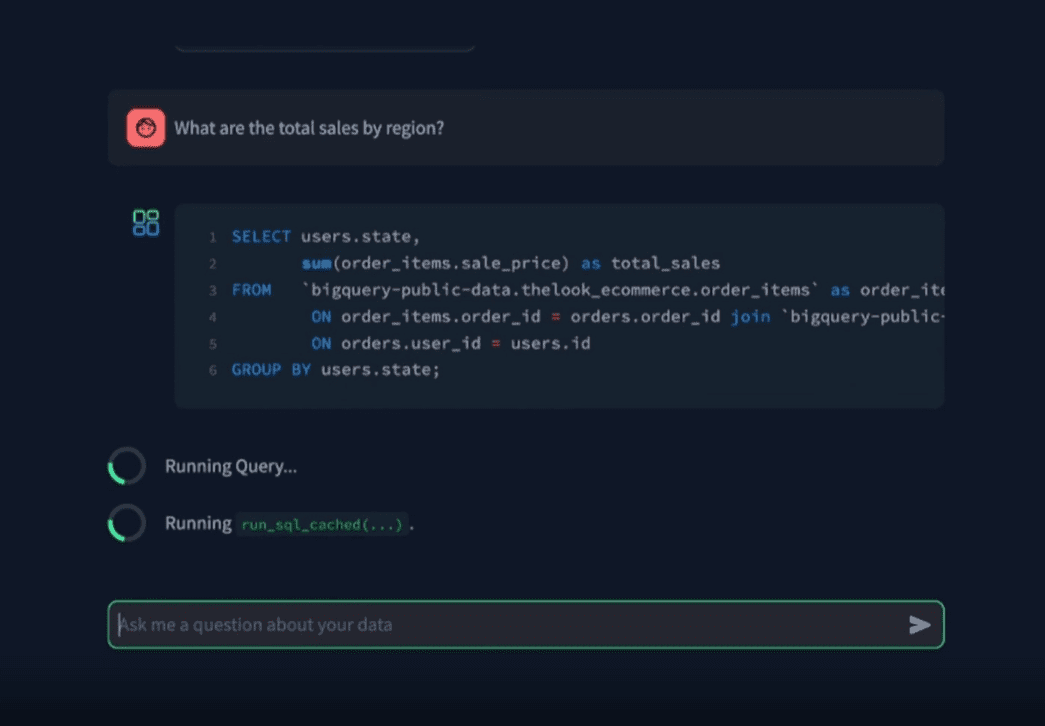
LlamaEdge: ¡la forma más rápida de ejecutar y ajustar LLM localmente!
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 67.3K 00

Introducción general
LlamaEdge es un proyecto de código abierto diseñado para simplificar el proceso de ejecución y ajuste de grandes modelos lingüísticos (LLM) en dispositivos locales o periféricos. El proyecto es compatible con la familia de modelos Llama2 y proporciona servicios de API compatibles con OpenAI que permiten a los usuarios crear y ejecutar fácilmente aplicaciones de razonamiento LLM.LlamaEdge aprovecha las pilas tecnológicas Rust y Wasm para ofrecer potentes alternativas para el razonamiento de IA. Los usuarios pueden poner en marcha modelos rápidamente con sencillas operaciones de línea de comandos y pueden ajustarlos y ampliarlos según sea necesario.
Lista de funciones
- Ejecutar LLM localmente: Soporte para ejecutar modelos de la serie Llama2 en dispositivos locales o edge.
- Servicios API compatibles con OpenAI: Proporciona puntos finales de servicio compatibles con la API OpenAI que admiten chat, conversión de voz a texto, conversión de texto a voz, generación de imágenes, etc.
- Soporte multiplataforma: Admite una amplia gama de dispositivos CPU y GPU y proporciona aplicaciones Wasm multiplataforma.
- inicio rápidoLos modelos pueden descargarse y ejecutarse rápidamente mediante sencillas operaciones de línea de comandos.
- Ajuste y ampliaciónLos usuarios pueden modificar y ampliar el código fuente según sus necesidades específicas.
- Documentación y tutoriales: Se proporciona documentación oficial detallada y tutoriales para ayudar a los usuarios a empezar rápidamente.
Utilizar la ayuda
Proceso de instalación
- Instalación de WasmEdgeEn primer lugar, debe instalar WasmEdge, lo que puede hacerse mediante la siguiente línea de comandos:
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash
- Descargar archivos de modelos LLM: Tome como ejemplo el modelo Meta Llama 3.2 1B y descárguelo utilizando el siguiente comando:
curl -LO https://huggingface.co/second-state/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q5_K_M.gguf
- Descargar LlamaEdge CLI Chat AppDescarga la aplicación multiplataforma Wasm: Utiliza el siguiente comando para descargar la aplicación multiplataforma Wasm:
curl -LO https://github.com/second-state/LlamaEdge/releases/latest/download/llama-chat.wasm
- Ejecutar la aplicación de chat: Utiliza el siguiente comando para chatear con LLM:
wasmedge --dir .:. --nn-preload default:GGML:AUTO:Llama-3.2-1B-Instruct-Q5_K_M.gguf llama-chat.wasm -p llama-3-chat
Función Flujo de operaciones
- Iniciar el servicio APIEl servicio API puede iniciarse con el siguiente comando:
wasmedge --dir .:. --env API_KEY=your_api_key llama-api-server.wasm --model-name llama-3.2-1B --prompt-template llama-chat --reverse-prompt "[INST]" --ctx-size 32000
- Interactuar con LLM mediante la interfaz webDespués de iniciar el servicio API, puede interactuar con el LLM local a través de la interfaz web.
- Creación de servicios API personalizadosPuntos finales de servicio API personalizados: se pueden crear puntos finales de servicio API personalizados según sea necesario, como voz a texto, texto a voz, generación de imágenes, etc.
- Ajuste y ampliaciónLos usuarios pueden modificar los archivos de configuración y los parámetros del código fuente para cumplir requisitos funcionales específicos.
LlamaEdge Destilación rápida en un portátil DeepSeek-R1
DeepSeek-R1 es un modelo de IA potente y versátil que desafía a actores establecidos como OpenAI con sus avanzadas capacidades de inferencia, rentabilidad y disponibilidad de código abierto. Aunque tiene algunas limitaciones, su enfoque innovador y su sólido rendimiento lo convierten en una herramienta inestimable para desarrolladores, investigadores y empresas. Para los interesados en explorar sus capacidades, el modelo y su versión lite están disponibles en plataformas como Hugging Face y GitHub.
Entrenado por un equipo chino con limitaciones de GPU, destaca en matemáticas, codificación e incluso en razonamiento bastante complejo. Lo más interesante es que se trata de un modelo "lite", es decir, más pequeño y eficiente que el modelo gigante en el que se basa. Esto es importante porque lo hace más práctico para que la gente lo use y lo construya.

En este artículo presentaremos
- Cómo ejecutar código abierto en su propio dispositivo DeepSeek modelización
- Cómo crear servicios API compatibles con OpenAI con los últimos modelos de DeepSeek
Utilizaremos LlamaEdge (Rust + Wasm technology stack) para desarrollar y desplegar aplicaciones para este modelo. ¡Sin necesidad de instalar complejos paquetes Python o cadenas de herramientas C++! Descubra por qué hemos elegido esta tecnología.
Ejecute el modelo DeepSeek-R1-Distill-Llama-8B en su propio equipo.
Paso 1: Instale WasmEge a través de la siguiente línea de comandos.
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash -s -- -v 0.14.1
Paso 2: Descargar el archivo del modelo cuantificado DeepSeek-R1-Distill-Llama-8B-GGUF.
Esto puede llevar algún tiempo, ya que el tamaño del modelo es de 5,73 GB.
curl -LO https://huggingface.co/second-state/DeepSeek-R1-Distill-Llama-8B-GGUF/resolve/main/DeepSeek-R1-Distill-Llama-8B-Q5_K_M.gguf`
Paso 3: Descargue la aplicación del servidor API de LlamaEdge.
También es una aplicación Wasm multiplataforma y portátil que funciona en muchos dispositivos con CPU y GPU.
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm
Paso 4: Descargar la interfaz de usuario del chatbot
para interactuar con el modelo DeepSeek-R1-Distill-Llama-8B en un navegador.
curl -LO https://github.com/LlamaEdge/chatbot-ui/releases/latest/download/chatbot-ui.tar.gz tar xzf chatbot-ui.tar.gz rm chatbot-ui.tar.gz
A continuación, inicie el servidor API LlamaEdge utilizando el siguiente modelo de comportamiento de comandos.
wasmedge --dir .:. --nn-preload default:GGML:AUTO:DeepSeek-R1-Distill-Llama-8B-Q5_K_M.gguf \ llama-api-server.wasm \ --prompt-template llama-3-chat \ --ctx-size 8096
A continuación, abre tu navegador y visita http://localhost:8080 para empezar a chatear. O puedes enviar una solicitud API al modelo.
curl -X POST http://localhost:8080/v1/chat/completions \
-H 'accept:application/json' \
-H 'Content-Type: application/json' \
-d '{"messages":[{"role":"system", "content": "You are a helpful assistant."}, {"role":"user", "content": "What is the capital of France?"}], "model": "DeepSeek-R1-Distill-Llama-8B"}'
{"id":"chatcmpl-68158f69-8577-4da2-a24b-ae8614f88fea","object":"chat.completion","created":1737533170,"model":"default","choices":[{"index":0,"message":{"content":"The capital of France is Paris.\n</think>\n\nThe capital of France is Paris.<|end▁of▁sentence|>","role":"assistant"},"finish_reason":"stop","logprobs":null}],"usage":{"prompt_tokens":34,"completion_tokens":18,"total_tokens":52}}
Creación de servicios API compatibles con OpenAI para DeepSeek-R1-Distill-Llama-8B
LlamaEdge es ligero y no requiere ningún demonio o proceso sudo para ejecutarse. ¡Se puede incrustar fácilmente en sus propias aplicaciones! Con soporte para chat e incrustación de modelos, ¡LlamaEdge puede ser una alternativa a la API OpenAI dentro de aplicaciones en tu máquina local!
A continuación, mostraremos cómo añadir una nueva función al módulo DeepSeek-R1 y el modelo de incrustación para iniciar el servidor API completo. el servidor API tendrá el modelo chat/completions responder cantando embeddings Puntos finales. Además de los pasos de la sección anterior, necesitamos:
Paso 5: Descargar el modelo de incrustación.
curl -LO https://huggingface.co/second-state/Nomic-embed-text-v1.5-Embedding-GGUF/resolve/main/nomic-embed-text-v1.5.f16.gguf
A continuación, podemos iniciar el servidor API LlamaEdge con los modelos de chat e incrustación utilizando la siguiente línea de comandos. Para obtener instrucciones más detalladas, consulte la documentación - Iniciar el servicio API de LlamaEdge.
wasmedge --dir .:. \ --nn-preload default:GGML:AUTO:DeepSeek-R1-Distill-Llama-8B-Q5_K_M.gguf \ --nn-preload embedding:GGML:AUTO:nomic-embed-text-v1.5.f16.gguf \ llama-api-server.wasm -p llama-3-chat,embedding \ --model-name DeepSeek-R1-Distill-Llama-8B,nomic-embed-text-v1.5.f16 \ --ctx-size 8192,8192 \ --batch-size 128,8192 \ --log-prompts --log-stat
Por último, puede seguir estos tutoriales para integrar el servidor API LlamaEdge con otros frameworks de Agente como reemplazo de OpenAI. En concreto, sustituya la API de OpenAI por los siguientes valores en la configuración de su aplicación o Agente.
| Opción de configuración | (valer) la pena |
|---|---|
| URL de la API base | http://localhost:8080/v1 |
| Nombre del modelo (modelo grande) | DeepSeek-R1-Distill-Llama-8B |
| Nombre del modelo (texto incrustado) | nomic-embed |
¡Ya está! Visita el repositorio de LlamaEdge ahora y construye tu primer Agente de IA. Si lo encuentras interesante, por favor, visita nuestro repositorio aquí. Si tienes alguna pregunta sobre el funcionamiento de este modelo, por favor, dirígete al repositorio para hacer preguntas o reservar una demo con nosotros para ejecutar tu propio LLM a través de dispositivos.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...