
Escalar el cálculo del tiempo de prueba: cadena de pensamiento sobre modelos vectoriales
Base de conocimientos de IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 50.4K 00

Desde que OpenAI lanzó el modelo o1.Ampliación del cálculo del tiempo de prueba(Razonamiento a escala) se ha convertido en uno de los temas más candentes en los círculos de la IA. En pocas palabras, en lugar de acumular potencia de cálculo en la fase de preentrenamiento o postentrenamiento, es mejor gastar más recursos computacionales en la fase de inferencia (es decir, cuando el modelo de gran lenguaje genera resultados). o1 El modelo divide un problema grande en una serie de problemas pequeños (es decir, Chain-of-Thought), de modo que el modelo puede pensar paso a paso como un ser humano, evaluando distintas posibilidades, haciendo una planificación más detallada, reflexionando sobre sí mismo antes de dar una respuesta, etc. Se permite al modelo pensar como un humano, evaluando distintas posibilidades, haciendo una planificación más detallada, reflexionando sobre sí mismo antes de dar una respuesta, etc. De este modo, no es necesario volver a entrenar al modelo, y el rendimiento sólo puede mejorarse con cálculos adicionales durante el razonamiento.En lugar de hacer que el modelo aprenda de memoria, haz que piense más-- Esta estrategia es especialmente eficaz en tareas de inferencia complejas, con una mejora significativa de los resultados, y el reciente lanzamiento del modelo QwQ por parte de Alibaba confirma esta tendencia tecnológica: mejorar las capacidades del modelo ampliando el cálculo en el momento de la inferencia.
👩🏫 El escalado en este documento se refiere al aumento de recursos computacionales (por ejemplo, aritméticos o de tiempo) durante el proceso de razonamiento. No se refiere al escalado horizontal (computación distribuida) ni al procesamiento acelerado (reducción del tiempo de cálculo).

Si también has utilizado el modelo o1, seguro que piensas que el razonamiento en varios pasos requiere más tiempo porque el modelo necesita construir cadenas de pensamiento para resolver el problema.
En Jina AI, nos centramos más en Embeddings y Rerankers que en Large Language Models (LLMs.) Así que, naturalmente, se nos ocurrió:¿Es posible aplicar el concepto de "cadenas de pensamiento" también al modelo de incrustación?
Aunque puede no ser intuitivo a primera vista, este documento explorará una nueva perspectiva y demostrará cómo Scaling Test-Time Compute puede aplicarse a lajina-clippara comprender mejor Imágenes difíciles fuera de dominio (OOD) La clasificación se lleva a cabo para resolver tareas que de otro modo serían imposibles.
Experimentamos con el reconocimiento de Pokémon, que sigue siendo todo un reto para los modelos vectoriales. Un modelo como CLIP, aunque es potente en la correspondencia imagen-texto, tiende a volcarse cuando encuentra datos fuera del dominio (OOD) que el modelo no ha visto antes.
Sin embargo, observamos queLa precisión de la clasificación de los datos fuera del dominio puede mejorarse aumentando el tiempo de inferencia del modelo y empleando una estrategia de clasificación multiobjetivo similar a la cadena de pensamiento que no requiera el ajuste del modelo.
Caso práctico: Clasificación de imágenes de Pokémon
🔗 Google Colab: https://colab.research.google.com/drive/1zP6FZRm2mN1pf7PsID-EtGDc5gP_hm4Z#scrollTo=CJt5zwA9E2jB
Utilizamos el conjunto de datos TheFusion21/PokemonCards, que contiene miles de imágenes de cartas de Pokemon.Se trata de una tarea de clasificación de imágenesque introduce una baraja Pokémon recortada (sin la descripción de texto) y muestra el nombre Pokémon correcto. Pero esto es difícil para el modelo CLIP Embedding por varias razones:
- Los nombres y el aspecto de los Pokémon son relativamente nuevos en el modelo, y es fácil caer en la categorización directa.
- Cada Pokémon tiene sus propias características visualesLos CLIP se comprenden mejor, como las formas, los colores y las poses.
- El estilo de las tarjetas es uniforme, aunquePero los diferentes fondos, poses y estilos de dibujo aumentan la dificultad..
- Esta tarea requiereConsiderar simultáneamente varias características visualescomo la compleja cadena de pensamiento de LLM.

Hemos eliminado toda la información textual (título, pie de página, descripción) de las cartas, para que los modelos no hagan trampas y encuentren sus respuestas directamente en el texto, ya que las etiquetas de estas clases de Pokémon son sus nombres, como Absol, Aerodactyl.
Metodología de referencia: comparación directa de similitudes
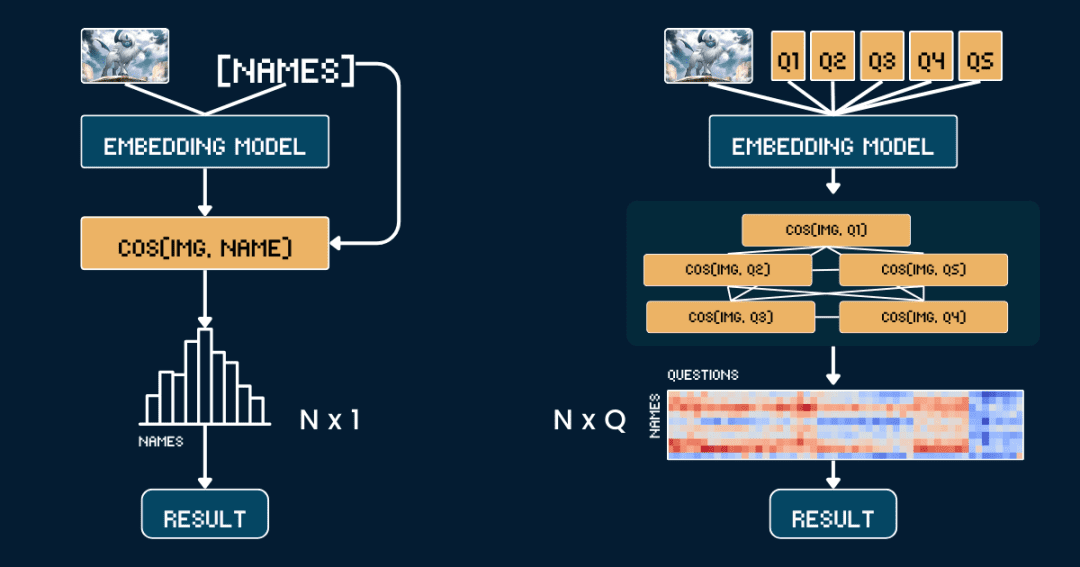
Empecemos con la metodología de base más sencilla, la Comparación directa de la similitud entre las imágenes y los nombres de los Pokémon.
En primer lugar, es mejor eliminar toda la información textual de las tarjetas, para que el modelo CLIP no tenga que adivinar la respuesta directamente a partir del texto. A continuación, utilizamos jina-clip-v1 responder cantando jina-clip-v2 El modelo codifica la imagen y el nombre del Pokémon por separado para obtener sus respectivas representaciones vectoriales. Por último, se calcula la similitud coseno entre los vectores de la imagen y los vectores del texto, y se considera que el nombre con mayor similitud es el Pokémon de la imagen.
Este enfoque equivale a hacer una correspondencia uno a uno entre la imagen y el nombre, sin tener en cuenta ninguna otra información contextual o atributos. El siguiente pseudocódigo describe brevemente el proceso.
# 预处理 cropped_images = [crop_artwork(img) for img in pokemon_cards] # 去掉文字,只保留图片 pokemon_names = ["Absol", "Aerodactyl", ...] # 宝可梦名字# 用 jina-clip-v1 获取 embeddings image_embeddings = model.encode_image(cropped_images) text_embeddings = model.encode_text(pokemon_names) # 计算余弦相似度进行分类 similarities = cosine_similarity(image_embeddings, text_embeddings) predicted_names = [pokemon_names[argmax(sim)] for sim in similarities] # 哪个名字相似度最高,就选哪个 # 评估准确率 accuracy = mean(predicted_names == ground_truth_names)
Avanzado: aplicación de cadenas de pensamiento a la clasificación de imágenes
Esta vez, en lugar de emparejar imágenes y nombres directamente, dividimos la identificación de Pokémon en varias partes, como si jugáramos a "Pokémon Connect".
Definimos cinco conjuntos de atributos clave: color primario (por ejemplo, "blanco", "azul"), forma primaria (por ejemplo, "un lobo", "un reptil alado"), rasgos clave (por ejemplo, "un cuerno blanco", "alas grandes"), tamaño corporal (por ejemplo, "forma de lobo de cuatro patas ", "alado y esbelto"), y escenas de fondo (por ejemplo, "espacio exterior", "bosque verde").
Para cada conjunto de atributos, diseñamos una palabra clave especial, como "El cuerpo de este Pokémon es principalmente de {} colores", y luego rellenamos las opciones posibles.A continuación, utilizamos el modelo para calcular las puntuaciones de similitud de la imagen y cada opción, y convertimos las puntuaciones en probabilidades utilizando la función softmax, que da una mejor medida de la confianza del modelo.
La cadena de pensamiento completa (CdT) consta de dos partes:classification_groups responder cantando pokemon_rulesEl primero define el marco de las preguntas: cada atributo (por ejemplo, color, forma) corresponde a una plantilla de pregunta y a un conjunto de posibles opciones de respuesta. El segundo registra qué opciones deben corresponder a cada Pokémon.
Por ejemplo, el color de Absol debería ser "blanco" y su forma debería ser "lobo". Hablaremos de cómo construir una estructura completa de CoT más adelante, y el pokemon_system de abajo es un ejemplo concreto de CoT:
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
En resumen, en lugar de limitarnos a comparar las similitudes una vez, ahora hacemos comparaciones múltiples, combinando las probabilidades de cada atributo para poder emitir un juicio más razonable.
# 分类流程
def classify_pokemon(image):
# 生成所有提示
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# 获取向量及其相似度
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# 将相似度转换为每个属性组的概率
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# 根据匹配的属性计算每个宝可梦的得分
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get) # 返回得分最高的宝可梦
Análisis de la complejidad de los dos métodos
Ahora analicemos la complejidad, supongamos que queremos encontrar el nombre que mejor se ajusta a la imagen dada entre N nombres de Pokémon:
El método básico requiere el cálculo de N vectores de texto (uno por cada nombre) y 1 vector de imagen, seguido de N cálculos de similitud (los vectores de imagen se comparan con cada vector de texto).Por lo tanto, la complejidad del método de referencia depende principalmente del número de cálculos N de los vectores de texto.
Y nuestro método CoT necesita calcular Q vectores de texto, donde Q es el número total de combinaciones pregunta-opción, y 1 vector de imagen. A continuación, es necesario realizar cálculos de similitud Q (comparación de vectores de imagen con vectores de texto para cada combinación pregunta-opción).Por lo tanto, la complejidad del método depende principalmente de Q.
En este ejemplo, N = 13 y Q = 52 (5 grupos de atributos con una media de unas 10 opciones por grupo). Ambos métodos necesitan calcular vectores de imagen y realizar pasos de clasificación, por lo que redondeamos estas operaciones comunes en la comparación.
En el caso extremo, si Q = N, nuestro método degenera en un método de referencia. Por tanto, la clave para ampliar de forma efectiva el cálculo del tiempo de inferencia es:
Diseña el problema para aumentar el valor de Q. Asegúrese de que cada pregunta ofrezca pistas útiles que nos ayuden a delimitarla. Es mejor no duplicar la información entre las preguntas para maximizar la obtención de información.
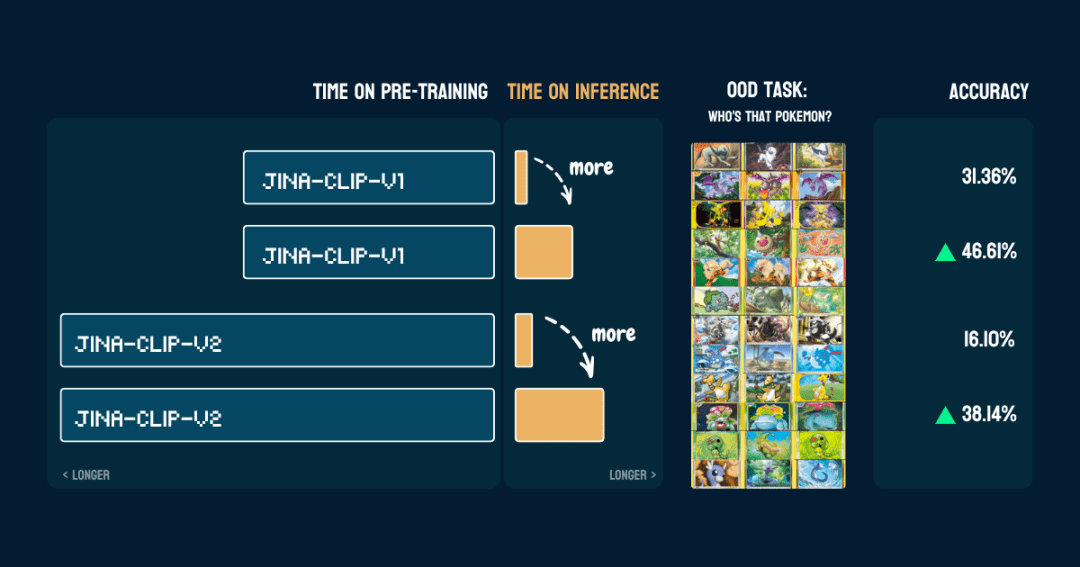
Resultados
Lo evaluamos con 117 imágenes de prueba que contenían 13 Pokémon diferentes. Los resultados de precisión son los siguientes:

También demuestra que una vezpokemon_systemEstá bien construido.El mismo CoT puede utilizarse directamente en un modelo diferente sin cambiar el código y sin necesidad de ajuste fino o formación adicional.
Interesante.jina-clip-v1La precisión base del modelo en la clasificación de Pokémon es entonces mayor (31,36%) porque se entrenó con el conjunto de datos LAION-400M que contiene datos de Pokémon. Mientras que jina-clip-v2El modelo se entrenó con DFN-2B, que es un conjunto de datos de mayor calidad, pero también filtra más datos y probablemente también elimina contenido relacionado con Pokémon, por lo que tiene una precisión de base más baja (16,10%).
Espera, ¿cómo funciona este método?
👩🏫 Repasemos lo que hicimos.
Empezamos con modelos de vectores fijos preentrenados que no podían manejar problemas de fuera de distribución (OOD) con muestras cero. Pero cuando construimos un árbol de clasificación, de repente pudieron hacerlo. ¿Cuál es el secreto? ¿Es algo parecido a la integración de aprendices débiles en el aprendizaje automático tradicional? Merece la pena señalar que nuestro modelo vectorial puede pasar de "malo" a "bueno" no gracias al aprendizaje integrado per se, sino al conocimiento externo del dominio contenido en el árbol de clasificación. Se pueden clasificar repetidamente miles de preguntas con cero muestras, pero si las respuestas no contribuyen al resultado final, no tiene sentido. Es como un juego de "tú me dices, yo adivino" (veinte preguntas), en el que hay que ir acotando progresivamente la solución con cada pregunta. Así pues, este conocimiento externo o proceso de pensamiento es la clave- Como en nuestro ejemplo, la clave está en cómo está construido el sistema Pokemon.Esta experiencia puede provenir de seres humanos o de grandes modelos lingüísticos.
pokemon_systemcalidad de.Hay muchas formas de construir este sistema CoT, desde manual hasta totalmente automatizado, cada una con sus propias ventajas e inconvenientes.1. Construcción manual
2. Construcción asistida por LLM
我需要一个宝可梦分类系统。对于以下宝可梦:[Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...],创建一个包含以下内容的分类系统:
1. 基于以下视觉属性的分类组:
- 宝可梦的主要颜色
- 宝可梦的形态
- 宝可梦最显著的特征
- 宝可梦的整体体型
- 宝可梦通常出现的背景环境
2. 对于每个分类组:
- 创建一个自然语言提示模板,用 "{}" 表示选项
- 列出所有可能的选项
- 确保选项互斥且全面
3. 创建规则,将每个宝可梦映射到每个属性组中的一个选项,使用索引引用选项
请以 Python 字典格式输出,包含两个主要部分:
- "classification_groups": 包含每个属性的提示和选项
- "pokemon_rules": 将每个宝可梦映射到其对应的属性索引
示例格式:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color.",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # "white" 的索引
...
},
...
}
}
LLM genera rápidamente un primer borrador, pero también requiere comprobaciones y correcciones manuales.
Un enfoque más fiable sería Generación combinada de LLM y validación manual. Primero se permite que el LLM genere una versión inicial, después comprueba y modifica manualmente las agrupaciones de atributos, las opciones y las reglas, y a continuación devuelve las modificaciones al LLM para que siga refinándolas hasta que esté satisfecho. Este enfoque equilibra eficacia y precisión.
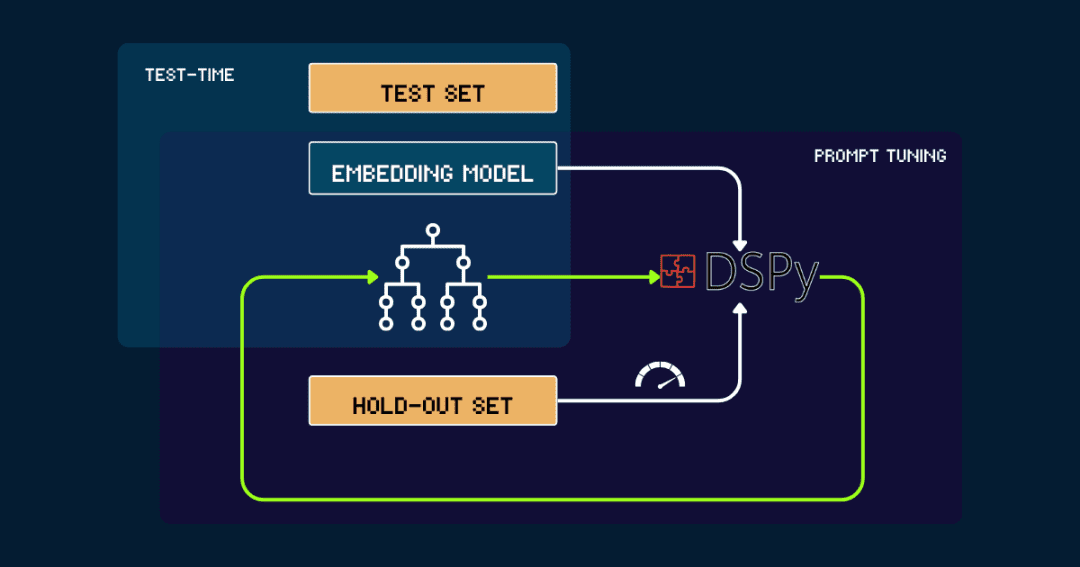
3. Creación automatizada con DSPy
Para construcciones totalmente automatizadas pokemon_systemque puede optimizarse iterativamente con DSPy.
Empecemos con un simple pokemon_system de inicio, creado manualmente o generado por LLM. A continuación, se evalúa con los datos del conjunto de omisión, indicando la precisión a DSPy como retroalimentación.DSPy utilizará esta retroalimentación para generar un nuevo pokemon_systemrepitiendo este ciclo hasta que el rendimiento converja y ya no haya una mejora significativa.
El modelo vectorial se mantiene fijo durante todo el proceso. Con DSPy es posible encontrar el mejor diseño de pokemon_system (CoT) automáticamente y sólo es necesario afinarlo una vez por tarea.
¿Por qué escalar el cálculo del tiempo de prueba en modelos vectoriales?
Es demasiado caro de llevar debido al coste de aumentar el tamaño de los modelos preentrenados todo el tiempo.
Colección Jina Embeddings, dejina-embeddings-v1yv2yv3 hasta jina-clip-v1yv2Y jina-ColBERT-v1yv2Cada actualización requiere modelos más grandes, más datos preentrenados y costes crecientes.
tomajina-embeddings-v1Para un lanzamiento en junio de 2023, con 110 millones de parámetros, la formación costará entre 5.000 y 10.000 dólares. Para cuando jina-embeddings-v3, el rendimiento ha mejorado mucho, pero sigue siendo principalmente a base de tirar el dinero en recursos. En la actualidad, el coste de formación de los mejores modelos ha pasado de miles de dólares a decenas de miles de dólares, y las grandes empresas incluso tienen que gastar cientos de millones de dólares. Aunque cuanto más se invierte en formación previa, mejores son los resultados del modelo, pero el coste es demasiado alto, la rentabilidad es cada vez menor, el desarrollo de la última necesidad de considerar la sostenibilidad.
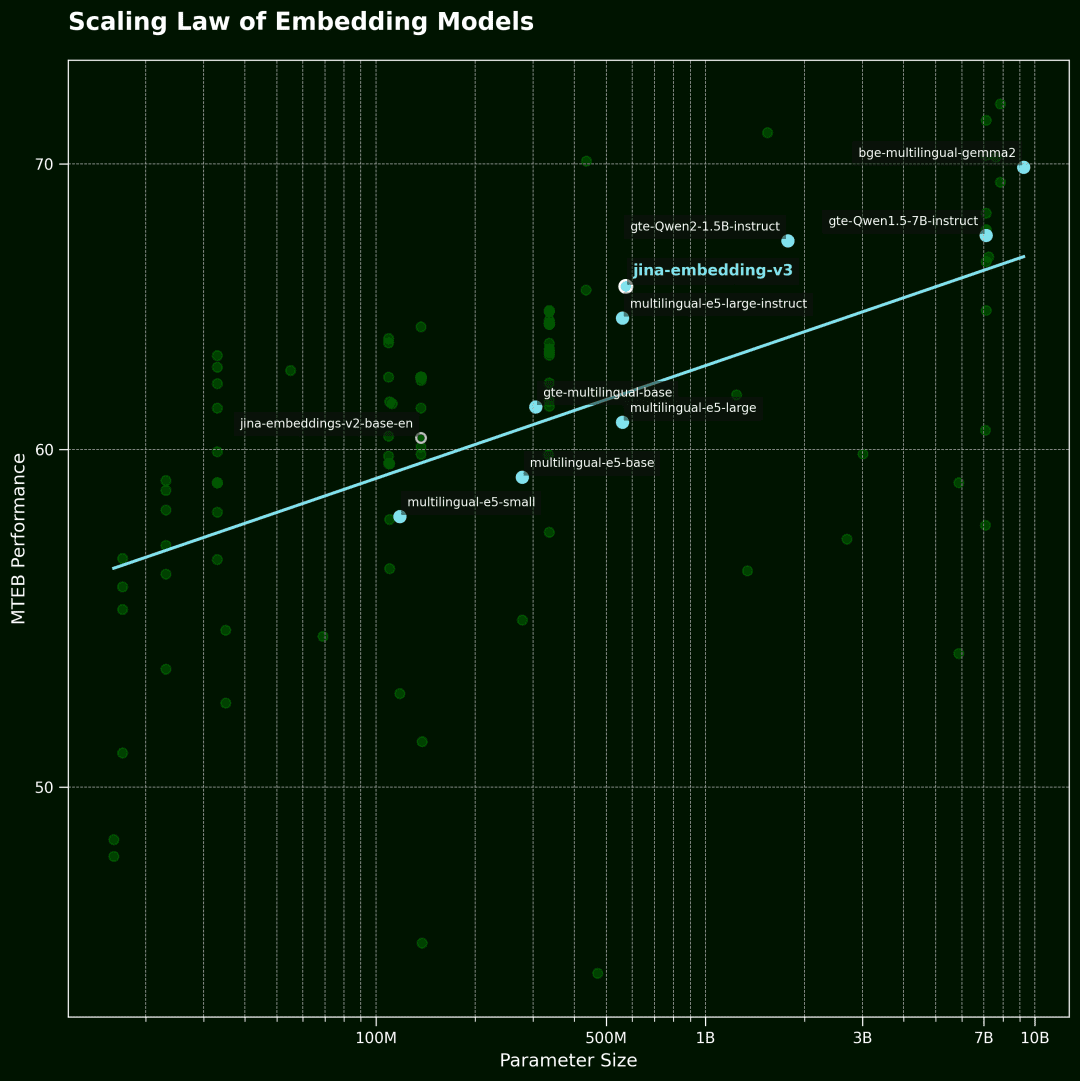
modelización vectorial Ley de escalado
Esta figura muestra el modelo vectorial Scaling Law.El eje horizontal es el número de parámetros del modelo y el eje vertical es el rendimiento medio del MTEB. Cada punto representa un modelo vectorial. La línea de tendencia representa la media de todos los modelos, y los puntos azules son modelos multilingües.
Los datos se seleccionaron entre los 100 mejores modelos vectoriales de la clasificación MTEB. Para garantizar la calidad de los datos, filtramos los modelos que no revelaban información sobre el tamaño del modelo y algunas presentaciones no válidas.
Por otra parte, los modelos vectoriales son ahora muy potentes: multilingües, multitarea, multimodales, con excelentes capacidades de aprendizaje sin muestras y de seguimiento de instrucciones.Esta versatilidad abre un gran abanico de posibilidades imaginativas para mejoras algorítmicas y ampliaciones del cálculo en el momento de la inferencia.
La pregunta clave es:¿Cuánto están dispuestos a pagar los usuarios por una consulta que realmente les interesa?? Si simplemente hacer que la inferencia de un modelo fijo preentrenado lleve un poco más de tiempo puede mejorar drásticamente la calidad de los resultados, estoy seguro de que a mucha gente le merecerá la pena.
En nuestra opinión.La computación extendida en tiempo de inferencia encierra un gran potencial sin explotar en el campo de la modelización vectoriallo que probablemente constituirá un avance importante para futuras investigaciones.En lugar de buscar un modelo más grande, es mejor esforzarse más en la fase de inferencia y explorar métodos computacionales más inteligentes para mejorar el rendimiento. -- Esta puede ser una vía más económica y eficaz.
llegar a un veredicto
existe jina-clip-v1/v2 En el rendimiento experimental, observamos los siguientes fenómenos clave:
nosotros Sobre datos no vistos por el modelo y fuera del dominio (OOD)(matemáticas) géneroSe obtuvieron mejores precisiones de reconocimiento y no hubo que afinar ni entrenar más el modelo. El sistema funciona mediante Perfeccionamiento iterativo de los criterios de búsqueda y clasificación de similitudes, logrando una capacidad de diferenciación más fina. introduciendo Ajuste dinámico de pistas y razonamiento iterativo(análogo a una "cadena de pensamiento"), transformamos el proceso de razonamiento del modelo vectorial de una única consulta a una cadena de pensamiento más compleja.
Esto es sólo el principio: el potencial de Scaling Test-Time Compute va mucho más allá.Sin embargo, aún queda un vasto espacio por explorar. Por ejemplo, podemos desarrollar algoritmos más eficientes para reducir el espacio de respuestas eligiendo de forma iterativa la estrategia más eficiente, similar a la estrategia de soluciones óptimas en el juego de las "veinte preguntas". Al ampliar la computación en tiempo de razonamiento, podemos llevar los modelos vectoriales más allá de los cuellos de botella existentes, desbloqueando tareas complejas y de grano fino que antes parecían fuera de nuestro alcance, y empujando estos modelos hacia aplicaciones más amplias.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...