OmniVinci: el modelo de gran lenguaje omnimodal de código abierto de NVIDIA
Últimos recursos sobre IAPublicado hace 5 meses Círculo de intercambio de inteligencia artificial 30.4K 00

¿Qué es OmniVinci?
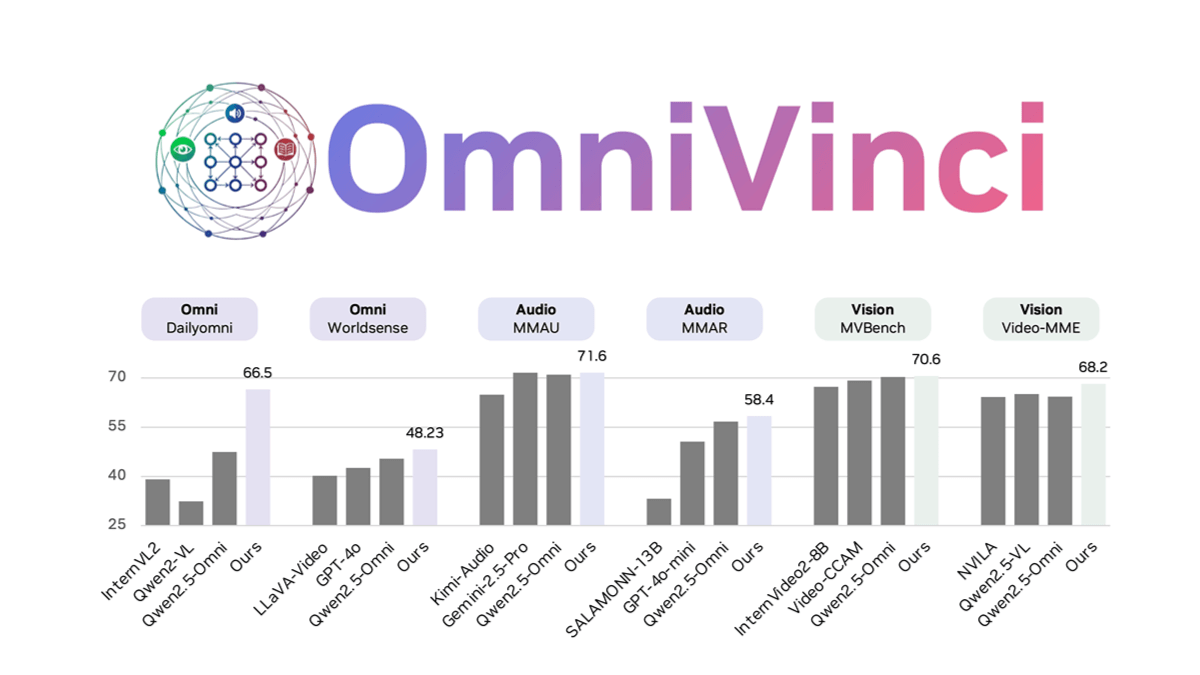
OmniVinci es un modelo de lenguaje a gran escala, completamente modal y de código abierto desarrollado por NVIDIA que resuelve el problema de la fragmentación modal en modelos multimodales mediante la innovación arquitectónica y la optimización de datos. La alineación de las incrustaciones visuales y sonoras se mejora mediante OmniAlignNet, que utiliza agrupaciones de incrustación temporal para capturar la información de alineación temporal relativa e incrustaciones temporales rotacionales restringidas para codificar la información temporal absoluta.OmniVinci genera un gran número de muestras de diálogo monomodal y omnimodal para el entrenamiento mediante la síntesis de datos y una estrategia de distribución de datos bien diseñada. La estrategia de entrenamiento en dos fases, entrenamiento unimodal seguido de entrenamiento omnimodal conjunto, integra eficazmente la comprensión multimodal.OmniVinci obtiene buenos resultados en varias pruebas de referencia, por ejemplo, obtiene 19,05 puntos más que Qwen2.5-Omni en DailyOmni, y la cantidad de tokens de entrenamiento se reduce drásticamente. OmniVinci se ha aplicado a la interpretación de imágenes médicas de TC, la detección de dispositivos semiconductores, etc., y ha demostrado una gran capacidad de comprensión multimodal.
Características de OmniVinci
- comprensión multimodalCapacidad de procesar simultáneamente información visual, sonora y textual para permitir la comprensión y el razonamiento multimodales; por ejemplo, se puede generar una descripción detallada basada en el contenido de un vídeo que incluya información visual y sonora.
- Modelo de innovación arquitectónicaMejora de la alineación de las incrustaciones visuales y sonoras mediante OmniAlignNet, utilizando la agrupación de incrustaciones temporales para capturar la información de alineación temporal relativa de las señales visuales y sonoras y codificando la información temporal absoluta mediante incrustaciones temporales rotacionales restringidas para mejorar la comprensión del modelo de señales multimodales.
- Síntesis y optimización de datosGenerar un gran número de muestras de diálogo unimodales y omnimodales mediante la síntesis de datos y una estrategia de distribución de datos bien diseñada para optimizar los datos de entrenamiento y mejorar la capacidad de generalización y el rendimiento del modelo.
- Estrategia de formación en dos etapasEl objetivo es desarrollar las capacidades de comprensión visual y auditiva por separado, y después integrarlas para lograr una comprensión intermodal, mejorando así la capacidad de razonamiento multimodal del modelo.
- Formación eficazDurante el entrenamiento, OmniVinci consigue un excelente rendimiento utilizando una pequeña cantidad de tokens de entrenamiento (0,2 billones), lo que reduce drásticamente el consumo de recursos de entrenamiento en comparación con otros modelos.
Puntos fuertes de OmniVinci
- Potente comprensión multimodalCapacidad de procesar simultáneamente información procedente de múltiples modalidades, como la visión, el audio y el texto, lo que permite la comprensión y el razonamiento intermodales.
- Estrategias de formación eficacesEl enfoque de formación en dos fases, con una formación unimodal seguida de una formación conjunta totalmente modal, integra eficazmente la comprensión multimodal al tiempo que reduce el consumo de recursos de formación.
- Arquitectura de modelos innovadoraEl alineamiento mejorado de las incrustaciones visuales y sonoras mediante OmniAlignNet, la agrupación de incrustaciones temporales y la incrustación temporal rotacional restringida mejora la comprensión de las señales multimodales por parte del modelo.
- Preparación optimizada de datosGenerar un gran número de muestras de diálogo unimodales y omnimodales de alta calidad mediante la síntesis de datos y estrategias de distribución de datos bien diseñadas para optimizar los datos de entrenamiento y mejorar la capacidad de generalización del modelo.
- Excelente rendimientoSupera a otros modelos en tareas como DailyOmni, MMAR y Video-MME, con una reducción significativa de la cantidad de tokens de entrenamiento.
Cuál es la página web oficial de OmniVinci
- Página web del proyecto:: https://nvlabs.github.io/OmniVinci/
- Repositorio Github:: https://github.com/NVlabs/OmniVinci
- Biblioteca de modelos HuggingFace:: https://huggingface.co/nvidia/omnivinci
- Documento técnico arXiv:: https://arxiv.org/pdf/2510.15870
¿A quién va dirigido OmniVinci?
- Investigadores en inteligencia artificialLos investigadores interesados en el aprendizaje multimodal, la modelización del lenguaje a gran escala y la comprensión multimodal pueden explorar nuevas vías de investigación y avances tecnológicos con OmniVinci.
- Ingeniero de aprendizaje automáticoLos ingenieros que desarrollan y optimizan aplicaciones multimodales pueden utilizar OmniVinci para mejorar el rendimiento de los modelos en proyectos reales.
- Profesionales de la industria médicaPor ejemplo, los radiólogos e investigadores médicos pueden utilizar la comprensión multimodal de OmniVinci para interpretar con mayor precisión las imágenes médicas y los datos relacionados.
- Especialistas en automatización industrialEn la fabricación inteligente, utilice las capacidades de procesamiento de visión y audio de OmniVinci para mejorar la eficacia de la inspección de equipos y el control de calidad.
- Desarrollador de robóticaOmniVinci: los ingenieros que desarrollan sistemas robóticos inteligentes pueden utilizar OmniVinci para mejorar la capacidad de un robot para percibir y comprender su entorno.
- científico de datosLos científicos de datos que necesiten procesar datos a gran escala y realizar análisis de datos multimodales pueden utilizar OmniVinci para mejorar la eficacia del procesamiento de datos y la precisión analítica.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...