
MinerU2.5 - Modelo de análisis sintáctico de documentos de código abierto del Laboratorio de Inteligencia Artificial de Shanghai y la Universidad de Pekín
Últimos recursos sobre IAActualizado hace 6 meses Círculo de intercambio de inteligencia artificial 46.2K 00

¿Qué es MinerU2.5?
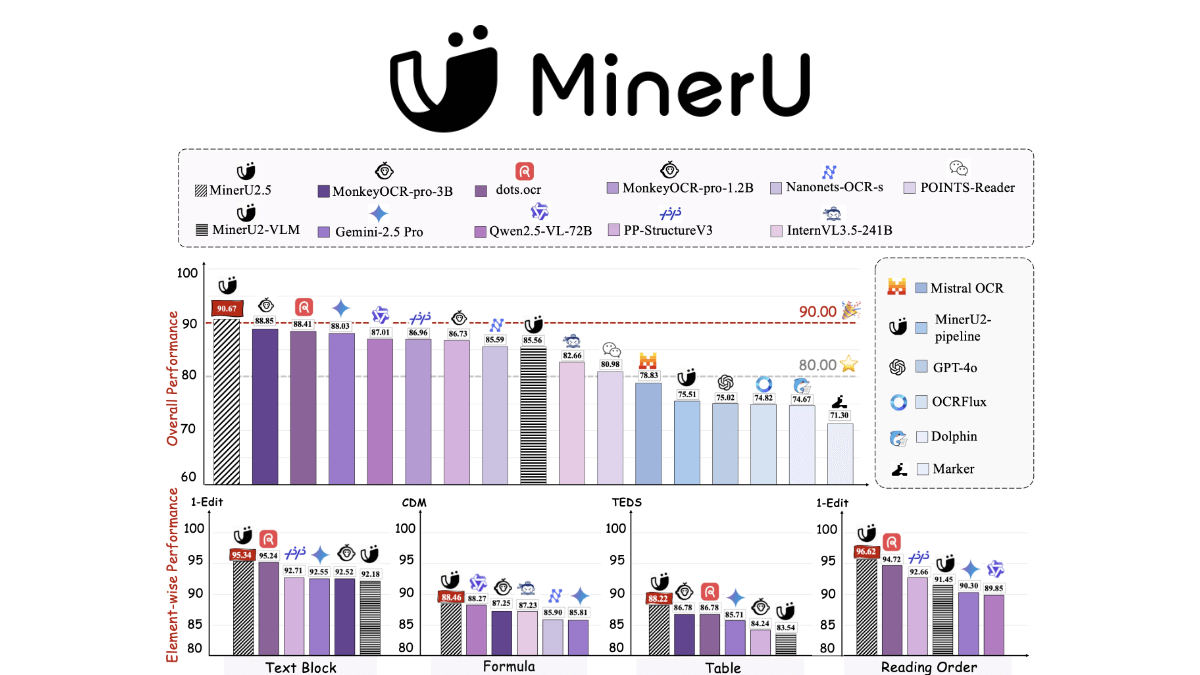
MinerU2.5 es un modelo de lenguaje visual desacoplado desarrollado conjuntamente por el Laboratorio de Inteligencia Artificial de Shanghái y el equipo de la Universidad de Pekín, centrado en el procesamiento eficiente del análisis sintáctico de imágenes de documentos de alta resolución. La principal innovación radica en el diseño en dos fases de la "detección del diseño global seguida del reconocimiento del contenido local": la primera fase localiza rápidamente la estructura del documento y el orden de lectura mediante miniaturas de baja resolución, y la segunda reconoce con precisión las áreas clave tras recortarlas a su resolución nativa. El modelo es de solo 1,2B pero puede mantener una alta precisión en documentos de 8K, y la velocidad de procesamiento medida con una sola tarjeta RTX 4090 es de hasta 2,12 páginas/segundo, lo que es significativamente mejor que otras soluciones similares. La singularidad también se refleja en la optimización especial de elementos complejos como tablas y fórmulas, como la compresión de la longitud de la secuencia HTML mediante el lenguaje intermedio OTSL, y la tecnología de descomposición y reorganización de fórmulas atómicas para resolver el problema de la ilusión de las estructuras de fórmulas largas.
Características de MinerU2.5
- Arquitectura eficiente de análisis sintáctico en dos fasesSe adopta la estrategia de desacoplamiento "primero lo grueso y luego lo fino": la primera etapa consiste en analizar el diseño global de la imagen de tamaño reducido para identificar rápidamente los bloques de texto, tablas, fórmulas y otros elementos estructurales del documento; la segunda etapa consiste en identificar el contenido de grano fino de la región de alta resolución sólo en la resolución nativa para equilibrar eficazmente la sobrecarga computacional con la retención de detalles.
- Precisión y rendimiento superioresAunque el número de parámetros es de sólo 1,2B, su precisión de análisis sintáctico global en varias pruebas de referencia autorizadas como OmniDocBench, olmOCR-bench, etc. supera a la del Géminis 2.5 Pro, GPT-4o, Qwen2.5-VL-72B y otros macromodelos multimodales de uso general de primer nivel, así como una ventaja significativa sobre herramientas profesionales de análisis sintáctico de documentos como dots.ocr y MonkeyOCR.
- Gran capacidad de adaptación a escenas complejasGracias a su arquitectura de fusión multimodal, integra en profundidad el reconocimiento de texto y el análisis de la disposición visual, y puede hacer frente con eficacia a situaciones en las que el OCR tradicional falla, como la ausencia de líneas de tabla, el texto sesgado y las fórmulas complejas. Su rendimiento es estable en condiciones extremas, como la disposición en varias columnas, la interferencia de ilustraciones, la distorsión difusa y los escaneados de baja resolución, y admite el reconocimiento de disposiciones mixtas en más de 20 idiomas, como chino, inglés, japonés y coreano.
- Despliegue extremadamente práctico y eficazEl modelo es pequeño, fácil de integrar y logra un análisis sintáctico de alta velocidad de 1,7 a 2 páginas por segundo en tarjetas gráficas de consumo como RTX 3090 o 4090, lo que lo hace ideal para implantaciones en el mundo real como la construcción de bases de conocimiento RAG (retrieval-enhanced generation) y la extracción de documentos a gran escala.
- Apoyo integral a las tareas con resultados estructuradosAnálisis del diseño: Reconstruye de forma innovadora el análisis del diseño en un problema multitarea que predice simultáneamente la posición, la categoría, el ángulo de rotación y el orden de lectura de los elementos del documento en una única inferencia. Admite la salida de resultados de análisis sintáctico a Markdown, JSON y otros formatos estructurados para su posterior procesamiento y aplicación.
Principales ventajas de MinerU 2.5
- Arquitectura avanzada de análisis sintáctico en dos fasesSe adopta la estrategia de desacoplamiento, en la que la primera etapa realiza un eficiente análisis global de la disposición en imágenes de tamaño reducido para identificar los elementos de la estructura del documento; la segunda etapa realiza un reconocimiento de contenido de grano fino en regiones de alta resolución a resolución nativa, equilibrando eficazmente la sobrecarga computacional y la retención de detalles.
- Excelente rendimientoEn OmniDocBench, olmOCR-bench y otras pruebas de referencia autorizadas, su precisión de análisis global supera ampliamente a la de los mejores modelos multimodales generales de gran tamaño, como Gemini 2.5 Pro, GPT-4o, Qwen2.5-VL-72B, etc., y también está significativamente por delante de herramientas profesionales de análisis sintáctico de documentos como dots.ocr, MonkeyOCR, PP- StructureV3 y otras herramientas profesionales de análisis sintáctico de documentos.
- Paradigma multitarea mejoradoEl análisis del diseño se ha redefinido como un problema multitarea que permite predecir simultáneamente la posición, la categoría, el ángulo de rotación y el orden de lectura de los elementos de un documento en una única inferencia, lo que resuelve con eficacia problemas complejos como el análisis sintáctico de elementos rotados.
- Extremadamente práctico y eficazEl modelo es pequeño, fácil de integrar y puede alcanzar una alta velocidad de análisis de 1,7 páginas por segundo en tarjetas gráficas de consumo, lo que resulta ideal para escenarios de aplicación práctica como la construcción de bases de conocimiento RAG (Retrieval Augmented Generation), la extracción de documentos a gran escala, etc.
¿Cuál es la web oficial de MinerU2.5?
- Biblioteca de modelos HuggingFace:: https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B
- Documento técnico arXiv:: https://arxiv.org/pdf/2509.22186
Personas a las que va dirigido MinerU2.5
- Equipo de Digitalización Empresarial y Gestión del ConocimientoEs adecuado para empresas que tienen que hacer frente a la tarea de digitalizar un gran número de contratos, informes, archivos y otros documentos en papel, y puede completar eficazmente el análisis sintáctico de documentos escaneados, PDF y otros datos no estructurados en la biblioteca, y mejorar significativamente la eficiencia de la construcción de la base de conocimientos RAG (Retrieval Augmented Generation).
- Desarrolladores y equipos de ingeniería de IAEl modelo es totalmente de código abierto y tiene un tamaño de referencia pequeño (1,2B), admite la implementación en tarjetas gráficas de consumo (por ejemplo, RTX 4090), y es ideal para desarrolladores y equipos de ingeniería que buscan integrar funciones de OCR de alto rendimiento en sus productos sin depender de una API grande y de código cerrado.
- Institutos de investigación y universidadesProporciona un potente modelo de referencia de código abierto para la investigación académica en las áreas de comprensión de documentos, macromodelado multimodal, etc., en el que los investigadores pueden basar otros experimentos, ajustes o comparaciones de métodos.
- Instituciones financieras, jurídicas y gubernamentalesMinerU2.5 satisface los estrictos requisitos de extracción de información estructurada de alta precisión destacando en escenarios con tipografía compleja y líneas de formulario ausentes, en los que es necesario manejar un gran número de formularios, contratos y formularios de estructura compleja.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...