Uso de la API DeepSeek-R1 Preguntas frecuentes

API DeepSeek-R1
El nombre estándar del modelo es: deepseek-reasoner
DeepSeek-R1 admite visitas en caché
Las consultas en caché se utilizan generalmente para entradas de alta frecuencia con pocos ejemplos de muestra, entradas de documentos grandes con múltiples salidas (menos de 64 fichas (cuyo contenido no se almacenará en caché)
La parte de entrada de los mensajes del sistema y del usuario se cuentan como visitas a la caché.
Los accesos a la caché son sensibles al tiempo, normalmente de unas horas a unos días.
Número de tokens alcanzados por la caché (1 $/millón de tokens)

Problemas de salida de DeepSeek-R1
DeepSeek-R1 La salida consiste tanto en la salida de la cadena de pensamiento como en la salida de la respuesta, ambas cuentan como salida ficha La facturación es la misma.
La API admite hasta 64K contextos, y las cadenas de pensamiento no cuentan para la longitud total.
La salida de la cadena de pensamiento puede establecerse en un máximo (reasoning_effort) de 32K tokens; la salida de la respuesta puede establecerse en un máximo (max_tokens) de 8K tokens.
DeepSeek-R1 Empalme contextual
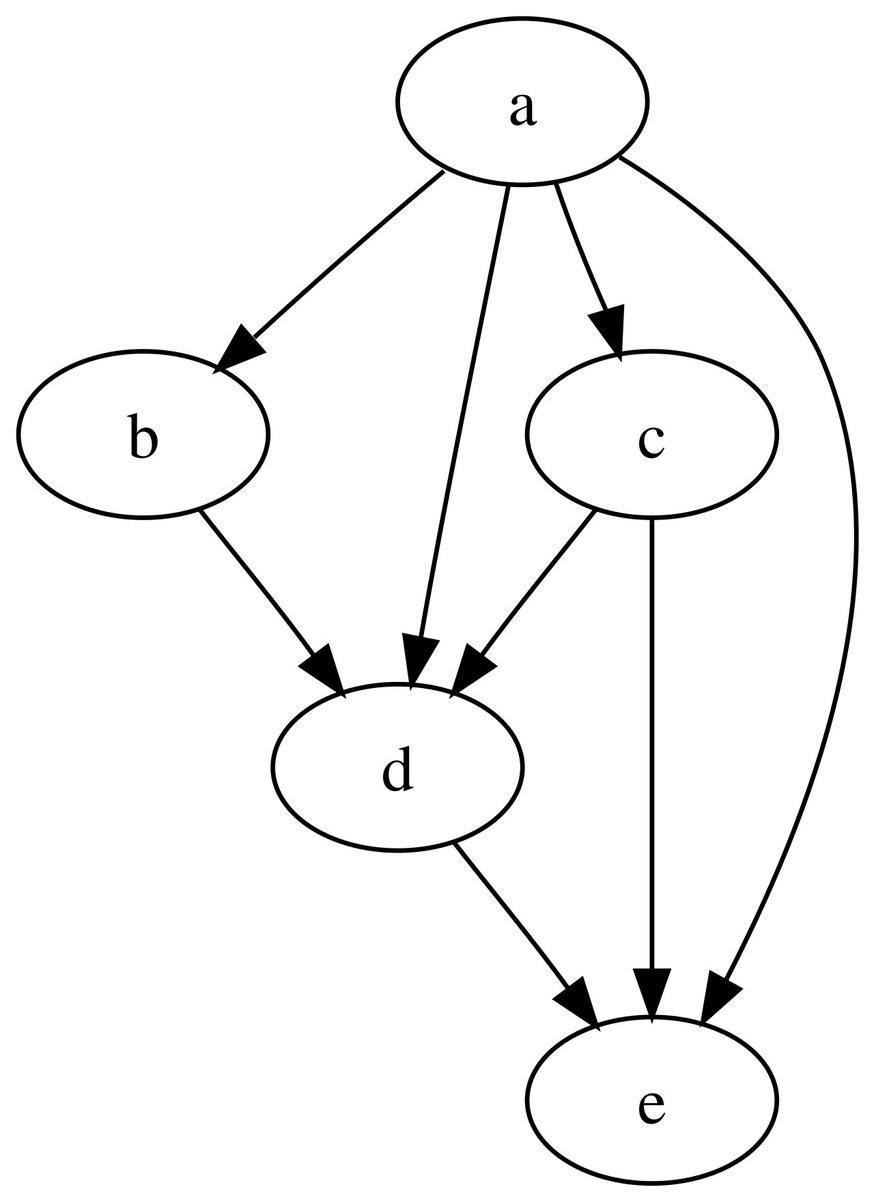
Durante cada ronda de diálogo, el modelo emite el contenido de la cadena de pensamiento (reasoning_content) y la respuesta final (content). En la siguiente ronda de diálogo, el contenido de la salida de la cadena de pensamiento de la ronda anterior no se empalma en el contexto, como se muestra a continuación:

El contexto siempre retiene la última vuelta de la cadena de pensamiento, de lo contrario la respuesta de salida será confusa.
Acerca del uso de la API DeepSeek-R1 de terceros
Nótese la incompatibilidad con los formatos oficiales. Por ejemplo, flujo basado en silicio.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...