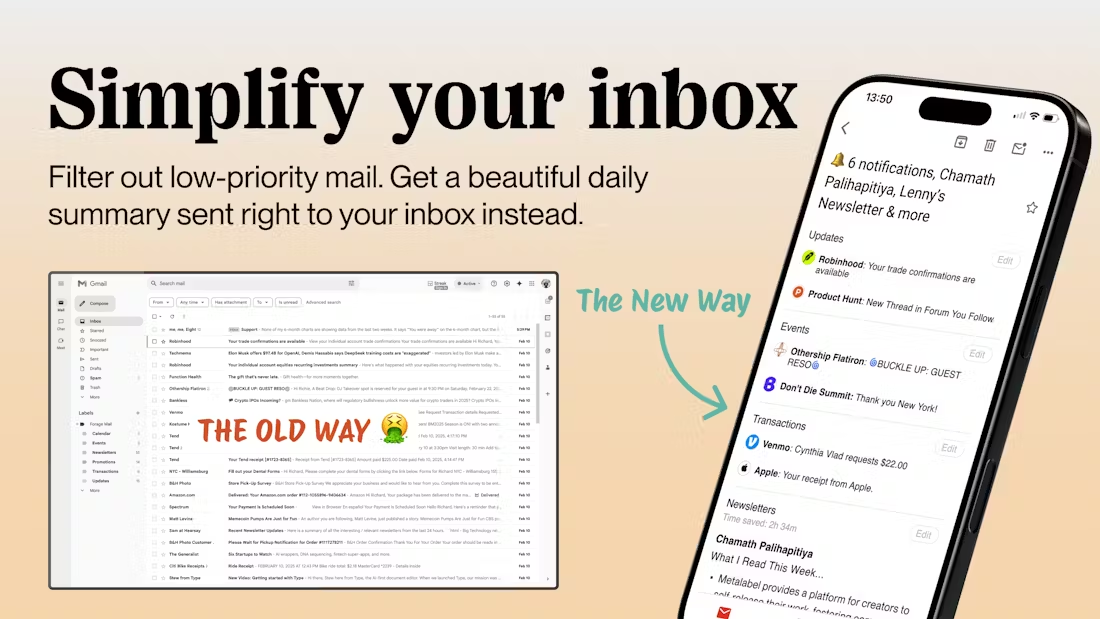
StreamingT2V: generación dinámica y escalable de texto a vídeo largo
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 58.3K 00

Introducción general
StreamingT2V es un proyecto público desarrollado por el equipo de investigación en IA de Picsart centrado en generar vídeos largos coherentes, dinámicos y escalables a partir de descripciones textuales. Esta tecnología utiliza un enfoque autorregresivo avanzado que garantiza un vídeo temporalmente coherente que se corresponde estrechamente con el texto de la descripción y mantiene una imagen de alta calidad de fotogramas. Es capaz de generar vídeos de hasta 1200 fps y hasta dos minutos de duración, con potencial para escalar a periodos de tiempo más largos. La eficacia de la técnica no está limitada por un modelo Text2Video específico, es decir, las mejoras en el modelo mejorarán aún más la calidad del vídeo.
StreamingT2V Experiencia en línea

Lista de funciones
Admite la generación de vídeos de hasta 1200 fps y hasta dos minutos de duración.
Mantiene la coherencia temporal del vídeo y de las imágenes de alta calidad de fotogramas
Generación dinámica de vídeos que se corresponden estrechamente con la descripción del texto
Admite múltiples aplicaciones del modelo Base para mejorar la calidad de los vídeos generados
Conversión de texto a vídeo y de imagen a vídeo
Demostración en línea de Gradio
Utilizar la ayuda
Clonar el repositorio del proyecto e instalar el entorno necesario
Descargar pesos y colocarlos en el catálogo correcto
Ejecutar código de ejemplo para la conversión de texto a vídeo o de imagen a vídeo
Consulte la página del proyecto para ver los resultados detallados y las demostraciones
tiempo de inferencia
ModelscopeT2V como modelo base
| frecuencia de imagen | Tiempo de inferencia de previsualización más rápido (256×256) | Tiempo de razonamiento para el resultado final (720×720) |
|---|---|---|
| 24 cuadros | 40 segundos. | 165 segundos. |
| 56 cuadros | 75 segundos | 360 segundos |
| 80 cuadros | 110 segundos. | 525 segundos. |
| 240 cuadros | 340 segundos. | 1610 segundos (unos 27 minutos) |
| 600 cuadros | 860 segundos. | 5128 segundos (unos 85 minutos) |
| 1200 cuadros. | 1710 segundos (unos 28 minutos) | 10225 segundos (unos 170 minutos) |
AnimateDiffcomo modelo base
| frecuencia de imagen | Tiempo de inferencia de previsualización más rápido (256×256) | Tiempo de razonamiento para el resultado final (720×720) |
|---|---|---|
| 24 cuadros | 50 segundos. | 180 segundos. |
| 56 cuadros | 85 segundos. | 370 segundos. |
| 80 cuadros | 120 segundos. | 535 segundos. |
| 240 cuadros | 350 segundos. | 1620 segundos (unos 27 minutos) |
| 600 cuadros | 870 segundos. | 5138 segundos (~85 minutos) |
| 1200 cuadros. | 1720 segundos (unos 28 minutos) | 10235 segundos (unos 170 minutos) |
SVDComo modelo básico
| frecuencia de imagen | Tiempo de inferencia de previsualización más rápido (256×256) | Tiempo de razonamiento para el resultado final (720×720) |
|---|---|---|
| 24 cuadros | 80 segundos. | 210 segundos. |
| 56 cuadros | 115 segundos. | 400 segundos. |
| 80 cuadros | 150 segundos. | 565 segundos. |
| 240 cuadros | 380 segundos. | 1650 segundos (unos 27 minutos) |
| 600 cuadros | 900 segundos. | 5168 segundos (~86 minutos) |
| 1200 cuadros. | 1750 segundos (aprox. 29 minutos) | 10265 segundos (~171 minutos) |
Todas las mediciones se realizaron con la GPU NVIDIA A100 (80 GB). Cuando el número de fotogramas superaba los 80, se utilizaba la mezcla aleatoria. Para la mezcla aleatoria, elchunk_sizey el valor deoverlap_sizese fijan en 112 y 32, respectivamente.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...