Qwen3-ASR-Flash - una serie de modelos de reconocimiento de voz lanzados por Ali Tongyi Qianqian
Últimos recursos sobre IAPublicado hace 7 meses Círculo de intercambio de inteligencia artificial 48.6K 00

¿Qué es Qwen3-ASR-Flash?
Qwen3-ASR-Flash es el último modelo de reconocimiento de voz de alta precisión de Alibaba, basado en la tecnología Qwen3 Modelo base, entrenado mediante datos multimodales masivos. Admite 11 idiomas y múltiples acentos, incluidos dialectos como el mandarín, sichuan, minnan, wu, cantonés, así como inglés británico y americano. Entre sus principales características se incluyen una precisión de reconocimiento líder, una capacidad de reconocimiento de canciones asombrosa (tasa de error inferior a 8%), reconocimiento personalizado (los usuarios pueden proporcionar texto de fondo para obtener resultados personalizados), reconocimiento de idiomas con rechazo no vocal y gran solidez en entornos acústicos complejos. Los usuarios pueden probar el modelo gratuitamente a través de ModelScope, Hugging Face y la API AliCloud Hundred Refinements.
Qwen3-ASR-Flash Características funcionales
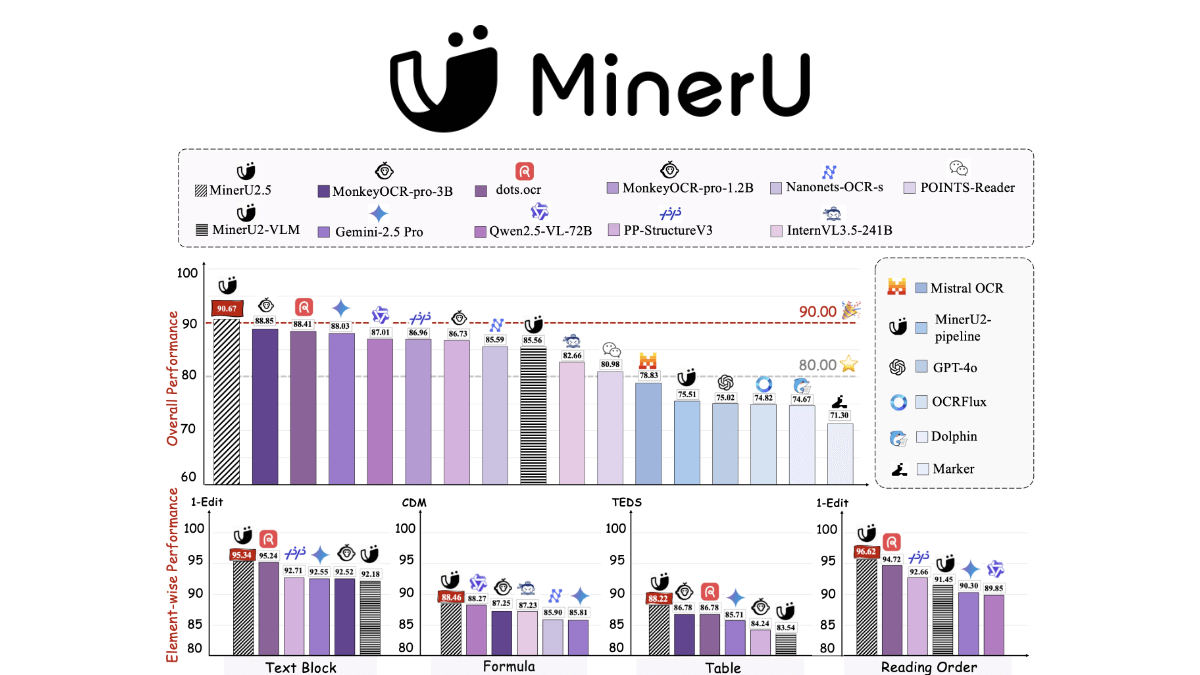
- Reconocimiento de gran precisiónEl mejor rendimiento en inglés, chino y pruebas de referencia multilingües, con un reconocimiento preciso de múltiples idiomas y dialectos.
- reconocimiento de cancionesEl sistema admite el canto limpio y el reconocimiento de canciones completas con música de fondo, y la tasa de error medida es inferior a 8%.
- Identificación personalizadaEl usuario puede proporcionar el texto de fondo en cualquier formato, y el modelo puede ajustar los resultados del reconocimiento en consecuencia, sin preprocesamiento.
- Reconocimiento lingüístico y rechazo no vocal: Distingue con precisión los idiomas hablados y filtra automáticamente los segmentos no hablados, como el silencio y el ruido de fondo.
- gran robustez: Mantiene una alta precisión en entornos acústicos complejos y cuando se enfrenta a patrones de texto difíciles, como frases largas y difíciles y cambios de idioma a mitad de frase.
Principales ventajas de Qwen3-ASR-Flash
- Reconocimiento de gran precisión: Excelente rendimiento en pruebas de reconocimiento multilingüe y dialectal, con tasas de error inferiores a las de los productos de la competencia.
- Soporte multilingüeEl modelo único es compatible con 11 idiomas y varios dialectos: mandarín, inglés, francés y alemán, entre otros.
- Identificación personalizadaLos usuarios pueden proporcionar texto de fondo en cualquier formato, y el modelo puede utilizar de forma inteligente la información contextual para obtener resultados de reconocimiento personalizados.
- reconocimiento de cancionesAdmite el canto limpio y el reconocimiento de canciones completas con música de fondo, y la tasa de error medida es inferior a 8%, lo que supone un excelente rendimiento en el campo del reconocimiento de canciones.
- Reconocimiento lingüístico y rechazo no vocalLa capacidad de distinguir con precisión los idiomas hablados y filtrar automáticamente los segmentos no hablados, como el silencio y el ruido de fondo, mejora la eficacia del reconocimiento.
- gran robustez: Mantiene una alta precisión en entornos acústicos complejos y cuando se enfrenta a patrones de texto difíciles, como frases largas y difíciles y cambios de idioma a mitad de frase.
¿Cuál es la página web oficial de Qwen3-ASR-Flash?
- Página web del proyecto: https://bailian.console.aliyun.com/?spm=5176.29597918.J_tAwMEW-mKC1CPxlfy227s.1.4f007b08aWhTjW&tab=model#/model-market/detail /grupo-qwen3-asr-flash?modelGroup=grupo-qwen3-asr-flash
- Demostración de la experiencia en línea:: https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
Personas para las que Qwen3-ASR-Flash es adecuado
- Usuarios que necesitan una transcripción de voz de alta precisiónpor ejemplo, periodistas, grabadores de conferencias, investigadores, etc., pueden convertir con rapidez y precisión los contenidos de voz en texto.
- políglotapor ejemplo, estudiantes de lenguas extranjeras, empleados de empresas multinacionales, participantes en conferencias internacionales, etc., pueden ayudar a superar las barreras lingüísticas.
- creador de contenidosPor ejemplo, los videoblogueros, los anfitriones de podcasts, etc., pueden generar subtítulos y transcripciones de forma eficaz.
- Profesionales del sectorPor ejemplo, los profesionales de los sectores médico, financiero y jurídico pueden utilizar funciones de reconocimiento personalizadas para identificar con precisión la terminología.
- Personas con necesidades especiales de reconocimiento del hablaPor ejemplo, las personas con deficiencias auditivas, que pueden entender mejor la información hablada con ayuda del modelo; y los usuarios que necesitan reconocimiento de voz en entornos ruidosos, como el personal de atención al cliente y los periodistas in situ.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...