MoBA: el gran modelo lingüístico de Kimi para el procesamiento de contextos largos
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 60.8K 00

Introducción general
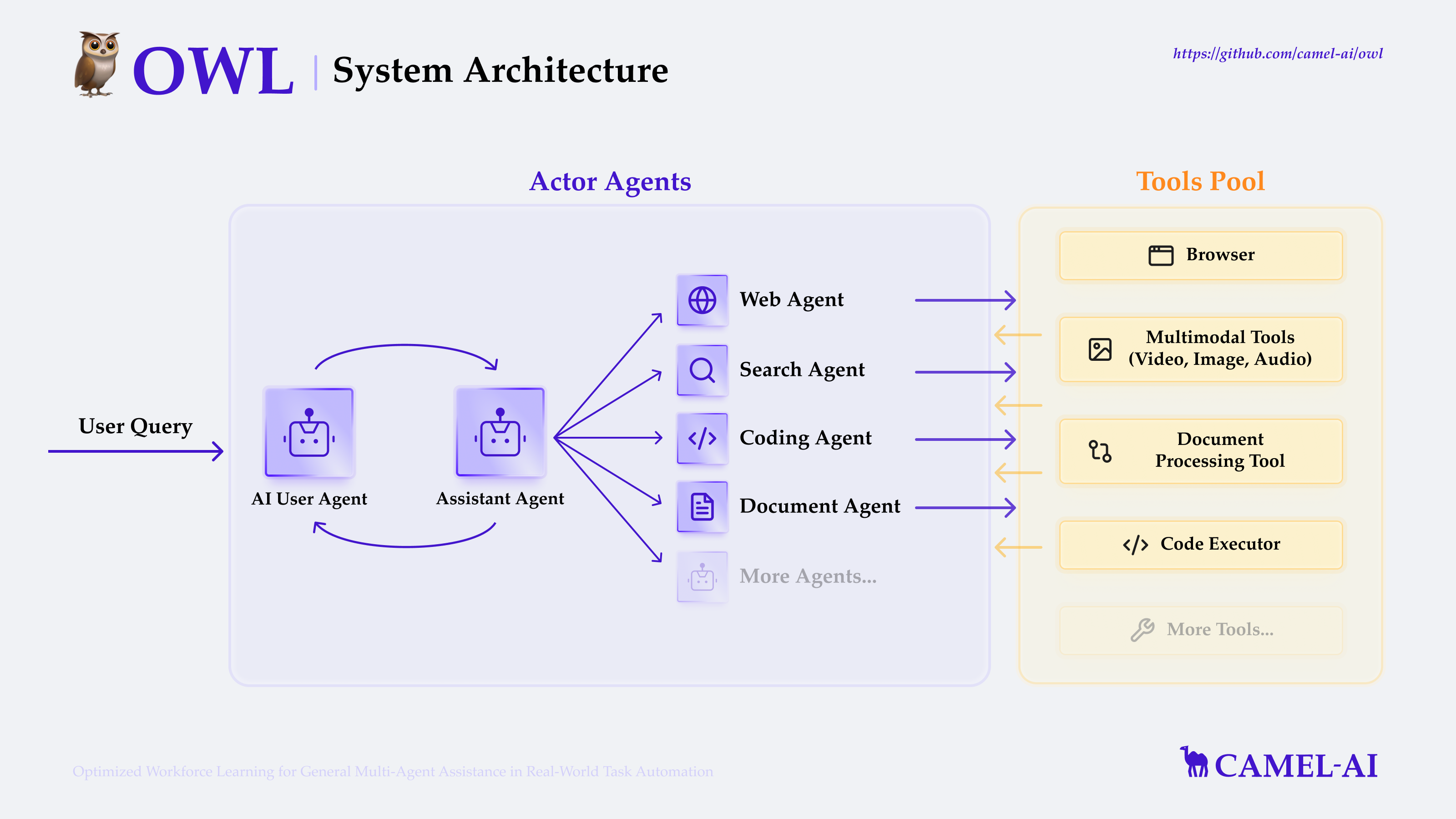
MoBA (Mixture of Block Attention) es un innovador mecanismo de atención desarrollado por MoonshotAI, diseñado para grandes modelos lingüísticos (LLM) con procesamiento de contextos largos. MoBA consigue un procesamiento eficiente de secuencias largas dividiendo el contexto completo en múltiples bloques, y cada token de consulta aprende a centrarse en los bloques KV más relevantes. Su mecanismo único de top-k gating sin parámetros garantiza que el modelo sólo se centre en los trozos más informativos, lo que mejora significativamente la eficiencia computacional.MoBA es capaz de cambiar sin problemas entre los modos de atención plena y atención dispersa, lo que garantiza tanto el rendimiento como la eficiencia. La técnica se ha aplicado con éxito a peticiones de contexto largas con Kimi, lo que demuestra avances significativos en el cálculo eficiente de la atención.

Lista de funciones
- Bloque Atención dispersaDividir el contexto completo en trozos y cada token de consulta aprende a centrarse en los trozos KV más relevantes.
- Mecanismo de activación sin parámetrosIntroducción de un mecanismo de top-k gating sin parámetros que selecciona el bloque más relevante para cada token de consulta.
- Conmutación de atención dispersa completa: Cambia sin problemas entre los modos de atención plena y atención dispersa.
- Informática eficienteMejora significativa de la eficiencia computacional en tareas de contexto largo.
- código abiertoSe proporciona el código fuente abierto completo para facilitar el uso y el desarrollo secundario.
Utilizar la ayuda
Proceso de instalación
- Crear un entorno virtual:
conda create -n moba python=3.10
conda activate moba
- Instale la dependencia:
pip install .
Inicio rápido
Proporcionamos una implementación de MoBA compatible con los transformadores. Los usuarios pueden utilizar el--attnEl parámetro selecciona el backend de atención entre moba y moba_naive.
python3 examples/llama.py --model meta-llama/Llama-3.1-8B --attn moba
Flujo detallado de funcionamiento de las funciones
- Bloque Atención dispersaEl método MoBA: cuando se trata de contextos largos, MoBA divide el contexto completo en múltiples trozos, y cada token de consulta aprende a centrarse en los trozos KV más relevantes, permitiendo así un procesamiento eficiente de secuencias largas.
- Mecanismo de activación sin parámetrosMoBA introduce un mecanismo top-k gating sin parámetros que selecciona el bloque más relevante para cada token de consulta, garantizando que el modelo se centre sólo en los bloques más informativos.
- Conmutación de atención dispersa completaMoBA está diseñado para ser una alternativa flexible a la atención plena, que permite cambiar sin problemas entre los modos de atención plena y atención dispersa, garantizando tanto el rendimiento como la eficiencia.
- Informática eficienteA través del mecanismo anterior, MoBA mejora significativamente la eficiencia computacional de las tareas de contexto largo para una variedad de tareas de razonamiento complejas.
código de ejemplo (informática)
A continuación se muestra un código de ejemplo que utiliza MoBA:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.1-8B", attn="moba")
inputs = tokenizer("长上下文示例文本", return_tensors="pt")
outputs = model(**inputs)
print(outputs)
Descripción en una frase (breve)
MoBA es un innovador mecanismo de atención en bloque diseñado para grandes modelos lingüísticos con procesamiento de contextos largos, que mejora significativamente la eficiencia computacional y admite el cambio de atención dispersa completa.
Palabras clave de la página
Procesamiento de contextos largos, mecanismo de atención en bloque, grandes modelos lingüísticos, computación eficiente, MoonshotAI
Introducción general
MoBA (Mixture of Block Attention) es un innovador mecanismo de atención desarrollado por MoonshotAI, diseñado para grandes modelos lingüísticos (LLM) con procesamiento de contextos largos. MoBA consigue un procesamiento eficiente de secuencias largas dividiendo el contexto completo en múltiples bloques, y cada token de consulta aprende a centrarse en los bloques KV más relevantes. Su mecanismo único de top-k gating sin parámetros garantiza que el modelo sólo se centre en los trozos más informativos, lo que mejora significativamente la eficiencia computacional.MoBA es capaz de cambiar sin problemas entre los modos de atención plena y atención dispersa, lo que garantiza tanto el rendimiento como la eficiencia. La técnica se ha aplicado con éxito a peticiones de contexto largas con Kimi, lo que demuestra avances significativos en el cálculo eficiente de la atención.
Lista de funciones
- Bloque Atención dispersaDividir el contexto completo en trozos y cada token de consulta aprende a centrarse en los trozos KV más relevantes.
- Mecanismo de activación sin parámetrosIntroducción de un mecanismo de top-k gating sin parámetros que selecciona el bloque más relevante para cada token de consulta.
- Conmutación de atención dispersa completa: Cambia sin problemas entre los modos de atención plena y atención dispersa.
- Informática eficienteMejora significativa de la eficiencia computacional en tareas de contexto largo.
- código abiertoSe proporciona el código fuente abierto completo para facilitar el uso y el desarrollo secundario.
Utilizar la ayuda
Proceso de instalación
- Crear un entorno virtual:
conda create -n moba python=3.10
conda activate moba
- Instale la dependencia:
pip install .
Inicio rápido
Proporcionamos una implementación de MoBA compatible con los transformadores. Los usuarios pueden utilizar el--attnEl parámetro selecciona el backend de atención entre moba y moba_naive.
python3 examples/llama.py --model meta-llama/Llama-3.1-8B --attn moba
Flujo detallado de funcionamiento de las funciones
- Bloque Atención dispersaEl método MoBA: cuando se trata de contextos largos, MoBA divide el contexto completo en múltiples trozos, y cada token de consulta aprende a centrarse en los trozos KV más relevantes, permitiendo así un procesamiento eficiente de secuencias largas.
- Mecanismo de activación sin parámetrosMoBA introduce un mecanismo top-k gating sin parámetros que selecciona el bloque más relevante para cada token de consulta, garantizando que el modelo se centre sólo en los bloques más informativos.
- Conmutación de atención dispersa completaMoBA está diseñado para ser una alternativa flexible a la atención plena, que permite cambiar sin problemas entre los modos de atención plena y atención dispersa, garantizando tanto el rendimiento como la eficiencia.
- Informática eficienteA través del mecanismo anterior, MoBA mejora significativamente la eficiencia computacional de las tareas de contexto largo para una variedad de tareas de razonamiento complejas.
código de ejemplo (informática)
A continuación se muestra un código de ejemplo que utiliza MoBA:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.1-8B", attn="moba")
inputs = tokenizer("长上下文示例文本", return_tensors="pt")
outputs = model(**inputs)
print(outputs)© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...