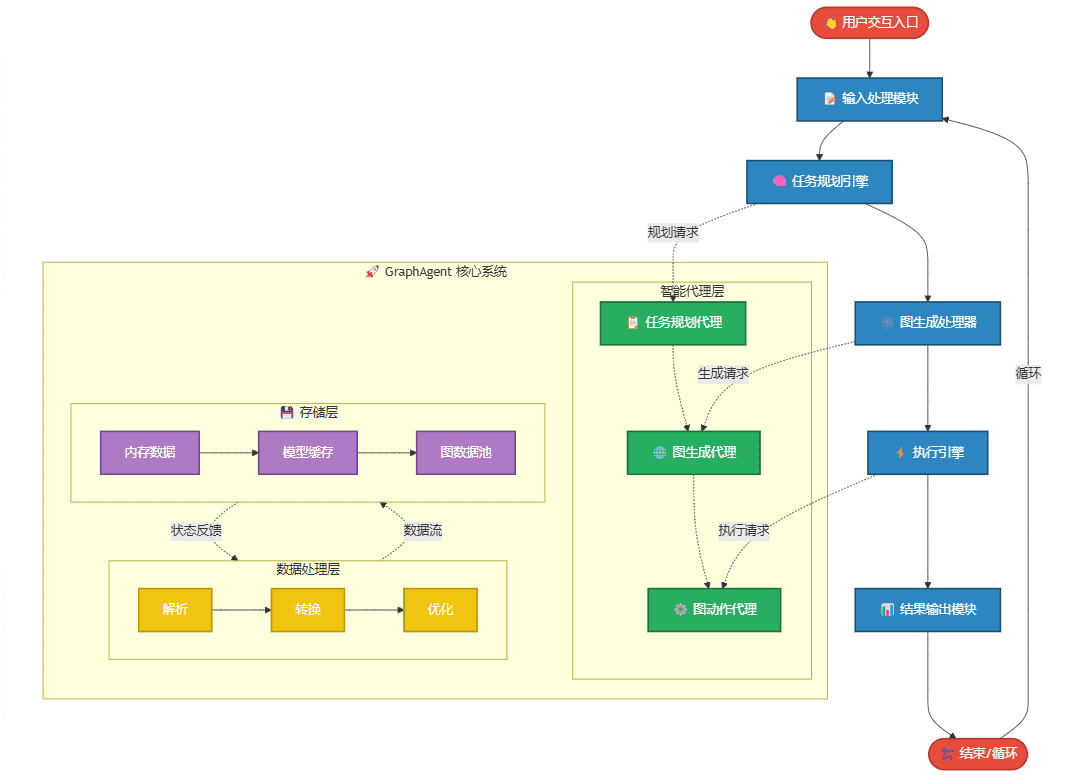
Orpheus-TTS: herramienta de conversión de texto a voz para generar habla china natural
Últimos recursos sobre IAPublicado hace 12 meses Círculo de intercambio de inteligencia artificial 90.5K 00

Introducción general
Orpheus-TTS es un sistema de texto a voz (TTS) de código abierto desarrollado sobre la arquitectura Llama-3b, con el objetivo de generar audio cercano al habla humana natural. Está lanzado por el equipo Canopy AI y es compatible con varios idiomas, como inglés, español, francés, alemán, italiano, portugués y chino. El sistema genera habla con entonación, emoción y ritmo a partir de la entrada de texto, y admite expresiones no verbales como risas y suspiros, lo que lo hace adecuado para conversaciones en tiempo real, producción de audiolibros y desarrollo de asistentes inteligentes.Orpheus-TTS ofrece modelos preentrenados y afinados, lo que permite a los desarrolladores personalizar el habla o el lenguaje según sus necesidades.

Lista de funciones
- Generación de habla casi humana: convertir texto en audio con entonación, emoción y ritmo naturales supera a los modelos parcialmente cerrados.
- Clonación del habla con muestra cero: imita el timbre del habla de destino sin entrenamiento adicional.
- Control emocional y de la entonación: mediante el etiquetado (p. ej.
<laugh>y<sigh>) Ajuste de la expresión de la voz para aumentar el realismo. - Salida de streaming de baja latencia: latencia de generación de voz en tiempo real de unos 200 ms, optimizada hasta 100 ms.
- Soporte multilingüe: inglés, español, francés, alemán, italiano, portugués, chino y otros idiomas.
- Ajuste del modelo: se proporcionan secuencias de comandos de procesamiento de datos y conjuntos de datos de ejemplo para ayudar a los desarrolladores a personalizar los estilos o idiomas de habla.
- Ejecución local y en la nube: compatible con LM Studio, llama.cpp o vLLM Ejecución local o en la nube.
- Marca de agua de audio: Proteja los derechos de autor mediante la marca de agua de audio generado con la tecnología Silent Cipher.
Utilizar la ayuda
Proceso de instalación
Orpheus-TTS requiere un entorno Python y soporte básico de hardware (se recomienda GPU). A continuación se detallan los pasos de instalación:
- Clonación del código base
Descarga el proyecto Orpheus-TTS usando Git:git clone https://github.com/canopyai/Orpheus-TTS.git cd Orpheus-TTS - Instalación de dependencias
Instalación de paquetes básicosorpheus-speechSe basa en vLLM para un razonamiento rápido:pip install orpheus-speechNota: La versión de 18 de marzo de 2025 de vLLM puede tener errores y se recomienda instalar la versión estable:
pip install vllm==0.7.3Otras dependencias son
transformersydatasetsresponder cantandotorchLa instalación puede realizarse previa solicitud:pip install transformers datasets torch - Compruebe los requisitos de hardware
- Versión de Python: 3.8-3.11 (3.12 no compatible).
- GPU: se recomienda el controlador NVIDIA CUDA, con más de 12 GB de memoria de vídeo para garantizar un funcionamiento fluido.
- CPU: Compatible con
orpheus-cpppero con menor rendimiento en las pruebas más ligeras. - Red: La primera ejecución requiere la descarga del modelo, se recomienda una conexión estable a Internet.
- Descargar modelos
Orpheus-TTS ofrece los siguientes modelos alojados en Hugging Face:- Ajuste del modelo (
canopylabs/orpheus-tts-0.1-finetune-prod): Adecuado para tareas cotidianas de generación de voz. - Modelos preentrenados (
canopylabs/orpheus-tts-0.1-pretrained): Basado en 100.000 horas de formación de datos del habla inglesa, adecuado para tareas avanzadas como la clonación del habla. - Modelización multilingüe (
canopylabs/orpheus-multilingual-research-release): Contiene 7 conjuntos de modelos preentrenados y afinados para apoyar los estudios multilingües.
Método de descarga:
huggingface-cli download canopylabs/orpheus-tts-0.1-finetune-prod - Ajuste del modelo (
- instalación de prueba
Ejecute el siguiente script Python para verificar que la instalación se ha realizado correctamente:from orpheus_tts import OrpheusModel model = OrpheusModel(model_name="canopylabs/orpheus-tts-0.1-finetune-prod") prompt = "tara: 你好,这是一个测试!" audio = model.generate_speech(prompt) with wave.open("test_output.wav", "wb") as file: file.setnchannels(1) file.setsampwidth(2) file.setframerate(24000) file.writeframes(audio)Tras ejecutarse correctamente, se generará un archivo WAV con la voz del texto introducido.
Funciones principales
1. Generación de habla casi humana
La función principal de Orpheus-TTS es convertir texto en audio que se aproxime al habla humana natural. El sistema admite una amplia gama de caracteres del habla, en el modelo de lengua inglesa tara el sentido más natural del habla, otros personajes incluyen leahyjessyleoydanymiayzac responder cantando zoe. Las funciones del modelo multilingüe deben remitirse a la documentación oficial. Procedimiento:
- Prepare indicaciones de texto en el formato
{角色名}: {文本}Por ejemplotara: 你好,今天天气很好!. - Llama a la función generar:
audio = model.generate_speech(prompt="tara: 你好,今天天气很好!") - La salida es audio en formato WAV con una frecuencia de muestreo de 24000 Hz en mono.
2. Control de las emociones y del tono
Los usuarios pueden controlar la expresión emocional de la voz mediante etiquetas para mejorar el realismo de la voz. Las etiquetas compatibles son:
<laugh>Risas.<sigh>Suspiro.<cough>Tos.<sniffle>Sniffles.<groan>:gemido.<yawn>Bostezo.<gasp>Sorpresa.
Ejemplo:
prompt = "tara: 这个消息太震撼了!<gasp> 你听说了吗?"
audio = model.generate_speech(prompt)
El audio generado incluirá efectos sorpresa en los lugares apropiados. Consulte la documentación de Cara abrazada para ver la compatibilidad con etiquetas de modelo en varios idiomas.
3. Clonación de discursos con muestra cero
Orpheus-TTS admite la clonación del habla con muestra cero, que puede imitar directamente el habla de destino sin entrenamiento previo. Pasos de la operación:
- Prepare un archivo WAV del discurso objetivo con una duración recomendada de 10-30 segundos y una frecuencia de muestreo de 24000 Hz.
- Utilice el siguiente script:
audio_ref = "path/to/reference.wav" prompt = "tara: 这段话会模仿你的声音!" audio = model.generate_with_voice_clone(prompt, audio_ref) - El audio de salida se acercará al timbre del habla de referencia. El modelo preentrenado obtiene mejores resultados en la tarea de clonación.
4. Salida de streaming de baja latencia
Orpheus-TTS proporciona generación de voz en streaming para escenarios de diálogo en tiempo real, con una latencia de unos 200 ms, optimizada hasta 100 ms. ejemplo operativo:
from flask import Flask, Response
from orpheus_tts import OrpheusModel
app = Flask(__name__)
[1]
model = OrpheusModel(model_name="canopylabs/orpheus-tts-0.1-finetune-prod")
@app.route("/stream")
def stream_audio():
def generate():
prompt = "tara: 这是实时语音测试!"
for chunk in model.stream_generate(prompt):
yield chunk
return Response(generate(), mimetype="audio/wav")
Después de ejecutar el servicio Flask, acceda a la página http://localhost:5000/stream Se oye la voz en tiempo real. Para optimizar la latencia hay que activar la caché KV y el streaming de entrada.
5. Ajuste del modelo
Los desarrolladores pueden ajustar el modelo para que admita nuevos idiomas o estilos de habla. Los pasos son los siguientes:
- Prepare el conjunto de datos: consulte el conjunto de datos de ejemplo Cara abrazada para conocer el formato (
canopylabs/zac-sample-dataset). Se recomienda incluir entre 50 y 300 muestras/caracteres, con 300 muestras para obtener los mejores resultados. - Preprocesamiento de datos: uso de cuadernos Colab proporcionados oficialmente (
1wg_CPCA-MzsWtsujwy-1Ovhv-tn8Q1nDLos datos se procesan en aproximadamente 1 minuto/mil entradas. - Formación en configuración: modificaciones
finetune/config.yamlestablece la ruta y los parámetros del conjunto de datos. - Entrenamiento de carrera:
huggingface-cli login wandb login accelerate launch train.py - El modelo ajustado puede utilizarse para tareas específicas, como la optimización del habla china.
6. Marca de agua de audio
Orpheus-TTS admite marcas de agua de audio con tecnología Silent Cipher para la protección de los derechos de autor. Método de funcionamiento:
- Consulte el script de aplicación oficial (
additional_inference_options/watermark_audio). - Ejemplo:
from orpheus_tts import add_watermark audio = model.generate_speech(prompt) watermarked_audio = add_watermark(audio, watermark_id="user123")
7. Sin razonamiento GPU
Los usuarios sin GPU pueden utilizar el orpheus-cpp Ejecución en una CPU, paso a paso:
- montaje llama.cpp Medio ambiente.
- Consulte la documentación oficial (
additional_inference_options/no_gpu/README.md). - Menor rendimiento que las GPU para tareas ligeras.
advertencia
- Selección de modelosLos modelos afinados son adecuados para tareas cotidianas y los modelos preentrenados son adecuados para tareas avanzadas como la clonación del habla.
- limitación de hardware: Menos de 12 GB de memoria de vídeo puede resultar insuficiente, se recomienda comprobar la configuración del hardware.
- Soporte multilingüe: Los idiomas no ingleses deben remitirse a la documentación del modelo multilingüe, algunos idiomas pueden necesitar un ajuste fino.
- ajustar los componentes durante las pruebasSi vLLM informa de un error (p. ej.
vllm._C), pruebe con otra versión o compruebe la compatibilidad con CUDA.
Funciones complementarias: extensión comunitaria
La naturaleza de código abierto de Orpheus-TTS ha atraído contribuciones de la comunidad, y se recomienda oficialmente la siguiente implementación (no totalmente verificada):
- LM Studio Cliente localEjecute Orpheus-TTS a través de la API de LM Studio (
isaiahbjork/orpheus-tts-local). - FastAPI compatible con Open AIProporciona una interfaz API de tipo Open AI (
Lex-au/Orpheus-FastAPI). - Gradio WebUIWSL e interfaz web compatible con CUDA (
Saganaki22/OrpheusTTS-WebUI). - Espacio Cara AbrazadaUna experiencia en línea creada por el usuario de la comunidad MohamedRashad (
MohamedRashad/Orpheus-TTS).
escenario de aplicación
- Robot inteligente de atención al cliente
Orpheus-TTS genera habla natural para los sistemas de atención al cliente, lo que permite el diálogo en tiempo real y la expresión emocional para mejorar la experiencia del usuario.
Por ejemplo, las plataformas de comercio electrónico pueden integrar Orpheus-TTS para añadir un tono amable al responder a las consultas de los clientes. - Producción de audiolibros y podcasts
Los editores pueden convertir novelas o artículos en audiolibros, lo que permite etiquetar múltiples personajes y emociones y reducir los costes de locución.
Los creadores de podcasts pueden generar líneas de apertura dinámicas para aumentar el atractivo de su programa. - Herramientas de aprendizaje de idiomas
Esta aplicación educativa genera sonidos estándar para ayudar a los alumnos a practicar la comprensión y la expresión oral.
Por ejemplo, los alumnos de chino pueden utilizar el modelo chino para practicar su pronunciación en mandarín. - Voz en off de personajes de juegos
Los desarrolladores de juegos pueden generar diálogos dinámicos para los PNJ, con soporte multilingüe y expresión emocional para mejorar la inmersión.
Por ejemplo, los juegos de rol pueden generar tonos únicos para distintos personajes. - Ayudas a la accesibilidad
Orpheus-TTS proporciona ayuda a la lectura en tiempo real para usuarios con discapacidad visual mediante la conversión de texto a voz.
Por ejemplo, integrándose en un lector de libros electrónicos para leer en voz alta artículos largos.
CONTROL DE CALIDAD
- ¿Qué idiomas admite Orpheus-TTS?
Admite inglés, español, francés, alemán, italiano, portugués y chino. El modelo multilingüe cubre más idiomas, consulte la documentación de Hugging Face. - ¿Cómo optimizar la latencia de voz en tiempo real?
Active el almacenamiento en caché de KV y la transmisión de entrada para reducir la latencia de 200 ms a 100 ms. Garantice un rendimiento suficiente de la GPU con al menos 12 GB de memoria de vídeo. - ¿Qué preparación se requiere para la clonación de voz de muestra cero?
Proporciona 10-30 segundos de audio de referencia en formato WAV con una frecuencia de muestreo de 24000 Hz para un mejor preentrenamiento del modelo. - ¿Puede la CPU ejecutar Orpheus-TTS?
Sí, utiliceorpheus-cppNo son tan potentes, pero tienen un rendimiento inferior al de las GPU, lo que las hace adecuadas para pruebas o tareas ligeras. - ¿Cómo añado una marca de agua a mi audio?
Gracias a la tecnología Silent Cipher, la llamadaadd_watermarknecesita consultar el script oficial para implementarla. - ¿Cuántos datos se necesitan para el ajuste?
50 muestras para los resultados iniciales, 300 muestras/carácter para la mejor calidad. Los datos deben estar en formato Hugging Face.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...