Consejos avanzados de Prompt: Control preciso de la salida de LLM y definición de la lógica de ejecución con pseudocódigo

Como todos sabemos, cuando necesitamos que un gran modelo lingüístico realice una tarea, necesitamos introducir una Prompt para guiar su ejecución, que se describe utilizando lenguaje natural. En el caso de tareas sencillas, el lenguaje natural puede describirlas con claridad, por ejemplo: "Por favor, traduzca lo siguiente al chino simplificado:", "Por favor, genere un resumen de lo siguiente:", etc.
Sin embargo, cuando nos encontramos con algunas tareas complejas, como la que requiere que el modelo genere un formato JSON específico, o la tarea tiene múltiples ramas, cada rama necesita ejecutar múltiples subtareas, y las subtareas están interrelacionadas entre sí, entonces las descripciones en lenguaje natural no son suficientes.
tema de debate
He aquí dos preguntas que invitan a la reflexión antes de seguir leyendo:
- Hay varias frases largas, cada una de las cuales debe dividirse en frases más cortas de no más de 80 caracteres, y luego enviarlas a un formato JSON que describa claramente la correspondencia entre las frases largas y las cortas.
Por ejemplo:
[
{
"long": "This is a long sentence that needs to be split into shorter sentences.",
"short": [
"This is a long sentence",
"that needs to be split",
"into shorter sentences."
]
},
{
"long": "Another long sentence that should be split into shorter sentences.",
"short": [
"Another long sentence",
"that should be split",
"into shorter sentences."
]
}
]
- Un texto original subtitulado con sólo información sobre los diálogos, del que ahora hay que extraer capítulos, hablantes y, a continuación, enumerar los diálogos por capítulos y párrafos. Si hay varios oradores, cada diálogo debe ir precedido por el orador, no si el mismo orador habla consecutivamente. (Se trata de una GPT que yo mismo utilizo para organizar guiones de vídeo). Cotejo de guiones de vídeo GPT)
Ejemplo de entrada:
所以我要引用一下埃隆·马斯克的话,希望你不要介意。 我向你道歉。 但他并不认同这是一个保障隐私和安全的模型。 他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? 不在意? 那是他的观点。 显然,我不这么认为。 我们也不这么认为。 Mira,感谢你能和我们在一起。 我知道你可能稍微有点忙。 我有许多问题想向 Mira 提问,但我们只有 20 分钟。 所以我想先设定一下大家的期望。 我们会专注于一些主题, 包括一些近期的新闻和 Mira 作为首席技术官所负责的一些领域。 希望我们能深入探讨其中的一些话题。 我想我第一个问题是, 考虑到你现在极其忙碌, 以及新闻的攻击, 有些好有些坏, 你大约六年前加入了这个公司。 那时,它是一个截然不同的组织。 你相对低调,不太为人知晓。 你是否怀念那些能够全神贯注工作的日子? 我想说,我们依旧全神贯注在工作中。 只不过工作的内容已经发展变化了,它不仅仅关乎研究。 也是因为,你知道,研究已经得到了很大的进展。 这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中所以,使命依然如一, 我们在研究上也已经取得了很多进展,工作领域也在不断扩大。 公众对此的关注度也很高, 这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。 但你要知道, 鉴于我们所做的事情的重要性,这种关注是非常必要的, 而且这是积极的。
Muestra de salida:
### 引言 **主持人**: 所以我要引用一下埃隆·马斯克的话,希望你不要介意。我向你道歉,但他并不认同这是一个保障隐私和安全的模型。他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? **Mira**: 那是他的观点。显然,我不这么认为。我们也不这么认为。 ### 欢迎与介绍 **主持人**: Mira,感谢你能和我们在一起。我知道你可能稍微有点忙。我有许多问题想向你提问,但我们只有 20 分钟。所以我想先设定一下大家的期望。我们会专注于一些主题,包括一些近期的新闻和你作为首席技术官所负责的一些领域。希望我们能深入探讨其中的一些话题。 ### 职业生涯回顾 **主持人**: 我想我第一个问题是,考虑到你现在极其忙碌,以及新闻的攻击,有些好有些坏,你大约六年前加入了这个公司。那时,它是一个截然不同的组织。你相对低调,不太为人知晓。你是否怀念那些能够全神贯注工作的日子? **Mira**: 我想说,我们依旧全神贯注在工作中。只不过工作的内容已经发展变化了,它不仅仅关乎研究。也是因为,研究已经得到了很大的进展。这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中。所以,使命依然如一,我们在研究上也已经取得了很多进展,工作领域也在不断扩大。公众对此的关注度也很高,这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。但你要知道,鉴于我们所做的事情的重要性,这种关注是非常必要的,而且这是积极的。
La esencia de Prompt
Quizá hayas leído muchos artículos en Internet sobre cómo escribir técnicas Prompt y memorizado un montón de plantillas Prompt, pero ¿cuál es la esencia de Prompt? ¿Por qué necesitamos Prompt?
Prompt es esencialmente una instrucción de control para el LLM, descrita en lenguaje natural, que permite al LLM entender nuestros requisitos y luego convertir las entradas en nuestras salidas deseadas según sea necesario.
Por ejemplo, la técnica comúnmente utilizada de few-shot consiste en dejar que el LLM comprenda nuestros requisitos mediante ejemplos, y luego remitirse a las muestras para producir nuestros resultados deseados. Por ejemplo, CoT (Chain of Thought) consiste en descomponer artificialmente la tarea y limitar el proceso de ejecución, para que el LLM pueda seguir el proceso y los pasos especificados por nosotros, sin ser demasiado difuso ni saltarse los pasos clave, y así obtener mejores resultados.
Es como cuando íbamos a la escuela, cuando el profesor hablaba de teoremas matemáticos, tenía que darnos ejemplos, a través de los cuales podíamos entender el significado de los teoremas; cuando hacíamos experimentos, tenía que decirnos los pasos de los experimentos, e incluso si no entendíamos los principios de los experimentos, pero podíamos ejecutar los experimentos de acuerdo con los pasos, todavía podíamos obtener más o menos los mismos resultados.
¿Por qué a veces los resultados de Prompt no son óptimos?
Esto se debe a que el LLM no puede comprender con exactitud nuestros requisitos, lo cual está limitado, por un lado, por la capacidad del LLM para comprender y seguir instrucciones y, por otro, por la claridad y exactitud de la descripción de nuestro Prompt.
Cómo controlar con precisión la salida del LLM y definir su lógica de ejecución con ayuda de pseudocódigo.
Dado que Prompt es esencialmente una instrucción de control para el LLM, podemos escribir Prompt sin limitarnos a las descripciones tradicionales en lenguaje natural, sino que también podemos utilizar pseudocódigo para controlar con precisión la salida del LLM y definir su lógica de ejecución.
¿Qué es el pseudocódigo?
De hecho, el pseudocódigo tiene una larga historia. El pseudocódigo es un método de descripción formal para describir algoritmos, que es un tipo de método de descripción entre el lenguaje natural y el lenguaje de programación para describir los pasos y procesos del algoritmo. En varios libros de algoritmos y documentos, a menudo vemos la descripción de pseudo-código, incluso no es necesario saber en un idioma, sino también a través del pseudo-código para entender la ejecución del flujo del algoritmo.
¿Qué tan bien entiende LLM el pseudo-código? En realidad la comprensión de LLM de pseudo-código es bastante fuerte, LLM ha sido entrenado con una gran cantidad de código de calidad y puede entender fácilmente el significado de pseudo-código.
¿Cómo escribir pseudocódigo Prompt?
El pseudocódigo es muy familiar para los programadores, y para los no programadores, se puede escribir pseudocódigo sencillo con sólo recordar algunas reglas básicas. Algunos ejemplos:
- Variables, que se utilizan para almacenar datos, por ejemplo, para representar entradas o resultados intermedios con algunos símbolos específicos.
- Tipo, utilizado para definir el tipo de datos, como cadenas, números, matrices, etc.
- que define la lógica de ejecución de una subtarea concreta
- Flujo de control, utilizado para controlar el proceso de ejecución del programa, como bucles, sentencias condicionales, etc.
- sentencia if-else, si se cumple la condición A, ejecuta la tarea A, en caso contrario ejecuta la tarea B.
- Un bucle for que realiza una tarea para cada elemento de la matriz.
- bucle while, cuando se cumpla la condición A, la tarea B se ejecutará de forma continua.
Ahora escribamos el pseudocódigo Prompt, utilizando como ejemplo las dos preguntas de reflexión anteriores.
Pseudocódigo para generar un formato JSON específico
El formato JSON deseado puede describirse claramente con la ayuda de un fragmento de pseudocódigo similar a la definición de tipos de TypeScript:
Please split the sentences into short segments, no more than 1 line (less than 80 characters, ~10 English words) each.
Please keep each segment meaningful, e.g. split from punctuations, "and", "that", "where", "what", "when", "who", "which" or "or" etc if possible, but keep those punctuations or words for splitting.
Do not add or remove any words or punctuation marks.
Input is an array of strings.
Output should be a valid json array of objects, each object contains a sentence and its segments.
Array<{
sentence: string;
segments: string[]
}>
Organización de guiones de subtítulos con pseudocódigo
La tarea de cotejar textos subtitulados es relativamente compleja. Si se imagina escribir un programa para realizar esta tarea, puede haber muchos pasos, como extraer capítulos, luego extraer hablantes y, por último, cotejar diálogos según capítulos y hablantes. Con la ayuda del pseudocódigo, podemos descomponer esta tarea en varias subtareas, para las que ni siquiera es necesario escribir código específico, sino que basta con describir claramente la lógica de ejecución de las subtareas. A continuación, se ejecutan estas subtareas paso a paso y, por último, se integra la salida resultante.
Podemos utilizar algunas variables para almacenar en, tales como subjectyspeakersychaptersyparagraphs etc.
También podemos utilizar bucles For para recorrer capítulos y párrafos, y sentencias If-else para determinar si es necesario mostrar el nombre del orador.
Su tarea consiste en reorganizar las transcripciones de vídeo para facilitar su lectura y reconocer a los interlocutores en los diálogos entre varias personas. Aquí tiene los pseudocódigos sobre cómo hacerlo Estos son los pseudocódigos para hacerlo
def extract_subject(transcript):
# Find the subject in the transcript and return it as a string.
def extract_chapters(transcript):
# Find the chapters in the transcript and return them as a list of strings.
def extract_speakers(transcript):
# Find the speakers in the transcript and return them as a list of strings.
def find_paragraphs_and_speakers_in_chapter(chapter):
# Find the paragraphs and speakers in a chapter and return them as a list of tuples.
# Each tuple contains the speaker and their paragraphs.
def format_transcript(transcript):
# extract the subject, speakers, chapters and print them
subject = extract_subject(transcript)
print("Subject:", subject)
speakers = extract_speakers(transcript)
print("Speakers:", speakers)
chapters = extract_chapters(transcript)
print("Chapters:", chapters)
# format the transcript
formatted_transcript = f"# {subject}\n\n"
for chapter in chapters:
formatted_transcript += f"## {chapter}\n\n"
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers:
# if there are multiple speakers, print the speaker's name before each paragraph
if speakers.size() > 1:
formatted_transcript += f"{speaker}:"
formatted_transcript += f"{speaker}:"
for paragraph in paragraphs:
formatted_transcript += f" {paragraph}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
Veamos cómo funciona:
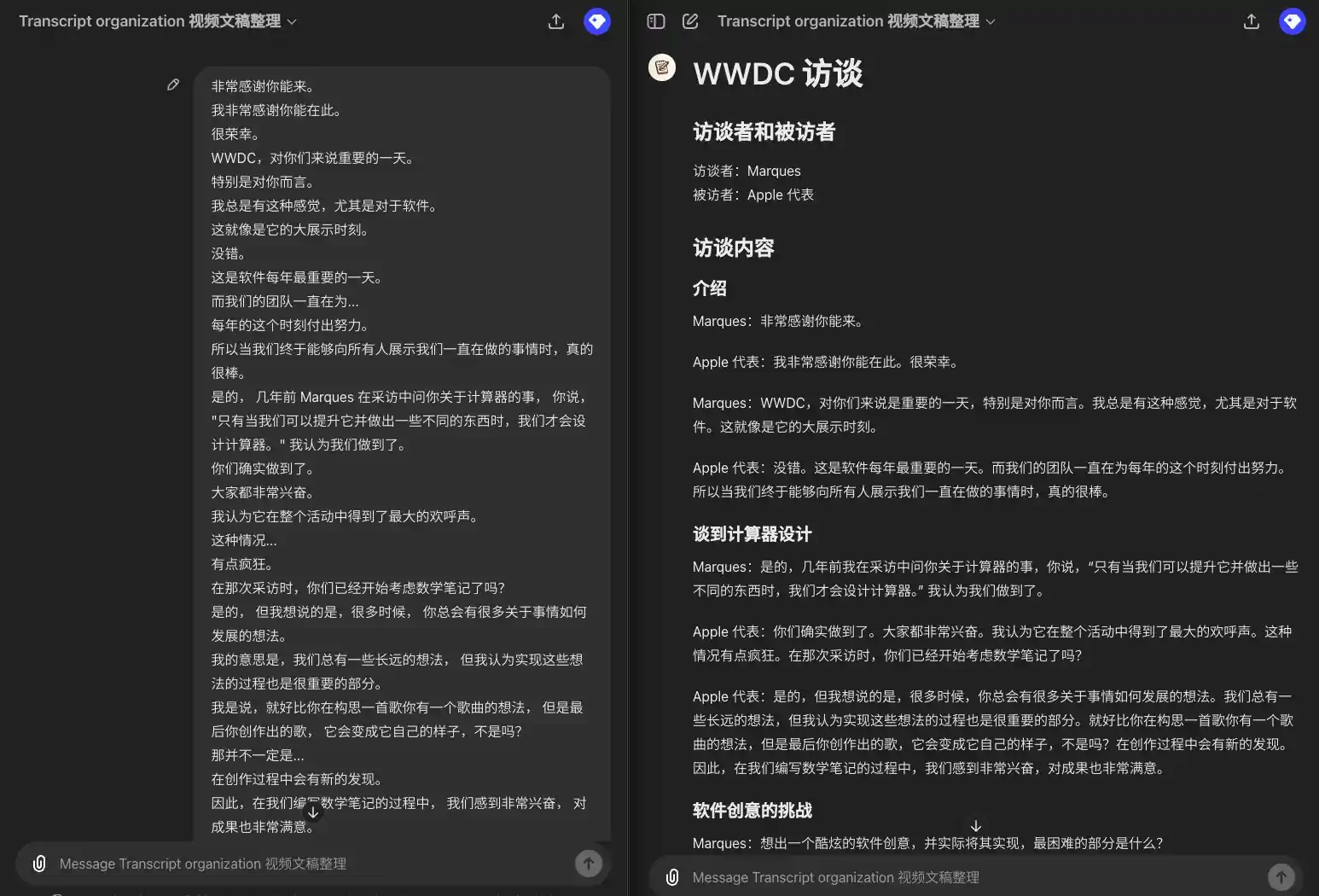
Recopilación de las transcripciones de las entrevistas de la WWDC
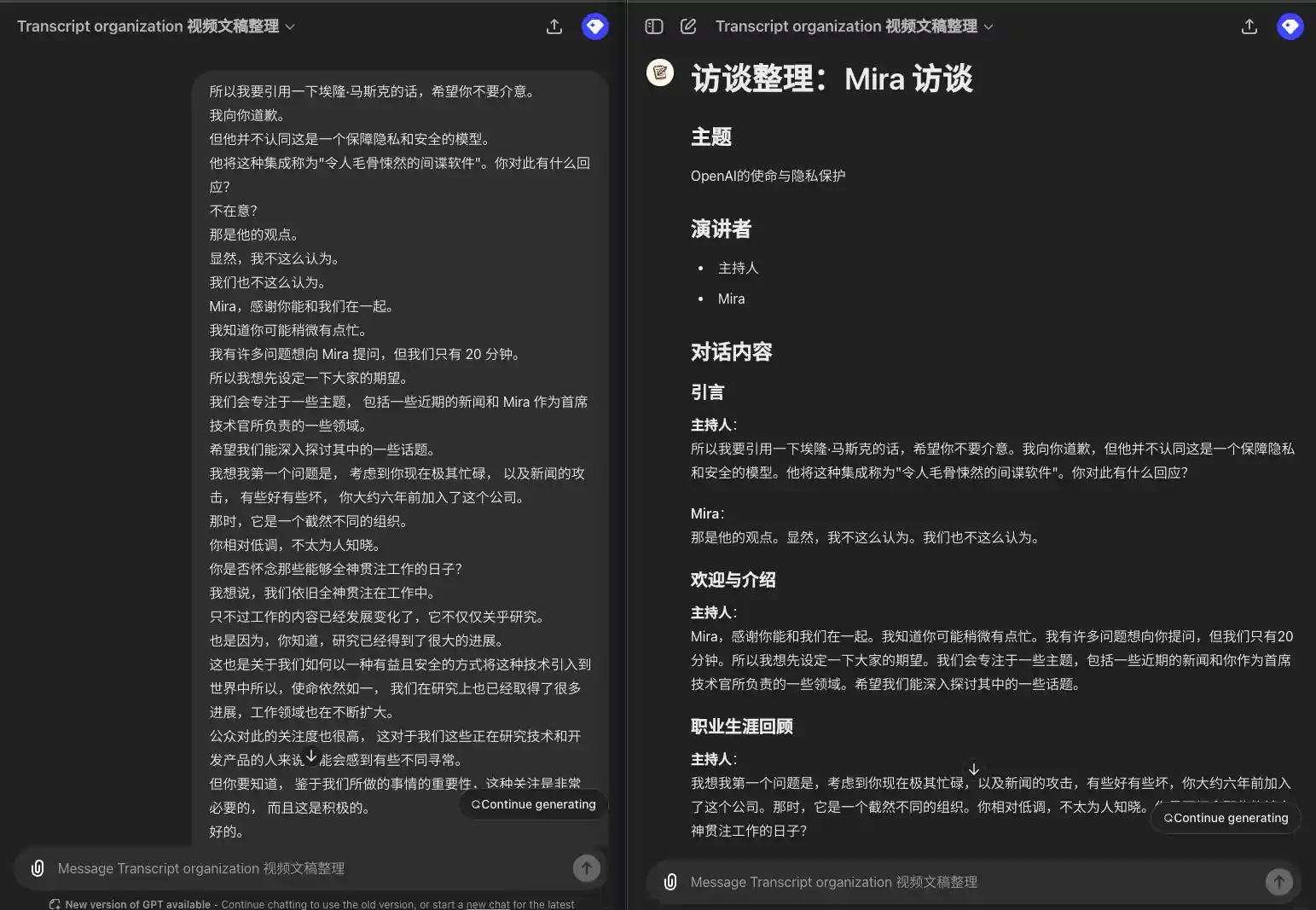
Oradores múltiples, Oradores de espectáculos
1 Altavoz, no se muestra ningún altavoz
También puedes usar el GPT que generé con este Prompt:Organización de transcripción GPT
Haga que ChatGPT dibuje varias imágenes a la vez con un pseudocódigo
También he aprendido recientemente un uso muy interesante del término de un internauta taiwanés, Sensei Yin Xiangzhi, que es el siguienteHaz que ChatGPT dibuje varias imágenes a la vez con pseudocódigo.
Ahora bien, si quieres hacer ChatGPT Si desea generar más de una imagen a la vez, puede utilizar el pseudocódigo para descomponer la tarea de generar varias imágenes en varias subtareas y, a continuación, ejecutar varias subtareas a la vez y, por último, integrar la salida resultante.
下面是一段画图的伪代码,请按照伪代码的逻辑,用DALL-E画图:
images_prompts = [
{
style: "Kawaii",
prompt: "Draw a cute dog",
aspectRatio: "Wide"
},
{
style: "Realistic",
prompt: "Draw a realistic dog",
aspectRatio: "Square"
}
]
images_prompts.forEach((image_prompt) =>{
print("Generating image with style: " + image_prompt.style + " and prompt: " + image_prompt.prompt + " and aspect ratio: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})

resúmenes
A través del ejemplo anterior, podemos ver que con la ayuda del pseudocódigo, podemos controlar con mayor precisión el resultado de salida de LLM y definir su lógica de ejecución, en lugar de limitarnos a la descripción en lenguaje natural. Cuando nos encontramos con algunas tareas complejas, o tareas con múltiples ramas, cada rama necesita ejecutar múltiples sub-tareas, y las sub-tareas están relacionadas entre sí, entonces el uso de pseudo-código para describir el Prompt será más claro y preciso.
Cuando escribimos una Prompt, recordamos que una Prompt es esencialmente una instrucción de control para el LLM, descrita en lenguaje natural, que permite al LLM entender lo que queremos, y luego convertir las entradas en las salidas que esperamos según sea necesario. En cuanto a la forma de describir el Prompt, puede ser flexible en muchas formas, como few-shot, CoT, pseudo-código, etc.
Más ejemplos:
Generación de metaindicadores de "pseudocódigo" para un control preciso del formato de salida
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...