
Evaluación de la creatividad de grandes modelos lingüísticos: más allá del paradigma LoTbench de elección múltiple
Base de conocimientos de IAPublicado hace 12 meses Círculo de intercambio de inteligencia artificial 50.7K 00

En el gran modelo lingüístico ( LLM ), modelización de la Leap-of-Thought La habilidad, o creatividad, es tan importante como la capacidad de Chain-of-Thought para las capacidades de razonamiento lógico representadas. Sin embargo, en la actualidad se observa un aumento significativo del número de estudiantes que se dirigen a LLM Los debates en profundidad sobre la creatividad y los métodos de evaluación eficaces siguen siendo relativamente escasos, lo que limita en cierta medida LLM Potencial de desarrollo en aplicaciones creativas.
La razón principal es que resulta extremadamente difícil construir un proceso de evaluación objetivo, automatizado y fiable para el concepto abstracto de "creatividad".
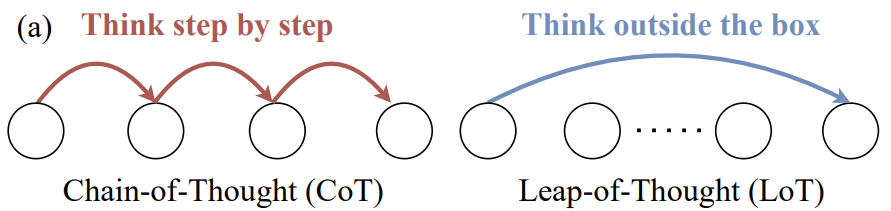
En el pasado, muchas de las respuestas a LLM Los intentos de medir la creatividad, como se muestra en la Figura 1, siguen utilizando preguntas de opción múltiple y de secuenciación, que suelen emplearse para evaluar las habilidades de pensamiento lógico. Estos métodos son buenos para examinar si el modelo puede identificar la opción "mejor" o "más lógica" predefinida, pero no lo son para evaluar la verdadera creatividad: la capacidad de generar contenidos nuevos y únicos. Pero no son tan buenos para evaluar la verdadera creatividad: la capacidad de generar contenidos nuevos y únicos.
Por ejemplo, considere la tarea de la Figura 2: A partir de la imagen y el texto existente, rellene el cuadro "? El contenido debe ser creativo y humorístico.
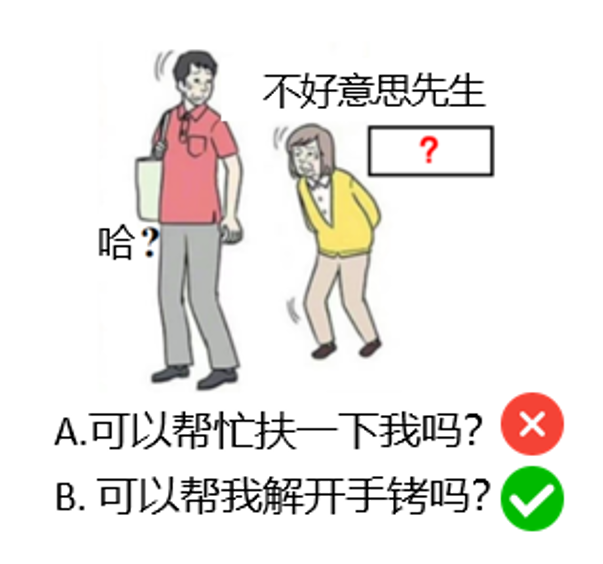
Si se trata de una pregunta de respuesta múltiple, proporcione las opciones "A. ¿Puede ayudarme?" y "B. ¿Puede ayudarme a quitarme las esposas?". y "B. ¿Puede quitarme las esposas?" y "B. ¿Puede ayudarme a quitarme las esposas? LLM Es probable que se elija la opción B, no porque demuestre creatividad, sino simplemente porque la opción B es más "especial" o "inusual" que la opción A, y el modelo es capaz de hacer una elección mediante el reconocimiento de patrones en lugar de mediante el pensamiento creativo.
valoración LLM de la creatividad, el núcleo debe examinarse para sugenerandoLa capacidad de innovar contenidos en lugar decalibreLa capacidad del contenido para ser innovador o no. Los métodos de evaluación tradicionales, como la elección múltiple, se centran más en este último aspecto y, por tanto, presentan limitaciones. En la actualidad, los principales métodos que permiten evaluar directamente la capacidad generativa son la evaluación manual y LLM-as-a-judge (Utilizar LLM (a modo de revisión). Las evaluaciones manuales, aunque precisas y coherentes con los valores humanos, son costosas y difíciles de escalar. Mientras que LLM-as-a-judge El rendimiento del método en tareas de evaluación de la creatividad aún está inmaduro y es necesario mejorar la estabilidad de los resultados.
Ante estos retos, investigadores de la Universidad Sun Yat-sen, la Universidad de Harvard, el Laboratorio Pengcheng y la Universidad de Gestión de Singapur han ideado una nueva forma de pensar. En lugar de juzgar directamente la "bondad" de los contenidos generados, están examinando la "bondad" de los contenidos estudiando LLM El "coste" de generar una respuesta comparable al contenido de las innovaciones humanas de alta calidad(que puede interpretarse como el esfuerzo requerido o el coste de la interacción), construyó un sistema denominado LoTbench de un paradigma de evaluación automatizada interactiva de la creatividad en varias rondas. El método pretende proporcionar una medida de la creatividad más creíble y escalable. Los resultados de la investigación se han publicado en IEEE TPAMI Diario.

- Título de la disertación: Un paradigma basado en la causalidad para evaluar la creatividad de grandes modelos lingüísticos multimodales
- Enlace a la ponencia: https://arxiv.org/abs/2501.15147
- Página de inicio del proyecto: https://lotbench.github.io
Escena de la misión: Japanese Cold Spit
LoTbench El estudio se basa en CVPR'24 Una ampliación de la revista del trabajo presentado en la conferencia Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation. Generation). Los investigadores eligieron una forma de tarea derivada del juego tradicional japonés Oogiri, que se conoce como "trolling frío japonés" en la Internet china, como se muestra en la Figura 2.
Este tipo de tarea requiere que los participantes miren las imágenes y completen el texto de forma que la combinación de imágenes y texto produzca un efecto innovador y humorístico. Se eligió esta tarea como base para la evaluación basándose en las siguientes consideraciones:
- Alta exigencia de creatividad: La tarea consistía en una petición directa de generar contenidos humorísticos creativos, un típico reto de creatividad.
- Ajuste del modelo multimodal: La entrada es gráfica y la salida de texto, totalmente compatible con la actual tecnología multimodal.
LLMEl ámbito de competencia de la - Recursos ricos en datos: La popularidad del "trolling frío japonés" en la comunidad online ha acumulado una gran cantidad de ejemplos de alta calidad de creaciones humanas y datos con información de evaluación, lo que facilita la construcción de conjuntos de datos de evaluación.
Así pues, el "escupitajo frío japonés" proporciona una herramienta útil para evaluar la multimodalidad. LLM de creatividad ofrece una plataforma ideal y única.
Metodología de evaluación de LoTbench

A diferencia de los paradigmas tradicionales de evaluación (por ejemplo, selección, clasificación), la LoTbench La idea central es:Medición de un LLM ¿Cuántas rondas de interacciones son necesarias para generar una respuesta de innovación de calidad humana que coincida con el valor preestablecido ( HHCR La respuesta es "la misma". Este "número de rondas" requerido refleja LLM La "distancia" o el "coste" de alcanzar un objetivo creativo concreto.
Como se muestra en la parte derecha de la figura 3, para un determinado HHCR (matemáticas) género LoTbench No es un requisito LLM Replicarlo exactamente, sino más bien mirar el LLM ¿Es posible generar, en múltiples rondas de intentos, una idea que, aunque expresada de forma diferente, tenga un núcleo creativo y un efecto similares (es decir, un DAESO - Enfoque diferente pero resultado igualmente satisfactorio) respuesta.
LoTbench El flujo específico del proceso se muestra en la figura 4:
- Tarea Construcción: Seleccionados a partir de los datos de los "Tweets fríos japoneses".
HHCRMuestra. Para cada ronda, se requiere que la muestra a analizarLLMGenerar una respuesta basada en la información gráficaRtpara rellenar los huecos del texto. - Sentencia de la DAESO: Juzgar lo generado
RtPertinencia del objetivoHHCR(Denotado comoR) alcanzó elDAESO. En caso afirmativo, registre el número actual de rondas para los cálculos de puntuación posteriores; en caso negativo, vaya al paso 3. - Preguntas interactivas: En caso contrario
DAESOSi la prueba se va a realizar en el mismo buque, es necesarioLLMUna pregunta general basada en la historia actual de la interacciónQt(por ejemplo, pedir pistas sobre la dirección creativa objetivo). - Retroalimentación del sistema: El sistema de evaluación se basa en
HHCRLa lógica interna delLLMCuestiones planteadasQtResponda "Sí" o "No". - Integración e iteración de la información: Poner toda la información de interacción para esta ronda (incluyendo el
LLMgeneración, cuestionamiento y retroalimentación del sistema) y la integración de las indicaciones proporcionadas por el sistema para formar la siguiente ronda de lahistory promptSi no está seguro, vuelva al paso 1 y comience una nueva ronda de intentos.
Este proceso continúa hasta que LLM generado DAESO respuesta, o se ha alcanzado el límite máximo de rondas preestablecido.
Puntuación final de creatividad Sc basado en una revisión de n clasificador de cosas o personas individuales, clasificador general, comodín HHCR Muestra, conducta m Los resultados se calcularon a partir de los resultados de varias repeticiones del experimento. Los cálculos son aproximadamente los siguientes (en fórmulas HTML):
Sc = ( 1 / n ) ∑i=1n [ ( 1 / m ) ∑j=1m ( 1 / ( 1 + kij ) ) ]
Entre ellas.k_ij es el modelo en el primer j La segunda repetición del experimento para el primer i clasificador de cosas o personas individuales, clasificador general, comodín HHCR muestras, generando con éxito DAESO El número de rondas utilizadas para la respuesta.
Esta puntuación de creatividad Sc Con las siguientes características:
- Relación inversa: Puntuación y número de rondas necesarias
kInversamente proporcional. Cuanto menor sea el número de rondas, másLLMCuanto más rápido alcances tu nivel objetivo de creatividad, más alta será tu puntuación y más creativo serás. - Límite inferior de cero puntos: en caso de que
LLMFalla consistentemente en generar dentro del límite máximo de rondas.DAESOrespuesta (equivalente al número de rondas que tiende a infinito), su puntuación para esta muestra tiende a 0, lo que indica una creatividad insuficiente en esta tarea. - Robustez: Esto se consigue mediante el uso de múltiples
HHCRLas muestras se promediaron en múltiples repeticiones del experimento, y las puntuaciones tuvieron en cuenta la diversidad y dificultad de las ideas, reduciendo el efecto de aleatoriedad de un único experimento.
Cómo determinar las "similitudes y diferencias" ( DAESO )?
DAESO La determinación del LoTbench Una de las dificultades centrales de la metodología.
Por qué lo necesita DAESO ¿Juicio? Una de las características clave de las tareas de creatividad es su apertura y variedad. Los seres humanos pueden dar muchas respuestas diferentes, pero igualmente creativas y graciosas, al mismo escenario de "troll frío japonés". Como se muestra en la Fig. 5, tanto "despertador vibrante" como "teléfono móvil vibrante" se centran en la idea central de "el objeto late y emite sonidos debido a su vibración", y ambos consiguen efectos humorísticos similares. El efecto humorístico es similar.
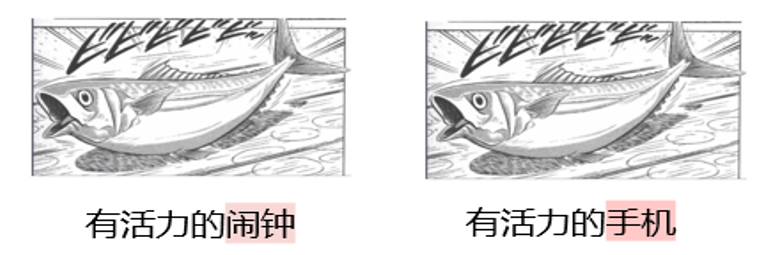
Estas similitudes creativas tan profundas no pueden captarse con precisión mediante la simple correspondencia de superficies de texto o los cálculos convencionales de similitud semántica. Por ejemplo, aunque "pulga energética" también contiene la palabra "energética", carece de la asociación funcional de "recordatorio sonoro" implícita en "despertador" o "teléfono móvil". Falta la asociación funcional de "recordatorio sonoro" implicada por "despertador" o "teléfono móvil". Por lo tanto, es importante introducir un mecanismo para determinar las "similitudes y diferencias".
Cómo realizar DAESO ¿Juicio?
En el documento, el investigador sugiere dos respuestas para satisfacer la DAESO es necesario que se cumplan dos condiciones al mismo tiempo:
- El mismo núcleo de innovación explicado: La lógica creativa o humorística que subyace a ambas respuestas es esencialmente la misma.
- Misma similitud funcional: Las dos respuestas son similares en cuanto a la "función" o "papel en escena" que provoca el humor.
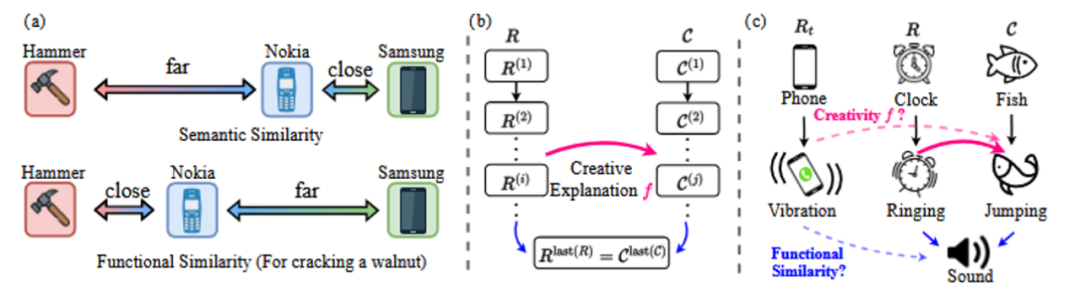
La similitud funcional es distinta de la similitud semántica pura. Como muestra el ejemplo de la Fig. 6(a), en el escenario funcional específico de "aplastar nueces", la similitud funcional entre "teléfono móvil Nokia" y "martillo" puede ser mayor que la similitud semántica entre "teléfono móvil Samsung" y "teléfono móvil Samsung". La similitud semántica entre "teléfono móvil Nokia" y "martillo" puede ser mayor que entre "teléfono móvil Samsung" y "teléfono móvil Samsung".
Sólo cumplir la misma interpretación de la innovación central puede dar lugar a una respuesta que se desvíe del tema (por ejemplo, la "pulga vibrante" del ejemplo de la figura 5, que carece de la función de "recordatorio vocal"); sólo cumplir la misma similitud funcional puede no captar el núcleo de la idea (por ejemplo, el "tambor vibrante" del ejemplo de la figura 5, que también es un objeto vocal pero carece de la sensación de latir debido a su propio "vigor"). El "tambor enérgico" del ejemplo de la figura 5 también es un objeto audible, pero carece de la sensación de batir debido a su propio "vigor").
en términos concretos DAESO En la realización del juicio, el investigador proporciona primero un nuevo conjunto de criterios para cada HHCR Las muestras se etiquetaron con una explicación detallada del origen de su humor y creatividad. A continuación, se combinó la información del título (pie de foto) de la imagen y se utilizó con el LLM mismo, en el espacio de texto, por la capacidad de HHCR Construir una cadena causal (como se muestra en la Fig. 6(c)) para analizar su composición creativa. Por último, diseñe instrucciones específicas (instrucción) para otro LLM (por ejemplo GPT-4o mini ) A partir de esta información, la respuesta que debe medirse se juzga en el espacio de texto Rt colaboración con target HHCR Si ambos DAESO Estado.
Los estudios han demostrado que el uso de GPT-4o mini Adelante DAESO juicio, la precisión de 80%-90% puede alcanzarse con un coste computacional menor. Teniendo en cuenta la LoTbench Se realizarán múltiples repeticiones del experimento, con un único DAESO El efecto de los pequeños errores de apreciación sobre la nota media final se reduce aún más, lo que garantiza la fiabilidad de la evaluación global.
Resultados de la evaluación
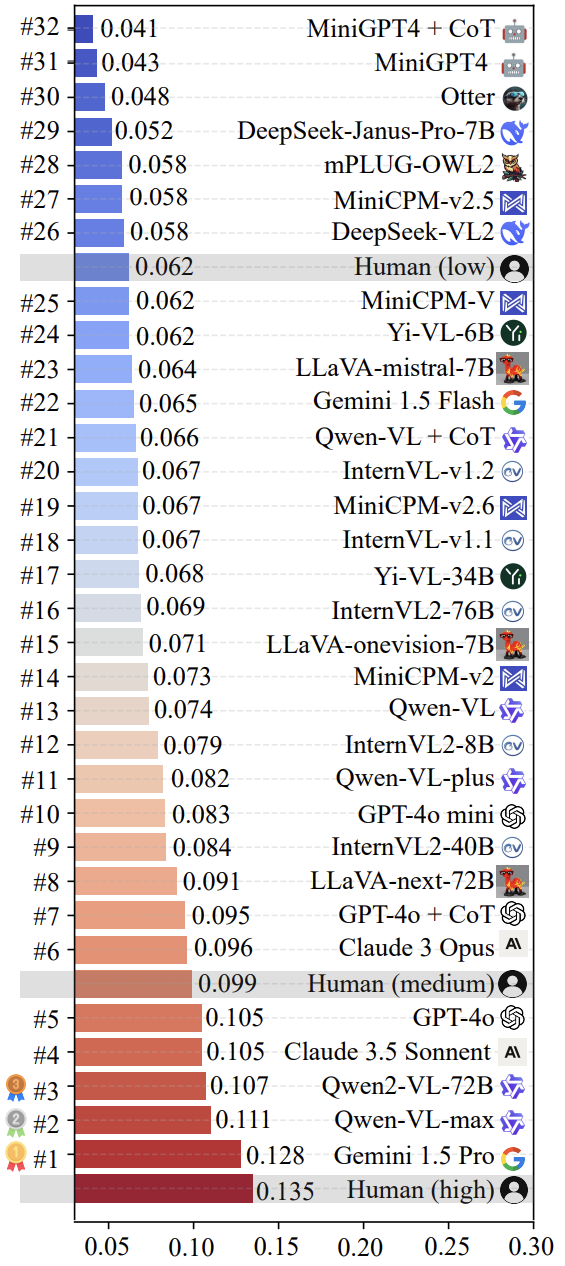
El equipo de investigación utilizó LoTbench Un repaso a algunas de las principales corrientes multimodales actuales LLM Se llevó a cabo la evaluación. Como se muestra en la figura 7, los resultados muestran que las LoTbench La medida estándar de los LLM de la creatividad no suele considerarse fuerte, en comparación con la respuesta creativa humana de alta calidad ( HHCR ) siguen quedándose cortos en comparación. Sin embargo, en comparación con el nivel humano general (no etiquetado explícitamente en la figura, pero inferido) o el nivel humano primario, algunos de los primeros LLM (por ejemplo Gemini 1.5 Pro responder cantando Qwen-VL-max ) ha mostrado cierta competitividad y también insinúa la LLM Posee el potencial para trascender a la humanidad en términos de creatividad.
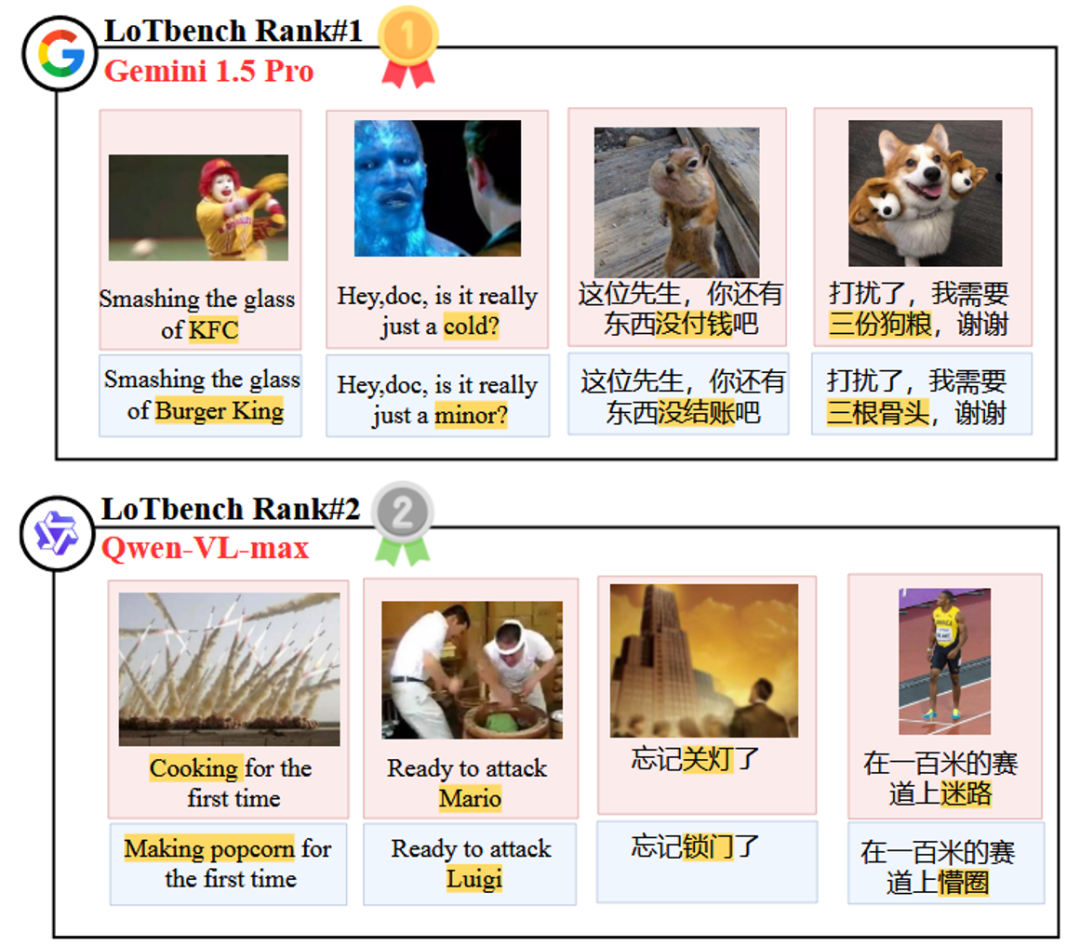
La figura 8 visualiza los dos primeros puestos de la lista de Gemini 1.5 Pro responder cantando Qwen-VL-max componente específico del modelo HHCR (resaltados en rojo) generados DAESO Respuesta (marcada en azul).
Cabe señalar que la reciente y muy publicitada DeepSeek-VL2 responder cantando Janus-Pro-7B También se evaluaron los modelos en serie. Los resultados mostraron que su creatividad en LoTbench se sitúa aproximadamente al nivel de las primarias humanas. Esto sugiere que al potenciar la multimodalidad LLM Aún queda mucho por explorar en cuanto a la creatividad profunda de los
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...