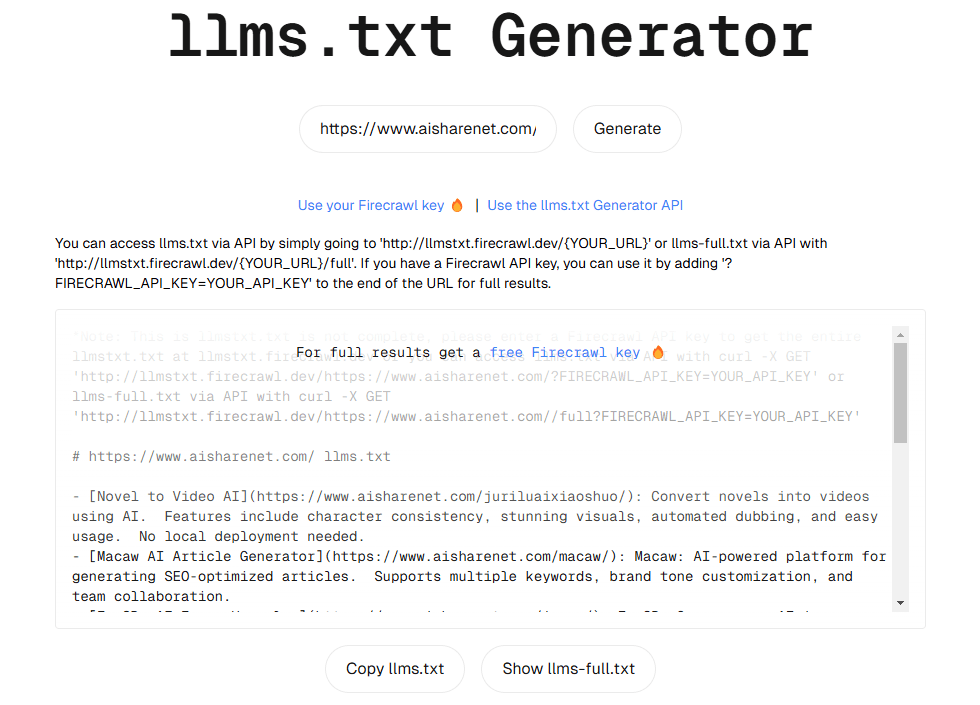
Flying Paddle PP-TableMagic: extracción de información estructurada para tablas complejas
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 64.7K 00

El objetivo del reconocimiento de tablas es analizar tablas en imágenes, identificar con precisión las estructuras de las tablas y la ubicación de las celdas, y reducirlas a formatos de tabla estructurados (por ejemplo, HTML). En la era actual de la información, una gran cantidad de datos de tablas importantes sigue existiendo en estado no estructurado (por ejemplo, imágenes de tablas de estadísticas de información en documentos escaneados, tablas de estadísticas de datos en estados financieros en PDF, etc.), que no pueden procesarse directamente de forma automática. Por ello, el reconocimiento de formularios se ha convertido en una tecnología clave en los escenarios de aplicación de la comprensión inteligente de documentos y el análisis automático de datos. Las soluciones de reconocimiento de formularios de alto rendimiento tienen un importante valor de aplicación en los campos del procesamiento de estados financieros, el análisis de datos de investigación científica, la contabilidad de reclamaciones de seguros, etc., que pueden mejorar significativamente la eficiencia del trabajo y reducir los errores humanos. Sin embargo, ante la complejidad de los formatos de los formularios en distintos escenarios de aplicación, los modelos tradicionales de reconocimiento de formularios de uso general suelen ser difíciles de adaptar. Por este motivo, Flying Paddle ha lanzado una nueva solución de reconocimiento de tablas, PP-TableMagic.

PP-TableEfecto mágico




PP-TableMagic Análisis técnico
Deficiencias de la tecnología actual
En la actualidad, las soluciones habituales de reconocimiento de tablas suelen adoptar el siguiente esquema: el usuario introduce una imagen de tabla, y el modelo predice tanto la estructura HTML como la posición de las celdas de la tabla en la imagen, para luego reducirla a una tabla HTML completa. Esta solución consigue un buen rendimiento de predicción en escenarios de tablas comunes y sencillas, pero adolece de dos problemas:
- El número de parámetros del modelo de reconocimiento de tablas suele ser pequeño, y las dos tareas, predicción de la estructura de la tabla y predicción de la posición de las celdas, tienen grandes diferencias en cuanto a objetivos y jerarquías semánticas de características dependientes, por lo que existe un límite superior de rendimiento para la optimización conjunta.
- Cuando los usuarios afinan el modelo en un escenario concreto, el afinamiento de determinados tipos de datos tabulares puede provocar una "doble caída" en el rendimiento del modelo, es decir, el rendimiento de las categorías tabulares afinadas aumenta, pero el rendimiento de otras categorías disminuye, y el rendimiento global puede disminuir en lugar de aumentar.

Soluciones y principios técnicos de PP-TableMagic
Con el fin de aprovechar al máximo el rendimiento del modelo de reconocimiento de tablas ligero, y para soportar el ajuste fino dirigido al usuario de cualquier tipo de datos de tabla, PP-TableMagic adopta la estructura que se muestra en la figura siguiente:

PP-TableMagic adopta una arquitectura de doble flujo para dividir las tablas en cableadas e inalámbricas. A continuación, la tarea de reconocimiento de la tabla de extremo a extremo se divide en dos subtareas: detección de celdas y reconocimiento de la estructura de la tabla, y finalmente se obtiene el resultado completo de la predicción de la tabla HTML mediante el algoritmo de fusión de resultados autooptimizado. Específicamente:
- El equipo de Flying Paddle investiga su propio modelo ligero de clasificación de mesas PP-LCNet_x1_0_table_cls para lograr una clasificación de alta precisión de mesas cableadas e inalámbricas.
- El equipo de I+D lanzó el primer modelo de detección de células de tabla de código abierto RT-DETR-L_table_cell_det, que incluye pesos de preentrenamiento de detección de células de tabla cableadas RT-DETR-L_wired_table_cell_det y pesos de preentrenamiento de detección de células de tabla inalámbricas RT-DETR-L_wireless_table_cell_det. para lograr un posicionamiento preciso de los distintos tipos de celdas de tabla.
- Flying Paddle introduce un nuevo modelo de reconocimiento de estructuras de tablas, SLANeXt, que proporciona un mejor análisis sintáctico de las estructuras de tablas que SLANet y SLANet_plus, lo que se traduce en estructuras HTML de tablas más precisas.
En el marco de PP-TableMagic, SLANeXt, un nuevo modelo de reconocimiento de estructuras de tablas desarrollado por FeiPaddle, es especialmente importante. El reconocimiento de la estructura de la tabla es el aspecto más crítico del reconocimiento de tablas, y la predicción de imágenes de tablas a expresiones HTML se basa en características de alto nivel de las imágenes. Por lo tanto, SLANeXt utiliza Vary-ViT-B, que es más capaz de representar características, como codificador visual y alimenta las características extraídas en SLAHead para lograr un reconocimiento de estructuras más preciso. Además de la mejora de la estructura del modelo, también se ha mejorado la estrategia de entrenamiento. Basándose en el conjunto de datos de volumen completo autoconstruido de Flying Paddle y en el conjunto de datos ajustados de alta calidad, las ponderaciones de reconocimiento de estructuras de la tabla con cable y la tabla inalámbrica se obtienen respectivamente mediante una nueva estrategia de preentrenamiento en tres fases.
Para evaluar la capacidad de reconocimiento de formas de SLANeXt, el equipo de I+D realizó una serie de pruebas basadas en varios tipos de conjuntos de datos. Los resultados de los experimentos son los siguientes:
Basado en un conjunto interno de revisión de reconocimiento de formas de alto nivel:

Basado en datos empresariales reales de los socios:

Los resultados experimentales demuestran que SLANeXt mejora notablemente el rendimiento de SLANet_plus.
Aplicaciones algorítmicas
Al utilizar PP-TableMagic, no sólo puede aprovechar sus excelentes capacidades de predicción de tablas HTML para trabajar directamente con tablas, sino que también puede aprovechar al máximo su estructura para permitir el ajuste personalizado del modelo.
A la hora de afinar otros modelos de reconocimiento de formas de extremo a extremo para casos malos, suele ser difícil crear grandes conjuntos de entrenamiento cuando sólo se pueden recopilar este tipo de datos, lo que provoca un fenómeno de "unos contra otros" en el que el rendimiento del modelo disminuye en lugar de aumentar.

Además, el ajuste fino del modelo de reconocimiento de tablas de extremo a extremo requiere la anotación simultánea de la estructura de la tabla y las posiciones de las celdas de los datos de entrenamiento, lo que requiere mucho tiempo y trabajo en la mayoría de los escenarios de aplicación.
Con la arquitectura de red multimodelo de PP-TableMagic, cuando es necesario mejorar el rendimiento de un determinado tipo de tabla, sólo hay que ajustar el modelo o modelos más críticos, minimizando así el impacto en el rendimiento del reconocimiento de otros tipos de tablas.

Por lo tanto, cuando PP-TableMagic se pone a punto en escenarios reales, no sólo el rendimiento del reconocimiento de cada tipo de tabla tiene poca influencia entre sí, sino que además la anotación de los datos sólo necesita etiquetarse con la categoría correspondiente, lo que ahorra mucha mano de obra.
Para los desarrolladores con grandes conocimientos de codificación, la arquitectura de PP-TableMagic puede ajustarse directamente a nivel de rama. Como se muestra en la siguiente figura, cuando un determinado tipo de datos de tabla se considera muy importante, se puede configurar una rama independiente para su procesamiento, lo que puede mejorar en gran medida la capacidad general de reconocimiento de tablas.

PP-TableMagic tiene un rendimiento excelente y permite una gran personalización y un alto grado de libertad de ajuste del modelo objetivo para lograr el mejor rendimiento de reconocimiento de mesas en una gran variedad de escenarios de aplicación, y es la primera solución de código abierto para el reconocimiento de mesas que puede lograr una gran personalización en todos los escenarios.
Primeros pasos
montaje
Instalar PaddlePaddle:
# CPU 版本
python -m pip install paddlepaddle==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
# GPU 版本,需显卡驱动程序版本 ≥450.80.02(Linux)或 ≥452.39(Windows)
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# GPU 版本,需显卡驱动程序版本 ≥545.23.06(Linux)或 ≥545.84(Windows)
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/
Instale el paquete PaddleX Wheel:
pip install https://paddle-model-ecology.bj.bcebos.com/paddlex/whl/paddlex-3.0.0rc0-py3-none-any.whl
Experiencia rápida
PP-TableMagic se puede llamar directamente.
PaddleX proporciona una API Python fácil de usar para experimentar predicciones de modelos con sólo unas pocas líneas de código.
Descargar imágenes de prueba:
https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/table_recognition_v2.jpg
PaddleX soporta llamar a PP-TableMagic desde la línea de comandos o mediante scripts Python (representados en PaddleX por la línea de producto table_recognition_v2).
Método de línea de comandos:
paddlex --pipeline table_recognition_v2
--use_doc_orientation_classify=False
--use_doc_unwarping=False
--input table_recognition.jpg
--save_path ./output
--device gpu:0
Método de script en Python:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="table_recognition_v2")
output = pipeline.predict(
input="table_recognition.jpg",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
)
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_xlsx("./output/")
res.save_to_html("./output/")
res.save_to_json("./output/")
Tras su uso, los resultados del reconocimiento se guardarán en la ruta especificada.
desarrollo secundario
Si está satisfecho con el efecto de PP-TableMagic, puede llevar a cabo directamente el razonamiento de alto rendimiento, el despliegue de servicios o el despliegue final en la línea de producción. Si el escenario de la mesa es particularmente vertical y todavía hay espacio para la optimización, también puede utilizar PaddleX para llevar a cabo un desarrollo secundario específico de uno o varios modelos en PP-TableMagic basándose en los datos de su propio escenario, aprovechando al máximo las ventajas del ajuste personalizado de PP-TableMagic. Basándose en la conveniente capacidad de desarrollo secundario de PaddleX, la verificación de datos, el entrenamiento del modelo y la inferencia de la evaluación pueden completarse mediante el uso de comandos unificados, sin necesidad de comprender los principios subyacentes del aprendizaje profundo, preparar los datos de la escena de acuerdo con los requisitos, y simplemente ejecutar los comandos para completar la iteración del modelo. Aquí mostramos el proceso de desarrollo secundario del modelo de detección de células de mesa inalámbricas RT-DETR-L_wireless_table_cell_det:
python main.py -c paddlex/configs/modules/table_cells_detection/RT-DETR-L_wireless_table_cell_det.yaml
-o Global.mode=train
-o Global.dataset_dir=./path_to_your_datasets
Todos los demás modelos admiten desarrollo secundario, consulte los detalles:
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-rc/docs/pipeline_usage/tutorials/ocr_pipelines/table_recognition_v2.md#4-%E4%BA%8C%E6%AC%A1%E5%BC%80%E5%8F%91
Despliegue orientado a servicios
PaddleX también proporciona una capacidad de despliegue de servicios para PP-TableMagic, encapsulando las capacidades de razonamiento del reconocimiento de tablas como servicios y permitiendo a los clientes acceder a estos servicios a través de peticiones web de resultados de razonamiento de tablas.
PaddleX proporciona dos tipos de despliegue servitizado: despliegue servitizado básico y despliegue servitizado de alta estabilidad. Basic Serviced Deployment es una solución de despliegue de servitización simple y fácil de usar con bajos costes de desarrollo que permite a los usuarios desplegar y depurar resultados rápidamente. El despliegue de servitización de alta estabilidad se basa en el servidor de inferencia NVIDIA Triton, que proporciona mayor estabilidad y permite un mayor rendimiento.
Para más información sobre PP-TableMagic, consulte la documentación oficial de la línea de producción de PaddleX:
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-rc/docs/pipeline_usage/tutorials/ocr_pipelines/table_recognition_v2.md
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...