
V-JEPA 2 - El modelo de gran tamaño más potente del mundo de Meta AI
Últimos recursos sobre IAPublicado hace 10 meses Círculo de intercambio de inteligencia artificial 45.3K 00

Qué es V-JEPA 2
V-JEPA 2 Sí Meta IA Lanzado un modelo de tamaño mundial basado en datos de vídeo con 1.200 millones de parámetros. El modelo se entrena a partir del aprendizaje autosupervisado de más de un millón de horas de vídeo y un millón de imágenes para comprender objetos, acciones y movimientos en el mundo físico y predecir estados futuros. El modelo utiliza una arquitectura de codificador-predictor, combinada con la predicción de las condiciones de acción, para apoyar la planificación de robots de muestra cero, lo que permite a los robots completar tareas en entornos nuevos. V-JEPA 2 destaca en tareas como el reconocimiento de acciones, la predicción y las preguntas y respuestas en vídeo, proporcionando un potente soporte técnico para el control de robots, la vigilancia inteligente, la educación y la asistencia sanitaria, y constituye un paso importante hacia la inteligencia artificial avanzada.
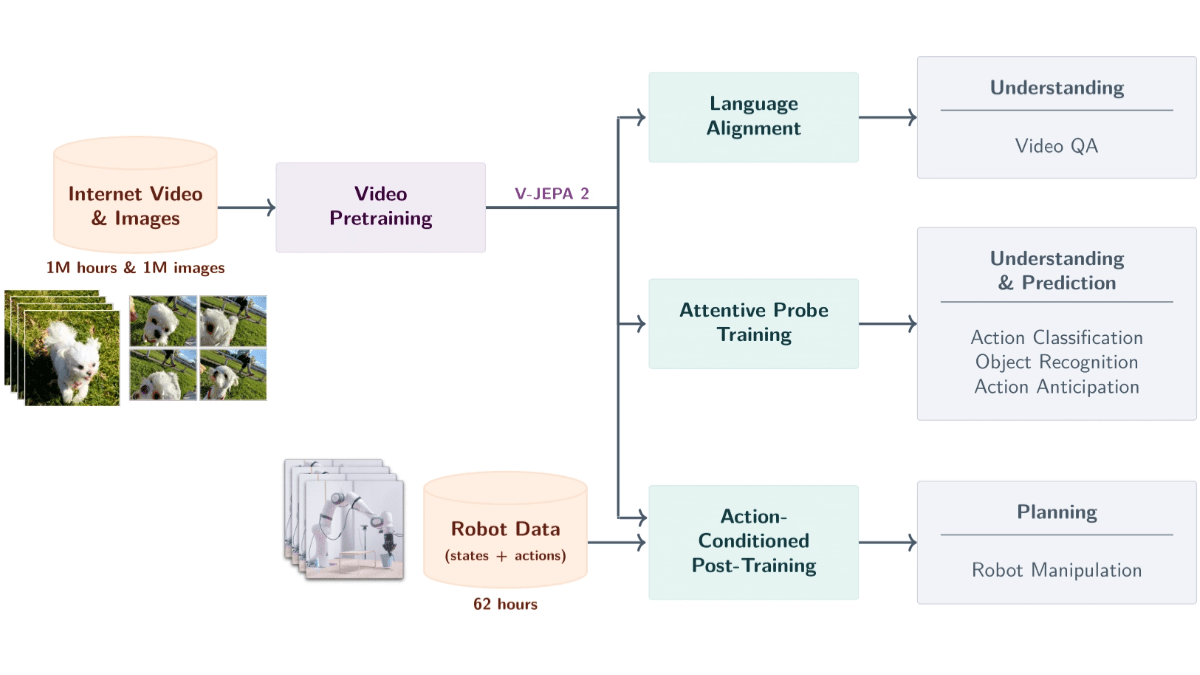
Características principales de V-JEPA 2
- Análisis semántico de vídeo: Reconocer objetos, acciones y movimientos a partir de vídeos y extraer con precisión información semántica sobre la escena.
- Previsión de acontecimientos futurosPredice futuros fotogramas de vídeo o resultados de acciones basándose en el estado y las acciones actuales, lo que permite realizar predicciones a corto y largo plazo.
- Robot cero planificación de muestras: Tareas de planificación para robots en entornos nuevos, como el agarre y la manipulación de objetos, basadas en capacidades predictivas, sin datos de entrenamiento adicionales.
- Vídeo de preguntas y respuestasResponder a preguntas relacionadas con el contenido del vídeo en conjunción con el modelado lingüístico, abarcando la causa y el efecto físicos y la comprensión de escenas.
- Generalización entre escenas: funciona bien en entornos y objetos no vistos y admite el aprendizaje y la adaptación con muestra cero en escenas nuevas.
Dirección del sitio web oficial de V-JEPA 2
- Página web del proyecto::https://ai.meta.com/blog/v-jepa-2
- Repositorio GitHub::https://github.com/facebookresearch/vjepa2
- Documentos técnicos::https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
Cómo utilizar V-JEPA 2
- Acceso a recursos modeloDescarga los archivos del modelo preentrenado y el código asociado desde el repositorio de GitHub. Los archivos del modelo se proporcionan en formato .pth o .ckpt.
- Configuración del entorno de desarrollo::
- Instalación de PythonAsegúrese de que Python está instalado (se recomienda Python 3.8 o superior).
- Instalación de bibliotecas dependientesPip: Utiliza pip para instalar las dependencias requeridas por el proyecto. Normalmente, los proyectos proporcionan un archivo requirements.txt para instalar dependencias basadas en los siguientes comandos:
pip install -r requirements.txt- Instalación de marcos de aprendizaje profundoV-JEPA 2 está basado en PyTorch y requiere la instalación de PyTorch, dependiendo de la configuración del sistema y de la GP, obtenga los comandos de instalación de la página web de PyTorch.
- Modelos de carga::
- Carga de modelos preentrenadosCarga archivos de modelos preentrenados con PyTorch.
import torch
from vjepa2.model import VJEPA2 # 假设模型类名为 VJEPA2
# 加载模型
model = VJEPA2()
model.load_state_dict(torch.load("path/to/model.pth"))
model.eval() # 设置为评估模式- Preparación de la introducción de datos::
- Preprocesamiento de datos de vídeoV-JEPA 2 requiere datos de vídeo como entrada. Los datos de vídeo se convierten al formato (normalmente tensor) requerido por el modelo. A continuación se muestra un ejemplo sencillo de preprocesamiento:
from torchvision import transforms
from PIL import Image
import cv2
# 定义视频帧的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整帧大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 读取视频帧
cap = cv2.VideoCapture("path/to/video.mp4")
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = transform(frame)
frames.append(frame)
cap.release()
# 将帧堆叠为一个张量
video_tensor = torch.stack(frames, dim=0).unsqueeze(0) # 添加批次维度- Previsiones con modelos::
- Previsiones de aplicaciónIntroducción de los datos de vídeo preprocesados en el modelo para obtener los resultados de la predicción. A continuación se muestra el código de ejemplo:
with torch.no_grad(): # 禁用梯度计算
predictions = model(video_tensor)- Análisis sintáctico y aplicación de los resultados de las previsiones::
- Análisis de los resultados de las previsionesAnaliza la salida del modelo según los requisitos de la tarea.
- Aplicación a situaciones realesAplicación de predicciones a tareas del mundo real, como el control de robots, el visionado de vídeos o la detección de anomalías.
Principales ventajas de V-JEPA 2
- Conocimiento profundo del mundo físico: V-JEPA 2 puede reconocer con precisión acciones y movimientos de objetos a partir de entradas de vídeo, captando información semántica sobre la escena y proporcionando un soporte básico para tareas complejas.
- Predicción eficiente del estado futuroEl modelo, basado en el estado y las acciones actuales, puede predecir futuros fotogramas de vídeo o resultados de acciones, lo que permite realizar predicciones a corto y largo plazo, impulsando aplicaciones como la planificación de robots y la supervisión inteligente.
- Capacidad de aprendizaje y generalización con muestra ceroV-JEPA 2 funciona bien en entornos y objetos invisibles, admite el aprendizaje y la adaptación sin muestras y no requiere datos de entrenamiento adicionales para completar nuevas tareas.
- Preguntas y respuestas por vídeo combinadas con modelización lingüísticaV-JEPA 2, combinado con un modelo lingüístico, es capaz de responder a preguntas relacionadas con el contenido de los vídeos, que abarcan la causalidad física y la comprensión de escenas, lo que amplía las aplicaciones en ámbitos como la educación y la sanidad.
- Formación eficaz basada en el aprendizaje autosupervisadoAprendizaje de representaciones visuales genéricas a partir de datos de vídeo a gran escala basado en el aprendizaje autosupervisado sin etiquetado manual de los datos, lo que reduce el coste y mejora la generalización.
- Entrenamiento multietapa y predicción de las condiciones de movimientoV-JEPA 2: Basado en el entrenamiento multietapa, V-JEPA 2 pre-entrena el codificador y luego entrena el predictor de condiciones de movimiento, combinando información visual y de movimiento para apoyar un control predictivo preciso.
Personas a las que va dirigido el V-JEPA 2
- Investigadores en inteligencia artificial: Investigación académica e innovación tecnológica con la tecnología punta de V-JEPA 2 para fomentar la inteligencia de las máquinas.
- Ingeniero en robótica: Desarrollo de sistemas robóticos adaptados a nuevos entornos y tareas complejas con la ayuda de capacidades de planificación de modelos de muestra cero.
- Desarrollador de visión por ordenadorMejora la eficacia del análisis de vídeo con V-JEPA 2, utilizado en seguridad inteligente, automatización industrial y otros campos.
- experto en procesamiento del lenguaje natural (PLN): Combinación de modelos visuales y lingüísticos para desarrollar sistemas de interacción inteligentes, como asistentes virtuales y servicios de atención al cliente inteligentes.
- educador: Desarrollar herramientas educativas inmersivas basadas en funciones de concurso de vídeo para mejorar la enseñanza y el aprendizaje.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...