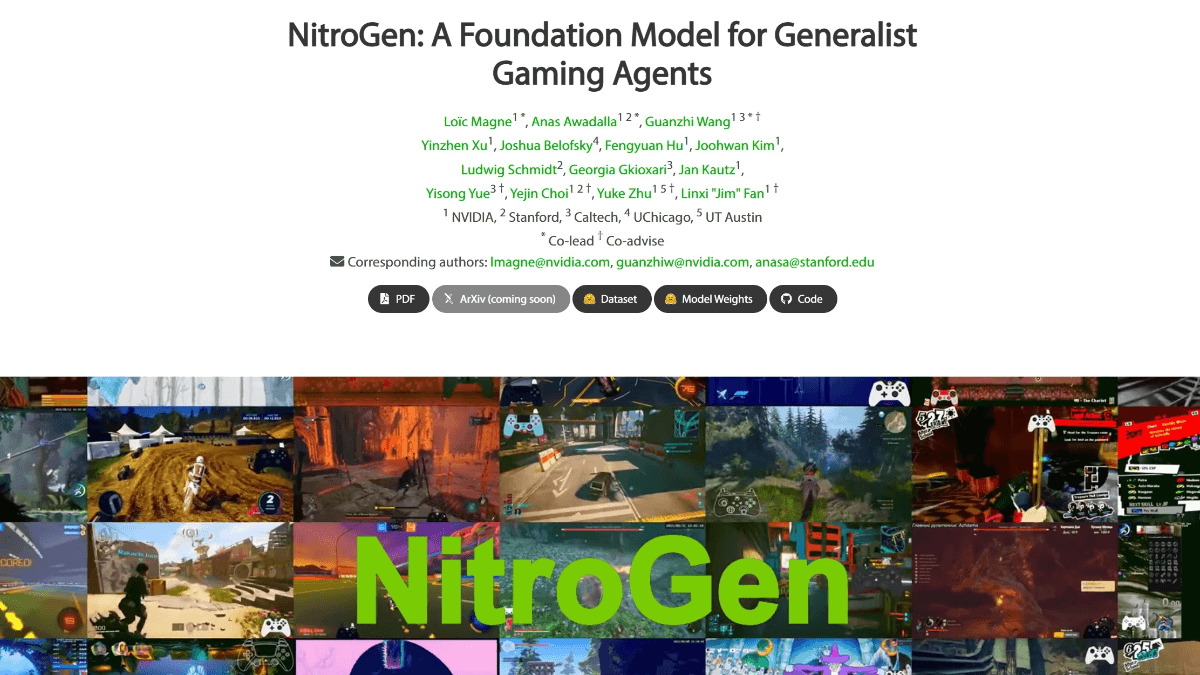
RapBank: modelo de generación directa de voces de rap a partir de letras y pistas de acompañamiento (conjunto de datos abierto actualmente).
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 61.2K 00

Introducción general
RapBank es un conjunto de datos y herramientas diseñado para generar letras de rap. Creado por NZqian, el proyecto tiene como objetivo proporcionar a los investigadores y desarrolladores un conjunto de datos de letras de rap de alta calidad mediante la recopilación y el procesamiento de canciones de rap de YouTube.RapBank contiene más de 90.000 canciones de rap en 84 idiomas, y proporciona tuberías de procesamiento detalladas e instrucciones de uso para ayudar a los usuarios a procesar datos y entrenar modelos de manera eficiente. Los datos y el código del proyecto son de código abierto en GitHub bajo licencia CC BY-NC-SA 4.0.
人声的模型(目前开放了数据集)-1")
Lista de funciones
- Descarga del conjunto de datos: Un conjunto de datos de más de 90.000 canciones de rap en varios idiomas.
- Canal de procesamiento de datos: incluye pasos como la separación de fuentes, la segmentación y el reconocimiento de letras para ayudar a los usuarios a procesar los datos con eficacia.
- Documentación detallada: proporciona instrucciones completas y código de ejemplo para ayudar a los usuarios a empezar rápidamente.
- Código fuente abierto: todo el código y los datos son de código abierto en GitHub, lo que resulta cómodo para que los usuarios realicen un desarrollo secundario.
- Acuerdo de licencia: Los datos y el código están sujetos al acuerdo de licencia CC BY-NC-SA 4.0, que garantiza que los usuarios se mantengan dentro de los límites de la legalidad.
Utilizar la ayuda
Proceso de instalación
- Almacén de proyectos de clonación:
git clone https://github.com/NZqian/RapBank.git
cd RapBank
- Instale la dependencia:
pip install -r requirements.txt
- Descargue el conjunto de datos y colóquelo en la carpeta especificada, por ejemplo
/path/to/your/data/wav.
tratamiento de datos
- Utilice los scripts proporcionados para procesar los datos:
bash pipeline.sh /path/to/your/data /path/to/save/features start_stage stop_stage
start_stageresponder cantandostop_stagese utilizan para especificar las etapas de inicio y fin del procesamiento, que van de 0 a 5.- Se recomienda utilizar varias GPU para acelerar el procesamiento.
Función Flujo de operaciones
- Descarga del conjunto de datos: Visite la página de GitHub para descargar los archivos del conjunto de datos necesarios.
- Procesamiento de datos: Siga los pasos anteriores para instalar las dependencias y ejecutar los scripts de procesamiento para generar los archivos de características necesarios.
- Entrenamiento del modelo: Utilice los datos procesados para el entrenamiento del modelo, consulte el código de ejemplo en el documento del proyecto para conocer los pasos específicos.
- Análisis de resultados: generación de letras de rap utilizando el modelo generado y análisis y optimización de los resultados.
Funciones detalladas
- Descarga de datos: Un conjunto de datos de más de 90.000 canciones de rap está disponible para que los usuarios lo descarguen y lo utilicen para investigación y desarrollo según sus necesidades.
- Proceso de datos: Incluye múltiples pasos, como la separación de fuentes, la segmentación y el reconocimiento de letras, para ayudar a los usuarios a procesar y analizar los datos con eficacia.
- Documentación detallada: El proyecto proporciona instrucciones completas y código de ejemplo para ayudar a los usuarios a empezar rápidamente y el desarrollo secundario.
- código abiertoTodos los códigos y datos son de código abierto en GitHub y pueden ser descargados y utilizados libremente por los usuarios.
- licenciaLos datos y el código siguen el acuerdo de licencia CC BY-NC-SA 4.0, lo que garantiza que el usuario los utiliza dentro de los límites legales.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...