Step-Audio-AQAA - Modelo de gran lenguaje sonoro integral de StepFun
Últimos recursos sobre IAPublicado hace 9 meses Círculo de intercambio de inteligencia artificial 44.5K 00

¿Qué es Step-Audio-AQAA?
Step-Audio-AQAA es un modelo integral de lenguaje de audio a gran escala para tareas de consulta y respuesta de audio (AQAA) del equipo de StepFun. La capacidad de procesar directamente la entrada de audio para generar respuestas de voz naturales y precisas sin depender de los módulos tradicionales de reconocimiento automático del habla (ASR) y conversión de texto a voz (TTS) simplifica la arquitectura del sistema y elimina los errores en cascada. El proceso de entrenamiento de Step-Audio-AQAA incluye preentrenamiento multimodal, ajuste fino supervisado (SFT), optimización directa de preferencias (DPO) y fusión de modelos. Gracias a estos métodos, los modelos obtienen buenos resultados en tareas complejas como el control de la emoción del habla, el juego de roles y el razonamiento lógico. En la prueba de referencia StepEval-Audio-360, Step-Audio-AQAA supera a los modelos LALM existentes en varias dimensiones clave, lo que demuestra su gran potencial para la interacción del habla de extremo a extremo.
Características principales de Step-Audio-AQAA
- Procesamiento directo de entradas de audioEl módulo de reconocimiento automático de voz (ASR) y conversión de texto a voz (TTS) permite generar respuestas de voz directamente a partir de la entrada de audio sin procesar.
- Interacción por voz sin fisuras: Al ser compatible con la interacción voz a voz, los usuarios pueden hacer preguntas con su voz y el modelo responde directamente con ella, lo que aumenta la naturalidad y fluidez de la interacción.
- Ajuste del tono emocional: Ayuda para ajustar el tono emocional del discurso a nivel de frase, por ejemplo para expresar emociones como alegría, tristeza o seriedad.
- control de vozEl usuario puede ajustar la velocidad de la respuesta vocal en función de las necesidades del escenario.
- Control de tono y afinaciónLa voz: puede ajustar el tono y el timbre de la voz según las órdenes del usuario, adaptándose a distintos papeles o escenarios.
- interacción multilingüeCompatible con chino, inglés, japonés y otros idiomas para satisfacer las necesidades lingüísticas de los distintos usuarios.
- Soporte dialectalEl modelo se aplica a dialectos chinos como el sichuanés y el cantonés para mejorar su aplicabilidad en regiones específicas.
- control de emociones por voz: Puede generar respuestas vocales con emociones específicas en función del contexto y de las órdenes del usuario.
- juego de rol (juego): Apoya la interpretación de papeles específicos en un diálogo, por ejemplo, atención al cliente, profesor, amigo, etc., y la generación de respuestas de voz que se ajusten a las características del papel.
- Cuestionarios de razonamiento lógico y conocimientos: Puede realizar tareas complejas de razonamiento lógico y cuestionarios de conocimientos, generando respuestas de voz precisas.
- Salida de voz de alta calidad: Genera formas de onda de voz de alta fidelidad, naturales y suaves mediante vocodificadores neuronales para mejorar la experiencia del usuario.
- coherencia fonética: Mantiene la coherencia y consistencia del discurso en la producción de frases o párrafos largos, evitando las interrupciones del discurso o los cambios bruscos.
- Salida intercalada de texto y voz: Admite texto intercalado y salida de voz, lo que permite a los usuarios elegir respuestas de voz o de texto según sea necesario.
- Comprensión de entradas multimodalesComprende entradas mixtas que contienen habla y texto, generando respuestas verbales adecuadas.
Dirección del proyecto Step-Audio-AQAA
- Biblioteca de modelos HuggingFace:: https://huggingface.co/stepfun-ai/Step-Audio-AQAA
- Documento técnico arXiv:: https://arxiv.org/pdf/2506.08967
Principios técnicos de Step-Audio-AQAA
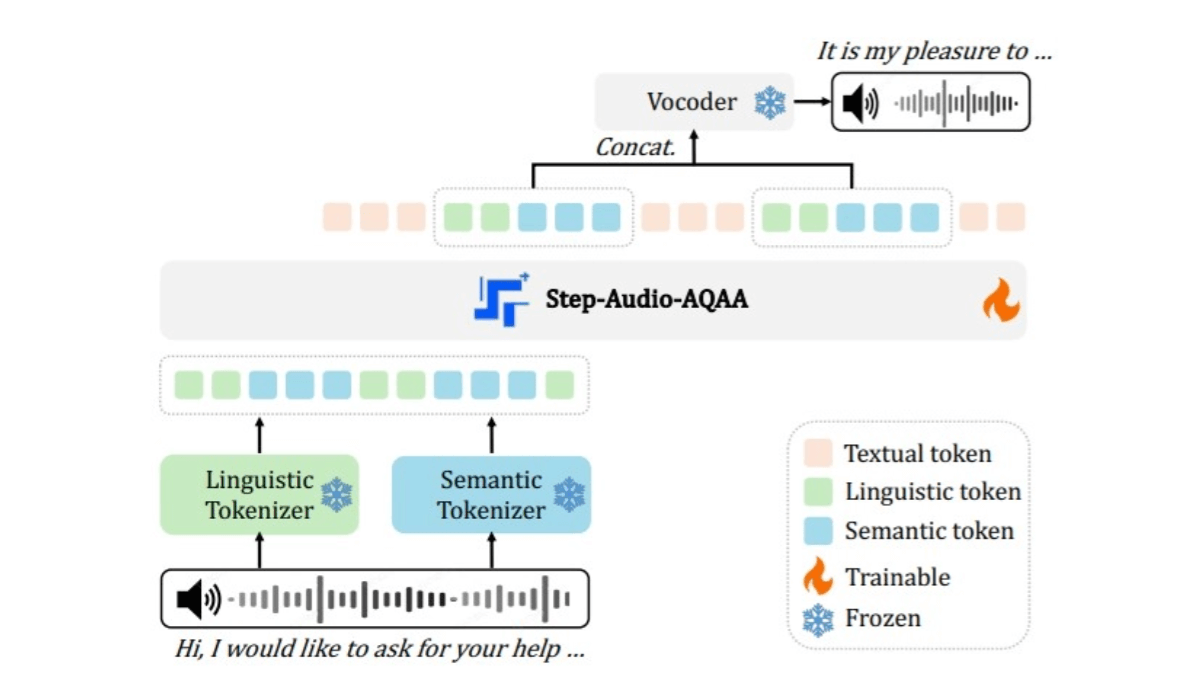
- Divisor de audio de doble libro de códigosConvertir la señal de audio de entrada en una secuencia estructurada de tokens. Consta de dos léxicos: un léxico lingüístico extrae fonemas y atributos lingüísticos del habla, muestreados a 16,7 Hz con un tamaño de libro de códigos de 1024, y un léxico semántico captura características acústicas del habla, como la emoción y la entonación, muestreadas a 25 Hz con un tamaño de libro de códigos de 4096, que es una forma mejor de captar la complejidad de la información del habla.
- Maestría en DerechoEl algoritmo se basa en un LLM multimodal (Step-Omni) preentrenado de 130.000 millones de parámetros. Los datos preentrenados abarcan tres modalidades: texto, voz e imagen. Los tokens bicodificados de texto y audio se incrustan en un espacio vectorial unificado por medio de múltiples... Transformador bloques para la comprensión semántica profunda y la extracción de características.
- vocoder neuralSintetiza los tokens de audio generados en formas de onda del habla naturales y de alta calidad. La arquitectura U-Net, combinada con la capa ResNet-1D y el bloque Transformer, convierte eficazmente los tokens de audio discretos en formas de onda de habla continuas.
Principales ventajas de Step-Audio-AQAA
- Interacción de audio de extremo a extremo: Step-Audio-AQAA genera respuestas de voz naturales y fluidas directamente a partir de la entrada de audio sin procesar, eliminando la necesidad de depender de los módulos tradicionales de reconocimiento automático de voz (ASR) y conversión de texto a voz (TTS). El diseño de extremo a extremo evita la distorsión de los resultados causada por los errores de ASR o TTS en las soluciones tradicionales.
- Soporte multilingüe: El modelo admite varios idiomas, como chino (incluidos el sichuanés y el cantonés), inglés, japonés, etc., que pueden satisfacer las necesidades lingüísticas de distintos usuarios.
- Control preciso de las funciones de voz: Step-Audio-AQAA permite un control preciso de las características de la voz, como la entonación emocional, la velocidad del habla, etc., para generar respuestas de voz más sensibles. Es especialmente eficaz en el control de las emociones vocales.
¿A quién va dirigido Step-Audio-AQAA?
- Usuarios de asistentes de voz inteligentesUsuarios que desean utilizar dispositivos de interacción por voz (por ejemplo, altavoces inteligentes, asistentes inteligentes) para operaciones cotidianas (por ejemplo, consultar información, establecer recordatorios, reproducir música, etc.).
- aficionado a los juegosJugadores a los que les gusta interactuar con los PNJ del juego para disfrutar de una experiencia de juego más envolvente.
- Usuarios educativos: Estudiantes y padres que desean aprender mediante la interacción por voz (por ejemplo, aprendizaje de idiomas, pruebas de conocimientos, etc.).
- Personas mayores y niñosLa interacción por voz es más cómoda y natural para los usuarios que no saben utilizar la introducción de texto.
- creador de audiolibrosCreadores que necesitan generar contenidos de voz de alta calidad, como audiolibros, obras radiofónicas, etc.
- productor de vídeoCreadores que necesitan interacción por voz o capacidades de generación de voz al producir contenidos de vídeo (por ejemplo, vídeos cortos, retransmisiones en directo).
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...