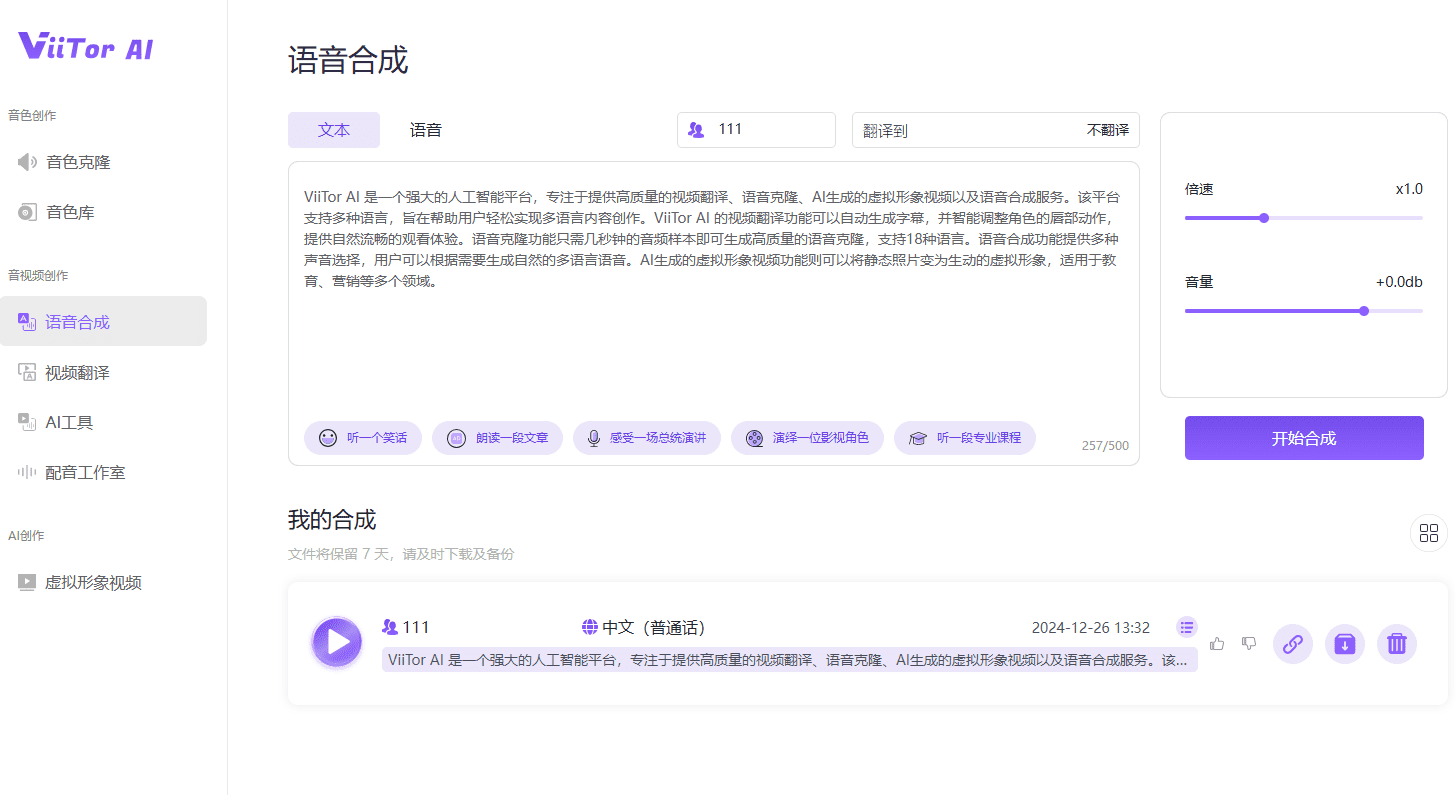
OpenVoice (MyShell): Clonación instantánea de voz en varios idiomas con menos muestras
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 150.3K 00

Introducción general
OpenVoice es un método versátil de clonación instantánea del habla que permite copiar la voz de un locutor de referencia y generar habla multilingüe utilizando sólo breves clips de audio del locutor. Además de replicar el timbre, OpenVoice permite controlar con precisión el estilo de la voz, incluida la emoción, el acento, el ritmo, las pausas y la entonación.
Proyectos de conversión de texto a voz relacionados con OpenVoice: https://github.com/myshell-ai/MeloTTS
El proyecto puede entrenar su propio habla utilizando el conjunto de datos, pero carece de interfaz de entrenamiento. No es lo mismo que Instantaneous Speech Cloning y se centra más en la conversión de texto a voz utilizando un modelo entrenado de forma estable.
Lista de funciones
Clonación precisa de tonos: OpenVoice puede replicar con precisión tonos de referencia y generar habla en varios idiomas y acentos.
Control flexible del estilo de voz: OpenVoice permite un control preciso del estilo de voz, incluida la emoción, el acento, el ritmo, las pausas y la entonación.
Clonación multilingüe sin disparos: no es necesario que el habla generada esté en el mismo idioma que el habla de referencia ni que se presente en un conjunto de datos de entrenamiento multilingüe a gran escala.
Destacado:
1. Clonación precisa del tono. OpenVoice puede clonar con precisión tonos de referencia y generar habla en varios idiomas y acentos.
2. Control de tono flexible. OpenVoice permite controlar con precisión el estilo de voz (por ejemplo, la emoción y el acento), así como otros parámetros estilísticos como el ritmo, las pausas y la entonación.
3. clonación multilingüe de muestras cero. Ni la lengua en la que se genera el habla ni la lengua en la que se hace referencia al habla tienen por qué estar presentes en un conjunto de datos de entrenamiento multilingüe de hablantes a gran escala.
Utilizar la ayuda
Consulte las instrucciones de uso para obtener información detallada.
Consulte las preguntas más frecuentes en la sección de control de calidad. Actualizaremos periódicamente la lista de preguntas y respuestas.
Aplicar en MyShell:Uso directo de los servicios de reproducción y síntesis de voz instantánea (TTS).
Ejemplo minimalista:Experimente rápidamente OpenVoice sin necesidad de alta calidad.
Instalación de Linux:Sólo para investigadores y desarrolladores.
Prueba rápida en google colab
%cd /content!git clone -b dev https://github.com/camenduru/OpenVoice%cd /content/OpenVoice!apt -y install -qq aria2!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/OpenVoice/resolve/main/checkpoints_1226.zip -d /content -o checkpoints_1226.zip!unzip /content/checkpoints_1226.zip!pip install -q gradio==3.50.2 langid faster-whisper whisper-timestamped unidecode eng-to-ipa pypinyin cn2an!python openvoice_app.py --share
Aplicar en MyShell
Para la mayoría de los usuarios, la forma más cómoda de experimentar los servicios gratuitos TTS y Replicación de voz en directo es directamente en MyShell.
Servicios TTS
Pulse aquíy sigue los pasos que se indican a continuación:

clonación de voz
Pulse aquíy sigue los pasos que se indican a continuación:

Ejemplo minimalista
Quienes deseen probar OpenVoice rápidamente y no necesiten mucha calidad o estabilidad, pueden hacer clic en cualquiera de los enlaces siguientes:
Lepton AI:https://www.lepton.ai/playground/openvoice
MySHell:https://app.myshell.ai/bot/z6Bvua/1702636181
HuggingFace:https://huggingface.co/spaces/myshell-ai/OpenVoice
Instalación de Linux
Esta sección es principalmente para desarrolladores e investigadores expertos en Linux, Python y PyTorch. Clona este repositorio y haz lo siguiente:
conda create -n openvoice python=3.9
conda activa openvoice
git clone git@github.com:myshell-ai/OpenVoice.git
cd OpenVoice
pip install -e .
De [aquí estánDescargue el punto de control y descomprímalo en la carpeta puntos de control archivo (papel)
1. Control flexible del estilo de voz:Ver [demo_parte1.ipynbAprenda cómo OpenVoice controla el estilo del habla clonada.
2. Clonación lingüística del habla:Consulte [demo_parte2.ipynb]Conozca las demostraciones de idiomas visibles o no visibles en el conjunto de formación MSML.
3. Demostración de Gradio:Aquí proporcionamos una simulación local mínima de gradio. Si tiene problemas con la demostración de gradio, le recomendamos encarecidamente que consulte la página demo_part1.ipynbydemo_part2.ipynb y [Preguntas frecuentes] Utilice el botón python -m openvoice_app --share Inicia la demo local de gradio.
3. Guía avanzada del usuario:El modelo de voz de base puede sustituirse por cualquier modelo (cualquier idioma, cualquier estilo) que prefiera el usuario. Como se muestra en la demostración, utilizando el se_extractor.get_se Métodos de extracción de incrustaciones tonales para nuevos locutores base.
4. Una propuesta para generar habla natural:Existen muchos métodos TTS de uno o varios locutores para generar un habla natural. Simplemente sustituyendo el modelo de altavoz base por el que prefiera, podrá llevar la naturalidad del habla al nivel que desee.
Tutorial de implantación local de OpenVoiceV2, proceso de implantación de Apple MacOs
Recientemente el proyecto OpenVoice ha actualizado su versión V2, el nuevo modelo es más amigable a la inferencia china, y el timbre ha sido mejorado en cierta medida, en esta ocasión compartimos como desplegar localmente la versión V2 de OpenVoice en el sistema MacOs de Apple.
Primero descarga el zip de OpenVoiceV2:
OpenVoiceV2-for-mac代码和模型 https://pan.quark.cn/s/33dc06b46699
Esta versión se ha optimizado para MacOs y se ha modificado el volumen de la voz china.
Después de descomprimir, copie primero la carpeta hub desde HF_HOME en el directorio del proyecto al siguiente directorio en su sistema actual:
/Users/当前用户名/.cache/huggingface
Esta es la ruta de guardado por defecto del modelo huggingface en el sistema Mac, si no lo copia, tendrá que descargar más de diez G de modelo de pre-entrenamiento desde cero, lo cual es muy problemático.
A continuación, vuelva al directorio raíz del proyecto e introduzca el comando:
conda create -n openvoice python=3.10
Crea un entorno virtual con la versión 3.10 de Python, ten en cuenta que la versión sólo puede ser 3.10.
A continuación, active el entorno virtual:
conda activate openvoice
El sistema vuelve:
(base) ➜ OpenVoiceV2 git:(main) ✗ conda activate openvoice
(openvoice) ➜ OpenVoiceV2 git:(main) ✗
Indica que la activación se ha realizado correctamente.
La instalación se realiza mediante brew, ya que la capa inferior requiere mecab:
brew install mecab
Comience a instalar las dependencias:
pip install -r requirements.txt
Dado que OpenVoice sólo es responsable de la extracción de fonemas, la conversión del habla también requiere soporte tts, y aquí la dependencia subyacente es del módulo melo-tts.
Vaya al directorio Melo:
(openvoice) ➜ OpenVoiceV2 git:(main) ✗ cd MeloTTS
(openvoice) ➜ MeloTTS git:(main) ✗
Instale la dependencia MeloTTS:
pip install -e .
Si lo consigue, deberá descargar el archivo del diccionario por separado:
python -m unidic download
A continuación, vuelva al directorio raíz e inicie el proyecto:
python app.py
El sistema vuelve:
(openvoice) ➜ OpenVoiceV2 git:(main) ✗ python app.py
Running on local URL: http://0.0.0.0:7860
IMPORTANT: You are using gradio version 3.48.0, however version 4.29.0 is available, please upgrade.
--------
To create a public link, set `share=True` in `launch()`.
:多语言少样本即时语音克隆-1")
Esto completa el despliegue de OpenVoice en MacOs.
observaciones finales
Una de las características más destacadas de OpenVoice es su capacidad para clonar voces de un idioma a otro. Puede clonar voces en idiomas que no están incluidos en el conjunto de datos de entrenamiento, sin necesidad de proporcionar grandes cantidades de datos de entrenamiento de hablantes para esos idiomas. Sin embargo, el hecho es que el aprendizaje sin disparos suele ser menos preciso en categorías desconocidas, especialmente en categorías complejas, en comparación con el aprendizaje supervisado tradicional con muchos datos etiquetados. Depender de información auxiliar puede introducir ruido e imprecisiones, por lo que OpenVoice no funciona bien para algunos tonos muy específicos, y debe ajustarse a la modalidad subyacente para resolver esos problemas.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...