Omnilingual ASR - Marco de reconocimiento del habla multilingüe de Meta
Últimos recursos sobre IAPublicado hace 5 meses Círculo de intercambio de inteligencia artificial 29K 00

¿Qué es la ASR omnilingüe?
Omnilingual ASR es un marco de reconocimiento del habla multilingüe de Meta, que cubre más de 1600 idiomas, con una tasa de error de caracteres de 781 TP3T por debajo de 101 TP3T. Su codificador wav2vec 2.0 de 7.000 millones de parámetros, combinado con el decodificador CTC y Transformer, admite la transcripción sin muestras de idiomas desconocidos, y sólo se necesitan unas pocas muestras para adaptarse a un nuevo lengua. El modelo es de código abierto y contiene un corpus de 350 lenguas de escasos recursos, lo que fomenta la digitalización de lenguas en peligro en todo el mundo y la inclusión de la tecnología del habla.
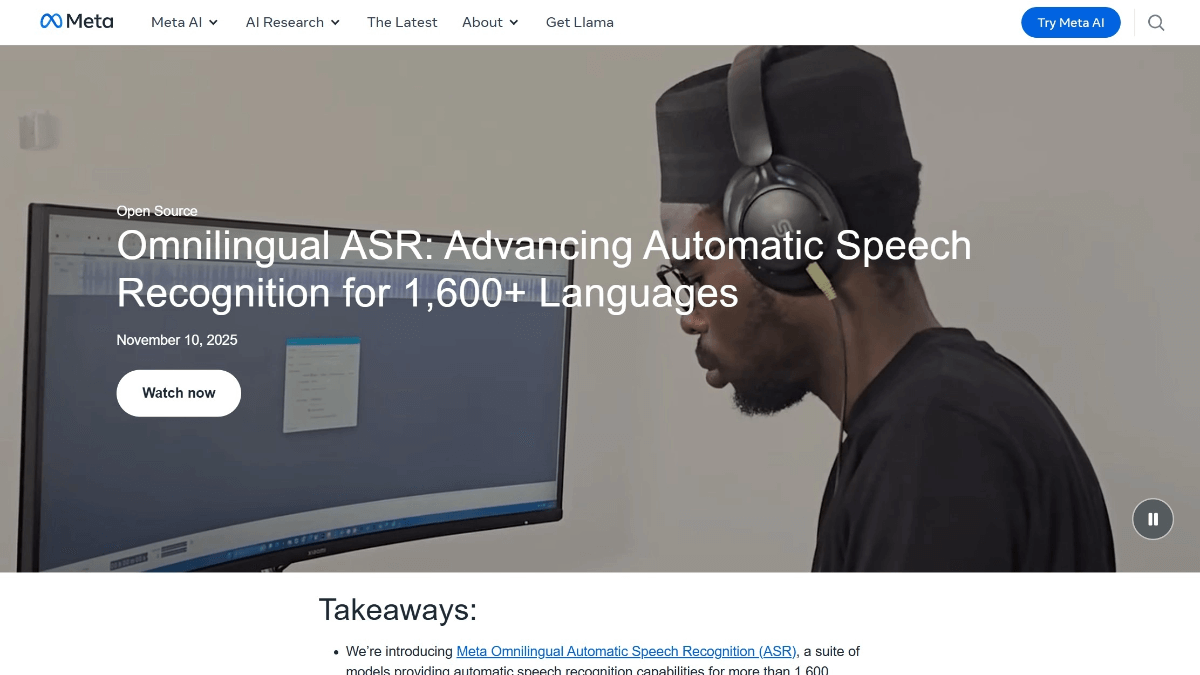
Características del ASR omnilingüe
- cobertura multilingüe: Admite más de 1.600 idiomas, entre ellos una amplia gama de lenguas con pocos recursos y en peligro de extinción, lo que mejora significativamente la cobertura lingüística global del reconocimiento de voz.
- Apoyo lingüístico de escasos recursos: Mediante técnicas de aprendizaje autosupervisado y mejora de datos, resuelve eficazmente el problema de los datos dispersos en lenguas de escasos recursos y reduce el umbral de reconocimiento del habla.
- Capacidad de aprendizaje de muestra ceroLa capacidad de transcribir una nueva lengua con sólo un pequeño número de ejemplos, sin necesidad de un corpus a gran escala, amplía enormemente la cobertura lingüística.
- Arquitectura de alto rendimientoEl codificador wav2vec 2.0 combinado con el decodificador CTC y Transformer permite un reconocimiento de voz de gran precisión y rendimiento.
- Código abierto y colaboraciónModelos y conjuntos de datos de código abierto para promover el trabajo conjunto de desarrolladores e investigadores de todo el mundo con el fin de hacer avanzar la tecnología de reconocimiento del habla y contribuir a la preservación de las lenguas en peligro de extinción.
Principales ventajas de la ASR omnilingüe
- Amplia cobertura lingüística: Admite más de 1.600 idiomas, incluido un gran número de lenguas de escasos recursos y en peligro de extinción, lo que mejora significativamente la cobertura lingüística global para el reconocimiento de voz.
- Capacidad de aprendizaje de muestra cero: Transcribir una lengua inédita con sólo unas pocas muestras de audio y texto reduce enormemente el coste de desarrollo de una nueva lengua.
- Arquitectura de alto rendimientoEl objetivo es lograr un reconocimiento del habla de alta precisión mediante un codificador wav2vec 2.0 de 7.000 millones de parámetros y un descodificador avanzado, combinados con el aprendizaje autosupervisado.
- Código abierto y apoyo comunitario: Fuente abierta de modelos y conjuntos de datos para facilitar la participación de desarrolladores e investigadores de todo el mundo con el fin de promover el desarrollo tecnológico y la preservación de las lenguas.
- Tecnología innovadora de mejora de datos: Resolver el problema de los datos lingüísticos dispersos de escasos recursos mediante técnicas como el habla sintética para mejorar la capacidad de generalización del modelo.
- Selección flexible del descodificador: Ofrece opciones de decodificador CTC y de transformador para satisfacer las necesidades de rendimiento y eficiencia de distintos escenarios.
¿Cuál es el sitio web oficial de Omnilingual ASR?
- Página web del proyecto:: https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/
- Repositorio GitHub:: https://github.com/facebookresearch/omnilingual-asr
- Biblioteca de modelos HuggingFace:: https://huggingface.co/datasets/facebook/omnilingual-asr-corpus
- Documentos técnicos:: https://ai.meta.com/research/publications/omnilingual-asr-open-source-multilingual-speech-recognition-for-1600-languages/
A quién va dirigido el ASR omnilingüe
- investigador lingüísticoEl objetivo es: estudiar las lenguas con pocos recursos y en peligro de extinción y contribuir a la preservación de las lenguas y a la investigación lingüística.
- Desarrollador tecnológico: Adecuado para el desarrollo de aplicaciones de reconocimiento de voz que aprovechan su naturaleza de código abierto para un desarrollo e integración secundarios.
- creador de contenidos: Facilita la producción de contenidos de audio y vídeo multilingües, permitiendo una rápida transcripción y generación de subtítulos.
- educador: Ayudar a desarrollar recursos educativos multilingües para apoyar la enseñanza de idiomas y la comunicación intercultural.
- usuario empresarial: Adecuado para empresas que requieren servicios de reconocimiento de voz multilingües, como atención al cliente, grabación de reuniones y otros escenarios.
- Organizaciones comunitarias y sin ánimo de lucroEl Fondo Europeo de Desarrollo (FED): Puede utilizarse para apoyar programas de diversidad lingüística y promover el intercambio cultural y la preservación de las lenguas.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...