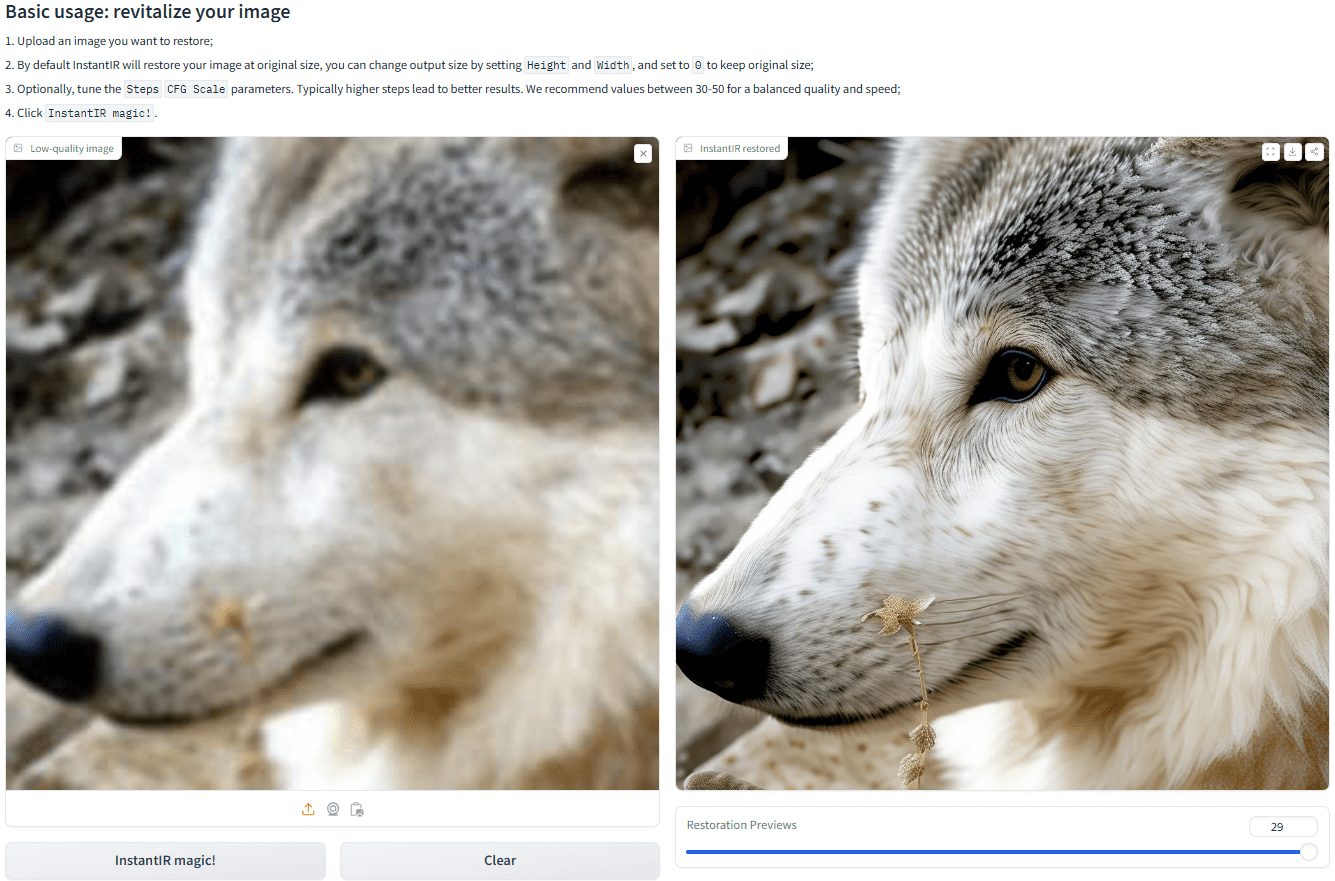
VikingDB - Base de datos vectorial nativa en la nube de alto rendimiento de Volcano Engine
Últimos recursos sobre IAPublicado hace 8 meses Círculo de intercambio de inteligencia artificial 57K 00

Qué es VikingDB
VikingDB es una base de datos vectorial de alto rendimiento nativa de la nube de Volcano Engine, diseñada para manejar datos vectoriales masivos de alta dimensión.VikingDB tiene múltiples métodos de escritura de datos, incluyendo la escritura sincrónica en tiempo real, asincrónica, etc., para satisfacer las necesidades de diferentes escenarios.VikingDB se basa en algoritmos de indexación de alta eficiencia de desarrollo propio como HNSW y IVF, que permite la búsqueda en milisegundos de decenas de miles de millones de vectores, y es compatible con la recuperación de vectores densos y dispersos. VikingDB proporciona una consola SaaS, API y SDK en varios idiomas, y admite la expansión elástica automática, lo que puede reducir eficazmente el coste de almacenamiento.VikingDB se utiliza ampliamente en los campos de la búsqueda multimodal, la recomendación inteligente, los escenarios RAG y la construcción de memoria, lo que puede ayudar a las empresas a lograr una gestión eficiente de los datos y el desarrollo de aplicaciones inteligentes.
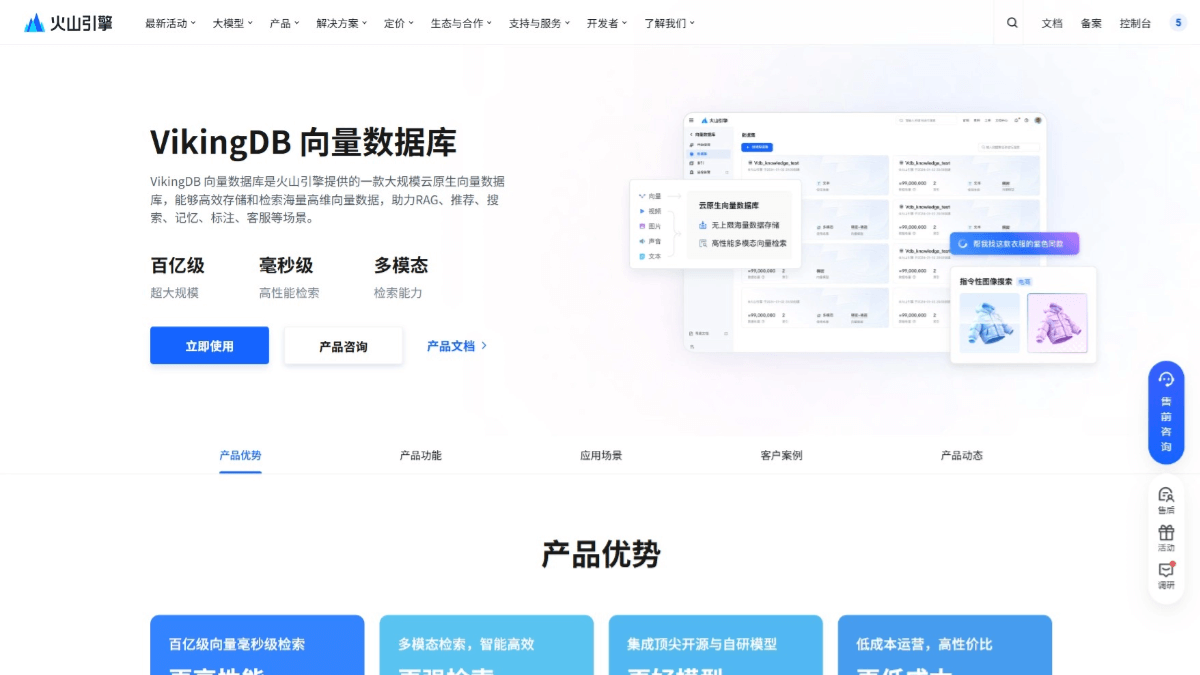
Características principales de VikingDB
- Escritura flexible de datosProporciona múltiples métodos de escritura, como la escritura síncrona en tiempo real, la asíncrona, la escritura de datos individuales y la escritura por lotes, para satisfacer las necesidades de diferentes escenarios empresariales.
- Indexación eficaz y actualizaciones en tiempo realEl algoritmo de indexación se basa en HNSW, IVF y otros algoritmos de indexación avanzados, combinados con la arquitectura de actualización de flujo, que asegura que los datos puedan seguir actualizándose rápidamente bajo una carga elevada y garantiza la recuperación en tiempo real.
- Potentes funciones de búsqueda: Soporta la recuperación de datos vectoriales, escalares, mixtos y multimodales, capaz de lograr una recuperación en milisegundos en decenas de miles de millones de datos vectoriales para satisfacer requisitos de consulta complejos.
- Servicios en nube elásticos y escalablesProporciona una consola SaaS, interfaces API y SDK en varios idiomas, admite la expansión elástica automática y facilita a los usuarios la creación y gestión rápidas de procesos de recuperación de datos.
- Alto rendimiento y optimización de costesGracias a algoritmos de indexación profundamente optimizados y técnicas de cuantificación, consigue una eficiencia de recuperación extremadamente alta al tiempo que reduce los costes de almacenamiento para garantizar la rentabilidad en escenarios de datos a gran escala.
- Base de conocimientos y funciones de memoriaEl sistema de gestión de la información de la Comisión Europea (CEI): admite la recuperación semántica compleja y el almacenamiento en memoria a largo plazo de modelos de gran tamaño, y es adecuado para escenarios de interacción personalizada, como los asistentes inteligentes, la educación y la enseñanza.
Dirección del sitio web oficial de VikingDB
- Dirección del sitio web oficial:: https://www.volcengine.com/product/VikingDB
Cómo utilizar VikingDB
- Registro e inicio de sesiónVisite el sitio web oficial de Volcano Engine, complete el registro de la cuenta e inicie sesión para acceder a la consola VikingDB.
- Creación de instanciasCree una instancia VikingDB en la consola, configurando parámetros como el nombre, la capacidad de almacenamiento y las especificaciones de rendimiento según sea necesario.
- Preparación de datos y vectorización: Organizar los datos que se van a procesar y utilizar modelos de incrustación (p. ej. Doubao u otros modelos de código abierto) en forma vectorial.
- Acceso al SDKInstale e inicialice el SDK proporcionado por VikingDB (Python, Java, Go, etc.) y conéctese a la instancia de base de datos creada.
- escribir datosEscritura de datos vectoriales a VikingDB basada en el SDK, eligiendo entre métodos de escritura en tiempo real síncrono, asíncrono y otros.
- recuperar: Utilice el SDK para realizar búsquedas vectoriales, escalares o híbridas para obtener los resultados más similares.
- Supervisión y optimizaciónSupervise las métricas de rendimiento de las instancias en la consola y ajuste las configuraciones para optimizar el rendimiento y los costes en función del uso real.
Principales ventajas de VikingDB
- Búsqueda de alto rendimientoBasándose en algoritmos de indexación eficientes de desarrollo propio (por ejemplo, HNSW, IVF, etc.), logra una recuperación en milisegundos en decenas de miles de millones de vectores, y la latencia de recuperación es tan baja como 10 ms, lo que mejora significativamente la eficiencia de la consulta.
- Apoyo a los datos sobre diversidadSoporta la recuperación de vectores densos y vectores dispersos, y es compatible con la recuperación de datos vectoriales, escalares, mixtos y multimodales, y es aplicable a una amplia gama de tipos de datos y escenarios complejos.
- Escritura flexible de datosProporciona escritura síncrona y asíncrona en tiempo real, escritura de datos individuales y escritura por lotes para satisfacer los requisitos de escritura de datos en diferentes escenarios empresariales y garantizar la flexibilidad y eficacia del procesamiento de datos.
- Elasticidad y escalabilidadComo base de datos nativa en la nube, ofrece una consola SaaS, API y SDK en varios idiomas, admite la expansión elástica automática y ajusta dinámicamente los recursos en función del volumen de datos y la carga de consultas para garantizar la estabilidad y eficiencia del sistema.
- Almacenamiento de bajo coste: Utiliza algoritmos de indexación profundamente optimizados y técnicas de cuantificación para lograr un alto rendimiento al tiempo que se reducen los costes de almacenamiento y se mejora la relación precio/rendimiento.
- Base de conocimientos y funciones de memoriaProporciona recuperación semántica compleja y almacenamiento en memoria a largo plazo de modelos de gran tamaño, aplicables a escenarios de interacción personalizada, como asistentes inteligentes, educación y enseñanza, juegos de rol, etc., y admite la recuperación eficiente y la gestión de memoria de modelos de gran tamaño.
Para quién es VikingDB
- Ingeniero de inteligencia artificial y aprendizaje automáticoHerramientas eficaces para el entrenamiento de modelos, la recuperación de características y el procesamiento de datos multimodales para ingenieros que necesitan procesar y recuperar datos vectoriales a gran escala.
- científico de datos: Durante el análisis y la minería de datos, las diversas capacidades de búsqueda y la escritura flexible de datos pueden ayudar a los científicos de datos a validar rápidamente modelos y procesar datos complejos.
- Equipo técnico de la empresaEl alto rendimiento y la escalabilidad elástica de VikingDB respaldan el crecimiento empresarial y las necesidades tecnológicas de las organizaciones que necesitan crear sistemas de recomendación inteligentes, plataformas de búsqueda multimodal o bases de conocimiento.
- arquitecto de sistemas: Para arquitectos responsables del diseño de arquitecturas de sistemas, proporcionan soluciones de alto rendimiento, escalables y fáciles de integrar que se adaptan perfectamente a las pilas tecnológicas existentes.
- desarrolladoresVikingDB proporciona SDK y documentación detallada en varios idiomas, lo que permite a los desarrolladores acceder y utilizar rápidamente VikingDB para una gestión de datos y un desarrollo de aplicaciones eficientes.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...