
¿Cómo elegir el modelo de incrustación adecuado?
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 50.5K 00

La Generación Aumentada por Recuperación (RAG) es una clase de aplicaciones en la IA Generativa (GenAI) que admite el uso de datos propios para aumentar el conocimiento de un modelo LLM (por ejemplo, ChatGPT).
RAG Se suelen utilizar tres modelos diferentes de IA: el modelo Embedding, el modelo Rerankear y el modelo Big Language. En este artículo explicaremos cómo elegir el modelo de incrustación adecuado en función del tipo de datos, el idioma o el ámbito específico (por ejemplo, el jurídico).
1. Datos textuales: clasificación MTEB
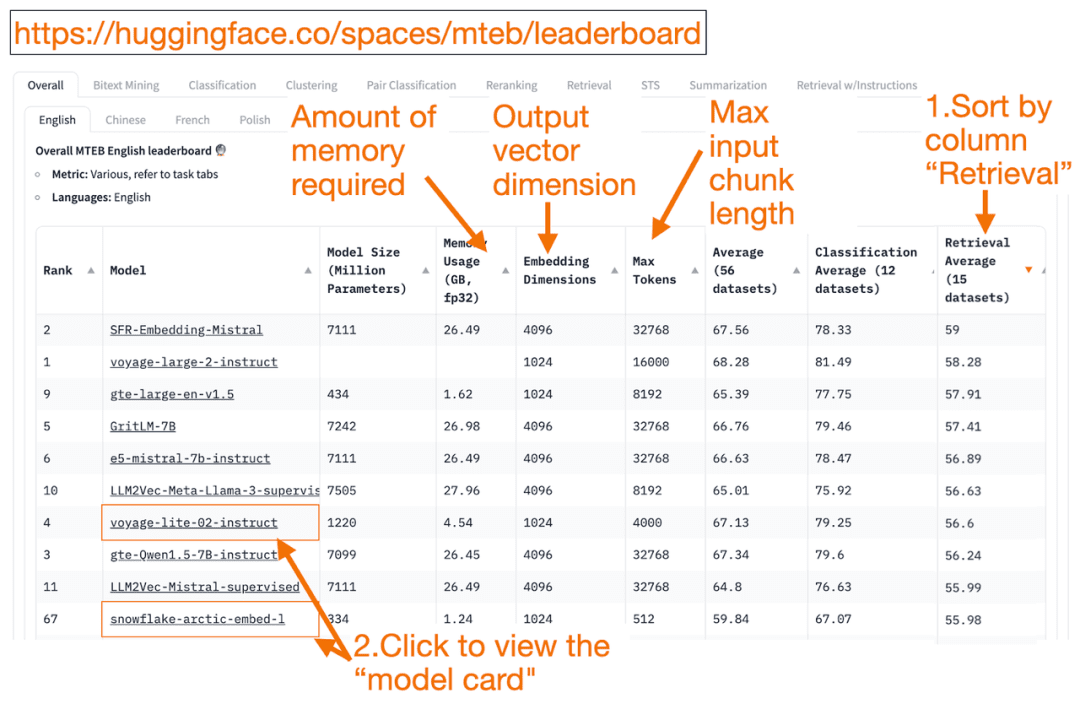
HuggingFace Clasificación MTEB es una lista completa de modelos de incrustación de texto. Puedes conocer el rendimiento medio de cada modelo.
Puede ordenar la columna "Promedio de recuperación" en orden descendente, ya que esto se ajusta mejor a la tarea de búsqueda vectorial. A continuación, busque el modelo mejor clasificado con el menor consumo de memoria.
- La dimensión del vector de incrustación es la longitud del vector, es decir, y en f(x)=y, que emitirá el modelo.
- mayor Ficha El número es la longitud del bloque de texto de entrada, es decir, x en f(x)=y , que puede introducir en el modelo.
Además de pasar el Recuperación Además de ordenar las tareas, también puede filtrar por los siguientes criterios:
- Idioma: francés, inglés, chino y polaco. (por ejemplo: task=recuperación.
Idioma=chino)
- Textos en el ámbito jurídico.
(por ejemplo, task=recuperación, lengua=derecho)
Cabe señalar que, dado que algunos de los datos de entrenamiento se han hecho públicos recientemente, algunos de los modelos de incrustación de la MTEB pueden seraparentemente adecuadoSin embargo, los modelos inadecuados reales con clasificaciones infladas pueden tener un rendimiento diferente. En consecuencia, HuggingFace ha publicado unblog (préstamo)Describe los puntos clave para determinar si la clasificación de un modelo es creíble o no. Tras hacer clic en el enlace de un modelo (denominado "ficha de modelo"):
- Busque blogs y artículos que expliquen cómo se entrenan y evalúan los modelos. Fíjese bien en el lenguaje, los datos y las tareas utilizadas para el entrenamiento de los modelos. Busque también modelos creados por empresas conocidas. Por ejemplo, en la ficha del modelo voyage-lite-02-instruct, verás otros modelos de VoyageAI, pero no éste. Esto es una pista. Este modelo está sobreajustado y no debe ser utilizado.
- En la siguiente captura de pantalla, probaré el nuevo modelo "snowflake-arctic-embed-1" de Snowflake porque está muy bien clasificado, es lo suficientemente pequeño para ejecutarlo en mi portátil y tiene enlaces a blogs y documentos en la tarjeta del modelo.
La ventaja de utilizar HuggingFace es que si necesita cambiar el modelo después de seleccionar el modelo Embedding, ¡sólo tiene que cambiar el model_name en el código!
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from Huggingface
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

2. Datos de imagen: ResNet50
A veces es posible que desee buscar imágenes similares a la imagen introducida. Por ejemplo, puede que esté buscando más imágenes de gatos de raza Scottish Fold. En este caso, puede cargar una imagen de un gato Scottish Fold y pedir al motor de búsqueda que encuentre imágenes similares.
ResNet50 es un popular modelo CNN entrenado originalmente por Microsoft en 2015 con datos de ImageNet.
Del mismo modo, paraBúsqueda de vídeosEn este caso, ResNet50 aún puede convertir el vídeo en vectores de incrustación. A continuación, se realiza una búsqueda de similitudes en los fotogramas de vídeo estáticos y se devuelve al usuario el vídeo más similar como la mejor coincidencia.
3. Datos de audio: PANN
De forma similar a la búsqueda de imágenes, también puede buscar audio similar basado en clips de audio de entrada.
PANNs(redes neuronales de audio preentrenadas) se utilizan habitualmente como modelos de incrustación para la búsqueda de audio porque las PANN están preentrenadas en conjuntos de datos de audio a gran escala y destacan en tareas como la clasificación y el etiquetado de audio.
4. datos multimodales de imagen y texto:
SigLIP o Unum
En los últimos años han surgido varios modelos de incrustación entrenados en una mezcla de datos no estructurados (texto, imágenes, audio o vídeo). Estos modelos son capaces de capturar la semántica de múltiples tipos de datos no estructurados simultáneamente en el mismo espacio vectorial.
El modelo de incrustación multimodal admite la búsqueda de imágenes mediante texto, la generación de descripciones de texto para imágenes o la búsqueda de imágenes.
Lanzamiento de OpenAI en 2021 CLIP es el modelo estándar de incrustación. Pero debido a que era difícil de usar, ya que requería que los usuarios se afinaran, en 2024, Google introdujo la SigLIP(Sigmoidal-CLIP). El modelo obtuvo un buen rendimiento cuando se utilizó la indicación de disparo cero.
Los modelos LLM pequeños son cada vez más populares hoy en día. Esto se debe a que estos modelos no requieren grandes clústeres en la nube y pueden ejecutarse en ordenadores portátiles. Los modelos más pequeños ocupan menos memoria, tienen menor latencia y funcionan más rápido que los modelos más grandes.Unum Se proporcionan modelos multimodales de mini-Embedding.
5. Datos multimodales de texto, audio y vídeo
La mayoría de los sistemas RAG multimodales de texto a audio utilizan LLM generativos multimodales, que primero convierten el sonido en texto, generan pares sonido-texto y, a continuación, convierten el texto en vectores de incrustación. A continuación, la GAR recupera el texto como de costumbre. En el último paso, el texto se mapea de nuevo a audio.
OpenAI Susurro puede transcribir voz a texto. Además, OpenAI Texto a voz (TTS) Los modelos también pueden convertir texto en audio.
El sistema RAG multimodal texto-vídeo utiliza un enfoque similar para mapear primero el vídeo en texto, convertirlo en un vector de incrustación, buscar en el texto y devolver el vídeo como resultado de la búsqueda.
OpenAI Sora El texto puede convertirse en vídeo. Sora también puede generar vídeos a partir de imágenes fijas u otros vídeos.
Milvus ya ha integrado el modelo Embedding mainstream, bienvenido a experimentarlo:https://milvus.io/docs/embeddings.md
consulta
Clasificación MTEB: https://huggingface.co/spaces/mteb/leaderboard
Buenas prácticas de MTEB: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Búsqueda de imágenes similares: https://milvus.io/docs/image_similarity_search.md
Búsqueda de imágenes en vídeo: https://milvus.io/docs/video_similarity_search.md
Búsquedas de audio similares: https://milvus.io/docs/audio_similarity_search.md
Búsqueda de imágenes de texto: https://milvus.io/docs/text_image_search.md
2024 SigLIP (sigmoid loss CLIP) Papel: https://arxiv.org/pdf/2401.06167v1
Modelo de incrustación multimodal Unum:
https://github.com/unum-cloud/uform
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...