
Molmo: una serie de modelos lingüísticos abiertos multimodales construidos por Ai2

Introducción general
Molmo es un modelo de lenguaje abierto multimodal desarrollado por el Allen Institute for AI (Ai2). El modelo combina capacidades de procesamiento de datos textuales y visuales para reconocer objetos en imágenes y generar descripciones precisas.Molmo obtiene buenos resultados en una serie de pruebas comparativas, lo que demuestra su potencia sobre todo en tareas complejas como la lectura de documentos y el razonamiento visual.Ai2 ha publicado estas en Hugging FaceModelos y conjuntos de datosy tiene previsto lanzar más modelos e informes técnicos ampliados en los próximos meses, con el objetivo de ofrecer más recursos a los investigadores, más información en Informe técnico.
La innovación clave de Molmo es el uso de un conjunto de datos de descripción de imágenes completamente nuevo, con modelos entrenados en PixMo, un conjunto de datos de un millón de pares imagen-texto altamente seleccionados. Estos conjuntos de datos fueron recopilados exclusivamente por anotadores humanos mediante descripciones de voz. Además, Molmo introduce una mezcla diversa de conjuntos de datos para su ajuste, incluidos los innovadores datos de señalización 2D que permiten a Molmo responder a preguntas utilizando no sólo el lenguaje natural, sino también señales no verbales.

Molmo se basa en Qwen2-72B y utiliza CLIP de OpenAI como columna vertebral visual para mejorar la capacidad del modelo para procesar imágenes y texto.
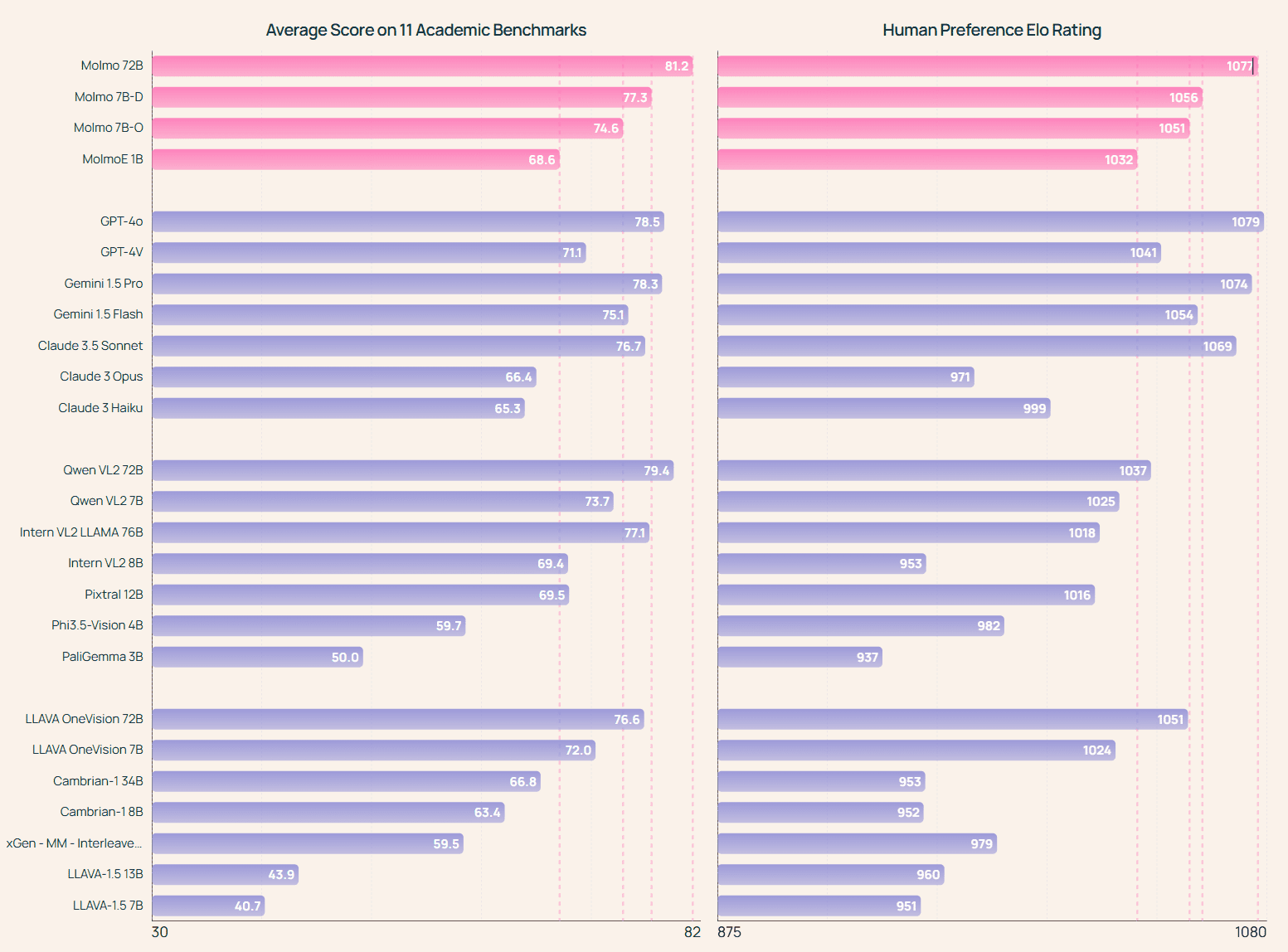
Molmo-72B: obtuvo la puntuación más alta en la prueba de referencia académica y ocupó el segundo lugar en la evaluación manual, sólo ligeramente por debajo de GPT-4o. También superó a varios sistemas propietarios de última generación, incluido el Géminis 1.5 Pro, Flash y Claude 3.5 Sonnet: MolmoE-1B: el modelo Molmo más eficiente, basado en nuestro LLM experto híbrido OLMoE-1B-7B totalmente abierto, que rinde casi tan bien como GPT-4V tanto en las pruebas académicas como en las evaluaciones manuales. Ambos modelos Molmo-7B: rinden entre GPT-4V y GPT-4o tanto en las pruebas académicas como en las evaluaciones manuales, y superan significativamente al modelo Pixtral 12B, recientemente publicado, en ambas pruebas.
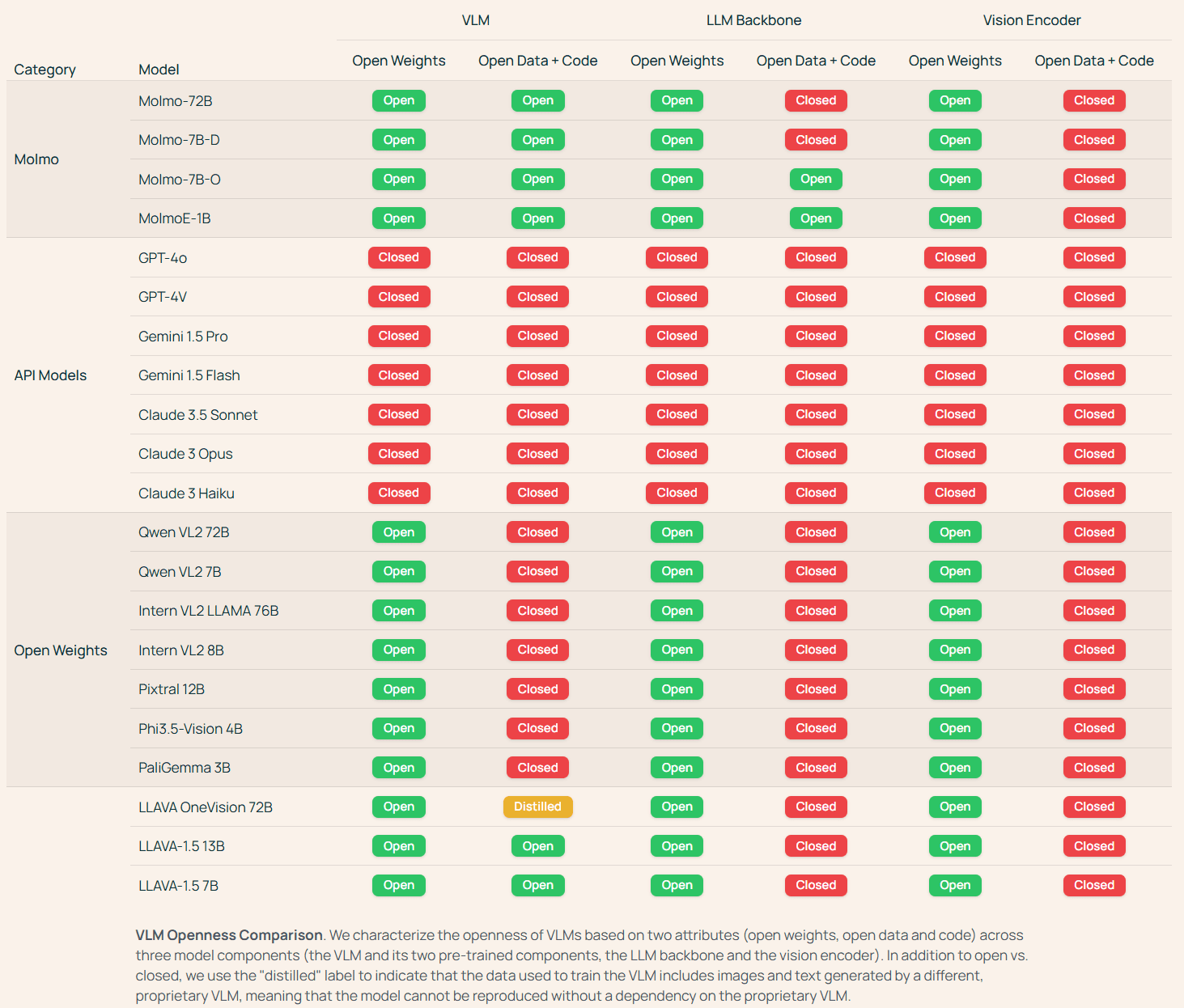
Abrir más pesos y modelos de datos
Lista de funciones
- Reconocimiento de imágenes: capacidad de reconocer objetos en una imagen y generar una descripción.
- Generación de texto: Genera descripciones de texto relevantes basadas en texto o imágenes de entrada.
- Procesamiento de datos multimodales: combinación de datos textuales y visuales para tareas complejas.
- Recursos de código abierto: los investigadores tienen a su disposición recursos de código abierto para modelos y conjuntos de datos.
- Demostración en línea: Ofrece una función de demostración en línea en la que los usuarios pueden cargar imágenes y generar descripciones.
Utilizar la ayuda
Normas de uso
- reconocimiento de imágenesHaga clic en el botón "Cargar imagen" de la página de inicio del sitio web y seleccione el archivo de imagen que desea reconocer. Una vez cargada, el sistema generará automáticamente una descripción de la imagen.
- Generación de textoIntroduzca el texto o la pregunta para la que desea generar una descripción en el cuadro de texto, pulse el botón "Generar" y el sistema generará la descripción de texto pertinente en función del contenido introducido.
- Tratamiento multimodal de datosLos usuarios pueden cargar tanto imágenes como texto, y el sistema combina ambos y genera una descripción completa.
- recurso de código abierto: Visite la plataforma Hugging Face para buscar modelos Molmo, descargar y utilizar los recursos de código abierto proporcionados.
- Demostración en líneaHaga clic en el botón "Demostración en línea" de la página de inicio del sitio web para acceder a la página de demostración. Los usuarios pueden cargar imágenes o introducir texto para experimentar las funciones de Molmo en tiempo real.
Función Flujo de operaciones
- reconocimiento de imágenes::
- Abra el sitio web de Molmo y haga clic en el botón "Cargar imagen".
- Seleccione el archivo de imagen que desea reconocer y haga clic en "Cargar".
- Espere a que el sistema procese y genere una descripción de la imagen.
- Ver y guardar la descripción generada.
- Generación de texto::
- En el cuadro de texto, introduzca el texto o la pregunta para la que desea generar una descripción.
- Pulse el botón "Generar" y espere a que el sistema lo procese.
- Vea la descripción de texto generada y edítela o guárdela según sea necesario.
- Tratamiento multimodal de datos::
- Sube la imagen y el texto al mismo tiempo y haz clic en el botón "Procesar".
- El sistema combina el tratamiento de imágenes y textos para generar una descripción exhaustiva.
- Visualice y guarde la descripción compuesta generada.
- Uso de recursos de código abierto::
- Visita la plataforma Hugging Face y busca los modelos Molmo.
- Descargue el modelo y el conjunto de datos, siga las instrucciones de instalación y uso.
- Utilice el código de ejemplo y la documentación proporcionada para el desarrollo secundario o la investigación.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Puestos relacionados

Sin comentarios...