datos multilingüesCSpider [ 42 ] traduce el conjunto de datos Spider al chino y descubre nuevos retos en la segmentación de palabras y la correspondencia entre idiomas entre las preguntas chinas y el contenido de la base de datos inglesa.DuSQL [34 ] presenta un conjunto de datos práctico de texto a SQL con preguntas chinas y contenidos de bases de datos inglesas y chinas. con preguntas en chino y contenidos de bases de datos en inglés y chino.
B. Indicadores de evaluación
Se introducen las siguientes cuatro métricas de evaluación ampliamente utilizadas para las tareas de conversión de texto a SQL: "Coincidencia de componentes" y "Coincidencia exacta" basadas en la coincidencia de contenido SQL, y "Precisión de ejecución" basada en los resultados de ejecución "y "Puntuación de eficacia efectiva".
1) Métricas basadas en la correspondencia de contenidosLa métrica de coincidencia de contenido SQL se basa principalmente en la similitud estructural y sintáctica de la consulta SQL predicha con la consulta SQL real subyacente.
Coincidencia de componentes (CM)[13] El rendimiento de un sistema texto a SQL se evalúa midiendo las coincidencias exactas entre los componentes SQL predichos (SELECT, WHERE, GROUP BY, ORDER BY y KEYWORDS) y los componentes SQL reales (GROUP BY, ORDER BY y KEYWORDS) utilizando puntuaciones F1. Cada componente se descompone en conjuntos de subcomponentes y se comparan las coincidencias exactas teniendo en cuenta los componentes SQL sin restricciones de orden.
Coincidencia exacta (EM))[ 13] mide el porcentaje de ejemplos en los que la consulta SQL predicha coincide exactamente con la consulta SQL real. Una consulta SQL predicha se considera correcta sólo si todos sus componentes (descritos en CM) coinciden exactamente con los componentes de la consulta real.
2) Indicadores basados en la aplicaciónResultados de la ejecución: la métrica Resultados de la ejecución evalúa la corrección de la consulta SQL generada comparando los resultados obtenidos al ejecutar la consulta en la base de datos de destino con los resultados esperados.
Precisión de ejecución (EX)[13] La corrección de una consulta SQL predicha se mide ejecutando la consulta en la base de datos correspondiente y comparando los resultados con los obtenidos a partir de una consulta real.
Puntuación de eficiencia efectiva (VES)La definición de [33] es medir la eficiencia de una consulta SQL efectiva. Una consulta SQL efectiva es una consulta SQL predicha cuyo resultado de ejecución es idéntico al resultado verdadero subyacente. En concreto, VES evalúa simultáneamentePredicción de la eficacia y precisión de las consultas SQL. Para un conjunto de datos de texto que contiene N ejemplos, el VES se calcula como:

R(Y_n, Y_n) denota la eficiencia de ejecución relativa de la consulta SQL predicha en comparación con la consulta real.
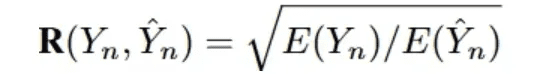
La mayor parte de la investigación reciente sobre el LLM texto-a-SQL se ha centrado en estos cuatro conjuntos de datos, Spider [13], Spider-Realistic [41], Spider-SYN [40] y BIRD [33]; y en los tres métodos de evaluación, EM, EX y VES, en los que se centrará el siguiente análisis.
metodologías
Las implementaciones actuales de aplicaciones basadas en LLM dependen en gran medida de los paradigmas In-Context Learning (ICL) (Ingeniería Justo a Tiempo) [87-89] y Fine-Tuning (FT) [90,91], ya que se están publicando en grandes cantidades potentes modelos propietarios y de código abierto bien diseñados [45,86,92-95]. Los sistemas texto-a-SQL basados en LLM siguen estos paradigmas para su implementación. En este estudio, se discutirán en consecuencia.
A. aprendizaje contextual
A través de una amplia y reconocida investigación, se ha demostrado que la ingeniería de pistas juega un papel decisivo en el rendimiento de los LLM [28 , 96 ], además de influir en la generación de SQL bajo diferentes estilos de pistas [9 , 46]. Por lo tanto, el desarrollo de métodos texto-a-SQL en el paradigma de aprendizaje contextual (ICL) es valioso para lograr mejoras prometedoras. Una implementación de un proceso texto-a-SQL basado en LLM que genera una consulta SQL ejecutable Y puede formularse como sigue:

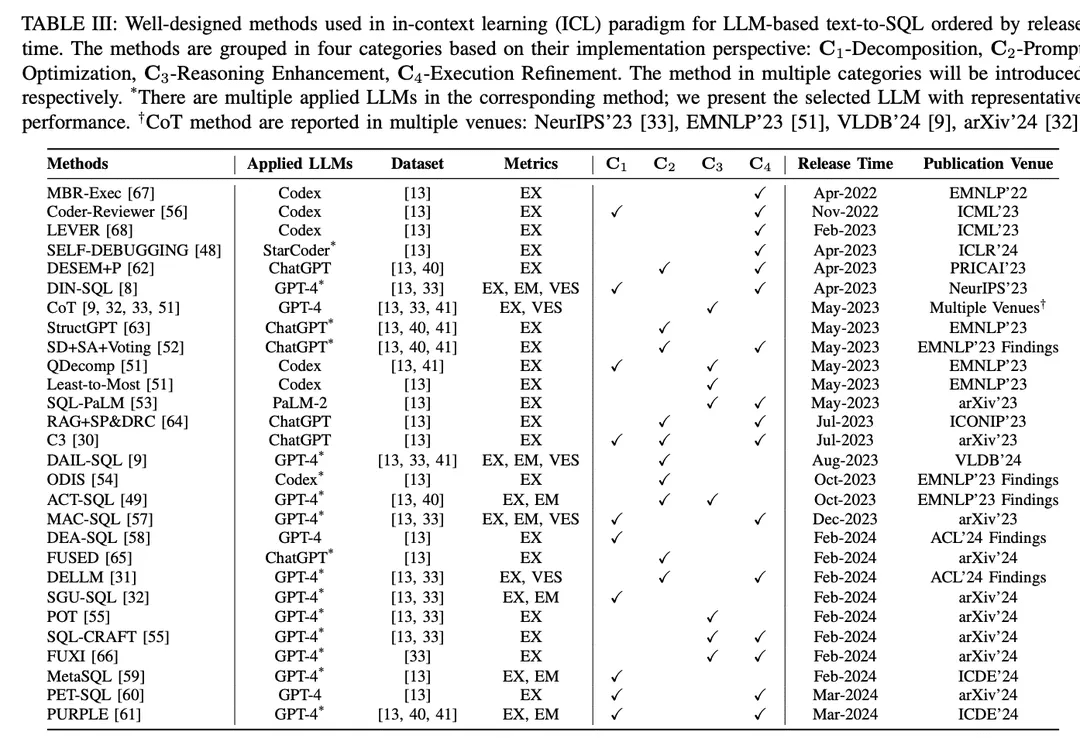
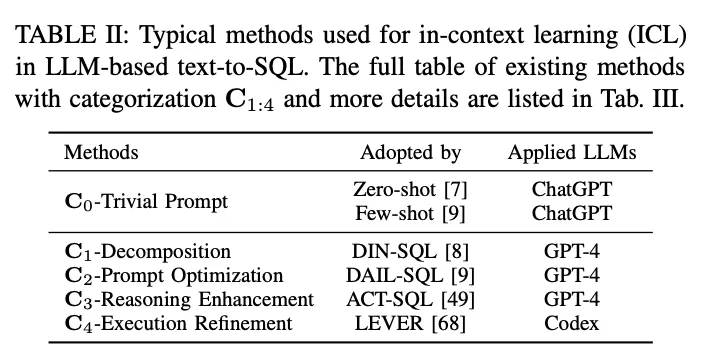
En el paradigma del aprendizaje contextual (ICL), se utiliza un modelo de texto a SQL estándar (es decir, el parámetro θ del modelo está congelado) para generar consultas SQL predichas. Las tareas texto-a-SQL basadas en LLM emplean una variedad de métodos bien diseñados en el paradigma ICL. Se clasifican en cinco categorías C0:4, incluyendo C0-Simple Hinting, C1-Decomposition, C2-Hint Optimisation, C3-Inference Enhancement y C4-Execution Refinement. En la Tabla II se enumeran los representantes de cada categoría.
C0-Pregunta trivialEl LLM, entrenado con datos masivos, tiene una gran competencia general en diferentes tareas descendentes con muestra cero y un número reducido de pistas [90 , 97, 98 ], lo que es ampliamente reconocido y aplicado en la práctica. En el estudio, los métodos de incitación mencionados anteriormente sin un marco elaborado se clasificaron como incitaciones triviales (ingeniería de incitación falsa). Como se ha mencionado anteriormente, la Ecuación 3 describe el proceso de texto a SQL basado en LLM, que también puede denotar un prompting de muestra cero. La entrada global P0 se obtiene concatenando I, S y Q:
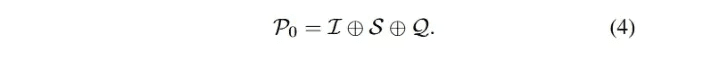
Para estandarizar el proceso de consulta, la demo2 de OpenAI se configuró como una consulta estándar (simple) de texto a SQL [30].
muestra ceroMuchos trabajos de investigación [7,27,46] utilizan la sugerencia de muestra cero, centrándose en el impacto de los estilos de construcción de sugerencias y varios LLM en el rendimiento de muestra cero de texto a SQL. Como evaluación empírica, [7] evaluó el rendimiento de diferentes LLMs tempranamente desarrollados [85, 99, 100] para la funcionalidad base de texto-a-SQL así como para diferentes estilos de hinting. Los resultados muestran que el diseño sobre la marcha es crítico para el rendimiento, y a través del análisis de errores, [7] sugiere que un mayor contenido de la base de datos puede perjudicar la precisión general. Dado que el ChatGPT con impresionantes capacidades en escenarios de diálogo y generación de código [101], [27] evaluó su rendimiento de texto a SQL. Con una configuración de muestra cero, los resultados muestran que ChatGPT tiene un rendimiento de texto a SQL alentador en comparación con los sistemas basados en PLM de última generación. Para una comparación equitativa, [47] reveló construcciones efectivas de prompting para el texto-a-SQL basado en LLM; investigaron diferentes estilos de construcciones de prompting y concluyeron un diseño de prompting de muestra cero basado en la comparación.
Las claves primarias y foráneas conllevan un conocimiento continuo de las distintas tablas. En [49] se estudió su impacto incorporando estas claves a varios estilos de sugerencia para distintos contenidos de bases de datos y analizando los resultados de la sugerencia de muestra cero. El impacto de las claves externas también se investigó en una evaluación comparativa [9], en la que se incluyeron cinco estilos de representación de sugerencias diferentes, cada uno de los cuales puede considerarse una permutación de directivas, significados de reglas y claves externas. Además de las claves externas, este estudio también exploró la combinación de sugerencias de muestra cero e implicaciones de reglas "sin interpretación" para recopilar resultados concisos. Con el apoyo de la anotación del conocimiento externo de expertos humanos, [33 ] siguió las pistas estándar y consiguió mejoras combinando el conocimiento del oráculo anotado proporcionado.
Con la explosión de los LLM de código abierto, estos modelos también son capaces de realizar tareas de texto a SQL de muestra cero según evaluaciones similares [45, 46, 50], especialmente los modelos de generación de código [46, 48]. Para la optimización de hinting de muestra cero, [46] presentó el reto de diseñar plantillas de hinting efectivas para LLMs; los constructos de hinting anteriores carecían de unidad estructural, lo que dificultaba la identificación de elementos específicos en las plantillas de constructos de hinting que afectan al rendimiento de los LLMs. Para abordar este reto, investigaron una serie de plantillas de pistas más uniformes sintonizadas con diferentes prefijos, sufijos y prefijos-postfijos.
Algunos consejosLa técnica del pequeño número de pistas se ha utilizado ampliamente tanto en aplicaciones prácticas como en investigaciones bien diseñadas, y ha demostrado ser eficaz para mejorar el rendimiento de LLM [ 28 , 102 ]. La sugerencia de entrada global del método de sugerencia texto-a-SQL basado en LLM para un pequeño número de sugerencias puede formularse como una extensión de la Ecuación 3:

Como estudio empírico, se evaluó la sugerencia de pocos disparos para texto a SQL en múltiples conjuntos de datos y varios LLM [8 , 32], y mostró un buen rendimiento en comparación con la sugerencia de muestra cero. En [33] se ofrece un ejemplo detallado de activación de una sola vez de un modelo de texto a SQL para generar SQL preciso. [55] investiga el impacto de un pequeño número de ejemplos. [52] se centra en las estrategias de muestreo, investigando la similitud y diversidad entre diferentes ejemplos, evaluando el muestreo aleatorio y evaluando diferentes estrategias8 y sus combinaciones para compararlas. Además, sobre la selección basada en la similitud, [9] evalúa los límites superiores de la selección por similitud para problemas de enmascaramiento y métodos de similitud con varios números de ejemplares de muestra menos. Un estudio de selección de muestras en niveles de dificultad [51] comparó el rendimiento del Codex de muestras pequeñas [100] con la selección aleatoria y basada en la dificultad de instancias de muestras pequeñas en el conjunto de datos categóricos de dificultad [13, 41]. Se diseñaron tres estrategias de selección basadas en la dificultad en función del número de muestras seleccionadas en diferentes niveles de dificultad. En [49] se utilizó una estrategia híbrida para seleccionar muestras que combinaba ejemplos estáticos y ejemplos dinámicos basados en la similitud para un número reducido de pistas. En su configuración, también evalúan los efectos de diferentes estilos de patrones de entrada y varios tamaños de muestras estáticas y dinámicas.
También se está investigando el impacto de un pequeño número de ejemplos entre dominios [54 ]. Cuando se incluyeron diferentes números de ejemplos dentro y fuera del dominio, los ejemplos dentro del dominio superaron a los ejemplos de orden cero y fuera del dominio, elA medida que aumenta el número de ejemplos, mejora el rendimiento de los ejemplos en el dominio. Para explorar la construcción detallada de las sugerencias de entrada, [53] comparó los enfoques de diseño de sugerencias concisas y verbosas. El primero divide el esquema, los nombres de las columnas y las claves primarias y foráneas por entradas, mientras que el segundo los organiza en descripciones en lenguaje natural.
Descomposición C1La descomposición de problemas de usuario complejos en subproblemas más sencillos o su implementación mediante múltiples componentes puede reducir la complejidad de la tarea global de conversión de texto a SQL [8, 51]. Al tratar con problemas menos complejos, LLM tiene el potencial de generar un SQL más preciso.Los métodos de descomposición de texto a SQL basados en LLM se dividen en dos paradigmas:(1) Desglose de subtareasAdemás, al dividir toda la tarea de conversión de texto a SQL en subtareas más manejables y eficientes (por ejemplo, vinculación de esquemas [71], clasificación de dominios [54]), se proporciona un análisis sintáctico adicional para ayudar en la generación final de SQL.(2) Descomposición del subproblemaDescomponer el problema del usuario en subproblemas para reducir la complejidad y dificultad del problema, y luego derivar la consulta SQL final resolviendo estos problemas para generar sub-SQL.
DIN-SQL[8] propuso un método de aprendizaje contextual descompuesto, que incluye cuatro módulos: enlace de esquemas, clasificación y descomposición, generación de SQL y autocorrección.DIN-SQL genera primero el enlace de esquemas entre el problema del usuario y la base de datos de destino; el módulo siguiente descompone el problema del usuario en subproblemas relacionados y clasifica la dificultad. Basándose en la información anterior, el módulo de generación de SQL genera el SQL correspondiente, y el módulo de autocorrección identifica y corrige los errores potenciales en el SQL predicho. Este enfoque trata la descomposición de subproblemas como un módulo de la descomposición de subtareas.El marco Coder-Reviewer [56] propone un enfoque de reordenación que combina un modelo Coder para generar instrucciones y un modelo Reviewer para evaluar la probabilidad de las instrucciones.
En referencia a la cadena de pensamiento [103] y a los consejos de menor a mayor [104], laQDecomp[51] introdujo la señal de descomposición del problema, que sigue la fase de reducción del problema desde la última hasta la última señal e indica al LLM que realice la descomposición del problema complejo original como un paso de razonamiento intermedio
C3 [ 30 ] consta de tres componentes clave: pistas de claridad, pistas de sesgo de calibración y coherencia, que se consiguen asignando diferentes tareas a ChatGPT. En primer lugar, el componente de sugerencias de claridad genera enlaces de esquemas y esquemas refinados relacionados con las preguntas como sugerencias de claridad. A continuación, se utilizan varias rondas de diálogo sobre sugerencias de texto a SQL como sugerencias de calibración, que se combinan con las sugerencias de claridad para guiar la generación de SQL. Las consultas SQL generadas se filtran mediante votaciones basadas en la coherencia y la ejecución para obtener el SQL final.
MAC-SQL[57] propuso un marco colaborativo multiagente; el proceso de texto a SQL se realiza en colaboración con agentes como selectores, descomponedores y refinadores. El selector guarda tablas relevantes para el problema del usuario; el descomponedor descompone el problema del usuario en subproblemas y proporciona soluciones; por último, el refinador valida y optimiza el SQL defectuoso.
DEA- SQL [58] introduce un paradigma de flujo de trabajo que pretende mejorar la atención y el alcance de la resolución de problemas del texto-a-SQL basado en LLM mediante la descomposición. El enfoque descompone la tarea global de forma que el módulo de generación SQL tiene sus correspondientes subtareas previas (determinación de la información, clasificación del problema) y posteriores (autocorrección, aprendizaje activo). El paradigma del flujo de trabajo permite a LLM generar consultas SQL más precisas.
SGU-SQL [ 32 ] es un marco de estructura a SQL que utiliza información estructural inherente para ayudar en la generación de SQL. En concreto, el marco construye estructuras de grafos para las preguntas de los usuarios y las bases de datos correspondientes, respectivamente, y luego utiliza grafos codificados para construir enlaces estructurales [105 , 106]. Los meta-operadores se utilizan para descomponer los problemas del usuario utilizando árboles de sintaxis, y finalmente los meta-operadores en SQL se utilizan para diseñar peticiones de entrada.
MetaSQL [ 59 ] introduce un enfoque de tres fases para la generación de SQL: descomposición, generación y clasificación. La fase de descomposición utiliza una combinación de descomposición semántica y metadatos para tratar los problemas del usuario. Utilizando los datos previamente procesados como entrada, se generan algunas consultas SQL candidatas utilizando el modelo de texto a SQL generado a partir de las condiciones de los metadatos. Por último, se aplica un proceso de clasificación en dos fases para obtener la consulta SQL óptima global.
PET-SQL [ 60 ] presenta un marco de dos etapas mejorado con pistas. En primer lugar, unas pistas bien diseñadas indican al LLM que genere SQL preliminar (PreSQL), en el que se seleccionan unas pocas demostraciones pequeñas basándose en la similitud. Después, se encuentran enlaces de esquemas basados en PreSQL y se combinan para pedir al LLM que genere SQL final (FinSQL). Por último, FinSQL se genera utilizando varios LLM para garantizar la coherencia basada en los resultados de ejecución.
Optimización C2-PromptAprendizaje de pocos minutos: Como se ha descrito anteriormente, el aprendizaje de pocos minutos para el cueing de LLMs ha sido ampliamente estudiado [85]. Para el aprendizaje texto-a-SQL (text-to-SQL) y contextual basado en LLMs, los métodos triviales de pocos minutos han dado resultados prometedores [8, 9, 33], y una mayor optimización de los hinting de pocos minutos tiene el potencial de mejorar el rendimiento. Dado que la precisión de la generación de SQL en los LLM comerciales depende en gran medida de la calidad de las pistas de entrada correspondientes [107], la investigación actual se ha centrado en muchos factores determinantes que afectan a la calidad de las pistas [9] (por ejemplo, la calidad y cantidad de la organización de las oligopistas, la similitud entre el problema del usuario y las instancias de las oligopistas, el conocimiento externo y las pistas).
DESEM [ 62 ] es un marco de ingeniería de pistas con des-semantización y recuperación de esqueletos. El marco emplea en primer lugar un módulo de enmascaramiento de palabras específico del dominio para eliminar los tokens semánticos que preservan la intención en las preguntas de los usuarios. A continuación, utiliza un módulo de sugerencias ajustable para recuperar un pequeño número de ejemplos con la misma intención que la pregunta, y combina esto con el filtrado de relevancia de patrones para guiar la generación de SQL para el LLM.
QDecomp [El marco introduce un mecanismo InterCOL que combina incrementalmente subproblemas descompuestos con nombres de tablas y columnas asociados. A través de la selección basada en la dificultad, un pequeño número de ejemplos de QDecomp son muestreados por dificultad. Además del muestreo de similitud-diversidad, [ 52 ] propuso la estrategia de muestreo SD+SA+Voting (similitud-diversidad+aumento de patrones+voting). Primero muestrearon un pequeño número de ejemplos usando similitud semántica y diversidad de agrupación k-Means, y después aumentaron las pistas usando conocimiento de patrones (aumento semántico o estructural).
C3 El marco de [ 30 ] consta de un componente de pista clara, que toma preguntas y esquemas como entrada para los LLM, y un componente de calibración que proporciona pistas, que genera una pista clara que incluye un esquema que elimina la información redundante no relacionada con la pregunta del usuario, y un enlace de esquema.Los LLM utilizan su composición como una pista mejorada por el contexto para la generación de SQL. El marco de mejora de la recuperación introduce sugerencias conscientes de la muestra [64], que simplifican el problema original y extraen el esqueleto del problema simplificado, y luego completan la recuperación de muestras en el repositorio basándose en la similitud de los esqueletos. Las muestras recuperadas se combinan con el problema original para obtener un pequeño número de pistas.
ODIS [54] introduce la selección de muestras mediante presentaciones fuera del dominio y datos sintéticos dentro del dominio, que recupera un pequeño número de presentaciones de una mezcla de fuentes para mejorar la caracterización de las señales.
DAIL- SQL[9] propuso un nuevo enfoque para abordar el problema del muestreo y la organización de un pequeño número de ejemplos, logrando un mejor equilibrio entre la calidad y la cantidad de un pequeño número de ejemplos.DAIL Selection enmascara primero el vocabulario específico del dominio de los usuarios y un pequeño número de problemas de ejemplo, y luego clasifica los ejemplos candidatos basándose en la distancia euclídea incrustada. Al mismo tiempo, se calcula la similitud entre las consultas SQL predichas. Por último, el mecanismo de selección obtiene ejemplos candidatos ordenados por similitud en función de criterios predefinidos. Con este enfoque, se garantiza que un pequeño número de ejemplos tengan una buena similitud tanto con el problema como con la consulta SQL.
ACT-SQL[49] presentó ejemplos dinámicos de selección basados en puntuaciones de similitud.
FUSED[65] propone construir un conjunto de presentaciones de alta diversidad a través de múltiples iteraciones de síntesis sin intervención manual para mejorar la diversidad de las presentaciones de pocos disparos. El proceso de FUSED muestrea las presentaciones que se van a fusionar mediante agrupación y, a continuación, fusiona las presentaciones muestreadas para construir un conjunto de presentaciones, mejorando así la eficacia del aprendizaje de pocos disparos.
Del conocimiento al SQL [31] El marco tiene como objetivo construir LLMs expertos en datos (DELLMs) para proporcionar conocimiento para la generación de SQL.
DELLM DELLM genera cuatro tipos de conocimiento y los métodos bien diseñados (p. ej., DAIL-SQL [9], MAC-SQL [57 ]) incorporan el conocimiento generado para lograr un mejor rendimiento del texto a SQL basado en LLM a través del aprendizaje contextual.
C3-Mejora del razonamiento:Los LLMs han demostrado buenas habilidades en tareas que implican razonamiento de sentido común, razonamiento simbólico y razonamiento aritmético [108]. En las tareas de conversión de texto a SQL, el razonamiento numérico y el razonamiento sinónimo aparecen a menudo en escenarios realistas [ 33 , 41 ].Las estrategias de sugerencia para el razonamiento con LLMs tienen el potencial de mejorar la generación de SQL. La investigación reciente se ha centrado en la integración de métodos de mejora del razonamiento bien diseñados para la adaptación de texto a SQL, la mejora de los LLM para hacer frente a los retos de problemas complejos que requieren un razonamiento sofisticado3 , y la autoconsistencia en la generación de SQL.
La técnica de sugerencia de Cadena de Pensamientos (CoT) [103] consiste en un proceso de razonamiento exhaustivo que guía al LLM hacia un razonamiento preciso y estimula su capacidad de razonamiento. Los estudios basados en LLM texto-a-SQL utilizan las sugerencias CoT como sugerencias de reglas [9], con instrucciones "pensemos paso a paso" establecidas en la construcción de la sugerencia [9, 32, 33, 51]. Sin embargo, la estrategia CoT directa (primitiva) para tareas de texto a SQL no ha mostrado el potencial que tiene para otras tareas de razonamiento; la investigación sobre la adaptación de CoT sigue en curso [51]. Dado que las sugerencias CoT siempre se demuestran utilizando ejemplos estáticos con anotaciones manuales, esto requiere un juicio empírico para seleccionar eficazmente un pequeño número de ejemplos para los que las anotaciones manuales son esenciales.
Como solución.ACT-SQL [ 49] propone un método para generar automáticamente ejemplos de CoT. En concreto, ACT-SQL, dado un problema, trunca el conjunto de rebanadas del problema y, a continuación, enumera cada columna que aparece en la consulta SQL correspondiente. Cada columna se asociará a su segmento más relevante mediante una función de similitud y se adjuntará a una sugerencia CoT.
QDecomp [51] A través de un estudio sistemático de la mejora de la generación de SQL para LLM junto con las sugerencias de CoT, se propone un marco novedoso para abordar el reto de cómo CoT propone pasos de razonamiento para predecir consultas SQL. El marco utiliza cada fragmento de una consulta SQL para construir los pasos lógicos del razonamiento CoT, y luego utiliza plantillas de lenguaje natural para elaborar cada fragmento de una consulta SQL y ordenarlos en el orden lógico de ejecución.
De menor a mayor [ 104 ] es otra técnica de sugerencia que divide el problema en subproblemas y luego los resuelve secuencialmente. Como sugerencia iterativa, los experimentos piloto [51] sugieren que este enfoque puede no ser necesario para el análisis sintáctico de texto a SQL. El uso de pasos de razonamiento detallados tiende a crear más problemas de propagación de errores.
Como variante de CoT, elPrograma de ideas (PdT)Se han propuesto estrategias de sugerencia [109] para mejorar el razonamiento aritmético del LLM.
Evaluando [55], PoT mejora los LLM generados por SQL, especialmente en conjuntos de datos complejos [33].
SQL-CRAFT [La política PoT requiere que el modelo genere tanto código Python como consultas SQL, forzando al modelo a incorporar código Python en su proceso de razonamiento.
Autoconsistencia[110] es una estrategia de sugerencia para mejorar el razonamiento LLM que explota la intuición de que un problema de razonamiento complejo típicamente permite múltiples formas diferentes de pensar para llegar a una respuesta únicamente correcta. En tareas de texto a SQL, la autoconsistencia se aplica al muestreo de un conjunto de diferentes SQLs y a la votación de SQLs consistentes a través de la retroalimentación de la ejecución [30 , 53 ].
Lo mismo digo.SD+SA+Voto [52] El marco rechaza los errores de ejecución identificados por un sistema de gestión de bases de datos (SGBD) determinista y selecciona la predicción que recibe la mayoría de los votos.
Además, impulsado por las recientes investigaciones sobre el uso de herramientas para ampliar la funcionalidad del LLM, elFUXI [66] se propone mejorar la generación de SQL para LLM invocando eficientemente herramientas bien diseñadas.
C4-Refinamiento de la ejecuciónEn el diseño de normas para la generación precisa de SQL, la prioridad es siempre que el SQL generado pueda ejecutarse con éxito y recuperar el contenido para responder correctamente a la pregunta del usuario [13]. Al tratarse de una tarea de programación compleja, generar un SQL correcto de una sola vez es todo un reto. Intuitivamente, considerar la retroalimentación/resultados de la ejecución durante la generación de SQL ayuda a alinearse con el entorno de base de datos correspondiente, permitiendo así al LLM recoger los posibles errores y resultados de la ejecución con el fin de refinar el SQL generado o tomar un voto mayoritario [30]. Los enfoques conscientes de la ejecución de texto a SQL incorporan la retroalimentación de la ejecución de dos formas principales:
1) Volver a generar opiniones con una segunda ronda de preguntasPor cada consulta SQL generada en la respuesta inicial, se ejecutará en la base de datos correspondiente para obtener información de la base de datos. Esta información puede consistir en errores o resultados que se añadirán a la segunda ronda de consultas. Aprendiendo esta información en contexto, LLM es capaz de refinar o regenerar el SQL original para mejorar la precisión.
2) Utilizar política de selección basada en la ejecución para SQL generadoPara ello, se muestrean múltiples consultas SQL generadas a partir del LLM y se ejecuta cada consulta en la base de datos. Basándose en el resultado de la ejecución de cada consulta SQL, se utiliza una estrategia de selección (por ejemplo, autoconsistencia, votación por mayoría [60]) para definir una consulta SQL del conjunto de SQL que satisfaga las condiciones como SQL final predicho.
MRC-EXEC [ 67 ] propusieron un marco de traducción de Lenguaje Natural a Código (NL2Code) con ejecución que clasifica cada consulta SQL muestreada y selecciona el ejemplo con el menor resultado de ejecución basado en el riesgo de Bayes [111].PALANCA [68] propone un método para validar NL2Code por ejecución, utilizando los módulos de generación y ejecución para recoger muestras del conjunto SQL y sus resultados de ejecución, respectivamente, y luego utilizando un validador de aprendizaje para emitir la probabilidad de corrección.
En una línea similar.AUTODEPURACIÓN [ 48] El marco también enseña a LLM a depurar su SQL predicho con un pequeño número de demostraciones. el modelo es capaz de corregir errores sin intervención humana investigando los resultados de ejecución e interpretando el SQL generado en lenguaje natural.
Como ya se ha mencionado, la implicación en dos fases se utilizó ampliamente para combinar un marco bien diseñado con la retroalimentación de la aplicación:1. muestreo de un conjunto de consultas SQL. 2. votación por mayoría (autoconsistente).Específicamente.C3[30] El marco elimina errores e identifica el SQL más coherente;El Retrieval Enhancement Framework [64] introduce cadenas de revisión dinámicasLa biblioteca SQL fue diseñada para ser un módulo autocorrectivo que combina mensajes de ejecución de grano fino con contenido de base de datos para pedir a los LLM que conviertan las consultas SQL generadas en interpretaciones de lenguaje natural; se pidió a los LLM que identificaran las lagunas semánticas y que modificaran su propio SQL generado.Aunque los métodos de filtrado de esquemas mejoran la generación de SQL, el SQL generado puede ser inejecutable.DESEM [62] fusionó una revisión fallback para abordar este problema; modifica y regenera las bibliotecas SQL basándose en diferentes tipos de errores y establece condiciones de terminación para evitar bucles. DIN-SQL [8] ideó sugerencias genéricas y suaves en su módulo de autocorrección; las sugerencias genéricas requieren que el LLM identifique y corrija los errores, y las suaves requieren que el modelo compruebe los problemas potenciales.
marco multiagenteMAC-SQL[57] incluye un agente de refinamiento que detecta y corrige automáticamente errores SQL, emplea clases de error y excepción SQLite para regenerar SQL corregido. ya que diferentes problemas pueden requerir diferentes números de revisiones.SQL-CRAFT [55] El marco introduce la calibración interactiva y el control automático del proceso de determinación para evitar la corrección excesiva o insuficiente. FUXI [66] considera la retroalimentación de errores en el razonamiento basado en herramientas para la generación de SQL. Del conocimiento al SQL [31] introdujo un marco de aprendizaje de preferencias que combina la retroalimentación de la ejecución de la base de datos con la optimización directa de preferencias [112] para mejorar el DELLM propuesto.PET-SQL[60] propuso la consistencia cruzada, que consiste en dos variantes: 1) votación simple: se ordena a múltiples LLMs que generen una consulta SQL, y luego se utiliza un voto mayoritario para decidir la SQL final basándose en los resultados de las diferentes ejecuciones, y 2) votación de grano fino: la votación simple se refina basándose en el nivel de dificultad para mitigar el sesgo de la votación.
B. Puesta a punto
Dado que el ajuste fino supervisado (SFT) es el enfoque dominante para entrenar LLMs [29, 91], para los LLMs de código abierto (por ejemplo, LLaMA-2 [94 ], Gemma [113]), la forma más directa de adaptar rápidamente el modelo a un dominio específico es realizar SFT en el modelo utilizando etiquetas de dominio recopiladas.La fase SFT suele ser la fase inicial de un marco de entrenamiento bien diseñado [112, 114], así como la fase de ajuste fino de texto a SQL. 114], así como la fase de ajuste fino de texto a SQL.El proceso de generación de auto-regresión para la consulta SQL Y puede formularse de la siguiente manera:

El enfoque SFT es también un método ficticio de ajuste fino para texto-a-SQL y ha sido ampliamente adoptado por varios LLM de código abierto en la investigación de texto-a-SQL [9, 10 , 46 ]. El paradigma de ajuste fino prefiere los puntos de partida de texto a SQL basados en LLM a los enfoques de aprendizaje contextual (ICL). Se han publicado varios estudios que exploran mejores métodos de ajuste fino. Los métodos de ajuste fino bien diseñados se clasifican en diferentes grupos según sus mecanismos, como se muestra en la Tabla IV:
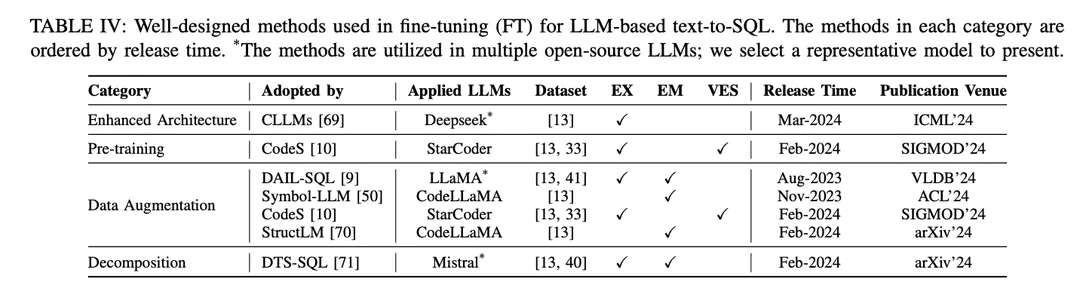
Arquitectura mejoradaEl marco ampliamente utilizado del Transformador Generativo Preentrenado (GPT, Generative Pretrained Transformer) utiliza una arquitectura de transformador sólo decodificador y la descodificación autorregresiva tradicional para generar texto. Estudios recientes sobre la eficiencia de los LLM han revelado un reto común: la latencia de los LLM es alta debido a la necesidad de incorporar un mecanismo de atención cuando se generan secuencias largas utilizando patrones autorregresivos [115 , 116 ]. En el text-to-SQL basado en LLM, la generación de consultas SQL es significativamente más lenta en comparación con el modelado del lenguaje tradicional [21 , 28 ], lo que se convierte en un reto para la construcción de NLIDBs locales eficientes. Como una de las soluciones, CLLM [ 69 ] pretende abordar los retos anteriores y acelerar la generación de SQL a través de una arquitectura de modelo mejorada.
Mejora de los datosEn el proceso de ajuste, el factor que más directamente afecta al rendimiento del modelo es la calidad de las etiquetas de entrenamiento [117]. El ajuste fino con baja calidad o falta de etiquetas de entrenamiento es una "obviedad", y el ajuste fino con datos de alta calidad o aumentados siempre supera a los métodos de ajuste fino bien diseñados con datos de baja calidad o sin procesar [29, 74]. Se han logrado avances sustanciales en el ajuste fino mejorado con datos de texto a SQL, centrándose en la mejora de la calidad de los datos en el proceso de SFT.
[117] "Aprendizaje a partir de etiquetas ruidosas con redes neuronales profundas: un estudio".[74] Avances recientes en la conversión de texto a SQL: estudio de lo que tenemos y de lo que esperamos[29] "Un estudio de los grandes modelos lingüísticos"DAIL-SQL [9] está diseñado como un marco de aprendizaje contextual que utiliza una estrategia de muestreo para obtener mejor un menor número de instancias de muestra. La incorporación de instancias muestreadas en el proceso de SFT mejora el rendimiento del LLM de código abierto.Symbol-LLM [50] propone instrucciones de aumento de datos ajustadas a las fases de inyección e infusión.CodeS [10] mejora los datos de entrenamiento mediante la generación bidireccional con la ayuda de ChatGPT.StructLM [70] se entrena en múltiples tareas de conocimiento estructural para mejorar la capacidad global.
formación previaPre-entrenamiento: El pre-entrenamiento es la etapa fundamental de todo el proceso de puesta a punto, cuyo objetivo es obtener capacidades de generación de texto a través del entrenamiento automático por regresión sobre una gran cantidad de datos [118]. Tradicionalmente, los potentes LLM propietarios actuales (por ejemplo, ChatGPT [119], GPT-4 [86], Claude [120]) se preentrenan en corpus híbridos, que se benefician principalmente de escenarios de diálogo que muestran capacidades de generación de texto [85]. Los LLM específicos de código (por ejemplo, CodeLLaMA [ 121 ], StarCoder [ 122 ]) se preentrenan sobre datos de código [100 ], y la mezcla de varios lenguajes de programación permite a los LLM generar código que se ajuste a las instrucciones del usuario [123 ]. El principal reto para las técnicas de preentrenamiento dirigidas a SQL como una subtarea de la generación de código es que el contenido relacionado con SQL/base de datos es sólo una pequeña parte de todo el corpus preentrenado.
Como resultado, los LLM de código abierto con capacidades de síntesis relativamente limitadas (en comparación con ChatGPT, GPT-4) no comprenden bien cómo transformar problemas NL en SQL durante el preentrenamiento.La fase de preentrenamiento del modelo CodeS [10] consta de tres etapas de preentrenamiento incremental. Partiendo del LLM básico específico del código [122 ], CodeS realiza un preentrenamiento incremental en un corpus de entrenamiento mixto (que incluye datos relacionados con SQL, datos de NL a código y datos relacionados con NL). La comprensión de texto a SQL y el rendimiento mejoran significativamente.
descomposiciónLa descomposición de una tarea en múltiples pasos o el uso de múltiples modelos para resolver la tarea es una solución intuitiva para resolver escenarios complejos, como muestra el paradigma ICL, introducido anteriormente en el Capítulo IV-A. Los modelos propietarios utilizados en los enfoques basados en ICL tienen un gran número de parámetros, que se encuentran en un nivel de parámetros diferente al de los modelos de código abierto utilizados en los enfoques de ajuste fino. Estos modelos son inherentemente capaces de realizar bien las subtareas asignadas (mediante mecanismos como el aprendizaje con menos muestras) [30, 57]. Por lo tanto, para replicar el éxito de este paradigma en un enfoque ICL, es importante asignar racionalmente las subtareas apropiadas (por ejemplo, generar conocimiento externo, vincular esquemas y refinar esquemas) a los modelos de código abierto con el fin de afinarlos para las subtareas específicas, y construir los datos apropiados para su uso en el afinamiento para ayudar en la generación del SQL final.
DTS-SQL [71] propone una descomposición en dos etapas del marco de ajuste fino de texto a SQL y diseña una tarea de pregeneración de enlaces de esquemas antes de la generación final de SQL.
cuenta
A pesar de los importantes avances en la investigación sobre la conversión de texto a SQL, aún quedan algunos retos por resolver. En esta sección se analizan los retos pendientes que se espera superar en futuros trabajos.
A. Robustez en aplicaciones prácticas
Text-to-SQL, implementado por LLMs, mantiene la promesa de generalidad y robustez en escenarios de aplicaciones complejas del mundo real. A pesar de los recientes avances sustanciales en conjuntos de datos específicos de robustez [ 37 , 41], su rendimiento aún no es suficiente para las aplicaciones del mundo real [ 33]. Aún quedan algunos retos por superar en futuras investigaciones. Desde el punto de vista del usuario, se da el fenómeno de que el usuario no siempre formula preguntas explícitamente, lo que significa que la pregunta del usuario puede no tener los valores exactos de la base de datos o puede ser diferente del conjunto de datos estándar, en el que pueden incluirse sinónimos, faltas de ortografía y expresiones difusas [40].
Por ejemplo, en el paradigma del ajuste fino, el modelo se entrena en problemas explícitamente indicativos con representaciones concretas. Dado que el modelo no aprende el mapeo de los problemas del mundo real a las bases de datos correspondientes, existe una laguna de conocimiento cuando se aplica a escenarios del mundo real [33]. Como se indica en las evaluaciones correspondientes sobre conjuntos de datos con sinónimos e instrucciones incompletas [7 , 51], las consultas SQL generadas por ChatGPT contienen alrededor de 40% de ejecuciones incorrectas, lo que supone 10% menos que en la evaluación original [51]. Al mismo tiempo, el ajuste fino mediante texto nativo a conjuntos de datos SQL puede contener muestras y etiquetas no estandarizadas. Por ejemplo, los nombres de tablas o columnas no siempre son representaciones exactas de su contenido, lo que provoca incoherencias en la construcción de los datos de entrenamiento.
B. Eficacia informática
La eficiencia computacional viene determinada por la velocidad de razonamiento y el coste de los recursos computacionales, algo que merece la pena tener en cuenta tanto en las aplicaciones como en los esfuerzos de investigación [49, 69]. Con el aumento de la complejidad de las bases de datos en las últimas evaluaciones comparativas de texto a SQL [15, 33], las bases de datos contendrán más información (incluidas más tablas y columnas) y la longitud de los tokens del esquema de la base de datos aumentará en consecuencia, lo que plantea una serie de retos. Cuando se trabaja con bases de datos ultracomplejas, utilizar el esquema correspondiente como entrada puede plantear el reto de que el coste de invocar LLM propietarios aumentará significativamente, pudiendo superar la longitud máxima de token del modelo, especialmente cuando se implementan modelos de código abierto con longitudes de contexto cortas.
Mientras tanto, otro reto obvio es que la mayoría de los estudios utilizan patrones completos como entradas del modelo, lo que introduce una gran cantidad de redundancia [57]. Proporcionar al LLM los patrones filtrados exactos relevantes para el problema directamente desde el lado del usuario para reducir el coste y la redundancia es una solución potencial para mejorar la eficiencia computacional [30]. El diseño de un método preciso de filtrado de patrones sigue siendo una dirección futura. Aunque el paradigma del aprendizaje contextual ha logrado una precisión prometedora, los marcos multietapa bien diseñados o los métodos contextuales ampliados aumentan el número de llamadas a la API, lo que mejora el rendimiento desde el punto de vista de la eficiencia computacional, pero también conlleva un aumento significativo del coste [8].
En los enfoques relacionados [49], la compensación entre rendimiento y eficiencia computacional debe considerarse cuidadosamente, y el diseño de un enfoque de aprendizaje contextual comparable (o incluso mejor) con un coste de interfaz de programación de aplicaciones más bajo sería una implementación práctica que aún se está explorando. En comparación con los enfoques basados en PLM, los enfoques basados en LLM tienen un razonamiento significativamente más lento [ 21, 28]. Acelerar el razonamiento acortando la longitud de la entrada y reduciendo el número de etapas en el proceso de implementación es intuitivo para el paradigma de aprendizaje contextual. Para el LLM local, desde el punto de partida [69], se pueden investigar más estrategias de aceleración para mejorar la arquitectura del modelo en futuras exploraciones.
Para hacer frente a este reto, el ajuste del LLM al sesgo intencional y el diseño de estrategias de entrenamiento para escenarios ruidosos beneficiarían los avances recientes. Mientras tanto, la cantidad de datos en las aplicaciones del mundo real es relativamente menor que la de los puntos de referencia basados en la investigación. Dado que el escalado de una gran cantidad de datos mediante anotación manual conlleva elevados costes de mano de obra, el diseño de métodos de expansión de datos para obtener más pares pregunta-SQL proporcionará apoyo a los LLM cuando los datos sean escasos. Además, el ajuste fino del LLM de código abierto para estudios de adaptación local en conjuntos de datos a pequeña escala es potencialmente beneficioso. Además, las extensiones para escenarios multilingües [ 42 , 124 ] y multimodales [ 125 ] deberían investigarse exhaustivamente en futuras investigaciones, lo que beneficiaría a más comunidades lingüísticas y ayudaría a construir interfaces de bases de datos más generales.
C. Privacidad e interpretabilidad de los datos
Como parte de la investigación LLM, el texto-a-SQL basado en LLM también se enfrenta a algunos retos generales que existen en la investigación LLM [4 , 126 , 127 ]. Desde una perspectiva texto-a-SQL, estos retos también conducen a mejoras potenciales que pueden beneficiar enormemente la investigación LLM. Como se mencionó anteriormente en el Capítulo IV-A, los paradigmas de aprendizaje contextual han dominado la investigación reciente tanto en términos de volumen como de rendimiento, y la mayor parte del trabajo se ha implementado utilizando modelos propios [8, 9]. Se plantea un reto inmediato en términos de privacidad de los datos, ya que invocar APIs propietarias para gestionar la confidencialidad de las bases de datos locales puede suponer un riesgo de fuga de datos. El uso de paradigmas de ajuste local puede resolver parcialmente este problema.
No obstante, el rendimiento del ajuste fino de vainilla es actualmente subóptimo [9], y los marcos de ajuste fino avanzados pueden depender de LLM propios para el aumento de datos [10]. Teniendo en cuenta el estado actual de las cosas, merece la pena prestar más atención a marcos más adaptados al paradigma de ajuste fino local de texto a SQL. En general, el desarrollo del aprendizaje profundo siempre se ha enfrentado a retos en términos de interpretabilidad [127 , 128 ].
Como desafío de larga data, se ha llevado a cabo una gran cantidad de investigación para abordar esta cuestión [ 129 , 130 ]. Sin embargo, la interpretabilidad de las implementaciones basadas en LLM sigue sin discutirse en la investigación texto-a-SQL, ya sea en paradigmas de aprendizaje contextual o de ajuste fino. Los enfoques con fases de descomposición explican las implementaciones de texto a SQL desde una perspectiva de generación por pasos [8, 51]. A partir de ahí, la combinación de la investigación avanzada en interpretabilidad [131, 132] para mejorar el rendimiento de text-to-SQL y la explicación de las arquitecturas de modelos locales en términos de conocimiento de bases de datos sigue siendo una dirección futura.
D. Expansión
Como subcampo de la investigación en LLM y comprensión del lenguaje natural, gran parte de la investigación en estas áreas se ha visto impulsada por el uso de tareas texto-a-SQL [103 , 110 ]. Sin embargo, la investigación texto-a-SQL también puede extenderse a una investigación más amplia en estas áreas. Por ejemplo, la generación de SQL forma parte de la generación de código. Los métodos de generación de código bien diseñados también pueden lograr un buen rendimiento en la conversión de texto a SQL [48, 68] y pueden generalizarse a una amplia gama de lenguajes de programación. También se puede discutir la posibilidad de ampliar algunos marcos personalizados de texto a SQL a estudios de NL a código.
Por ejemplo, los marcos que integran la salida de ejecución en NL-to-code también consiguen un rendimiento excelente en la generación de SQL [8]. Merece la pena debatir los intentos de ampliar el enfoque consciente de la ejecución en text-to-SQL con otros módulos de avance [30, 31] a la generación de código. Desde otra perspectiva, se discutió previamente que el texto-a-SQL puede mejorar la respuesta a preguntas (QA) basada en LLM proporcionando información factual. Las bases de datos pueden almacenar conocimiento relacional como información estructural, y la GC basada en estructuras puede beneficiarse de la conversión de texto a SQL (por ejemplo, la respuesta a preguntas basada en el conocimiento, KBQA [ 133 , 134 ]). Utilizar estructuras de bases de datos para construir conocimiento factual y luego combinarlo con un sistema de texto a SQL para permitir la recuperación de información tiene el potencial de ayudar a la GC a obtener un conocimiento factual más preciso [ 135 ]. Se espera que en el futuro se lleven a cabo más investigaciones sobre la conversión de texto a SQL.
Presentación del producto Asistente de Inteligencia Digital OlaChat

El Asistente de Inteligencia Digital OlaChat es un nuevo producto de análisis inteligente de datos lanzado por el Departamento de Plataforma de Big Data PCG de Tencent que utiliza grandes modelos en el campo del análisis de datos en la práctica del aterrizaje, y se ha integrado en DataTalk, OlaIDE y otras plataformas de datos principales internas de Tencent, para proporcionar soporte inteligente para todo el proceso de escenarios de análisis de datos. Contiene una serie de capacidades como text2sql, análisis de indicadores, optimización inteligente de SQL, etc. Desde el análisis de datos (análisis de arrastrar y soltar, consulta SQL), visualización de datos, hasta la interpretación y atribución de resultados, ¡OlaChat ayuda de forma integral a que el trabajo de análisis de datos sea más sencillo y eficiente!
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...