Despliegue rápido del RAG 3-Pack para Dify con GPUStack
Tutoriales prácticos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 75.7K 00

GPUStack Se trata de una plataforma de big model-as-a-service de código abierto que puede integrar y utilizar eficazmente diversos recursos heterogéneos de GPU/NPU como Nvidia, Apple Metal, Huawei Rise y Moore Threads para proporcionar un despliegue privado local de soluciones de big model.
GPUStack puede soportar RAG Los tres modelos clave requeridos en el sistema: el modelo de diálogo Chat (un gran modelo lingüístico), el modelo de incrustación de texto Embedding y el modelo de reordenación Rerank están disponibles en una suite de tres piezas, y es una operación muy sencilla e infalible desplegar los modelos privados locales requeridos por el sistema RAG.
A continuación se explica cómo instalar GPUStack y Dify con el programa Dify para interactuar con el modelo de diálogo, el modelo Embedding y el modelo Reranker desplegados por GPUStack.
Instalación de GPUStack
Instale en línea en Linux o macOS con los siguientes comandos, se requiere una contraseña sudo durante el proceso de instalación: curl -sfL https://get.gpustack.ai | sh -
Si su entorno no está conectado a GitHub y no puede descargar algunos binarios, utilice el siguiente comando para instalarlos con el comando --tools-download-base-url El parámetro especifica que se descargue desde Tencent Cloud Object Storage:curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Ejecute Powershell como administrador en Windows e instálelo en línea con el siguiente comando:Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
Si su entorno no está conectado a GitHub y no puede descargar algunos binarios, utilice el siguiente comando para instalarlos con el comando --tools-download-base-url El parámetro especifica que se descargue desde Tencent Cloud Object Storage:Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
Cuando vea la siguiente salida, el GPUStack se ha desplegado e iniciado correctamente:
[INFO] Install complete. GPUStack UI is available at http://localhost. Default username is 'admin'. To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'. CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
A continuación, siga las instrucciones de la salida del script para obtener la contraseña inicial para iniciar sesión en GPUStack y ejecute el siguiente comando:
en Linux o macOS:cat /var/lib/gpustack/initial_admin_password
En Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustackinitial_admin_password") -Raw
Acceda a la interfaz de usuario de GPUStack en un navegador con el nombre de usuario admin y la contraseña como la inicial obtenida anteriormente.
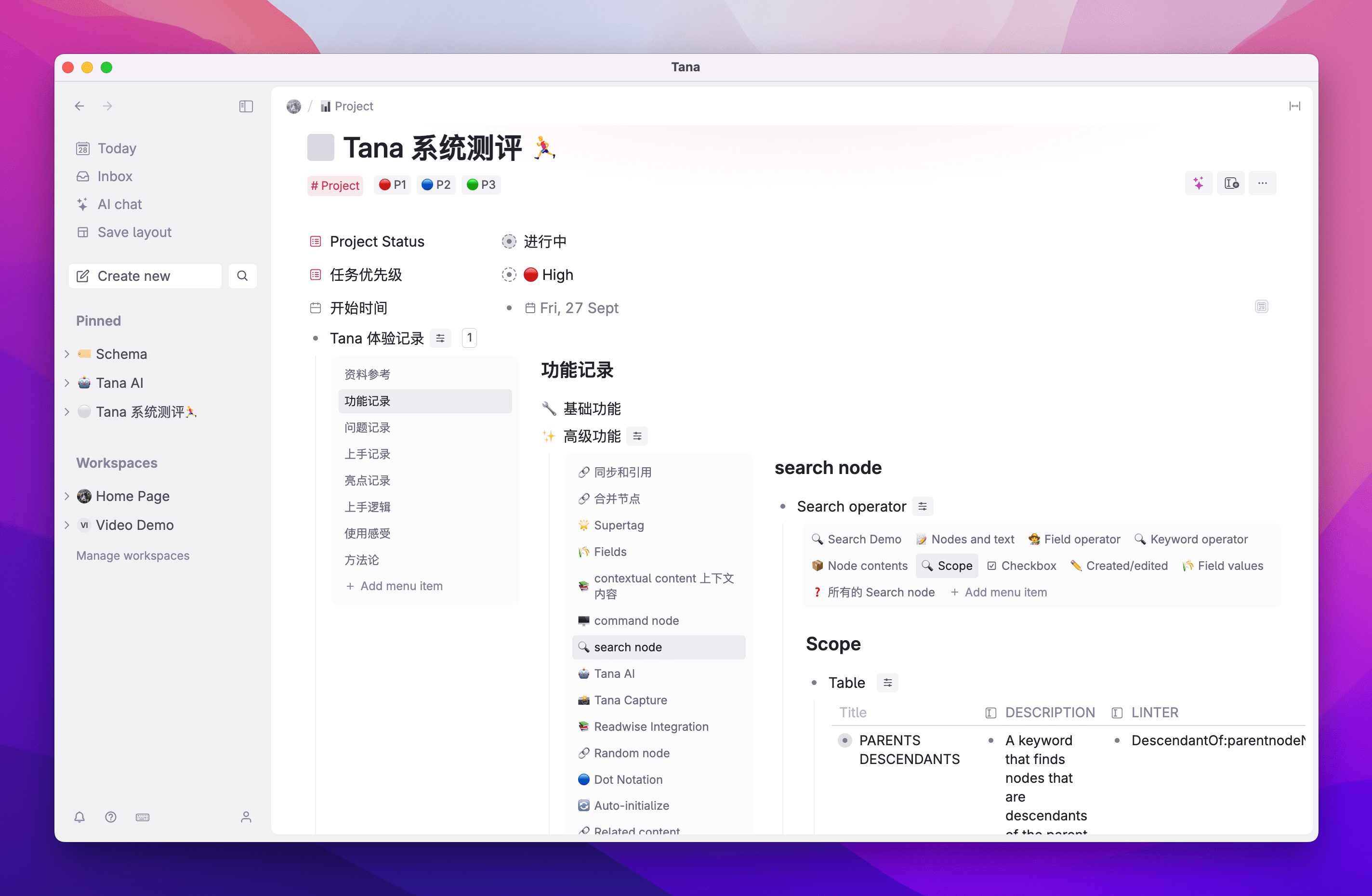
Después de restablecer la contraseña, introduzca GPUStack:
Nanogestión Recursos GPU
GPUStack admite recursos de GPU para dispositivos Linux, Windows y macOS, y gestiona estos recursos de GPU siguiendo estos pasos.
Otros nodos deben autenticarse Ficha Únase al cluster GPUStack y ejecute el siguiente comando en el nodo GPUStack Server para obtener un Token:
en Linux o macOS:cat /var/lib/gpustack/token
En Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustacktoken") -Raw
Una vez que tengas el Token, ejecuta el siguiente comando en los otros nodos para añadir el Worker al GPUStack, y nanomanejar las GPUs en esos nodos (sustituye http://YOUR_IP_ADDRESS por tu dirección de acceso al GPUStack y YOUR_TOKEN por el Token de autenticación utilizado para añadir el Worker):
en Linux o macOS:curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
En Windows:Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
Con los pasos anteriores, hemos creado un entorno GPUStack y gestionado múltiples nodos GPU, que luego se pueden utilizar para desplegar grandes modelos privados.
Despliegue de macromodelos privados
Visite GPUStack y despliegue modelos en el menú Modelos. GPUStack soporta el despliegue de modelos desde HuggingFace, Ollama Library, ModelScope y repositorios de modelos privados; ModelScope se recomienda para redes domésticas.
Soporte GPUStack vLLM y llama-box, vLLM está optimizado para la inferencia de producción y se adapta mejor a las necesidades de producción en términos de concurrencia y rendimiento, pero vLLM sólo es compatible con Linux. llama-box es un motor de inferencia flexible y compatible con múltiples plataformas que es llama.cpp Es compatible con sistemas Linux, Windows y macOS, y admite no solo entornos de GPU, sino también de CPU para ejecutar modelos de gran tamaño, lo que lo hace más adecuado para escenarios que requieren compatibilidad multiplataforma.
GPUStack selecciona automáticamente el backend de inferencia apropiado basándose en el tipo de archivo del modelo al desplegarlo. GPUStack utiliza llama-box como backend para ejecutar el servicio del modelo si éste está en formato GGUF, y vLLM como backend para ejecutar el servicio del modelo si está en formato no GGUF.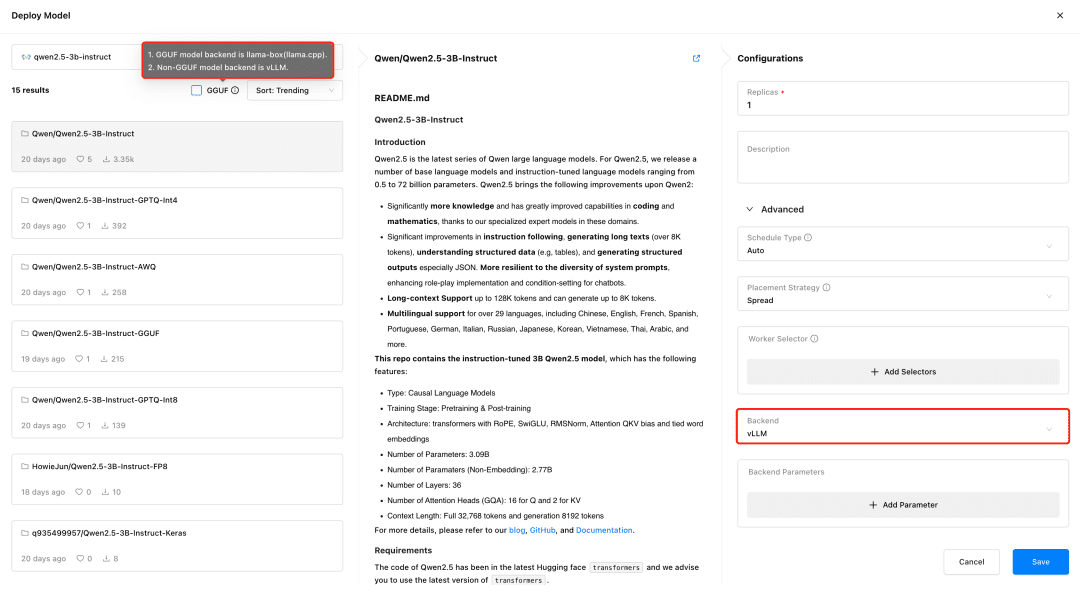
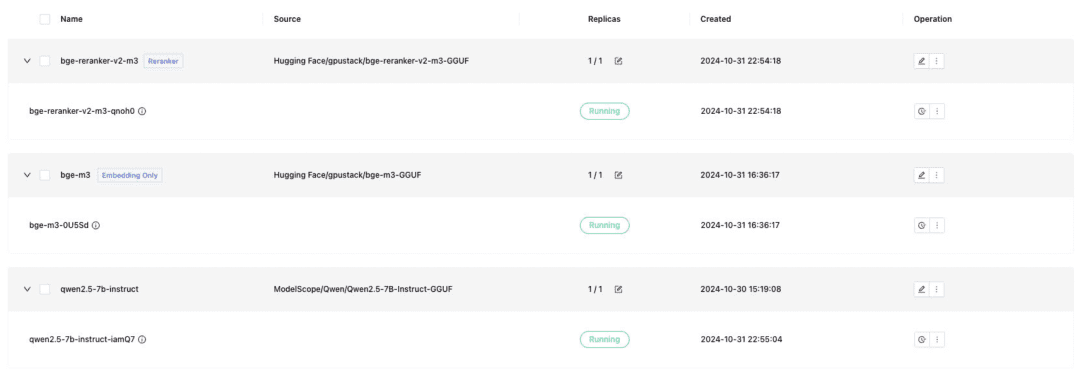
Despliegue el modelo de diálogo de texto, el modelo de incrustación de texto y el modelo Reranker necesarios para el acoplamiento de Dify, y recuerde comprobar el formato GGUF al desplegar:
- Qwen/Qwen2.5-7B-Instrucción-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
GPUStack también admite modelos multimodales VLM, cuyo despliegue requiere el uso de un backend de inferencia vLLM:
Qwen2-VL-2B-Instrucciones 

Una vez desplegado el modelo, un sistema RAG u otra aplicación de IA generativa puede interactuar con el modelo desplegado de GPUStack a través de la API compatible con OpenAI / Jina proporcionada por GPUStack, seguida de Dify para interactuar con el modelo desplegado de GPUStack.
Integración Dify Modelos GPUStack
Instalar Dify
Para ejecutar Dify utilizando Docker, es necesario preparar un entorno Docker, y tener cuidado de evitar conflictos entre Dify y el puerto 80 de GPUStack, utilizar otros hosts o modificar el puerto. Ejecute el siguiente comando para instalar Dify:git clone -b 0.10.1 https://github.com/langgenius/dify.gitVisite la interfaz de usuario de Dify en http://localhost para inicializar la cuenta de administrador e iniciar sesión.
cd dify/docker/
cp .env.example .env
docker compose up -d
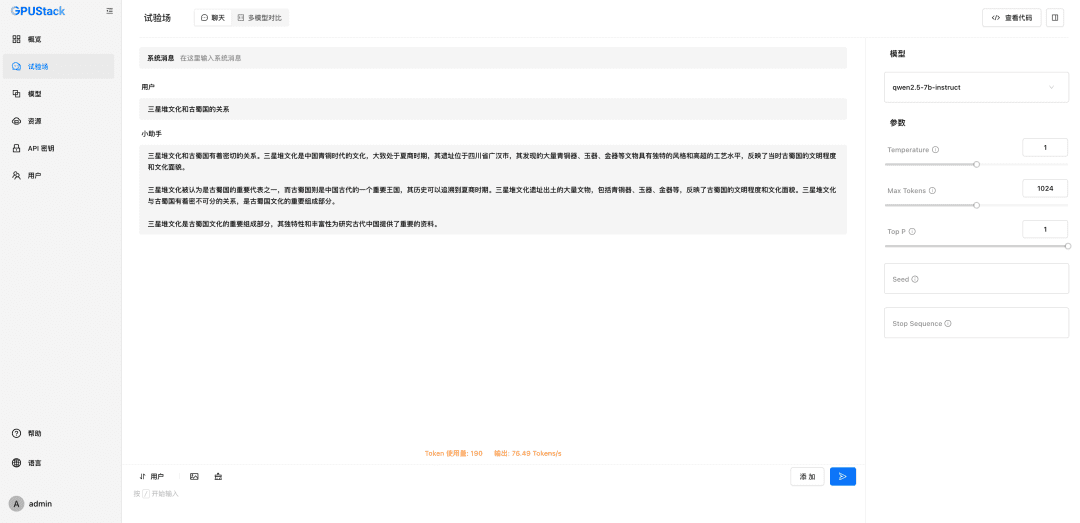
Para integrar un modelo GPUStack primero agregue un modelo de diálogo de Chat, en la esquina superior derecha de Dify seleccione "Configuración - Proveedores de Modelos", encuentre el tipo GPUStack en la lista y seleccione Agregar Modelo:
Rellene el nombre del modelo LLM desplegado en el GPUStack (por ejemplo, qwen2.5-7b-instruct), la dirección de acceso del GPUStack (por ejemplo, http://192.168.0.111) y la clave API generada, y las longitudes de contexto de los ajustes del modelo 8192 y max. fichas 2048: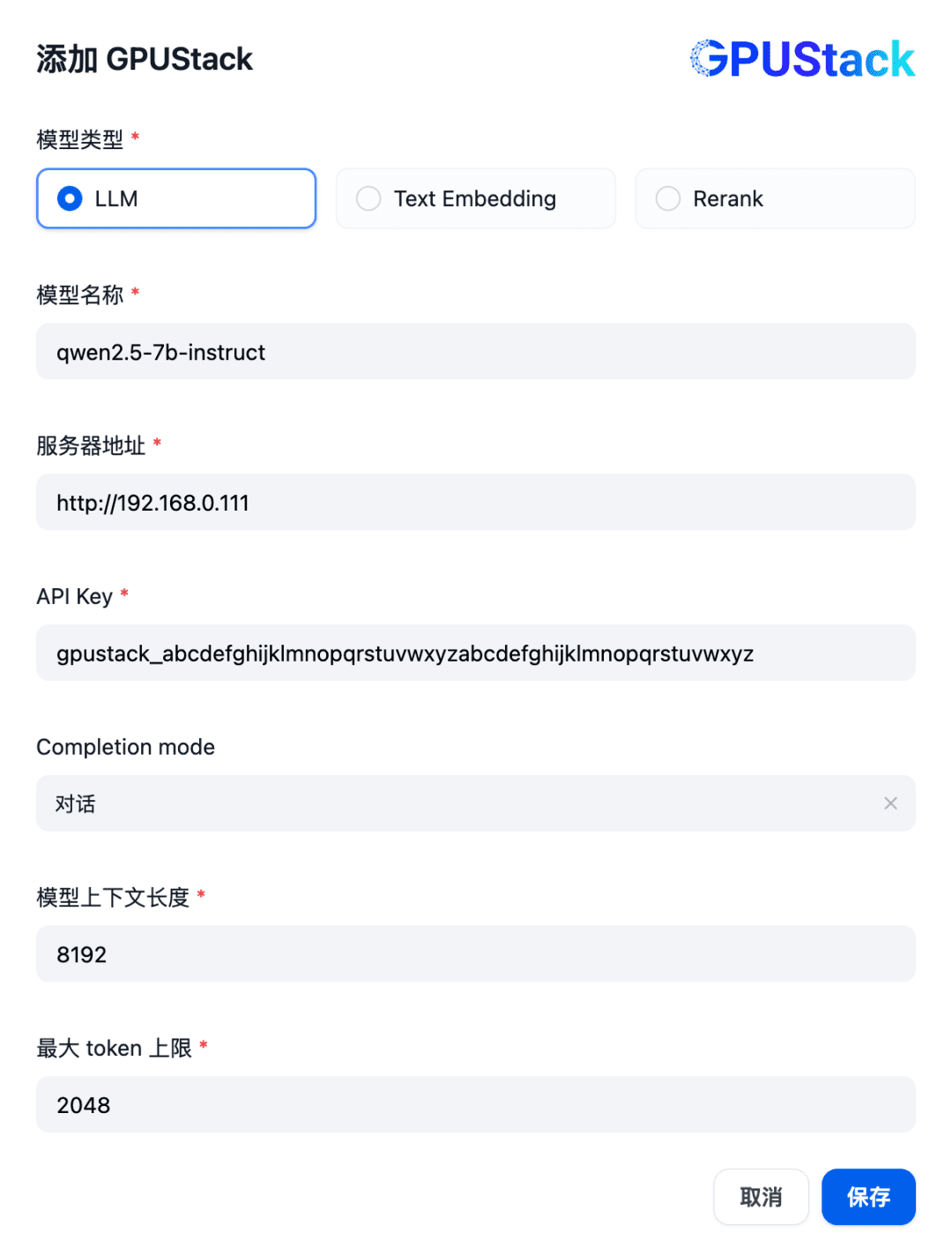
A continuación, añada el modelo de incrustación, en la parte superior del proveedor de modelos siga adelante y seleccione el tipo GPUStack y seleccione Añadir modelo: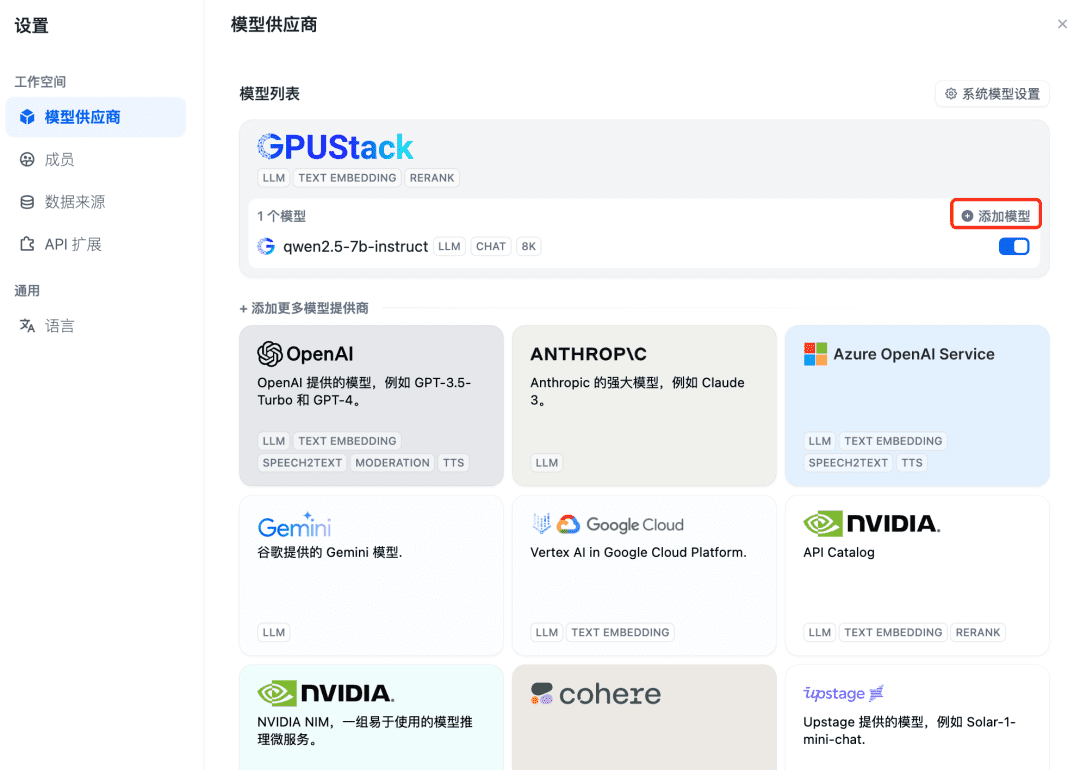
Añada un modelo de tipo Text Embedding, rellenando el nombre del modelo Embedding desplegado en el GPUStack (por ejemplo, bge-m3), la dirección de acceso del GPUStack (por ejemplo, http://192.168.0.111) y la API Key generada, y una longitud de contexto de 8192 para la configuración del modelo: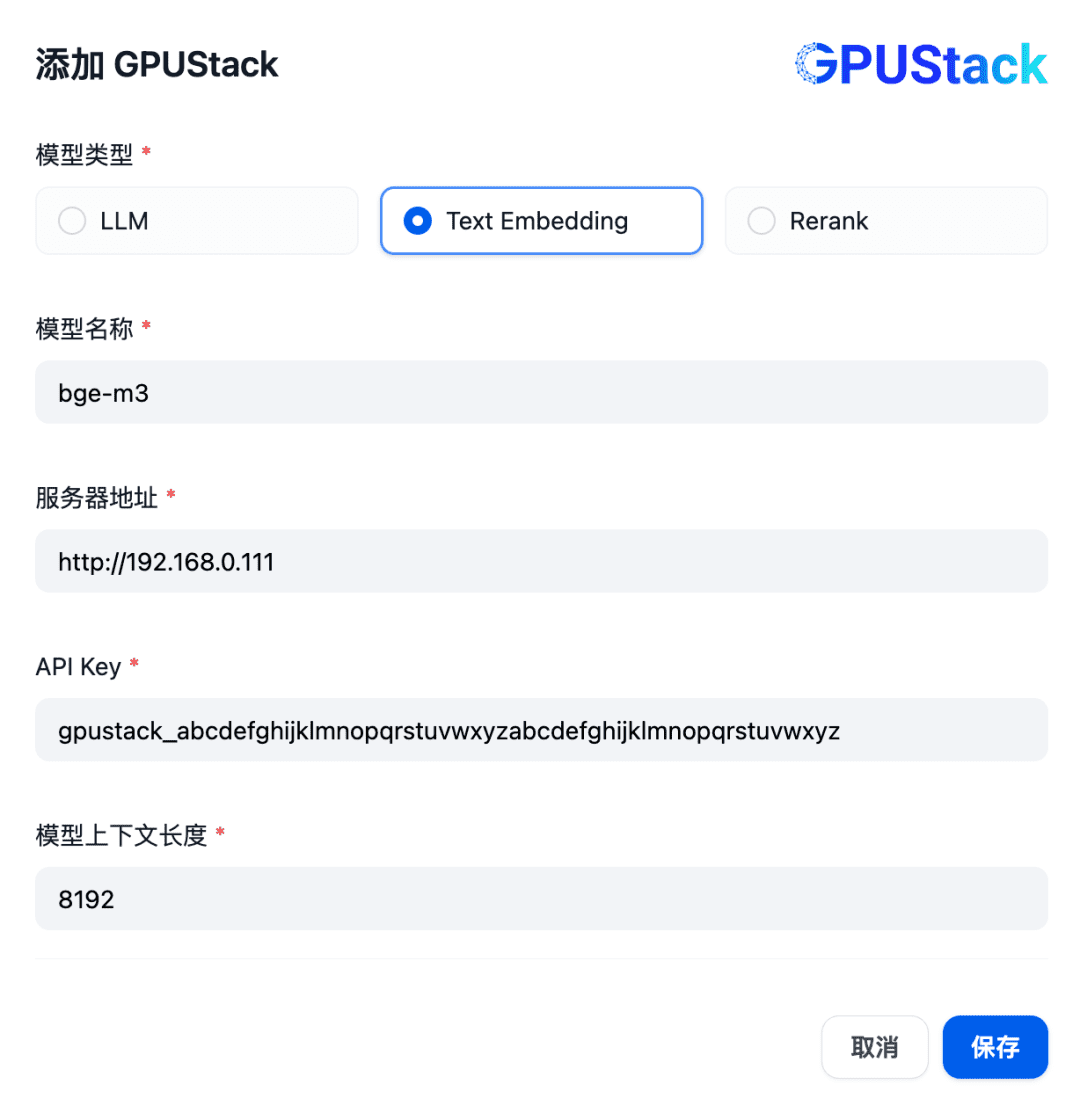
A continuación, para añadir un modelo Rerank, siga adelante y seleccione el tipo de GPUStack, seleccione Añadir modelo, añada un modelo de tipo Rerank, rellene el nombre del modelo Rerank desplegado en el GPUStack (por ejemplo, bge-reranker-v2-m3), la dirección de acceso del GPUStack (por ejemplo, http://192.168. 0.111) y la clave API generada, así como la longitud de contexto 8192 para la configuración del modelo: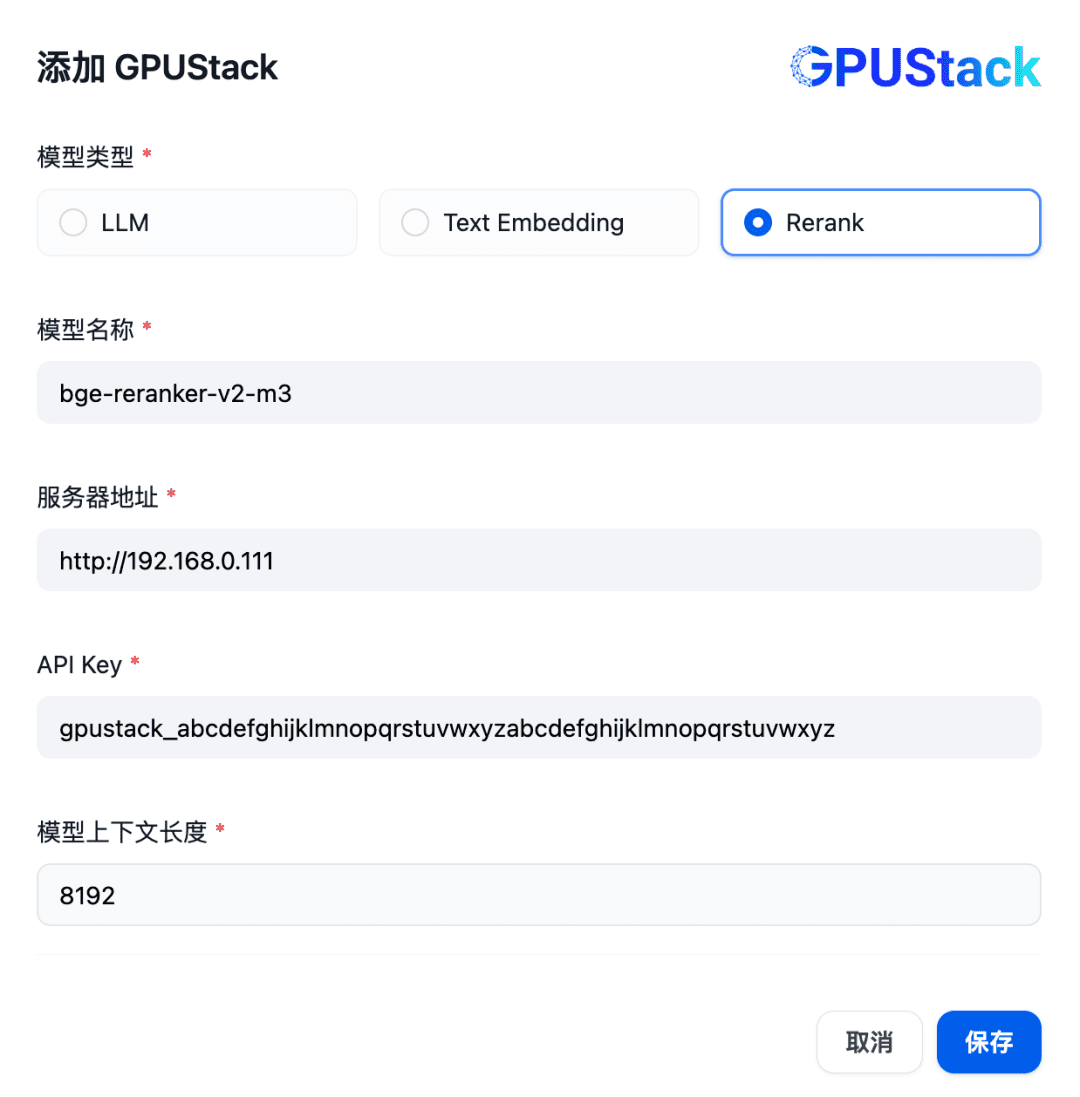
Actualice después de añadir y confirme en el proveedor de modelos que los modelos del sistema están configurados para los tres modelos añadidos anteriormente: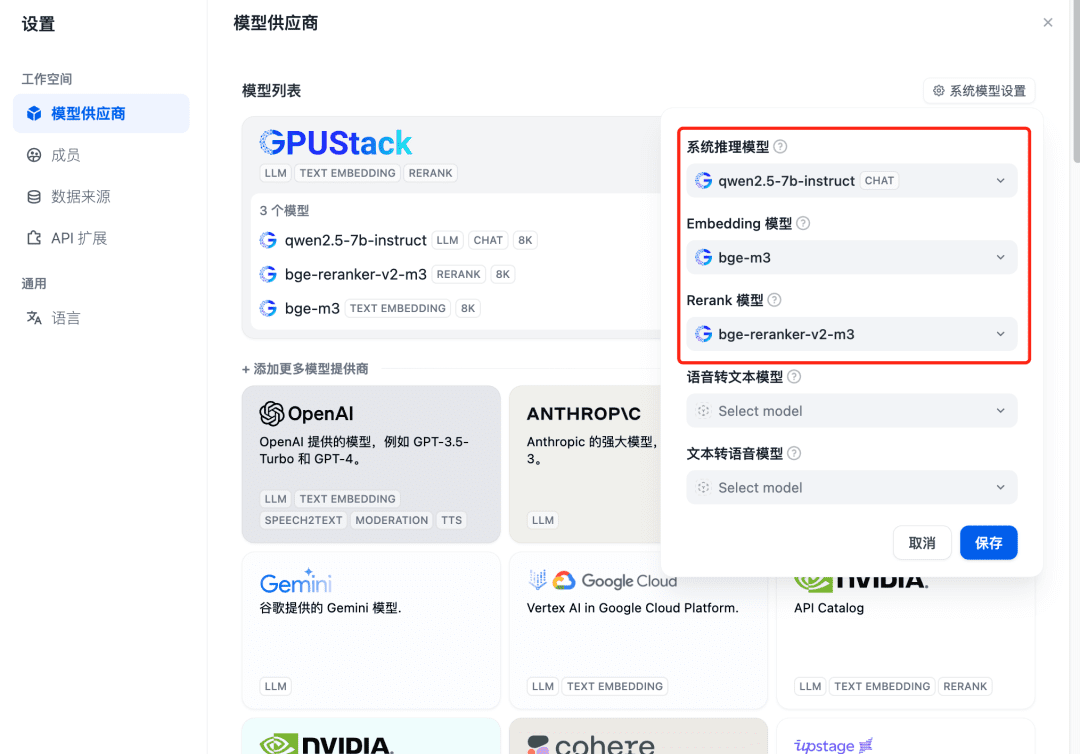
Uso de modelos en el sistema RAG Seleccione la Base de conocimientos de Dfiy, seleccione Crear base de conocimientos, importe un archivo de texto, confirme la opción Modelo de incrustación, utilice la búsqueda híbrida recomendada para la configuración de búsqueda y active el modelo Rerank: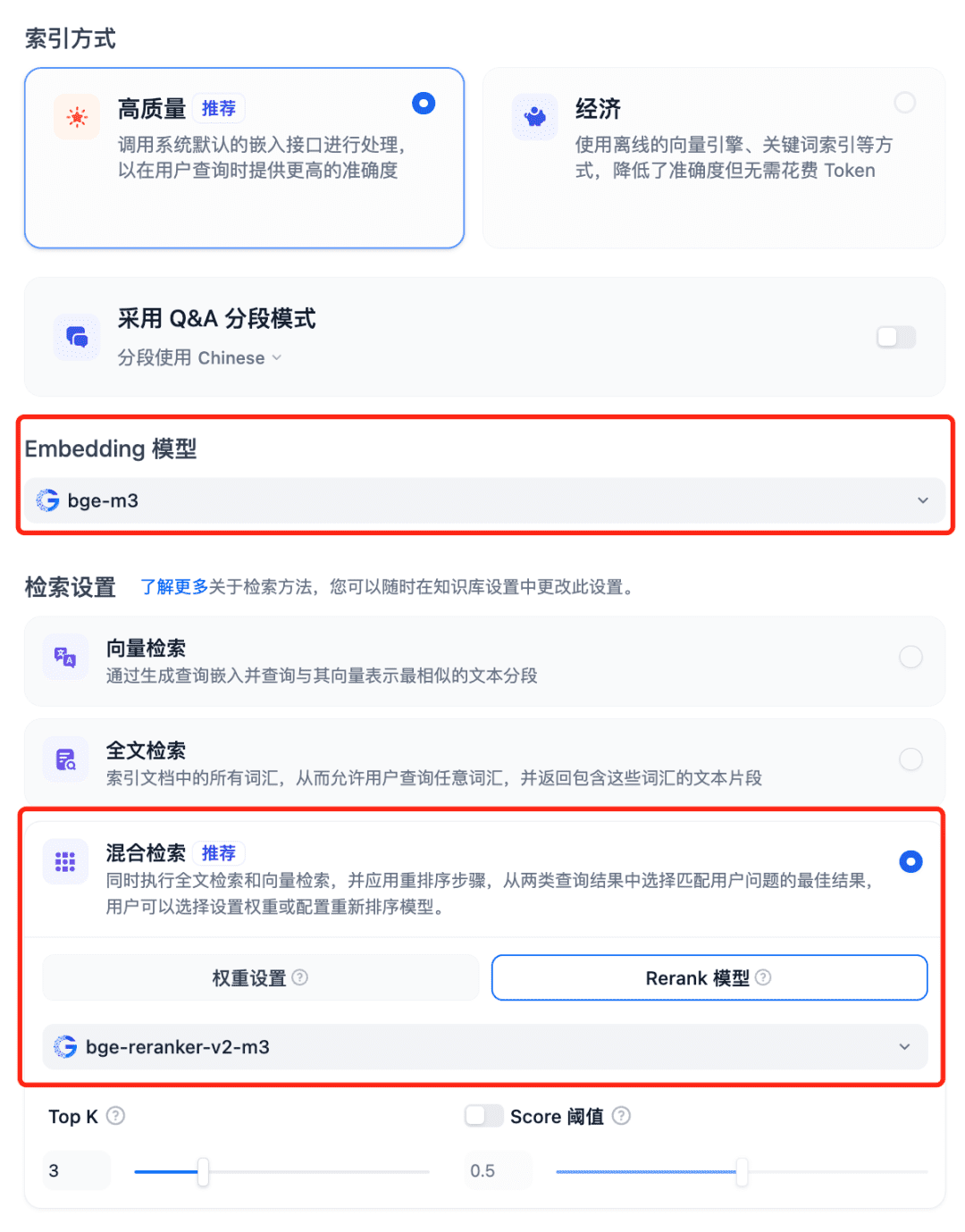
Guarde y comience el proceso de vectorización del documento. Una vez finalizada la vectorización, la base de conocimientos estará lista para su uso.
Las pruebas de recuperación se pueden utilizar para confirmar la eficacia de la recuperación de la base de conocimientos, y el modelo Rerank se perfeccionará para recuperar documentos más relevantes con el fin de obtener mejores resultados de recuperación: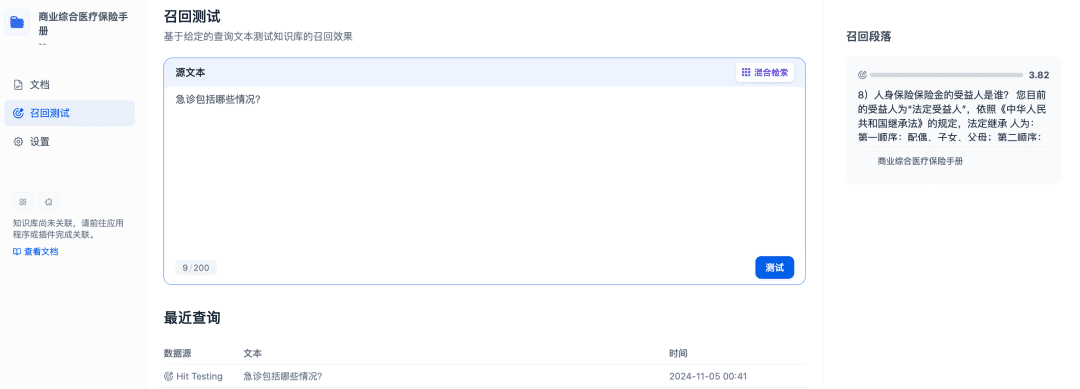
A continuación, crea una aplicación de asistente de chat en la sala de chat: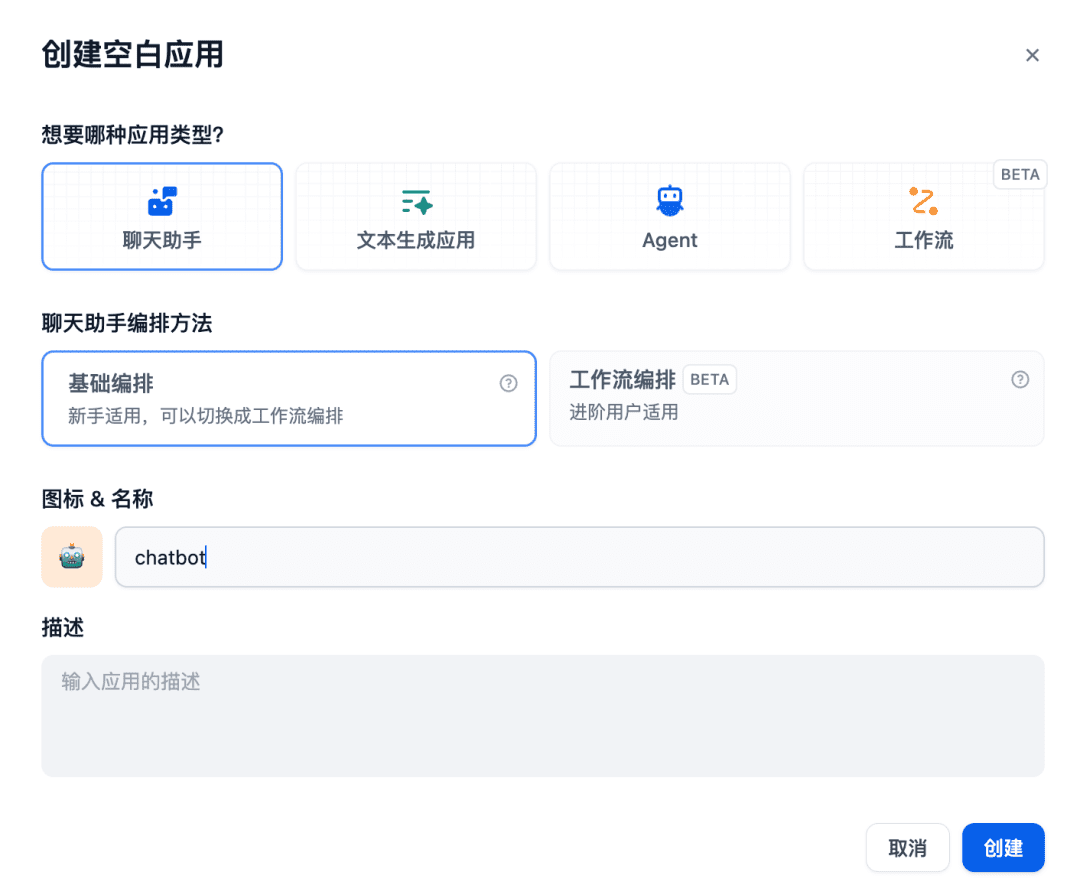
La base de conocimientos pertinente se añade al contexto que se va a utilizar, momento en el que el modelo de chat, el modelo de incrustación y el modelo Reranker trabajarán juntos para apoyar la aplicación RAG, siendo el modelo de incrustación responsable de la vectorización, el modelo Reranker responsable de afinar el contenido de la recuperación y el modelo de chat responsable de responder basándose en el contenido de la pregunta y el contexto de la recuperación: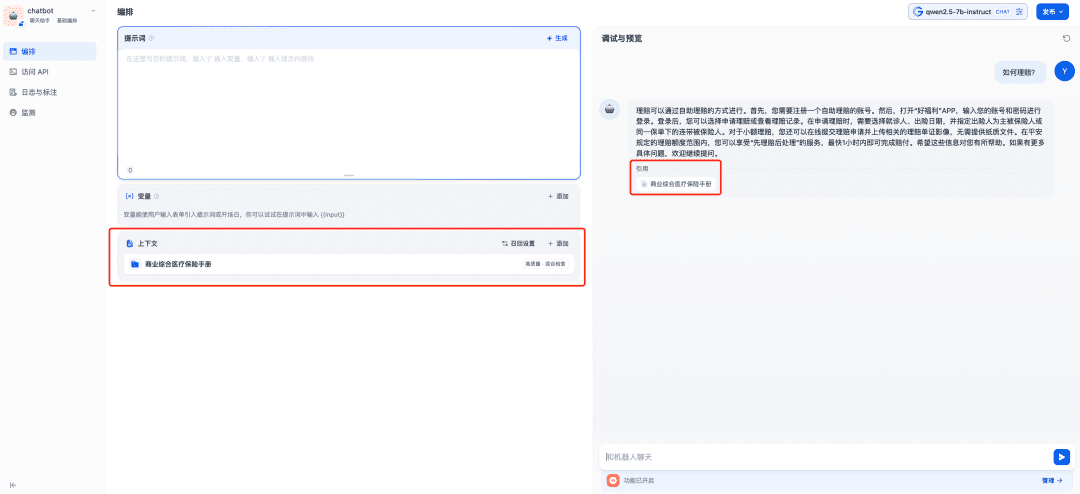
Lo anterior es un ejemplo del uso de Dify para interactuar con los modelos de GPUStack. Otros sistemas RAG también pueden interactuar con GPUStack a través de APIs compatibles con OpenAI / Jina, y pueden aprovechar los diversos modelos de Chat, Embedding y Reranker desplegados por la plataforma GPUStack para dar soporte a los sistemas RAG.
A continuación se describe brevemente la función GPUStack.
Características de GPUStack
- Compatibilidad con GPU heterogéneas: compatibilidad con recursos de GPU heterogéneos, actualmente compatible con Nvidia, Apple Metal, Huawei Rise y Moore Threads y otros tipos de GPU/NPU.
- Soporte de backend de inferencia múltiple: se soportan los backends de inferencia vLLM y llama-box (llama.cpp), teniendo en cuenta tanto el rendimiento de producción como los requisitos de compatibilidad multiplataforma.
- Compatibilidad multiplataforma: admite plataformas Linux, Windows y macOS, y cubre las arquitecturas amd64 y arm64.
- Compatibilidad con varios tipos de modelos: admite varios tipos de modelos, como el modelo de texto LLM, el modelo multimodal VLM, el modelo de incrustación de texto Embedding y el modelo de reordenación Reranker.
- Compatibilidad con repositorios multimodelo: admite el despliegue de modelos desde HuggingFace, Ollama Library, ModelScope y repositorios de modelos privados.
- Ricas políticas de programación automática/manual: admite varias políticas de programación, como la programación compacta, la programación descentralizada, la programación de etiquetas de trabajador especificadas, la programación de GPU especificadas, etc.
- Inferencia distribuida: si una sola GPU no puede ejecutar un modelo de gran tamaño, puede utilizarse la función de inferencia distribuida de GPUStack para ejecutar automáticamente el modelo en varias GPU de distintos hosts.
- Razonamiento por CPU: Si no hay GPU o los recursos de la GPU son insuficientes, GPUStack puede utilizar los recursos de la CPU para ejecutar modelos de gran tamaño, soportando dos modos de razonamiento por CPU: razonamiento híbrido GPU&CPU y razonamiento puro por CPU.
- Comparación multimodelo: GPUStack en Parque infantil Se proporciona una vista de comparación multimodelo para comparar el contenido de preguntas y respuestas y los datos de rendimiento de varios modelos al mismo tiempo para evaluar el efecto de servicio de modelos diferentes, pesos diferentes, parámetros Prompt diferentes, cuantificación diferente, GPU diferentes y backends de inferencia diferentes.
- Observables de GPU y LLM: proporciona métricas completas de rendimiento, utilización, monitorización del estado y datos de uso para evaluar la utilización de GPU y LLM.
GPUStack proporciona todas las funciones empresariales necesarias para crear una gran plataforma privada de modelo como servicio. Al tratarse de un proyecto de código abierto, su instalación y configuración son muy sencillas.
resúmenes
Lo anterior es un tutorial de configuración para instalar GPUStack e integrar modelos GPUStack usando Dify, la dirección de código abierto del proyecto es: https://github.com/gpustack/gpustack.
GPUStack como una solución de bajo coste, fácil de usar y lista para usar.plataforma de código abiertoPuede ayudar a las empresas a integrar y aprovechar con rapidez recursos heterogéneos de GPU, y a crear rápidamente una plataforma privada de gran tamaño como servicio en un breve periodo de tiempo.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...