
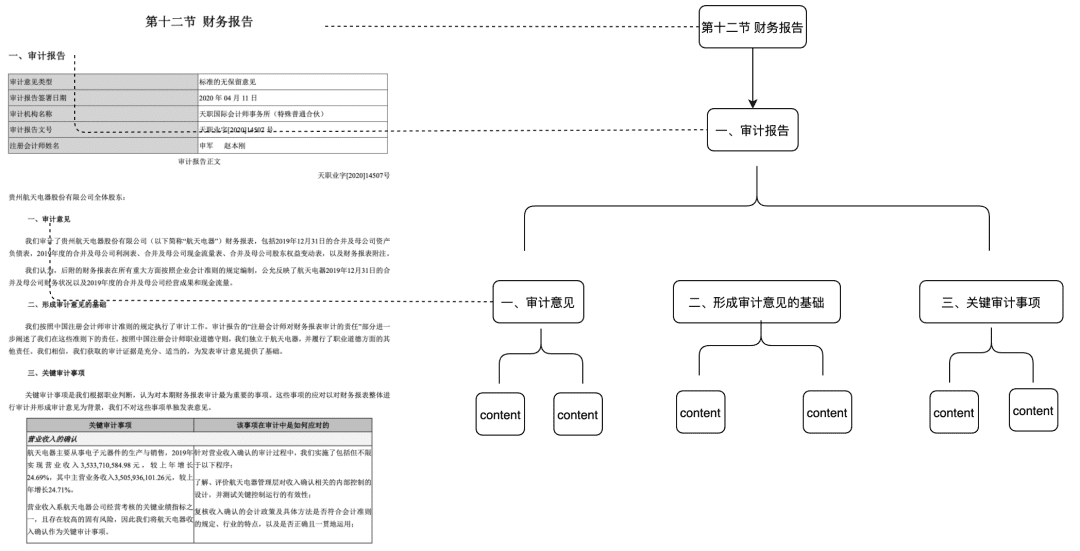
Un artículo de 10.000 palabras sobre la optimización RAG en escenarios reales DB-GPT.
Base de conocimientos de IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 38.5K 00

prólogo
En los dos últimos años, la tecnología de Recuperación-Generación Aumentada (RAG, Retrieval-Augmented Generation) se ha convertido gradualmente en un componente esencial de las inteligencias mejoradas. Al combinar las capacidades duales de recuperación y generación, la RAG es capaz de introducir conocimientos externos, ofreciendo así más posibilidades para la aplicación de grandes modelos en escenarios complejos. Sin embargo, en escenarios prácticos de aterrizaje, a menudo se presentan problemas de baja precisión de recuperación, interferencia de ruido, exhaustividad de la memoria e insuficiente profesionalidad, lo que conduce a graves ilusiones de LLM. En este artículo nos centraremos en los detalles del procesamiento del conocimiento y la recuperación de la RAG en escenarios de aterrizaje reales, en cómo optimizar el enlace Pineline de la RAG y, en última instancia, en mejorar la precisión de la recuperación.
Es fácil crear rápidamente una aplicación inteligente de preguntas y respuestas RAG, pero aplicarla en un escenario empresarial real requiere mucha preparación.
1.RAG Clave de proceso Interpretación del código fuente
centroprocesamiento del conocimientoresponder cantandoRAGAlgunos de los procesos clave:
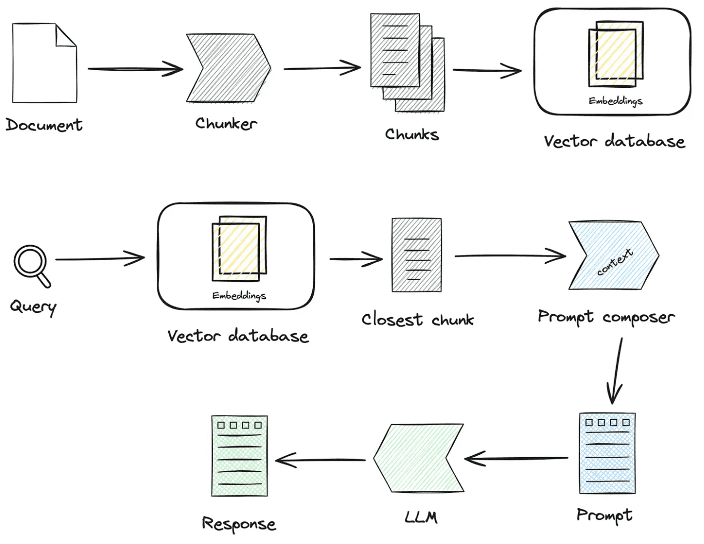
1. Tratamiento de los conocimientos
Carga de conocimientos -> Troceado de conocimientos -> Extracción de información -> Tratamiento de conocimientos (incrustación/grafiado/palabras clave) -> Almacenamiento de conocimientos
- Carga de conocimientos
# 知识工厂进行实例化 KnowledgeFactory -> create() -> load() -> Document - knowledge - markdown - pdf - docx - txt - html - pptx - url - ...
Cómo ampliarlo:
from abc import ABC from typing import List, Any class Knowledge(ABC): def load(self) -> List[Document]: """Load knowledge from data loader.""" pass @classmethod def document_type(cls) -> Any: """Get document type.""" pass @classmethod def support_chunk_strategy(cls) -> List[ChunkStrategy]: """Return supported chunk strategy.""" return [ ChunkStrategy.CHUNK_BY_SIZE, ChunkStrategy.CHUNK_BY_PAGE, ChunkStrategy.CHUNK_BY_PARAGRAPH, ChunkStrategy.CHUNK_BY_MARKDOWN_HEADER, ChunkStrategy.CHUNK_BY_SEPARATOR, ] @classmethod def default_chunk_strategy(cls) -> ChunkStrategy: """ Return default chunk strategy. Returns: ChunkStrategy: default chunk strategy """ return ChunkStrategy.CHUNK_BY_SIZE
- parcela de conocimiento
ChunkManager: Enruta los datos de conocimiento cargados al procesador de trozos correspondiente para su asignación en función de la política de troceo y los parámetros de troceo especificados por el usuario.
class ChunkManager: """Manager for chunks.""" def __init__( self, knowledge: Knowledge, chunk_parameter: Optional[ChunkParameters] = None, extractor: Optional[Extractor] = None, ): """ Create a new ChunkManager with the given knowledge. Args: knowledge: (Knowledge) Knowledge datasource. chunk_parameter: (Optional[ChunkParameters]) Chunk parameter. extractor: (Optional[Extractor]) Extractor to use for summarization. """ self._knowledge = knowledge self._extractor = extractor self._chunk_parameters = chunk_parameter or ChunkParameters() self._chunk_strategy = ( chunk_parameter.chunk_strategy if chunk_parameter and chunk_parameter.chunk_strategy else self._knowledge.default_chunk_strategy().name ) self._text_splitter = self._chunk_parameters.text_splitter self._splitter_type = self._chunk_parameters.splitter_type
Cómo ampliar: si desea personalizar una nueva estrategia de corte en la interfaz
- Nueva estrategia de corte
- Nueva lógica de implementación de Splitter
class ChunkStrategy(Enum):
"""Chunk Strategy Enum."""
CHUNK_BY_SIZE: _STRATEGY_ENUM_TYPE = (
RecursiveCharacterTextSplitter,
[
{
"param_name": "chunk_size",
"param_type": "int",
"default_value": 512,
"description": "The size of the data chunks used in processing.",
},
{
"param_name": "chunk_overlap",
"param_type": "int",
"default_value": 50,
"description": "The amount of overlap between adjacent data chunks.",
},
],
"chunk size",
"split document by chunk size",
)
CHUNK_BY_PAGE: _STRATEGY_ENUM_TYPE = (
PageTextSplitter,
[],
"page",
"split document by page",
)
CHUNK_BY_PARAGRAPH: _STRATEGY_ENUM_TYPE = (
ParagraphTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "paragraph separator",
}
],
"paragraph",
"split document by paragraph",
)
CHUNK_BY_SEPARATOR: _STRATEGY_ENUM_TYPE = (
SeparatorTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "chunk separator",
},
{
"param_name": "enable_merge",
"param_type": "boolean",
"default_value": False,
"description": (
"Whether to merge according to the chunk_size after "
"splitting by the separator."
),
},
],
"separator",
"split document by separator",
)
CHUNK_BY_MARKDOWN_HEADER: _STRATEGY_ENUM_TYPE = (
MarkdownHeaderTextSplitter,
[],
"markdown header",
"split document by markdown header",
)
- Extracción de conocimientos
- Extracción vectorial -> incrustación, aplicación
Embeddingsconector
@abstractmethod def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed search docs.""" @abstractmethod def embed_query(self, text: str) -> List[float]: """Embed query text.""" async def aembed_documents(self, texts: List[str]) -> List[List[float]]: """Asynchronous Embed search docs.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_documents, texts ) async def aembed_query(self, text: str) -> List[float]: """Asynchronous Embed query text.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_query, text )
# EMBEDDING_MODEL=proxy_openai
# proxy_openai_proxy_server_url=https://api.openai.com/v1
# proxy_openai_proxy_api_key={your-openai-sk}
# proxy_openai_proxy_backend=text-embedding-ada-002
## qwen embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_tongyi
# proxy_tongyi_proxy_backend=text-embedding-v1
# proxy_tongyi_proxy_api_key={your-api-key}
## qianfan embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_qianfan
# proxy_qianfan_proxy_backend=bge-large-zh
# proxy_qianfan_proxy_api_key={your-api-key}
# proxy_qianfan_proxy_api_secret={your-secret-key}
- Extracción del grafo de conocimiento -> grafo de conocimiento
class TripletExtractor(LLMExtractor):
"""TripletExtractor class."""
def __init__(self, llm_client: LLMClient, model_name: str):
"""Initialize the TripletExtractor."""
super().__init__(llm_client, model_name, TRIPLET_EXTRACT_PT)
TRIPLET_EXTRACT_PT = (
"Some text is provided below. Given the text, "
"extract up to knowledge triplets as more as possible "
"in the form of (subject, predicate, object).\n"
"Avoid stopwords. The subject, predicate, object can not be none.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Alice has 2 apples.\n"
"Triplets:\n(Alice, has 2, apple)\n"
"Text: Alice was given 1 apple by Bob.\n"
"Triplets:(Bob, gives 1 apple, Alice)\n"
"Text: Alice was pushed by Bob.\n"
"Triplets:(Bob, pushes, Alice)\n"
"Text: Bob's mother Alice has 2 apples.\n"
"Triplets:\n(Alice, is mother of, Bob)\n(Alice, has 2, apple)\n"
"Text: A Big monkey climbed up the tall fruit tree and picked 3 peaches.\n"
"Triplets:\n(monkey, climbed up, fruit tree)\n(monkey, picked 3, peach)\n"
"Text: Alice has 2 apples, she gives 1 to Bob.\n"
"Triplets:\n"
"(Alice, has 2, apple)\n(Alice, gives 1 apple, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
)
- Extracción inversa de índices -> segmentación de palabras clave
- Puede utilizar el léxico por defecto de es, o puede personalizar el léxico utilizando el modo plugin de es.
- Extracción inversa de índices -> segmentación de palabras clave
- Almacenamiento de conocimientos
Toda la persistencia del conocimiento se consigue de manera uniformeIndexStoreBaseofrece actualmente tres tipos de implementaciones: bases de datos vectoriales, bases de datos gráficos e indexación de texto completo.

- VectorStore, la lógica principal de la base de datos vectorial se encuentra en load_document(), incluyendo la creación del esquema del índice, la escritura por lotes de datos vectoriales, etc.
# Base class hierarchy - VectorStoreBase - ChromaStore - MilvusStore - OceanbaseStore - ElasticsearchStore - PGVectorStore # Base class definition class VectorStoreBase(IndexStoreBase, ABC): """ Vector store base class. """ @abstractmethod def load_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database. """ pass @abstractmethod async def aload_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database asynchronously. """ pass @abstractmethod def similar_search_with_scores( self, text: str, topk: int, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search with scores in the index database. """ pass def similar_search( self, text: str, topk: int, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search in the index database. """ return self.similar_search_with_scores(text, topk, 1.0, filters)
- GraphStore , el almacén de grafos específico proporciona una implementación de escritura ternaria, que generalmente se realiza llamando al lenguaje de consulta de la base de datos de grafos específica. Por ejemplo
TuGraphStoreSe generará y ejecutará una sentencia Cypher específica basada en el ternario.
- La interfaz de almacenamiento de grafos GraphStoreBase proporciona una abstracción unificada para el almacenamiento de grafos y, en la actualidad, tiene incorporado
MemoryGraphStoreresponder cantandoTuGraphStoretambién proporcionamos la interfaz Neo4j a los desarrolladores para que puedan acceder a ella.
- La interfaz de almacenamiento de grafos GraphStoreBase proporciona una abstracción unificada para el almacenamiento de grafos y, en la actualidad, tiene incorporado
# GraphStoreBase -> TuGraphStore -> Neo4jStore
def insert_triplet(self, subj: str, rel: str, obj: str) -> None:
"""Add triplet."""
# Create queries to merge nodes and relationship
subj_query = f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
obj_query = f"MERGE (n2:{self._node_label} {{id:'{obj}'}})"
rel_query = (
f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
f"-[r:{self._edge_label} {{id:'{rel}'}}]->"
f"(n2:{self._node_label} {{id:'{obj}'}})"
)
# Execute queries
self.conn.run(query=subj_query)
self.conn.run(query=obj_query)
self.conn.run(query=rel_query)
- FullTextStore: mediante la creación de un índice es, a través del algoritmo de división de palabras incorporado en es para la división de palabras y, a continuación, mediante es para crear un índice invertido palabra clave->doc_id.
{
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
},
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": self._k1,
"b": self._b
}
}
}
self._es_mappings = {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25"
},
"metadata": {
"type": "keyword"
}
}
}
# FullTextStoreBase
# ElasticDocumentStore
# OpenSearchStore
2. Recuperación de conocimientos
pregunta -> reescritura -> búsqueda_similar -> clasificación -> contexto_candidatos
El siguiente paso es la recuperación del conocimiento, la lógica actual de recuperación de la comunidad se divide principalmente en estos pasos, si se establecen los parámetros de reescritura de consulta, actualmente se le dará una ronda de reescritura de preguntas a través del modelo grande, y luego se dirigirá al recuperador correspondiente de acuerdo a su forma de procesamiento del conocimiento, si se procesa a través de los vectores, se recuperará a través del EmbeddingRetriever, si se construye de manera se construye a través de grafos de conocimiento, se recuperará de acuerdo con el modo de grafos de conocimiento, si se configura el modelo rerank, dará a los valores candidatos después de un cribado grueso un cribado fino para hacer que los valores candidatos sean más relevantes para la pregunta del usuario.
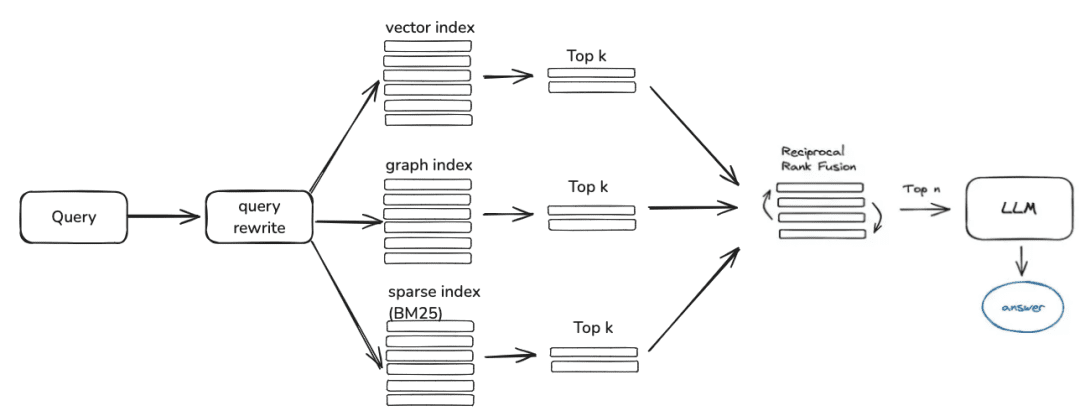
- EmbeddingRetriever
class EmbeddingRetriever(BaseRetriever): """Embedding retriever.""" def __init__( self, index_store: IndexStoreBase, top_k: int = 4, query_rewrite: Optional[QueryRewrite] = None, rerank: Optional[Ranker] = None, retrieve_strategy: Optional[RetrieverStrategy] = RetrieverStrategy.EMBEDDING, ): pass async def _aretrieve_with_score( self, query: str, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Retrieve knowledge chunks with score. Args: query (str): Query text. score_threshold (float): Score threshold. filters: Metadata filters. Returns: List[Chunk]: List of chunks with score. """ queries = [query] new_queries = await self._query_rewrite.rewrite( origin_query=query, context=context, nums=1 ) queries.extend(new_queries) candidates_with_score = [ self._similarity_search_with_score( query, score_threshold, filters, root_tracer.get_current_span_id() ) for query in queries ] new_candidates_with_score = await self._rerank.arank( new_candidates_with_score, query ) return new_candidates_with_score
- index_store: base de datos vectorial específica
- top_k: El número de trozos candidatos devueltos.
- query_rewrite: función de reescritura de consultas
- rerank: función de reordenación
- consulta:Consulta original
- score_threshold: puntuación, por defecto filtramos los contextos con una puntuación de similitud inferior al umbral.
- filtros:
Optional[MetadataFilters]El filtro de información de metadatos se puede utilizar principalmente para filtrar la información de atributos y descartar información candidata no coincidente.
from enum import Enum from typing import Union, List from pydantic import BaseModel, Field class FilterCondition(str, Enum): """Vector Store Meta data filter conditions.""" AND = "and" OR = "or" class MetadataFilter(BaseModel): """Meta data filter.""" key: str = Field( ..., description="The key of metadata to filter." ) operator: FilterOperator = Field( default=FilterOperator.EQ, description="The operator of metadata filter." ) value: Union[str, int, float, List[str], List[int], List[float]] = Field( ..., description="The value of metadata to filter." )
- Gráfico RAG
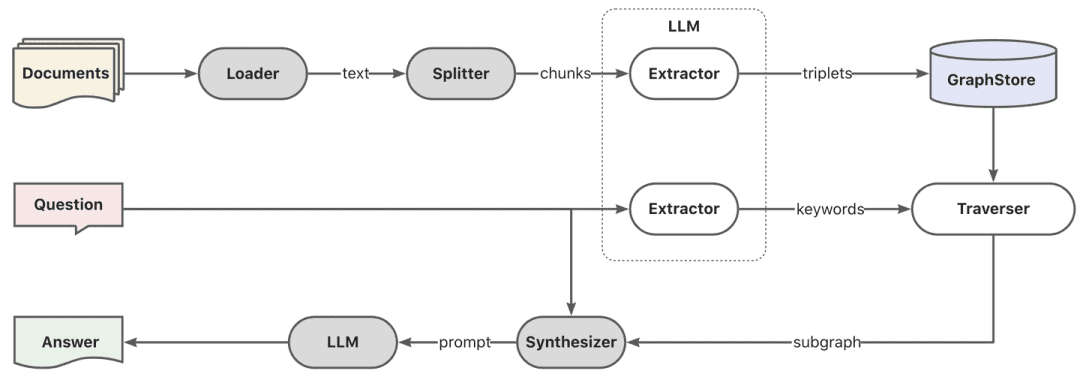
En primer lugar, la extracción de palabras clave se lleva a cabo a través del modelo, aquí se puede hacer a través de la técnica nlp tradicional para la división de palabras, o a través del gran modelo para la división de palabras, y luego las palabras clave se hacen de acuerdo con los sinónimos para hacer la expansión, para encontrar la lista de candidatos de palabras clave, y es mejor llamar al método de exploración para recordar los subgrafos locales de acuerdo con la lista de candidatos de palabras clave.
KEYWORD_EXTRACT_PT = (
"A question is provided below. Given the question, extract up to "
"keywords from the text. Focus on extracting the keywords that we can use "
"to best lookup answers to the question.\n"
"Generate as more as possible synonyms or alias of the keywords "
"considering possible cases of capitalization, pluralization, "
"common expressions, etc.\n"
"Avoid stopwords.\n"
"Provide the keywords and synonyms in comma-separated format."
"Formatted keywords and synonyms text should be separated by a semicolon.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Keywords:\nAlice,mother,Bob;mummy\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Keywords:\nPhilz,coffee shop,Berkeley,1982;coffee bar,coffee house\n"
"---------------------\n"
"Text: {text}\n"
"Keywords:\n"
)
def explore(
self,
subs: List[str],
direct: Direction = Direction.BOTH,
depth: Optional[int] = None,
fan: Optional[int] = None,
limit: Optional[int] = None,
) -> Graph:
"""Explore on graph."""
DBSchemaRetrieverSe trata en parte de una búsqueda de enlaces de esquema para escenarios ChatDataPrincipalmente a través de la forma de vinculación de esquemas mediante la recuperación de similitudes en dos etapas, primero se encuentra la tabla más relevante y después la información de campo más relevante.
Pros: esta búsqueda en dos fases también pretende responder a los comentarios de la comunidad sobre la experiencia de la gran mesa ancha.
def _similarity_search(self, query, filters: Optional[MetadataFilters] = None) -> List[Chunk]:
"""Similar search."""
# Perform similarity search with scores
table_chunks = self._table_vector_store_connector.similar_search_with_scores(
query, self._top_k, 0, filters
)
# Filter out chunks with 'separated' metadata
not_sep_chunks = [
chunk for chunk in table_chunks if not chunk.metadata.get("separated")
]
separated_chunks = [
chunk for chunk in table_chunks if chunk.metadata.get("separated")
]
# If no separated chunks, return the non-separated chunks
if not separated_chunks:
return not_sep_chunks
# Create tasks list for retrieving fields from separated chunks
tasks = [
lambda c=chunk: self._retrieve_field(c, query) for chunk in separated_chunks
]
# Run tasks concurrently with a concurrency limit of 3
separated_result = run_tasks(tasks, concurrency_limit=3)
# Combine and return results
return not_sep_chunks + separated_result
- table_vector_store_connector: responsable de recuperar la tabla más relevante.
- field_vector_store_connector: responsable de recuperar los campos más relevantes.
2. Tratamiento del conocimiento, ideas de optimización de la recuperación del conocimiento
Actualmente, las aplicaciones de cuestionarios inteligentes RAG presentan varios puntos débiles:
- A medida que aumenta el número de documentos en la base de conocimientos, la búsqueda se vuelve ruidosa y la precisión de la recuperación no es alta.
- Recuperaciones incompletas y falta de exhaustividad
- El recuerdo y la intención de pregunta del usuario tienen poca relevancia
- Poder responder sólo a datos estáticos y no poder acceder al conocimiento de forma dinámica conduce a una aplicación de respuesta aburrida y muda.
1. Optimización del tratamiento del conocimiento
El tratamiento de datos no estructurados/semiestructurados/estructurados está listo para determinar el límite superior de la aplicación de la GAR, por lo que, en primer lugar, es necesario realizar un gran trabajo de ETL de grano fino en el tratamiento del conocimiento, la etapa de indexación y la optimización principal de la dirección de la idea:
- No estructurado -> Estructurado: organizar la información del conocimiento de forma estructurada.
- Extraer información semántica más rica y diversa.
1.1 Carga de conocimientos
Finalidad: Se necesita un análisis sintáctico preciso de los documentos para identificar distintos tipos de datos de forma más diversificada.
Recomendaciones de optimización:
- Se recomienda que docx, txt u otro texto antes de procesar para el formato pdf o markdown, para que pueda utilizar algunas herramientas de reconocimiento para extraer mejor el contenido del texto.
- Extrae la información de una tabla a partir de un texto.
- Conservar la información de la jerarquía de títulos de markdown y pdf para el próximo árbol de relaciones jerárquicas y otros métodos de indexación que se preparen.
- Conserva enlaces de imágenes, fórmulas y otra información, también procesada uniformemente en formato markdown.
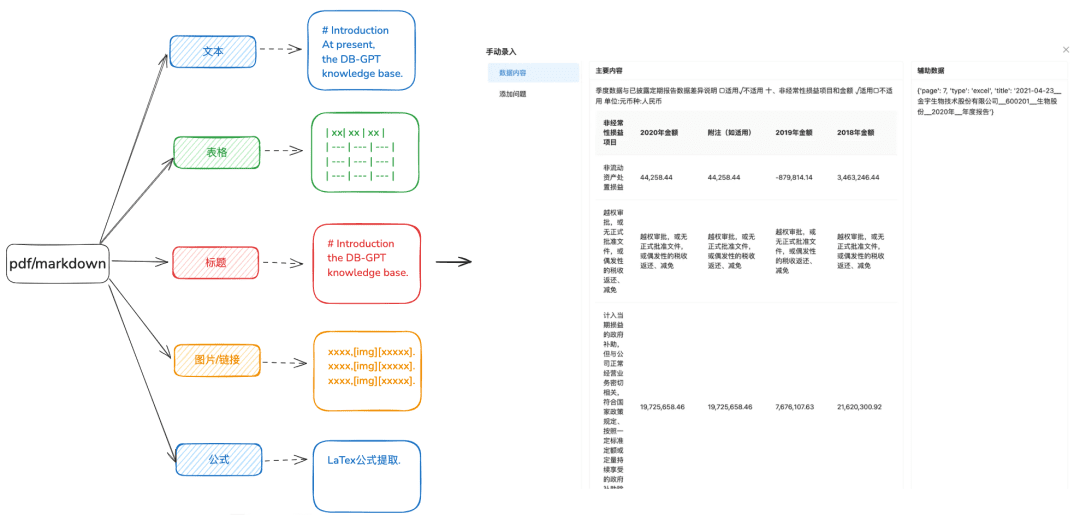
1.2 Corte el trozo lo más intacto posible
Finalidad: Preservar la integridad y pertinencia contextuales, que están directamente relacionadas con la precisión de las respuestas.
Dentro de los límites contextuales del modelo general, la fragmentación garantiza que el texto introducido en los LLM no supere los límites de tokens.
Recomendaciones de optimización:
- Imágenes + Tablas extraídas como Chunks separados, manteniendo los pies de tabla y de imagen en los metadatos
- El contenido del documento se divide en la medida de lo posible según la jerarquía del encabezado o Markdown Header, preservando la integridad del chunk en la medida de lo posible.
- Si hay un separador personalizado, puede cortar y dividir por el separador personalizado.
1.3 Extracción de información diversificada
Además de la extracción de vectores de incrustación de documentos, otra extracción de información diversificada puede mejorar los datos de los documentos y mejorar significativamente el efecto RAG recall.
- mapa del conocimiento
- Ventajas: 1. Abordar la falta de exhaustividad de NativeRAG, todavía existe el problema de la ilusión, y la exactitud del conocimiento, incluyendo la exhaustividad de los límites del conocimiento, la claridad de la estructura del conocimiento y la semántica, es un complemento semántico a la capacidad de recuperación de similitudes.
- Escenarios: Para ámbitos profesionales rigurosos (sanidad, O&M, etc.) en los que la preparación de los conocimientos debe ser limitada y en los que las relaciones jerárquicas entre los conocimientos pueden establecerse claramente.
- Cómo conseguirlo:
1. Depender del modelo grande para extraer la relación ternaria (entidad,relación,entidad).
2. Confiar en la preparación, limpieza y extracción de conocimientos estructurados de calidad previa, a través de las reglas de negocio mediante procesos SOP manuales o personalizados, para construir el grafo de conocimiento.
- Doc Árbol
- Escenarios aplicables: resuelve el problema de la integridad contextual insuficiente, pero también las coincidencias basadas únicamente en la semántica y las palabras clave, y puede reducir el ruido.
- Cómo conseguirlo: construyendo un árbol de nodos de trozos en el nivel de título para formar una estructura de árbol multinomial, donde cada nodo de nivel sólo necesita almacenar el título del documento y los nodos hoja almacenan el contenido específico del texto. De este modo, utilizando el algoritmo de recorrido del árbol, si una pregunta de usuario llega a un nodo de título relevante que no sea hoja, se pueden recuperar los datos relevantes del nodo hijo. De este modo, no existe el problema de la deficiencia en la integridad de los trozos.
Esta parte del reportaje también la pondremos en la comunidad a principios del año que viene.
- La extracción de pares de GC requiere la extracción frontal de información de pares de GC mediante métodos predefinidos o de extracción de modelos
- Escenarios aplicables:
- La capacidad de golpear la pregunta en la recuperación y la recuperación directa, recuperar directamente la respuesta que el usuario desea, aplicable a algunos escenarios de preguntas frecuentes, la integridad de memoria no es suficiente escenarios.
- Cómo conseguirlo:
- Predefinido: añada de antemano algunas preguntas para cada trozo.
- Extracción del modelo: Dado un contexto, deja que el modelo realice la extracción de pares de GC.
- Extracción de metadatos
- Cómo conseguirlo: De acuerdo con las características de sus propios datos empresariales, extraiga las características de los datos para su retención, como etiquetas, categorías, tiempo, versión y otros atributos de metadatos.
- Escenarios aplicables: la recuperación puede prefiltrarse en función de los atributos de los metadatos para filtrar la mayor parte del ruido.
- Resumir y extraer
- Escenarios aplicables: resolución
这篇文章讲了个啥(matemáticas) género总结一下y otros escenarios de problemas globales. - Cómo implementarlo: extracción segmentada mediante mapreduce, etc., extracción de información resumida para cada chunk mediante un modelo.
- Escenarios aplicables: resolución
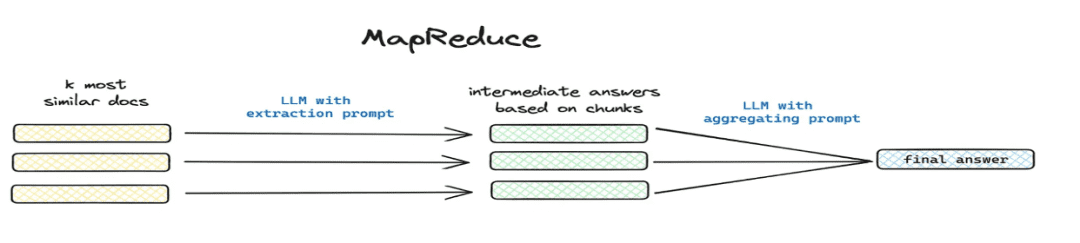
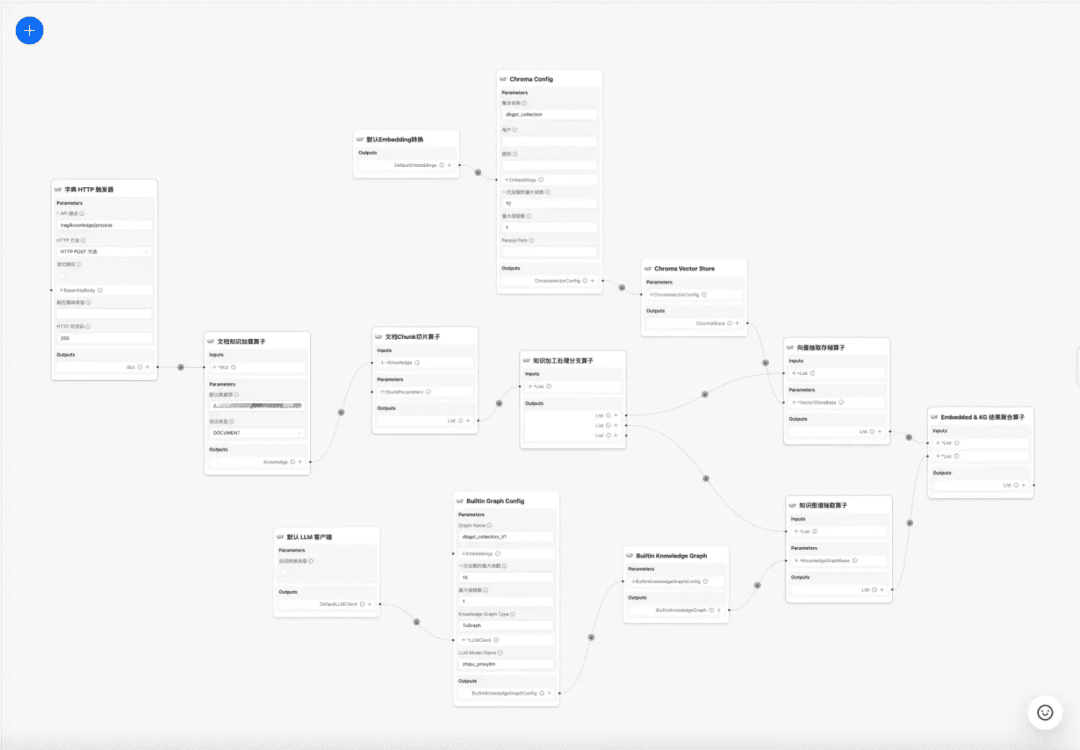
1.4 Flujo de trabajo del tratamiento del conocimiento
en la actualidad DB-GPT La base de conocimientos proporciona capacidades de procesamiento de conocimientos tales como carga de documentos -> análisis sintáctico -> troceado -> incrustación -> extracción de tríadas de grafos de conocimiento -> almacenamiento en bases de datos vectoriales -> almacenamiento en bases de datos de grafos, etc., pero no tiene la capacidad de extraer información compleja y personalizada de los documentos, por lo que se espera que mediante la construcción de una plantilla de flujo de trabajo de procesamiento de conocimientos para completar los procesos de extracción, transformación y procesamiento de conocimientos complejos, visuales y definidos por el usuario. Por lo tanto, se espera que mediante la construcción de una plantilla de flujo de trabajo de procesamiento de conocimientos para completar el complejo, visual, definido por el usuario de extracción de conocimientos, la conversión, el proceso de procesamiento.
Flujo de trabajo del tratamiento del conocimiento:
https://www.yuque.com/eosphoros/dbgpt-docs/vg2gsfyf3x9fuglf
2. Optimización del proceso de RAG La optimización del proceso de RAG se subdivide en RAG de documentos estáticos y RAG de adquisición de datos dinámicos, la mayoría de los RAG actuales sólo cubren los activos estáticos de documentos no estructurados, pero el negocio real de muchos escenarios de preguntas y respuestas es a través de la herramienta para obtener datos dinámicos + datos de conocimiento estático juntos para responder al escenario, no sólo necesitan recuperar el conocimiento estático, sino que también necesitan ser RAG recuperar la información de las herramientas en la biblioteca de activos de herramientas y ejecutar la adquisición de datos dinámicos.
2.1 Optimización RAG de conocimientos estáticos
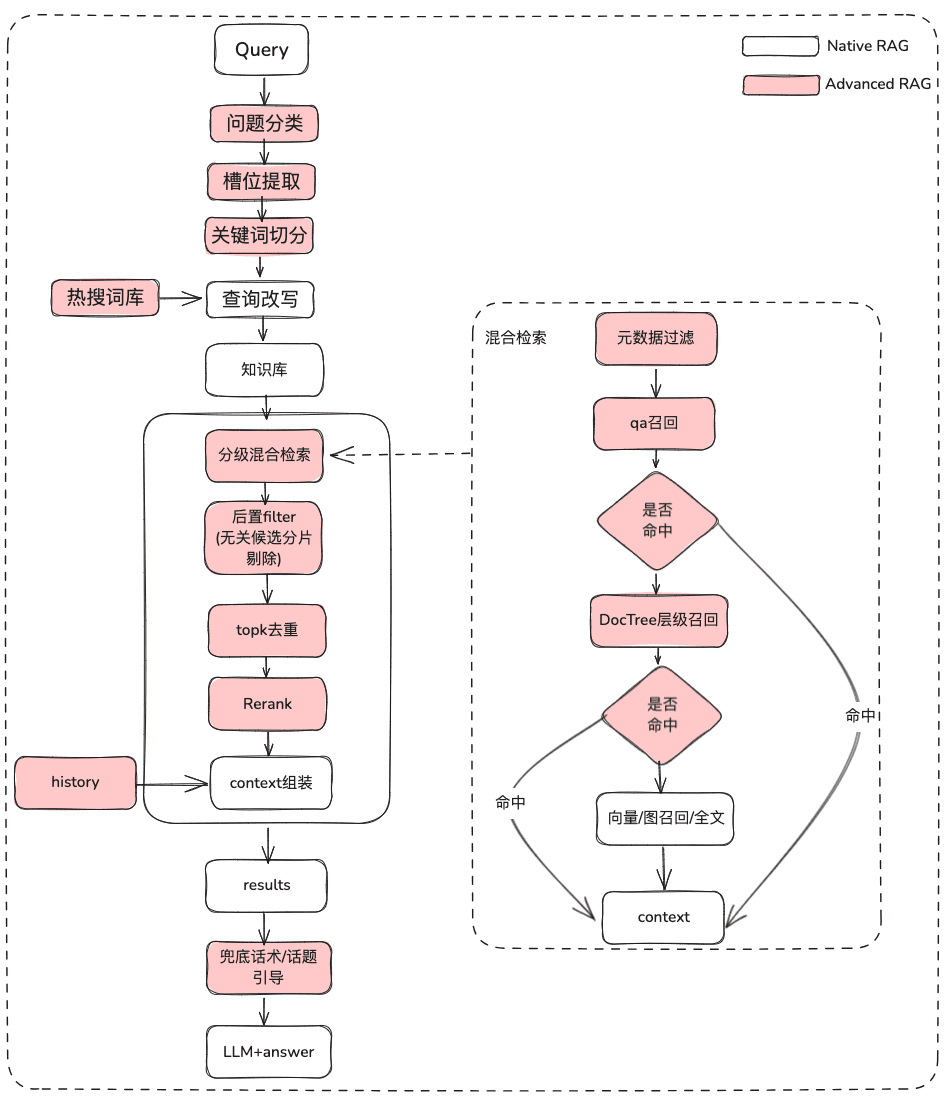
(1) Tratamiento del problema original
Finalidad: Aclarar la semántica del usuario y optimizar la pregunta original del usuario para que pase de ser una consulta difusa y malintencionada a una consulta recuperable más rica en significado.
- Clasificación de problemas en bruto, mediante la cual los problemas se pueden
- Clasificación LLM (
LLMExtractor) - Construyendo incrustación + regresión logística para implementar un modelo de dos torres, text2nlu DB-GPT-Hub/src/dbgpt-hub-nlu/README.zh.md at main - eosphoros-ai/DB-GPT-Hub
- Clasificación LLM (
- Consejo:Si necesita un modelo de incrustación de alta calidad, recomiende bge-v1.5-large
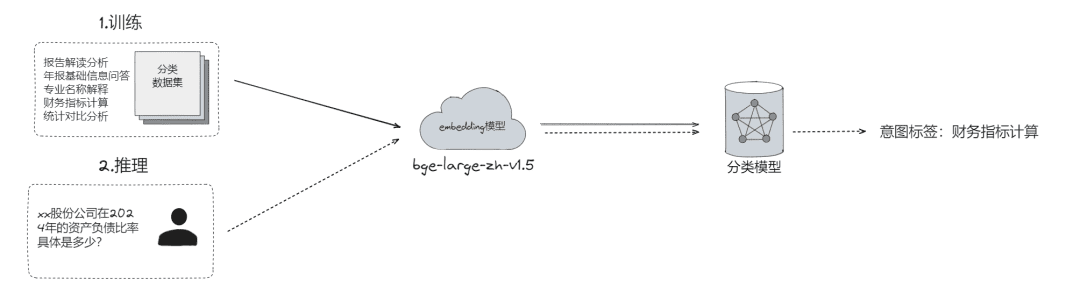
- Preguntar al usuario y, si la semántica no está clara, devolverle la pregunta para que la aclare, mediante varias rondas de interacción.
- Sugiere al usuario una lista de preguntas basadas en la relevancia semántica utilizando un tesauro de búsqueda.
- Extracción de ranuras, cuyo objetivo es obtener información sobre ranuras clave en la pregunta del usuario, como la intención, los atributos de negocio, etc.
- Extracción LLM (
LLMExtractor)
- Extracción LLM (
- Reescribir la pregunta
- Reescritura del tesauro Hot Search
- interacción multicapa
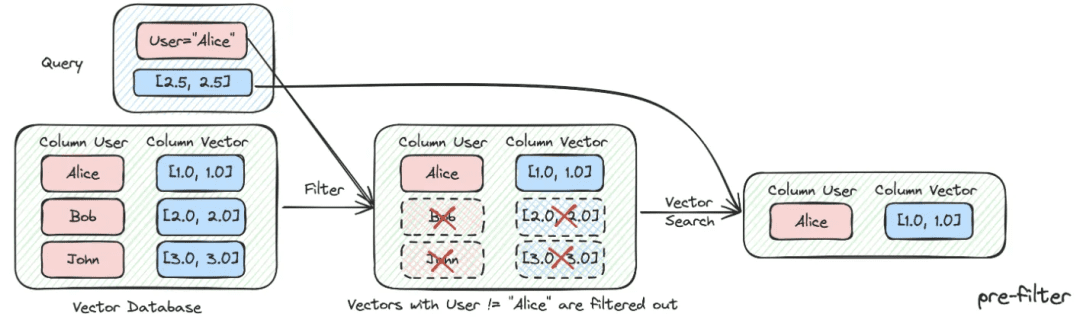
(2) Filtrado de metadatos
Cuando dividimos el índice en muchos trozos y se almacenan en el mismo espacio de conocimiento, la eficacia de la recuperación se convertirá en un problema. Por ejemplo, cuando los usuarios piden información sobre "Zhejiang I Wu Technology Company", no quieren recuperar información sobre otras empresas. Por lo tanto, si se puede filtrar primero por el atributo de metadatos del nombre de la empresa, mejorará mucho la eficacia y la relevancia.
async def aretrieve( self, query: str, filters: Optional[MetadataFilters] = None ) -> List[Chunk]: """ Retrieve knowledge chunks. Args: query (str): async query text. filters (Optional[MetadataFilters]): metadata filters. Returns: List[Chunk]: list of chunks """ return await self._aretrieve(query, filters)
(3) Recuperación híbrida multiestrategia
- Defina prioridades para los distintos recuperadores en función de la prioridad de recuperación, y devuelva el contenido en cuanto se recupere.
- Definir diferentes recuperaciones como qa_retriever, doc_tree_retriever para ser escritas en la cola, y lograr la prioridad de recuperación a través de la propiedad first-in-first-out de la cola.
class RetrieverChain(BaseRetriever): """Retriever chain class.""" def __init__( self, retrievers: Optional[List[BaseRetriever]] = None, executor: Optional[Executor] = None, ): """Create retriever chain instance.""" self._retrievers = retrievers or [] self._executor = executor or ThreadPoolExecutor() async def retrieve(self, query: str, score_threshold: float, filters: Optional[dict] = None): """Perform retrieval with the given query, score threshold, and filters.""" for retriever in self._retrievers: candidates_with_scores = await retriever.aretrieve_with_scores( query=query, score_threshold=score_threshold, filters=filters ) if candidates_with_scores: return candidates_with_scores
- Indexación multiconocimiento/recuperación espacial paralela
- Obtención de listas de candidatos mediante la recuperación paralela a través de diferentes formas de indexación del conocimiento para garantizar la exhaustividad de la recuperación
(4) Postfiltrado
Tras pasar por la lista de candidatos de la criba gruesa, ¿cómo se filtra el ruido a través de la criba fina?
- Eliminación de candidatos irrelevantes
- Rechazo de la puntualidad
- Los atributos empresariales no satisfacen la selección
- desduplicación topk
- Reordenación No es suficiente confiar en la recuperación del cribado grueso, en este momento necesitamos tener algunas estrategias para hacer la reordenación de los resultados recuperados, por ejemplo, hacer algún reajuste de factores como la relevancia de la combinación, la coincidencia, etc., para conseguir la ordenación que esté más en línea con nuestros escenarios de negocio. Porque después de este paso, enviaremos los resultados a LLM para su procesamiento final, por lo que los resultados de esta parte son muy importantes.
- Selección fina utilizando modelos de reordenación pertinentes, ya sean modelos de código abierto o modelos con ajuste semántico empresarial.
## Rerank model # RERANK_MODEL = bce-reranker-base #### If you do not set RERANK_MODEL_PATH, DB-GPT will read the model path from EMBEDDING_MODEL_CONFIG based on the RERANK_MODEL. # RERANK_MODEL_PATH = /Users/chenketing/Desktop/project/DB-GPT-NEW/DB-GPT/models/bce-reranker-base_v1 #### The number of rerank results to return # RERANK_TOP_K = 5
- Selección de la puntuación compuesta ponderada por FRR para empresas basada en diferentes retiradas indexadas
score = 0.0 for q in queries: if d in result(q): score += 1.0 / (k + rank(result(q), d)) return score # where: # k is a ranking constant # q is a query in the set of queries # d is a document in the result set of q # result(q) is the result set of q # rank(result(q), d) is d's rank within the result(q) starting from 1
(5) Optimización de la visualización + Touting / Liderazgo temático
- Obtener el modelo de salida utilizando el formato markdown
基于以下给出的已知信息,遵守规范约束,专业、简要回答用户的问题。 规范约束: 1. 如果已知信息包含的图片、链接、表格、代码块等特殊 markdown 标签格式的信息,确保在答案中包含原文这些图片、链接、表格和代码标签,不要丢弃不要修改,例如: - 图片格式:`` - 链接格式:`[xxx](xxx)` - 表格格式:`|xxx|xxx|xxx|` - 代码格式:```xxx```。 2. 如果无法从提供的内容中获取答案,请说:“知识库中提供的内容不足以回答此问题”,禁止胡乱编造。 3. 回答的时候最好按照 1.2.3. 点进行总结,并以 Markdown 格式显示。
2.2 Optimización dinámica del conocimiento RAG
El conocimiento de la documentación es relativamente estático, no puede responder a información personalizada y dinámica, necesita depender de algunas herramientas de plataformas de terceros para responder, basándonos en esta situación, necesitamos algunos métodos RAG dinámicos, a través de la definición de activos de herramientas -> selección de herramientas -> validación de herramientas -> ejecución de herramientas para obtener datos dinámicos.
(1) Biblioteca de activos de herramientas
Construir una biblioteca de activos de herramientas de dominio empresarial para integrar API de herramientas, scripts de herramientas dispersos a varias plataformas, y así proporcionar capacidades de uso de extremo a extremo para las inteligencias. Por ejemplo, además de la base de conocimientos estática, podemos procesar las herramientas importando la biblioteca de herramientas.

(2) Recuperación de herramientas
La recuperación de la herramienta sigue la idea de la recuperación RAG para el conocimiento estático y, a continuación, se utiliza el ciclo de vida completo de ejecución de la herramienta para obtener los resultados de la ejecución de la herramienta.
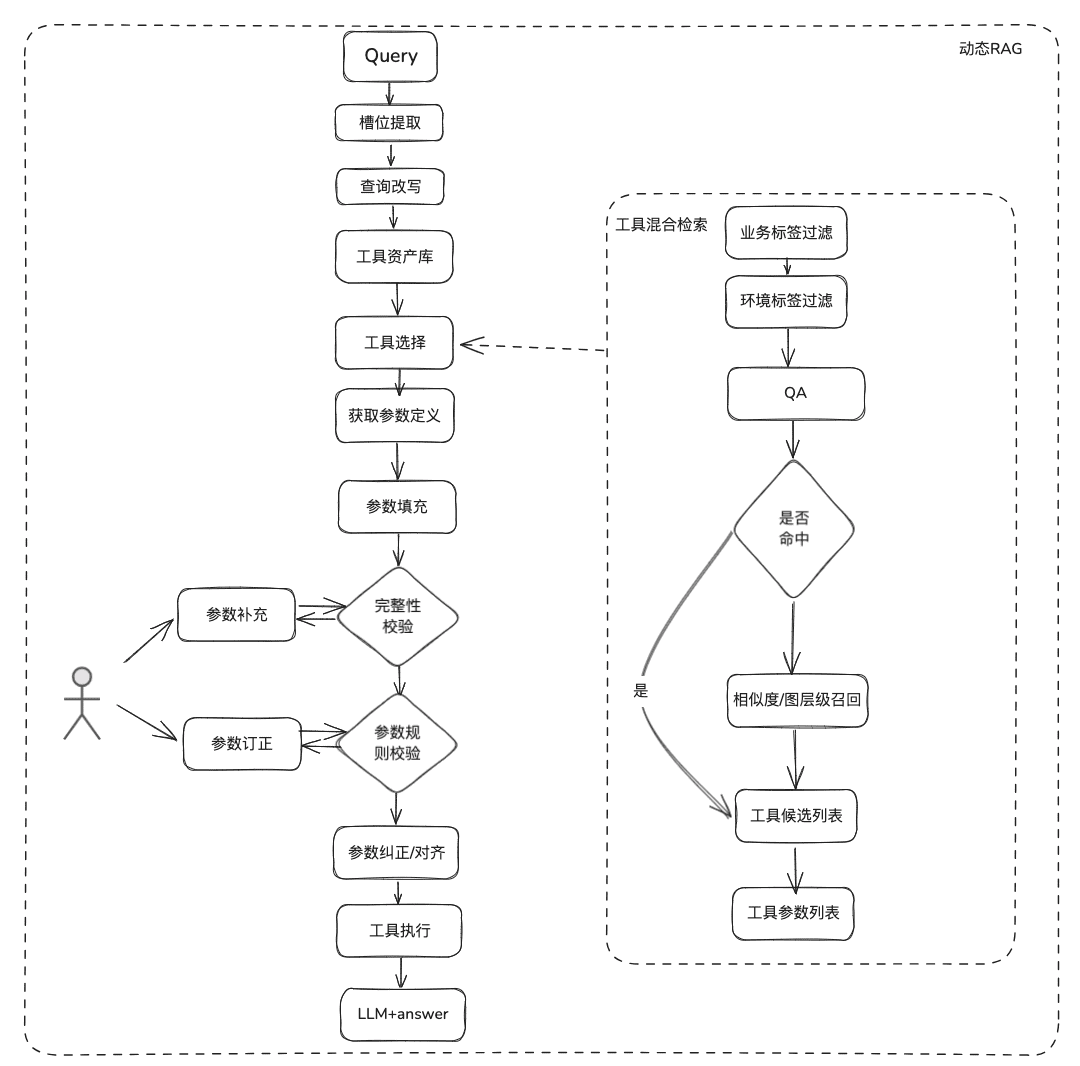
- Extracción de ranuras: Obtenga LLM a través de nlp tradicional para analizar el problema del usuario, incluyendo tipos de negocio comunes, marcadores de entorno, parámetros del modelo de dominio, etc.
- Selección de herramientas: recuperación según las líneas de la GAR estática con dos capas principales, recuperación del nombre de la herramienta y recuperación de los parámetros de la herramienta.
- Tool Parameter Recall, cuya idea es similar a la de TableRAG, recupera primero el nombre de la tabla y luego el del campo.
- Relleno de parámetros: es necesario que los parámetros extraídos de las ranuras coincidan con las definiciones de parámetros de la herramienta de las retiradas.
- Puedes codificar para rellenarla, o puedes hacer que el modelo la rellene.
- Ideas de optimización: Dado que los nombres de los mismos parámetros de las distintas herramientas de la plataforma no están unificados, y no es conveniente acudir a la gobernanza, se sugiere realizar primero una ronda de ampliación de datos del modelo de dominio, y después de obtener el modelo de dominio completo, estarán presentes los parámetros necesarios.
- calibración de parámetros
- Comprobación de integridad: realiza una comprobación de integridad del número de parámetros.
- Comprobación de reglas de parámetros: Realiza la comprobación de reglas en el tipo de nombre de parámetro, valor de parámetro, enumeración, etc.
- Corrección/alineación de parámetros, esta parte es principalmente para reducir el número de interacciones con el usuario, la finalización automatizada de la corrección de errores de parámetros del usuario, incluyendo reglas de casos, reglas de enumeración, etc. por ejemplo.
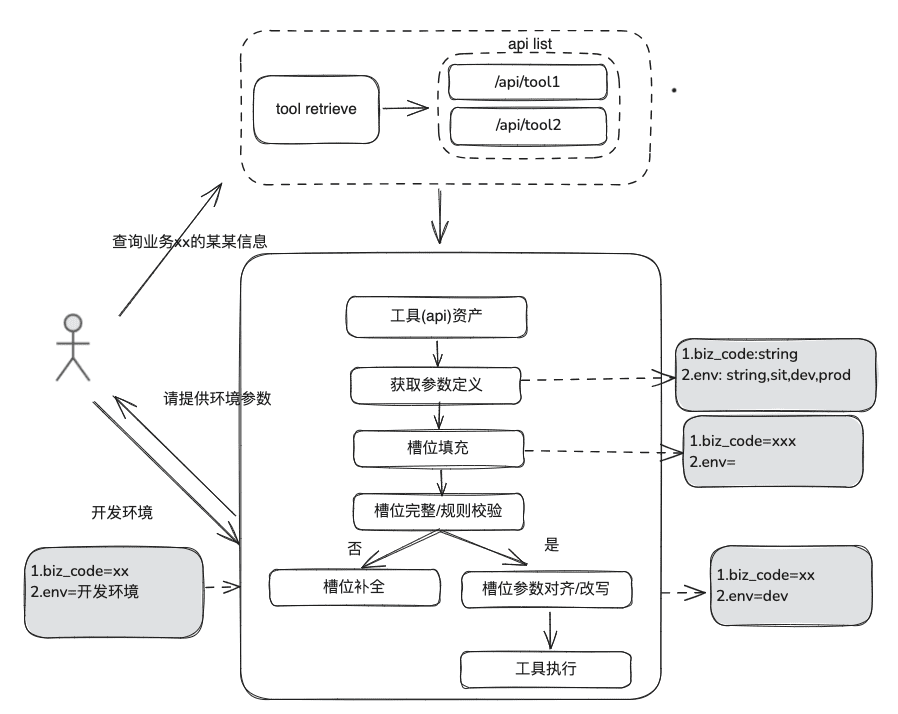
2.3 Revisión RAG
A la hora de evaluar el proceso Smart Q&A, es necesario evaluar por separado la precisión de la pertinencia del recuerdo y la pertinencia del modelo Q&A, y después considerarlas conjuntamente para determinar en qué aspectos aún debe mejorarse el proceso RAG.
Evaluación de los indicadores:
EvaluationMetric ├── LLMEvaluationMetric │ ├── AnswerRelevancyMetric ├── RetrieverEvaluationMetric │ ├── RetrieverSimilarityMetric │ ├── RetrieverMRRMetric │ └── RetrieverHitRateMetric
RAGRetrieverEvaluationMetric:RetrieverHitRateMetricEl porcentaje de aciertos mide el GARretrieverProporción de retiradas que aparecen en los documentos top-k de los resultados recuperados.RetrieverMRRMetric:Mean Reciprocal RankLa precisión de cada consulta se calcula analizando la clasificación de los documentos más relevantes en los resultados de la búsqueda. Más concretamente, es la media del rango inverso de los documentos relevantes para todas las consultas. Por ejemplo, si el documento más relevante aparece en primer lugar, su rango inverso es 1; si aparece en segundo lugar, es 1/2; y así sucesivamente.RetrieverSimilarityMetricMétricas de similitud: las métricas de similitud se calculan para calcular la similitud entre el contenido recuperado y el contenido previsto.
模型生成Indicador de respuesta.
AnswerRelevancyMetric:: Métrica de relevancia de la respuesta del cuerpo inteligente, según el grado de coincidencia de la respuesta del cuerpo inteligente con la pregunta del usuario. Una respuesta de alta relevancia no sólo requiere que el modelo comprenda la pregunta del usuario, sino también que genere una respuesta estrechamente relacionada con la pregunta. Esto afecta directamente a la satisfacción del usuario y a la utilidad del modelo.
3.RAG Aterrizaje Compartición de casos
1. GAR en el ámbito de la infraestructura de datos
1.1 Antecedentes del Órgano de Inteligencia de O&M
En el espacio de la infraestructura de datos, hay muchos Ops SRE que reciben un gran número de alertas cada día, por lo que se dedica mucho tiempo a responder a las emergencias, lo que a su vez conduce a la solución de problemas, y luego a la revisión de problemas, lo que a su vez conduce a la experiencia. Otra parte del tiempo se dedica a responder a las consultas de los usuarios, lo que les obliga a responder a las preguntas con sus conocimientos y experiencia en el uso de las herramientas.
Por tanto, esperamos resolver estos problemas de diagnóstico de alarmas y respuesta a preguntas creando una inteligencia general para la infraestructura de datos.
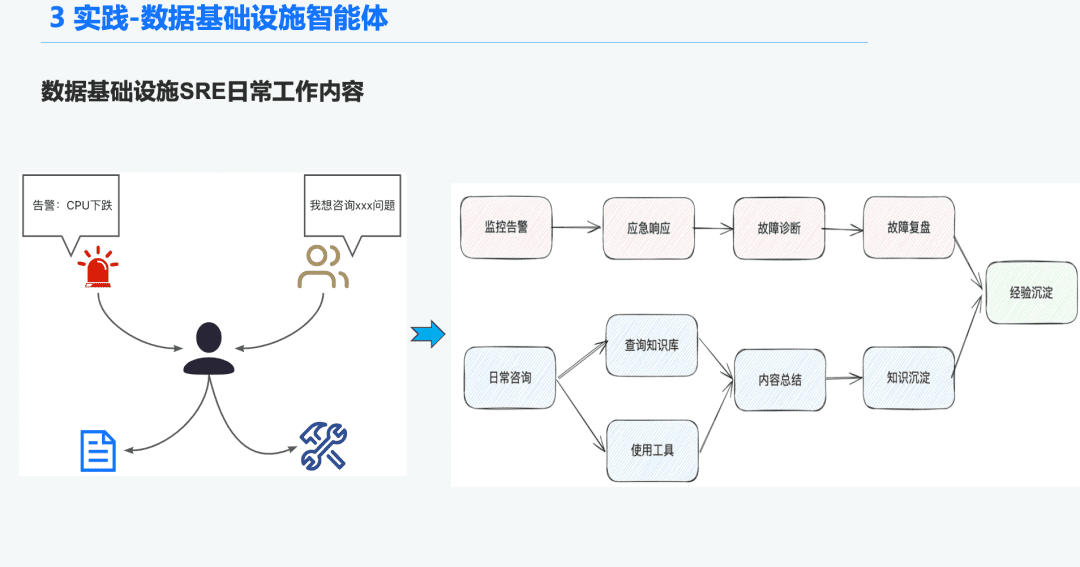
1.2 Un GAR riguroso y profesional
La tecnología tradicional de RAG + Agente puede resolver escenarios de uso general, menos deterministas y con tareas de un solo paso. Sin embargo, cuando nos enfrentamos a escenarios profesionales en el campo de la infraestructura de datos, todo el proceso de recuperación debe ser determinista, profesional y realista, y requiere un razonamiento paso a paso.
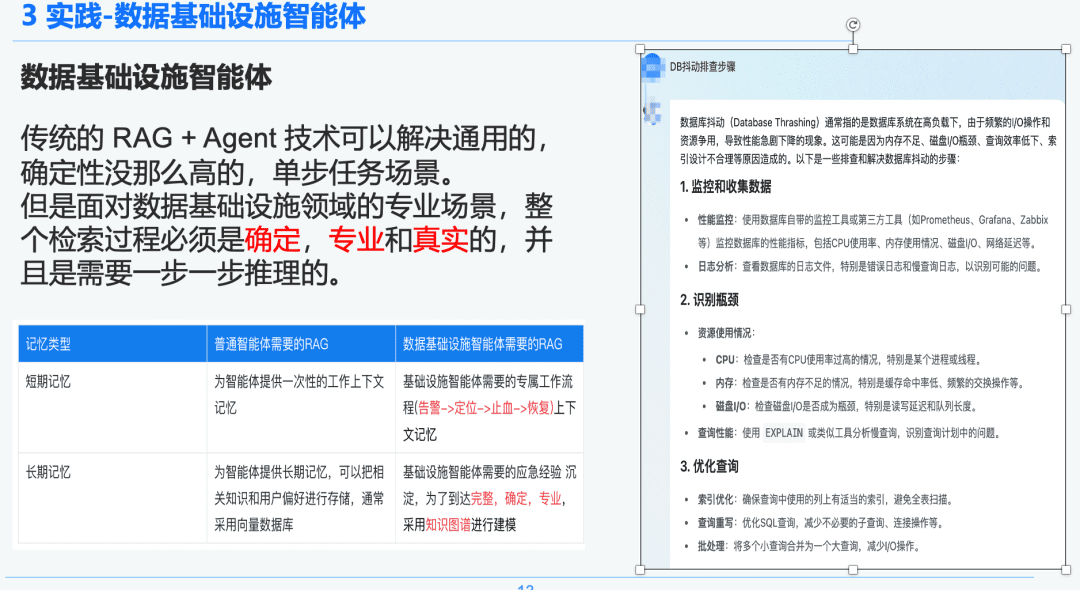
A la derecha hay un resumen generalizado a través de NativeRAG, que puede ser información útil para un usuario de C-suite que no tenga muchos conocimientos del dominio, y luego para un profesional, esta parte de la respuesta no tendrá mucho sentido.
Por lo tanto, comparamos la diferencia entre las inteligencias genéricas y las inteligencias de infraestructura de datos sobre GAR:
- Inteligencias de uso general: las GAR tradicionales no requieren tanto rigor intelectual ni tanta experiencia, y son adecuadas para algunos escenarios empresariales como la atención al cliente, el turismo y los robots de preguntas y respuestas de las plataformas.
- Cuerpo de inteligencia de la infraestructura de datos: El proceso GAR es riguroso y profesional, y requiere flujos de trabajo GAR exclusivos con contextos que incluyan (Alertar -> Localizar -> Detener la hemorragia -> Recuperar) y extracción estructurada de preguntas y respuestas y experiencia en respuesta a emergencias precipitadas por expertos para establecer relaciones jerárquicas. Por eso elegimos Knowledge Graph como portador de datos.
1.3 Tratamiento de los conocimientos
Basándonos en el determinismo y la especificidad de la infraestructura de datos, elegimos utilizarla como portadora de conocimiento para diagnosticar experiencias de respuesta a emergencias combinando gráficos de conocimiento. Nuestra experiencia de conocimiento de eventos de solución de problemas de emergencia precipitados por SRE Combinado con el proceso de revisión de emergencia, establecimos un gráfico de conocimiento impulsado por eventos de emergencia de BD, tomamos el jitter de BD como ejemplo, varios eventos que afectan al jitter de BD, incluyendo problemas de SQL lento, problemas de capacidad, establecimos relaciones entre cada evento de emergencia.
Por último, hemos establecido un sistema normalizado de tratamiento del conocimiento a partir de múltiples fuentes -> extracción estructurada del conocimiento -> extracción de relaciones de emergencia -> revisión por expertos -> almacenamiento del conocimiento paso a paso mediante la normalización de las reglas de los sucesos de emergencia.

1.4 Recuperación de conocimientos
En la fase de recuperación del cuerpo inteligente, utilizamos GraphRAG como portador de la recuperación del conocimiento estático, por lo que después de identificar la anomalía de fluctuación de la base de datos, encontramos los nodos relacionados con el nodo de anomalía de fluctuación de la base de datos como base de nuestro análisis, ya que cada nodo también conserva alguna información de metadatos para cada evento en la fase de extracción del conocimiento, incluyendo el nombre del evento, la descripción del evento, las herramientas relacionadas, los parámetros de la herramienta, etc.
Por lo tanto, podemos obtener los resultados de retorno a través del enlace del ciclo de vida de ejecución de la herramienta de ejecución para obtener los datos dinámicos que se utilizarán como base del diagnóstico de emergencia para la resolución de problemas. A través de este enfoque de recuperación híbrida dinámica y estática, la certeza, la profesionalidad y el rigor de la ejecución de las inteligencias de la infraestructura de datos están garantizados que la recuperación RAG pura y simple.
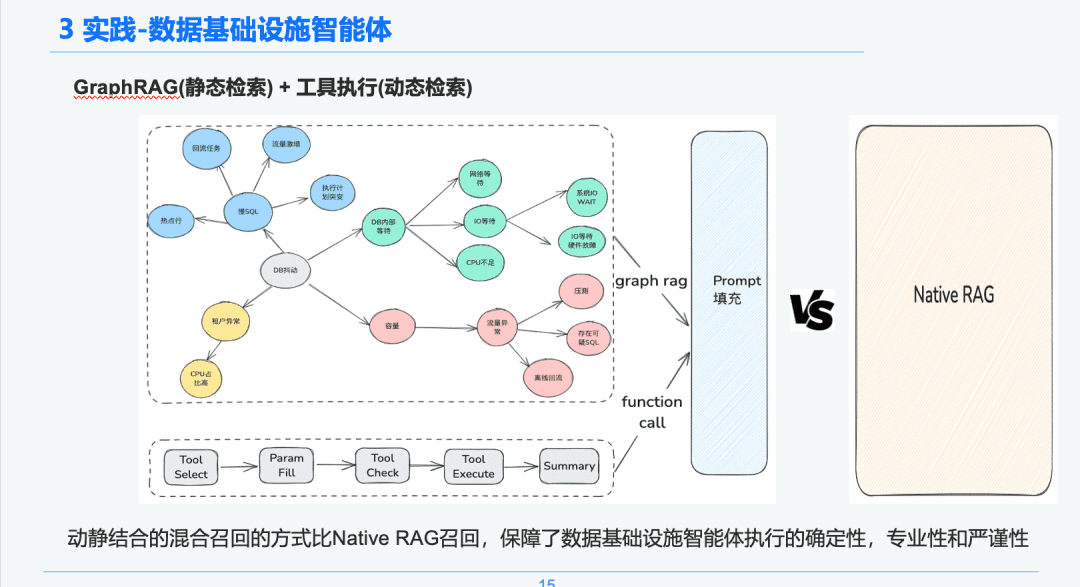
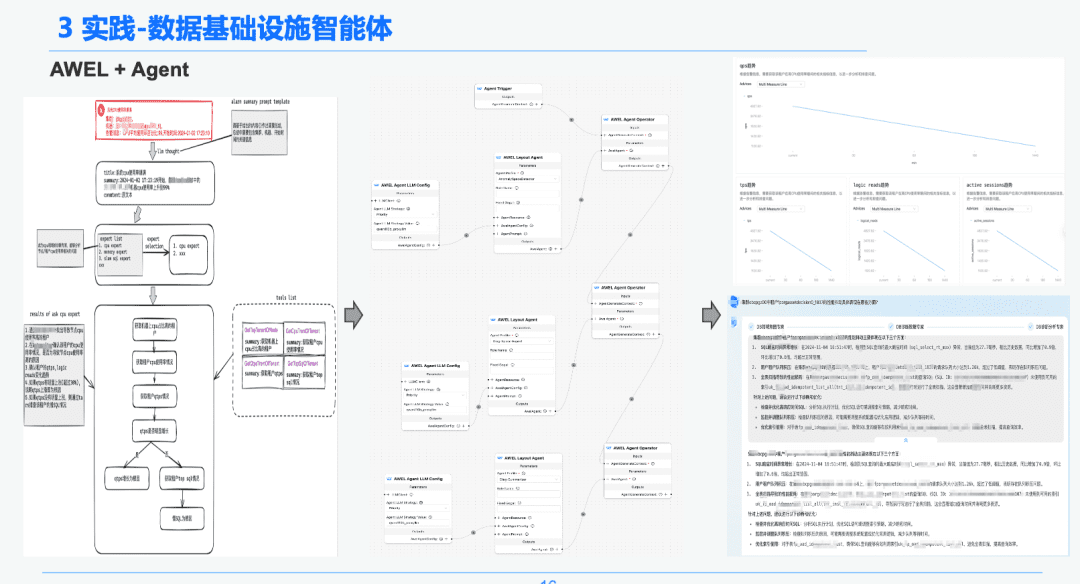
1,5 AWEL + Agente
Por último, a través de la tecnología comunitaria AWEL+AGENT, se ha utilizado el paradigma de la orquestación AGENT para crear un experto desde la intención -> experto en diagnóstico de emergencia -> experto en análisis de la causa raíz del diagnóstico.
Cada Agente tiene una función diferente. El Experto en Intenciones es responsable de identificar y analizar la intención del usuario y de identificar los mensajes de alerta. El Experto en Diagnóstico necesita localizar el nodo de causa raíz que se va a analizar a través de GraphRAG y obtener información específica sobre la causa raíz. El experto en análisis necesita combinar los datos de cada nodo de causa raíz + el informe de revisión del análisis histórico para generar un informe de análisis de diagnóstico.
2. GAR en el ámbito del análisis de la información financiera
¡Última práctica! ¿Cómo construir un asistente de análisis de informes financieros basado en DB-GPT?
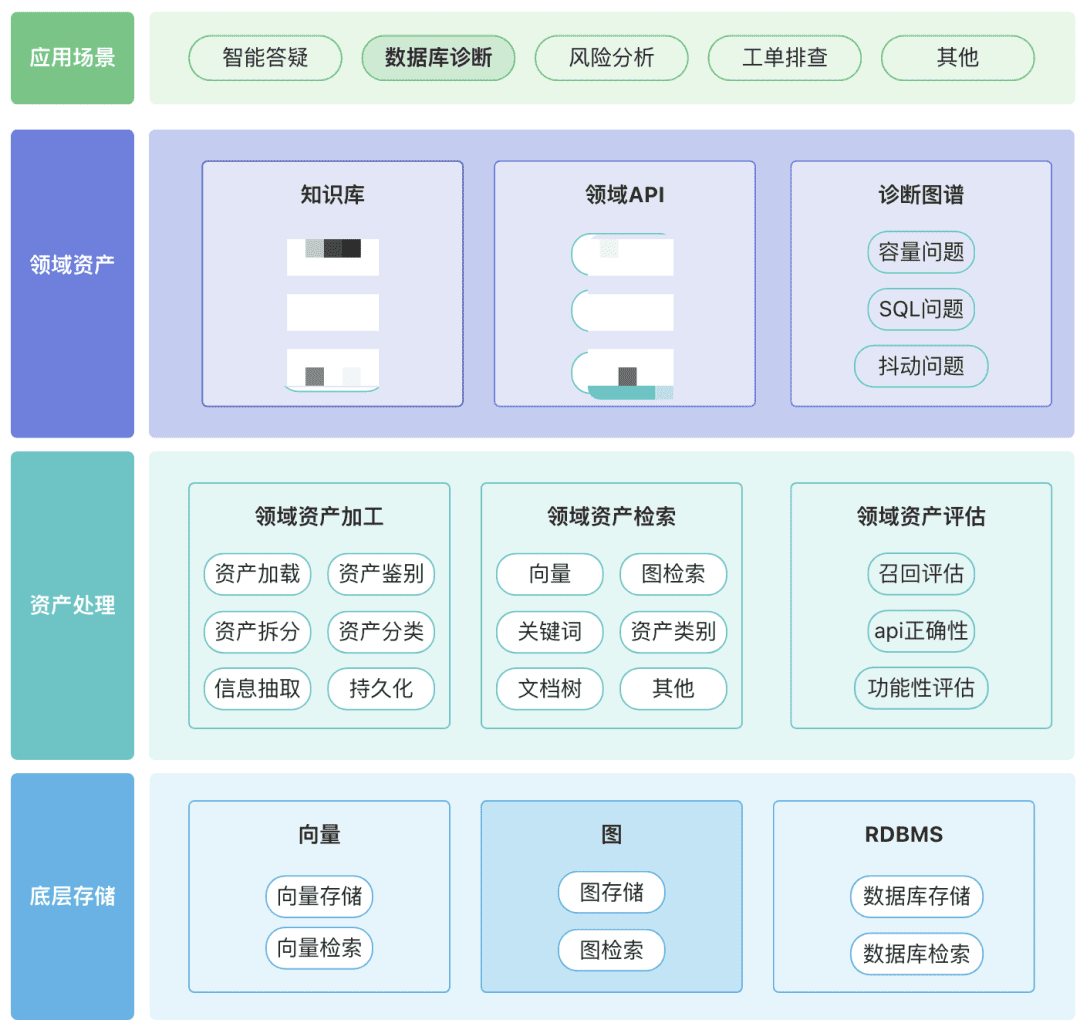
Puede crear su propio repositorio de activos de dominio, incluidos activos de conocimiento, activos de herramientas y activos de gráficos de conocimiento, en torno a su dominio.
- Activos de dominio: Los activos de dominio incluyen bases de conocimiento, API y scripts de herramientas.
- Procesamiento de activos, todo el enlace de datos de activos implica el procesamiento de activos de dominio, la recuperación de activos de dominio y la evaluación de activos de dominio.
- No estructurada -> Estructurada: categorizada de forma estructurada, información del conocimiento correctamente organizada.
- Extraer información semántica más rica.
- Recuperación de activos:
- Afortunadamente, se trata de una búsqueda jerárquica y priorizada en lugar de una búsqueda única.
- El postfiltrado es importante, preferiblemente a través de la semántica empresarial de algunas reglas.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...