
Publicación de OpenAI: Aplicaciones y mejores prácticas para el modelado de inferencias de IA
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 52.6K 00

En el campo de la IA, la elección del modelo es fundamental. openAI, líder del sector, ofrece una familia de modelos de dos tipos principales:modelo de inferencia (Modelos de razonamiento) y Modelo GPT (Modelos GPT). Los primeros están representados por la serie o de modelos, como o1 responder cantando o3-miniEsta última es conocida por su familia de modelos GPT, como el GPT-4o. Comprender las diferencias entre estos dos tipos de modelos y los escenarios de aplicación en los que cada uno destaca es fundamental para aprovechar plenamente el potencial de la IA.
Este artículo profundizará en ello:
- Principales diferencias entre los modelos de inferencia de OpenAI y los modelos GPT.
- Cuándo priorizar el uso de los modelos de inferencia de OpenAI.
- Cómo orientar eficazmente los modelos de inferencia para obtener un rendimiento óptimo.
El otro día, los ingenieros de Microsoft publicaron un Ingeniería de sugerencias para los modelos de inferencia O1 y O3-mini de OpenAI es posible comparar las diferencias de aplicación entre ambos.
Modelos de razonamiento frente a modelos GPT: estrategas frente a ejecutores
Los modelos de inferencia de la serie o de OpenAI, a diferencia de los conocidos modelos GPT, presentan sus propios puntos fuertes en diferentes tipos de tareas y requieren diferentes estrategias de señalización. Es importante entender que estos dos tipos de modelos no son simplemente mejores o peores, sino que tienen un enfoque de capacidades diferente. Esto refleja los continuos esfuerzos de OpenAI por ampliar los límites de las capacidades de sus modelos para satisfacer las necesidades de aplicaciones cada vez más complejas que requieren un razonamiento profundo.
OpenAI ha entrenado especialmente a los modelos de la serie o, cuyo nombre en código interno es Planners (planificadores), para que piensen durante más tiempo y con mayor profundidad, lo que les permite destacar en ámbitos como la formulación de estrategias, la planificación de problemas complejos y la toma de decisiones basadas en grandes cantidades de información ambigua. La capacidad de estos modelos para completar tareas con un alto grado de precisión y exactitud los hace ideales para campos que tradicionalmente dependen de expertos humanos, como áreas especializadas de las matemáticas, la ciencia, la ingeniería, los servicios financieros y los servicios jurídicos.
Por otro lado, los modelos GPT de OpenAI (cuyo nombre en código interno es "Workhorses") son más económicos y de baja latencia, y están diseñados para la ejecución directa de tareas. En la práctica, un patrón común es utilizar una combinación de estos dos tipos de modelos: utilizar los modelos de la serie o para formular una macroestrategia de resolución de problemas y, a continuación, ejecutar eficazmente subtareas específicas con la ayuda de los modelos GPT, especialmente en escenarios en los que la velocidad y la rentabilidad son más críticas que la precisión absoluta. Esta división del trabajo refleja la madurez de la filosofía de diseño de modelos de IA, que separa la planificación de la ejecución.
¿Cómo elegir el modelo adecuado? Entender sus necesidades
A la hora de elegir un modelo, la clave está en definir los requisitos básicos de su escenario de aplicación:
- Rapidez y coste. Si la velocidad y la rentabilidad son sus prioridades, el modelo GPT suele ser la opción más rápida y económica.
- Tareas claramente definidas. Para aplicaciones con objetivos claros y límites de tareas bien definidos, el modelo GPT es capaz de sobresalir en tareas de ejecución.
- Precisión y fiabilidad. Si su aplicación exige el máximo nivel de precisión y fiabilidad de los resultados, los modelos de la serie o son los más fiables a la hora de tomar decisiones.
- Resolución de problemas complejos. Ante la gran ambigüedad y complejidad, los modelos de la serie o son capaces de hacer frente con eficacia.
Por lo tanto, si la velocidad y el coste son consideraciones primordiales, y sus casos de uso implican principalmente tareas sencillas y bien definidas, los modelos GPT de OpenAI son ideales. Sin embargo, si la precisión y la fiabilidad son fundamentales y está resolviendo problemas complejos de varios pasos, los modelos de la serie o de OpenAI pueden adaptarse mejor a sus necesidades.
En muchos flujos de trabajo de IA del mundo real, la mejor práctica es utilizar una combinación de estos dos modelos: la familia de modelos o actúa como un "planificador" responsable de la planificación y la toma de decisiones del agente, mientras que la familia de modelos GPT actúa como un "ejecutor" responsable de la ejecución de tareas específicas. Esta estrategia combinada aprovecha al máximo los puntos fuertes de ambos tipos de modelos.

Por ejemplo, los modelos GPT-4o y GPT-4o mini de OpenAI pueden utilizarse en escenarios de servicio al cliente, donde la información del cliente se utiliza primero para clasificar los detalles del pedido, identificar los problemas del pedido y las políticas de devolución, y luego estos puntos de datos se introducen en el modelo o3-mini, que toma la decisión final sobre la viabilidad de una devolución basándose en políticas preestablecidas.
Escenarios de aplicación de los modelos de inferencia: sobresalir en complejidad y ambigüedad
OpenAI ha desarrollado algunos patrones típicos de aplicaciones exitosas de sus modelos de inferencia a través de la colaboración con clientes y observaciones internas. Los escenarios de aplicación que se enumeran a continuación no son exhaustivos, sino más bien guías prácticas diseñadas para ayudarle a evaluar y probar mejor los modelos de la serie o de OpenAI.
1. Navegar por tareas ambiguas: comprender la intención a partir de información fragmentada
Los modelos de razonamiento son especialmente buenos a la hora de gestionar tareas con información incompleta o dispersa. Incluso cuando se les pide información limitada, los modelos de inferencia pueden comprender eficazmente la verdadera intención del usuario y manejar adecuadamente las ambigüedades de las instrucciones. Cabe destacar que los modelos de inferencia no suelen apresurarse a hacer conjeturas imprudentes o tratar de rellenar los vacíos de información por su cuenta, sino que formulan preguntas aclaratorias de forma proactiva para asegurarse de que los requisitos de la tarea se entienden con precisión. Este es un buen ejemplo de las ventajas de los modelos de razonamiento a la hora de enfrentarse a la incertidumbre y a tareas complejas.
Hebbia, una plataforma de conocimiento de IA para los sectores jurídico y financiero, ha declarado: "Las superiores capacidades de inferencia de o1 permiten a Matrix, la plataforma multiagente de OpenAI, procesar eficazmente documentos complejos y generar respuestas detalladas, bien estructuradas e informativas. Por ejemplo, o1 facilita a Matrix la identificación, con sencillas indicaciones, de la cantidad de dinero disponible en virtud de un contrato de crédito con capacidad de pago restringida. Ningún otro modelo había alcanzado antes este nivel de rendimiento. En las pruebas intensivas de señalización compleja de contratos de crédito de 52%, o1 obtuvo resultados más significativos que otros modelos."
-Hebbia, una empresa de plataformas de conocimiento de IA para los sectores jurídico y financiero
2. Recuperación de la información: encontrar la aguja en el pajar, localizarla con precisión
Cuando se enfrenta a cantidades masivas de información no estructurada, el modelo de inferencia demuestra una gran comprensión de la información y es capaz de extraer con precisión la información más relevante para la pregunta, respondiendo así con eficacia a la pregunta del usuario. Esto pone de relieve el rendimiento superior de los modelos de inferencia en la recuperación de información y el filtrado de información clave, especialmente cuando se trata de conjuntos de datos a gran escala.
Endex, la plataforma de inteligencia financiera basada en IA, afirma: "Para analizar en profundidad las adquisiciones de empresas, se utilizó el modelo o1 para revisar docenas de documentos de la empresa, incluidos contratos y acuerdos de arrendamiento, con el objetivo de encontrar posibles cláusulas que pudieran afectar negativamente al acuerdo. El modelo se encargó de señalar las cláusulas clave. Al hacerlo, o1 identificó con agudeza una cláusula clave de "cambio de control" en una nota a pie de página: una cláusula que estipulaba la devolución inmediata de un préstamo de 75 millones de dólares si se vendía la empresa. La gran atención al detalle de o1 permite a los agentes de IA de OpenAI apoyar eficazmente el trabajo de los profesionales financieros identificando con precisión la información de misión crítica."
--Endex, Plataforma de Inteligencia Financiera de IA
3. Descubrimiento de relaciones e identificación de matices: profundizar en el valor de los datos
OpenAI ha descubierto que los modelos de inferencia son especialmente buenos para analizar documentos densos y desestructurados de cientos de páginas, como contratos legales, estados financieros y reclamaciones de seguros. Estos modelos son eficaces a la hora de extraer información de documentos complejos, establecer conexiones entre distintos documentos y tomar decisiones inferenciales basadas en hechos implícitos en los datos. Esto demuestra que los modelos de inferencia tienen ventajas significativas a la hora de procesar documentos complejos y extraer información en profundidad.
Blue J, una plataforma de IA para la investigación fiscal, menciona: "La investigación fiscal a menudo requiere integrar información de múltiples documentos para formar una conclusión final convincente. Tras sustituir el modelo GPT-4o por el modelo o1, OpenAI descubrió que o1 funciona mejor a la hora de razonar sobre las interacciones entre documentos y es capaz de extraer conclusiones lógicas que no son evidentes en un solo documento. Como resultado, al cambiar al modelo o1, OpenAI vio una impresionante mejora de 4x en el rendimiento de extremo a extremo."
--Blue J, Plataforma de IA para la investigación fiscal
Los modelos de razonamiento son igualmente hábiles para comprender políticas y normas matizadas y aplicarlas a tareas específicas para llegar a conclusiones razonables.
BlueFlame AI, una plataforma de IA para la gestión de inversiones, pone un ejemplo: "En el campo del análisis financiero, los analistas deben enfrentarse a menudo a situaciones complejas relacionadas con los derechos de los accionistas y necesitan conocer en profundidad las complejidades jurídicas asociadas. OpenAI probó unos 10 modelos de distintos proveedores a partir de una pregunta difícil pero común: ¿Cómo afectará el comportamiento de la financiación a los accionistas existentes, especialmente cuando ejercen su privilegio antidilución? Esta pregunta requiere razonar sobre las valoraciones de la empresa antes y después de la financiación y abordar las complejidades de la dilución cíclica, una cuestión que incluso los mejores analistas financieros tardarían entre 20 y 30 minutos en comprender. OpenAI ha descubierto que los modelos o1 y o3-mini resuelven este problema a la perfección. Los modelos generaron incluso una tabla computacional clara que mostraba en detalle el impacto del comportamiento de la financiación en 100.000 accionistas."
--BlueFlame AI, una plataforma de IA para la gestión de inversiones
4. Planificación multietapa de la agencia: planificar el éxito en el lugar de trabajo
Los modelos de inferencia desempeñan un papel crucial en la planificación de agentes y la formulación de estrategias. OpenAI ha observado que los modelos de inferencia, cuando se sitúan como "planificadores", son capaces de generar soluciones detalladas de varios pasos para problemas complejos. Posteriormente, el sistema puede seleccionar y asignar el modelo GPT ("ejecutor") más adecuado para ejecutar cada paso, en función de las distintas demandas de latencia e inteligencia. Esto demuestra aún más las ventajas de utilizar una combinación de modelos, con el modelo de inferencia actuando como el "cerebro" para la planificación de la estrategia y el modelo GPT actuando como los "brazos y piernas" para la ejecución.
Argon AI, una plataforma de conocimiento de IA para la industria farmacéutica, revela: "OpenAI utiliza el modelo o1 como planificador en su infraestructura de agentes, lo que le permite orquestar otros modelos en el flujo de trabajo para completar eficientemente tareas de varios pasos. OpenAI ha descubierto que el modelo o1 es muy bueno a la hora de elegir el tipo de datos adecuado y descomponer problemas grandes y complejos en módulos más pequeños y manejables para que otros modelos puedan centrarse en ejecuciones específicas."
--Argon AI, una plataforma de conocimiento de IA para la industria farmacéutica
Lindy.AI, un asistente de trabajo de IA, ha declarado: "El modelo o1 ofrece un potente soporte para los numerosos flujos de trabajo de Lindy, el asistente de trabajo de IA de OpenAI. El modelo es capaz de utilizar llamadas a funciones para extraer información clave del calendario o el correo electrónico de un usuario para ayudarle automáticamente a programar reuniones, enviar correos electrónicos y gestionar otros aspectos de sus tareas diarias". OpenAI cambió todos los pasos anteriores del agente de Lindy que causaban problemas al modelo o1 y observó que la funcionalidad del agente de Lindy pasó a ser impecable casi de la noche a la mañana."
--Lindy.AI, Asistente de IA para el trabajo
5. Razonamiento visual: comprender la información que hay detrás de la imagen
A partir de hoy.o1 es el único modelo de inferencia que admite funciones de inferencia visual. o1 junto con GPT-4o La diferencia significativa entre loso1 Incluso la información visual más difícil, como gráficos de estructura compleja, tablas o fotografías con mala calidad de imagen, puede manejarse con eficacia. Esto pone de relieve la importancia de o1 Ventajas únicas en el campo del procesamiento de la información visual.
Safetykit, una plataforma de supervisión de comerciantes basada en IA, menciona: "OpenAI se compromete a automatizar las revisiones de riesgo y cumplimiento de millones de productos en línea, incluidas réplicas de joyas de lujo, especies en peligro de extinción y artículos regulados". En la tarea de clasificación de imágenes más exigente de OpenAI, el modelo GPT-4o solo fue preciso en 50%. y
o1El modelo alcanza una impresionante precisión de hasta 88% sin necesidad de modificar los procesos actuales de OpenAI".-Safetykit, plataforma de inteligencia artificial para la supervisión de comercios
Las propias pruebas internas de OpenAI también han demostrado queo1 El modelo es capaz de identificar accesorios y materiales a partir de planos arquitectónicos muy detallados y generar una lista de materiales completa. Uno de los fenómenos más sorprendentes observados por OpenAI es que elo1 El modelo es capaz de establecer conexiones entre distintas imágenes; por ejemplo, puede tomar la leyenda de una página de un dibujo arquitectónico y aplicarla exactamente a otra página sin instrucciones explícitas. En el ejemplo siguiente, podemos ver que para la "Columna de madera 4x4 PT", la leyendao1 El modelo fue capaz de reconocer correctamente que "PT" significaba "tratado a presión" según la leyenda. Esta es una buena demostración de la o1 en la comprensión de información visual compleja y el razonamiento entre documentos.

6. Revisión del código, depuración y mejora de la calidad: búsqueda de la excelencia, optimización del código
Los modelos de inferencia destacan en la revisión y mejora de código y son especialmente buenos en el manejo de bases de código a gran escala. Dada la latencia relativamente alta de los modelos de inferencia, las tareas de revisión de código suelen ejecutarse en segundo plano. Esto sugiere que, a pesar de la latencia, los modelos de inferencia tienen importantes aplicaciones en el análisis de código y el control de calidad, especialmente para escenarios que no requieren un alto rendimiento en tiempo real.
La startup de revisión de código de IA CodeRabbit revela: "OpenAI ofrece servicios automatizados de revisión de código de IA en plataformas de alojamiento de código como GitHub y GitLab. El proceso de revisión de código es intrínsecamente insensible a la latencia, pero requiere un profundo conocimiento de los cambios de código en múltiples archivos. Aquí es donde destaca el modelo o1: detecta con fiabilidad cambios sutiles en el código base que un revisor humano podría pasar por alto fácilmente. Después de cambiar a los modelos de la serie o, OpenAI vio un aumento de 3 veces en las conversiones de productos."
-CodeRabbit, la startup de revisión de código por IA
aunque GPT-4o responder cantando GPT-4o mini puede ser más adecuado para escenarios de codificación de baja latencia, pero OpenAI también observa que o3-mini destaca en los casos de uso de generación de código insensible a la latencia. Esto significa que el modelo o3-mini También tiene potencial en el ámbito de la generación de código, especialmente en escenarios de aplicación que requieren una alta calidad de código y son relativamente indulgentes con la latencia.
Empresas emergentes de completado de código basado en IA Codeium comentó: "Incluso ante tareas de codificación difíciles, el
o3-miniLos modelos también son capaces de generar sistemáticamente código concluyente y de alta calidad, y con mucha frecuencia dan con la solución correcta cuando el problema está bien definido. Puede que otros modelos sólo sean adecuados para pequeñas y rápidas iteraciones de código, pero loso3-miniLos modelos se especializan en la planificación y ejecución de sistemas complejos de diseño de software".--Codeium, la startup de extensión de código basada en IA
7. Evaluación de modelos y evaluación comparativa: evaluación objetiva y selección de lo mejor de lo mejor
OpenAI también descubrió que los modelos de inferencia funcionaban bien a la hora de comparar y evaluar otras respuestas de modelos. La validación de datos es fundamental para garantizar la calidad y fiabilidad de los conjuntos de datos, especialmente en ámbitos delicados como la sanidad. Los métodos de validación tradicionales se basan en reglas y patrones predefinidos, pero métodos como o1 responder cantando o3-mini Estos modelos avanzados son capaces de comprender el contexto y razonar sobre él, permitiendo métodos de verificación más flexibles e inteligentes. Esto sugiere que los modelos de inferencia pueden actuar como "árbitros" para evaluar la calidad de los resultados de otros modelos, lo cual es fundamental para la optimización iterativa de los sistemas de IA.
Braintrust, la plataforma de evaluación de IA, señala: "Muchos clientes utilizan la función LLM-as-a-judge de la plataforma Braintrust como parte de su proceso de evaluación. Por ejemplo, una empresa sanitaria podría utilizar una herramienta como
gpt-4oDicho modelo maestro para resumir el problema de la historia del paciente y luego utilizar elo1para evaluar la calidad de los resúmenes. Un cliente de Braintrust descubrió que4oLa puntuación F1 es de 0,12 cuando el modelo se utiliza como árbitro, y al pasar alo1Tras la modelización, la puntuación F1 subió a 0,74. En estos casos de uso, descubrieron queo1La capacidad de razonamiento del modelo es transformadora a la hora de captar los matices de los resultados finales, especialmente en las tareas de puntuación más difíciles y complejas."--Braintrust, una plataforma de evaluación de IA
Consejos para estimular eficazmente los modelos de razonamiento: la sencillez es lo primero
Los modelos de razonamiento tienden a rendir mejor cuando reciben indicaciones claras y concisas. Algunas técnicas tradicionales de ingeniería de pistas, como ordenar al modelo que "piense paso a paso", pueden no ser eficaces para mejorar el rendimiento, e incluso a veces pueden ser contraproducentes. A continuación se exponen algunas de las mejores prácticas, o puede consultar los ejemplos de indicaciones para empezar.
- Los mensajes del desarrollador sustituyen a los mensajes del sistema. a través de (un hueco)
o1-2024-12-17en adelante, el modelo de inferencia empezó a admitir mensajes del desarrollador, en lugar de los mensajes tradicionales del sistema, para ajustarse al comportamiento de la cadena de instrucciones descrita en la especificación del modelo. - Las preguntas deben ser sencillas y directas. Los modelos de razonamiento son buenos comprendiendo y respondiendo a instrucciones claras y concisas. Por lo tanto, las instrucciones claras y directas son más eficaces para los modelos de razonamiento que las técnicas complejas de ingeniería de pistas.
- Consejo para evitar las cadenas de pensamiento. No es necesario pedir al modelo de razonamiento que "piense paso a paso" o "explique su proceso de razonamiento", puesto que ya dispone de capacidades de razonamiento internas. Por el contrario, estas indicaciones redundantes pueden degradar el rendimiento del modelo.
- Utilice delimitadores para mejorar la claridad. El uso de separadores como Markdown, etiquetas XML y encabezados de sección para etiquetar claramente las distintas partes de la entrada ayuda al modelo a comprender con precisión el contenido de las diferentes secciones.
- Dar prioridad a los intentos de obtener indicios de muestra nula antes de considerar indicios de muestra menor: la Los modelos de inferencia suelen producir buenos resultados sin necesidad de pocos ejemplos de muestra. Por lo tanto, se recomienda que primero intente escribir sugerencias sin ejemplos. Si tiene requisitos más complejos para los resultados de salida, puede ser útil incluir algunos ejemplos de entradas y salidas deseadas en sus sugerencias. Sin embargo, es importante asegurarse de que los ejemplos son muy coherentes con sus instrucciones, ya que las desviaciones entre los dos pueden conducir a resultados pobres.
- Proporcionar orientaciones claras y específicas. Si hay restricciones explícitas que pueden limitar la gama de respuestas del modelo (por ejemplo, "Proponga una solución con un presupuesto inferior a 500 dólares"), articule claramente esas restricciones en la solicitud.
- Aclaración del objetivo final. En las instrucciones, sea lo más específico posible al describir los criterios por los que se juzgarán las respuestas satisfactorias, y anime al modelo a seguir razonando e iterando hasta que se cumplan sus criterios de éxito.
- Control de formato Markdown. a través de (un hueco)
o1-2024-12-17A partir de la versión 1, los modelos de inferencia de la API evitan generar respuestas con formato Markdown por defecto. Si desea que el modelo incluya el formato Markdown en sus respuestas, añada la cadenaFormatting re-enabled.
Ejemplos de uso de la API del modelo de inferencia
Los modelos de razonamiento son únicos en su proceso de "pensamiento". A diferencia de los modelos lingüísticos tradicionales, los modelos de inferencia piensan internamente en profundidad y construyen una larga cadena de razonamientos antes de dar una respuesta. Como se indica en la descripción oficial de OpenAI, estos modelos piensan profundamente antes de responder al usuario. Este mecanismo confiere a los modelos de inferencia la capacidad de sobresalir en tareas como la resolución de rompecabezas complejos, la codificación, el razonamiento científico y la planificación en varios pasos de los flujos de trabajo de los Agentes.
De forma similar al modelo GPT de OpenAI, OpenAI proporciona dos modelos de inferencia para satisfacer diferentes necesidades:o3-mini Este modelo destaca por su menor tamaño y mayor velocidad, mientras que el ficha Los costes también son relativamente bajos. o1 Los modelos, por su parte, compensan una mayor escala y una velocidad ligeramente inferior con una resolución de problemas más potente.o1 Los modelos suelen generar respuestas de mejor calidad cuando se enfrentan a tareas complejas y muestran un mejor rendimiento de generalización entre dominios.
inicio rápido
Para ayudar a los desarrolladores a empezar rápidamente, OpenAI proporciona una interfaz API fácil de usar. A continuación se muestra un ejemplo de inicio rápido sobre cómo utilizar el modelo de inferencia en las finalizaciones de chat:
Utilización de modelos de inferencia en la finalización de chats
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
reasoning_effort: "medium",
messages: [
{
role: "user",
content: prompt
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
"""
response = client.chat.completions.create(
model="o3-mini",
reasoning_effort="medium",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o3-mini",
"reasoning_effort": "medium",
"messages": [
{
"role": "user",
"content": "编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,格式为 \"[1,2],[3,4],[5,6]\",并以相同的格式打印转置矩阵。"
}
]
}'
Intensidad del razonamiento: control de la profundidad del pensamiento en el modelo
En el ejemplo anterior, elreasoning_effort El parámetro (denominado cariñosamente "jugo" durante el desarrollo de estos modelos) se utiliza para guiar al modelo en la cantidad de cálculo de inferencia que realiza antes de generar una respuesta. El usuario puede especificar para este parámetro lowymedium tal vez high Uno de los tres valores. Donde.low se centra en la velocidad y el menor coste de las fichas, mientras que el modelo high provoca un razonamiento más profundo y exhaustivo por parte del modelo, pero aumenta el consumo de tokens y el tiempo de respuesta. El valor por defecto es mediumtiene como objetivo lograr un equilibrio entre velocidad y precisión de inferencia. Los desarrolladores pueden ajustar con flexibilidad la intensidad de la inferencia en función de las necesidades de los escenarios de aplicación reales para lograr un rendimiento y una rentabilidad óptimos.
Cómo funciona el razonamiento: un análisis en profundidad del proceso de "pensamiento" de los modelos
El modelo de inferencia se basa en los tradicionales tokens de entrada y salida introduciendo el Razonamiento sobre fichas Este concepto. Estos tokens de inferencia son análogos al "proceso de pensamiento" del modelo, y éste los utiliza para descomponer su comprensión de las pistas del usuario y explorar múltiples caminos posibles para generar respuestas. Sólo después de que se haya completado la generación de los tokens de inferencia, el modelo emite la respuesta final, un token complementario visible para el usuario, y descarta el token de inferencia del contexto.
La siguiente figura muestra un ejemplo de diálogo en varios pasos entre un usuario y un asistente. En cada paso del diálogo, se retienen los tokens de entrada y salida, mientras que el modelo descarta los tokens de inferencia.
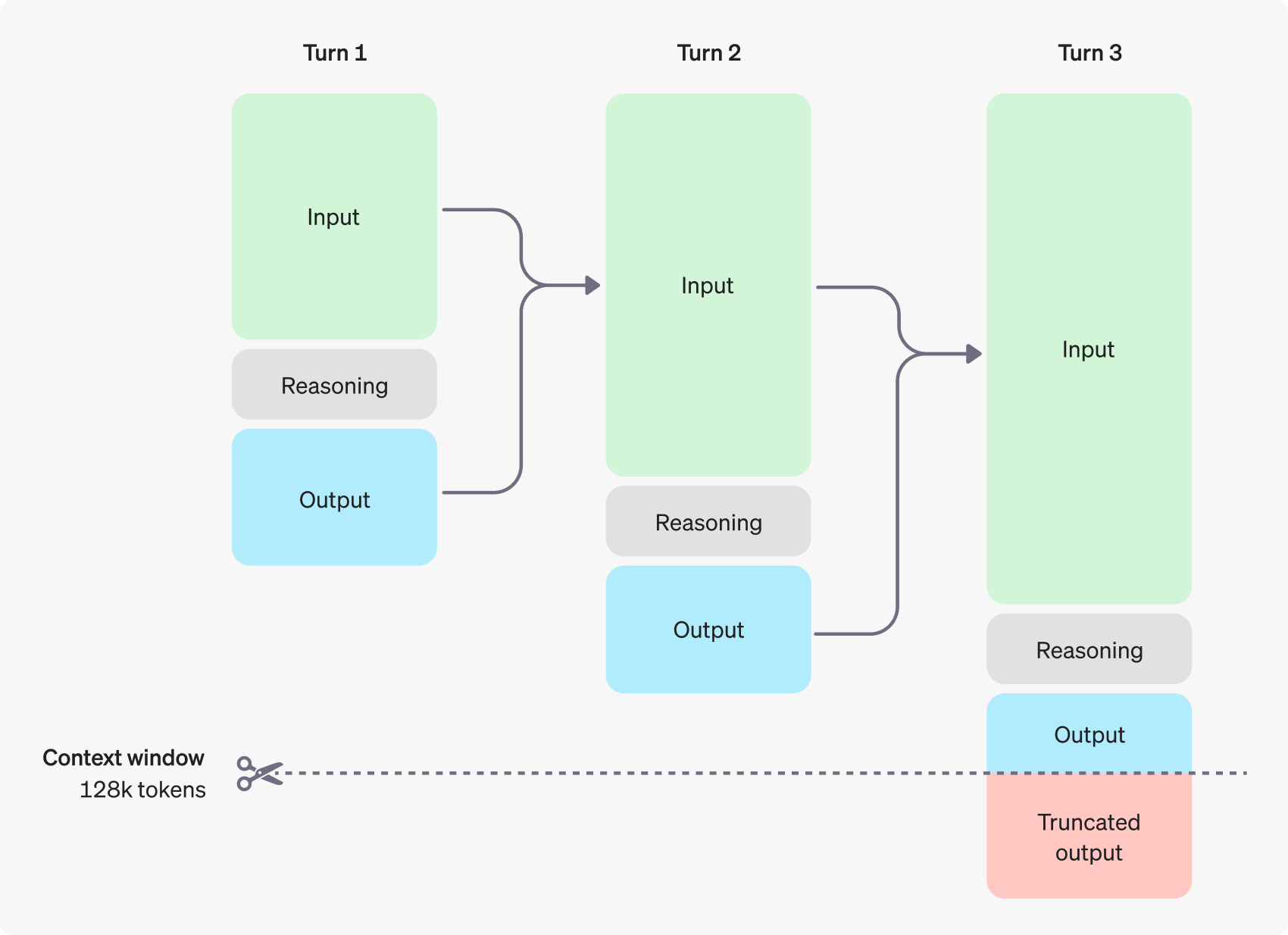
Cabe señalar que, aunque los tokens de inferencia no son visibles a través de la interfaz API, siguen ocupando el espacio de la ventana de contexto del modelo y cuentan para el uso total de tokens, y deben pagarse igual que los tokens de salida. Por lo tanto, en la práctica, los desarrolladores deben tener en cuenta el impacto de los tokens de inferencia y gestionar adecuadamente la ventana de contexto del modelo y el consumo de tokens.
Gestión contextual de ventanas: garantizar que los modelos tengan mucho "espacio para pensar".
Cuando se crea una solicitud de finalización, es importante asegurarse de que la ventana de contexto tiene espacio suficiente para los tokens de inferencia generados por el modelo.Dependiendo de la complejidad del problema, el modelo puede necesitar generar de cientos a decenas de miles de tokens de inferencia.El usuario puede crear los tokens de inferencia a través del objeto de uso del objeto de respuesta de finalización del chat en el objeto completion_tokens_details para ver el número exacto de tokens de inferencia utilizados por el modelo para una solicitud concreta:
{
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
Las longitudes de la ventana de contexto para los distintos modelos están a disposición del usuario en la página de Referencia del modelo. La evaluación y gestión adecuadas de la ventana de contexto son esenciales para garantizar el funcionamiento eficaz del modelo de inferencia.
Control de costes: ajuste y optimización del consumo de fichas
Para gestionar eficazmente el coste del modelo de inferencia, los usuarios pueden utilizar la función max_completion_tokens que limita el número total de fichas generadas por el modelo, incluidas las fichas de inferencia y las fichas complementarias.
En los modelos anteriores, elmax_tokens El parámetro controla tanto el número de tokens generados por el modelo como el número de tokens visibles para el usuario, que son siempre los mismos. Sin embargo, para los modelos de inferencia, el número total de tokens generados por el modelo puede exceder el número de tokens vistos finalmente por el usuario debido a la introducción de tokens de inferencia interna.
Tenga en cuenta que algunas aplicaciones pueden depender de max_tokens sea coherente con el número de tokens devueltos por la API, OpenAI ha introducido un parámetro especial max_completion_tokens para controlar de forma más explícita el número total de tokens generados por el modelo, incluidos los tokens de inferencia y los tokens complementarios visibles para el usuario. Esta configuración explícita de los parámetros garantiza una transición fluida para las aplicaciones existentes que utilicen el nuevo modelo, evitando posibles problemas de compatibilidad. En todos los modelos anteriores, el parámetromax_tokens La función del parámetro no cambia.
Dejar espacio para el razonamiento: evitar las interrupciones para "pensar
Si el número de tokens generados alcanza el límite de la ventana de contexto o el establecido por el usuario max_completion_tokens la API devolverá una respuesta de finalización de chat con el valor finish_reason El campo se establece en length. Esto puede ocurrir antes de que el modelo genere ningún token complementario visible para el usuario, lo que significa que el usuario puede tener que pagar por tokens de entrada y tokens de inferencia, pero en última instancia no recibir ninguna respuesta visible.
Para evitar lo anterior, asegúrese siempre de que la ventana contextual tiene suficiente espacio reservado, o coloque el botón max_completion_tokens openAI recomienda reservar espacio para al menos 25.000 tokens para los procesos de inferencia y salida cuando se prueban por primera vez estos modelos de inferencia. A medida que los usuarios se familiaricen con el número de tokens de inferencia necesarios para sus peticiones, este tamaño de buffer puede ajustarse según convenga para un control de costes más granular.
Sugerencia: liberar el potencial de los modelos de razonamiento
Existen algunas diferencias clave que el usuario debe tener en cuenta a la hora de solicitar modelos de inferencia y modelos GPT. En general, el modelo de inferencia tiende a dar mejores resultados en tareas en las que sólo se proporcionan instrucciones de alto nivel. Esto contrasta con el modelo GPT, que suele dar mejores resultados cuando se reciben instrucciones muy precisas.
- Modelos de razonamiento como los colegas experimentados -- Se puede confiar en que los usuarios resuelvan los detalles concretos de forma autónoma simplemente diciéndoles lo que quieren conseguir.
- El modelo GPT es más como un asistente junior -- Funcionan mejor cuando tienen instrucciones claras y detalladas para crear un resultado específico.
Para obtener más información sobre las mejores prácticas para el uso de modelos de inferencia, consulte la guía oficial de OpenAI.
Ejemplo de consejo: Demostración de un escenario de aplicación
Codificación (refactorización del código)
Los modelos de la serie o de OpenAI demuestran unas potentes capacidades de comprensión algorítmica y generación de código. El siguiente ejemplo demuestra cómo se puede utilizar el modelo o1 para refactorizar según criterios específicos Reaccione Componente.
refactorizar código
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Código (planificación de proyectos)
El modelo o-series de OpenAI también es bueno para desarrollar planes de proyectos de varios pasos. El siguiente ejemplo muestra cómo usar el modelo o1 para crear una estructura completa de sistema de archivos para una aplicación Python y generar código Python que implemente la funcionalidad requerida.
Planificar y crear un proyecto Python
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Investigación STEM
Los modelos de la serie o de OpenAI han demostrado un excelente rendimiento en la investigación STEM (Ciencia, Tecnología, Ingeniería y Matemáticas). Estos modelos suelen ofrecer resultados impresionantes en tareas de investigación básica.
Plantear cuestiones relacionadas con la investigación en ciencias básicas
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
ejemplo oficial
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...