Ovis-U1: un modelo multimodal de IA unificada lanzado por Ali
Últimos recursos sobre IAPublicado hace 9 meses Círculo de intercambio de inteligencia artificial 42.5K 00

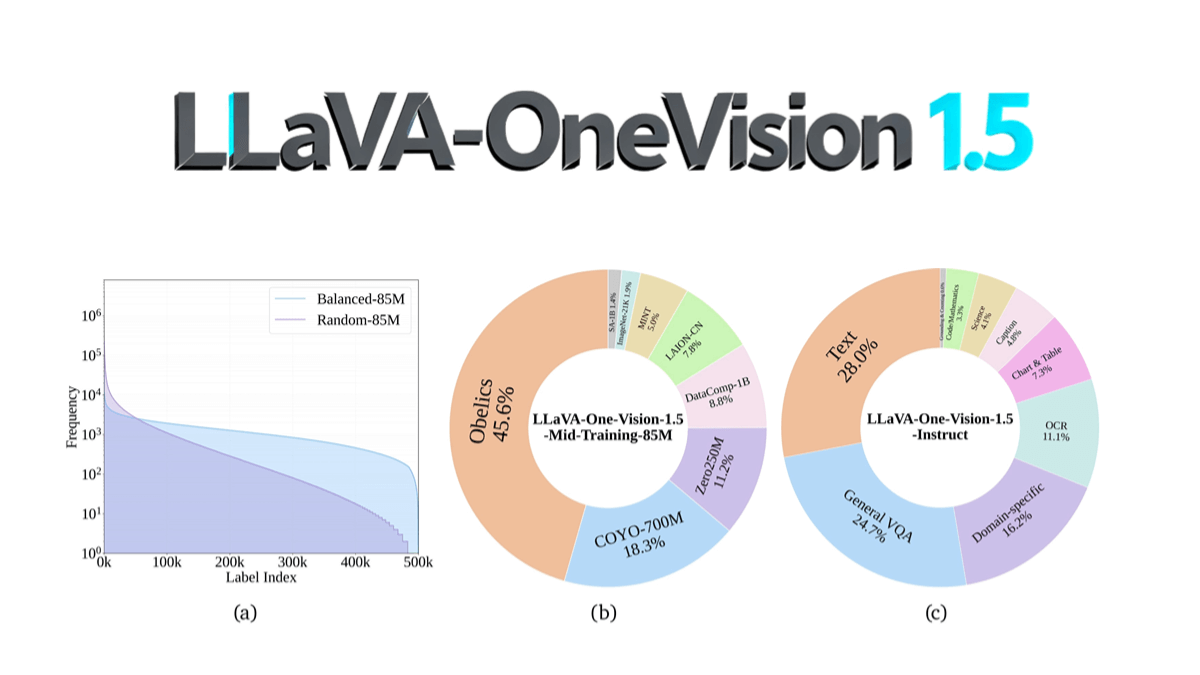
¿Qué es Ovis-U1?
Ovis-U1 es un modelo unificado multimodal presentado por el equipo Ovis de Alibaba Group con una escala de parámetros de 3.000 millones. El modelo está equipado con tres capacidades básicas: comprensión multimodal, generación de texto a imagen y edición de imágenes. Con un diseño arquitectónico avanzado y métodos de formación colaborativos y unificados, apoya la realización de síntesis de imágenes de alta fidelidad y una interacción visual de texto eficiente. Ovis-U1 ha obtenido excelentes resultados en pruebas académicas de referencia en muchos campos, como la comprensión, la generación y la edición multimodales, demostrando una excelente capacidad de generalización y un rendimiento sobresaliente.

Características principales de Ovis-U1
- comprensión multimodalEl sistema de análisis de imágenes es capaz de analizar con precisión escenas visuales complejas y contenidos textuales, completar preguntas y respuestas visuales (VQA) y generar textos descriptivos que se ajusten a la imagen.
- Generación de texto a imagenEl generador de imágenes puede generar imágenes de alta calidad a partir de descripciones de texto, cubriendo una amplia gama de estilos y escenarios complejos para satisfacer diferentes necesidades creativas.
- edición de imágenesAñada, ajuste, sustituya, elimine elementos y convierta estilos basados en comandos textuales para ayudar a crear y optimizar imágenes.
Dirección del sitio web oficial de Ovis-U1
- Repositorio GitHub:: https://github.com/AIDC-AI/Ovis-U1
- Biblioteca de modelos HuggingFace:: https://huggingface.co/AIDC-AI/Ovis-U1-3B
- Documentos técnicos:: https://github.com/AIDC-AI/Ovis-U1/blob/main/docs/Ovis_U1_Report.pdf
- Demostración de la experiencia en línea:: https://huggingface.co/spaces/AIDC-AI/Ovis-U1-3B
Cómo utilizar Ovis-U1
- Experiencia en línea: Visite la página de demostración de Hugging Face, introduzca comandos de texto o cargue una imagen para ver los resultados generados por el modelo sin ninguna instalación ni configuración.
- Uso de la biblioteca de modelos Cara abrazada::
- Instala la biblioteca Transformers para Cara de abrazo.
- Cargue el modelo Ovis-U1 de la biblioteca de modelos Hugging Face.
- Razonamiento con modelos, como generación de texto a imagen, edición de imágenes y otras operaciones.
from transformers import AutoModelForVision2Seq, AutoProcessor
# 加载模型和处理器
model = AutoModelForVision2Seq.from_pretrained("AIDC-AI/Ovis-U1-3B")
processor = AutoProcessor.from_pretrained("AIDC-AI/Ovis-U1-3B")
# 准备输入数据(文本或图像)
inputs = processor(text="描述一个美丽的日出场景", return_tensors="pt")
# 进行推理
outputs = model.generate(**inputs)
# 处理输出结果
result = processor.decode(outputs[0], skip_special_tokens=True)
print(result)- despliegue localDescarga el código del modelo y los recursos relacionados desde el repositorio de GitHub y sigue la documentación para la instalación y configuración.
Ventajas principales de Ovis-U1
- Potentes funciones multimodales: Ovis-U1 está equipada con potentes funciones como la comprensión multimodal, la generación de texto a imagen y la edición de imágenes para satisfacer las necesidades de una amplia gama de escenarios complejos.
- Arquitectura tecnológica avanzada: Interacción visual textual eficiente basada en diseños arquitectónicos avanzados como descodificadores visuales, refinadores bidireccionales de tokens, codificadores visuales, adaptadores y modelos de macrolenguaje multimodal.
- Armonización de los métodos de formaciónUn enfoque de entrenamiento unificado con entrenamiento multitarea y optimización por etapas para mejorar la generalización de los modelos en tareas multimodales.
- Amplio soporte de datosDatos que abarcan una amplia gama de tareas, como la comprensión multimodal, la generación de texto a imagen y la generación de imagen+texto a imagen, que proporcionan una base sólida para el entrenamiento de modelos.
- Optimización del alto rendimiento: Control preciso de la edición de imágenes basado en el ajuste de los coeficientes de guiado, evaluado en múltiples pruebas de referencia para garantizar el alto rendimiento y la estabilidad del modelo.
- Uso flexibleAdmite diversos métodos de uso, como la experiencia en línea, la integración en la biblioteca del modelo Hugging Face y la implantación local para satisfacer las distintas necesidades de los usuarios.
Para quién es Ovis-U1
- creador de contenidos: Incluye artistas, diseñadores y editores de vídeo para materializar rápidamente ideas creativas y mejorar la eficacia creativa.
- Personal de publicidad y marketingLos diseñadores de anuncios y los responsables de marketing en redes sociales pueden generar imágenes publicitarias atractivas y carteles promocionales basados en las características del producto y las descripciones del público objetivo para mejorar la comunicación de la marca.
- desarrollador de juegos: Los diseñadores de juegos generan imágenes de escenas de juego, personajes y atrezo basándose en el trasfondo del juego y las descripciones de los personajes, proporcionando inspiración creativa y materiales preliminares para el diseño del juego.
- Arquitectos e interioristas: Los arquitectos y diseñadores de interiores generan dibujos conceptuales arquitectónicos e imágenes de escenas interiores y disposiciones de mobiliario basadas en estilos arquitectónicos y descripciones del entorno, lo que ayuda a los clientes a comprender rápidamente la intención del diseño y contribuye a la presentación eficaz de las propuestas de diseño.
- investigador (científico)Los investigadores generan imágenes visuales de fenómenos y datos científicos complejos, así como imágenes de escenas y equipos experimentales, para ayudar a comprender y presentar mejor los resultados de la investigación.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...