
QwenLong-L1.5 - Modelo de inferencia de texto largo de código abierto de Ali Tongyi Lab
Últimos recursos sobre IAPublicado hace 3 meses Círculo de intercambio de inteligencia artificial 22.8K 00

¿Qué es QwenLong-L1.5?
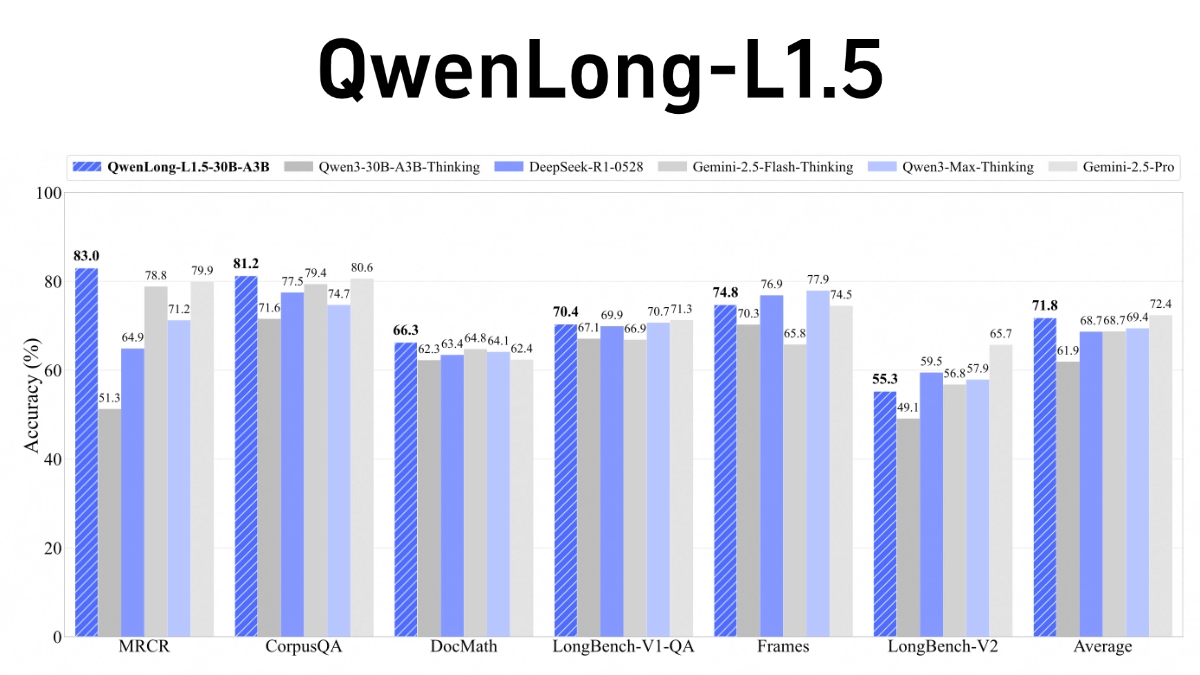
QwenLong-L1.5 es un modelo de inferencia de textos largos de código abierto de Alibaba Tongyi Labs, centrado en la resolución de problemas de inferencia complejos con contextos ultralargos (por ejemplo, 1M-4M de tokens). El avance principal radica en tres innovaciones importantes en la fase de post-entrenamiento: la generación de datos de inferencia multi-hop de alta calidad a través del grafo de conocimiento, el análisis sintáctico SQL y el marco del cuerpo multi-inteligencia; la propuesta de la estrategia de control de entropía adaptativa AEPo para equilibrar dinámicamente la estabilidad del entrenamiento; y el diseño de la arquitectura del agente de memoria para procesar el texto ultra-largo en trozos y actualizar el resumen de memoria en tiempo real. El modelo supera a GPT-5 y Gemini-2.5-Pro en LongBench-V2 y otras listas, especialmente en la tarea de texto ultralargo, y también mejora las capacidades de propósito general, como el razonamiento matemático.
Características de QwenLong-L1.5
- Mejora significativa del razonamiento en contextos largosQwenLong-L1.5: Con un esquema sistemático de post-entrenamiento, QwenLong-L1.5 sobresale en la inferencia de contextos largos, manejando tareas más allá de su ventana física de contexto (256K).
- Estrategias innovadoras de síntesis de datos y aprendizaje por refuerzoDesarrollo de un nuevo proceso de síntesis de datos centrado en la creación de tareas desafiantes que requieren trazabilidad multisalto y razonamiento probatorio distribuido globalmente, introduciendo estrategias de aprendizaje por refuerzo como el muestreo equilibrado de tareas y la optimización de políticas de control de entropía adaptativa para estabilizar el entrenamiento en contextos largos.
- Potente marco de gestión de memoriaEl uso del aprendizaje de refuerzo por fusión en varias etapas, combinado con un mecanismo de actualización de la memoria, permite al modelo manejar tareas más largas fuera de la ventana de contexto de 256K de una sola inferencia.
- excelente rendimientoEn las pruebas de contexto largo, QwenLong-L1.5 supera a su modelo de referencia Qwen3-30B-A3B-Thinking en una media de 9,9 puntos, con un rendimiento comparable al de modelos superiores como GPT-5 y Gemini-2.5-Pro. Su marco memoria-cuerpo inteligente logra un aumento de rendimiento de 9,48 puntos sobre el modelo de referencia de cuerpo inteligente en tareas ultralargas (de 1 a 4 millones de tokens).
- ampliar los propios recursos financierosEl modelo es de código abierto para facilitar su uso a investigadores y desarrolladores.
Principales ventajas de QwenLong-L1.5
- Capacidad de procesamiento de textos superlargosPuede realizar tareas que superen su ventana de contexto física (256K), y es adecuado para procesar razonamientos y análisis de textos ultralargos, como documentos largos, conjuntos de datos complejos, etc.
- Estrategias de formación innovadoras: Combinar métodos de aprendizaje por refuerzo como el muestreo equilibrado de tareas y la optimización de políticas controlada por entropía adaptativa (AEPO) para mejorar eficazmente la estabilidad y el rendimiento del modelo en tareas de contexto largo.
- Gestión eficiente de la memoriaGracias al mecanismo de actualización de la memoria y al aprendizaje de refuerzo por fusión en varias fases, el modelo puede gestionar eficazmente la información de los textos largos y lograr un procesamiento eficiente de las tareas ultralargas (de 1 a 4 millones de tokens).
- Rendimiento superiorEn las pruebas comparativas de contexto largo, QwenLong-L1.5 supera significativamente a su modelo de referencia e incluso rivaliza con modelos superiores como GPT-5 y Gemini-2.5-Pro.
¿Cuál es la página web oficial de QwenLong-L1.5?
- Repositorio GitHub:: https://github.com/Tongyi-Zhiwen/Qwen-Doc
- Biblioteca de modelos HuggingFace:: https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B
- Documento técnico arXiv:: https://arxiv.org/pdf/2512.12967
Personas a las que se aplica QwenLong-L1.5
- investigador en procesamiento del lenguaje natural (PLN)QwenLong-L1.5: Las capacidades de procesamiento de contextos largos y las innovadoras estrategias de entrenamiento de QwenLong-L1.5 proporcionan a los investigadores nuevas herramientas para estudiar cuestiones de vanguardia como el razonamiento de textos largos y la gestión de la memoria, contribuyendo así al avance de la investigación en el campo del procesamiento del lenguaje natural.
- Desarrolladores de inteligencia artificial: Su naturaleza de código abierto lo hace ideal para que los desarrolladores creen aplicaciones de procesamiento de textos largos, como servicios inteligentes de atención al cliente, análisis de documentos, creación de contenidos, etc., lo que puede ayudar a los desarrolladores a desarrollar rápidamente funciones de procesamiento de textos largos de alto rendimiento.
- científico de datosQwenLong-L1.5 es capaz de realizar análisis e inferencias de texto largo de forma eficaz cuando se trabaja con conjuntos de datos de texto a gran escala, lo que proporciona a los científicos de datos una potente ayuda para el análisis de datos y las tareas de aprendizaje automático.
- Equipo técnico de la empresaQwenLong-L1.5 puede ayudar a las empresas que tienen que trabajar con textos largos, como empresas financieras, jurídicas, médicas y otros sectores, a gestionar de forma más eficiente datos de texto largo como contratos, informes, historiales médicos y otros datos de texto largo, y a mejorar la eficiencia de la empresa.
- Investigadores universitariosQwenLong-L1.5: En la investigación académica, especialmente en campos que implican el análisis de textos largos, como la investigación literaria, el análisis de documentos históricos, etc., QwenLong-L1.5 puede utilizarse como herramienta de investigación para ayudar a los investigadores a desenterrar la información profunda del texto.
- educadorEn el campo de la educación, QwenLong-L1.5 puede utilizarse para ayudar a la enseñanza, como la corrección automática de redacciones largas y el análisis de trabajos académicos, proporcionando a los educadores herramientas de apoyo a la enseñanza más eficientes.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...