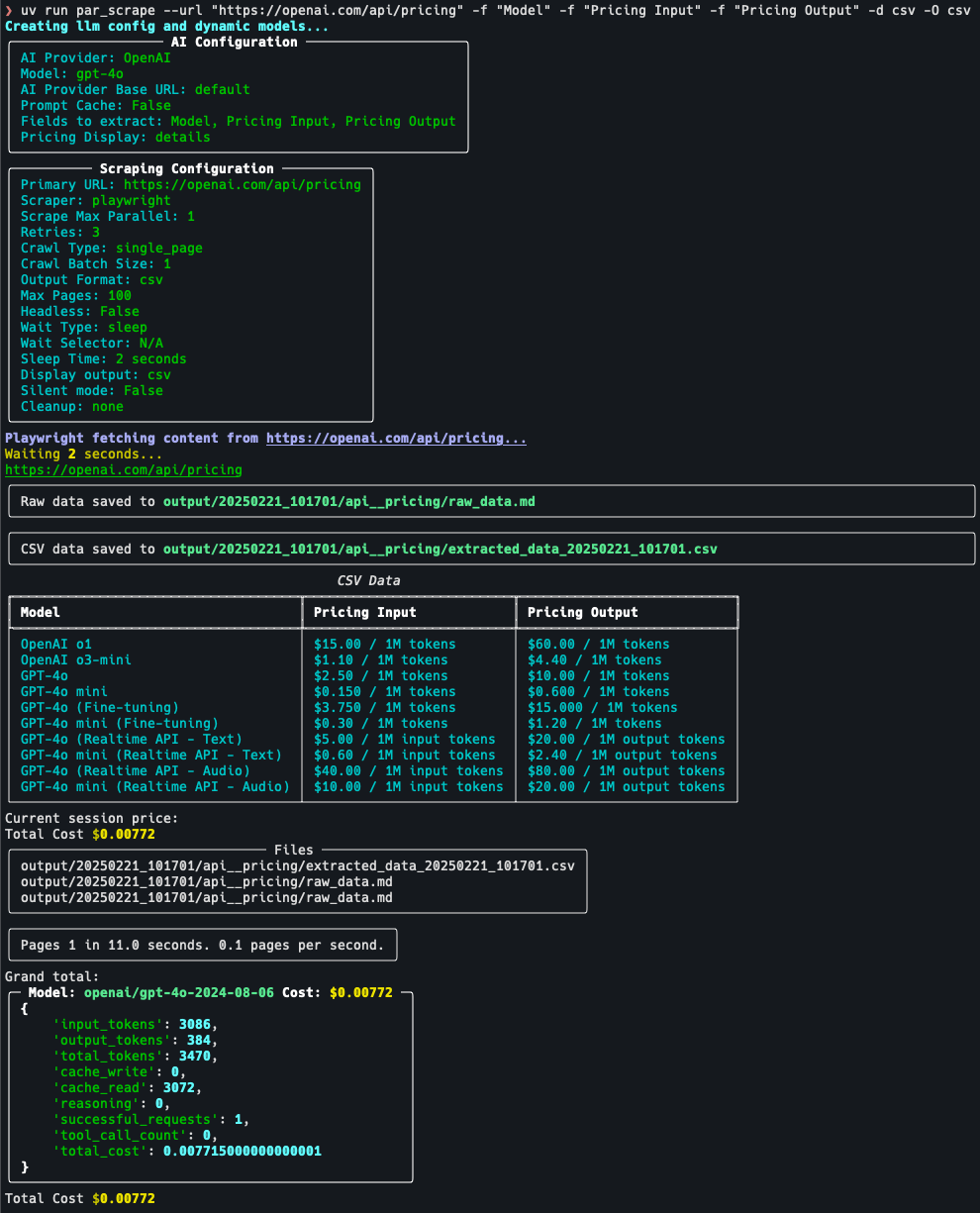
OneFileLLM: Integración de múltiples fuentes de datos en un único archivo de texto
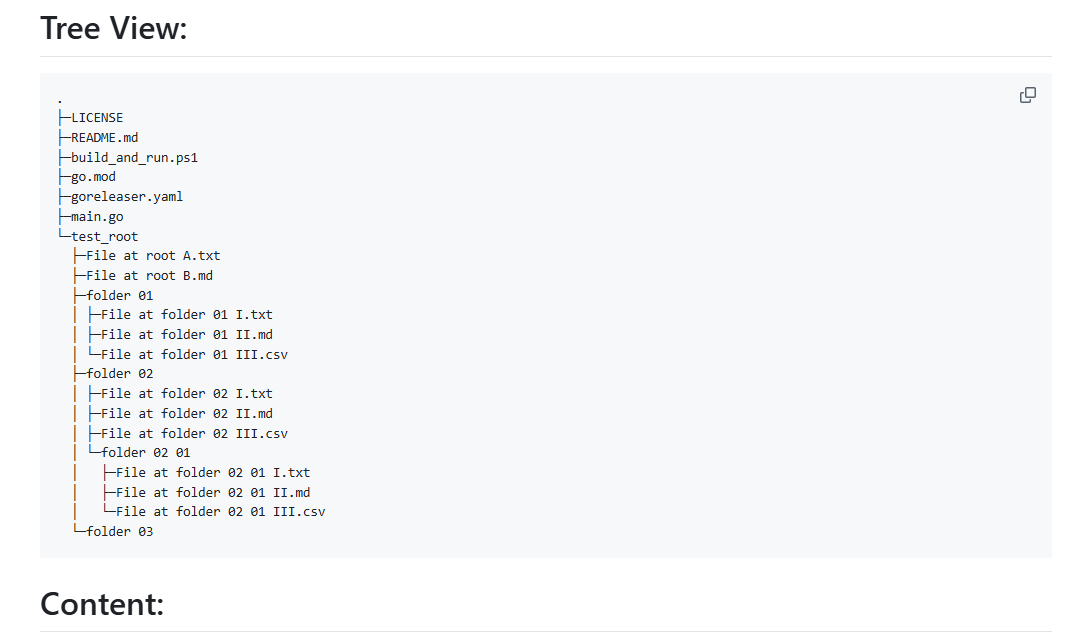
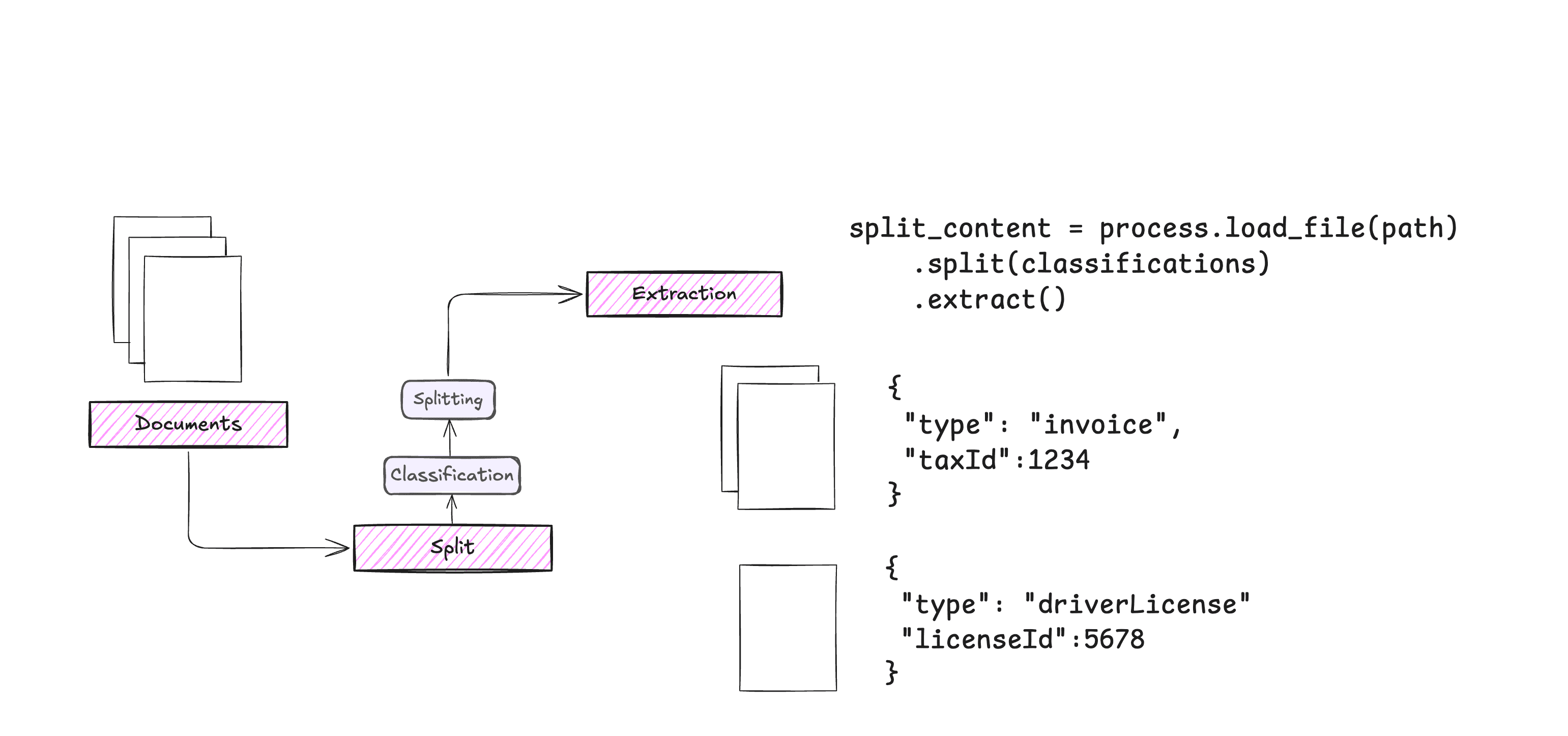
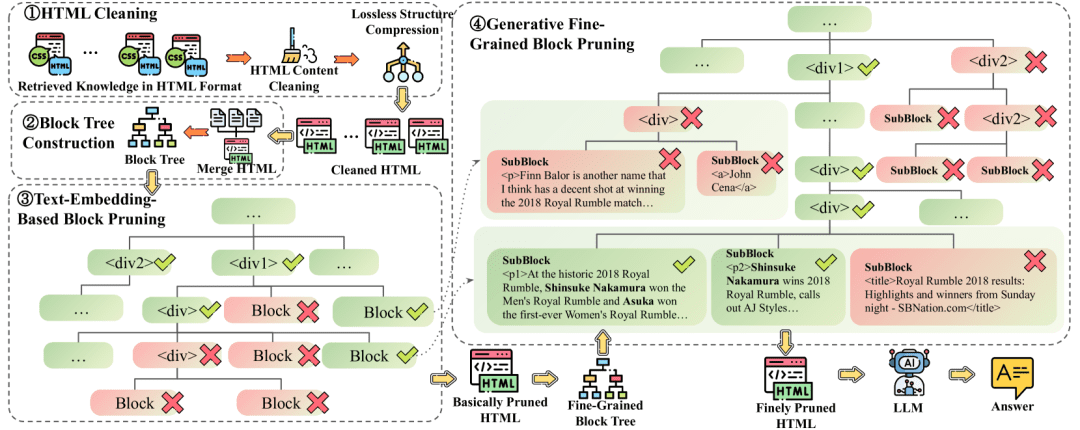
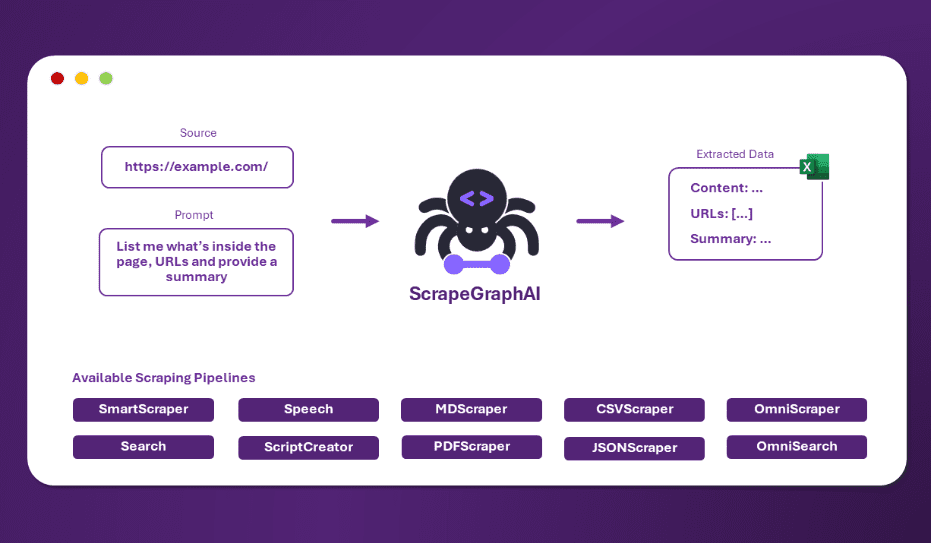
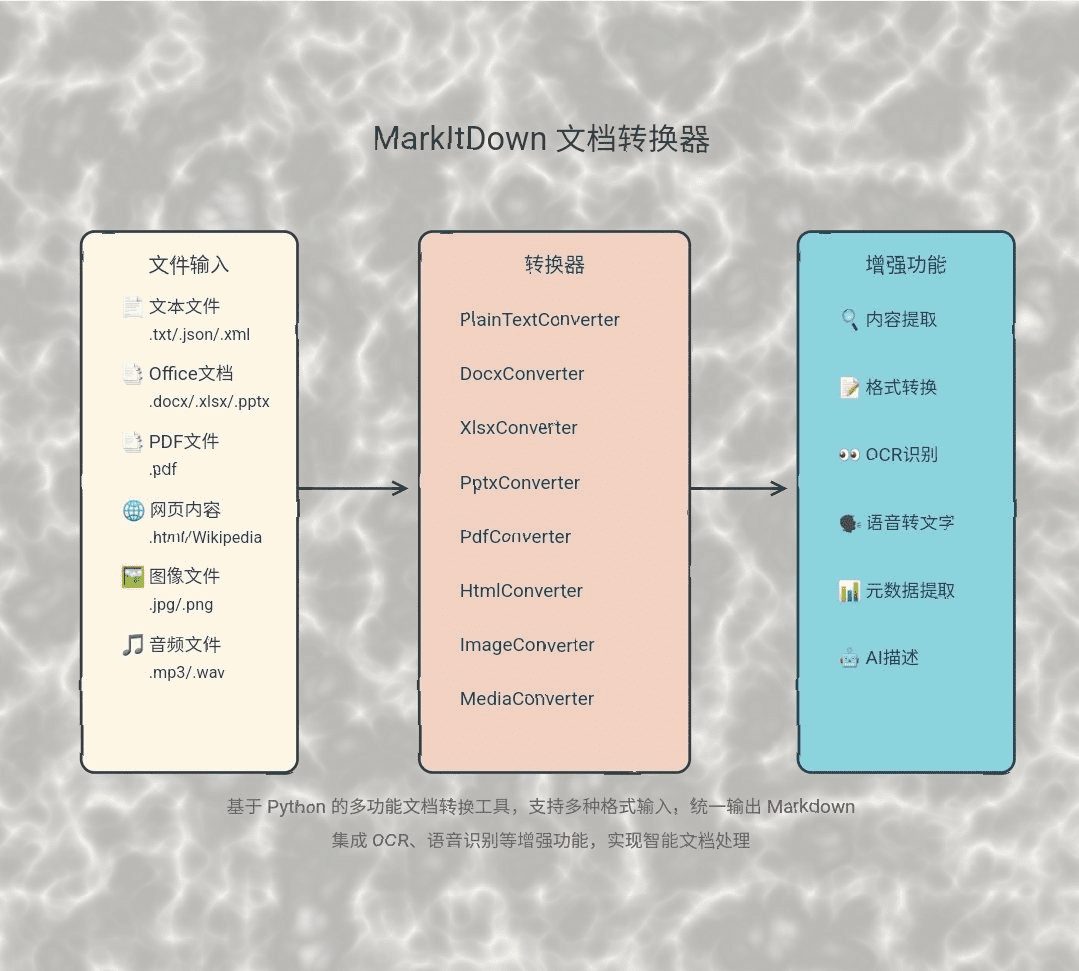
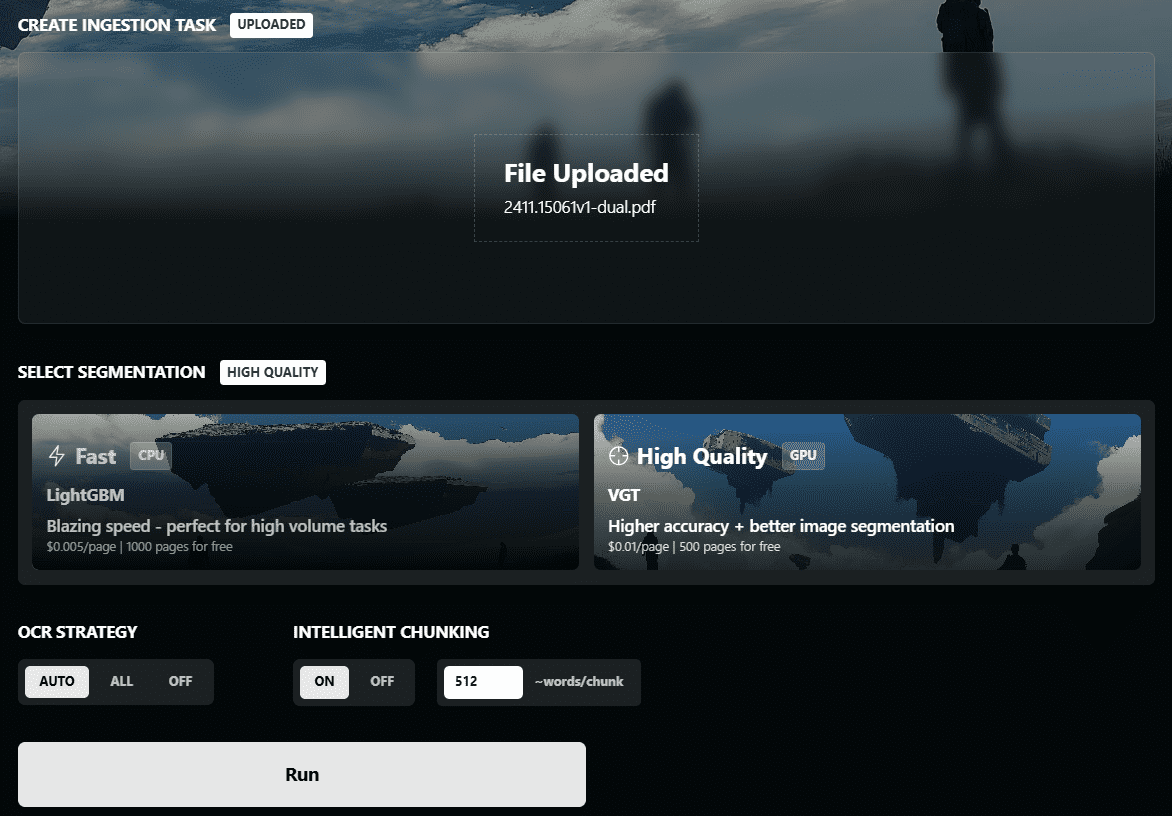
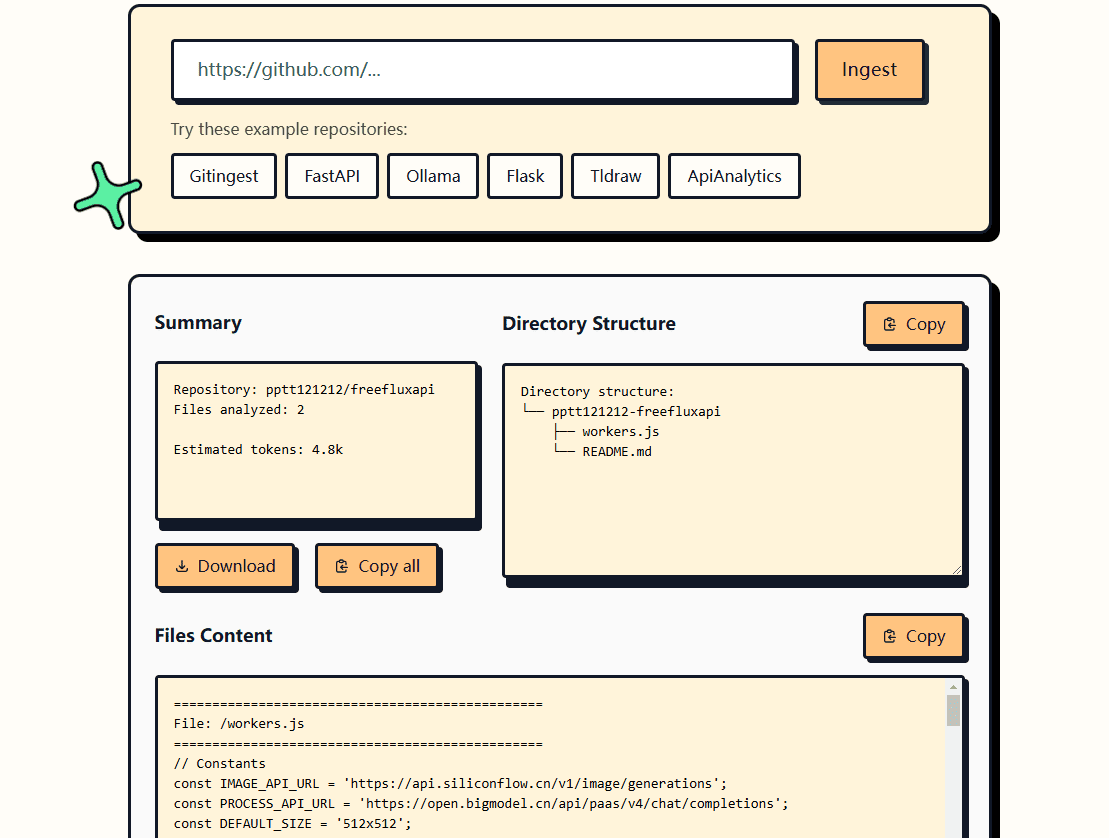
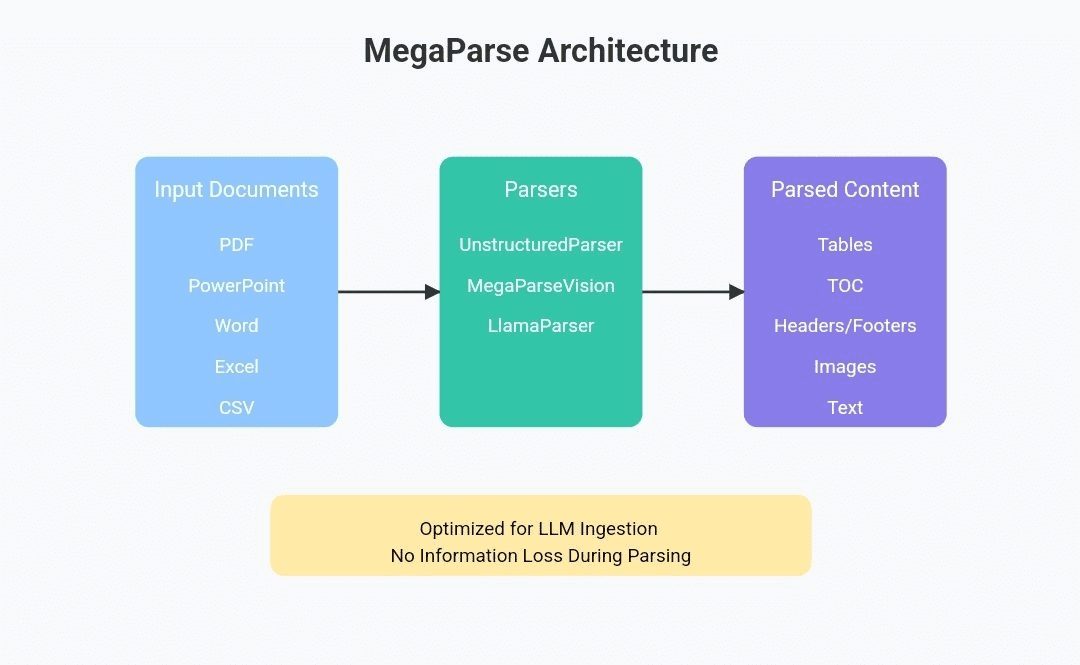
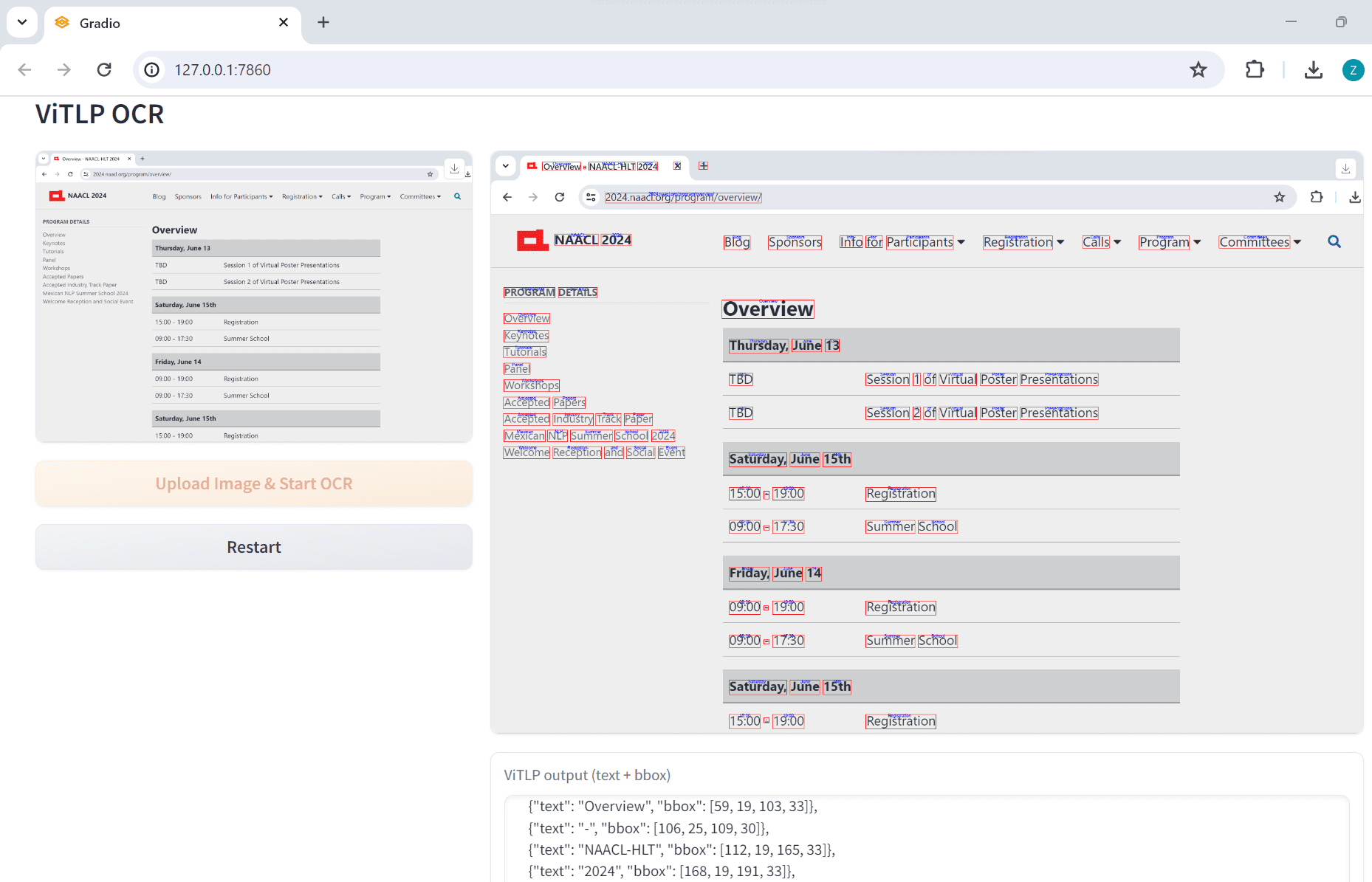
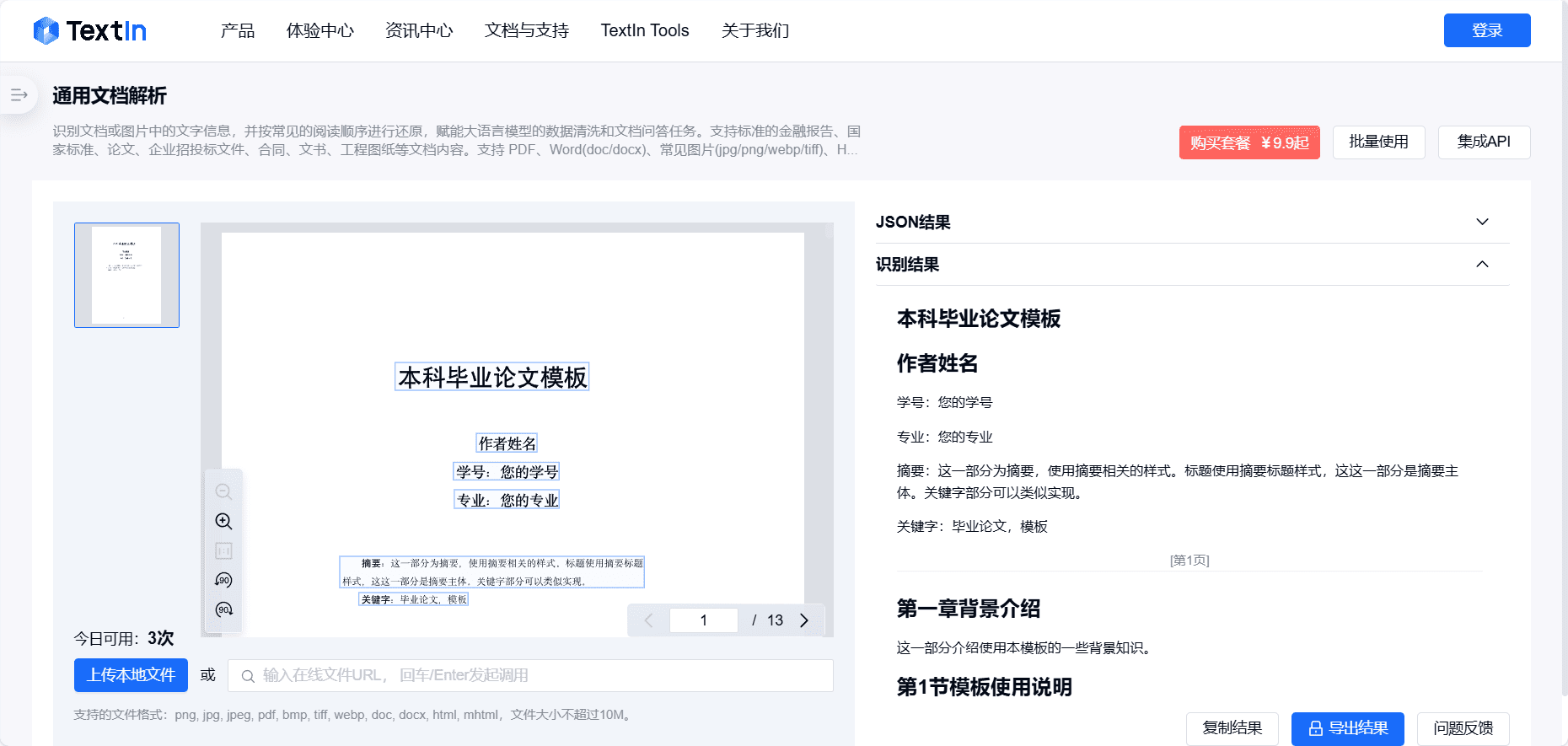
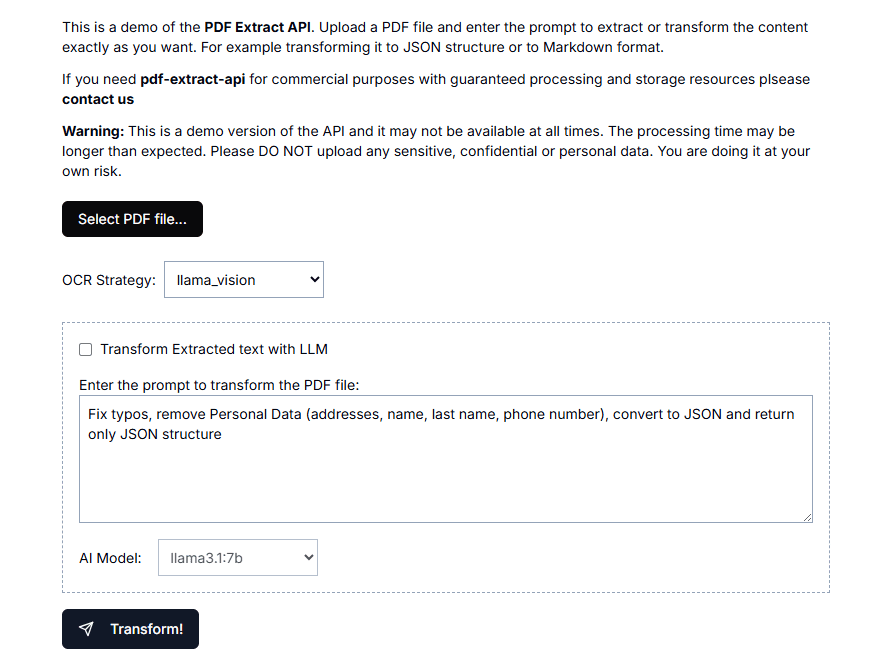
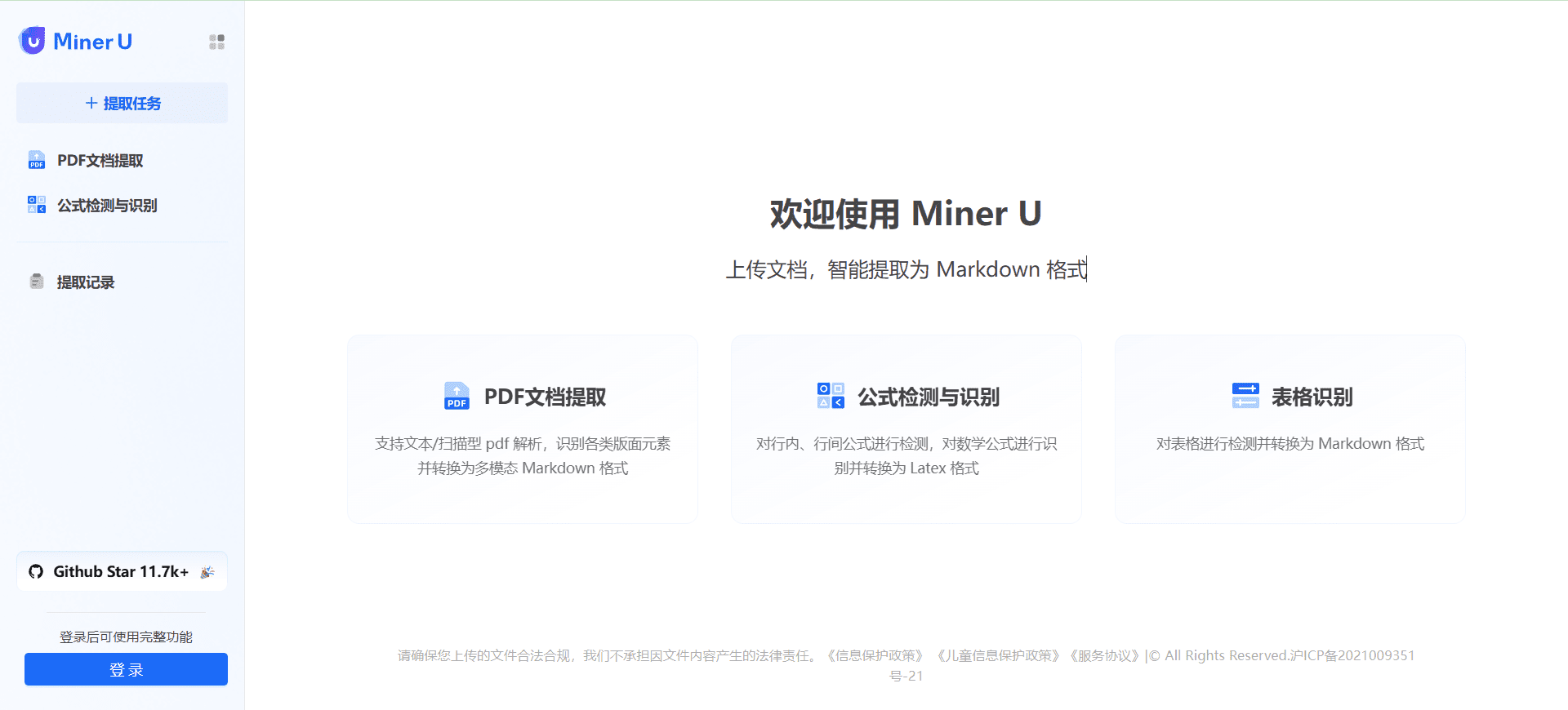
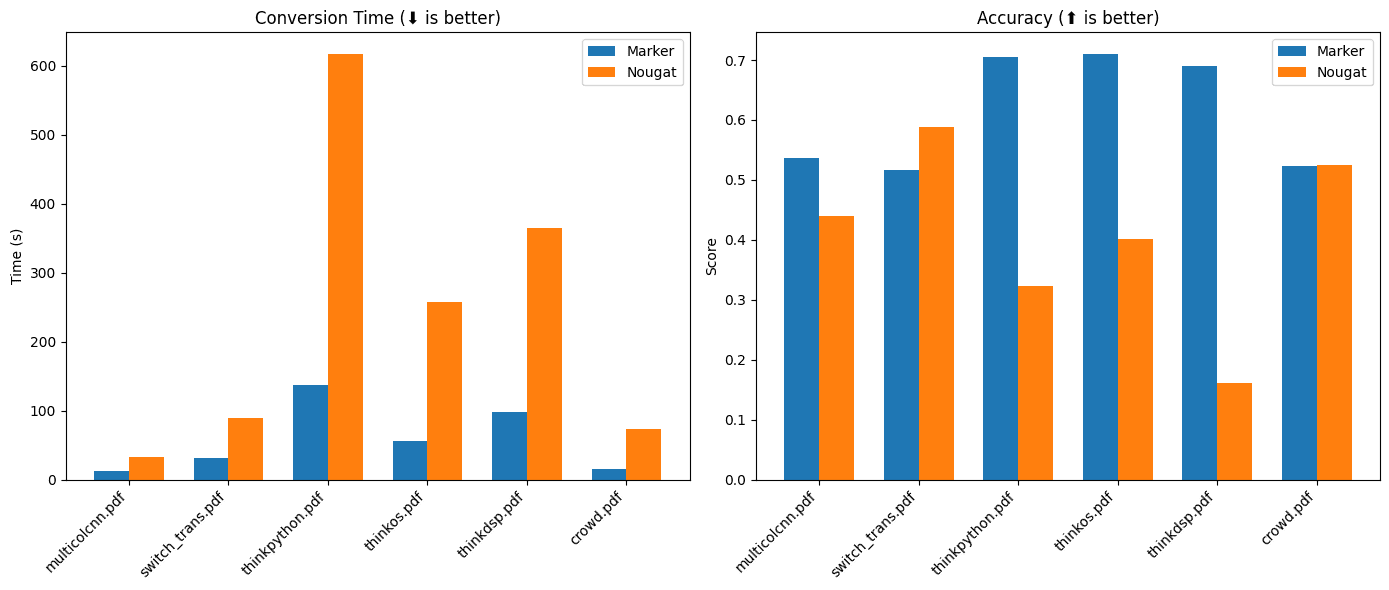
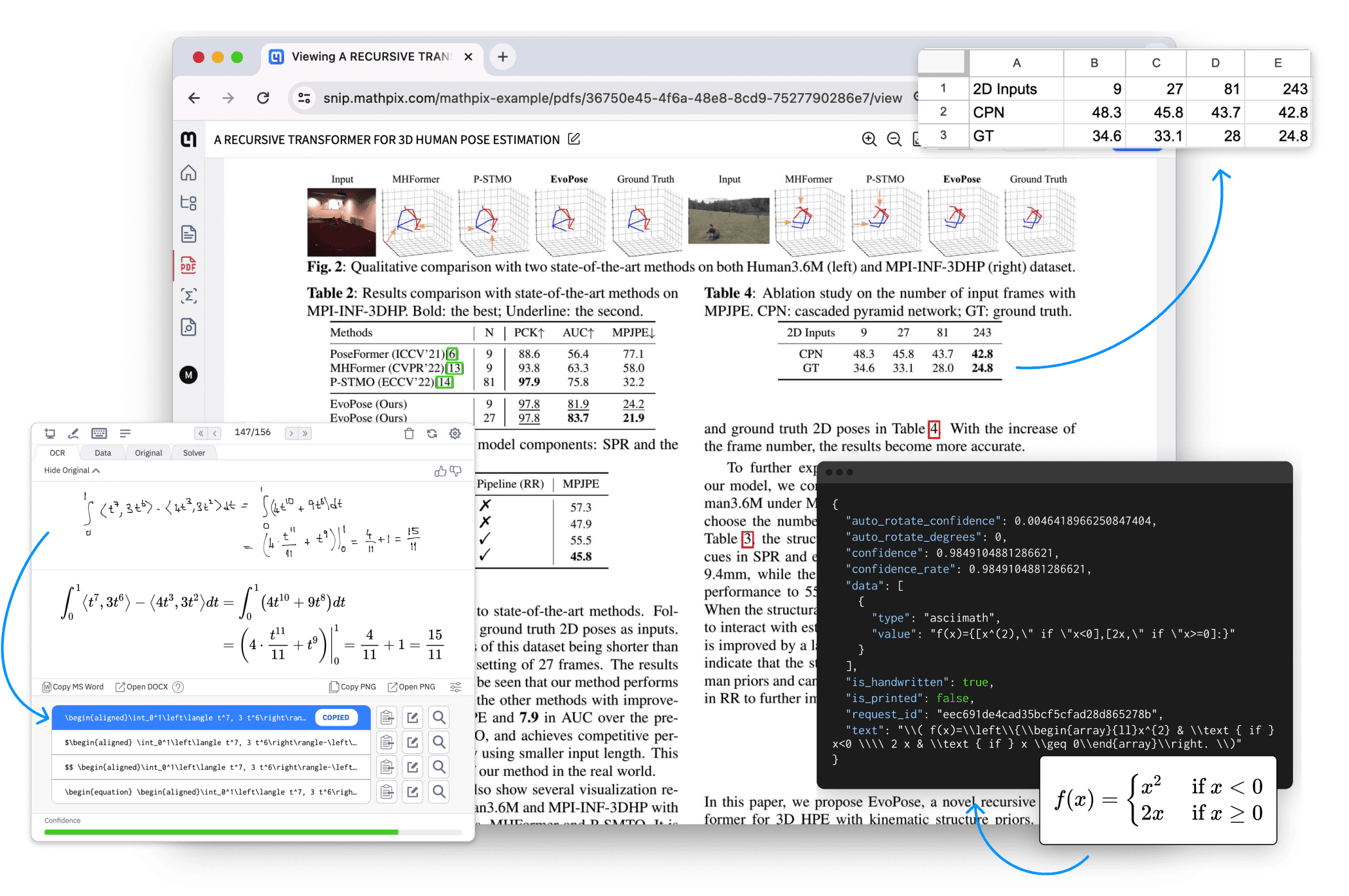
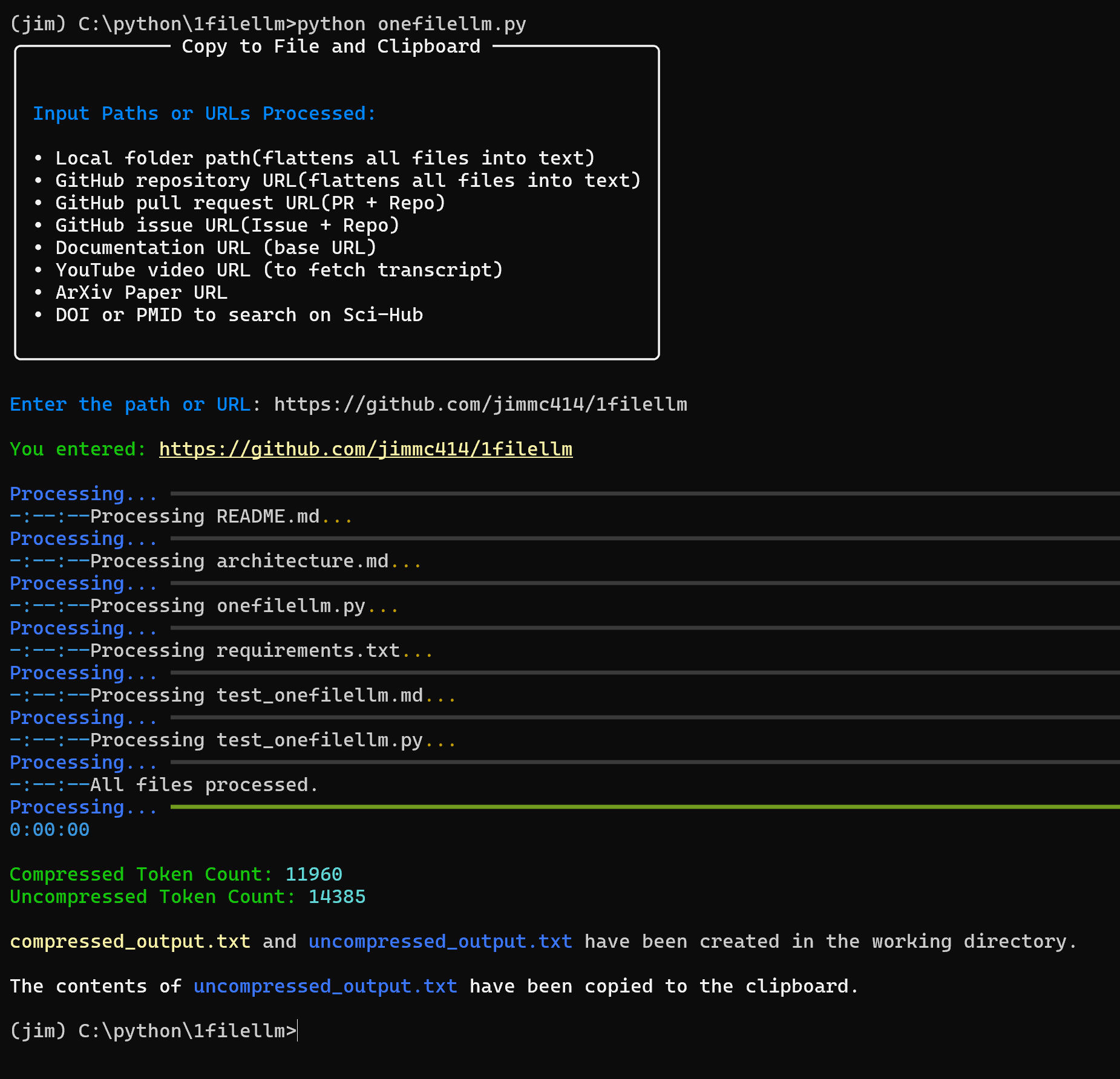
Introducción completa OneFileLLM es una herramienta de línea de comandos de código abierto diseñada para consolidar múltiples fuentes de datos en un único archivo de texto para facilitar la entrada en grandes modelos lingüísticos (LLM). Permite procesar repositorios de GitHub, artículos de ArXiv, transcripciones de vídeos de YouTube,...