
Cómo elegir el mejor modelo de incrustación para aplicaciones GAR
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 70.6K 00


La incrustación vectorial es el núcleo de las actuales aplicaciones de Generación Aumentada de Recuperación (RAG). Capturan información semántica sobre objetos de datos (por ejemplo, texto, imágenes, etc.) y los representan como matrices de números. En las aplicaciones actuales de IA generativa, estos Embedding vectoriales suelen generarse mediante modelos de Embedding. ¿Cómo elegir el modelo de Incrustación adecuado para una aplicación GAR? En general, depende del caso de uso concreto, así como de los requisitos específicos. A continuación, vamos a desglosar los pasos para examinar cada uno de ellos individualmente.
01. Identificar casos de uso específicos
Consideramos las siguientes cuestiones basándonos en los requisitos de la aplicación RAG:
En primer lugar, ¿es suficiente un modelo genérico para satisfacer las necesidades?
En segundo lugar, ¿existen necesidades específicas? Por ejemplo, la modalidad (por ejemplo, sólo texto o imagen; para las opciones de incrustación multimodal, consulte la secciónCómo elegir el modelo de incrustación adecuado"), campos específicos (por ejemplo, derecho, medicina, etc.)
En la mayoría de los casos, se suele elegir un modelo genérico para los modos deseados.
02. Selección de modelos genéricos
¿Cómo elegir un modelo de propósito general? La tabla de clasificación Massive Text Embedding Benchmark (MTEB) de HuggingFace enumera una serie de modelos de incrustación de texto actuales, propios y de código abierto, y para cada modelo de incrustación, la MTEB enumera una serie de métricas, incluidos los parámetros del modelo, la memoria, las dimensiones de incrustación, el número máximo de signaturas y sus puntuaciones en tareas como la recuperación y el resumen, las dimensiones de incrustación, el número máximo de tokens y sus puntuaciones en tareas como la recuperación y el resumen.
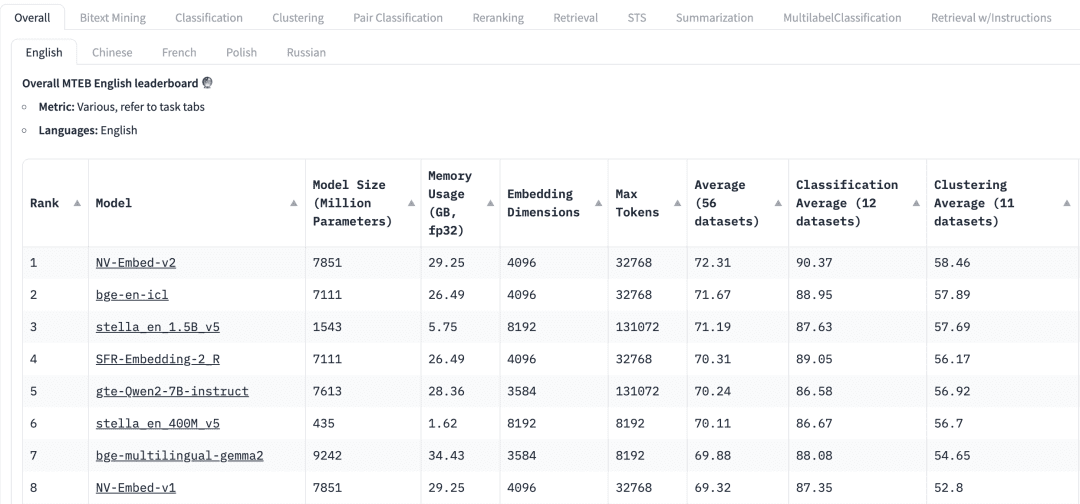
A la hora de seleccionar un modelo de incrustación para una aplicación GAR, deben tenerse en cuenta los siguientes factores:
mandatos: En la parte superior de la tabla de clasificación de MTEB, veremos varias pestañas de tareas. Para una aplicación RAG, puede que necesitemos centrarnos más en la tarea "Recuperar", donde podemos elegir entre Retrial Esta pestaña.
multilingüismoBasándose en el idioma del conjunto de datos en el que se aplica la GAR para seleccionar el modelo de incrustación para el idioma correspondiente.
puntuaciónIndica el rendimiento del modelo en un conjunto de datos de referencia específico o en varios conjuntos de datos de referencia. Dependiendo de la tarea, se utilizan diferentes métricas de evaluación. Normalmente, estas métricas toman valores que van de 0 a 1, y los valores más altos indican un mejor rendimiento.
Tamaño del modelo y uso de memoriaEstas métricas nos dan una idea de los recursos informáticos necesarios para ejecutar el modelo. Aunque el rendimiento de la recuperación mejora con el tamaño del modelo, es importante tener en cuenta que el tamaño del modelo también afecta directamente a la latencia. Además, los modelos más grandes pueden estar sobreajustados y tener un bajo rendimiento de generalización, por lo que su rendimiento en producción es bajo. Por lo tanto, tenemos que buscar un equilibrio entre rendimiento y latencia en un entorno de producción. En general, podemos empezar con un modelo pequeño y ligero y construir primero la aplicación GAR rápidamente. Después de que el proceso subyacente de la aplicación funcione correctamente, podemos cambiar a un modelo más grande y de mayor rendimiento para optimizar aún más la aplicación.
Dimensiones de incrustaciónLongitud: es la longitud del vector de incrustación. Aunque unas dimensiones de incrustación mayores pueden captar detalles más precisos de los datos, los resultados no son necesariamente óptimos. Por ejemplo, ¿necesitamos realmente 8192 dimensiones para los datos de un documento? Probablemente no. Por otro lado, las dimensiones de incrustación más pequeñas proporcionan una inferencia más rápida y son más eficientes en términos de almacenamiento y memoria. Por lo tanto, tenemos que encontrar un buen equilibrio entre la captura del contenido de los datos y la eficiencia de la ejecución.
Número máximo de fichas: indica el número máximo de tokens para un único Embedding. Para las aplicaciones RAG habituales, el mejor tamaño de trozo para el Embedding suele ser un único párrafo, en cuyo caso un modelo de Embedding con un token máximo de 512 debería ser suficiente. Sin embargo, en algunos casos especiales, podemos necesitar modelos con un mayor número de tokens para manejar textos más largos.
03. Evaluación de modelos en aplicaciones GAR
Aunque podemos encontrar modelos genéricos en las tablas de clasificación de la MTEB, debemos tratar sus resultados con cautela. Teniendo en cuenta que estos resultados son autodeclarados por los modelos, es posible que algunos de ellos obtengan puntuaciones que inflen su rendimiento porque pueden haber incluido los conjuntos de datos MTEB en sus datos de entrenamiento, que son, al fin y al cabo, conjuntos de datos a disposición del público. Además, es posible que el conjunto de datos que el modelo utiliza para la evaluación comparativa no represente con exactitud los datos utilizados en nuestra aplicación. Por lo tanto, tenemos que evaluar los modelos de incrustación en nuestros propios conjuntos de datos.
3.1 Conjuntos de datos
Podemos generar un pequeño conjunto de datos etiquetados a partir de los datos utilizados por la aplicación RAG. Tomemos como ejemplo el siguiente conjunto de datos.
| Idioma | Descripción |
|---|---|
| C/C++ | Lenguaje de programación de propósito general conocido por su rendimiento y eficacia. Ofrece capacidades de manipulación de memoria de bajo nivel y se utiliza ampliamente en el desarrollo de sistemas/software, juegos y aplicaciones que requieren un alto rendimiento. ampliamente utilizado en el desarrollo de sistemas/software, desarrollo de juegos y aplicaciones que requieren un alto rendimiento. |
| Java | Un lenguaje de programación versátil y orientado a objetos diseñado para tener el menor número posible de dependencias de implementación. Es ampliamente utilizado para construir Es ampliamente utilizado para crear aplicaciones a escala empresarial, aplicaciones móviles (especialmente Android) y aplicaciones web debido a su portabilidad y robustez. |
| Python | Lenguaje de programación interpretado de alto nivel, conocido por su legibilidad y sencillez, compatible con múltiples paradigmas de programación y ampliamente utilizado en el desarrollo web, el análisis de datos, la inteligencia artificial, la informática científica y la automatización. Admite múltiples paradigmas de programación y se utiliza ampliamente en el desarrollo web, el análisis de datos, la inteligencia artificial, la informática científica y la automatización. |
| JavaScript | Lenguaje de programación dinámico de alto nivel utilizado principalmente para crear contenidos interactivos y dinámicos en la web. Es una tecnología esencial para Es una tecnología esencial para el desarrollo web front-end y se utiliza cada vez más en el lado del servidor con entornos como Node.js. |
| C# | Se utiliza para desarrollar una amplia gama de aplicaciones, incluidas las web, de escritorio, móviles y juegos, en particular dentro del ecosistema de Microsoft. Se utiliza para desarrollar una amplia gama de aplicaciones, incluidas las web, de escritorio, móviles y juegos, en particular dentro del ecosistema de Microsoft. |
| SQL | Lenguaje específico utilizado en la programación y gestión de bases de datos relacionales, esencial para consultar, actualizar y gestionar datos en bases de datos. Es esencial para consultar, actualizar y gestionar datos en bases de datos, y se utiliza ampliamente en el análisis de datos y la inteligencia empresarial. |
| PHP | Se integra en HTML y se utiliza ampliamente para crear páginas web y aplicaciones dinámicas, con una fuerte presencia en sistemas de gestión de contenidos como WordPress. aplicaciones, con una fuerte presencia en sistemas de gestión de contenidos como WordPress. |
| Golang | Lenguaje de programación compilado de tipado estático diseñado por Google. Conocido por su sencillez y eficiencia, se utiliza para crear aplicaciones escalables y de alto rendimiento, especialmente en servicios en la nube y sistemas distribuidos. -escalables y de alto rendimiento, especialmente en servicios en la nube y sistemas distribuidos. |
| Óxido | Lenguaje de programación de sistemas centrado en la seguridad y la concurrencia que proporciona seguridad de memoria sin utilizar un recolector de basura y se utiliza para crear software fiable y eficiente, especialmente en programación de sistemas y ensamblaje web. Proporciona seguridad de memoria sin utilizar un recolector de basura y se utiliza para crear software fiable y eficiente, especialmente en programación de sistemas y ensamblaje web. |
3.2 Crear incrustación
A continuación, utilizamos elpymilvus[model]Para el conjunto de datos anterior se genera el vector Embedding correspondiente. sobre el pymilvus[model] Para su uso, consulte https://milvus.io/blog/introducing-pymilvus-integrations-with-embedding-models.md
def gen_embedding(model_name): openai_ef = model.dense.OpenAIEmbeddingFunction( model_name=model_name, api_key=os.environ["OPENAI_API_KEY"] ) docs_embeddings = openai_ef.encode_documents(df['description'].tolist()) return docs_embeddings, openai_ef
A continuación, la incrustación generada se deposita en la colección de Milvus.
def save_embedding(docs_embeddings, collection_name, dim):
data = [
{"id": i, "vector": docs_embeddings[i].data, "text": row.language}
for i, row in df.iterrows()
]
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(collection_name=collection_name, dimension=dim)
res = milvus_client.insert(collection_name=collection_name, data=data)
3.3 Consultas
Definimos funciones de consulta para facilitar la recuperación del vector Embedding.
def query_results(query, collection_name, openai_ef):
query_embeddings = openai_ef.encode_queries(query)
res = milvus_client.search(
collection_name=collection_name,
data=query_embeddings,
limit=4,
output_fields=["text"],
)
result = {}
for items in res:
for item in items:
result[item.get("entity").get("text")] = item.get('distance')
return result
3.4 Evaluación del rendimiento del modelo de incrustación
Utilizamos dos modelos de incrustación de OpenAI.text-embedding-3-small responder cantando text-embedding-3-largepara las dos consultas siguientes. Existen muchas métricas de evaluación, como la precisión, la recuperación, el MRR, el MAP, etc. Aquí utilizamos la precisión y la recuperación.
Precisión Evalúa el porcentaje de contenido genuinamente relevante en los resultados de búsqueda, es decir, cuántos de los resultados devueltos son relevantes para la consulta de búsqueda.
Precisión = TP / (TP + FP)
En este caso, los Verdaderos Positivos (TP) son los que son realmente relevantes para la consulta, mientras que los Falsos Positivos (FP) se refieren a los que no son relevantes en los resultados de la búsqueda.
La recuperación evalúa la cantidad de contenidos relevantes recuperados con éxito de todo el conjunto de datos.
Recuperación = TP / (TP + FN)
Los falsos negativos (FN) se refieren a todos los elementos relevantes que no se incluyen en el conjunto de resultados final.
Para una explicación más detallada de estos dos conceptos
Consulta 1::auto garbage collection
Temas relacionados: Java, Python, JavaScript, Golang
| Rango | texto-incrustado-3-pequeño | text-embedding-3-large |
|---|---|---|
| 1 | ❎ Óxido | ❎ Óxido |
| 2 | ❎ C/C++ | ❎ C/C++ |
| 3 | ✅ Golang | Java |
| 4 | Java | ✅ Golang |
| Precisión | 0.50 | 0.50 |
| Recall | 0.50 | 0.50 |
Consulta 2::suite for web backend server development
Temas relacionados: Java, JavaScript, PHP, Python (Las respuestas incluyen un juicio subjetivo)
| Rango | texto-incrustado-3-pequeño | text-embedding-3-large |
|---|---|---|
| 1 | PHP | JavaScript |
| 2 | Java | Java |
| 3 | JavaScript | PHP |
| 4 | ❎ C# | Python |
| Precisión | 0.75 | 1.0 |
| Recall | 0.75 | 1.0 |
En estas dos consultas, comparamos los dos modelos de incrustación por precisión y recuerdo text-embedding-3-small responder cantando text-embedding-3-large El modelo Embedding puede utilizarse como punto de partida. Podemos utilizarlo como punto de partida para aumentar el número de objetos de datos del conjunto de datos, así como el número de consultas, de modo que el modelo Embedding pueda evaluarse con mayor eficacia.
04. Resumen
En las aplicaciones de Generación Aumentada de Recuperación (RAG), la selección de modelos de Incrustación vectorial adecuados es crucial. En este artículo, ilustramos que tras seleccionar un modelo genérico de MTEB a partir de los requisitos empresariales reales, la precisión y la recuperación se utilizan para probar el modelo basado en un conjunto de datos específico de la empresa, con el fin de seleccionar el modelo de Incrustación más adecuado, lo que a su vez mejora eficazmente la precisión de recuperación de la aplicación RAG.
El código completo puede descargarse
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...