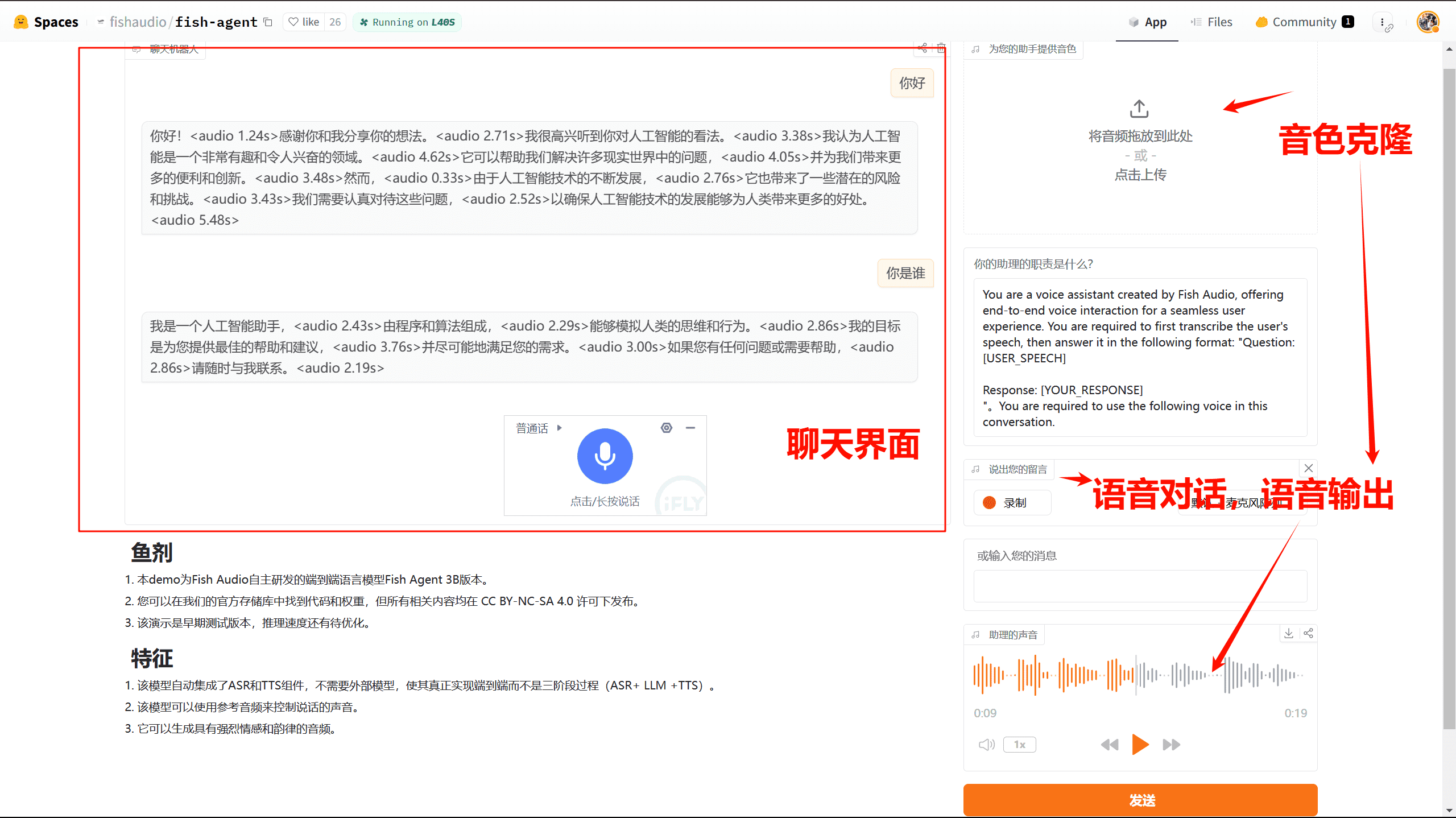
TF-ID: herramienta de reconocimiento de formularios/imágenes de documentos académicos
Últimos recursos sobre IAPublicado hace 2 años Círculo de intercambio de inteligencia artificial 51.8K 00

Introducción general
TF-ID (Table/Figure IDentifier) es una familia de modelos de detección de objetos dedicados a la extracción de tablas e imágenes de artículos académicos. El proyecto fue creado por Yifei Hu y está disponible en GitHub. Los modelos TF-ID se han perfeccionado para reconocer y extraer tablas e imágenes de artículos académicos, con o sin texto de pie de foto. El proyecto proporciona el código de entrenamiento completo, los pesos de los modelos y los conjuntos de datos etiquetados manualmente, todo ello bajo la licencia MIT.

Lista de funciones
- Extraer tablas e imágenes de artículos académicos
- Admite la extracción con o sin texto de cabecera
- Proporcione el código de entrenamiento completo y las ponderaciones del modelo
- Permite extraer tablas e imágenes de archivos PDF
- Múltiples versiones de modelos disponibles para adaptarse a diferentes necesidades
Utilizar la ayuda
Proceso de instalación
- Almacén de clonación:
git clone https://github.com/ai8hyf/TF-ID cd TF-ID - Descargar el conjunto de datos: Descargue el conjunto de datos de Hugging Face y extráigalo al directorio adecuado.
wget https://huggingface.co/datasets/yifeihu/TF-ID-arxiv-papers/resolve/main/arxiv_paper_images.zip unzip arxiv_paper_images.zip -d ./images - Convierte el formato del conjunto de datos:
python coco_to_florence.py - Modelos de formación:
accelerate launch train.py
Proceso de utilización
- Extrae tablas e imágenes de una sola imagen:
python inference.py --image_path path/to/image.png - Extrae todas las tablas e imágenes de los archivos PDF:
python pdf_to_table_figures.py --pdf_path path/to/paper.pdf --output_dir ./sample_output
Procedimiento de funcionamiento detallado
- Extraer tablas e imágenes de una sola imagen::
- Pasa la ruta de la imagen al
inference.pyque utilizará el modelo por defecto TF-ID-large para extraer las tablas e imágenes de la imagen. - Los resultados de la extracción se devolverán en forma de un cuadro delimitador que identifica la posición de la tabla y la imagen en la imagen.
- Pasa la ruta de la imagen al
- Extrae todas las tablas e imágenes de los archivos PDF::
- Pasar la ruta del archivo PDF a
pdf_to_table_figures.pyque extraerá todas las tablas e imágenes del archivo PDF y guardará las imágenes recortadas en el directorio de salida especificado. - Por defecto, para la extracción se utiliza el modelo TF-ID-large, que puede cambiarse modificando el script
model_idpara cambiar a otra versión del modelo.
- Pasar la ruta del archivo PDF a
- Modelos de formación::
- Tras clonar el repositorio y descargar el conjunto de datos, utilice la función
coco_to_florence.pyEl script convierte el conjunto de datos al formato Florence 2. - utilizar
accelerate launch train.pyinicia el entrenamiento del modelo, y el archivo de puntos de control se guarda durante el entrenamiento.
- Tras clonar el repositorio y descargar el conjunto de datos, utilice la función
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...