LLaVA-OneVision-1.5 - Modelo multimodal gratuito y de código abierto para una comprensión multimodal de alto rendimiento
Últimos recursos sobre IAPublicado hace 6 meses Círculo de intercambio de inteligencia artificial 31.4K 00

¿Qué es LLaVA-OneVision-1.5?
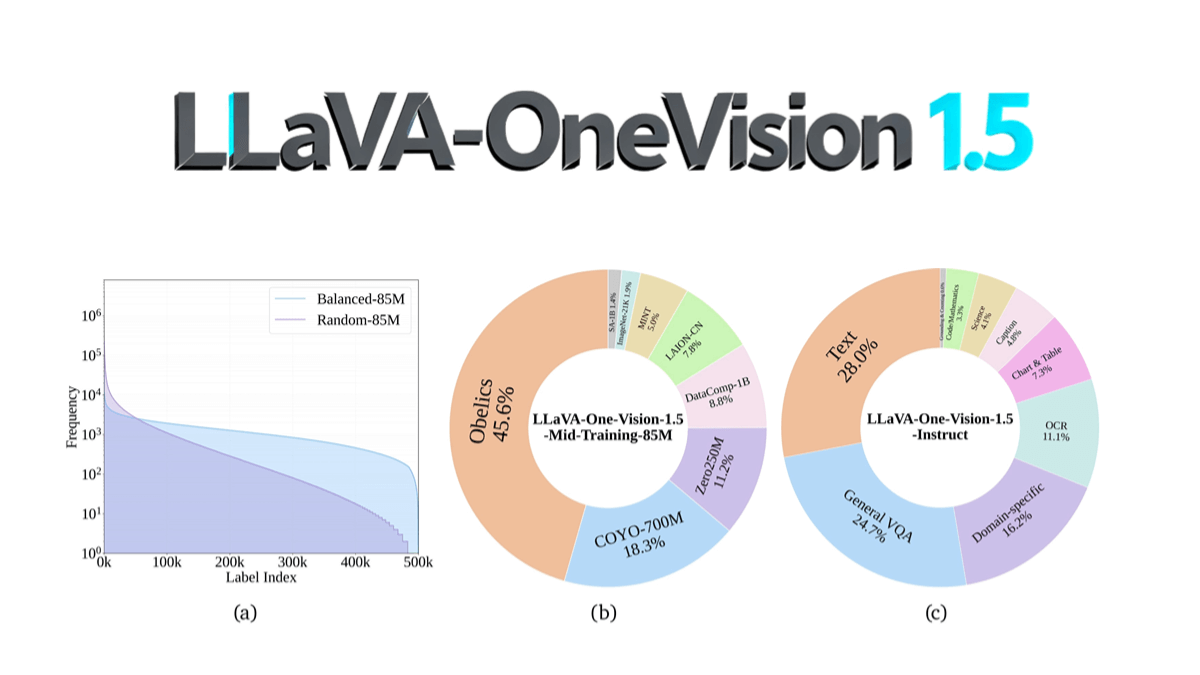
LLaVA-OneVision-1.5 es un modelo multimodal de código abierto del equipo EvolvingLMMS-Lab que se preentrenó en 4 días en 128 GPUs A800 con un coste total de ~US$16.000 utilizando una escala de parámetros de 8B a través de un proceso de entrenamiento compacto en tres fases (alineación lenguaje-imagen, ecualización conceptual e inyección de conocimiento, y ajuste fino de instrucciones). Entre sus principales innovaciones, el codificador visual RICE-ViT admite la resolución nativa y el modelado semántico de grano fino a nivel de región, así como la utilización optimizada de datos mediante una estrategia de "equilibrio de conceptos". Supera a Qwen2.5-VL en OCR, comprensión de documentos y otras tareas, y por primera vez consigue un código abierto completo (incluidos datos, cadena de herramientas de formación y scripts de evaluación), lo que reduce significativamente el umbral para la reproducción de modelos multimodales. El código del modelo se ha publicado en GitHub, lo que permite la reproducción a bajo coste y el desarrollo secundario por parte de la comunidad.
Características de LLaVA-OneVision-1.5
- Comprensión multimodal de alto rendimiento: Procesa y comprende eficazmente la información de imágenes y textos para generar descripciones y respuestas precisas para una amplia gama de situaciones complejas.
- Formación eficaz y bajo coste: Uso de estrategias de formación optimizadas y técnicas de empaquetado de datos para reducir significativamente los costes de formación manteniendo un alto rendimiento.
- Cumplimiento estricto de las normas: Puede comprender y ejecutar con precisión las órdenes del usuario, tiene una buena capacidad de generalización de tareas y puede aplicarse a una amplia gama de tareas multimodales.
- Datos de alta calidadAsegurarse de que el modelo adquiere una gran cantidad de conocimientos e información semántica mediante conjuntos de datos de preentrenamiento y perfeccionamiento de instrucciones cuidadosamente elaborados.
- Resolución de entrada flexibleEl codificador de visión admite una resolución de entrada variable, lo que elimina la necesidad de un ajuste fino específico de la resolución y se adapta a diferentes requisitos de tamaño de imagen.
- Mecanismos regionales de atención perceptiva: Mejora de la comprensión semántica de las regiones locales de una imagen mediante un mecanismo de atención consciente de la región para mejorar la capacidad del modelo de captar detalles.
- Soporte multilingüeSoporta entrada y salida multilingüe, con capacidades de comprensión y generación en varios idiomas, para adaptarse a las necesidades de las aplicaciones internacionalizadas.
- Marco transparente y abiertoProporcionar un recurso completo de código, datos y modelos para garantizar la reproducción a bajo coste y extensiones verificables para la comunidad, facilitando las aplicaciones académicas e industriales.
- capacidad para identificar la larga colaTambién es posible identificar y comprender eficazmente las categorías o conceptos que aparecen con menos frecuencia en los datos, lo que mejora la capacidad de generalización del modelo.
- Función de búsqueda multimodal: Admite texto de consulta basado en imágenes o texto de consulta basado en imágenes para lograr una recuperación de información intermodal eficaz.
Principales ventajas de LLaVA-OneVision-1.5
- alto rendimiento: Se desempeña bien en tareas multimodales, procesando eficazmente información de imagen y texto para producir resultados de alta calidad.
- barato: Reduce significativamente los costes de formación y mejora la rentabilidad mediante estrategias de formación optimizadas y técnicas de empaquetado de datos.
- altamente reproducibleEl suministro de código completo, datos y guiones de entrenamiento garantiza que la comunidad pueda reproducir y validar el rendimiento del modelo a bajo coste.
- Formación eficazEl empaquetamiento paralelo de datos fuera de línea y las técnicas paralelas híbridas se utilizan para mejorar la eficiencia del entrenamiento y reducir el desperdicio de recursos computacionales.
- Datos de alta calidadSe construye un conjunto de datos de preentrenamiento y ajuste de instrucciones a gran escala y de alta calidad para garantizar que el modelo aprenda información semántica rica.
- Soporte de entrada flexibleEl codificador de visión admite una resolución de entrada variable, lo que elimina la necesidad de un ajuste fino específico de la resolución y se adapta a diferentes requisitos de tamaño de imagen.
- Conocimiento de la zonaEnhanced semantic understanding of local regions in an image and improved detail capture through region-aware attention mechanism.
¿Cuál es la web oficial de LLaVA-OneVision-1.5?
- Dirección de Github:: https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
- Biblioteca de modelos HuggingFace:: https://huggingface.co/collections/lmms-lab/llava-onevision-15-68d385fe73b50bd22de23713
- Documento técnico arXiv:: https://arxiv.org/pdf/2509.23661
- Demostración de la experiencia en línea:: https://huggingface.co/spaces/lmms-lab/LLaVA-OneVision-1.5
Personas para las que LLaVA-OneVision-1.5 es adecuado
- investigadorLos investigadores que trabajan en aprendizaje multimodal, visión por ordenador y procesamiento del lenguaje natural pueden utilizar los modelos para la investigación de vanguardia y el desarrollo de algoritmos.
- desarrolladoresLos ingenieros de software y desarrolladores de aplicaciones pueden integrar LLaVA-OneVision-1.5 en diversas aplicaciones para desarrollar servicios inteligentes de atención al cliente, recomendaciones de contenidos, etc.
- educador: Profesores y tecnólogos educativos, que pueden utilizarlo en la enseñanza para ayudar a la enseñanza y el aprendizaje, como la interpretación de imágenes y la creación de contenidos multimedia.
- Profesionales médicosEl sistema de diagnóstico por imagen: médicos e investigadores médicos, puede utilizarse para el análisis de imágenes médicas y el diagnóstico asistido con el fin de mejorar la eficacia y la precisión médicas.
- creador de contenidosEl modelo sirve a escritores, diseñadores y productores de medios para generar contenidos creativos, textos y descripciones de imágenes con el fin de mejorar la eficacia creativa.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...