
Agentes en tiempo real de OpenAI: una aplicación multiinteligente de interacción cuerpo-voz (ejemplo de OpenAI)
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 51.3K 00

Introducción general
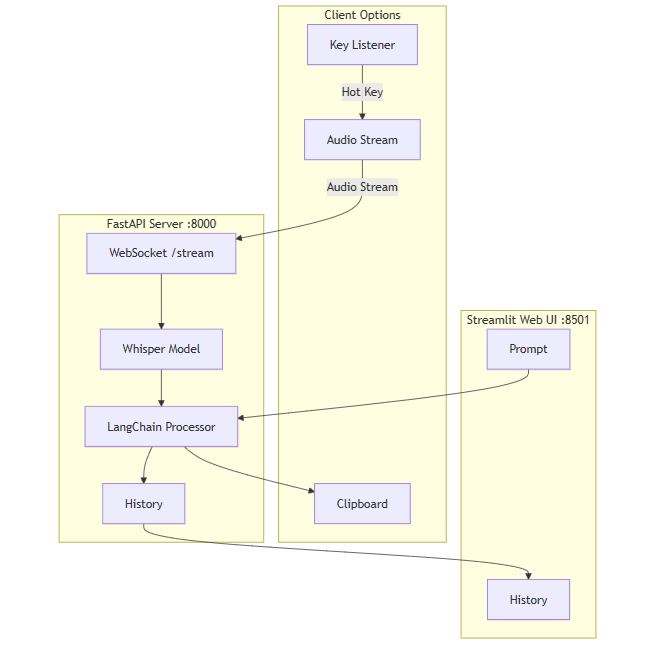
OpenAI Realtime Agents es un proyecto de código abierto que pretende mostrar cómo se pueden utilizar las API en tiempo real de OpenAI para construir aplicaciones de habla corporal multiinteligente. Proporciona un modelo de cuerpo inteligente de alto nivel (tomado de OpenAI Swarm) que permite a los desarrolladores construir complejos sistemas de habla corporal multi-inteligente en un corto periodo de tiempo. El proyecto muestra, a modo de ejemplo, cómo realizar traspasos secuenciales entre inteligencias, la potenciación en segundo plano de un modelo más inteligente y cómo hacer que el modelo siga una máquina de estados para tareas como la confirmación de la información del usuario carácter por carácter. Se trata de un valioso recurso para desarrolladores que deseen crear rápidamente prototipos de aplicaciones de voz en tiempo real con múltiples inteligencias corporales.
OpenAI proporciona una implementación de referencia para construir y orquestar patrones inteligentes utilizando APIs en tiempo real. Puedes utilizar este repositorio para crear el prototipo de una aplicación de voz utilizando un proceso de múltiples cuerpos inteligentes en menos de 20 minutos. Construir con APIs en tiempo real puede ser complicado debido a la naturaleza sincrónica y de baja latencia de la interacción por voz. Este repositorio incluye las mejores prácticas que hemos aprendido para gestionar esta complejidad.

Lista de funciones
- Traspaso inteligente de secuencias corporalesPermite el traspaso secuencial de inteligencias a partir de gráficos de inteligencias predefinidos.
- Mejora del fondoEl modelo o1-mini: es posible ampliar la tarea a modelos más avanzados (por ejemplo, o1-mini) que se ocupen de decisiones de alto riesgo.
- procesamiento de máquinas de estado: Recopila y valida con precisión información, como nombres de usuario y números de teléfono, haciendo que el modelo siga una máquina de estados.
- Creación rápida de prototipos: Proporciona herramientas para crear y probar rápidamente aplicaciones de voz multiinteligencia en tiempo real.
- Flexibilidad de configuración: Los usuarios pueden configurar su propio comportamiento corporal inteligente y su flujo de interacción.
Utilizar la ayuda
Instalación y configuración
- almacén de clones::
git clone https://github.com/openai/openai-realtime-agents.git cd openai-realtime-agents - Configuración del entorno::
- Asegúrate de tener Node.js y npm instalados.
- utilizarnpm instalarInstale todos los paquetes de dependencias necesarios.
- Iniciar el servidor local::
npm startEsto iniciará un servidor local al que podrá acceder en su navegador visitando la páginahttp://localhost:3000Ver aplicación.
Normas de uso
Buscar y seleccionar inteligencias::
- Abra su navegador y vaya ahttp://localhost:3000**. **
- Verá una interfaz con un menú desplegable "Escenario" y un menú desplegable "Agente" que le permite seleccionar diferentes escenarios de inteligencias e inteligencias específicas.
experiencia interactiva::
- Seleccionar escena: Seleccione un escenario predefinido en el menú "Escenario", por ejemplo "simpleEjemplo" o "customerServiceRetail ".
- Elegir un cuerpo inteligenteEn el menú "Agente", seleccione la inteligencia con la que desea empezar, por ejemplo "frontDeskAuthentication" o "customerServiceRetail". customerServiceRetail".
- Iniciar el diálogoInicio: Comienza a interactuar con un cuerpo inteligente introduciendo texto a través de la interfaz o directamente a través de la entrada de voz (si es compatible). La inteligencia responderá a tus entradas y podrá redirigirte a otra inteligencia para tareas más complejas.
Funcionamiento detallado de las funciones
- traspaso secuencialCuando necesite pasar de una Inteligencia a otra, por ejemplo, de la autenticación de recepción al servicio posventa, el sistema gestiona esta transferencia automáticamente. Asegúrese de que la configuración de cada organismo inteligente está correctamente definida en eldownstreamAgents.
- Mejora del fondoCuando se trata de tareas complejas o de alto riesgo, las inteligencias pueden ser promovidas automáticamente a un modelo más potente para su procesamiento. Por ejemplo, el sistema invoca el modelo o1-mini cuando se requiere una verificación detallada de la identidad de un usuario o el tratamiento de una devolución.
- procesamiento de máquinas de estadoPara las tareas que requieren confirmación carácter por carácter, como la introducción de información personal, el cuerpo inteligente guiará al usuario paso a paso a través de una máquina de estados para garantizar que cada carácter o dato es correcto. El usuario recibe información en tiempo real durante el proceso de introducción, como "Confirme que su apellido es X".
- Configuración de cuerpos inteligentesArchivos de configuración: Los archivos de configuración de las inteligencias se encuentran en el directorio src/app/agentConfigs/. Al editar estos archivos, puede cambiar el comportamiento de las inteligencias, añadir nuevas inteligencias o ajustar la lógica de las inteligencias existentes.
Consejos para desarrolladores
- Para ampliar o modificar el comportamiento de las inteligencias, se recomienda estudiar primero losagenteConfigsy, a continuación, pasar el archivoagente_transferenciaHerramientas para permitir el traspaso entre inteligencias.
- Todas las interacciones y cambios de estado entre inteligencias se muestran en la sección "Transcripción de la conversación" de la interfaz de usuario para facilitar la depuración y la mejora.
Con estos pasos y características detalladas, puedes empezar rápidamente y construir tu propia aplicación de interacción de voz corporal multi-inteligencia con OpenAI Realtime Agents.
Sobre la generación de estados de diálogo
Original: https://github.com/openai/openai-realtime-agents/blob/main/src/app/agentConfigs/voiceAgentMetaprompt.txt
Example: https://chatgpt.com/share/678dcc28-9570-800b-986a-51e6f80fd241
pista
// 将此**完整**文件直接粘贴到 ChatGPT 中,并在前两个部分添加您的上下文信息。 <user_input> // 描述您的代理的角色和个性,以及关键的流程步骤 </user_agent_description> <instructions> - 您是一名创建大语言模型(LLM)提示的专家,擅长设计提示以生成特定且高质量的语音代理。 - 根据用户在 user_input 中提供的信息,创建一个遵循 output_format 中格式和指南的提示。参考 <state_machine_info> 以确保状态机的构建和定义准确。 - 在定义“个性和语气”特征时要具有创造性和详细性,并尽可能使用多句表达。 <step1> - 此步骤可选。如果用户在输入中已经提供了用例的详细信息,则可以跳过。 - 针对“个性和语气”模板中尚未明确的特征,提出澄清性问题。通过后续问题帮助用户澄清并确认期望的行为,为每个问题提供三个高层次选项,**但不要**询问示例短语,示例短语应通过推断生成。**仅针对未明确说明或不清楚的特征提出问题。** <step_1_output_format> 首先,我需要澄清代理个性的几个方面。对于每一项,您可以接受当前草案、选择一个选项,或者直接说“使用你的最佳判断”来生成提示。 1. [未明确的特征 1]: a) // 选项 1 b) // 选项 2 c) // 选项 3 ... </step_1_output_format> </step1> <step2> - 输出完整的提示,用户可以直接逐字使用。 - **不要**在 state_machine_schema 周围输出 ``` 或 ```json,而是将完整提示输出为纯文本(用 ``` 包裹)。 - **不要**推断状态机,仅根据用户明确的指令定义状态机。 </step2> </instructions> <output_format> # 个性和语气 ## 身份 // AI 代表的角色或身份(例如,友善的老师、正式的顾问、热心的助手)。需要详细描述,包括其背景或角色故事的具体细节。 ## 任务 // 从高层次说明代理的主要职责(例如,“您是一名专注于准确处理用户退货的专家”)。 ## 风度 // 整体态度或性格特点(例如,耐心、乐观、严肃、富有同情心)。 ## 语气 // 语言风格(例如,热情且健谈、礼貌且权威)。 ## 热情程度 // 回应中表现的能量水平(例如,充满热情 vs. 冷静沉稳)。 ## 正式程度 // 语言风格的正式性(例如,“嘿,很高兴见到你!” vs. “下午好,有什么可以为您效劳?”)。 ## 情绪程度 // AI 在交流中表现出的情绪强度(例如,同情心强 vs. 直截了当)。 ## 语气词 // 用于让代理更加平易近人的填充词,例如“嗯”“呃”“哼”等。选项包括“无”“偶尔”“经常”“非常频繁”。 ## 节奏 // 对话的语速和节奏感。 ## 其他细节 // 任何能帮助塑造代理个性或语气的其他信息。 # 指令 - 紧密遵循对话状态,确保结构化和一致的互动 // 如果用户提供了 user_agent_steps,则应包含此部分。 - 如果用户提供了姓名、电话号码或其他需要确认拼写的信息,请始终重复确认,确保理解无误后再继续。// 此部分需始终包含。 - 如果用户对任何细节提出修改,请直接承认更改并确认新的拼写或信息值。 # 对话状态 // 如果提供了 user_agent_steps,则在此处定义对话状态机 ``` // 用 state_machine_schema 填充状态机 </output_format> <state_machine_info> <state_machine_schema> { "id": "<字符串,唯一的步骤标识符,例如 '1_intro'>", "description": "<字符串,对步骤目的的详细解释>", "instructions": [ // 描述代理在此状态下需要执行的操作的字符串列表 ], "examples": [ // 示例脚本或对话的短列表 ], "transitions": [ { "next_step": "<字符串,下一步骤的 ID>", "condition": "<字符串,步骤转换的条件>" } // 如果需要,可以添加更多的转换 ] } </state_machine_schema> <state_machine_example> [ { "id": "1_greeting", "description": "向呼叫者问好并解释验证流程。", "instructions": [ "友好地问候呼叫者。", "通知他们需要收集个人信息以进行记录。" ], "examples": [ "早上好,这里是前台管理员。我将协助您完成信息验证。", "让我们开始验证。请告诉我您的名字,并逐字母拼写以确保准确。" ], "transitions": [{ "next_step": "2_get_first_name", "condition": "问候完成后。" }] }, { "id": "2_get_first_name", "description": "询问并确认呼叫者的名字。", "instructions": [ "询问:‘请问您的名字是什么?’", "逐字母拼写回呼叫者以确认。" ], "examples": [ "请问您的名字是什么?", "您刚才拼写的是 J-A-N-E,对吗?" ], "transitions": [{ "next_step": "3_get_last_name", "condition": "确认名字后。" }] }, { "id": "3_get_last_name", "description": "询问并确认呼叫者的姓氏。", "instructions": [ "询问:‘谢谢。请问您的姓氏是什么?’", "逐字母拼写回呼叫者以确认。" ], "examples": [ "您的姓氏是什么?", "确认一下:D-O-E,是这样吗?" ], "transitions": [{ "next_step": "4_next_steps", "condition": "确认姓氏后。" }] }, { "id": "4_next_steps", "description": "验证呼叫者信息并继续下一步。", "instructions": [ "告知呼叫者您将验证他们提供的信息。", "调用 'authenticateUser' 函数进行验证。", "验证完成后,将呼叫者转接给 tourGuide 代理以提供进一步帮助。" ], "examples": [ "感谢您提供信息,我现在开始验证。", "正在验证您的信息。", "现在我将为您转接到另一位代理,她会为您介绍我们的设施。为展示不同的个性,她会表现得稍微严肃一些。" ], "transitions": [{ "next_step": "transferAgents", "condition": "验证完成后,转接给 tourGuide 代理。" }] } ] </state_machine_example> </state_machine_info> ```
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...