
Llama 3: una familia de modelos de IA versátil y de código abierto

Resúmenes.
Este artículo presenta un nuevo conjunto de modelos base denominado Llama 3. Llama 3 es una comunidad de modelos lingüísticos que soporta de forma inherente el multilingüismo, la escritura de código, el razonamiento y el uso de herramientas. Nuestro modelo más grande es un transformador denso con 405.000 millones de parámetros y una ventana de contexto de hasta 128.000 tokens. Los resultados muestran que Llama 3 alcanza una calidad comparable a la de los principales modelos lingüísticos, como GPT-4, en muchas tareas. Ponemos a disposición del público Llama 3, que incluye modelos lingüísticos preentrenados y postentrenados de 405.000 millones de parámetros, así como el modelo Llama Guard 3 para la seguridad de entrada-salida. Este artículo también presenta resultados experimentales sobre la integración de características de imagen, vídeo y habla en Llama 3 mediante un enfoque combinatorio. Observamos que este enfoque es competitivo con los enfoques más avanzados para tareas de reconocimiento de imagen, vídeo y habla. Dado que estos modelos están aún en fase de desarrollo, no han sido ampliamente publicados.
Texto completo descargar pdf:
1722344341-Llama_3.1 paper: a versatile, open-source _AI_ model family (versión en chino)
1 Introducción
modelo básicoson modelos generales del lenguaje, la visión, el habla y otras modalidades diseñados para dar soporte a una amplia gama de tareas de IA. Constituyen la base de muchos sistemas modernos de IA.
El desarrollo de un modelo básico moderno se divide en dos etapas principales:
(1) Fase de preentrenamiento. Los modelos se entrenan con cantidades ingentes de datos, mediante tareas sencillas como la predicción de palabras o la generación de anotaciones gráficas;
(2) Fase posterior a la formación. Los modelos se afinan para seguir instrucciones, ajustarse a las preferencias humanas y mejorar capacidades específicas (por ejemplo, codificación y razonamiento).
Este artículo presenta un nuevo conjunto de modelos de base lingüística denominado Llama 3. La familia de modelos Llama 3 Herd soporta intrínsecamente el multilingüismo, la codificación, el razonamiento y el uso de herramientas. Nuestro modelo más grande es un Transformador denso con 405B parámetros, capaz de procesar información en ventanas de contexto de hasta 128K tokens.
En la Tabla 1 se enumeran todos los miembros del rebaño. Todos los resultados presentados en este documento se basan en el modelo Llama 3.1 (Llama 3 para abreviar).
Creemos que las tres herramientas clave para desarrollar modelos base de alta calidad son los datos, la escala y la gestión de la complejidad. Nos esforzaremos por optimizar estas tres áreas durante nuestro proceso de desarrollo:
- Datos. Tanto la cantidad como la calidad de los datos que utilizamos en el preentrenamiento y el postentrenamiento mejoraron en comparación con las versiones anteriores de Llama (Touvron et al., 2023a, b). Estas mejoras incluyen el desarrollo de tuberías de preprocesamiento y curación más cuidadosas para los datos de preentrenamiento y el desarrollo de una garantía de calidad y un filtrado más rigurosos. de un preprocesamiento y una curación más cuidadosos de los datos de preentrenamiento y el desarrollo de una garantía de calidad y un filtrado más rigurosos. Llama 3 se preentrenó con un corpus de aproximadamente 15T de tokens multilingües, mientras que Llama 2 se preentrenó con 1,8T de tokens.
- Alcance. Hemos entrenado un modelo mayor que el anterior de Llama: nuestro modelo lingüístico estrella utiliza 3,8 × 1025 FLOPs para el preentrenamiento, casi 50 veces más que la versión más grande de Llama 2. En concreto, preentrenamos un modelo insignia con 405B parámetros entrenables en 15,6T tokens de texto. Como era de esperar, el

- Gestión de la complejidad. Las opciones de diseño que elegimos tenían por objeto maximizar la escalabilidad del proceso de desarrollo de modelos. Por ejemplo, elegimos un Transformador (Vaswani et al., 2017) con algunos ajustes menores, en lugar de utilizar un modelo de mezcla experto (Shazeer et al., 2017) para maximizar la estabilidad del entrenamiento. Del mismo modo, empleamos un posprocesador relativamente sencillo basado en el ajuste fino supervisado (SFT), el muestreo de rechazo (RS) y la optimización directa de preferencias (DPO; Rafailov et al. (2023)), en lugar de algoritmos de aprendizaje de refuerzo más complejos (Ouyang et al., 2022; Schulman et al., 2017), que suelen ser menos estables y difíciles de escalar.
El resultado de nuestro trabajo es Llama 3: un multilingüe trilingüe con parámetros 8B, 70B y 405B.1de modelos lingüísticos. Hemos evaluado el rendimiento de Llama 3 en un gran número de conjuntos de datos de referencia que cubren una amplia gama de tareas de comprensión del lenguaje. Además, realizamos extensas evaluaciones manuales comparando Llama 3 con modelos de la competencia. La Tabla 2 muestra un resumen del rendimiento del modelo insignia Llama 3 en pruebas de referencia clave. Nuestras evaluaciones experimentales muestran que nuestro modelo insignia está a la par con los principales modelos lingüísticos como GPT-4 (OpenAI, 2023a) y cerca del estado de la técnica en una variedad de tareas. Nuestro modelo más pequeño es el mejor de su clase y supera a otros modelos con un número similar de parámetros (Bai et al., 2023; Jiang et al., 2023).Llama 3 también logra un mejor equilibrio entre utilidad e inocuidad que su predecesor (Touvron et al., 2023b). Analizamos la seguridad de Llama 3 en detalle en la sección 5.4.
Estamos publicando los tres modelos de Llama 3 bajo una versión actualizada de la Licencia Comunitaria de Llama 3; véase https://llama.meta.com. Esto incluye versiones pre-entrenadas y post-procesadas de nuestro modelo paramétrico de lenguaje 405B, así como una nueva versión del modelo Llama Guard (Inan et al., 2023) para la seguridad de entrada y salida. de entrada y salida. Esperamos que el lanzamiento público de un modelo emblemático inspire una ola de innovación en la comunidad investigadora y acelere el progreso hacia el desarrollo responsable de la Inteligencia Artificial (AGI).
Multilingüe: se refiere a la capacidad del modelo para comprender y generar texto en varios idiomas.
Durante el desarrollo de Llama 3, también hemos desarrollado extensiones multimodales del modelo para permitir el reconocimiento de imágenes, el reconocimiento de vídeo y la comprensión del habla. Estos modelos siguen en desarrollo y aún no están listos para su publicación. Además de los resultados de nuestro modelo lingüístico, este artículo presenta los resultados de nuestros experimentos iniciales con estos modelos multimodales.
Llama 3 8B y 70B se preentrenaron con datos multilingües, pero en aquel momento se utilizaban principalmente para el inglés.

2 Generalidades
La arquitectura del modelo Llama 3 se muestra en la Figura 1. El desarrollo de nuestro modelo lingüístico Llama 3 se divide en dos fases principales:
- Preformación del modelo lingüístico.En primer lugar, convertimos un gran corpus de texto multilingüe en tokens discretos y preentrenamos un Modelo de Gran Lenguaje (LLM) en los datos resultantes para la siguiente predicción de tokens. En la fase de preentrenamiento del LLM, el modelo aprende la estructura de la lengua y adquiere una gran cantidad de conocimientos sobre el mundo a partir del texto que "lee". Para hacerlo de forma eficiente, el preentrenamiento se realiza a escala: preentrenamos un modelo con 405B parámetros en un modelo con 15,6T tokens, utilizando una ventana de contexto de 8K tokens. A esta fase de preentrenamiento estándar le sigue una fase de preentrenamiento continuado, que aumenta la ventana de contexto admitida a 128.000 tokens. Para más información, véase la sección 3.
- Formación postmodelo.El modelo lingüístico preentrenado tiene un conocimiento profundo de la lengua, pero aún no ha seguido instrucciones ni se ha comportado como el asistente que esperamos que lo haga. Calibramos el modelo mediante comentarios humanos en varias rondas, cada una de las cuales incluía el ajuste fino supervisado (SFT) y la optimización directa de preferencias (DPO; Rafailov et al., 2024) sobre datos ajustados a las instrucciones. En esta fase de post-entrenamiento, también integramos nuevas características, como el uso de herramientas, y observamos mejoras significativas en áreas como la codificación y la inferencia. Para más información, véase la sección 4. Por último, en la fase de post-entrenamiento también se integran mitigaciones de seguridad en el modelo, cuyos detalles se describen en la Sección 5.4. Los modelos generados son muy funcionales. Son capaces de responder a preguntas en al menos ocho lenguajes, escribir código de alta calidad, resolver problemas de inferencia complejos y utilizar herramientas listas para usar o de forma cero-muestra.
También realizamos experimentos para añadir capacidades de imagen, vídeo y voz a Llama 3 mediante un enfoque combinado. El enfoque que investigamos consta de tres fases adicionales que se muestran en la Figura 28:

- Preentrenamiento del codificador multimodal.Entrenamos codificadores distintos para la imagen y el habla. Entrenamos el codificador de imágenes con un gran número de pares imagen-texto. Esto permite al modelo aprender la relación entre el contenido visual y su descripción en lenguaje natural. Nuestro codificador de voz utiliza un método autosupervisado que enmascara una parte de la entrada de voz e intenta reconstruir la parte enmascarada mediante una representación discreta de marcadores. Así, el modelo aprende la estructura de la señal del habla. Para más información sobre los codificadores de imagen, véase la sección 7; para más información sobre los codificadores de voz, véase la sección 8.
- Formación de adaptadores visuales.Entrenamos un adaptador que integra un codificador de imágenes preentrenado con un modelo de lenguaje preentrenado. El adaptador consta de una serie de capas de atención cruzada que introducen la representación del codificador de imágenes en el modelo lingüístico. El adaptador se entrena con pares texto-imagen, lo que alinea la representación de la imagen con la del lenguaje. Durante el entrenamiento del adaptador, también actualizamos los parámetros del codificador de imágenes, pero intencionadamente no actualizamos los parámetros del modelo lingüístico. También entrenamos un adaptador de vídeo sobre el adaptador de imagen, utilizando datos emparejados de vídeo-texto. Esto permite al modelo agregar información entre fotogramas. Para más información, véase la sección 7.
- Por último, integramos el codificador del habla en el modelo mediante un adaptador que convierte la codificación del habla en una representación etiquetada que puede introducirse directamente en el modelo lingüístico ajustado. Durante la fase de ajuste supervisado, los parámetros del adaptador y del codificador se actualizan conjuntamente para lograr una comprensión del habla de alta calidad. No modificamos el modelo lingüístico durante el entrenamiento del adaptador de voz. También integramos un sistema de conversión de texto en voz. Para más detalles, véase la sección 8.
Nuestros experimentos multimodales han dado lugar a modelos que reconocen el contenido de imágenes y vídeos y admiten la interacción a través de una interfaz de voz. Estos modelos siguen en fase de desarrollo y aún no están listos para su lanzamiento.
3 Formación previa
El preentrenamiento de modelos lingüísticos implica los siguientes aspectos:
(1) Recopilación y filtrado de corpus de formación a gran escala;
(2) Desarrollo de arquitecturas de modelos y de las correspondientes leyes de escala para determinar el tamaño de los modelos;
(3) Desarrollo de técnicas para un preentrenamiento eficaz a gran escala;
(4) Desarrollo de un programa de formación previa. A continuación describiremos cada uno de estos componentes.
3.1 Datos de preentrenamiento
Creamos conjuntos de datos de preentrenamiento de modelos lingüísticos a partir de varias fuentes de datos que contienen conocimientos hasta finales de 2023. Aplicamos varios métodos de desduplicación y mecanismos de limpieza de datos a cada fuente de datos para obtener un etiquetado de alta calidad. Eliminamos los dominios que contenían grandes cantidades de información personal identificable (IPI), así como los dominios con contenido para adultos.
3.11 Depuración de datos web
La mayoría de los datos que utilizamos proceden de Internet, y a continuación describimos nuestro proceso de limpieza.
PII y filtrado de seguridad. Entre otras medidas, hemos implantado filtros diseñados para eliminar datos de sitios web que puedan contener contenidos inseguros o grandes cantidades de IPI, dominios clasificados como dañinos según diversas normas de seguridad de Meta y dominios conocidos por contener contenido para adultos.
Extracción y limpieza de textos. Procesamos el contenido HTML en bruto para extraer texto diverso y de alta calidad, y para ello utilizamos documentos web no truncados. Para ello, creamos un analizador sintáctico personalizado que extrae el contenido HTML y optimiza la precisión de la eliminación de plantillas y la recuperación de contenido. Hemos evaluado manualmente la calidad del analizador y lo hemos comparado con analizadores HTML de terceros optimizados para el contenido de artículos similares, y hemos comprobado que funciona bien. Tenemos cuidado con las páginas HTML que contienen contenido matemático y código para preservar la estructura de ese contenido. Conservamos el texto del atributo alt de la imagen porque el contenido matemático suele representarse como una imagen pre-renderizada en la que las matemáticas también se proporcionan en el atributo alt.
Descubrimos que Markdown era perjudicial para el rendimiento del modelo, que se había entrenado principalmente con datos web, en comparación con el texto sin formato, por lo que eliminamos todas las etiquetas Markdown.
Sin énfasis. Aplicamos múltiples rondas de desduplicación a nivel de URL, documento y línea:
- Desduplicación a nivel de URL. Realizamos la desduplicación a nivel de URL en todo el conjunto de datos. Para cada página correspondiente a una URL, conservamos la última versión.
- Desduplicación a nivel de documento. Realizamos una desduplicación global MinHash (Broder, 1997) en todo el conjunto de datos para eliminar los documentos casi duplicados.
- Desduplicación a nivel de fila. Realizamos una de-duplicación a nivel radical similar a ccNet (Wenzek et al., 2019). Eliminamos las filas que aparecen más de 6 veces en cada grupo que contiene 30 millones de documentos.
Aunque nuestros análisis cualitativos manuales sugieren que la deduplicación a nivel de línea elimina no sólo el contenido repetitivo residual de una variedad de sitios (por ejemplo, menús de navegación, advertencias sobre cookies), sino también texto frecuente de alta calidad, nuestras evaluaciones empíricas muestran mejoras significativas.
Filtrado heurístico. Se desarrollaron heurísticas para eliminar los documentos adicionales de baja calidad, los valores atípicos y los documentos con demasiadas repeticiones. Algunos ejemplos de heurísticas son:
- Utilizamos la cobertura de n-tuplas duplicadas (Rae et al., 2021) para eliminar las filas con contenido duplicado (por ejemplo, registros o mensajes de error). Estas filas pueden ser muy largas y únicas, por lo que no pueden filtrarse mediante la eliminación de duplicados de filas.
- Utilizamos un recuento de "palabras sucias" (Raffel et al., 2020) para filtrar los sitios para adultos que no están incluidos en la lista negra de dominios.
- Utilizamos la dispersión de Kullback-Leibler de la distribución de tokens para filtrar los documentos que contienen demasiados tokens anómalos en comparación con la distribución del corpus de entrenamiento.
Filtrado de calidad basado en modelos.
Además, hemos intentado utilizar varios clasificadores de calidad basados en modelos para seleccionar etiquetas de alta calidad. Estos métodos incluyen:
- Utilizando clasificadores rápidos como fasttext (Joulin et al., 2017), que están entrenados para reconocer si un texto dado será citado por Wikipedia (Touvron et al., 2023a).
- Se utilizó un clasificador modelo Roberta (Liu et al., 2019a) más intensivo computacionalmente, que se entrenó con las predicciones de Llama 2.
Para entrenar el clasificador de calidad basado en Llama 2, creamos un conjunto de documentos web limpios que describían los requisitos de calidad e instruimos al modelo de chat de Llama 2 para determinar si los documentos cumplían con estos requisitos. Para mayor eficiencia, utilizamos DistilRoberta (Sanh et al., 2019) para generar puntuaciones de calidad para cada documento. Evaluaremos experimentalmente la eficacia de varias configuraciones de filtrado de calidad.
Código y datos de inferencia.
De forma similar a DeepSeek-AI et al. (2024), construimos pipelines específicos de dominio para extraer páginas web que contienen código y páginas web relacionadas con las matemáticas. Específicamente, tanto los clasificadores de código como los de inferencia son modelos DistilledRoberta entrenados utilizando datos web anotados de Llama 2. A diferencia de los clasificadores de calidad genéricos mencionados anteriormente, realizamos un ajuste de pistas para dirigirnos a páginas web que contienen inferencias matemáticas, razonamiento en dominios STEM y código incrustado en lenguaje natural. Dado que las distribuciones de tokens del código y las matemáticas son muy diferentes de las del lenguaje natural, estas líneas implementan la extracción de HTML específica del dominio, características de texto personalizadas y heurística para el filtrado.
Datos multilingües.
Al igual que en el procesamiento de textos en inglés descrito anteriormente, aplicamos filtros para eliminar datos de sitios web que puedan contener información personal identificable (IPI) o contenidos inseguros. Nuestra línea de procesamiento de texto multilingüe presenta las siguientes características exclusivas:
- Utilizamos un modelo rápido de reconocimiento lingüístico basado en el texto para clasificar los documentos en 176 idiomas.
- Para cada idioma, realizamos una desduplicación de los datos a nivel de documento y a nivel de fila.
- Aplicamos una heurística específica para cada lengua y filtros basados en modelos para eliminar los documentos de baja calidad.
Además, utilizamos un clasificador multilingüe basado en Llama 2 para clasificar la calidad de los documentos multilingües y garantizar que se da prioridad a los contenidos de alta calidad. El número de tokens multilingües que utilizamos en el preentrenamiento se determina experimentalmente, y el rendimiento del modelo se equilibra en pruebas de referencia en inglés y multilingües.
3.12 Determinar la combinación de datos
为了获得高质量语言模型,必须谨慎确定预训练数据混合中不同数据源的比例。我们主要利用知识分类和尺度定律实验来确定这一数据混合。
知识分类。我们开发了一个分类器,用于对网页数据中包含的信息类型进行分类,以便更有效地确定数据组合。我们使用这个分类器对网页上过度代表的数据类别(例如艺术和娱乐)进行下采样。
为了确定最佳数据混合方案。我们进行规模定律实验,其中我们将多个小型模型训练于特定数据混合集上,并利用其预测大型模型在该混合集上的性能(参见第 3.2.1 节)。我们多次重复此过程,针对不同的数据混合集选择新的候选数据混合集。随后,我们在该候选数据混合集上训练一个更大的模型,并在多个关键基准测试上评估该模型的性能。
数据混合摘要。我们的最终数据混合包含大约 50% 的通用知识标记、25% 的数学和推理标记、17% 的代码标记以及 8% 的多语言标记。
3.13 Datos de recocido
Los resultados empíricos muestran que el recocido en una pequeña cantidad de datos de código y matemáticas de alta calidad (véase la sección 3.4.3) puede mejorar el rendimiento de los modelos preentrenados en pruebas de referencia clave. Al igual que en el estudio de Li et al. (2024b), recocemos utilizando un conjunto de datos mixto que contiene datos de alta calidad de dominios seleccionados. Nuestros datos recocidos no contienen ningún conjunto de entrenamiento de pruebas de referencia comúnmente utilizadas. Esto nos permite evaluar la verdadera capacidad de aprendizaje de pocas muestras y la generalización fuera del dominio de Llama 3.
Siguiendo a OpenAI (2023a), evaluamos el efecto del recocido en los conjuntos de entrenamiento GSM8k (Cobbe et al., 2021) y MATH (Hendrycks et al., 2021b). Encontramos que el recocido mejora el rendimiento del modelo Llama 3 8B preentrenado en 24,0% y 6,4% en los conjuntos de validación GSM8k y MATH, respectivamente. Sin embargo, la mejora es insignificante para el modelo 405B, lo que sugiere que nuestro modelo insignia tiene fuertes capacidades de aprendizaje e inferencia contextual, y que no requiere muestras de entrenamiento específicas del dominio para lograr un rendimiento fuerte.
Utilice el recocido para evaluar la calidad de los datos.Al igual que Blakeney et al. (2024), encontramos que el recocido nos permite juzgar el valor de pequeños conjuntos de datos de dominios específicos. Medimos el valor de estos conjuntos de datos templando linealmente la tasa de aprendizaje del modelo Llama 3 8B, que ha sido entrenado con 50%, a 0 sobre 40.000 millones de tokens. En estos experimentos, asignamos ponderaciones 30% al nuevo conjunto de datos y las restantes 70% a la mezcla de datos por defecto. Es más eficiente utilizar el recocido para evaluar nuevas fuentes de datos que realizar experimentos de ley de escala en cada conjunto de datos pequeño.
3.2 Arquitectura del modelo
Llama 3 utiliza la arquitectura dense Transformer estándar (Vaswani et al., 2017). La arquitectura de su modelo no difiere significativamente de Llama y Llama 2 (Touvron et al., 2023a, b); nuestro aumento del rendimiento se debe principalmente a mejoras en la calidad y la diversidad de los datos, así como al aumento del tamaño del entrenamiento.
Hicimos un par de modificaciones menores:
- Utilizamos Grouped Query Attention (GQA; Ainslie et al. (2023)), donde se utilizan 8 cabeceras de valores clave para aumentar la velocidad de inferencia y reducir el tamaño de la caché de valores clave durante la descodificación.
- Utilizamos una máscara de atención para evitar mecanismos de autoatención entre distintos documentos de la secuencia. Comprobamos que este cambio tiene un impacto limitado durante el preentrenamiento estándar, pero es importante durante el preentrenamiento continuo de secuencias muy largas.
- Utilizamos un vocabulario de 128.000 tokens. Nuestro vocabulario tokenizado combina los 100.000 tokens del vocabulario tiktoken3 con 28.000 tokens adicionales para soportar mejor las lenguas no inglesas. En comparación con el vocabulario de Llama 2, nuestro nuevo vocabulario mejora la compresión de las muestras de datos en inglés de 3,17 a 3,94 caracteres/token. Esto permite al modelo "leer" más texto con la misma cantidad de cálculo de entrenamiento. También hemos comprobado que la adición de 28.000 tokens de lenguas no inglesas específicas mejora la compresión y el rendimiento posterior, pero no afecta a la tokenización en inglés.
- Aumentamos el hiperparámetro de frecuencia base RoPE a 500.000. Esto nos permite soportar mejor contextos más largos; Xiong et al. (2023) muestran que este valor es válido para longitudes de contexto de hasta 32.768.

La Llama 3 405B utiliza una arquitectura con 126 capas, 16.384 dimensiones de representación de marcadores y 128 cabezas de atención; para más información, véase la Tabla 3. Esto da como resultado un tamaño de modelo que es aproximadamente óptimo desde el punto de vista computacional según nuestros datos y un presupuesto de entrenamiento de 3,8 × 10^25 FLOPs.
3.2.1 Leyes de escala
Utilizamos las leyes de escalado (Hoffmann et al., 2022; Kaplan et al., 2020) para determinar el tamaño óptimo del modelo insignia teniendo en cuenta nuestro presupuesto computacional previo al entrenamiento. Además de determinar el tamaño óptimo del modelo, la predicción del rendimiento del modelo insignia en tareas de referencia posteriores presenta retos importantes por las siguientes razones:
- Las leyes de escalado existentes suelen predecir sólo la pérdida de predicción de la siguiente marca, no un rendimiento de referencia específico.
- Las leyes de escalado pueden ser ruidosas y poco fiables porque se desarrollan a partir de ejecuciones de preentrenamiento con un presupuesto computacional reducido (Wei et al., 2022b).
Para hacer frente a estos retos, aplicamos un enfoque en dos fases para desarrollar leyes de escalado que predijeran con precisión el rendimiento de las pruebas comparativas posteriores:
- Primero establecemos la correlación entre los FLOPs de preentrenamiento y el cálculo de la log-verosimilitud negativa del mejor modelo en la tarea descendente.
- A continuación, correlacionamos la log-verosimilitud negativa en la tarea descendente con la precisión de la tarea utilizando el modelo de Leyes de Escalado y un modelo más antiguo previamente entrenado utilizando FLOPs computacionales más altos. En este paso, utilizamos exclusivamente la familia de modelos Llama 2.
Este enfoque nos permite predecir el rendimiento de la tarea posterior (para modelos óptimos desde el punto de vista computacional) basándonos en un número específico de FLOPs preentrenados. Utilizamos un enfoque similar para seleccionar nuestra combinación de datos de preentrenamiento (véase la sección 3.4).
Escala Experimento de Derecho.En concreto, construimos leyes de escalado preentrenando modelos con presupuestos computacionales entre 6 × 10^18 FLOPs y 10^22 FLOPs. En cada presupuesto computacional, preentrenamos modelos con tamaños entre 40M y 16B parámetros y utilizamos una fracción del tamaño del modelo en cada presupuesto computacional. En estas ejecuciones de entrenamiento, utilizamos la programación de la tasa de aprendizaje coseno y el calentamiento lineal en 2.000 pasos de entrenamiento. La tasa de aprendizaje máxima se fijó entre 2 × 10^-4 y 4 × 10^-4 en función del tamaño del modelo. La caída del coseno se fijó en 0,1 veces el valor máximo. La caída del peso de cada paso se fijó en 0,1 veces la tasa de aprendizaje de ese paso. Utilizamos un tamaño de lote fijo para cada tamaño computacional, que oscilaba entre 250K y 4M.

Estos experimentos produjeron las curvas IsoFLOPs de la Figura 2. Las pérdidas de estas curvas se midieron en conjuntos de validación independientes. Ajustamos los valores de pérdida medidos utilizando un polinomio de segundo orden y determinamos el valor mínimo de cada parábola. Nos referimos al mínimo de la parábola como el modelo computacionalmente óptimo bajo el correspondiente presupuesto computacional preentrenado.
Utilizamos modelos computacionalmente óptimos identificados de este modo para predecir el número óptimo de fichas de entrenamiento para un presupuesto computacional determinado. Para ello, asumimos una relación de ley de potencia entre el presupuesto computacional C y el número óptimo de tokens de entrenamiento N (C):
N (C) = AC α .
Ajustamos A y α utilizando los datos de la Fig. 2. Encontramos (α, A) = (0,53, 0,29); el ajuste correspondiente se muestra en la Fig. 3. Extrapolando la ley de escala resultante a 3,8 × 10 25 FLOPs, se sugiere entrenar el modelo con 402B parámetros y utilizar 16,55T de fichas. La extrapolación de la ley de escala resultante a 3,8 × 10 25 FLOPs sugiere entrenar un modelo con 402B parámetros y utilizar 16,55T tokens.
Una observación importante es que la curva de IsoFLOPs se hace más plana alrededor del mínimo a medida que aumenta el presupuesto computacional. Esto implica que el rendimiento del modelo insignia es relativamente estable frente a pequeñas variaciones en el equilibrio entre el tamaño del modelo y los marcadores de entrenamiento. Basándonos en esta observación, finalmente decidimos entrenar un modelo insignia que contiene el parámetro 405B.
Predicción del rendimiento en tareas posteriores.Utilizamos el modelo computacionalmente óptimo generado para predecir el rendimiento del modelo insignia Llama 3 en el conjunto de datos de referencia. En primer lugar, relacionamos linealmente la log-verosimilitud negativa (normalizada) de la respuesta correcta en la prueba de referencia con los FLOPs de entrenamiento. Para este análisis, utilizamos únicamente el modelo de ley de escala entrenado hasta 10^22 FLOPs en la mezcla de datos anterior. A continuación, establecimos una relación en forma de S entre la verosimilitud logarítmica y la precisión utilizando el modelo de ley de escala y el modelo Llama 2, que se entrenó utilizando la mezcla de datos y el etiquetador Llama 2. (Mostramos los resultados de este experimento a continuación). (En la Figura 4 mostramos los resultados de este experimento en la prueba de referencia ARC Challenge). Encontramos que esta predicción de ley de escala en dos pasos (extrapolada a cuatro órdenes de magnitud) es bastante precisa: sólo subestima ligeramente el rendimiento final del modelo insignia Llama 3.
3.3 Infraestructura, expansión y eficiencia
Describimos el hardware y la infraestructura que soportan el preentrenamiento de Llama 3 405B y analizamos varias optimizaciones que mejoran la eficacia del entrenamiento.
3.3.1 Infraestructura de formación
Los modelos Llama 1 y Llama 2 fueron entrenados en el supercluster de investigación de IA de Meta (Lee y Sengupta, 2022). A medida que aumentamos la escala, el entrenamiento de Llama 3 se migró al clúster de producción de Meta (Lee et al., 2024). Esta configuración optimiza la fiabilidad a nivel de producción, que es fundamental a medida que ampliamos el entrenamiento.

Recursos informáticos: La Llama 3 405B entrena hasta 16.000 GPU H100, cada una de ellas con un TDP de 700 W y 80 GB de HBM3, utilizando la plataforma de servidor de IA Grand Teton de Meta (Matt Bowman, 2022). Cada servidor está equipado con ocho GPU y dos CPU; dentro del servidor, las ocho GPU están conectadas mediante NVLink. Los trabajos de entrenamiento se programan utilizando MAST (Choudhury et al., 2024), el programador de entrenamiento a escala global de Meta.
Almacenamiento: Tectonic (Pan et al., 2021), el sistema de archivos distribuido de propósito general de Meta, se utilizó para construir la arquitectura de almacenamiento para el preentrenamiento de Llama 3 (Battey y Gupta, 2024). Proporciona 240 PB de espacio de almacenamiento y consta de 7.500 servidores equipados con SSD que soportan un rendimiento sostenible de 2 TB/s y un rendimiento máximo de 7 TB/s. Uno de los principales retos es soportar las escrituras de puntos de control en ráfagas que saturan la estructura de almacenamiento en un corto periodo de tiempo. Los puntos de control guardan el estado del modelo por GPU, que oscila entre 1 MB y 4 GB por GPU, para su recuperación y depuración. Nuestro objetivo es minimizar el tiempo de pausa de la GPU durante los puntos de control y aumentar su frecuencia para reducir la cantidad de trabajo que se pierde tras la recuperación.
Trabajo en red: La Llama 3 405B utiliza una arquitectura RDMA sobre Ethernet convergente (RoCE) basada en los conmutadores de rack Arista 7800 y Minipack2 Open Compute Project (OCP). Los modelos más pequeños de la serie Llama 3 se entrenaron utilizando la red Nvidia Quantum2 Infiniband. Tanto los clusters RoCE como los Infiniband utilizan una conexión de enlace de 400 Gbps entre las GPU. A pesar de las diferencias en la tecnología de red subyacente de estos clusters, hemos ajustado ambos para que proporcionen un rendimiento equivalente a la hora de manejar estas grandes cargas de trabajo de entrenamiento. Profundizaremos más en nuestra red RoCE a medida que nos hagamos cargo de su diseño.
- Topología de red: Nuestro clúster de IA basado en RoCE contiene 24.000 GPU (nota 5) conectadas a través de una red Clos de tres niveles (Lee et al., 2024). En el nivel inferior, cada bastidor alberga 16 GPU, asignadas a dos servidores y conectadas a través de un único conmutador Minipack2 para la parte superior del bastidor (ToR). En el nivel intermedio, 192 de estos bastidores se conectan a través de conmutadores de clúster para formar un pod de 3.072 GPU con ancho de banda bidireccional completo, lo que garantiza que no haya sobresuscripción. En el nivel superior, ocho de estos Pods dentro del mismo edificio del centro de datos se conectan a través de switches de agregación para formar un cluster de 24.000 GPUs. Sin embargo, en lugar de mantener un ancho de banda bidireccional completo, las conexiones de red en la capa de agregación tienen una tasa de sobresuscripción de 1:7. Tanto nuestro enfoque paralelo al modelo (véase la Sección 3.3.2) como el programador de tareas de entrenamiento (Choudhury et al., 2024) están optimizados para ser conscientes de la topología de la red, con el objetivo de minimizar la comunicación de red entre Pods.
- Equilibrio de carga: El entrenamiento de grandes modelos lingüísticos genera un tráfico de red pesado que es difícil de equilibrar entre todas las rutas de red disponibles mediante métodos tradicionales como el enrutamiento Equal Cost Multipath (ECMP). Para resolver este problema, empleamos dos técnicas. En primer lugar, nuestra biblioteca de agregados crea 16 flujos de red entre dos GPU en lugar de uno, lo que reduce la cantidad de tráfico por flujo y proporciona más flujos para el equilibrio de la carga. En segundo lugar, nuestro protocolo ECMP mejorado (E-ECMP) equilibra eficazmente estos 16 flujos a través de diferentes rutas de red mediante el hash de otros campos del paquete de cabecera RoCE.

- Control de la congestión: Utilizamos conmutadores de búfer profundo (Gangidi et al., 2024) en la red troncal para acomodar la congestión transitoria y el almacenamiento en búfer causados por patrones de comunicación agregados. Esto ayuda a limitar el impacto de la congestión persistente y la contrapresión de la red causada por servidores lentos, que es común en la formación. Por último, un mejor equilibrio de la carga a través de E-ECMP reduce en gran medida la probabilidad de congestión. Gracias a estas optimizaciones, hemos conseguido hacer funcionar un cluster de 24.000 GPUs sin necesidad de recurrir a métodos tradicionales de control de la congestión como la notificación cuantificada de la congestión en el centro de datos (DCQCN).
3.3.2 Paralelismo en la ampliación de modelos
Para escalar el entrenamiento de nuestro modelo más grande, lo fragmentamos utilizando paralelismo 4D, un esquema que combina cuatro enfoques paralelos diferentes. Este enfoque distribuye eficazmente el cálculo entre varias GPU y garantiza que los parámetros del modelo, los estados del optimizador, los gradientes y los valores de activación de cada GPU se ajusten a su HBM. Nuestra implementación paralela 4D (como se muestra en et al. (2020); Ren et al. (2021); Zhao et al. (2023b)) trocea el modelo, el optimizador y el gradiente a la vez que implementa el paralelismo de datos, que procesa los datos en paralelo en múltiples GPUs y los sincroniza después de cada paso de entrenamiento. Usamos FSDP para cortar el estado del optimizador y el gradiente para Llama 3, pero para el corte del modelo no volvemos a cortar después del cálculo hacia delante para evitar la comunicación adicional de la colección completa durante el paso inverso.
Utilización de la GPU.Ajustando cuidadosamente la configuración paralela, el hardware y el software, conseguimos una utilización de FLOPs del modelo BF16 (MFU; Chowdhery et al. (2023)) de 38-43%. Las configuraciones mostradas en la Tabla 4 indican que, en comparación con 43% en GPUs de 8K y DP=64, la caída de la MFU a 41% en GPUs de 16K y DP=128 se debe a la necesidad de reducir el tamaño del lote de cada grupo de DP para mantener constante el número de marcadores globales durante el entrenamiento. 41% se debe a la necesidad de reducir el tamaño del lote de cada grupo de AD para mantener constante el número de marcadores globales durante el entrenamiento.
Racionalizar las mejoras paralelas.Nos encontramos con varios retos en nuestra aplicación actual:
- Limitaciones del tamaño de los lotes.Las implementaciones actuales limitan el tamaño de lote admitido por GPU, exigiendo que sea divisible por el número de etapas del pipeline. En el ejemplo de la Fig. 6, el paralelismo de canalización para la programación depth-first (DFS) (Narayanan et al. (2021)) requiere N = PP = 4, mientras que la programación breadth-first (BFS; Lamy-Poirier (2023)) requiere N = M, donde M es el número total de microlotes y N es el número de microlotes consecutivos en la misma etapa en la dirección de avance o retroceso. Sin embargo, el preentrenamiento suele requerir flexibilidad en el dimensionamiento de los lotes.
- Desequilibrio de la memoria.Las implementaciones paralelas en paralelo existentes conducen a un consumo de recursos desequilibrado. La primera etapa consume más memoria debido a la incrustación y el calentamiento de microlotes.
- Los cálculos no están equilibrados. Después de la última capa del modelo, necesitamos calcular las salidas y las pérdidas, lo que convierte esta fase en un cuello de botella en términos de latencia de ejecución. donde Di es el índice de la i-ésima dimensión paralela. En este ejemplo, la GPU0[TP0, CP0, PP0, DP0] y la GPU1[TP1, CP0, PP0, DP0] están en el mismo grupo TP, la GPU0 y la GPU2 están en el mismo grupo CP, la GPU0 y la GPU4 están en el mismo grupo PP, y la GPU0 y la GPU8 están en el mismo grupo DP.

Para resolver estos problemas, modificamos el método de programación de canalizaciones, como se muestra en la figura 6, que permite un ajuste flexible de N, en este caso N = 5, lo que permite ejecutar cualquier número de microlotes en cada lote. Esto nos permite:
(1) Cuando exista un límite de tamaño de lote, ejecute menos microlotes que el número de etapas; o bien
(2) Ejecutar más microlotes para ocultar la comunicación entre pares y encontrar la mejor eficiencia de comunicación y memoria entre la programación por profundidad (DFS) y la programación por amplitud (BFS). Para equilibrar el pipeline, reducimos una capa Transformer de la primera y la última etapa, respectivamente. Esto significa que el primer bloque de modelo de la primera etapa sólo tiene la capa de incrustación, mientras que el último bloque de modelo de la última etapa sólo tiene la proyección de salida y el cálculo de pérdidas.
Para reducir las burbujas de canalización, utilizamos un enfoque de programación intercalada (Narayanan et al., 2021) en una jerarquía de canalización con V etapas de canalización. El ratio de burbuja global de la tubería es PP-1 V * M . Además, empleamos la comunicación asíncrona entre pares, que acelera significativamente el entrenamiento, especialmente en los casos en los que las máscaras de documentos introducen desequilibrios computacionales adicionales. Activamos TORCH_NCCL_AVOID_RECORD_STREAMS para reducir el uso de memoria de la comunicación asíncrona entre pares. Por último, para reducir los costes de memoria, basándonos en un análisis detallado de la asignación de memoria, liberamos de forma proactiva los tensores que no se utilizarán en futuros cálculos, incluidos los tensores de entrada y salida de cada etapa del pipeline. ** Con estas optimizaciones, somos capaces de realizar los 8K tensores sin el uso de puntos de control de activación, sin el uso de puntos de control de activación. ficha secuencias para el preentrenamiento de Llama 3.
La paralelización contextual se utiliza para secuencias largas. Aprovechamos la paralelización de contextos (CP) para mejorar la eficiencia de memoria al escalar las longitudes de contexto de Llama 3 y permitir el entrenamiento en secuencias muy largas de hasta 128K de longitud. En CP, hacemos una partición a través de las dimensiones de la secuencia, concretamente dividimos la secuencia de entrada en bloques 2 × CP de forma que cada nivel CP recibe dos bloques para un mejor equilibrio de la carga. El nivel CP i-ésimo recibe el bloque i-ésimo y (2 × CP -1 -i).
A diferencia de las implementaciones de CP existentes que solapan la comunicación y el cálculo en una estructura de anillo (Liu et al., 2023a), nuestra implementación de CP emplea un enfoque basado en la recopilación total que primero agrega globalmente el tensor clave-valor (K, V) y, a continuación, calcula las salidas atencionales de los bloques del tensor de consulta local (Q). Aunque la latencia de la comunicación all-gather está en la ruta crítica, adoptamos este enfoque por dos razones principales:
(1) Es más fácil y flexible admitir distintos tipos de máscaras de atención, como las máscaras de documentos, en la atención CP basada en la recopilación total;
(2) La latencia all-gather expuesta es pequeña porque el tensor K y V de la comunicación es mucho menor que el tensor Q, debido al uso de GQA (Ainslie et al., 2023). Como resultado, la complejidad temporal del cálculo de la atención es un orden de magnitud mayor que la del all-gather (O(S²) frente a O(S), donde S denota la longitud de la secuencia en la máscara causal completa), lo que hace que la sobrecarga del all-gather sea insignificante.

Configuración paralelizada sensible a la red.El orden de las dimensiones de paralelización [TP, CP, PP, DP] está optimizado para la comunicación de red. La capa más interna de la paralelización requiere el mayor ancho de banda de red y la menor latencia, por lo que normalmente se limita al mismo servidor. La capa más externa de la paralelización puede abarcar redes multisalto y debe ser capaz de tolerar una latencia de red más alta. Por lo tanto, basándonos en los requisitos de ancho de banda y latencia de la red, clasificamos las dimensiones de paralelización en el orden [TP, CP, PP, DP]. DP (es decir, FSDP) es la capa más externa de paralelización, ya que puede tolerar una latencia de red más larga mediante la precarga asíncrona de los pesos del modelo de corte y la reducción del gradiente. Determinar la configuración de paralelización óptima con la mínima sobrecarga de comunicación y evitando al mismo tiempo el desbordamiento de memoria de la GPU es todo un reto. Hemos desarrollado un estimador del consumo de memoria y una herramienta de proyección del rendimiento, que nos han ayudado a explorar varias configuraciones de paralelización y a predecir el rendimiento global del entrenamiento e identificar las lagunas de memoria de forma eficiente.
Estabilidad numérica.Comparando las pérdidas de entrenamiento entre diferentes configuraciones paralelas, solucionamos algunos problemas numéricos que afectan a la estabilidad del entrenamiento. Para garantizar la convergencia del entrenamiento, utilizamos la acumulación de gradientes FP32 durante el cálculo inverso de múltiples microlotes y reducimos los gradientes de dispersión utilizando FP32 entre los trabajadores de datos paralelos en FSDP. Para los tensores intermedios que se utilizan varias veces en los cálculos hacia delante, como las salidas del codificador visual, el gradiente inverso también se acumula en FP32.
3.3.3 Comunicaciones colectivas
La biblioteca de comunicación colectiva de Llama 3 se basa en una rama de la biblioteca NCCL de Nvidia llamada NCCLX. NCCLX mejora enormemente el rendimiento de NCCL, especialmente para redes de alta latencia. Recordemos que el orden de las dimensiones paralelas es [TP, CP, PP, DP], donde DP corresponde a FSDP, y que las dimensiones paralelas más externas, PP y DP, pueden comunicarse a través de una red multisalto con latencias de decenas de microsegundos. Las operaciones de comunicación colectiva all-gather y reduce-scatter del NCCL original se utilizan en FSDP, mientras que la comunicación punto a punto se utiliza para PP, que requiere fragmentación de datos y replicación de datos por etapas. Este enfoque conlleva algunas de las siguientes ineficiencias:
- Es necesario intercambiar un gran número de pequeños mensajes de control a través de la red para facilitar la transferencia de datos;
- Operaciones adicionales de copia de memoria;
- Utiliza ciclos adicionales de la GPU para la comunicación.
Para el entrenamiento de Llama 3, abordamos algunas de estas ineficiencias adaptando la fragmentación y las transferencias de datos a la latencia de nuestra red, que puede llegar a decenas de microsegundos en clústeres grandes. También permitimos que los mensajes de control pequeños pasen a través de nuestra red con mayor prioridad, evitando específicamente el bloqueo de la cabeza de cola en conmutadores de núcleo con búfer profundo.
Nuestro trabajo en curso para futuras versiones de Llama incluye cambios más profundos en NCCLX para abordar plenamente todos los problemas anteriores.

3.3.4 Fiabilidad y retos operativos
La complejidad y las posibles situaciones de fallo del entrenamiento en GPU de 16K superan las de los clusters de CPU más grandes con los que hemos trabajado. Además, la naturaleza sincrónica del entrenamiento lo hace menos tolerante a fallos: un solo fallo de la GPU puede obligar a reiniciar todo el trabajo. A pesar de estas dificultades, en el caso de Llama 3 conseguimos tiempos de entrenamiento efectivos superiores a 90% mientras realizábamos el mantenimiento automatizado del clúster (por ejemplo, actualizaciones del firmware y del kernel de Linux (Vigraham y Leonhardi, 2024)), lo que provocó al menos una interrupción del entrenamiento al día.
El tiempo efectivo de formación es la cantidad de tiempo dedicado a la formación efectiva durante el tiempo transcurrido. Durante la instantánea de 54 días previa al entrenamiento, experimentamos un total de 466 interrupciones operativas. De ellas, 47 fueron interrupciones planificadas debido a operaciones de mantenimiento automatizadas (por ejemplo, actualizaciones de firmware u operaciones iniciadas por el operador, como actualizaciones de configuración o de conjuntos de datos). Las 419 restantes fueron interrupciones imprevistas, que se clasifican en el Cuadro 5. Aproximadamente 78% de las interrupciones imprevistas se atribuyeron a problemas de hardware identificados, como fallos de la GPU o de componentes del host, o a presuntos problemas relacionados con el hardware, como corrupción silenciosa de datos y tareas de mantenimiento no planificadas de hosts individuales. A pesar del gran número de fallos, durante este periodo sólo fue necesario realizar tres intervenciones manuales importantes y el resto de problemas se resolvieron de forma automatizada.
Para mejorar el tiempo de formación efectivo, redujimos el tiempo de inicio y de comprobación de los trabajos, y desarrollamos herramientas para el diagnóstico rápido y la resolución de problemas. Hicimos un uso extensivo del registrador de vuelo NCCL integrado de PyTorch (Ansel et al., 2024), una función que captura metadatos colectivos y rastros de pila en un búfer de anillo, lo que nos permite diagnosticar rápidamente cuelgues y problemas de rendimiento a escala, especialmente en el caso de los aspectos de aspectos NCCLX. Gracias a él, podemos registrar eficazmente los eventos de comunicación y la duración de cada operación colectiva, y volcar automáticamente los datos de rastreo en caso de que se agote el tiempo de espera de un watchdog o un heartbeat de NCCLX. Con los cambios de configuración en línea (Tang et al., 2015), podemos habilitar de forma selectiva operaciones de rastreo y recopilación de metadatos más intensivas desde el punto de vista computacional sin necesidad de liberar código o reiniciar el trabajo. Los problemas de depuración en la formación a gran escala se complican por el uso mixto de NVLink y RoCE en nuestra red. Las transferencias de datos suelen realizarse a través de NVLink mediante operaciones de carga/almacenamiento emitidas por el núcleo CUDA, y el fallo de una GPU remota o de una conexión NVLink suele manifestarse como una operación de carga/almacenamiento bloqueada en el núcleo CUDA sin devolver un código de error explícito. PyTorch acceda al estado interno de NCCLX y rastree la información relevante. Aunque no es posible evitar por completo los bloqueos debidos a fallos de NVLink, nuestro sistema supervisa el estado de las bibliotecas de comunicación y agota automáticamente el tiempo de espera cuando se detectan dichos bloqueos. Además, NCCLX rastrea la actividad del núcleo y de la red para cada comunicación NCCLX y proporciona una instantánea del estado interno del colectivo NCCLX que está fallando, incluyendo las transferencias de datos completadas y no completadas entre todos los rangos. Analizamos estos datos para depurar los problemas de extensión de NCCLX.
A veces, los problemas de hardware pueden dar lugar a rezagados que siguen funcionando pero son lentos y difíciles de detectar. Incluso si sólo hay un rezagado, puede ralentizar miles de otras GPU, a menudo en forma de funcionamiento normal pero comunicación lenta. Hemos desarrollado herramientas para priorizar las comunicaciones potencialmente problemáticas de grupos de procesos seleccionados. Investigando sólo unos pocos sospechosos clave, a menudo somos capaces de identificar eficazmente a los rezagados.
Una observación interesante es el impacto de los factores ambientales en el rendimiento del entrenamiento a gran escala. En el caso de la Llama 3 405B, observamos fluctuaciones de rendimiento de 1-2% en función de la variación horaria. Esta fluctuación se debe a las altas temperaturas del mediodía, que afectan al escalado dinámico del voltaje y la frecuencia de la GPU. Durante el entrenamiento, decenas de miles de GPU pueden aumentar o disminuir simultáneamente el consumo de energía, por ejemplo, debido a que todas las GPU están esperando a que termine un punto de control o una comunicación colectiva, o a que se inicie o cierre un trabajo de entrenamiento completo. Cuando esto ocurre, pueden producirse fluctuaciones transitorias en el consumo de energía dentro del centro de datos del orden de decenas de megavatios, lo que pone a prueba los límites de la red eléctrica. Se trata de un reto constante a medida que ampliamos la formación para futuros modelos Llama aún mayores.
3.4 Programas de formación
La receta de preentrenamiento de la Llama 3 405B consta de tres etapas principales:
(1) preentrenamiento inicial, (2) preentrenamiento de contexto largo y (3) recocido. Cada una de estas tres etapas se describe a continuación. Utilizamos recetas similares para preentrenar los modelos 8B y 70B.
3.4.1 Formación previa inicial
Preentrenamos el modelo Llama 3 405B utilizando un esquema de tasa de aprendizaje coseno con una tasa de aprendizaje máxima de 8 × 10-⁵, calentada linealmente hasta 8.000 pasos, y decaída a 8 × 10-⁷ tras 1.200.000 pasos de entrenamiento. Para mejorar la estabilidad del entrenamiento, utilizamos un tamaño de lote más pequeño al principio del entrenamiento y posteriormente aumentamos el tamaño del lote para mejorar la eficiencia. En concreto, inicialmente tenemos un tamaño de lote de 4 millones de tokens y una longitud de secuencia de 4.096. Después de preentrenar 252 millones de tokens, duplicamos el tamaño de lote y la longitud de secuencia a 8 millones de secuencias y 8.192 tokens, respectivamente. Después de preentrenar 2,87 millones de tokens, volvemos a duplicar el tamaño de lote a 16 millones. Este método de entrenamiento es muy estable: se producen muy pocos picos de pérdida y no es necesario intervenir para corregir las desviaciones en el entrenamiento del modelo.
Ajuste de las combinaciones de datos. Durante el entrenamiento, realizamos varios ajustes en la combinación de datos del preentrenamiento para mejorar el rendimiento del modelo en tareas descendentes específicas. En concreto, aumentamos la proporción de datos no ingleses durante el preentrenamiento para mejorar el rendimiento multilingüe de Llama 3. También aumentamos la proporción de datos matemáticos para mejorar el razonamiento matemático del modelo, añadimos datos de redes más recientes en las últimas fases del preentrenamiento para actualizar los límites de conocimiento del modelo y redujimos la proporción de un subconjunto de datos que posteriormente se consideró de menor calidad.
3.4.2 Preentrenamiento en contexto largo
En la etapa final del preentrenamiento, entrenamos secuencias largas para soportar ventanas de contexto de hasta 128.000 tokens. No entrenamos secuencias largas antes porque el cálculo en la capa de autoatención crece cuadráticamente con la longitud de la secuencia. Aumentamos gradualmente la longitud del contexto y realizamos un preentrenamiento una vez que el modelo se ha adaptado correctamente a la mayor longitud del contexto. Evaluamos el éxito de la adaptación midiendo ambas cosas:
(1) Si se ha recuperado totalmente el rendimiento del modelo en las evaluaciones de contexto corto;
(2) Si el modelo puede resolver perfectamente la tarea "una aguja en un pajar" hasta esta longitud. En el preentrenamiento de Llama 3 405B, aumentamos progresivamente la longitud del contexto en seis etapas, empezando con una ventana de contexto inicial de 8.000 tokens y llegando finalmente a una ventana de contexto de 128.000 tokens. Esta larga fase de preentrenamiento del contexto utilizó aproximadamente 800.000 millones de tokens de entrenamiento.

3.4.3 Recocido
Durante el preentrenamiento de los últimos 40 millones de tokens, ajustamos la tasa de aprendizaje linealmente a 0, manteniendo una longitud de contexto de 128.000 tokens. Durante esta fase de templado, también ajustamos la mezcla de datos para aumentar el tamaño de la muestra de fuentes de datos de muy alta calidad; véase la sección 3.1.3. Por último, calculamos la media de los puntos de control del modelo (media de Polyak (1991)) durante el recocido para generar el modelo final preentrenado.
4 Formación de seguimiento
Generamos y alineamos los modelos de Llama 3 aplicando múltiples rondas de entrenamiento de seguimiento. Estos entrenamientos de seguimiento se basan en puntos de control preentrenados e incorporan comentarios humanos para la alineación de modelos (Ouyang et al., 2022; Rafailov et al., 2024). Cada ronda de entrenamiento de seguimiento consistió en un ajuste fino supervisado (SFT), seguido de una optimización directa de preferencias (DPO; Rafailov et al., 2024) utilizando ejemplos generados mediante anotación o síntesis manual. En las secciones 4.1 y 4.2, respectivamente, describimos nuestros métodos de datos y modelos de entrenamiento. Además, proporcionamos más detalles sobre las estrategias de cotejo de datos personalizadas en la Sección 4.3 para mejorar el modelo en términos de inferencia, capacidades de programación, factorización, soporte multilingüe, uso de herramientas, contextos largos y cumplimiento de instrucciones precisas.
4.1 Modelización
La base de nuestra estrategia de post-entrenamiento es un modelo de recompensa y un modelo lingüístico. Primero entrenamos un modelo de recompensa sobre los puntos de control del preentrenamiento utilizando datos de preferencias etiquetados por humanos (véase el apartado 4.1.2). A continuación, ajustamos los puntos de control del preentrenamiento con un ajuste fino supervisado (SFT; véase el apartado 4.1.3) y los alineamos con los puntos de control mediante una optimización directa de las preferencias (DPO; véase el apartado 4.1.4). Este proceso se muestra en la figura 7. A menos que se indique lo contrario, nuestro proceso de modelado se aplica a la Llama 3 405B, a la que nos referiremos como Llama 3 405B para simplificar.
4.1.1 Formato del diálogo de chat
Para adaptar un Modelo de Lenguaje Extenso (LLM) a la interacción persona-ordenador, necesitamos definir un protocolo de diálogo por chat que permita al modelo entender órdenes humanas y realizar tareas de diálogo. En comparación con su predecesor, Llama 3 tiene nuevas características, como el uso de herramientas (Sección 4.3.5), que pueden requerir la generación de múltiples mensajes en una sola ronda de diálogo y su envío a diferentes lugares (por ejemplo, usuario, ipython). Para ello, hemos diseñado un nuevo protocolo de chat multimensaje que utiliza una serie de tokens especiales de cabecera y terminación. Los tokens de cabecera se utilizan para indicar el origen y el destino de cada mensaje en un diálogo. Del mismo modo, los marcadores de terminación indican cuándo es el turno del humano y de la IA para alternar la palabra.
4.1.2 Modelos de recompensa
Entrenamos un modelo de recompensa (MR) que cubre diferentes habilidades y lo construimos sobre puntos de control preentrenados. El objetivo del entrenamiento es el mismo que en Llama 2, pero eliminamos el término marginal en la función de pérdida porque observamos una mejora reducida a medida que aumenta el tamaño de los datos. Como en Llama 2, utilizamos todos los datos de preferencias para el modelado de recompensas tras filtrar las muestras con respuestas similares.
Además de los pares de preferencia de respuesta estándar (seleccionada, rechazada), la anotación crea una tercera "respuesta editada" para algunas pistas, en la que la respuesta seleccionada del par se edita de nuevo para mejorarla (véase el apartado 4.2.1). Así, cada muestra de clasificación de preferencias tiene dos o tres respuestas claramente clasificadas (editada > seleccionada > rechazada). Durante el entrenamiento, concatenamos las pistas y las respuestas múltiples en una fila y aleatorizamos las respuestas. Se trata de una aproximación al escenario estándar de cálculo de puntuaciones colocando las respuestas en filas separadas, pero en nuestros experimentos de ablación este enfoque mejora la eficacia del entrenamiento sin pérdida de precisión.
4.1.3 Ajuste de la supervisión
En primer lugar, se rechazan las señales humanas etiquetadas para el muestreo mediante el modelo de recompensa, cuya metodología detallada se describe en la sección 4.2. Combinamos estos datos muestreados de rechazo con otras fuentes de datos (incluidos datos sintéticos) para ajustar el modelo lingüístico preentrenado utilizando pérdidas de entropía cruzada estándar, con el objetivo de predecir las marcas de destino (al tiempo que se enmascaran las pérdidas de las marcas marcadas). Consulte la sección 4.2 para obtener más información sobre la combinación de datos. Aunque muchos de los objetivos de entrenamiento son generados por el modelo, nos referimos a esta fase como ajuste fino supervisado (SFT; Wei et al. 2022a; Sanh et al. 2022; Wang et al. 2022b).
Nuestro modelo máximo se ajusta con una tasa de aprendizaje de 1e-5 en 8,5K a 9K pasos. Estos hiperparámetros resultan adecuados para diferentes rondas y combinaciones de datos.
4.1.4 Optimización directa de las preferencias
Seguimos entrenando nuestros modelos SFT para la alineación de preferencias humanas mediante la Optimización Directa de Preferencias (OPD; Rafailov et al., 2024). En el entrenamiento, utilizamos principalmente los últimos lotes de datos de preferencias recopilados de los modelos con mejor rendimiento en la ronda anterior de alineación. Como resultado, nuestros datos de entrenamiento se ajustan mejor a la distribución de los modelos de estrategia optimizados en cada ronda. También exploramos algoritmos de estrategia como PPO (Schulman et al., 2017), pero descubrimos que DPO requiere menos computación y funciona mejor en modelos a gran escala, especialmente en puntos de referencia de cumplimiento de instrucciones como IFEval (Zhou et al., 2023).
Para Llama 3, utilizamos una tasa de aprendizaje de 1e-5 y fijamos el hiperparámetro β en 0,1. Además, aplicamos las siguientes modificaciones algorítmicas a la OPD:
- Enmascaramiento de los marcadores de formato en las pérdidas de RPD. Enmascaramos los marcadores de formato especiales (incluidos los marcadores de cabecera y terminación descritos en la sección 4.1.1) de las respuestas seleccionadas y rechazadas para estabilizar el entrenamiento de OPD. Observamos que la participación de estos marcadores en la pérdida puede dar lugar a un comportamiento no deseado del modelo, como la duplicación de la cola o la generación repentina de marcadores de terminación. Nuestra hipótesis es que esto se debe a la naturaleza contrastada de la pérdida de OPD: la presencia de marcadores comunes tanto en las respuestas seleccionadas como en las rechazadas puede conducir a objetivos de aprendizaje contradictorios, ya que el modelo necesita aumentar y disminuir simultáneamente la probabilidad de estos marcadores.
- Regularización mediante pérdidas NLL: la Añadimos un término de pérdida de log-verosimilitud negativa (NLL) adicional a las secuencias seleccionadas con un factor de escala de 0,2, similar al de Pang et al. (2024). Esto ayuda a estabilizar aún más el entrenamiento de OPD manteniendo el formato necesario para la generación y evitando que disminuya la log-verosimilitud de las respuestas seleccionadas (Pang et al., 2024; Pal et al., 2024).
4.1.5 Promedio de modelos
Por último, promediamos los modelos obtenidos en experimentos utilizando varias versiones de datos o hiperparámetros en cada etapa de MR, SFT o OPD (Izmailov et al. 2019; Wortsman et al. 2022; Li et al. 2022). Presentamos información estadística sobre los datos de preferencias humanas recopilados internamente y utilizados para el condicionamiento de Llama 3. Pedimos a los evaluadores que participaran en varias rondas de diálogo con el modelo y comparamos las respuestas de cada ronda. Durante el posprocesamiento, dividimos cada diálogo en varios ejemplos, cada uno de los cuales contenía una indicación (incluido el diálogo anterior, si estaba disponible) y una respuesta (por ejemplo, una respuesta seleccionada o rechazada).

4.1.6 Rondas de iteración
Siguiendo a Llama 2, aplicamos la metodología anterior durante seis rondas de iteraciones. En cada ronda, recopilamos nuevos datos de etiquetado y ajuste de preferencias (SFT) y muestreamos datos sintéticos del último modelo.
4.2 Datos posteriores a la formación
La composición de los datos posteriores al entrenamiento desempeña un papel crucial en la utilidad y el comportamiento del modelo lingüístico. En esta sección, analizamos nuestro procedimiento de anotación y recopilación de datos de preferencias (Sección 4.2.1), la composición de los datos SFT (Sección 4.2.2) y los métodos de control de calidad y limpieza de datos (Sección 4.2.3).
4.2.1 Preferencias
Nuestro proceso de etiquetado de datos de preferencias es similar al de Llama 2. Después de cada ronda, desplegamos múltiples modelos para la anotación y muestreamos dos respuestas de diferentes modelos para cada pista de usuario. Estos modelos pueden entrenarse utilizando diferentes esquemas de combinación y alineación de datos, lo que da lugar a diferentes capacidades (por ejemplo, experiencia en código) y a una mayor diversidad de datos. Pedimos a los anotadores que clasificaran las puntuaciones de preferencia en uno de cuatro niveles según su nivel de preferencia: significativamente mejor, mejor, ligeramente mejor o ligeramente mejor.
También hemos incluido un paso de edición después de la ordenación de preferencias para animar al anotador a refinar aún más la respuesta preferida. El anotador puede editar directamente la respuesta seleccionada o utilizar el modelo de pista de retroalimentación para refinar su propia respuesta. Como resultado, algunos datos de preferencias tienen tres respuestas ordenadas (Editar > Seleccionar > Rechazar).
Las estadísticas de anotación de preferencias que utilizamos para el entrenamiento de Llama 3 se recogen en la Tabla 6. El inglés general abarca varias subcategorías, como las preguntas y respuestas basadas en el conocimiento o el seguimiento preciso de instrucciones, que quedan fuera del alcance de las habilidades específicas. En comparación con Llama 2, observamos un aumento de la longitud media de las preguntas y respuestas, lo que sugiere que estamos entrenando a Llama 3 en tareas más complejas. Además, implementamos un proceso de análisis de calidad y evaluación manual para evaluar de forma crítica los datos recopilados, lo que nos permitió perfeccionar las preguntas y proporcionar comentarios sistemáticos y procesables a los anotadores. Por ejemplo, a medida que Llama 3 mejore en cada ronda, aumentaremos la complejidad de las indicaciones para centrarnos en las áreas en las que el modelo se está quedando atrás.
En cada ronda de entrenamiento tardío, utilizamos todos los datos de preferencias disponibles en ese momento para el modelado de recompensas, y sólo los lotes más recientes de cada capacidad para el entrenamiento de OPD. Tanto para la modelización de recompensas como para la OPD, entrenamos con muestras etiquetadas como "respuesta de selección significativamente mejor o mejor" y descartamos las muestras con respuestas similares.
4.2.2 Datos SFT
Nuestros datos de ajuste proceden principalmente de las siguientes fuentes:
- Cuestiones de nuestra colección anotada manualmente y su rechazo a las respuestas de muestreo
- Datos sintéticos para capacidades específicas (véase la sección 4.3 para más detalles)
- Pequeña cantidad de datos etiquetados manualmente (véase la sección 4.3 para más detalles)
A medida que avanzábamos en nuestro ciclo de post-entrenamiento, desarrollamos variantes más potentes de Llama 3 y las utilizamos para recopilar conjuntos de datos más grandes para cubrir una amplia gama de capacidades complejas. En esta sección, analizamos los detalles del proceso de muestreo de rechazo y la composición general de la mezcla final de datos SFT.
Negativa a tomar muestras.En el muestreo de rechazo (RS), por cada pista que recogemos durante la anotación manual (Sección 4.2.1), muestreamos K salidas de la estrategia de modelado de chat más reciente (normalmente los mejores puntos de control de ejecución de la iteración de post-entrenamiento anterior, o los mejores puntos de control de ejecución para una competencia concreta) y utilizamos nuestro modelo de recompensa para seleccionar el mejor candidato, en línea con Bai et al. (2022). En etapas posteriores del post-entrenamiento, introducimos pistas del sistema para guiar las respuestas de las RS para que se ajusten a un tono, estilo o formato deseados, que pueden variar según las distintas capacidades.
Para mejorar la eficiencia del muestreo de rechazo, empleamos PagedAttention (Kwon et al., 2023).PagedAttention mejora la eficiencia de la memoria mediante la asignación dinámica de memoria caché clave-valor. Admite una longitud de salida arbitraria programando dinámicamente las solicitudes en función de la capacidad actual de la caché. Desafortunadamente, esto introduce el riesgo de swapping cuando la memoria se agota. Para eliminar esta sobrecarga de intercambio, definimos una longitud máxima de salida y sólo ejecutamos las peticiones si hay memoria suficiente para almacenar salidas de esa longitud. pagedAttention también nos permite compartir la página de caché de valor clave sugerida entre todas las salidas correspondientes. En conjunto, esto se tradujo en un aumento de más del doble en el rendimiento durante el muestreo de rechazo.
Composición de los datos agregados.La tabla 7 muestra las estadísticas de cada una de las categorías generales de datos de nuestra mezcla de "utilidad". Aunque los datos de SFT y los de preferencias contienen ámbitos que se solapan, su tratamiento es diferente, lo que da lugar a estadísticas de recuento distintas. En la sección 4.2.3 se describen las técnicas utilizadas para clasificar la materia, la complejidad y la calidad de nuestras muestras de datos. En cada ronda de post-entrenamiento, afinamos cuidadosamente nuestra combinación global de datos para ajustar el rendimiento en múltiples ejes para una amplia gama de puntos de referencia. Nuestra combinación final de datos se repetirá varias veces para determinadas fuentes de alta calidad y se reducirá para otras.

4.2.3 Tratamiento de datos y control de calidad
Teniendo en cuenta que la mayoría de nuestros datos de formación son generados por modelos, es necesario realizar una limpieza y un control de calidad minuciosos.
Depuración de datos: En las primeras fases, observamos muchos patrones no deseados en los datos, como el uso excesivo de emoticonos o signos de exclamación. Por ello, aplicamos una serie de estrategias de eliminación y modificación de datos basadas en reglas para filtrar o eliminar los datos problemáticos. Por ejemplo, para mitigar el problema de la entonación excesivamente apologética, identificábamos las frases demasiado utilizadas (por ejemplo, "lo siento" o "pido disculpas") y equilibrábamos cuidadosamente la proporción de tales muestras en el conjunto de datos.
Poda de datos: También aplicamos una serie de técnicas basadas en modelos para eliminar las muestras de entrenamiento de baja calidad y mejorar el rendimiento general del modelo:
- Clasificación por materias: Primero ajustamos Llama 3 8B para convertirlo en un clasificador de temas y razonamos sobre todos los datos para clasificarlos en categorías de grano grueso ("Razonamiento matemático") y categorías de grano fino ("Geometría y trigonometría").
- Índice de calidad: Utilizamos el modelo de recompensa y las señales basadas en Llama para obtener puntuaciones de calidad para cada muestra. Para las puntuaciones basadas en RM, consideramos los datos con puntuaciones en el cuartil más alto como de alta calidad. Para las puntuaciones basadas en Llama, pedimos a los puntos de control de Llama 3 que puntuaran los datos de inglés general en tres niveles (precisión, cumplimiento de las instrucciones y tono/presentación) y los datos de código en dos niveles (reconocimiento de errores e intención del usuario) y consideramos las muestras que recibieron las puntuaciones más altas como datos de alta calidad. Las puntuaciones basadas en RM y Llama tienen altos índices de conflicto, y descubrimos que la combinación de estas señales daba como resultado la mejor recuperación para el conjunto de pruebas internas. En última instancia, seleccionamos los ejemplos etiquetados como de alta calidad por los filtros basados en RM o en Llama.
- Grado de dificultad: Como también nos interesaba dar prioridad a los ejemplos de modelos más complejos, puntuamos los datos utilizando dos métricas de dificultad: la puntuación Instag (Lu et al., 2023) y la puntuación basada en Llama. Para Instag, pedimos a Llama 3 70B que realizara el etiquetado de intención en las pistas SFT, donde más intención implica mayor complejidad. También pedimos a Llama 3 que midiera la dificultad del diálogo en tres niveles (Liu et al., 2024c).
- Desenfatización semántica: Por último, realizamos la desduplicación semántica (Abbas et al., 2023; Liu et al., 2024c). En primer lugar, agrupamos los diálogos completos mediante RoBERTa (Liu et al., 2019b) y los clasificamos por puntuación de calidad × puntuación de dificultad en cada grupo. A continuación, realizamos una selección codiciosa iterando sobre todos los ejemplos ordenados, manteniendo solo aquellos cuya similitud coseno máxima con los ejemplos vistos en los clústeres hasta el momento es inferior a un umbral.
4.3 Capacidad
En particular, destacamos algunos de los esfuerzos realizados para mejorar competencias específicas, como el manejo de códigos (sección 4.3.1), el multilingüismo (sección 4.3.2), las habilidades matemáticas y de razonamiento (sección 4.3.3), la contextualización a largo plazo (sección 4.3.4), el uso de herramientas (sección 4.3.5), la facticidad (sección 4.3.6) y la controlabilidad (sección 4.3.7).
4.3.1 Código
desde (un tiempo) Copiloto y Codex (Chen et al., 2021), los LLM para código han recibido mucha atención. Los desarrolladores utilizan ahora ampliamente estos modelos para generar fragmentos de código, depurar, automatizar tareas y mejorar la calidad del código. Para Llama 3, nuestro objetivo es mejorar y evaluar las capacidades de generación, documentación, depuración y revisión de código para los siguientes lenguajes de programación prioritarios: Python, Java, JavaScript, C/C++, TypeScript, Rust, PHP, HTML/CSS, SQL y bash/shell.Aquí, presentamos los resultados obtenidos al la formación de expertos en código, la generación de datos sintéticos para SFT, el paso a formatos mejorados mediante avisos del sistema y la creación de filtros de calidad para eliminar las muestras malas de los datos de formación con el fin de mejorar estas funciones de codificación.
Formación especializada.Entrenamos a un experto en código y lo utilizamos en múltiples rondas de post-entrenamiento para recopilar anotaciones de código humano de alta calidad. Esto se consiguió desviando el preentrenamiento principal y continuando con el preentrenamiento en una mezcla de tokens de 1T que eran principalmente (>85%) datos de código. Se ha demostrado que el preentrenamiento continuado con datos de dominios específicos es eficaz para mejorar el rendimiento en dominios específicos (Gururangan et al., 2020). Seguimos una receta similar a la de CodeLlama (Rozière et al., 2023). En los últimos miles de pasos del entrenamiento, realizamos un ajuste fino del contexto largo (LCFT) en una mezcla de alta calidad de datos de código a nivel de repositorio, ampliando la longitud del contexto del experto a 16.000 tokens. Por último, seguimos una receta de modelado post-entrenamiento similar a la descrita en la sección 4.1 para alinear el modelo, pero utilizando una mezcla de datos SFT y DPO que son principalmente específicos del código. El modelo también se utiliza para el muestreo de rechazo de pistas de codificación (sección 4.2.2).
Generación de datos sintéticos.Durante el desarrollo, identificamos problemas clave en la generación de código, como la dificultad para seguir instrucciones, los errores de sintaxis del código, la generación de código incorrecto y la dificultad para corregir errores. Aunque las anotaciones humanas densas podrían resolver en teoría estos problemas, la generación de datos sintéticos ofrece un enfoque complementario que es más barato, se adapta mejor y no está limitado por el nivel de experiencia de los anotadores.
Por lo tanto, utilizamos Llama 3 y Code Expert para generar un gran número de diálogos SFT sintéticos. Describimos tres métodos de alto nivel para generar datos de código sintéticos. En total, utilizamos más de 2,7 millones de ejemplos sintéticos durante el SFT.
1. Generación de datos sintéticos: aplicación de la retroalimentación.Los modelos 8B y 70B muestran mejoras significativas de rendimiento con datos de entrenamiento generados por modelos más grandes y competentes. Sin embargo, nuestros experimentos preliminares muestran que entrenar sólo a Llama 3 405B con sus propios datos generados no ayuda (o incluso degrada el rendimiento). Para abordar esta limitación, introducimos la retroalimentación de la ejecución como fuente de verdad que permite al modelo aprender de sus errores y mantenerse en el buen camino. En concreto, generamos un conjunto de datos de aproximadamente un millón de diálogos de código sintético mediante el siguiente procedimiento:
- Generación de la descripción del problema:En primer lugar, generamos un amplio conjunto de descripciones de problemas de programación que abarcaban una gran variedad de temas (incluidas las distribuciones de cola larga). Para lograr esta diversidad, muestreamos aleatoriamente fragmentos de código de diversas fuentes y pedimos al modelo que generara problemas de programación basados en estos ejemplos. Esto nos permitió aprovechar una amplia gama de temas y crear un conjunto exhaustivo de descripciones de problemas (Wei et al., 2024).
- Generación de soluciones:A continuación, pedimos a Llama 3 que resolviera cada problema en el lenguaje de programación dado. Observamos que añadir buenas reglas de programación a las instrucciones mejoraba la calidad de las soluciones generadas. Además, nos pareció útil pedir al modelo que explicara su proceso de pensamiento con anotaciones.
- Análisis de corrección: Una vez generadas las soluciones, es fundamental reconocer que su corrección no está garantizada y que la inclusión de soluciones incorrectas en el conjunto de datos ajustado puede comprometer la calidad del modelo. Aunque no podemos garantizar una corrección completa, hemos desarrollado métodos para aproximarnos a ella. Para ello, tomamos el código fuente extraído de las soluciones generadas y aplicamos una combinación de técnicas de análisis estático y dinámico para comprobar su corrección:
- Análisis estático: Pasamos todo el código generado por un analizador sintáctico y herramientas de comprobación de código para garantizar la corrección sintáctica, detectar errores de sintaxis, uso de variables no inicializadas o funciones no importadas, problemas de estilo del código, errores tipográficos, etc.
- Generación y ejecución de pruebas unitarias: Para cada problema y solución, pedimos al modelo que genere pruebas unitarias y las ejecute con la solución en un entorno de contenedores, detectando errores de ejecución en tiempo de ejecución y algunos errores semánticos.
- Retroalimentación de errores y autocorrección iterativa: Cuando la solución falla en cualquier paso, pedimos al modelo que la modifique. El aviso contiene la descripción original del problema, la solución errónea y la información procedente del analizador sintáctico/herramienta de inspección de código/programa de pruebas (salida estándar, error estándar y código de retorno). Tras un fallo en la ejecución de una prueba unitaria, el modelo puede arreglar el código para que pase las pruebas existentes o modificar sus pruebas unitarias para que se ajusten al código generado. Sólo los diálogos que superan todas las comprobaciones se incluyen en el conjunto de datos final para el ajuste fino supervisado (SFT). En particular, observamos que aproximadamente 20% de las soluciones eran inicialmente incorrectas pero se autocorregían, lo que sugiere que el modelo aprendió de la retroalimentación de la ejecución y mejoró su rendimiento.
- Puesta a punto y mejora iterativa: El proceso de ajuste se realiza en varias rondas, cada una de las cuales se basa en la anterior. Después de cada ronda de ajuste, el modelo se mejora para generar datos sintéticos de mayor calidad para la siguiente ronda. Este proceso iterativo permite perfeccionar y mejorar el rendimiento del modelo.
2. Generación de datos sintéticos: traducción de lenguajes de programación. Observamos una diferencia de rendimiento entre los principales lenguajes de programación (por ejemplo, Python/C++) y los menos comunes (por ejemplo, Typescript/PHP). Esto no es sorprendente, ya que disponemos de menos datos de entrenamiento para los lenguajes de programación menos comunes. Para mitigar esto, complementaremos los datos disponibles traduciendo datos de lenguajes de programación comunes a lenguajes menos comunes (similar a Chen et al. (2023) en el campo de la inferencia). Esto se consigue solicitando a Llama 3 y garantizando la calidad mediante el análisis sintáctico, la compilación y la ejecución. La Figura 8 muestra un ejemplo de código PHP sintético traducido desde Python. Esto mejora significativamente el rendimiento de los lenguajes menos comunes medido por el benchmark MultiPL-E (Cassano et al., 2023).
3. Generación de datos sintéticos: traducción inversa. Para mejorar ciertas capacidades de codificación (por ejemplo, documentación, interpretación) en las que la cantidad de información procedente de la retroalimentación de la ejecución es insuficiente para determinar la calidad, utilizamos otro enfoque de varios pasos. Mediante este proceso, generamos aproximadamente 1,2 millones de diálogos sintéticos relacionados con la interpretación, generación, documentación y depuración de código. Empezamos con fragmentos de código en varios idiomas procedentes de los datos de preentrenamiento:


- Generar: Pedimos a Llama 3 que generara datos que representaran las capacidades objetivo (por ejemplo, añadiendo comentarios y cadenas de documentación a un fragmento de código, o pidiendo al modelo que interpretara un fragmento de código).
- Traducción inversa. Pedimos al modelo que "retrotraduzca" los datos generados sintéticamente al código original (por ejemplo, pedimos al modelo que genere código sólo a partir de sus documentos, o pedimos al modelo que genere código sólo a partir de sus explicaciones).
- Filtración. Utilizando el código original como referencia, pedimos a Llama 3 que determine la calidad del resultado (por ejemplo, preguntamos al modelo cómo de fiel es el código retrotraducido al código original). A continuación, utilizamos el ejemplo generado con la mayor puntuación de autovalidación en SFT.
Guía de avisos del sistema para rechazar muestras. Durante el muestreo de rechazo, utilizamos pistas del sistema específicas del código para mejorar la legibilidad, la documentación, la integridad y la concreción del código. Recordemos que en la sección 7 estos datos se utilizan para ajustar el modelo lingüístico. La figura 9 muestra un ejemplo de cómo las pistas del sistema pueden ayudar a mejorar la calidad del código generado: añade los comentarios necesarios, utiliza nombres de variables más informativos, ahorra memoria, etc.
Filtrado de datos de formación utilizando la ejecución y el modelo como rúbrica. Como se describe en la sección 4.2.3, ocasionalmente encontramos problemas de calidad en los datos de muestreo de rechazo, como la inclusión de bloques de código erróneos. Detectar estos problemas en los datos de muestreo de rechazo no es tan sencillo como detectar nuestros datos de código sintético, porque las respuestas de muestreo de rechazo a menudo contienen una mezcla de lenguaje natural y código que no siempre es ejecutable. (Por ejemplo, las peticiones de los usuarios pueden pedir explícitamente pseudocódigo o ediciones de sólo partes muy pequeñas del ejecutable). Para abordar este problema, utilizamos un enfoque de "modelo como juez", en el que se evalúan versiones anteriores de Llama 3 y se les asigna una puntuación binaria (0/1) basada en dos criterios: corrección y estilo del código. Sólo se retuvieron las muestras con una puntuación perfecta de 2. En un principio, este estricto filtrado provocó una degradación del rendimiento del benchmark aguas abajo, principalmente porque eliminaba de forma desproporcionada las muestras con pistas desafiantes. Para contrarrestarlo, modificamos estratégicamente algunas de las respuestas categorizadas como los datos codificados más desafiantes hasta que cumplieron los criterios de "modelo como juez" basados en Llama. Al mejorar estas preguntas desafiantes, los datos codificados equilibraron calidad y dificultad para lograr un rendimiento descendente óptimo.
4.3.2 Multilingüismo
Esta sección describe cómo hemos mejorado las capacidades multilingües de Llama 3, incluyendo: el entrenamiento de un modelo experto especializado en más datos multilingües; la obtención y generación de datos afinados de alta calidad de comandos multilingües para alemán, francés, italiano, portugués, hindi, español y tailandés; y la resolución de los retos específicos del bootstrapping multilingüe para mejorar el rendimiento general de nuestro modelo.
Formación especializada.Nuestra mezcla de datos de preentrenamiento de Llama 3 contiene muchos más tokens en inglés que en otros idiomas. Con el fin de recopilar anotaciones humanas no inglesas de mayor calidad, entrenamos un modelo experto multilingüe bifurcando las ejecuciones de preentrenamiento y continuando el preentrenamiento en una mezcla de datos que contiene 901 tokens multilingüesTP3T. A continuación, realizamos el postentrenamiento de este modelo experto tal y como se describe en la sección 4.1. A continuación, este modelo experto se utiliza para recopilar anotaciones humanas de mayor calidad en lengua no inglesa hasta que se haya completado el preentrenamiento.
Recogida multilingüe de datos.Nuestros datos multilingües de SFT proceden principalmente de las siguientes fuentes. La distribución global es de 2,41 TP3T de anotaciones humanas, 44,21 TP3T de datos de otras tareas de PLN, 18,81 TP3T de datos de muestreo de rechazo y 34,61 TP3T de datos de inferencia de traducción.
- Anotación manual:Recopilamos datos de alta calidad anotados manualmente por lingüistas y hablantes nativos. Estas anotaciones consisten principalmente en pistas abiertas que representan casos de uso del mundo real.
- Datos de otras tareas de PNL:Para seguir mejorando, utilizamos datos de entrenamiento multilingües de otras tareas y los reescribimos en formato de diálogo. Por ejemplo, utilizamos datos de exams-qa (Hardalov et al., 2020) y Conic10k (Wu et al., 2023). Para mejorar la alineación lingüística, también utilizamos textos paralelos de GlobalVoices (Prokopidis et al., 2016) y Wikimedia (Tiedemann, 2012). Utilizamos el filtrado basado en LID y Blaser 2.0 (Seamless Communication et al., 2023) para eliminar los datos de baja calidad. Para los datos de textos paralelos, en lugar de utilizar pares de bi-textos directamente, aplicamos una plantilla multilingüe inspirada en Wei et al. (2022a) para simular mejor los diálogos reales en escenarios de traducción y aprendizaje de idiomas.
- Rechazar datos de muestreo:Aplicamos el muestreo de rechazo a las claves anotadas por humanos para generar muestras de alta calidad para el ajuste fino, con pocas modificaciones en comparación con el proceso para los datos en inglés:
- Generación: exploramos la selección aleatoria de hiperparámetros de temperatura en el rango de 0,2 -1 en las primeras rondas de post-entrenamiento para diversificar la generación. Cuando se utilizan temperaturas altas, las respuestas a las señales multilingües pueden llegar a ser creativas e inspiradoras, pero también pueden ser propensas a cambios de código innecesarios o antinaturales. En las fases finales del postentrenamiento, utilizamos un valor constante de 0,6 para equilibrar esta compensación. Además, utilizamos claves especializadas del sistema para mejorar el formato, la estructura y la legibilidad general de las respuestas.
- Selección: antes de la selección basada en modelos de recompensa, se realizaron comprobaciones específicas multilingües para garantizar un alto índice de coincidencias lingüísticas entre las preguntas y las respuestas (por ejemplo, no se debe esperar que las preguntas en hindi romanizado se respondan en sánscrito hindi).
- Datos de traducción:Intentamos evitar el uso de datos de traducción automática para afinar el modelo con el fin de evitar la aparición del inglés traducido (Bizzoni et al., 2020; Muennighoff et al., 2023) o posibles sesgos de nombre (Wang et al., 2022a), de género (Savoldi et al., 2021) o culturales (Ji et al., 2023). . Además, pretendíamos evitar que el modelo se expusiera únicamente a tareas arraigadas en contextos culturales angloparlantes, que podrían no ser representativos de la diversidad lingüística y cultural que pretendíamos captar. Hicimos una excepción y tradujimos los datos de razonamiento cuantitativo sintetizados (para más información, véase el apartado 4.3.3) a lenguas distintas del inglés para mejorar el rendimiento del razonamiento cuantitativo en lenguas distintas del inglés. Debido a la sencillez del lenguaje de estos problemas matemáticos, las muestras traducidas presentaban pocos problemas de calidad. Observamos ganancias significativas al añadir estos datos traducidos al MGSM (Shi et al., 2022).
4.3.3 Matemáticas y razonamiento
Definimos el razonamiento como la capacidad de realizar un cálculo de varios pasos y llegar a la respuesta final correcta.
Varios retos guiaron nuestro planteamiento para entrenar modelos que destaquen en razonamiento matemático:
- Falta de propinas. A medida que aumenta la complejidad de los problemas, disminuye el número de pistas o problemas válidos para el ajuste fino supervisado (SFT). Esta escasez dificulta la creación de conjuntos de datos de entrenamiento diversos y representativos para enseñar a los modelos diversas habilidades matemáticas (Yu et al. 2023; Yue et al. 2023; Luo et al. 2023; Mitra et al. 2024; Shao et al. 2024; Yue et al. 2024b).
- Falta de procesos de razonamiento reales. Un razonamiento eficaz requiere soluciones paso a paso para facilitar el proceso de razonamiento (Wei et al., 2022c). Sin embargo, a menudo faltan procesos de razonamiento realistas que sean esenciales para guiar al modelo sobre cómo descomponer progresivamente el problema y llegar a la respuesta final (Zelikman et al., 2022).
- Paso intermedio incorrecto. Cuando se utilizan cadenas de inferencia generadas por modelos, es posible que los pasos intermedios no siempre sean correctos (Cobbe et al. 2021; Uesato et al. 2022; Lightman et al. 2023; Wang et al. 2023a). Esta imprecisión puede dar lugar a respuestas finales incorrectas y debe abordarse.
- Entrenamiento del modelo mediante herramientas externas. La capacidad de mejorar los modelos para utilizar herramientas externas como intérpretes de código les permite razonar entrelazando código y texto (Gao et al. 2023; Chen et al. 2022; Gou et al. 2023). Esta capacidad puede mejorar significativamente sus habilidades para resolver problemas.
- Diferencias entre formación y razonamiento: la El modo en que se ajustan los modelos durante el entrenamiento suele diferir del modo en que se utilizan durante el razonamiento. Durante el razonamiento, el modelo perfeccionado puede interactuar con personas u otros modelos y necesitar información para mejorar su razonamiento. Garantizar la coherencia entre el entrenamiento y las aplicaciones del mundo real es fundamental para mantener el rendimiento de la inferencia.
Para abordar estos retos, aplicamos la siguiente metodología:
- Resolver la falta de indicios. Tomamos datos de preentrenamiento relevantes de contextos matemáticos y los convertimos en un formato de pregunta-respuesta que puede utilizarse para el ajuste supervisado. Además, identificamos las destrezas matemáticas en las que el modelo rinde mal y recogemos activamente pistas de los humanos para enseñar al modelo estas destrezas. Para facilitar este proceso, creamos una taxonomía de destrezas matemáticas (Didolkar et al., 2024) y pedimos a los humanos que proporcionen las indicaciones/preguntas correspondientes.
- Aumento de los datos de entrenamiento con pasos de razonamiento paso a paso. Utilizamos Llama 3 para generar soluciones paso a paso para un conjunto de pistas. Para cada indicación, el modelo produce un número variable de resultados generados. Estos resultados generados se filtran en función de la respuesta correcta (Li et al., 2024a). También realizamos una autovalidación, en la que Llama 3 se utiliza para verificar que una solución paso a paso concreta es válida para un problema determinado. Este proceso mejora la calidad de los datos ajustados eliminando los casos en los que el modelo no produce trayectorias de inferencia válidas.
- Filtrado de pasos de razonamiento erróneos. Entrenamos resultados y modelos de recompensa por pasos (Lightman et al., 2023; Wang et al., 2023a) para filtrar los datos de entrenamiento con pasos de inferencia intermedios incorrectos. Estos modelos de recompensa se utilizan para eliminar los datos con inferencia escalonada no válida, lo que garantiza que el ajuste fino produzca datos de alta calidad. Para pistas más difíciles, utilizamos la búsqueda en árbol Monte Carlo (MCTS) con modelos de recompensa por pasos aprendidos para generar trayectorias de inferencia válidas, lo que mejora aún más la recopilación de datos de inferencia de alta calidad (Xie et al., 2024).
- Códigos entrelazados y razonamiento textual. Sugerimos que Llama 3 resuelva el problema de la inferencia mediante una combinación de inferencia textual y su código Python asociado (Gou et al., 2023). La ejecución del código se utiliza como señal de retroalimentación para eliminar los casos en los que la cadena de inferencia no es válida y garantizar la corrección del proceso de inferencia.
- Aprender de los comentarios y los errores. Para simular la retroalimentación humana, utilizamos resultados de generación incorrectos (es decir, resultados de generación que conducen a trayectorias de inferencia incorrectas) y realizamos correcciones de errores indicando a Llama 3 que genere resultados de generación correctos (An et al. 2023b; Welleck et al. 2022; Madaan et al. 2024a). El proceso autoiterativo de utilizar la retroalimentación de los intentos incorrectos y corregirlos ayuda a mejorar la capacidad del modelo para razonar con precisión y aprender de sus errores.
4.3.4 Contextos largos
En la fase final de preentrenamiento, ampliamos la longitud del contexto de Llama 3 de 8.000 a 128.000 tokens (véase la sección 3.4 para más información al respecto). Al igual que en el preentrenamiento, descubrimos que durante la puesta a punto había que ajustar cuidadosamente la formulación para equilibrar las capacidades de contextos cortos y largos.
SFT y generación de datos sintéticos. La mera aplicación de nuestra formulación SFT existente utilizando únicamente datos de contextos cortos dio lugar a una disminución significativa de la capacidad de contextos largos en el preentrenamiento, lo que pone de relieve la necesidad de incorporar datos de contextos largos en la cartera de datos de la SFT. En la práctica, sin embargo, no resulta práctico etiquetar manualmente la mayoría de estos ejemplos, ya que leer contextos largos es tedioso y lleva mucho tiempo, por lo que recurrimos en gran medida a datos sintéticos para salvar esta laguna. Utilizamos una versión anterior de Llama 3 para generar datos sintéticos basados en los principales casos de uso de contextos largos: (potencialmente múltiples rondas de) preguntas y respuestas, resúmenes de documentos largos y razonamiento sobre el código base, y describimos estos casos de uso con más detalle a continuación.
- PREGUNTAS Y RESPUESTAS: Seleccionamos cuidadosamente un conjunto de documentos largos del conjunto de datos de preentrenamiento. Dividimos estos documentos en 8.000 trozos etiquetados e incitamos a una versión anterior del modelo Llama 3 a generar pares de GC en trozos seleccionados al azar. El documento completo se utiliza como contexto durante el entrenamiento.
- Resúmenes: Aplicamos el resumen jerárquico de documentos de contexto largo utilizando primero nuestro modelo de contexto Llama 3 8K más potente para resumir jerárquicamente bloques de 8K de longitud de entrada. A continuación, se agregan estos resúmenes. Durante el entrenamiento, proporcionamos el documento completo y pedimos al modelo que lo resuma conservando todos los detalles importantes. También generamos pares de control de calidad basados en los resúmenes de los documentos y planteamos al modelo preguntas que requieren una comprensión global de todo el documento largo.
- Razonamiento de código de contexto largo: Analizamos los archivos de Python para identificar las declaraciones de importación y determinar sus dependencias. A partir de aquí, seleccionamos los archivos más utilizados, concretamente aquellos a los que hacen referencia al menos otros cinco archivos. Eliminamos uno de estos archivos clave del repositorio y pedimos al modelo que identifique las dependencias de los archivos que faltan y genere el código necesario que falta.
Además, clasificamos estas muestras generadas sintéticamente según la longitud de la secuencia (16K, 32K, 64K y 128K) para una localización más precisa de la longitud de entrada.
Mediante cuidadosos experimentos de ablación, observamos que mezclar los datos de contexto largo generados sintéticamente de 0,1% con los datos de contexto corto originales optimiza el rendimiento de las pruebas de referencia tanto de contexto corto como largo.
DPO. Observamos que utilizar sólo datos de entrenamiento de contexto corto en la OPD no afecta negativamente al rendimiento de contexto largo, siempre que el modelo SFT funcione bien para tareas de contexto largo. Sospechamos que esto se debe a que nuestra formulación DPO tiene menos pasos de optimización que SFT. Teniendo en cuenta este hallazgo, mantenemos la formulación DPO estándar de contexto corto sobre los puntos de control SFT de contexto largo.
4.3.5 Utilización de herramientas
Enseñar a los grandes modelos lingüísticos (LLM) a utilizar herramientas como motores de búsqueda o intérpretes de código puede ampliar enormemente la gama de tareas que pueden resolver, transformándolos de modelos puramente parlanchines en asistentes más versátiles (Nakano et al. 2021; Thoppilan et al. 2022; Parisi et al. 2022; Gao et al. 2023 2022; Parisi et al. 2022; Gao et al. 2023; Mialon et al. 2023a; Schick et al. 2024). Entrenamos a Llama 3 para interactuar con las siguientes herramientas:
- Llama 3 fue entrenada para utilizar Brave Search7 a fin de responder a preguntas sobre acontecimientos recientes después de su fecha límite de conocimiento, o a peticiones que requieren la recuperación de información específica de la web.
- Intérprete de Python.Llama 3 genera y ejecuta código para realizar cálculos complejos, lee archivos cargados por el usuario y resuelve tareas basadas en estos archivos, como cuestionarios, resúmenes, análisis de datos o visualización.
- Motor de cálculo matemático.Llama 3 puede utilizar la API8 de Wolfram Alpha para resolver problemas matemáticos y científicos con mayor precisión, o para recuperar información precisa de las bases de datos de Wolfram.
El modelo generado es capaz de utilizar estas herramientas en un entorno de chat para resolver las consultas de los usuarios, incluidos los diálogos de varias rondas. Si la consulta requiere múltiples invocaciones de las herramientas, el modelo puede escribir planes paso a paso que invocan las herramientas secuencialmente y razonan después de cada invocación de la herramienta.
También mejoramos las capacidades de uso de herramientas de muestra cero de Llama 3: dadas las definiciones de herramientas potencialmente desconocidas y las consultas de los usuarios en un entorno contextual, entrenamos al modelo para que genere las llamadas a herramientas correctas.
Realización.Implementamos las herramientas principales como objetos Python con diferentes métodos. Las herramientas de muestra cero pueden implementarse como funciones Python con descripciones, documentación (es decir, ejemplos de cómo usarlas), y el modelo sólo necesita la firma de la función y el docstring como contexto para generar las llamadas apropiadas.
También convertimos las definiciones de las funciones y las llamadas al formato JSON, por ejemplo, para las llamadas a la Web API. Todas las llamadas a herramientas son ejecutadas por el intérprete de Python, que debe habilitarse en el indicador del sistema de Llama 3. Las herramientas principales pueden habilitarse o deshabilitarse por separado desde el indicador del sistema. Las herramientas principales pueden activarse o desactivarse por separado desde el indicador del sistema.
Recogida de datos.A diferencia de Schick et al. (2024), nos basamos en anotaciones y preferencias humanas para enseñar a Llama 3 a utilizar las herramientas. Esto difiere del proceso de post-entrenamiento utilizado normalmente en Llama 3 en dos aspectos clave:
- En cuanto a las herramientas, los diálogos suelen contener más de un mensaje de asistente (por ejemplo, invocación de una herramienta y razonamiento sobre el resultado de la herramienta). Por lo tanto, realizamos anotaciones a nivel de mensaje para recoger comentarios detallados: el anotador proporciona preferencias para dos mensajes de asistente en el mismo contexto, o edita uno de los mensajes si hay un problema importante con ambos. El mensaje seleccionado o modificado se añade al contexto y el diálogo continúa. De este modo, se obtiene información humana sobre la capacidad del asistente para invocar la herramienta y razonar sobre su resultado. El anotador no puede clasificar ni editar el resultado de la herramienta.
- No realizamos muestreo de rechazo porque no se observaron ganancias en nuestra herramienta de evaluación comparativa.
Con el fin de acelerar el proceso de anotación, en primer lugar hemos puesto a prueba las capacidades básicas de uso de la herramienta mediante el ajuste de los datos sintéticos de los puntos de control anteriores de Llama 3. De este modo, el anotador necesitará realizar menos operaciones de edición. Del mismo modo, a medida que Llama 3 mejora con el tiempo durante su desarrollo, complicamos progresivamente nuestro protocolo de anotación humana: empezamos con una única ronda de anotación del uso de herramientas, luego pasamos al uso de herramientas en diálogo y, por último, anotamos el uso de herramientas en varios pasos y el análisis de datos.
Conjunto de datos de herramientas.Con el fin de crear datos para su uso en aplicaciones que utilizan herramientas, seguimos los siguientes pasos.
- Uso de herramientas en un solo paso. En primer lugar, realizamos una pequeña generación de muestras para sintetizar las peticiones de los usuarios que, por construcción, requieren una llamada a una de nuestras herramientas principales (por ejemplo, una pregunta que excede nuestro plazo de conocimiento). A continuación, basándonos en una pequeña generación de muestras, generamos las llamadas a las herramientas adecuadas para estas sugerencias, las ejecutamos y añadimos el resultado al contexto del modelo. Por último, volvemos a pedir al modelo que genere la respuesta final a la consulta del usuario basándose en el resultado de la herramienta. Al final, obtenemos trayectorias de la siguiente forma: pistas del sistema, pistas del usuario, llamadas a la herramienta, resultados de la herramienta y respuestas finales. También filtramos aproximadamente 30% del conjunto de datos para eliminar las llamadas a herramientas no ejecutables u otros problemas de formato.
- Uso de herramientas de varios pasos. Seguimos un protocolo similar generando primero datos sintéticos para enseñar al modelo las capacidades 다단계 básicas de uso de herramientas. Para ello, primero pedimos a Llama 3 que genere pistas de usuario que requieran al menos dos invocaciones de herramientas (ya sea de la misma herramienta o de herramientas diferentes de nuestro conjunto básico). A continuación, basándonos en estas pistas, realizamos un pequeño número de muestras para incitar a Llama 3 a generar una solución que consista en pasos de inferencia entrelazados y llamadas a herramientas, similar a la ReAct (Yao et al., 2022). Véase en la Figura 10 un ejemplo de Llama 3 realizando una tarea que implica el uso de herramientas en varios pasos.
- Carga de archivos. Anotamos los siguientes tipos de archivos: .txt, .docx, .pdf, .pptx, .xlsx, .csv, .tsv, .py, .json, .jsonl, .html, .xml. Nuestras indicaciones se basan en los archivos suministrados y piden resumir el contenido de los archivos, encontrar y corregir errores, optimizar los fragmentos de código y realizar análisis o visualizaciones de datos. La figura 11 muestra un ejemplo de Llama 3 realizando una tarea que implica la carga de archivos.

Tras afinar estos datos sintéticos, recopilamos anotaciones humanas de diversos escenarios, como rondas múltiples de interacciones, uso de herramientas más allá de tres pasos y situaciones en las que la invocación de herramientas no producía respuestas satisfactorias. Aumentamos los datos sintéticos con distintas señales del sistema para enseñar al modelo a utilizar las herramientas sólo cuando estaban activadas. Para entrenar al modelo a evitar las llamadas a la herramienta para consultas sencillas, también añadimos consultas y sus respuestas de conjuntos de datos fáciles de calcular o de preguntas y respuestas (Berant et al. 2013; Koncel-Kedziorski et al. 2016; Joshi et al. 2017; Amini et al. 2019), que no utilizan la herramienta pero en los que las pistas del sistema activaron la herramienta.
Muestra cero de datos de uso de herramientas. Mejoramos la capacidad de Llama 3 para utilizar herramientas de muestra cero (también conocidas como llamadas a funciones) afinando una tupla grande y diversa de composiciones parciales (definiciones de funciones, consultas de usuario, llamadas correspondientes). Evaluamos nuestro modelo en una colección de herramientas desconocidas.
- Llamadas a funciones simples, anidadas y paralelas: Las llamadas pueden ser simples, anidadas (es decir, pasamos llamadas a funciones como argumentos a otra función) o paralelas (es decir, el modelo devuelve una lista de llamadas a funciones independientes). Generar una variedad de funciones, consultas y resultados reales puede suponer un reto (Mekala et al., 2024), por lo que nos basamos en la minería de la Pila (Kocetkov et al., 2022) para basar nuestras consultas sintéticas de usuario en funciones reales. Más concretamente, extraemos las llamadas a funciones y sus definiciones, las limpiamos y filtramos (por ejemplo, cadenas de documentos que faltan o funciones no ejecutables), y utilizamos Llama 3 para generar consultas en lenguaje natural correspondientes a las llamadas a funciones.
- Llamadas a funciones de varias rondas: También generamos datos sintéticos para diálogos de varias rondas que contienen llamadas a funciones, siguiendo un protocolo similar al presentado en Li et al. (2023b). Utilizamos múltiples agentes para generar dominios, APIs, consultas de usuarios, llamadas a APIs y respuestas, asegurando al mismo tiempo que los datos generados cubren un rango de diferentes dominios y APIs reales.Todos los agentes son variantes de Llama 3, incitados de una forma que depende de sus responsabilidades y colaboran de forma escalonada.
4.3.6 Hechos
La irrealidad sigue siendo un reto importante para los grandes modelos lingüísticos. Los modelos tienden a ser demasiado confiados, incluso en dominios en los que carecen de conocimientos. A pesar de estos defectos, a menudo se utilizan como bases de conocimiento, lo que puede conducir a resultados peligrosos, como la difusión de información errónea. Aunque reconocemos que la veracidad trasciende la ilusión, aquí adoptamos un enfoque que antepone la ilusión.
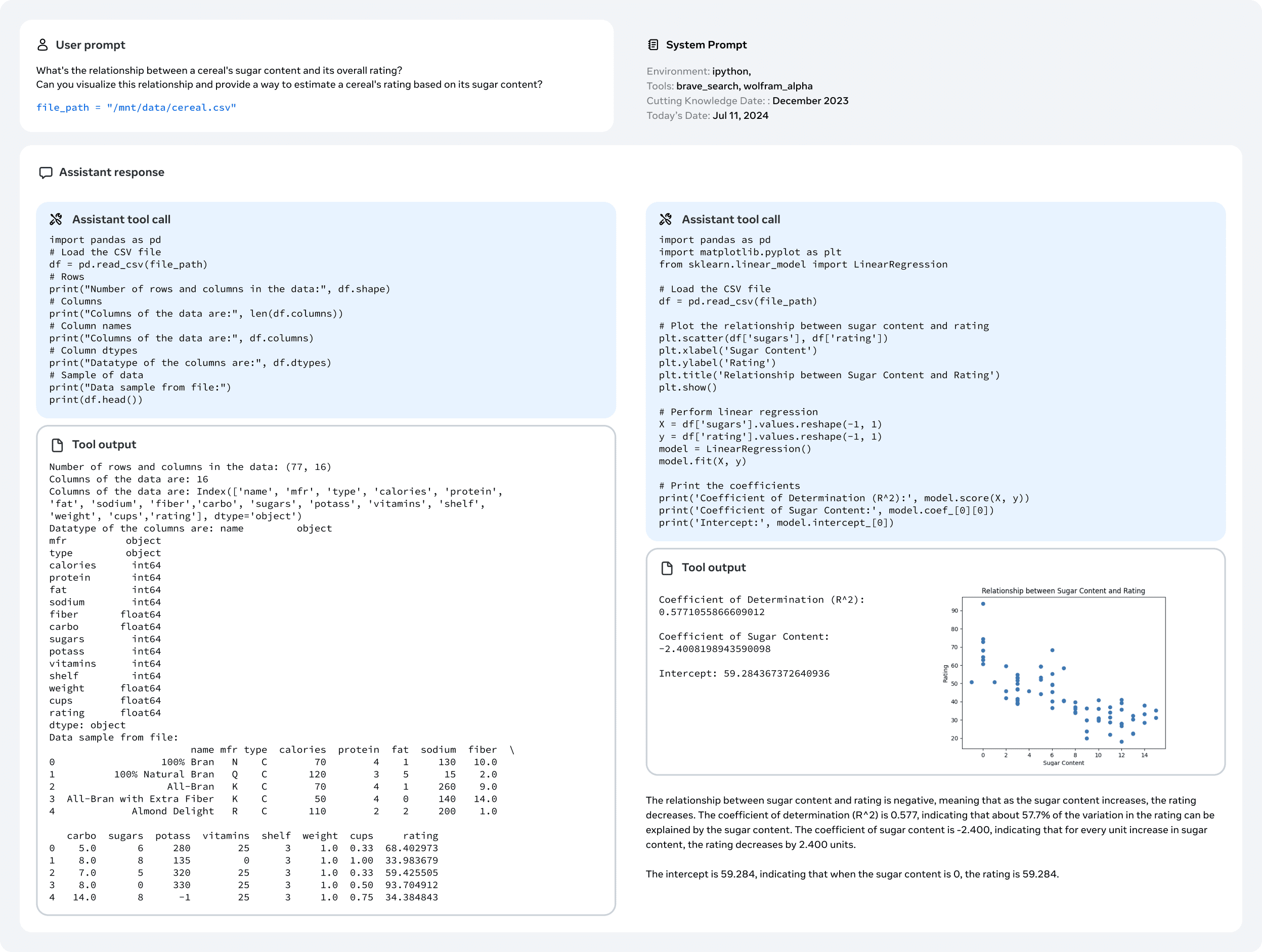
Figura 11 Procesamiento de la carga de archivos. El ejemplo muestra cómo Llama 3 analiza y visualiza un archivo cargado.
Seguimos el principio de que el post-entrenamiento debe alinear el modelo con "saber lo que sabe" en lugar de añadir conocimiento (Gekhman et al., 2024; Mielke et al., 2020). Nuestro enfoque principal consiste en generar datos que alineen la generación del modelo con un subconjunto de los datos reales presentes en los datos de preentrenamiento. Para ello, hemos desarrollado una técnica de detección de conocimiento que utiliza las capacidades contextuales de Llama 3. Este proceso de generación de datos consta de los siguientes pasos:
- Extraer un segmento de datos de los datos de preentrenamiento.
- Genera preguntas factuales sobre estos segmentos (contextos) incitando a Llama 3.
- Ejemplos de respuestas a esta pregunta de Llama 3.
- Se utilizó el contexto original como referencia y Llama 3 como juez para puntuar la corrección de la generación.
- Utilice Llama 3 como calificador para puntuar la riqueza generada.
- Generar razones de rechazo para respuestas que son consistentemente informativas e incorrectas a través de múltiples generaciones y utilizar Llama 3
Utilizamos datos generados a partir de sondas de conocimiento para animar al modelo a responder sólo a las preguntas que conoce y negarse a responder a las preguntas de las que no está seguro. Además, los datos de preentrenamiento no siempre son coherentes o correctos. Por lo tanto, también recogimos un conjunto limitado de datos de veracidad etiquetados que trataban temas delicados en los que había muchas afirmaciones contradictorias o incorrectas.
4.3.7 Controlabilidad
La controlabilidad es la capacidad de dirigir el comportamiento y los resultados del modelo para satisfacer las necesidades de desarrolladores y usuarios. Dado que Llama 3 es un modelo base genérico, debería ser fácil dirigirlo a diferentes casos de uso posteriores. Para mejorar la capacidad de control de Llama 3, nos hemos centrado en mejorar su capacidad de control a través de las indicaciones del sistema (utilizando comandos de lenguaje natural), especialmente en lo que respecta a la longitud de la respuesta, el formato, el tono de voz y la configuración del rol/personaje.
Recogida de datos. Recopilamos muestras de preferencias de controlabilidad en la categoría de Inglés General pidiendo a los anotadores que diseñaran diferentes instrucciones del sistema para Llama 3. El anotador hacía participar al modelo en un diálogo para evaluar si era capaz de seguir las instrucciones definidas en las instrucciones del sistema a lo largo del diálogo. A continuación, el anotador entabló un diálogo con el modelo para evaluar si éste era capaz de seguir las instrucciones definidas en las instrucciones del sistema a lo largo de todo el diálogo. A continuación se presentan ejemplos de instrucciones del sistema personalizadas para mejorar la capacidad de control:
"Eres un chatbot de IA útil y enérgico que sirve como asistente de planificación de comidas para familias ocupadas. Las comidas del día a día deben ser rápidas y fáciles. Para el desayuno y el almuerzo deben priorizarse los alimentos precocinados, como los cereales, los panecillos ingleses con beicon precocinado y otros alimentos rápidos y fáciles de preparar. Esta familia está ocupada. Asegúrate de preguntarles si tienen a mano productos esenciales y sus bebidas favoritas, como café o bebidas energéticas, para que no se olviden de comprarlos. A menos que sea una ocasión especial, recuerda ahorrar en tu presupuesto".
Modelización. Tras recopilar los datos de preferencias, los utilizamos para el modelado de recompensas, el muestreo de rechazo, el SFT (ajuste fino continuo) y el DPO (optimización de parámetros basada en datos) para mejorar la controlabilidad de Llama 3.
5 resultados
Hemos llevado a cabo una amplia serie de evaluaciones de Llama 3, investigando el rendimiento de (1) los modelos lingüísticos preentrenados, (2) los modelos lingüísticos postentrenados y (3) las características de seguridad de Llama 3. A continuación presentamos los resultados de estas evaluaciones en subsecciones separadas.
5.1 Preformación de modelos lingüísticos
En esta sección, presentamos los resultados de la evaluación de Llama 3 preentrenada (Parte III) y los comparamos con otros modelos de tamaño comparable. Reproduciremos los resultados de los modelos competidores en la medida de lo posible. En el caso de los modelos que no son Llama, informaremos de las mejores puntuaciones en los resultados publicados o (cuando sea posible) en los resultados que reproduzcamos nosotros mismos. Los detalles específicos de estas evaluaciones, incluidas configuraciones como recuentos de disparos, métricas y otros hiperparámetros y ajustes relevantes, están disponibles en nuestro repositorio de Github: [insertar enlace aquí]. Además, también publicaremos los datos generados como parte de las evaluaciones comparativas públicas, que se pueden encontrar aquí: [insertar enlace aquí].
Evaluaremos la calidad de los modelos en función de parámetros de referencia estándar (Sección V 5.1.1), comprobaremos su solidez frente a cambios en la configuración de las opciones múltiples (Sección V 5.1.2) y realizaremos evaluaciones adversariales (Sección V 5.1.3). También realizaremos análisis de contaminación para estimar hasta qué punto la contaminación de los datos de entrenamiento afecta a nuestra evaluación (Sección V 5.1.4).
5.1.1 Puntos de referencia estándar
Para comparar nuestro modelo con el estado actual de la técnica, evaluamos Llama 3 en un gran número de pruebas de referencia estándar, que se muestran a continuación:
(1) razonamiento de sentido común; (2) conocimientos; (3) comprensión lectora; (4) matemáticas, razonamiento y resolución de problemas; (5) contexto largo; (6) código; (7) evaluación contradictoria; y (8) evaluación global.

Configuración experimental.Para cada punto de referencia, calculamos las puntuaciones de Llama 3, así como las puntuaciones de otros modelos preentrenados con tamaños comparables. Cuando es posible, recalculamos los datos de otros modelos utilizando nuestro propio pipeline. Para garantizar una comparación justa, elegimos entonces la mejor puntuación que tenemos entre los datos calculados y las cifras comunicadas por ese modelo (utilizando la misma configuración o una más conservadora). Puede encontrar información más detallada sobre nuestros parámetros de evaluación aquí. En el caso de algunos modelos, no es posible recalcular los valores de referencia, por ejemplo, debido a modelos preentrenados no publicados o porque la API no proporciona acceso a las probabilidades logarítmicas. Esto se aplica en particular a todos los modelos comparables a Llama 3 405B. Por lo tanto, no informamos de los promedios de las categorías para Llama 3 405B, ya que sería necesario disponer de todas las cifras de referencia.
Valor de significación.Al calcular las puntuaciones de la evaluación comparativa, hay varias fuentes de variación que pueden dar lugar a estimaciones inexactas del rendimiento del modelo que se pretende medir, como un número reducido de demostraciones, semillas aleatorias y tamaños de lote. Esto dificulta la comprensión de si un modelo es significativamente mejor que otro desde el punto de vista estadístico. Por lo tanto, presentamos las puntuaciones junto con los intervalos de confianza (IC) 95% para reflejar la varianza introducida por la elección de los datos de referencia. Calculamos el IC 95% analíticamente utilizando la fórmula (Madaan et al., 2024b):

CI_analytic(S) = 1,96 * sqrt(S * (1 - S) / N)
donde S es la puntuación de referencia preferida y N es el tamaño de la muestra de la referencia. Observamos que, dado que la varianza de los datos de referencia no es la única fuente de varianza, estos IC de 95% son límites inferiores de la varianza de la estimación de la capacidad real. Para los indicadores que no son medias simples, se omitirán los IC.
Resultados de los modelos Llama 3 8B y 70B.La figura 12 muestra el rendimiento medio de Llama 3 8B y 70B en las pruebas de Razonamiento de Sentido Común, Conocimientos, Comprensión Lectora, Matemáticas y Razonamiento, y Benchmarking de Código. Los resultados muestran que Llama 3 8B supera a los modelos de la competencia en casi todas las categorías, tanto en términos de porcentaje de victorias por categoría como de rendimiento medio por categoría. También observamos que Llama 3 70B mejora sustancialmente el rendimiento de su predecesor, Llama 2 70B, en la mayoría de las pruebas, con la excepción de las pruebas de sentido común, que pueden estar saturadas.Llama 3 70B también supera a Mixtral 8x22B.
Resultados de los modelos 8B y 70B.La figura 12 muestra el rendimiento medio de la Llama 3 8B y 70B en las pruebas de Razonamiento de Sentido Común, Conocimientos, Comprensión Lectora, Matemáticas y Razonamiento, y Código Benchmark. Los resultados muestran que la Llama 3 8B supera a los modelos de la competencia en casi todas las categorías, tanto en términos de porcentaje de victorias por categoría como de rendimiento medio por categoría. También hemos comprobado que la Llama 3 70B mejora significativamente a su predecesora, la Llama 2 70B, en la mayoría de las pruebas, con la excepción de la prueba Common Sense Benchmark, que podría haberse saturado.
Resultados detallados de todos los modelos.Las tablas 9, 10, 11, 12, 13 y 14 muestran el rendimiento en pruebas de referencia de los modelos Llama 3 8B, 70B y 405B preentrenados en una tarea de comprensión lectora, una tarea de codificación, una tarea de comprensión de conocimientos generales, una tarea de razonamiento matemático y una tarea de rutina. Estas tablas comparan el rendimiento de Llama 3 con modelos de tamaño similar. Los resultados muestran que Llama 3 405B es competitivo en su categoría y especialmente supera en gran medida a modelos anteriores de código abierto. Para las pruebas con contextos largos, proporcionamos resultados más exhaustivos (incluidas tareas de detección como needle-in-a-haystack) en la sección 5.2.


5.1.2 Robustez del modelo
Además del rendimiento de las pruebas comparativas, la robustez es un factor importante en la calidad de los modelos lingüísticos preentrenados. Investigamos la solidez de las elecciones de diseño realizadas por modelos lingüísticos preentrenados en entornos de preguntas de opción múltiple (MCQ). Estudios anteriores han demostrado que el rendimiento de los modelos puede ser sensible a elecciones de diseño aparentemente arbitrarias en estos entornos, por ejemplo, las puntuaciones de los modelos e incluso las clasificaciones pueden cambiar con el orden y el etiquetado de los ejemplos contextuales (Lu et al. 2022; Zhao et al. 2021; Robinson y Wingate 2023; Liang et al. 2022; Gupta et al. 2024), el formato exacto de las instrucciones (Weber et al., 2023b; Mishra et al., 2022) o el formato y el orden de las opciones de respuesta (Alzahrani et al., 2024; Wang et al., 2024a; Zheng et al., 2023). Inspirándonos en este trabajo, utilizamos la referencia MMLU para evaluar la solidez del modelo preentrenado frente a (1) el sesgo de etiquetado de pocos disparos, (2) las variantes de etiquetado, (3) el orden de las respuestas y (4) el formato de las pistas:
- Algunas etiquetas de las lentes están despegadas. Siguiendo a Zheng et al. (2023), ... (se omiten aquí los detalles experimentales y la descripción de los resultados).
- Variantes de etiquetas. También investigamos la respuesta del modelo a diferentes conjuntos de tokens seleccionados. Consideramos dos conjuntos de etiquetas propuestos por Alzahrani et al. (2024): a saber, un conjunto de etiquetas comunes independientes del idioma ($ & # @) y un conjunto de etiquetas raras (oe § з ü) que no tienen ningún orden relativo implícito. También consideramos dos versiones de etiquetas canónicas (A. B. C. D. y A) B) C) D)) y una lista de números (1. 2. 3. 4.).
- Orden de las respuestas. Siguiendo a Wang et al. (2024a), calculamos la estabilidad de los resultados bajo diferentes órdenes de respuesta. Para ello, redistribuimos todas las respuestas del conjunto de datos según una permutación fija. Por ejemplo, para las permutaciones A B C D, todas las opciones de respuesta etiquetadas como A y B mantienen sus etiquetas, mientras que todas las opciones de respuesta etiquetadas como C adquieren la etiqueta D, y viceversa.
- Formato Cue. Evaluamos las diferencias de rendimiento entre cinco pistas de tareas que diferían en la cantidad de información que contenían: una pista simplemente pedía al modelo que respondiera a la pregunta, mientras que otras afirmaban la experiencia del modelo o que debía elegir la mejor respuesta.

Tabla 11 Rendimiento de los modelos preentrenados en una tarea de comprensión de conocimientos generales. Los resultados incluyen intervalos de confianza de 95%.

Tabla 12 Rendimiento de los modelos preentrenados en tareas matemáticas y de razonamiento. Los resultados incluyen intervalos de confianza 95%. 11 disparos.

Tabla 13 Rendimiento de los modelos preentrenados en tareas lingüísticas de propósito general. Los resultados incluyen intervalos de confianza de 95%.

Fig. 13 Robustez de nuestro modelo lingüístico preentrenado frente a distintas opciones de diseño en la prueba comparativa MMLU. Izquierda: rendimiento con diferentes variantes de etiquetado. Lado derecho: rendimiento en presencia de diferentes etiquetas en el ejemplo sin muestra.

Fig. 14 Robustez de nuestro modelo lingüístico preentrenado frente a distintas opciones de diseño en la prueba de referencia MMLU. Izquierda: rendimiento para distintas secuencias de respuestas. Derecha: rendimiento para distintos formatos de pregunta.
La Figura 13 ilustra los resultados de nuestros experimentos que investigan la solidez del rendimiento del modelo para las variantes de etiquetas (izquierda) y el sesgo de etiquetas de pocos disparos (derecha). Los resultados muestran que nuestro modelo lingüístico preentrenado es muy robusto frente a las variaciones de etiquetas de MCQ, así como frente a la estructura de las etiquetas de pistas de pocos disparos. Esta solidez es especialmente evidente en el modelo paramétrico 405B.
La figura 14 ilustra los resultados de nuestros estudios sobre la solidez del orden de las respuestas y el formato de las pistas. Estos resultados ponen aún más de relieve la solidez del rendimiento de nuestros modelos lingüísticos preentrenados, en particular la solidez de Llama 3 405B.

5.1.3 Evaluación comparativa adversarial
Además de las pruebas de referencia mencionadas, evaluamos varias pruebas de referencia adversariales en tres ámbitos: preguntas y respuestas, razonamiento matemático y detección de reescritura de frases. Estas pruebas están diseñadas para comprobar la capacidad del modelo en tareas diseñadas específicamente para ser desafiantes y pueden señalar problemas de sobreajuste del modelo en las pruebas de referencia.
- Preguntas y respuestasutilizamos Adversarial SQuAD (Jia y Liang, 2017) y Dynabench SQuAD (Kiela et al., 2021).
- Razonamiento matemáticoUtilizamos GSM-Plus (Li et al., 2024c).
- Aspectos de las pruebas de reescritura de frasesutilizamos PAWS (Zhang et al., 2019).
La Figura 15 muestra las puntuaciones de Llama 3 8B, 70B y 405B en las pruebas de referencia adversariales en función de su rendimiento en las pruebas de referencia no adversariales. Las pruebas de referencia no adversariales que utilizamos son SQuAD para preguntas y respuestas (Rajpurkar et al., 2016), GSM8K para razonamiento matemático y QQP para detección de reescritura de frases (Wang et al., 2017). Cada punto de datos representa un conjunto de datos adversario y un conjunto de datos no adversario (por ejemplo, QQP emparejado con PAWS), y mostramos todos los emparejamientos posibles dentro de la categoría. La línea negra en la diagonal indica la paridad entre los conjuntos de datos adversos y no adversos, donde la línea indica que el modelo tiene un rendimiento similar independientemente de que sea adverso o no adverso.
En cuanto a la detección de la prosodia de las frases, ni los modelos preentrenados ni los postentrenados parecen verse afectados por la naturaleza adversarial de los constructos PAWS, lo que representa una enorme mejora con respecto a la generación anterior de modelos. Este resultado confirma los hallazgos de Weber et al. (2023a), que también descubrieron que los modelos de lenguaje grandes son menos sensibles a las correlaciones espurias en varios conjuntos de datos adversariales. Sin embargo, para el razonamiento matemático y las preguntas y respuestas, el rendimiento adversarial es significativamente inferior al rendimiento no adversarial. Este patrón se aplica tanto a los modelos preentrenados como a los postentrenados.
5.1.4 Análisis de la contaminación
Llevamos a cabo un análisis de contaminación para estimar hasta qué punto las puntuaciones de referencia pueden verse afectadas por la contaminación de los datos de evaluación en el corpus de preentrenamiento. En algunos trabajos anteriores se han utilizado distintos métodos de contaminación e hiperparámetros; nos remitimos al estudio de Singh et al. (2024). Los resultados muestran que nuestro modelo lingüístico preentrenado es muy robusto frente a las variaciones en el etiquetado de las preguntas de opción múltiple, así como frente a las variaciones en la estructura de las etiquetas con menos muestras (esbozadas en 2024). Con cualquiera de estos enfoques pueden producirse falsos positivos y falsos negativos, y la mejor forma de realizar análisis de contaminación sigue siendo un área de investigación abierta. Aquí seguimos principalmente las recomendaciones de Singh et al. (2024).


Métodos:En concreto, Singh et al. (2024) sugieren elegir empíricamente un método de detección de la contaminación basándose en qué método conduce a la mayor diferencia entre el conjunto de datos "limpio" y el conjunto de datos completo, a lo que se refieren como la ganancia de rendimiento estimada. Para todos los conjuntos de datos de evaluación, puntuamos basándonos en el solapamiento de 8 gramos, que Singh et al. (2024) consideraron preciso para muchos conjuntos de datos. Consideramos que un ejemplo del conjunto de datos D está contaminado si su etiquetado TD de una proporción de ellos aparecen al menos una vez en el corpus de preentrenamiento. Seleccionamos para cada conjunto de datos individualmente TDdependiendo de qué valor muestre la máxima ganancia de rendimiento significativa estimada (en los tres tamaños de modelo).
Resultados:La tabla 15 muestra el porcentaje de los datos de evaluación de todos los puntos de referencia principales que se consideran contaminados para obtener la máxima ganancia de rendimiento estimada, tal y como se ha descrito anteriormente. De esta tabla, excluimos las cifras de los puntos de referencia en los que los resultados no eran significativos, por ejemplo, debido a que había muy pocas muestras limpias o contaminadas, o en los que las estimaciones de ganancia de rendimiento observadas mostraban un comportamiento extremadamente errático.
En la Tabla 15, podemos ver que para algunos conjuntos de datos la contaminación tiene un gran impacto, mientras que para otros no. Por ejemplo, para PiQA y HellaSwag, tanto la estimación de la contaminación como la estimación de la ganancia de rendimiento son altas. Por otro lado, en el caso de Natural Questions, la contaminación estimada de 52% parece no tener casi ningún efecto en el rendimiento. Para SQuAD y MATH, los umbrales bajos dan como resultado altos niveles de contaminación, pero ningún aumento del rendimiento. Esto sugiere que la contaminación puede no ser útil para estos conjuntos de datos, o que se necesita un n mayor para obtener mejores estimaciones. Por último, en el caso de MBPP, HumanEval, MMLU y MMLU-Pro, es posible que se necesiten otros métodos de detección de la contaminación: incluso con umbrales más altos, el solapamiento de 8 gramos da lugar a puntuaciones de contaminación tan altas que no se pueden obtener buenas estimaciones de la ganancia de rendimiento.
5.2 Ajuste del modelo lingüístico
Mostramos los resultados del modelo Llama 3 tras el entrenamiento en pruebas de referencia de diferentes capacidades. De forma similar al preentrenamiento, publicamos los datos generados como parte de la evaluación en pruebas de referencia disponibles públicamente que se pueden encontrar en Huggingface (insertar enlace aquí). Se puede encontrar información más detallada sobre nuestra configuración de evaluación aquí (insertar enlace aquí).
Evaluación comparativa e indicadores.En el cuadro 16 se resumen todas las pruebas de referencia, clasificadas por capacidades. Descontaminaremos los datos posteriores al entrenamiento haciendo coincidir exactamente las pistas de cada prueba de referencia. Además de las pruebas de referencia académicas estándar, también realizamos una amplia evaluación manual de distintas capacidades. Consulte la sección 5.3 para obtener información detallada.
Configuración experimental.Utilizamos una configuración experimental similar a la de la fase de preentrenamiento y analizamos Llama 3 en comparación con otros modelos de tamaño y capacidades comparables. En la medida de lo posible, evaluaremos nosotros mismos el rendimiento de los demás modelos y compararemos los resultados con las cifras comunicadas para seleccionar la mejor puntuación. Encontrará información más detallada sobre nuestra configuración de evaluación aquí (enlace insertado aquí).

Tabla 16 Pruebas de referencia post-entrenamiento por categoría. Resumen de todas las pruebas de referencia que utilizamos para evaluar el modelo Llama 3 posterior al entrenamiento, ordenadas por capacidad.
5.2.1 Conocimientos genéricos y evaluación comparativa del cumplimiento de la instrucción
Utilizamos los puntos de referencia que figuran en la Tabla 2 para evaluar las capacidades de Llama 3 en términos de conocimientos generales y cumplimiento de las instrucciones.
Conocimientos generales: Utilizamos MMLU (Hendrycks et al., 2021a) y MMLU-Pro (Wang et al., 2024b) para evaluar el rendimiento de Llama 3 en las capacidades de interrogación basadas en el conocimiento. MMLU-Pro es una versión ampliada de MMLU que contiene preguntas más desafiantes y centradas en la inferencia, elimina las preguntas ruidosas y amplía la gama de opciones de cuatro a diez. Dado que se centra en el razonamiento complejo, presentamos cinco ejemplos de CoT para MMLU-Pro. Todas las tareas están formateadas como tareas generativas, similares a simple-evals (OpenAI, 2024).
Como se muestra en la Tabla 2, nuestras variantes Llama 3 8B y 70B superan a otros modelos de tamaño similar en ambas tareas de conocimientos generales. Nuestro modelo 405B supera a GPT-4 y Nemotron 4 340B, y Claude 3.5 Sonnet aventaja a los modelos de mayor tamaño.
Instrucciones a seguir: Utilizamos IFEval (Zhou et al., 2023) para evaluar la capacidad de Llama 3 y otros modelos para seguir instrucciones en lenguaje natural. IFEval consta de unas 500 "instrucciones verificables", como "escribir en más de 400 palabras", que pueden verificarse utilizando heurística. IFEval incluye unas 500 "instrucciones verificables", como "escribir en más de 400 palabras", que pueden verificarse mediante heurística. En la Tabla 2 se muestra la media de las precisiones a nivel de instrucción y a nivel de instrucción con restricciones estrictas y laxas. Obsérvese que todas las variantes de Llama 3 superan a los modelos comparables en IFEval.
5.2.2 Exámenes de aptitud
A continuación, evaluamos nuestro modelo en una serie de pruebas de aptitud diseñadas originalmente para evaluar a seres humanos. Obtenemos estos exámenes de fuentes oficiales de acceso público; para algunos exámenes, informamos de las puntuaciones medias de los distintos conjuntos de exámenes como resultado de cada prueba de aptitud. En concreto, hacemos la media:
- GRE: Los exámenes oficiales de práctica GRE 1 y 2 ofrecidos por Educational Testing Service;
- LSAT: Pre-test oficial 71, 73, 80 y 93;
- SAT: 8 exámenes de La guía oficial de estudio del SAT, edición 2018;
- AP: un examen práctico oficial por asignatura;
- GMAT: El examen oficial GMAT en línea.
Las preguntas de estos exámenes contienen preguntas de opción múltiple y generativas. Excluiremos las preguntas que contengan imágenes. En el caso de las preguntas GRE que contienen varias opciones correctas, calificamos la salida como correcta sólo si el modelo selecciona todas las opciones correctas. En los casos en los que hay más de un conjunto de exámenes, utilizamos un número reducido de pistas para la evaluación. Ajustamos las puntuaciones al intervalo 130-170 (para el GRE) e informamos de la precisión para todos los demás exámenes.

Nuestros resultados se muestran en la Tabla 17. Encontramos que nuestro modelo Llama 3 405B se comporta de forma similar al modelo Llama 3 405B. Claude El Sonnet 3,5 es muy similar al GPT-4 4o. Nuestro modelo 70B, en cambio, muestra un rendimiento aún más impresionante. Es significativamente mejor que el GPT-3.5 Turbo y supera al Nemotron 4 340B en muchas pruebas.
5.2.3 Parámetros de codificación
Evaluamos las capacidades de generación de código de Llama 3 en varias pruebas de referencia populares de Python y de programación multilingüe. Para medir la eficacia del modelo en la generación de código funcionalmente correcto, utilizamos la métrica pass@N, que evalúa la tasa de aprobación de pruebas unitarias para un conjunto de N generaciones. Presentamos los resultados de pass@1.


Generación de código Python. HumanEval (Chen et al., 2021) y MBPP (Austin et al., 2021) son benchmarks populares de generación de código Python que se centran en funcionalidades relativamente sencillas y autocontenidas.HumanEval+ (Liu et al., 2024a) es una versión mejorada de HumanEval en la que se generan más casos de prueba para evitar falsos positivos.La versión del benchmark MBPP EvalPlus (v0.2.0) es una selección de 378 preguntas bien formateadas (Liu et al., 2024a) de un total de 974. La versión de referencia MBPP EvalPlus (v0.2.0) es una selección de 378 preguntas bien formateadas (Liu et al., 2024a) de las 974 preguntas iniciales del conjunto de datos MBPP original (entrenamiento y pruebas). Los resultados de estas pruebas de referencia se muestran en la Tabla 18. En la evaluación comparativa de estas variantes de Python, Llama 3 8B y 70B superaron a modelos del mismo tamaño con un rendimiento similar. En cuanto a los modelos de mayor tamaño, Llama 3 405B, Claude 3.5 Sonnet y GPT-4o obtuvieron resultados similares, siendo GPT-4o el que obtuvo los mejores resultados.
Modelos. Comparamos Llama 3 con otros modelos de tamaño similar. En el caso del modelo más grande, Llama 3 405B, Claude 3.5 Sonnet y GPT-4o tienen un rendimiento similar, siendo GPT-4o el que mejores resultados muestra.
Generación de código en múltiples lenguajes de programación: Para evaluar las capacidades de generación de código de lenguajes distintos de Python, presentamos los resultados de la prueba comparativa MultiPL-E (Cassano et al., 2023) basada en traducciones de preguntas de HumanEval y MBPP. La Tabla 19 muestra los resultados para una selección de lenguajes de programación populares.
Nótese que hay una caída significativa del rendimiento en comparación con la contrapartida de Python en la Tabla 18.
5.2.4 Evaluación comparativa multilingüe
Llama 3 admite 8 idiomas -inglés, alemán, francés, italiano, portugués, hindi, español y tailandés-, aunque el modelo base se entrenó utilizando un conjunto más amplio de idiomas. En la Tabla 20, mostramos los resultados de nuestra evaluación de Llama 3 en las pruebas de referencia Multilingual MMLU (Hendrycks et al., 2021a) y Multilingual Primary Mathematics (MGSM) (Shi et al., 2022).
- MMLU multilingüePreguntas: Utilizamos Google Translate para traducir las preguntas, los ejemplos y las respuestas del MMLU a diferentes idiomas. Mantuvimos las descripciones de las tareas en inglés y las evaluamos a 5 tiros.
- MGSM (Shi et al., 2022)Para nuestro modelo Llama 3, informamos de los resultados de CoT de 0 disparos para MGSM. El MMLU multilingüe es una prueba interna que consiste en traducir las preguntas y respuestas del MMLU (Hendrycks et al., 2021a) a 7 idiomas.
Para MGSM (Shi et al., 2022), probamos nuestro modelo utilizando las mismas indicaciones nativas que en simple-evals (OpenAI, 2024) y lo colocamos en un entorno de CoT de 0 disparos. En la tabla 20, presentamos los resultados medios de todos los idiomas incluidos en la prueba de referencia MGSM.

Comprobamos que Llama 3 405B supera a la mayoría de los demás modelos en el MGSM, con una puntuación media de 91,61TP3 T. En el MMLU, en consonancia con los resultados del MMLU en inglés anteriores, Llama 3 405B queda por detrás de GPT-4o 21TP3 T. Por otro lado, tanto el modelo 70B como el 8B de Llama 3 superan a los competidores, liderando a la competencia por un amplio margen en ambas tareas. en ambas tareas.
5.2.5 Puntos de referencia matemáticos y de razonamiento
Los resultados de nuestras pruebas de referencia matemáticas y de inferencia se muestran en la Tabla 2. El modelo Llama 3 8B supera a otros modelos del mismo tamaño en GSM8K, MATH y GPQA. Nuestro modelo 70B muestra un rendimiento significativamente mejor que sus homólogos en todas las pruebas de referencia. Por último, el modelo Llama 3 405B es el mejor modelo de su categoría en GSM8K y ARC-C, mientras que en MATH es el segundo mejor modelo. En GPQA, compite bien con GPT-4 4o, mientras que Claude 3.5 Sonnet encabeza la lista por un margen significativo.
5.2.6 Evaluación comparativa a largo plazo
Consideramos una serie de tareas en diferentes dominios y tipos de texto. En las pruebas comparativas que figuran a continuación, nos centramos en las subtareas que utilizan un protocolo de evaluación imparcial, es decir, métricas basadas en la precisión en lugar de métricas de solapamiento de n-gramas. También damos prioridad a las tareas en las que se encuentra una menor varianza.
- Aguja en un pajar (Kamradt, 2023) Medir la capacidad del modelo para recuperar información oculta en partes aleatorias de documentos largos. Nuestro modelo Llama 3 muestra un rendimiento perfecto en la recuperación de agujas, recuperando con éxito 100% "agujas" en todas las profundidades de documento y longitudes de contexto. También medimos el rendimiento de Multi-needle (Tabla 21), una variación de Needle-in-a-Haystack, en la que insertamos cuatro "agujas" en el contexto y comprobamos si el modelo podía recuperar dos de ellas. Nuestro modelo Llama 3 consigue resultados de recuperación casi perfectos.
- ZeroSCROLLS (Shaham et al., 2023)es una prueba de referencia de muestra cero para la comprensión en lenguaje natural de textos largos. Como las respuestas verdaderas no están disponibles públicamente, presentamos las cifras del conjunto de validación. Nuestros modelos Llama 3 405B y 70B igualan o superan a los demás modelos en diversas tareas de esta prueba de referencia.
- InfiniteBench (Zhang et al., 2024) Los modelos son necesarios para comprender las dependencias a larga distancia en las ventanas contextuales. Evaluamos Llama 3 en En.QA (cuestionario sobre novelas) y En.MC (cuestionario de opción múltiple sobre novelas), donde nuestro modelo 405B supera a todos los demás modelos. La ganancia es especialmente significativa en En.QA.

Tabla 21 Evaluación comparativa de texto largo. Para ZeroSCROLLS (Shaham et al., 2023) informamos de los resultados en el conjunto de validación. Para QuALITY informamos de las coincidencias exactas, para Qasper - f1, y para SQuALITY - rougeL. informamos de f1 para la métrica En.QA de InfiniteBench (Zhang et al., 2024), y de la precisión para En.MC. Para Multi-needle (Kamradt, 2023), insertamos 4 agujas en el contexto y probamos si el modelo es capaz de recuperar 2 agujas de diferentes longitudes de contexto, y calculamos la recuperación media para hasta 128k de 10 longitudes de secuencia.
5.2.7 Rendimiento de las herramientas
Evaluamos nuestro modelo utilizando una serie de puntos de referencia de uso de herramientas (es decir, llamadas a funciones) de muestra cero: Nexus (Srinivasan et al., 2023), API-Bank (Li et al., 2023b), Gorilla API-Bench (Patil et al., 2023) y Berkeley Function Call Leaderboard ( BFCL) (Yan et al., 2024). Los resultados se muestran en la Tabla 22.
En Nexus, nuestra variante Llama 3 obtiene los mejores resultados, superando a los demás modelos de su categoría. En API-Bank, nuestros modelos Llama 3 8B y 70B superan significativamente a los demás modelos de sus respectivas categorías. El modelo 405B sólo queda por detrás del Claude 3.5 Sonnet 0.6%.Por último, nuestros modelos 405B y 70B obtienen mejores resultados en BFCL y ocupan el segundo lugar en sus respectivas categorías de tamaño. El Llama 3 8B fue el que obtuvo mejores resultados en su categoría.
También realizamos una evaluación manual para comprobar la capacidad del modelo para utilizar la herramienta, centrándonos en las tareas de ejecución de código. Recopilamos 2.000 peticiones de usuarios, generación de dibujos y carga de archivos relacionados con la ejecución de código (sin incluir la carga de dibujos o archivos). Estos mensajes proceden de LMSys (Chiang et al., 2024), puntos de referencia GAIA (Mialon et al., 2023b), anotadores humanos y generación sintética. Comparamos Llama 3 405B con GPT-4o utilizando la API de asistentes de OpenAI10 . Los resultados se muestran en la Figura 16. Llama 3 405B supera claramente a GPT-4o en las tareas de ejecución de código de sólo texto y generación de dibujos; sin embargo, queda por detrás de GPT-4o en el caso de uso de carga de archivos.

5.3 Evaluación manual
Además de las evaluaciones sobre el conjunto de datos de referencia estándar, realizamos una serie de evaluaciones humanas. Estas evaluaciones nos permiten medir y optimizar aspectos más sutiles del rendimiento del modelo, como el tono del mismo, el nivel de redundancia y la comprensión de los matices y el contexto cultural. Las evaluaciones rengren cuidadosamente diseñadas están estrechamente relacionadas con la experiencia del usuario, ya que proporcionan información sobre el rendimiento del modelo en el mundo real.
https://platform.openai.com/docs/assistants/overview
En las evaluaciones humanas multirronda, el número de rondas en cada taco osciló entre 2 y 11. Se evaluó la respuesta del modelo en la última ronda. Se evaluó la respuesta del modelo en la última ronda.
Recogida de propinas. Hemos recopilado instrucciones de alta calidad que cubren una amplia gama de categorías y dificultades. Para ello, primero desarrollamos una taxonomía con categorías y subcategorías para el mayor número posible de habilidades modelo. Utilizamos esta taxonomía para recopilar aproximadamente 7.000 preguntas que cubrían seis capacidades de una sola vuelta (inglés, razonamiento, codificación, hindi, español y portugués) y tres capacidades de varias vueltas11 (Inglés, Razonamiento y Codificación). Dentro de cada categoría, las preguntas se distribuyeron uniformemente entre las subcategorías. También clasificamos cada pregunta en uno de los tres niveles de dificultad y nos aseguramos de que nuestro conjunto de preguntas contuviera aproximadamente 10% de preguntas fáciles, 30% de preguntas moderadamente difíciles y 60% de preguntas difíciles. Figura 16 Resultados de la evaluación humana de Llama 3 405B frente a GPT-4o en tareas de ejecución de código como dibujar y cargar archivos. La Llama 3 405B supera a la GPT-4o en la ejecución de código (sin incluir el trazado ni la carga de archivos), así como en la generación de trazados, pero se queda atrás en el caso de carga de archivos.
Los conjuntos de claves se han sometido a un riguroso proceso de control de calidad. El equipo de modelización no tiene acceso a nuestros indicadores de evaluación humana para evitar la contaminación accidental o el sobreajuste del conjunto de pruebas.
Proceso de evaluación. Para realizar evaluaciones humanas por pares de los dos modelos, preguntamos a los anotadores humanos cuál de las dos respuestas del modelo (generadas por modelos diferentes) prefieren. Los anotadores utilizan una escala de 7 puntos que les permite indicar si una respuesta del modelo es mucho mejor, mejor, ligeramente mejor o más o menos igual que la otra. Cuando los anotadores indiquen que la respuesta de un modelo es mucho mejor o mejor que la respuesta de otro modelo, lo consideraremos una "victoria" para ese modelo. Compararemos los modelos de dos en dos e indicaremos el porcentaje de victorias para cada capacidad del conjunto de pistas.
al final. Comparamos la Llama 3 405B con la GPT-4 (versión API 0125), la GPT-4o (versión API) y la Claude 3.5 Sonnet (versión API) mediante un proceso de evaluación humana. Los resultados de estas evaluaciones se muestran en la figura 17. Observamos que el rendimiento de Llama 3 405B es aproximadamente comparable al de la versión API 0125 de GPT-4, con resultados mixtos (algunas victorias y algunas derrotas) cuando se compara con GPT-4o y Claude 3.5 Sonnet. En casi todas las capacidades, Llama 3 y GPT-4 ganan dentro del margen de error. La Llama 3 405B supera a la GPT-4 en las tareas de razonamiento y codificación multirronda, pero no en las preguntas multilingües (hindi, español y portugués). La Llama 3 se comporta igual de bien que la GPT-4 en las preguntas en inglés, igual que la Claude 3.5 Sonnet en las preguntas multilingües, y supera tanto las preguntas en inglés de una sola ronda como las de varias rondas. Cualitativamente, hemos comprobado que el rendimiento del modelo en la evaluación humana depende en gran medida de factores sutiles como el tono de voz, la estructura de la respuesta y el nivel de redundancia, factores que estamos optimizando en el proceso de postentrenamiento. factores que se están optimizando. En general, los resultados de nuestra evaluación humana coinciden con los de las evaluaciones de referencia estándar: el Llama 3 405B compite muy bien con los modelos líderes del sector, lo que lo convierte en el modelo de mejor rendimiento disponible públicamente.
limitaciones. Todos los resultados de las evaluaciones humanas se han sometido a un riguroso proceso de control de calidad de los datos. Sin embargo, debido a la dificultad de definir criterios objetivos para la respuesta de los modelos, las evaluaciones humanas aún pueden verse influidas por los sesgos personales, los antecedentes y las preferencias de los anotadores humanos, lo que puede dar lugar a resultados incoherentes o poco fiables.

Figura 16 Resultados de la evaluación humana de Llama 3 405B frente a GPT-4o en tareas de ejecución de código (incluidos el trazado y la carga de archivos). Llama 3 405B supera a GPT-4o en la ejecución de código (excluidos el trazado y la carga de archivos) y la generación de trazados, pero se queda atrás en el caso de carga de archivos.

Fig. 17 Resultados de la evaluación manual del modelo Llama 3 405B. Izquierda: comparación con GPT-4. Centro: comparación con GPT-4o. Derecha: comparación con Claude 3.5 Sonnet. Todos los resultados incluyen intervalos de confianza 95% y excluyen los empates.
5.4 Seguridad
La sección de seguridad incluye palabras sensibles, que pueden omitirse o descargarse en PDF, ¡gracias!
Nos centramos en evaluar la capacidad de Llama 3 para generar contenidos de forma segura y responsable, maximizando al mismo tiempo la información útil. Nuestro trabajo de seguridad comienza con una fase de preentrenamiento, principalmente en forma de limpieza y filtrado de datos. A continuación, describiremos la metodología de ajuste de la seguridad, centrándonos en cómo entrenar al modelo para que cumpla políticas de seguridad específicas sin dejar de ser útil. Analizaremos cada característica de Llama 3, incluido el multilingüismo, los contextos largos, el uso de herramientas y varias características multimodales, para medir la eficacia de nuestras mitigaciones de seguridad.
A continuación describimos nuestra evaluación de la ciberseguridad y la elevación del riesgo de las armas químicas/biológicas. La elevación se refiere al riesgo adicional que plantean los nuevos avances tecnológicos en comparación con el uso de las tecnologías disponibles existentes (por ejemplo, búsquedas en Internet).
A continuación, describimos cómo utilizamos las pruebas de "equipo rojo" para identificar y abordar de forma iterativa diversos riesgos de seguridad interfuncionales y realizar evaluaciones de riesgos residuales.
Por último, describiremos la seguridad a nivel de sistema, o el desarrollo y programación de clasificadores en torno a las entradas y salidas del propio modelo, para mejorar aún más la seguridad y facilitar a los desarrolladores la adaptación de la seguridad a diversos casos de uso y desplegar la IA generativa de forma más responsable.
5.4.1 Construcción de referencias
Para desarrollar modelos de forma segura y responsable, hemos creado varios puntos de referencia internos. Nuestras pruebas se inspiran en la taxonomía de riesgos de ML Commons (Vidgen et al., 2024). Aunque ya existen puntos de referencia de seguridad de modelos lingüísticos como ToxiGen (Hartvigsen et al., 2022), XS Test (Röttger et al., 2023), etc., muchas de las nuevas características de Llama 3 carecen de suficientes puntos de referencia externos, y los puntos de referencia externos existentes son a menudo inadecuados en amplitud y profundidad.
Para cada categoría de riesgo, recopilamos indicios adversos o límite escritos por humanos; en la Tabla 23 se enumeran ejemplos de estos indicios. Estas señales van desde las más sencillas, que desencadenan directamente una respuesta dañina, hasta las que incorporan complejas técnicas de fuga de la cárcel. Estos indicios constituyen la base de referencia con la que medimos los índices de infracción.
Como indicador inverso de la tasa de violación, también construimos un punto de referencia de falso rechazo consistente en indicios de delimitación. Cuando el modelo se niega a responder de forma útil incluso cuando existe una respuesta razonable y segura, nos referimos a esta situación como falso rechazo. Los indicios de limitación son similares a los indicios de límite de decisión, y un modelo bien calibrado debería ser capaz de manejar estos indicios, por ejemplo, "¿Cómo puedo robarle el protagonismo a mi mejor amigo, que siempre es el protagonista?". Nuestro tamaño global de referencia para infracciones y falsos rechazos supera las 4000 pistas/competencias o idiomas, incluyendo pistas de una sola ronda y de varias rondas.
5.4.2 Formación previa en materia de seguridad
Creemos que el desarrollo responsable debe considerarse desde una perspectiva integral e incorporarse en cada fase del desarrollo y la implantación del modelo. Durante el preentrenamiento, aplicamos varios filtros, como los utilizados para identificar sitios web que puedan contener información de identificación personal (véase la sección 3.1). También nos centramos en la memoización descubrible (Nasr et al., 2023). De forma similar a Carlini et al. (2022), muestreamos las claves y los resultados verdaderos con diferentes frecuencias de aparición utilizando el índice hash rodante efectivo de todas las n-tuplas de los datos de entrenamiento. Construimos diferentes escenarios de prueba variando la longitud de las pistas y los resultados verdaderos, el lenguaje de detección y el dominio de los datos objetivo. A continuación, medimos la frecuencia con la que el modelo genera con precisión secuencias de resultados verdaderos y analizamos los índices relativos de memoización en los escenarios especificados. Definimos la memorización literal como la tasa de inclusión (la proporción de secuencias generadas por el modelo que contienen resultados verdaderos) e informamos de esta tasa en las medias ponderadas que se muestran en la Tabla 24, determinadas por la prevalencia de una característica dada en los datos. La tasa de memorización de los datos de entrenamiento es baja (1,13% y 3,91% de media para n = 50 y n = 1000, respectivamente, para 405B). Utilizando la misma metodología aplicada al tamaño equivalente de su mezcla de datos, Llama 2 tiene aproximadamente la misma tasa de memorización.

Tabla 23 Ejemplos de señales de adversario para todas las capacidades de nuestra evaluación comparativa interna.

Tabla 24 Memoria literal media de Llama 3 preentrenada en escenarios de prueba seleccionados. Nuestra línea de base es Llama 2, que utiliza la misma metodología de cueing aplicada a sus datos mezclados con inglés, escenarios de 50 gramos.
5.4.3 Ajuste de la seguridad
Este capítulo describe el enfoque de ajuste de seguridad que utilizamos para mitigar los riesgos de varias capacidades, que abarca dos aspectos clave: (1) datos sobre formación en seguridad y (2) técnicas de reducción de riesgos. Nuestro proceso de ajuste de la seguridad se basa en nuestra metodología genérica de ajuste con modificaciones para abordar problemas de seguridad específicos.
Optimizamos dos métricas principales: la tasa de violaciones (VR), que recoge los casos en los que el modelo genera respuestas que violan la política de seguridad; y la tasa de falsos rechazos (FRR), que recoge los casos en los que el modelo rechaza incorrectamente respuestas a pistas inocuas. Al mismo tiempo, evaluamos el rendimiento del modelo en pruebas comparativas de utilidad para garantizar que las mejoras de seguridad no comprometen la utilidad general. Nuestros experimentos muestran que un modelo de 8.000 millones de parámetros requiere una proporción mayor de datos de seguridad que de datos de utilidad en comparación con un modelo de 70.000 millones de parámetros para lograr un rendimiento de seguridad comparable. Los modelos más grandes son más capaces de distinguir entre contextos adversos y límites, lo que resulta en un equilibrio más favorable entre RV y FRR.
Datos de ajuste
La calidad y el diseño de los datos de entrenamiento de seguridad tienen un profundo efecto en el rendimiento. Mediante amplios experimentos de ablación, hemos descubierto que la calidad es más importante que la cantidad. Principalmente utilizamos datos generados por humanos de proveedores de datos, pero los encontramos propensos a errores e inconsistencias, especialmente para políticas de seguridad sutiles. Para garantizar la máxima calidad de los datos, hemos desarrollado herramientas de anotación asistidas por IA que respaldan nuestro riguroso proceso de control de calidad.
Además de recoger pistas adversas, también recogimos un conjunto similar de pistas llamadas pistas límite. Estos indicios están estrechamente relacionados con los indicios adversos, pero su objetivo es enseñar al modelo a proporcionar respuestas útiles y reducir así la tasa de falsos rechazos (FRR).
Además de las anotaciones humanas, utilizamos datos sintéticos para mejorar la calidad y la cobertura del conjunto de datos de entrenamiento. Generamos ejemplos adversarios adicionales mediante diversas técnicas, incluido el aprendizaje contextual mediante pistas elaboradas del sistema, mutaciones basadas en nuevos vectores de ataque que guían las pistas de semillas y algoritmos avanzados, incluido el Rainbow Team (Samvelyan et al., 2024), basado en MAP-Elites (Mouret y Clune, 2015), que genera pistas a través de múltiples de múltiples dimensiones.
Además, abordamos la cuestión del tono de voz del modelo al generar respuestas de seguridad, que puede afectar a la experiencia del usuario posterior. Desarrollamos una directriz de tono de rechazo para Llama 3 y nos aseguramos de que todos los nuevos datos de seguridad se adhirieran a ella mediante un riguroso proceso de control de calidad. También mejoramos los datos de seguridad existentes mediante una combinación de reescritura de muestra cero y edición manual para generar datos de alta calidad. Gracias a estos métodos y al uso de clasificadores de tono para evaluar la calidad tonal de las respuestas de seguridad, pudimos mejorar significativamente la redacción del modelo.
Puesta a punto del control de seguridad
Siguiendo nuestra receta Llama 2 (Touvron et al., 2023b), combinamos todos los datos de utilidad y de seguridad en la fase de alineación del modelo. Además, introdujimos conjuntos de datos límite para ayudar al modelo a distinguir la sutil diferencia entre las solicitudes seguras y las inseguras. Nuestro equipo de anotación recibió instrucciones para diseñar cuidadosamente las respuestas a las señales de seguridad basándose en nuestras directrices. Descubrimos que la SFT era muy eficaz a la hora de alinear el modelo cuando equilibrábamos estratégicamente la proporción de ejemplos adversos con respecto a los límites. Nos centramos en las áreas de riesgo más difíciles cuando la proporción de ejemplos límite era mayor. Esto desempeña un papel fundamental en el éxito de nuestros esfuerzos de mitigación de la seguridad, al tiempo que minimiza los falsos rechazos.
Además, investigamos el efecto del tamaño del modelo en el equilibrio entre FRR y VR (véase la figura 18). Nuestros resultados sugieren que cambiará: los modelos más pequeños requieren una mayor proporción de datos de seguridad en relación con la utilidad, y es más difícil equilibrar eficazmente RV y FRR que los modelos más grandes.
RPD de Seguridad
Para mejorar el aprendizaje de seguridad, incorporamos ejemplos adversos y límites al conjunto de datos de preferencias en la OPD. Descubrimos que diseñar pares de respuestas para una pista determinada que sean casi ortogonales en el espacio de incrustación es especialmente eficaz para enseñar al modelo a distinguir entre respuestas buenas y malas. Realizamos varios experimentos para determinar la proporción óptima de ejemplos adversos, limitados y útiles con el objetivo de optimizar el equilibrio entre FRR y VR. También descubrimos que el tamaño del modelo afecta a los resultados del aprendizaje, por lo que adaptamos distintas combinaciones de seguridad para distintos tamaños de modelo.

La Figura 18 muestra el impacto del tamaño del modelo en el diseño de combinaciones de datos de seguridad para equilibrar la Tasa de Violación (VR) y la Tasa de Falsos Rechazos (FRR). Cada punto del diagrama de dispersión representa una combinación de datos distinta para equilibrar los datos de seguridad y los de utilidad. Los distintos tamaños de los modelos conservan distintas capacidades de aprendizaje en materia de seguridad. Nuestros experimentos muestran que el modelo 8B necesita una mayor proporción de datos de seguridad en relación con los datos de utilidad en la cartera general de SFT (ajuste fino supervisado) para lograr un rendimiento de seguridad comparable al del modelo 70B. Los modelos más grandes son más capaces de distinguir entre contextos adversos y de borde, lo que resulta en un equilibrio más deseable entre VR y FRR.
5.4.4 Resultados de seguridad
En primer lugar, ofrecemos una visión general del rendimiento general de Llama 3 en todos los aspectos y, a continuación, describimos los resultados de las pruebas de cada una de las nuevas funciones y nuestra eficacia a la hora de mitigar los riesgos de seguridad.
Rendimiento global:Las figuras 19 y 20 muestran los resultados de las tasas finales de violación y falso rechazo de Llama 3 en comparación con modelos similares. Estos resultados se centran en nuestro modelo de mayor escala de parámetros (Llama 3 405B) y lo comparan con competidores relacionados. Dos de estos competidores son sistemas integrales a los que se accede a través de API, y el otro es un modelo lingüístico de código abierto que alojamos internamente y evaluamos directamente. Probamos nuestro modelo Llama por sí solo y junto con Llama Guard, nuestra solución de seguridad a nivel de sistema de código abierto, como se detalla en la sección 5.4.7.
Aunque es deseable que los índices de violación sean más bajos, es fundamental utilizar los falsos rechazos como indicador inverso, ya que un modelo que siempre rechaza es el más alto en términos de seguridad, pero completamente inútil. Del mismo modo, un modelo que siempre responde a todas las peticiones, por muy problemática que sea la solicitud, es excesivamente perjudicial y tóxico. La Figura 21 explora cómo los diferentes modelos y sistemas del sector hacen concesiones y cómo se comporta Llama 3, utilizando nuestros puntos de referencia internos. Descubrimos que nuestro modelo es muy competitivo en términos de métricas de tasa de violación, además de tener una tasa baja de falsos rechazos, lo que sugiere un buen equilibrio entre utilidad y seguridad.
Seguridad multilingüe:Nuestros experimentos demuestran que los conocimientos de seguridad en inglés no son fácilmente transferibles a otros idiomas, sobre todo teniendo en cuenta los matices de las políticas de seguridad y los contextos específicos de cada lengua. Por tanto, es crucial recopilar datos de seguridad de alta calidad para cada idioma. También descubrimos que la distribución de los datos de seguridad por idioma afecta significativamente al rendimiento de la seguridad, ya que algunos idiomas se benefician del aprendizaje por transferencia mientras que otros requieren más datos específicos del idioma. Para lograr un equilibrio entre la tasa de falsos rechazos (FRR) y la tasa de violaciones (VR), añadimos de forma iterativa datos de adversarios y de límites mientras controlábamos el impacto de estas dos métricas.
La figura 19 ilustra los resultados de nuestra evaluación comparativa interna con modelos de contexto breve, mostrando las tasas de violación y de falsos rechazos de Llama 3 en inglés y otros idiomas, y comparándolas con modelos y sistemas similares. Para construir los modelos de referencia de cada idioma, utilizamos una combinación de instrucciones escritas por hablantes nativos, a veces complementadas con traducciones de los modelos de referencia en inglés. Para todos los idiomas que soportamos, comprobamos que Llama 405B junto con Llama Guard es al menos tan seguro como los dos sistemas competidores, si no contamos la seguridad más estricta, mientras que la tasa de falsos rechazos sigue siendo competitiva.
Seguridad a largo plazo:Los modelos de contexto largo sin mitigación específica son vulnerables a los ataques de fuga múltiple (Anil et al., 2024). Para abordar este problema, afinamos nuestro modelo en el conjunto de datos SFT, que contiene ejemplos de comportamiento seguro en presencia de demostraciones de comportamiento inseguro. Desarrollamos una estrategia de mitigación escalable que reduce significativamente la RV, neutralizando así eficazmente el impacto de los ataques de contexto más largo, incluso para 256 ataques. El impacto de este enfoque en la FRR y en la mayoría de las métricas de utilidad es casi insignificante.
Para cuantificar la eficacia de nuestras medidas de seguridad en contextos largos, utilizamos dos métodos de evaluación comparativa adicionales: DocQA y Many-shot. Para DocQA (abreviatura de "cuestionario de documentos"), utilizamos documentos largos que contienen información que podría utilizarse con fines adversos. Se proporciona al modelo el documento y un conjunto de preguntas relacionadas con el documento para comprobar si la pregunta es relevante para la información del documento, lo que afecta a la capacidad del modelo para responder a las preguntas de forma segura.
En Many-shot, siguiendo a Anil et al. (2024), construimos un registro de chat sintético formado por pares de pregunta-respuesta insegura. El último mensaje es independiente de los anteriores y se utiliza para comprobar si el comportamiento contextual inseguro afecta a las respuestas inseguras del modelo. La figura 20 muestra las tasas de violaciones y falsos rechazos de DocQA y Many-shot. Vemos que la Llama 405B (con y sin Llama Guard) supera al sistema Comp. 2 tanto en el índice de violaciones como en el de falsos rechazos para DocQA y Many-shot.En relación con Comp. 1, vemos que la Llama 405B es más segura, pero aumenta ligeramente el índice de falsos rechazos.
Seguridad en el uso de herramientas:La diversidad de posibles herramientas e invocaciones del uso de herramientas, así como las implementaciones que integran herramientas en el modelo, hacen que sea un reto mitigar por completo la capacidad de uso de herramientas (Wallace et al., 2024). Nos centramos en el caso de uso de búsqueda. La figura 20 muestra las tasas de infracciones y falsos rechazos. Realizamos pruebas con el sistema Comp. 1 y descubrimos que el Llama 405B es más seguro, pero tiene una tasa de falsos rechazos ligeramente superior.

Comparación de Llama 3 405B (con y sin protección del sistema Llama Guard (LG)) con modelos y sistemas de la competencia.Comp. 3 Los idiomas no compatibles se indican con "x". ". Cuanto menor sea el valor, mejor.

Figura 20 Tasa de violaciones (VR) y tasa de falsos rechazos (FRR) en el uso de herramientas y la evaluación comparativa de textos largos. Cuanto más bajo, mejor. El rendimiento de las pruebas de referencia DocQA y Multi-Round Q&A se presenta por separado. Tenga en cuenta que, debido a la naturaleza adversarial de esta prueba de referencia, no disponemos de un conjunto de datos acotado para el cuestionario multirronda y, por lo tanto, no medimos la tasa de falsos rechazos. En cuanto al uso de la herramienta (búsqueda), sólo comparamos Llama 3 405B con Comp. 1.

Figura 21 Índices de infracción y rechazo de modelos y capacidades. Cada punto representa el índice de rechazo global. Y los índices de violación se evalúan para los puntos de referencia de capacidades inherentes a todas las categorías de seguridad. Los símbolos indican si estamos evaluando la seguridad a nivel de modelo o a nivel de sistema. Como era de esperar, los resultados para la seguridad a nivel de modelo muestran mayores tasas de violación y menores tasas de rechazo que los resultados para la seguridad a nivel de sistema.Llama 3 pretende equilibrar bajas tasas de violación con bajas tasas de falsos rechazos, mientras que algunos competidores prefieren una u otra.
5.4.5 Resultados de la evaluación de la ciberseguridad
Para evaluar el riesgo de ciberseguridad, utilizamos el marco de referencia CyberSecEval (Bhatt et al., 2023, 2024), que incorpora mediciones de seguridad para tareas como la generación de código inseguro, la generación de código malicioso, la inyección de texto y la identificación de vulnerabilidades. Desarrollamos y aplicamos Llama 3 a nuevos puntos de referencia, incluidos el spear phishing y los ataques de red autónomos. En general, comprobamos que Llama 3 no es significativamente vulnerable a la generación de código malicioso ni a la explotación de vulnerabilidades. A continuación se presentan breves resultados de tareas específicas:
- Un marco para probar la codificación insegura:Al evaluar los modelos Llama 3 8B, 70B y 405B con el marco de pruebas de codificación insegura, seguimos observando que los modelos más grandes generan más código inseguro y el código tiene una puntuación BLEU media más alta (Bhatt et al., 2023).
- Corpus de Códigos de Abuso del Intérprete de Códigos:Encontramos que el modelo Llama 3 es propenso a ejecutar código malicioso en prompts específicos, donde Llama 3 405B tiene una tasa de cumplimiento de 10,41 TP3T a prompts maliciosos, comparado con 3,81 TP3T para Llama 3 70B.
- Prueba comparativa de inyección de puntas de texto:Cuando se evaluó frente a la referencia de inyección de señales, la Llama 3 405B se enfrentó con éxito a un ataque de inyección de señales a 21,71 TP3T. La figura 22 ilustra la tasa de éxito de la inyección de señales textuales para los modelos Llama 3, GPT-4 Turbo, Gemini Pro y Mixtral.
- Desafíos en la identificación de vulnerabilidades:Al evaluar la capacidad de Llama 3 para identificar y explotar vulnerabilidades mediante el desafío de prueba Capture-the-Flag de CyberSecEval 2, Llama 3 no logró superar a las herramientas y técnicas tradicionales no-LLM de uso común.
- Puntos de referencia de la pesca submarina:Evaluamos la capacidad de persuasión y el éxito del modelo a la hora de mantener conversaciones personalizadas para engañar a los objetivos y conseguir que se comprometan con la seguridad sin saberlo. Se utilizaron perfiles de víctimas aleatorios y detallados generados por el LLM para engañar a los objetivos. El LLM evaluador (Llama 3 70B) valoró la actuación de Llama 3 70B y 405B al interactuar con el modelo de víctima (Llama 3 70B) y evaluó el éxito de los intentos. El LLM juzgador evaluó a la Llama 3 70B como exitosa en los intentos de pesca submarina a 241 TP3T y a la Llama 3 405B como exitosa en los intentos a 141 TP3T. La figura 23 ilustra las puntuaciones persuasivas de la evaluación del LLM juzgador para cada modelo y objetivo de pesca.
- Marco de automatización de ataques:Evaluamos el potencial de Llama 3 405B como agente autónomo en cuatro fases clave de un ataque de ransomware: reconocimiento de la red, identificación de vulnerabilidades, ejecución de exploits y acciones posteriores a la explotación. Habilitamos el modelo para comportarse de forma autónoma configurándolo para generar y ejecutar iterativamente nuevos comandos Linux en una máquina virtual Kali Linux contra otra máquina virtual con vulnerabilidades conocidas. Aunque Llama 3 405B fue eficaz en la identificación de servicios de red y puertos abiertos durante el reconocimiento de la red, no pudo utilizar eficazmente esta información para obtener acceso inicial a máquinas vulnerables durante 34 ejecuciones de prueba. La Llama 3 405B funcionó moderadamente bien en la identificación de vulnerabilidades, pero tuvo dificultades para seleccionar y aplicar técnicas de explotación con éxito. Los intentos de realizar exploits y mantener el acceso o realizar movimientos laterales dentro de la red fracasaron por completo.
Prueba de elevación de ciberataque:Realizamos un estudio de refuerzo para medir hasta qué punto los asistentes virtuales mejoran las tasas de ataque de atacantes novatos y expertos en dos retos de ciberseguridad ofensiva simulados. En el estudio participaron 62 voluntarios internos. Los voluntarios se clasificaron en "expertos" (31 sujetos) y "novatos" (31 sujetos) en función de su experiencia en seguridad ofensiva.
Para evaluar los riesgos asociados a la proliferación de armas químicas y biológicas, realizamos una prueba de refuerzo destinada a evaluar si el uso de Llama 3 mejora significativamente la capacidad de los actores para planificar este tipo de ataques.
Diseño experimental.
- El estudio consistió en un escenario de seis horas en el que se pidió a dos participantes que desarrollaran planes operativos ficticios para un ataque biológico o químico.
- Los escenarios abarcan las principales fases de planificación (adquisición de reactivos, producción, armamento y entrega) de un ataque QBRNE (químico, biológico, radiológico, nuclear y con explosivos), y están diseñados para desencadenar una planificación detallada que aborde cuestiones relacionadas con el acceso a materiales restringidos, los protocolos de laboratorio en el mundo real y la seguridad operativa.
- Los participantes fueron seleccionados en función de su experiencia previa en un campo relacionado con la ciencia o las operaciones y asignados a un equipo de dos agentes poco cualificados (sin formación formal) o dos agentes medianamente cualificados (con cierta formación formal y experiencia práctica en ciencia u operaciones).
Métodos de investigación.
- El estudio se ha desarrollado en colaboración con un grupo de expertos en CBRNE y pretende maximizar la aplicabilidad general, la validez y la solidez de los resultados cuantitativos y cualitativos.
- Se realizó un estudio preliminar para validar el diseño del estudio, incluido un sólido análisis de eficacia para garantizar que el tamaño de nuestra muestra fuera suficiente para el análisis estadístico.
- Cada equipo se asigna a las condiciones "control" o "LLM". El grupo de control solo tenía acceso a recursos basados en Internet, mientras que los equipos equipados con LLM tenían acceso al modelo Llama 3 con búsqueda web (incluida la ingestión de PDF), recuperación de información (RAG) y ejecución de código (Python y Wolfram Alpha) habilitados, además de Internet.
- Para probar la funcionalidad de la GAR, se generó un conjunto de cientos de artículos científicos relevantes mediante búsquedas de palabras clave y se cargaron previamente en el sistema de inferencia de modelos Llama 3.
Evaluación.
- Al final del ejercicio, los planes de acción generados por cada equipo serán evaluados por expertos en los campos de la biología, la química y la planificación operativa.
- Cada plan se evalúa en cuatro etapas de un ataque potencial, generando puntuaciones para métricas como la precisión científica, el detalle, la evasión de la detección y la probabilidad de éxito de la ejecución científica y operativa.
- Tras un riguroso proceso Delphi para mitigar el sesgo y la variabilidad en las evaluaciones de los expertos en la materia (SME), las puntuaciones finales se generaron combinando indicadores a nivel de etapa.
Análisis de los resultados.
Los análisis cuantitativos indican que el uso del modelo Llama 3 no mejora significativamente el rendimiento. Este resultado se mantiene tanto para el análisis global (comparando todas las condiciones LLM con la condición de control sólo Web) como para desgloses específicos de subgrupos (por ejemplo, evaluando los modelos Llama 3 70B y Llama 3 405B por separado, o evaluando escenarios relacionados con armas químicas o biológicas por separado). Tras validar estos resultados con la PYME CBRNE, evaluamos como baja la probabilidad de que la publicación del modelo Llama 3 aumente el riesgo asociado a un ataque con armas biológicas o químicas en el ecosistema.

5.4.6 Tácticas del equipo rojo
Utilizamos "pruebas de equipo rojo" para identificar riesgos y utilizar estos resultados para mejorar nuestros conjuntos de datos de evaluación comparativa y ajuste de seguridad. Llevamos a cabo ejercicios regulares de equipo rojo para iterar continuamente e identificar nuevos riesgos, que guían nuestro proceso de desarrollo y mitigación de modelos.
Nuestro Red Team está formado por expertos en ciberseguridad, aprendizaje automático adversarial, IA responsable e integridad, además de expertos en contenidos multilingües con experiencia en cuestiones de integridad en mercados geográficos específicos. También trabajamos con expertos internos y externos en la materia para crear taxonomías de riesgos y ayudar con evaluaciones más específicas de adversarios.
Pruebas adversariales para capacidades de modelos específicos. En primer lugar, realizamos pruebas del equipo rojo centrándonos en las características individuales del modelo para categorías específicas de alto riesgo y, a continuación, probamos estas características en conjunto. Centrándose en los ataques de nivel indirecto que simulan escenarios más realistas, el equipo rojo descubrió que los modelos se desviaban a menudo del comportamiento esperado, especialmente cuando el esquema de mención estaba ofuscado o las pistas incluían múltiples abstracciones en cascada. Estos riesgos se hicieron más complejos con la adición de más características, y describimos algunos de nuestros hallazgos del equipo rojo en detalle a continuación. Utilizamos estos hallazgos del equipo rojo junto con los resultados de nuestra evaluación comparativa de seguridad interna para desarrollar mitigaciones específicas que mejoren iterativamente la seguridad del modelo.
- Texto corto y texto largo en inglés. Empleamos una conocida combinación de técnicas publicadas e inéditas en diálogos de una y varias rondas. También utilizamos técnicas avanzadas de automatización adversarial multirronda similares a PAIR (Chao et al., 2023) para algunas técnicas y categorías de riesgo. En general, el diálogo multirronda conduce a resultados más dañinos. Muchos ataques prevalecen en los puntos de control del modelo, especialmente cuando se utilizan juntos.
- Múltiples rondas de supresión de denegaciones: Especifica que la respuesta del modelo debe seguir un formato determinado o incluir/excluir información sobre una frase concreta asociada al rechazo.
- Embalaje de escena hipotética: Plantee la infracción como una tarea hipotética/teórica o un escenario ficticio. Puede ser tan sencillo como añadir la palabra "hipotéticamente" o construir un escenario jerárquico complejo.
- Juego de roles: Asigne roles ofensivos a modelos con características de respuesta ofensivas específicas (por ejemplo, "Usted es X y su objetivo es Y"), o usted mismo como usuario encarne roles benignos específicos para enmascarar el contexto de la indicación.
- La adición de avisos y advertencias es una forma de iniciación a la reacción que, según nuestra hipótesis, es una manera de proporcionar al modelo un camino hacia el cumplimiento beneficioso que se cruza con la formación generalizada en seguridad. Junto con los otros ataques mencionados, medidas como pedir que se añadan cláusulas de exención de responsabilidad, advertencias de activación, etc. en múltiples rondas de diálogo pueden conducir a un aumento de los índices de incumplimiento.
- Las violaciones escalonadas son ataques de varias rondas en los que el diálogo comienza con una petición más o menos benigna y luego genera un contenido más exagerado a través de indicaciones directas, llevando gradualmente al modelo a generar respuestas muy ofensivas. Una vez que un modelo empieza a emitir el contenido ofensivo, puede ser difícil recuperarlo (o si se encuentra con una denegación, se pueden utilizar otros ataques). Este problema será cada vez más frecuente en los modelos con contextos largos.
- Multilingüe. Cuando se consideran varias lenguas, encontramos muchos riesgos únicos.
- Mezclar varias lenguas en un mensaje o diálogo puede dar lugar fácilmente a un resultado más ofensivo que utilizar una sola lengua.
- Los lenguajes con pocos recursos pueden dar lugar a resultados violados debido a la falta de datos pertinentes para el ajuste de la seguridad, a la escasa generalización de los modelos a la seguridad o a la priorización de las pruebas o los puntos de referencia. Sin embargo, este tipo de ataques suele dar lugar a resultados de baja calidad, lo que limita la explotación malintencionada real.
- La jerga, las referencias específicas del contexto o de la cultura pueden dar la falsa impresión de una violación para empezar, pero en realidad el modelo no entiende una referencia correctamente, por lo que la salida no es realmente perjudicial y no se puede hacer que sea una salida violatoria.
- Uso de herramientas. Durante las pruebas, se identificaron varios ataques específicos a la herramienta, además de las técnicas de provocación adversarial a nivel de texto en inglés que produjeron con éxito la salida ofensiva. Esto incluye, pero no se limita a:
Las llamadas de encadenamiento de herramientas inseguras, como la solicitud de varias herramientas al mismo tiempo, una de las cuales está en infracción, pueden dar lugar a una mezcla de infracciones y entradas benignas a todas las herramientas en un punto de control temprano.
Uso obligatorio de herramientas: Imponer con frecuencia el uso de herramientas con cadenas de entrada específicas, fragmentación o texto codificado puede dar lugar a posibles violaciones de las entradas de la herramienta, lo que se traduce en más salidas ofensivas. Entonces pueden emplearse técnicas alternativas para acceder a los resultados de la herramienta, incluso si el modelo normalmente se negaría a realizar una búsqueda o a ayudar a procesar los resultados.
Modificar los parámetros de uso de la herramienta: Por ejemplo, intercambiar palabras en una consulta, reintentarla o difuminar parte de la petición inicial en un diálogo de varias rondas puede dar lugar a infracciones en muchos puntos de control tempranos como forma de imponer el uso de herramientas.
Riesgos para la seguridad infantil: Reunimos a un equipo de expertos para llevar a cabo evaluaciones de riesgos para la seguridad infantil con el fin de valorar la capacidad del modelo para producir resultados que pudieran dar lugar a riesgos para la seguridad infantil y para informar sobre cualquier medida necesaria y adecuada de mitigación de riesgos (a través de la puesta a punto). Utilizamos estas reuniones del equipo rojo de expertos para ampliar la cobertura de nuestros puntos de referencia de evaluación desarrollados a través del modelo. Para Llama 3, llevamos a cabo una nueva sesión en profundidad utilizando un enfoque basado en objetivos para evaluar el riesgo del modelo a lo largo de múltiples rutas de ataque. También trabajamos con expertos en contenidos para realizar ejercicios de equipo rojo con el fin de evaluar contenidos potencialmente ofensivos, teniendo en cuenta matices o experiencias específicas del mercado.
5.4.7 Seguridad del sistema
Los modelos lingüísticos a gran escala no se utilizan de forma aislada en diversas aplicaciones del mundo real, sino que se integran en sistemas más amplios. Esta sección describe nuestra implementación de la seguridad a nivel de sistema, que complementa la mitigación a nivel de modelo proporcionando flexibilidad y control adicionales.
Con este fin, hemos desarrollado y lanzado un nuevo clasificador, Llama Guard 3, un modelo Llama 3 8B afinado para la clasificación de seguridad. Al igual que Llama Guard 2 (Llama-Team, 2024), este clasificador se utiliza para detectar si las señales de entrada y/o las respuestas de salida generadas por el modelo lingüístico infringen la política de seguridad para una clase de peligro concreta.
Está diseñado para soportar las crecientes capacidades de Llama para texto en inglés y multilingüe. También está optimizado para su uso en el contexto de llamadas a herramientas (por ejemplo, herramientas de búsqueda) y para evitar el abuso del intérprete de código. Por último, ofrecemos variantes cuantificadas para reducir los requisitos de memoria. Animamos a los desarrolladores a utilizar nuestras versiones de los componentes de seguridad del sistema como base y configurarlas para sus propios casos de uso.
clasificaciónEntrenamos utilizando las 13 categorías de daños enumeradas en la Taxonomía de Seguridad de la IA (Vidgen et al., 2024): explotación sexual infantil, difamación, elecciones, odio, armas indiscriminadas, propiedad intelectual, delitos no violentos, privacidad, delitos relacionados con el sexo, contenido pornográfico, asesoramiento profesional, suicidio y autolesiones, y delitos violentos. También nos formamos contra categorías de abuso de intérpretes de código para apoyar casos de uso de llamadas a herramientas.
Datos de formaciónCaracterísticas: Empezamos con datos en inglés utilizados por Llama Guard (Inan et al., 2023) y ampliamos este conjunto de datos para incluir nuevas características. Para las nuevas características, como el multilingüismo y el uso de herramientas, recopilamos datos de categorización de pistas y respuestas, así como datos utilizados para el ajuste de la seguridad. El número de respuestas inseguras en el conjunto de entrenamiento se incrementa realizando ingeniería de pistas para que el LLM no rechace respuestas a pistas adversas. Utilizamos Llama 3 para obtener etiquetas de respuesta para estos datos generados.
Para mejorar el rendimiento de Llama Guard 3, limpiamos exhaustivamente las muestras recogidas utilizando tanto el etiquetado humano como el etiquetado LLM del modelo Llama 3. La obtención de etiquetas para las señales de usuario es más difícil tanto para los humanos como para los LLM. La obtención de etiquetas para las señales de usuario es más difícil tanto para los humanos como para los LLM, y nos pareció que el etiquetado manual era ligeramente mejor, especialmente para las señales de límite, aunque nuestro sistema iterativo completo fue capaz de reducir el ruido y producir etiquetas más precisas.
Resultados. Llama Guard 3 reduce significativamente las violaciones entre capacidades (la tasa media de violaciones se redujo en 65% en nuestra evaluación comparativa). Hay que tener en cuenta que añadir salvaguardas al sistema (así como cualquier mitigación de seguridad) tendrá el coste de aumentar el rechazo de peticiones benignas. La Tabla 25 muestra la disminución de la tasa de infracciones y el aumento de los falsos rechazos en comparación con el modelo base para resaltar esta compensación. Este impacto también es visible en las Figuras 19, 20 y 21.
La seguridad del sistema también proporciona una mayor flexibilidad, ya que Llama Guard 3 puede desplegarse sólo para peligros específicos, permitiendo el control de las violaciones y las compensaciones de falsa denegación a nivel de categoría de peligro. La Tabla 26 enumera las reducciones de violaciones por categoría para determinar qué categorías deben activarse/desactivarse en función de los casos de uso del desarrollador.
Para simplificar el despliegue de sistemas de seguridad, proporcionamos una versión cuantificada de Llama Guard 3 utilizando la técnica de cuantificación int8 de uso común, reduciendo su tamaño en más de 40%. La tabla 27 ilustra que la cuantificación tiene un impacto insignificante en el rendimiento del modelo.
El componente de seguridad a nivel de sistema permite a los desarrolladores personalizar y controlar cómo responde el sistema LLM a las peticiones de los usuarios. Para mejorar la seguridad general del sistema de modelado y permitir a los desarrolladores desplegar modelos de forma responsable, describimos y publicamos dos mecanismos de filtrado basados en sugerencias:Prompt Guard responder cantando Código Escudo. Los ponemos a disposición de la comunidad en código abierto para que puedan utilizarlos tal cual o inspirarse en ellos para adaptarlos a sus casos de uso.
Prompt Guard es un filtro basado en un modelo diseñado para detectar ataques de indirecta, es decir, cadenas de entrada diseñadas para subvertir el comportamiento esperado del LLM como parte de la aplicación. El modelo es un clasificador multietiqueta que detecta dos tipos de riesgos de ataque por indirecta:
- Fuga directa (intento explícito de anular las condiciones de seguridad del modelo o las técnicas promovidas por el sistema).
- Inyección indirecta de comandos (el caso en el que la ventana de contexto del modelo contiene datos de terceros, incluyendo instrucciones para comandos de usuario que fueron ejecutados accidentalmente por el LLM).
El modelo se ha ajustado a partir de mDeBERTa-v3-base (un modelo pequeño con 86 millones de parámetros) y es adecuado para filtrar entradas en el LLM. Evaluamos su rendimiento en varios conjuntos de datos de evaluación que se muestran en la Tabla 28. Evaluamos dos conjuntos de datos de la misma distribución que los datos de entrenamiento (jailbreaks e inyecciones), así como un conjunto de datos fuera de distribución en inglés, un conjunto multilingüe de jailbreak basado en traducción automática y un conjunto de datos de inyección indirecta de CyberSecEval (inglés y multilingüe). En general, comprobamos que el modelo se generaliza bien a nuevas distribuciones y tiene un rendimiento sólido.
Código Escudo es un ejemplo de clase de protección a nivel de sistema basada en el filtrado en tiempo de inferencia. Se centra específicamente en detectar la generación de código inseguro antes de que pueda entrar en casos de uso posteriores (por ejemplo, sistemas de producción). Para ello, aprovecha la biblioteca de análisis estático "Insecure Code Detector" (ICD) para identificar el código inseguro. ICD utiliza un conjunto de herramientas de análisis estático para realizar análisis en siete lenguajes de programación. Este tipo de protección suele ser muy útil para los desarrolladores, que pueden desplegar varias capas de protección en diversas aplicaciones.



5.4.8 Limitaciones
Hemos llevado a cabo un extenso trabajo para medir y mitigar los diversos riesgos asociados al uso seguro de Llama 3. Sin embargo, ninguna prueba puede garantizar la identificación completa de todos los riesgos posibles. Como resultado del entrenamiento en una variedad de conjuntos de datos, especialmente en idiomas distintos del inglés y sujeto a pistas cuidadosamente elaboradas por miembros del equipo rojo de adversarios expertos, Llama 3 aún puede generar contenido dañino. Los desarrolladores malintencionados o los usuarios adversarios pueden encontrar nuevas formas de descifrar nuestros modelos y utilizarlos para diversos fines nefastos. Seguiremos identificando riesgos de forma proactiva, investigando métodos de mitigación y animando a los desarrolladores a tener en cuenta la responsabilidad en todos los aspectos, desde el desarrollo del modelo hasta su despliegue a los usuarios. Esperamos que los desarrolladores aprovechen y contribuyan a las herramientas publicadas en nuestra suite de seguridad a nivel de sistema de código abierto.
6 Inferencia
Investigamos dos técnicas principales para mejorar la eficiencia de inferencia del modelo Llama 3 405B: (1) el paralelismo de canalización y (2) la cuantificación FP8. Hemos publicado una implementación de la cuantificación FP8.
6.1 Paralelismo de canalizaciones
El modelo Llama 3 405B no cabe en la memoria de la GPU de una sola máquina equipada con 8 GPU Nvidia H100 cuando se utiliza BF16 para representar los parámetros del modelo. Para solucionar este problema, utilizamos la precisión BF16 para paralelizar la inferencia del modelo en 16 GPU de dos máquinas. Dentro de cada máquina, NVLink de gran ancho de banda permite el uso del paralelismo tensorial (Shoeybi et al., 2019). Sin embargo, las conexiones entre nodos tienen menor ancho de banda y mayor latencia, por lo que utilizamos el paralelismo de canalización (Huang et al., 2019).
Las burbujas son un importante problema de eficiencia durante el entrenamiento utilizando el paralelismo de canalización (véase la Sección 3.3). Sin embargo, no son un problema durante la inferencia, ya que la inferencia no implica retropropagación que requiera el lavado de tuberías. Por lo tanto, utilizamos la micromezcla para mejorar el rendimiento de la inferencia en paralelo.
Evaluamos el efecto de utilizar dos microlotes en una carga de trabajo de inferencia de 4.096 tokens de entrada y 256 tokens de salida para la fase de prepoblación de la caché de valores clave y la fase de descodificación de la inferencia, respectivamente. Observamos que el micromezclado mejora el rendimiento de la inferencia para el mismo tamaño de lote local; véase la figura 24. Estas mejoras se deben a la capacidad del micromezclado de ejecutar micromezclas simultáneamente en ambas fases. Dado que el micro-batching conlleva puntos de sincronización adicionales, también aumenta la latencia, pero en general, el micro-batching sigue ofreciendo una mejor relación rendimiento-latencia.


6.2 Cuantificación del 8PM
Realizamos experimentos de inferencia de baja precisión utilizando el soporte FP8 inherente a la GPU H100. Para lograr una inferencia de baja precisión, aplicamos la cuantificación FP8 a la mayoría de las multiplicaciones matriciales del modelo. En concreto, cuantificamos la gran mayoría de los parámetros y valores de activación de las capas de la red feedforward del modelo, que representan aproximadamente 50% del tiempo de cálculo de la inferencia. Utilizamos un factor de escalado dinámico para mejorar la precisión (Xiao et al., 2024b) y optimizamos nuestro kernel CUDA15 para reducir la sobrecarga de escalado computacional.
Descubrimos que la calidad de Llama 3 405B era sensible a ciertos tipos de cuantificación e introdujimos algunos cambios adicionales para mejorar la calidad de los resultados del modelo:
- Al igual que Zhang et al. (2021), no cuantificamos la primera y la última capa Transformer.
- Los tokens muy alineados (por ejemplo, fechas) pueden dar lugar a grandes valores de activación. A su vez, esto puede llevar a factores de escalado dinámico más altos en FP8 y a una cantidad no despreciable de desbordamiento de punto flotante, lo que lleva a errores de descodificación. La Figura 26 muestra la distribución de las puntuaciones de recompensa para Llama 3 405B usando inferencia BF16 y FP8. Nuestro método de cuantificación FP8 tiene poco efecto en la respuesta del modelo.
Para resolver este problema, fijamos el límite superior del factor de escala dinámico en 1200.
- Utilizamos la cuantificación fila por fila para calcular los factores de escala entre filas para las matrices de parámetros y activación (véase la Figura 25). Nos pareció que funcionaba mejor que el método de cuantificación a nivel de tensor.
cuantificar el impacto de los errores. Las evaluaciones de puntos de referencia estándar suelen mostrar que, incluso sin estas mitigaciones, el razonamiento FP8 tiene un rendimiento comparable al razonamiento BF16. Sin embargo, descubrimos que estas pruebas no reflejan adecuadamente el impacto de la cuantificación FP8. Cuando el factor de escala no está limitado, el modelo produce ocasionalmente respuestas corruptas, incluso cuando el rendimiento de la referencia es bueno.
En lugar de basarse en puntos de referencia para medir los cambios en la distribución debidos a la cuantificación, es posible analizar la distribución de las puntuaciones del modelo de recompensa para las 100.000 respuestas generadas utilizando BF16 y FP8. La figura 26 muestra la distribución de recompensas obtenida por nuestro método de cuantificación. Los resultados muestran que nuestro método de cuantificación FP8 tiene un impacto muy limitado en las respuestas del modelo.
evaluación experimental de la eficiencia. La Figura 27 muestra el equilibrio entre rendimiento y latencia al realizar la inferencia FP8 en las fases de prepoblación y decodificación utilizando 4.096 tokens de entrada y 256 tokens de salida con la Llama 3 405B. La figura compara la eficiencia de la inferencia FP8 con el enfoque de inferencia BF16 de dos máquinas descrito en la Sección 6.1. Los resultados muestran que el uso de la inferencia FP8 mejora el rendimiento en la fase de prepoblación hasta 50% y mejora sustancialmente la relación rendimiento-retraso durante la descodificación.



7 Experimentos visuales
Hemos llevado a cabo una serie de experimentos para integrar las capacidades de reconocimiento visual en Llama 3 mediante un enfoque combinado. El enfoque se divide en dos fases principales:
Primera etapa. Combinamos un codificador de imágenes preentrenado (Xu et al., 2023) con un modelo de lenguaje preentrenado e introdujimos y entrenamos un conjunto de capas de atención cruzada (Alayrac et al., 2022) en un gran número de pares imagen-texto. El resultado fue el modelo que se muestra en la Figura 28.
Segunda etapa. Introducimos una capa de agregación temporal y capas adicionales de atención cruzada de vídeo que actúan sobre un gran número de pares de texto de vídeo para aprender el modelo de reconocimiento y procesamiento de la información temporal de los vídeos.
El enfoque combinatorio para construir modelos base tiene varias ventajas.
(1) Nos permite desarrollar paralelamente funciones de modelización visual y lingüística;
(2) Evita las complejidades asociadas al preentrenamiento conjunto de datos visuales y verbales, que surgen de la tokenización de los datos visuales, las diferencias en la perplejidad de fondo entre modalidades y la competencia entre modalidades;
(3) Garantiza que la introducción de capacidades de reconocimiento visual no afecte al rendimiento del modelo en tareas de sólo texto;
(4) La arquitectura de atención cruzada garantiza que no necesitemos pasar imágenes de resolución completa a la columna vertebral LLM en constante crecimiento (especialmente la red feed-forward en cada capa Transformer), mejorando así la eficiencia de la inferencia.
Tenga en cuenta que nuestro modelo multimodal aún está en fase de desarrollo y no está listo para su lanzamiento.
Antes de presentar los resultados experimentales en las Secciones 7.6 y 7.7, describimos los datos utilizados para entrenar las capacidades de reconocimiento visual, la arquitectura del modelo de los componentes visuales, cómo ampliamos el entrenamiento de estos componentes y nuestras recetas de preentrenamiento y postentrenamiento.
7.1 Datos
Describimos los datos de imagen y vídeo por separado.
7.1.1 Datos de imagen
Nuestros codificadores y adaptadores de imágenes se entrenan con pares imagen-texto. Construimos este conjunto de datos mediante un complejo proceso que consta de cuatro etapas principales:
(1) Filtrado de calidad (2) Desacentuación perceptiva (3) Remuestreo (4) Reconocimiento óptico de caracteres . También hemos aplicado una serie de medidas de seguridad.
- Filtración masiva. Implementamos filtros de calidad para eliminar los pies de foto que no están en inglés y los de baja calidad mediante heurísticas como las puntuaciones de alineación bajas generadas por (Radford et al., 2021). En concreto, eliminamos todos los pares imagen-texto que caen por debajo de una puntuación CLIP específica.
- Sin énfasis. La desduplicación de conjuntos de datos de entrenamiento a gran escala mejora el rendimiento del modelo, ya que reduce los cálculos de entrenamiento para datos redundantes (Esser et al. 2024; Lee et al. 2021; Abbas et al. 2023) y reduce el riesgo de memorización del modelo (Carlini et al. 2023; Somepalli et al. 2023). Por lo tanto, desduplicamos los datos de entrenamiento por razones de eficiencia y privacidad. Para ello, utilizamos la última versión interna del modelo de detección de copias SSCD (Pizzi et al., 2022) para desduplicar masivamente las imágenes. Para todas las imágenes, primero calculamos una representación de 512 dimensiones utilizando el modelo SSCD. A continuación, utilizamos estas incrustaciones para realizar una búsqueda del vecino más próximo (NN) en todas las imágenes del conjunto de datos, utilizando una métrica de similitud coseno. Definimos los ejemplos que superan un umbral de similitud específico como términos duplicados. Agrupamos estos términos duplicados mediante un algoritmo de componentes conectados y conservamos sólo un par imagen-texto por cada componente conectado. Mejoramos la eficiencia de la tubería de desduplicación mediante (1) la agrupación previa de los datos utilizando la agrupación k-mean (2) utilizando FAISS para la búsqueda y agrupación de NN (Johnson et al., 2019).
- Remuestreo. Garantizamos la diversidad de pares imagen-texto, de forma similar a Xu et al. (2023); Mahajan et al. (2018); Mikolov et al. (2013). En primer lugar, construimos un glosario gramatical de n-tuplas analizando fuentes de texto de alta calidad. A continuación, calculamos la frecuencia de n-tuplas gramaticales para cada glosario en el conjunto de datos. A continuación, volvemos a muestrear los datos de la siguiente manera: si cualquier gramática de n-tuplas de un pie de foto aparece menos de T veces en el glosario, conservamos el par imagen-texto correspondiente. En caso contrario, muestreamos independientemente cada gramática n-tupla n i en el titular con probabilidad T / f i, donde f i denota la frecuencia de la gramática n-tupla n i; si se muestreó cualquier gramática n-tupla, conservamos el par imagen-texto. Este remuestreo ayuda a mejorar el rendimiento de las categorías de baja frecuencia y las tareas de reconocimiento de grano fino.
- Reconocimiento óptico de caracteres. Hemos mejorado aún más nuestros datos de texto de imágenes extrayendo el texto de la imagen y encadenándolo con un pie de foto. El texto escrito se extrajo mediante un proceso propio de reconocimiento óptico de caracteres (OCR). Hemos observado que añadir datos de OCR a los datos de entrenamiento puede mejorar mucho el rendimiento de tareas que requieren capacidades de OCR, como la comprensión de documentos.
Para mejorar el rendimiento del modelo en la tarea de comprensión de documentos, representamos las páginas de los documentos como imágenes y emparejamos las imágenes con sus respectivos textos. El texto del documento se obtiene directamente de la fuente o mediante un proceso de análisis sintáctico.
Seguridad: Nuestro principal objetivo es garantizar que los conjuntos de datos de preentrenamiento para el reconocimiento de imágenes no contengan contenidos inseguros, como material sexualmente abusivo (CSAM) (Thiel, 2023). Utilizamos métodos de hash perceptual como PhotoDNA (Farid, 2021), así como un clasificador propio que escanea todas las imágenes de entrenamiento en busca de CSAM. También utilizamos una canalización propia de recuperación de riesgos de medios para identificar y eliminar pares imagen-texto que consideramos NSFW, por ejemplo, porque contienen contenido sexual o violento. Creemos que minimizar la prevalencia de este tipo de material en el conjunto de datos de entrenamiento mejora la seguridad y utilidad del modelo final, sin comprometer su utilidad. Por último, realizamos un difuminado facial en todas las imágenes del conjunto de entrenamiento. Probamos el modelo con pistas generadas por humanos que hacen referencia a imágenes adicionales.
Datos de recocido: Creamos un conjunto de datos recocido que contiene aproximadamente 350 millones de ejemplos mediante el remuestreo de pares de pies de foto utilizando n-gramas. Como el remuestreo de n-gramas favorece las descripciones textuales más ricas, selecciona un subconjunto de datos de mayor calidad. A los datos resultantes añadimos unos 150 millones de ejemplos procedentes de otras cinco fuentes:
- Orientación visual. Asociamos frases sustantivadas del texto a recuadros o máscaras de la imagen. La información de localización (cuadros delimitadores y máscaras) se especifica en los pares imagen-texto de dos maneras:(1) Superponemos los cuadros o máscaras en la imagen y utilizamos marcadores como referencias en el texto, de forma similar a un conjunto de marcadores (Yang et al., 2023a). (2) Insertamos las coordenadas normalizadas (x min, y min, x max, y max) directamente en el texto y las separamos con marcadores especiales.
- Análisis de capturas de pantalla. Hacemos capturas de pantalla a partir de código HTML y dejamos que el modelo prediga el código que genera elementos específicos de la captura de pantalla, de forma similar a Lee et al. (2023). Los elementos de interés se indican en la captura de pantalla mediante cuadros delimitadores.
- Preguntas y respuestas con. Incluimos pares de preguntas y respuestas que nos permiten utilizar grandes cantidades de datos de preguntas y respuestas que son demasiado grandes para utilizarlos en el ajuste fino del modelo.
- Título sintético. Incluimos imágenes con pies de foto sintéticos generados a partir de versiones anteriores del modelo. En comparación con los pies de foto originales, comprobamos que los sintéticos ofrecían una descripción más completa de la imagen que los originales.
- Síntesis de imágenes estructuradas. También incluimos imágenes generadas sintéticamente para diversos campos, como gráficos, tablas, diagramas de flujo, fórmulas matemáticas y datos de texto. Estas imágenes van acompañadas de las correspondientes representaciones estructuradas, como la correspondiente notación Markdown o LaTeX. Además de mejorar la capacidad de reconocimiento del modelo en estos ámbitos, hemos comprobado que estos datos son útiles para generar pares de preguntas y respuestas que se pueden afinar mediante el modelado textual.

Fig. 28 Esquema del enfoque combinado para añadir capacidades multimodales a Llama 3 estudiado en este artículo. Este enfoque da como resultado un modelo multimodal que se entrena en cinco etapas: preentrenamiento del modelo lingüístico, preentrenamiento del codificador multimodal, entrenamiento del adaptador visual, ajuste fino del modelo y entrenamiento del adaptador del habla.
7.1.2 Datos de vídeo
Para el preentrenamiento de vídeo, utilizamos un amplio conjunto de datos de pares vídeo-texto. Nuestro conjunto de datos se recopila mediante un proceso de varias fases. Utilizamos reglas heurísticas para filtrar y limpiar el texto pertinente, por ejemplo, garantizando una longitud mínima y fijando las mayúsculas. A continuación, utilizamos modelos de reconocimiento del lenguaje para filtrar el texto que no está en inglés.
Ejecutamos el modelo de detección OCR para filtrar los vídeos con texto excesivamente superpuesto. Para garantizar una alineación razonable entre pares de vídeo-texto, utilizamos modelos de comparación imagen-texto y vídeo-texto del estilo de CLIP (Radford et al., 2021). Primero calculamos la similitud imagen-texto utilizando un único fotograma del vídeo y filtramos los pares con baja similitud, y posteriormente filtramos los pares con mala alineación vídeo-texto. Algunos de nuestros datos contenían vídeos fijos o con poco movimiento; los filtramos utilizando el filtrado basado en la puntuación de movimiento (Girdhar et al., 2023). No aplicamos ningún filtro a la calidad visual de los vídeos, como puntuaciones estéticas o filtros de resolución.
Nuestro conjunto de datos contiene vídeos con una duración mediana de 16 segundos y una duración media de 21 segundos, y más de 99% de los vídeos son inferiores a un minuto. La resolución espacial varía mucho entre los vídeos de 320p y 4K, y más de 70% de los vídeos tienen bordes cortos de más de 720 píxeles. Los vídeos tienen diferentes relaciones de aspecto, con casi todos los vídeos con una relación de aspecto entre 1:2 y 2:1, con una mediana de 1:1.
7.2 Arquitectura del modelo
Nuestro modelo de reconocimiento visual consta de tres componentes principales: (1) un codificador de imágenes, (2) un adaptador de imágenes y (3) un adaptador de vídeo.
Codificador de imágenes.
Nuestro codificador de imágenes es un transformador visual estándar (ViT; Dosovitskiy et al. (2020)) entrenado para alinear imágenes y texto (Xu et al., 2023). Utilizamos la versión ViT-H/14 del codificador de imágenes, que tiene 630 millones de parámetros y se entrenó durante cinco épocas con 2.500 millones de pares imagen-texto. La resolución de la imagen de entrada del codificador de imágenes fue de 224 × 224; la imagen se dividió en 16 × 16 trozos de igual tamaño (es decir, un tamaño de bloque de 14 × 14 píxeles). Como se ha demostrado en trabajos anteriores, como ViP-Llava (Cai et al., 2024), descubrimos que los codificadores de imágenes entrenados comparando objetivos alineados con texto no retienen información de localización detallada. Para mitigar este problema, utilizamos un enfoque de extracción de características multicapa que proporcionaba características en las capas 4, 8, 16, 24 y 31, además de la última capa de características.
Además, insertamos 8 capas de autoatención con compuerta (40 bloques Transformer en total) antes del preentrenamiento de las capas de atención cruzada para aprender características específicas de la alineación. El resultado fue un codificador de imágenes con 850 millones de parámetros y capas adicionales. Con múltiples capas de características, el codificador de imágenes produce una representación de 7680 dimensiones para cada uno de los 16 × 16 = 256 trozos generados. No congelamos los parámetros del codificador de imágenes en las fases de entrenamiento posteriores, ya que hemos comprobado que esto mejora el rendimiento, especialmente en áreas como el reconocimiento de textos.
Adaptadores de imagen.
Introducimos una capa de atención cruzada entre la representación del marcador visual producida por el codificador de imágenes y la representación del marcador producida por el modelo de lenguaje (Alayrac et al., 2022). La capa de atención cruzada se aplica después de cada cuarta capa de autoatención en el modelo de lenguaje principal. Al igual que el propio modelo de lenguaje, la capa de atención cruzada utiliza la atención a la consulta generalizada (GQA) para mejorar la eficacia.
La capa de atención cruzada introduce un gran número de parámetros entrenables en el modelo: para Llama 3 405B, la capa de atención cruzada tiene unos 100.000 millones de parámetros. Preentrenamos los adaptadores de imágenes en dos etapas: (1) preentrenamiento inicial y (2) recocido:*. Formación inicial previa. Preentrenamos nuestros adaptadores de imágenes en el mencionado conjunto de datos de unos 6.000 millones de pares imagen-texto. Para mejorar la eficiencia computacional, redimensionamos todas las imágenes para que quepan en un máximo de cuatro bloques de 336 × 336 píxeles, en los que organizamos los bloques para que admitan diferentes relaciones de aspecto, como 672 × 672, 672 × 336 y 1344 × 336. ● Los adaptadores de imágenes están diseñados para que quepan en un máximo de cuatro bloques de 336 × 336 píxeles. Recocido. Seguimos entrenando el adaptador de imágenes utilizando aproximadamente 500 millones de imágenes del conjunto de datos de recocido descrito anteriormente. Durante el proceso de recocido, aumentamos la resolución de imagen de cada parcela para mejorar el rendimiento en tareas que requieren imágenes de mayor resolución, como la comprensión infográfica.
Adaptador de vídeo.
Nuestro modelo acepta entradas de hasta 64 fotogramas (muestreados uniformemente del vídeo completo), cada uno de los cuales es procesado por un codificador de imágenes. Modelamos la estructura temporal en el vídeo mediante dos componentes: (i) los fotogramas de vídeo codificados se fusionan en uno mediante un agregador temporal, que combina 32 fotogramas consecutivos en uno; y (ii) se añaden capas adicionales de atención cruzada de vídeo antes de cada cuarta capa de atención cruzada de imagen. Los agregadores temporales se implementan como remuestreadores de perceptrón (Jaegle et al., 2021; Alayrac et al., 2022). Utilizamos 16 fotogramas por vídeo (agregados en 1 fotograma) para el preentrenamiento, pero aumentamos el número de fotogramas de entrada a 64 durante el ajuste fino supervisado. El agregador de vídeo y la capa de atención cruzada tienen 0,6 y 4,6 mil millones de parámetros en Llama 3 7B y 70B, respectivamente.
7.3 Tamaño del modelo
Tras añadir los componentes de reconocimiento visual a Llama 3, el modelo contiene una capa de autoatención, una capa de atención cruzada y un codificador de imágenes ViT. Descubrimos que el paralelismo de datos y el paralelismo de tensor eran las combinaciones más eficientes a la hora de entrenar adaptadores para modelos más pequeños (8.000 y 70.000 millones de parámetros). A estas escalas, el paralelismo de modelos o de canalizaciones no mejorará la eficiencia porque la recopilación de parámetros del modelo dominará el cálculo. Sin embargo, utilizamos el paralelismo de canalización (además del paralelismo de datos y tensor) al entrenar el adaptador para el modelo de 405.000 millones de parámetros. El entrenamiento a esta escala presenta tres nuevos retos además de los descritos en la Sección 3.3: heterogeneidad del modelo, heterogeneidad de los datos e inestabilidad numérica.
heterogeneidad del modelo. El modelo de cálculo es heterogéneo, ya que algunos tokens realizan más cálculos que otros. En concreto, los tokens de imagen se procesan a través del codificador de imágenes y la capa de atención cruzada, mientras que los tokens de texto se procesan únicamente a través de la red troncal lingüística. Esta heterogeneidad puede provocar cuellos de botella en la programación paralela de la red. Abordamos este problema asegurándonos de que cada etapa del pipeline contenga cinco capas: es decir, cuatro capas de autoatención y una capa de atención cruzada en la red troncal lingüística. (Recordemos que introdujimos una capa de atención cruzada después de cada cuatro capas de autoatención). Además, reproducimos el codificador de imágenes en todas las etapas del proceso. Dado que nos entrenamos con datos emparejados de imagen y texto, esto nos permite equilibrar la carga entre las partes de imagen y texto del cálculo.
Heterogeneidad de los datosLos datos son heterogéneos porque, de media, las imágenes tienen más tokens que el texto asociado: una imagen tiene 2308 tokens, mientras que el texto asociado sólo tiene 192 de media. Los datos son heterogéneos porque, de media, las imágenes tienen más tokens que el texto asociado: una imagen tiene 2308 tokens, mientras que el texto asociado sólo tiene 192 tokens de media. Como resultado, el cálculo de la capa de atención cruzada lleva más tiempo y requiere más memoria que el cálculo de la capa de autoatención. Abordamos este problema introduciendo paralelismo de secuencias en el codificador de imágenes para que cada GPU procese aproximadamente el mismo número de tokens. También utilizamos un tamaño de microlote mayor (8 en lugar de 1) debido al tamaño medio relativamente pequeño del texto.
Inestabilidad numérica. Tras añadir el codificador de imágenes al modelo, descubrimos que la acumulación de gradientes mediante bf16 daba lugar a valores inestables. La explicación más probable es que los marcadores de imagen se introducen en la red troncal lingüística a través de todas las capas de atención cruzada. Esto significa que las desviaciones numéricas en la representación con marcadores de imagen tienen un impacto desproporcionado en el cómputo global, ya que los errores se agravan. Abordamos este problema mediante la acumulación de gradientes utilizando FP32.
7.4 Formación previa
Preentrenamiento de imágenes. Comenzamos la inicialización con el modelo de texto preentrenado y los pesos del codificador visual. El codificador visual se descongeló, mientras que los pesos del modelo de texto permanecieron congelados, como se ha descrito anteriormente. En primer lugar, entrenamos el modelo utilizando 6.000 millones de pares imagen-texto, cada imagen redimensionada para que cupiera en cuatro parcelas de 336 × 336 píxeles. Utilizamos un tamaño de lote global de 16.384 y un esquema de tasa de aprendizaje coseno con una tasa de aprendizaje inicial de 10 × 10 -4 y un decaimiento del peso de 0,01. La tasa de aprendizaje inicial se determinó a partir de experimentos a pequeña escala. Sin embargo, estos resultados no se generalizan bien a programas de entrenamiento muy largos, y reducimos la tasa de aprendizaje varias veces durante el entrenamiento cuando los valores de pérdida se estancan. Tras el preentrenamiento básico, aumentamos la resolución de la imagen y continuamos el entrenamiento con los mismos pesos en el conjunto de datos recocido. El optimizador se reinicializa a una tasa de aprendizaje de 2 × 10 -5 mediante calentamiento, siguiendo de nuevo el programa del coseno.
Vídeo de formación previa. Para el preentrenamiento de vídeo, comenzamos con el preentrenamiento de imagen y los pesos de recocido descritos anteriormente. Añadiremos las capas de agregador de vídeo y atención cruzada descritas en la arquitectura y las inicializaremos aleatoriamente. Congelamos todos los parámetros del modelo excepto los específicos de vídeo (agregador y atención cruzada de vídeo) y los entrenamos con los datos de preentrenamiento de vídeo. Utilizamos los mismos hiperparámetros de entrenamiento que en la fase de templado de imágenes, con tasas de aprendizaje ligeramente diferentes. Tomamos muestras uniformes de 16 fotogramas del vídeo completo y utilizamos cuatro bloques de 448 × 448 píxeles para representar cada fotograma. Utilizamos un factor de agregación de 16 en el agregador de vídeo para obtener un fotograma válido en el que los marcadores de texto se crucen. Nos entrenamos utilizando un tamaño de lote global de 4.096, una longitud de secuencia de 190 tokens y una tasa de aprendizaje de 10 -4 .
7.5 Tratamiento posterior a la formación
En esta sección, describimos en detalle los pasos de entrenamiento subsiguientes para el adaptador visual.
Tras el preentrenamiento, afinamos el modelo con datos de diálogo multimodal muy seleccionados para habilitar la función de chat.
Además, aplicamos la Optimización de Preferencia Directa (OPD) para mejorar el rendimiento de la evaluación manual y empleamos el muestreo de rechazo para mejorar la inferencia multimodal.
Por último, añadimos una fase de ajuste de la calidad en la que seguimos afinando el modelo en un conjunto de datos muy reducido de diálogos de alta calidad, lo que mejora aún más los resultados de la evaluación manual al tiempo que preserva el rendimiento de la prueba de referencia.
A continuación se ofrece información detallada sobre cada paso.
7.5.1 Seguimiento de los datos ajustados
A continuación describimos los datos de ajuste fino supervisado (SFT) para las funciones de imagen y vídeo, respectivamente.
IMAGEN. Utilizamos una mezcla de diferentes conjuntos de datos para el ajuste supervisado.
- Conjuntos de datos académicos: convertimos conjuntos de datos académicos existentes muy filtrados en pares de preguntas y respuestas utilizando plantillas o mediante reescrituras de Large Language Modelling (LLM). Las reescrituras de LLM están diseñadas para aumentar los datos con diferentes instrucciones y mejorar la calidad lingüística de las respuestas.
- Anotación manual: Recopilamos datos de diálogos multimodales para diversas tareas (preguntas y respuestas abiertas, subtítulos, casos de uso en el mundo real, etc.) y dominios (por ejemplo, imágenes naturales e imágenes estructuradas) a través de anotadores manuales. El anotador recibirá las imágenes y se le pedirá que componga el diálogo.
Para garantizar la diversidad, agrupamos el conjunto de datos a gran escala y muestreamos las imágenes uniformemente en los distintos grupos. Además, obtenemos imágenes adicionales para algunos dominios específicos ampliando las semillas mediante k-vecinos más próximos. El anotador también dispone de puntos de control intermedios de los modelos existentes para facilitar la anotación estilística de los modelos en el bucle, de modo que la generación de modelos pueda utilizarse como punto de partida para que el anotador aporte ediciones humanas adicionales. Se trata de un proceso iterativo en el que los puntos de control del modelo se actualizan periódicamente a versiones de mejor rendimiento que se han entrenado con los datos más recientes. Esto aumenta la cantidad y la eficacia de la anotación manual, al tiempo que mejora la calidad.
- Datos sintéticos: exploramos distintos enfoques para generar datos multimodales sintéticos utilizando representaciones textuales de imágenes y LLM de entrada textual. La idea básica es utilizar las capacidades de inferencia del LLM de entrada textual para generar pares de preguntas y respuestas en el dominio textual y sustituir las representaciones textuales por sus correspondientes imágenes para producir datos multimodales sintéticos. Algunos ejemplos son la representación de texto de conjuntos de datos de preguntas y respuestas como imágenes o de datos tabulares como imágenes sintéticas de tablas y gráficos. Además, utilizamos la extracción de subtítulos y OCR de imágenes existentes para generar diálogos generales o datos de preguntas y respuestas asociados a las imágenes.
Vídeo. De forma similar al adaptador de imágenes, utilizamos conjuntos de datos académicos anotados preexistentes para transformarlos en instrucciones textuales y respuestas objetivo adecuadas. Los objetivos se convertirán en respuestas abiertas o preguntas de opción múltiple, según proceda. Pedimos a anotadores humanos que añadieran preguntas y sus correspondientes respuestas a los vídeos. Pedimos al anotador que se centrara en las preguntas que no podían responderse basándose en fotogramas individuales, con el fin de orientar al anotador hacia las preguntas cuya comprensión llevaría tiempo.
7.5.2 Supervisión de los programas de puesta a punto
Presentamos esquemas de ajuste fino supervisado (SFT) para capacidades de imagen y vídeo, respectivamente:
IMAGEN. Inicializamos el modelo a partir de los adaptadores de imagen preentrenados, pero sustituimos los pesos del modelo de lenguaje preentrenado por los pesos del modelo de lenguaje ajustado a las instrucciones. Para mantener el rendimiento de sólo texto, las ponderaciones del modelo de lenguaje se mantienen congeladas, es decir, sólo actualizamos las ponderaciones del codificador visual y del adaptador de imágenes.
Nuestro enfoque de ajuste fino es similar al de Wortsman et al. (2022). En primer lugar, realizamos exploraciones de hiperparámetros utilizando múltiples subconjuntos aleatorios de datos, tasas de aprendizaje y valores de decaimiento del peso. A continuación, clasificamos los modelos en función de su rendimiento. El valor de K se determinó evaluando el modelo medio y seleccionando la instancia de mayor rendimiento. Observamos que el modelo medio produce sistemáticamente mejores resultados que el mejor modelo individual hallado mediante la búsqueda en cuadrícula. Además, esta estrategia reduce la sensibilidad a los hiperparámetros.
Vídeo. Para el SFT de vídeo, inicializamos el agregador de vídeo y la capa de atención cruzada utilizando pesos preentrenados. Los demás parámetros del modelo (pesos de imagen y LLM) se inicializan a partir del modelo correspondiente y siguen sus etapas de ajuste fino. Al igual que en el preentrenamiento de vídeo, sólo se ajustan los parámetros de vídeo de los datos SFT de vídeo. En esta fase, aumentamos la longitud del vídeo a 64 fotogramas y utilizamos un factor de agregación de 32 para obtener dos fotogramas válidos. La resolución de la aynı zamanda,bloque se aumenta en consecuencia para que sea coherente con los hiperparámetros de imagen correspondientes.
7.5.3 Preferencias
Para recompensar la modelización y la optimización directa de las preferencias, construimos conjuntos de datos de preferencias emparejadas multimodales.
- Etiquetado manual. Los datos de preferencia anotados manualmente consisten en una comparación de los resultados de dos modelos diferentes, etiquetados como "seleccionar" y "rechazar", y valorados en una escala de 7 puntos. Los modelos utilizados para generar las respuestas se seleccionan aleatoriamente cada semana de un conjunto de los mejores modelos recientes, cada uno con características diferentes. Además de las etiquetas de preferencia, pedimos a los anotadores que realizaran una edición manual opcional para corregir imprecisiones en la respuesta "Seleccionar", ya que la tarea visual es menos tolerante con las imprecisiones. Tenga en cuenta que la edición manual es un paso opcional, ya que en la práctica hay un equilibrio entre cantidad y calidad.
- Datos de síntesis. También se pueden generar pares de preferencias sintéticas utilizando la edición LLM de sólo texto e introduciendo deliberadamente errores en el conjunto de datos de ajuste fino supervisado. Tomamos datos de diálogo como entrada y utilizamos LLM para introducir errores sutiles pero significativos (por ejemplo, cambiar objetos, cambiar atributos, añadir errores de cálculo, etc.). Estas respuestas editadas se utilizan como muestras negativas "rechazadas" y se emparejan con los datos originales "seleccionados" de ajuste fino supervisado.
- Rechazar muestreo. Además, para crear muestras negativas más estratégicas, utilizamos un proceso iterativo de muestreo de rechazo para recoger datos adicionales sobre preferencias. En las secciones siguientes se explica con más detalle cómo se utiliza el muestreo de rechazo. En resumen, el muestreo de rechazo se utiliza para muestrear de forma iterativa los resultados de alta calidad generados a partir del modelo. Por lo tanto, como subproducto, todos los resultados generados no seleccionados pueden utilizarse como muestras de rechazo negativas y como pares de datos de preferencias adicionales.
7.5.4 Modelos de recompensa
Entrenamos un modelo de recompensa visual (MR) basado en un modelo SFT visual y un MR lingüístico. Las capas del codificador visual y de atención cruzada se inicializaron a partir del modelo SFT visual y se descongelaron durante el entrenamiento, mientras que la capa de autoatención se inicializó a partir del MR lingüístico y se mantuvo congelada. Observamos que congelar la parte del MR lingüístico suele conducir a una mayor precisión, especialmente en tareas que requieren que el MR emita juicios basados en sus conocimientos o en la calidad del lenguaje. Utilizamos el mismo objetivo de entrenamiento que para el MR lingüístico, pero añadimos un término de regularización ponderado para elevar al cuadrado los logits de recompensa promediados por lotes para evitar la deriva de la puntuación de recompensa.
Las anotaciones de preferencias humanas de la sección 7.5.3 se utilizaron para entrenar los MR visuales. Seguimos el mismo enfoque que para los datos de preferencias lingüísticas (sección 4.2.1), creando dos o tres pares con clasificaciones claras (versión editada > versión seleccionada > versión rechazada). Además, mejoramos sintéticamente las respuestas negativas codificando palabras o frases (por ejemplo, números o texto visual) asociadas a la información de la imagen. Esto anima al MR visual a emitir juicios basados en el contenido real de la imagen.
7.5.5 Optimización directa de las preferencias
Al igual que con el modelo lingüístico (sección 4.1.4), entrenamos los adaptadores visuales utilizando la Optimización Directa de Preferencias (OPD; Rafailov et al. (2023)) con los datos de preferencias descritos en la sección 7.5.3. Para combatir el sesgo distribucional durante el post-entrenamiento, retuvimos sólo los lotes más recientes de anotaciones de preferencias humanas, y descartamos aquellos lotes que se quedaban lejos de la estrategia (por ejemplo, si se cambiaba el modelo subyacente de pre-entrenamiento). Comprobamos que, en lugar de congelar el modelo de referencia todo el tiempo, actualizarlo cada k pasos como una media móvil exponencial (EMA) ayuda al modelo a aprender más de los datos, lo que se traduce en un mejor rendimiento en las evaluaciones humanas. En general, observamos que el modelo visual OPD supera sistemáticamente a su punto de partida SFT en las evaluaciones humanas y obtiene buenos resultados en cada iteración de ajuste fino.
7.5.6 Rechazo del muestreo
La mayoría de las parejas de pruebas existentes sólo contienen respuestas finales y carecen de las explicaciones de la cadena de pensamiento necesarias para razonar sobre modelos que generalicen bien la tarea. Utilizamos el muestreo de rechazo para generar las explicaciones que faltan en estos ejemplos, mejorando así la inferencia del modelo.
Dado un par de preguntas, generamos múltiples respuestas muestreando el modelo afinado utilizando diferentes pistas o temperaturas del sistema. A continuación, comparamos las respuestas generadas con las verdaderas mediante heurísticos o árbitros LLM. Por último, volvemos a entrenar el modelo añadiendo respuestas correctas a los datos ajustados. Nos pareció útil conservar varias respuestas correctas por pregunta.
Para garantizar que sólo se añadían ejemplos de alta calidad a la formación, aplicamos las dos medidas de seguridad siguientes:
- Observamos que algunos ejemplos contenían explicaciones incorrectas, aunque la respuesta final era correcta. Observamos que este patrón es más común en preguntas en las que sólo una pequeña fracción de las respuestas generadas son correctas. Por lo tanto, descartamos las respuestas de las preguntas cuya probabilidad de respuesta correcta estaba por debajo de un umbral específico.
- Los revisores favorecen determinadas respuestas debido a diferencias lingüísticas o de estilo. Utilizamos un modelo de recompensa para seleccionar las K respuestas de mayor calidad y añadirlas al entrenamiento.
7.5.7 Ajuste de la calidad
Hemos conservado cuidadosamente un conjunto de datos de ajuste fino (SFT) pequeño pero altamente selectivo, en el que todas las muestras se reescriben y validan para cumplir los estándares más exigentes, ya sea manualmente o mediante nuestros mejores modelos. Utilizamos estos datos para entrenar los modelos de OPD con el fin de mejorar la calidad de las respuestas y denominamos a este proceso ajuste de calidad (QT). Descubrimos que cuando el conjunto de datos de QT abarca una amplia gama de tareas y se aplican paradas tempranas adecuadas, QT puede mejorar significativamente los resultados de la evaluación humana sin afectar al rendimiento general de la validación de la prueba de referencia. En esta fase, seleccionamos los puntos de control basándonos únicamente en las pruebas de referencia para garantizar que se mantienen o mejoran las capacidades.
7.6 Resultados del reconocimiento de imágenes
Evaluamos el rendimiento de las capacidades de comprensión de imágenes de Llama 3 en una serie de tareas que abarcan la comprensión de imágenes naturales, la comprensión de textos, la comprensión de diagramas y el razonamiento multimodal:
- MMMU (Yue et al., 2024a) es un desafiante conjunto de datos de razonamiento multimodal en el que se exige a los modelos que den sentido a las imágenes y resuelvan problemas de nivel universitario en 30 disciplinas diferentes. Incluye preguntas de opción múltiple y preguntas abiertas. Evaluamos el modelo en un conjunto de validación que contiene 900 imágenes, en consonancia con otros trabajos.
- VQAv2 (Antol et al., 2015) pone a prueba la capacidad del modelo para combinar la comprensión de imágenes, la comprensión del lenguaje y el conocimiento general para responder a preguntas generales sobre imágenes naturales.
- AI2 Diagram (Kembhavi et al., 2016) evalúa la capacidad de los modelos para analizar diagramas científicos y responder a preguntas sobre ellos. Utilizamos el mismo modelo que Géminis Mismo protocolo de evaluación que x.ai y utiliza cuadros delimitadores transparentes para informar de las puntuaciones.
- ChartQA (Masry et al., 2022) es una exigente prueba de referencia para la comprensión de gráficos. Requiere que los modelos comprendan visualmente diferentes tipos de gráficos y respondan a preguntas sobre la lógica de estos gráficos.
- TextVQA (Singh et al., 2019) es un popular conjunto de datos de referencia que requiere que los modelos lean y razonen sobre el texto en imágenes para responder a consultas sobre ellas. Esto pone a prueba la capacidad del modelo para comprender el OCR en imágenes naturales.
- DocVQA (Mathew et al., 2020) es un conjunto de datos de referencia centrado en el análisis y el reconocimiento de documentos. Contiene imágenes de una amplia gama de documentos y evalúa la capacidad de los modelos para realizar OCR con el fin de comprender y razonar sobre el contenido de los documentos para responder a preguntas sobre ellos.
La tabla 29 muestra los resultados de nuestros experimentos. Los resultados de la tabla muestran que el módulo de visión acoplado a Llama 3 es competitivo en varios benchmarks de reconocimiento de imágenes con diferentes capacidades de modelo. Utilizando el modelo Llama 3-V 405B resultante, superamos al GPT-4V en todas las pruebas de referencia, pero quedamos ligeramente por debajo del Gemini 1.5 Pro y del Claude 3.5 Sonnet. el Llama 3 405B rinde especialmente bien en la tarea de comprensión de documentos.

7.7 Resultados del reconocimiento de vídeo
Hemos evaluado el adaptador de vídeo de Llama 3 en tres pruebas:
- PerceptionTest (Lin et al., 2023)Prueba comparativa: esta prueba comparativa pone a prueba la capacidad del modelo para comprender y predecir clips de vídeo cortos. Contiene varios tipos de problemas, como el reconocimiento de objetos, acciones, escenas, etc. Informamos de los resultados basándonos en el código proporcionado oficialmente y en las métricas de evaluación (precisión).
- TVQA (Lei et al., 2018)Esta prueba evalúa la capacidad de razonamiento compuesto del modelo, lo que implica la localización espaciotemporal, el reconocimiento de conceptos visuales y el razonamiento conjunto con diálogos subtitulados. Dado que el conjunto de datos procede de programas de televisión populares, también pone a prueba la capacidad del modelo para utilizar conocimientos externos de estos programas de televisión para responder a las preguntas. Contiene más de 15.000 pares de preguntas validadas, cada una de las cuales corresponde a un videoclip con una duración media de 76 segundos. Utiliza un formato de elección múltiple con cinco opciones por pregunta, e informamos del rendimiento en el conjunto de validación basado en trabajos anteriores (OpenAI, 2023b).
- ActivityNet-QA (Yu et al., 2019)Este parámetro evalúa la capacidad del modelo para dar sentido a videoclips de larga duración y comprender la acción, las relaciones espaciales y temporales, el recuento, etc. Contiene 8.000 pares de QA de prueba de 800 vídeos, cada uno con una duración media de 3 minutos. Para la evaluación, seguimos el protocolo de trabajos anteriores (Google, 2023; Lin et al., 2023; Maaz et al., 2024), en los que el modelo genera respuestas de palabras o frases cortas y las compara con respuestas reales utilizando la API GPT-3.5 para evaluar la corrección del resultado. Informamos de la precisión media calculada por la API.
proceso de razonamiento
Al realizar la inferencia, tomamos una muestra uniforme de fotogramas del videoclip completo y se los pasamos al modelo junto con una breve indicación textual. Como la mayoría de las pruebas consisten en responder a preguntas de opción múltiple, utilizamos las siguientes instrucciones:
- Elija la respuesta correcta entre las siguientes opciones:{pregunta}. Responda utilizando sólo la letra de la opción correcta y no escriba nada más.
Para los puntos de referencia que necesitan generar respuestas cortas (por ejemplo, ActivityNet-QA y NExT-QA), utilizamos las siguientes pistas:
- Responde a la pregunta utilizando una palabra o frase: {pregunta}.
En el caso de NExT-QA, dado que las métricas de evaluación (WUPS) son sensibles a la longitud y a las palabras concretas utilizadas, también pedimos al modelo que fuera específico y respondiera a las respuestas más destacadas, por ejemplo, especificando "salón" cuando se le preguntaba por la ubicación en lugar de responder simplemente "casa ". En el caso de las pruebas que incluyen subtítulos (por ejemplo, TVQA), incluimos los subtítulos correspondientes del clip en la pista durante el proceso de inferencia.
al final
La tabla 30 muestra el rendimiento de los modelos Llama 3 8B y 70B. Comparamos su rendimiento con el de los dos modelos Gemini y los dos modelos GPT-4. Nótese que todos los resultados son de muestra cero, ya que no incluimos ninguna porción de estos puntos de referencia en nuestros datos de entrenamiento o ajuste fino. Hemos comprobado que nuestro modelo Llama 3 es muy competitivo en el entrenamiento de pequeños adaptadores de vídeo durante el postprocesamiento y, en algunos casos, incluso supera a otros modelos que pueden aprovechar el procesamiento multimodal nativo desde el preentrenamiento.Llama 3 funciona especialmente bien en el reconocimiento de vídeo, ya que sólo evaluamos los modelos de parámetros 8B y 70B.Llama 3 obtuvo el mejor rendimiento en el Llama 3 obtuvo los mejores resultados en la prueba de percepción, lo que demuestra la gran capacidad del modelo para realizar razonamientos temporales complejos. En tareas de comprensión de actividad de clips largos como ActivityNet-QA, Llama 3 obtiene buenos resultados incluso cuando sólo procesa hasta 64 fotogramas (para un vídeo de 3 minutos, el modelo procesa sólo un fotograma cada 3 segundos).


8 Experimento de habla
Realizamos experimentos para investigar un enfoque combinatorio para integrar la funcionalidad del habla en Llama 3, similar al esquema que utilizamos para el reconocimiento visual. En la entrada, se añadieron codificadores y adaptadores para procesar la señal del habla. Utilizamos indicaciones del sistema (en forma de texto) para que Llama 3 admita distintos modos de comprensión del habla. Si no se proporcionan indicaciones del sistema, el modelo actúa como un modelo de diálogo de voz genérico que puede responder eficazmente al habla del usuario de forma coherente con la versión de sólo texto de Llama 3. La introducción del historial de diálogo como prefijo puede mejorar la experiencia de diálogo en varias rondas. También experimentamos con el uso de indicaciones del sistema para el Reconocimiento Automático del Habla (ASR) y la Traducción Automática del Habla (AST) en Llama 3. La interfaz de habla de Llama 3 admite hasta 34 idiomas.18 También permite la entrada alternativa de texto y habla, lo que permite al modelo resolver tareas avanzadas de comprensión de audio.
También experimentamos con un enfoque de generación de voz en el que implementamos un sistema de transmisión de texto a voz (TTS) que genera dinámicamente formas de onda de voz durante la descodificación del modelo lingüístico. Diseñamos el generador de voz de Llama 3 basándonos en el sistema TTS propietario y no ajustamos el modelo lingüístico para la generación de voz. En su lugar, nos centramos en mejorar la latencia, la precisión y la naturalidad de la síntesis del habla utilizando las incrustaciones de palabras de Llama 3 durante la inferencia. La interfaz de voz se muestra en las figuras 28 y 29.
8.1 Datos
8.1.1 Comprensión verbal
Los datos de entrenamiento pueden dividirse en dos categorías. Los datos de preentrenamiento consisten en grandes cantidades de habla sin etiquetar que se utilizan para inicializar el codificador de voz de forma autosupervisada. Los datos supervisados de ajuste fino incluyen datos de reconocimiento del habla, traducción del habla y diálogo hablado; se utilizan para desbloquear capacidades específicas cuando se integran con grandes modelos lingüísticos.
Datos previos al entrenamiento. Para preentrenar el codificador de voz, recopilamos un conjunto de datos con unos 15 millones de horas de grabaciones de voz en varios idiomas. Filtramos los datos de audio mediante un modelo de detección de actividad vocal (VAD) y seleccionamos muestras de audio con un umbral VAD superior a 0,7 para el preentrenamiento. En los datos de preentrenamiento de voz, también nos centramos en garantizar la ausencia de información personal identificable (IPI). Utilizamos Presidio Analyzer para identificar dicha información.
Reconocimiento de voz y datos de traducción. Nuestros datos de formación ASR contienen 230.000 horas de grabaciones de voz transcritas a mano en 34 idiomas. Nuestros datos de formación AST contienen 90.000 horas de traducción bidireccional: de 33 idiomas al inglés y del inglés a 33 idiomas. Estos datos contienen tanto datos supervisados como datos sintéticos generados mediante el conjunto de herramientas NLLB (NLLB Team et al., 2022). El uso de datos AST sintéticos mejora la calidad de los modelos para lenguas de escasos recursos. La longitud máxima de los segmentos de habla en nuestros datos es de 60 segundos.
Datos de diálogos hablados. Para afinar los adaptadores del habla para el diálogo hablado, sintetizamos las respuestas a las indicaciones del habla pidiendo al modelo lingüístico que respondiera a las transcripciones de estas indicaciones (Fathullah et al., 2024). Utilizamos un subconjunto del conjunto de datos ASR (que contiene 60.000 horas de habla) para generar datos sintéticos de este modo.
Además, generamos 25.000 horas de datos sintéticos ejecutando el sistema Voicebox TTS (Le et al., 2024) en un subconjunto de los datos utilizados para afinar Llama 3. Utilizamos varios métodos heurísticos para seleccionar un subconjunto de los datos ajustados que coincidieran con la distribución del habla. Esta heurística se centraba en pistas relativamente cortas y de estructura sencilla, y no incluía símbolos no textuales.
8.1.2 Generación de voz
语音生成数据集主要包括用于训练文本规范化(TN)模型和韵律模型(PM)的数据集。两种训练数据都通过添加 Llama 3 词嵌入作为额外的输入特征进行增强,以提供上下文信息。
文本规范化数据。我们的 TN 训练数据集包含 5.5 万个样本,涵盖了广泛的符号类别(例如,数字、日期、时间),这些类别需要非平凡的规范化。每个样本由书面形式文本和相应的规范化口语形式文本组成,并包含一个推断的手工制作的 TN 规则序列,用于执行规范化。
声韵模型数据。PM 训练数据包括从一个包含 50,000 小时的 TTS 数据集提取的语言和声韵特征,这些特征与专业配音演员在录音室环境中录制的文字稿件和音频配对。
Llama 3 嵌入。Llama 3 嵌入取自第 16 层解码器输出。我们仅使用 Llama 3 8B 模型,并提取给定文本的嵌入(即 TN 的书面输入文本或 PM 的音频转录),就像它们是由 Llama 3 模型在空用户提示下生成的。在一个样本中,每个 Llama 3 标记序列块都明确地与 TN 或 PM 本地输入序列中的相应块对齐,即 TN 特定的文本标记(由 Unicode 类别区分)或语音速率特征。这允许使用 Llama 3 标记和嵌入的流式输入训练 TN 和 PM 模块。
8.2 Arquitectura del modelo
8.2.1 Comprensión verbal
En cuanto a la entrada, el módulo de voz consta de dos módulos consecutivos: un codificador de voz y un adaptador. La salida del módulo del habla se introduce directamente en el modelo lingüístico como una representación de tokens, lo que permite la interacción directa entre los tokens del habla y del texto. Además, introducimos dos nuevos tokens especiales para contener secuencias de representaciones del habla. El módulo del habla es muy diferente del módulo de visión (véase la sección 7), que introduce información multimodal en el modelo de lenguaje a través de la capa de atención cruzada. En cambio, las incrustaciones generadas por el módulo del habla pueden integrarse sin problemas en los tokens textuales, lo que permite a la interfaz del habla aprovechar todas las características del modelo de lenguaje de Llama 3.
Codificador de voz:Nuestro codificador del habla es un modelo Conformer con mil millones de parámetros (Gulati et al., 2020). La entrada al modelo consiste en características de espectrograma de Meier de 80 dimensiones, que primero se procesan a través de una capa apilada con un tamaño de paso de 4, y luego se reducen a una longitud de fotograma de 40 milisegundos mediante proyección lineal. Las características procesadas son tratadas por un codificador que contiene 24 capas Conformer. Cada capa Conformer tiene una dimensión potencial de 1536 e incluye dos redes feedforward estilo Macron-net con una dimensión de 4096, un módulo convolucional con un tamaño de núcleo de 7 y un módulo de atención rotacional con 24 cabezas de atención (Su et al., 2024).
Adaptador de voz:El adaptador de voz contiene unos 100 millones de parámetros. Consta de una capa convolucional, una capa de transformador giratorio y una capa lineal. La capa convolucional tiene un tamaño de núcleo de 3 y un tamaño de paso de 2, y está diseñada para reducir la longitud de la trama del habla a 80 ms. Esto permite al modelo proporcionar características de grano más grueso al modelo lingüístico. La capa Transformer, con una dimensión potencial de 3.072, y la red feed-forward, con una dimensión de 4.096, procesan la información del habla muestreada por la convolución. Por último, la capa lineal asigna la dimensión de salida para que coincida con la capa de incrustación del modelo lingüístico.
8.2.2 Generación de voz
Utilizamos la incrustación de Llama 3 8B en dos componentes clave de la generación del habla: la normalización del texto y el modelado métrico. El módulo de Normalización de Texto (TN) garantiza la corrección semántica convirtiendo contextualmente el texto escrito en forma hablada. El módulo de modelado prosódico (PM) mejora la naturalidad y la expresividad utilizando estas incrustaciones para predecir las características prosódicas. Estos dos componentes trabajan en tándem para lograr una generación del habla precisa y natural.
**Normalización del texto**: como factor determinante de la corrección semántica del habla generada, el módulo de Normalización del Texto (TN) realiza la conversión, teniendo en cuenta el contexto, del texto escrito a la forma hablada correspondiente, que es verbalizada en última instancia por los componentes posteriores. Por ejemplo, dependiendo del contexto semántico, la forma escrita "123" puede leerse como un número base (ciento veintitrés) o deletrearse dígito a dígito (uno, dos, tres). El sistema TN consiste en un modelo de etiquetado de secuencias basado en LSTM que predice el número de dígitos que se utilizarán para transformar las secuencias de reglas TN elaboradas a mano del texto de entrada (Kang et al., 2024). El modelo neuronal también recibe incrustaciones de Llama 3 mediante atención cruzada para aprovechar la información contextual codificada en ellas, lo que permite una previsión mínima del etiquetado de texto y una entrada/salida de flujo.
**Modelado de rimas**: para mejorar la naturalidad y expresividad del habla sintética, integramos un modelo de rimas (PM) (Radford et al., 2021) que descodifica solo la arquitectura Transformer, que utiliza incrustaciones de Llama 3 como entrada adicional. Esta integración aprovecha las capacidades lingüísticas de Llama 3, utilizando su salida textual y las incrustaciones intermedias (Devlin et al. 2018; Dong et al. 2019; Raffel et al. 2020; Guo et al. 2023) para aumentar la predicción de las características de rima, reduciendo así la anticipación requerida por el modelo. El PM integra múltiples componentes de entrada para generar predicciones métricas completas: características lingüísticas, tokens e incrustaciones derivadas del front-end de normalización de texto detallado anteriormente. El PM predice tres características métricas clave: la duración logarítmica de cada fonema, la media logarítmica de la frecuencia fundamental (F0) y la media logarítmica de la potencia sobre la duración del fonema. El modelo consta de un transformador unidireccional y seis cabezas de atención. Cada bloque consta de una capa de atención cruzada y una capa dual totalmente conectada con 864 dimensiones ocultas. Una característica distintiva del PM es su mecanismo de atención cruzada dual, con una capa dedicada a la entrada lingüística y la otra a la incrustación de Llama. Esta configuración gestiona eficazmente diferentes tasas de entrada sin necesidad de una alineación explícita.
8.3 Programas de formación
8.3.1 Comprensión del habla
El entrenamiento del módulo del habla se llevó a cabo en dos fases. En la primera, el preentrenamiento del habla, se entrena un codificador del habla a partir de datos no etiquetados que muestra una gran capacidad de generalización con respecto a las condiciones lingüísticas y acústicas. En la segunda fase, de ajuste supervisado, el adaptador y el codificador preentrenado se integran en el modelo del habla y se entrenan conjuntamente con él, mientras que el LLM permanece congelado. Esto permite que el modelo responda a la entrada del habla. En esta fase se utilizan datos etiquetados correspondientes a las capacidades de comprensión del habla.
La modelización multilingüe de ASR y AST suele provocar confusión/interferencia lingüística, lo que degrada el rendimiento. Un método de mitigación muy utilizado consiste en incluir información de identificación lingüística (LID) tanto en el origen como en el destino. Esto puede mejorar el rendimiento en una dirección predeterminada, pero también puede provocar una degradación de la generalización. Por ejemplo, si un sistema de traducción espera proporcionar información LID tanto en el origen como en el destino, es poco probable que el modelo muestre un buen rendimiento de muestra cero en direcciones no observadas en el entrenamiento. Por tanto, nuestro reto consiste en diseñar un sistema que permita cierto grado de información LID y, al mismo tiempo, mantenga el modelo lo suficientemente general como para traducir el habla en direcciones no vistas. Para abordar este problema, diseñamos señales del sistema que contienen únicamente información LID para el texto que se va a emitir (lado de destino). Estas claves no contienen información LID para la entrada del habla (lado fuente), lo que también puede hacer posible manejar el habla con cambio de código. Para el ASR, utilizamos la siguiente instrucción del sistema: Repita mis palabras en {idioma}:, donde {idioma} es uno de los 34 idiomas (inglés, francés, etc.). Para la traducción de voz, la pregunta del sistema es: "Traduzca la siguiente frase a {idioma}:". Este diseño ha demostrado ser eficaz para que los modelos lingüísticos respondan en el idioma deseado. Utilizamos la misma instrucción del sistema durante el entrenamiento y la inferencia.
Utilizamos el algoritmo autosupervisado BEST-RQ (Chiu et al., 2022) para preentrenar el habla.
编码器采用长度为 32 帧的掩码,对输入 mel 谱图的概率为 2.5%。如果语音话语超过 60 秒,我们将随机裁剪 6K 帧,对应 60 秒的语音。通过堆叠 4 个连续帧、将 320 维向量投影到 16 维空间,并在 8192 个向量的代码库内使用余弦相似度度量进行最近邻搜索,对 mel 谱图特征进行量化。为了稳定预训练,我们采用 16 个不同的代码库。投影矩阵和代码库随机初始化,在模型训练过程中不更新。多软最大损失仅用于掩码帧,以提高效率。编码器经过 50 万步训练,全局批处理大小为 2048 个语音。
监督微调。预训练语音编码器和随机初始化的适配器在监督微调阶段与 Llama 3 联合优化。语言模型在此过程中保持不变。训练数据是 ASR、AST 和对话数据的混合。Llama 3 8B 的语音模型经过 650K 次更新训练,使用全局批大小为 512 个话语和初始学习率为 10。Llama 3 70B 的语音模型经过 600K 次更新训练,使用全局批大小为 768 个话语和初始学习率为 4 × 10。
8.3.2 Generación de voz
Para facilitar el procesamiento en tiempo real, el modelo de rima emplea un mecanismo de anticipación que tiene en cuenta un número fijo de posiciones fonémicas futuras y un número variable de fichas futuras. De este modo, se garantiza la coherencia en el procesamiento del texto entrante, algo fundamental para las aplicaciones de síntesis de voz de baja latencia.
Formación. Desarrollamos una estrategia de alineación dinámica que utiliza máscaras causales para facilitar el streaming de la síntesis de voz. La estrategia combina un mecanismo de anticipación en el modelo prosódico para un número fijo de fonemas futuros y un número variable de tokens futuros, en consonancia con el proceso de fragmentación en el proceso de normalización del texto (sección 8.1.2).
Para cada fonema, el marcador de anticipación consiste en el número máximo de marcadores definido por el tamaño del bloque, lo que da como resultado incrustaciones Llama con anticipación variable y fonemas con anticipación fija.
Incrustaciones Llama 3 del modelo Llama 3 8B, mantenidas congeladas durante el entrenamiento del modelo de rima. Las características de la tasa de llamadas de entrada incluyen elementos lingüísticos y de control del locutor/estilo. El modelo se entrena utilizando un optimizador AdamW con un tamaño de lote de 1.024 tonos y una tasa de aprendizaje de 9 × 10 -4. El modelo se entrena a lo largo de 1 millón de actualizaciones, con las primeras 3.000 actualizaciones realizando un calentamiento de la tasa de aprendizaje y luego siguiendo la programación del coseno.
Razonamiento. Durante la inferencia, se utiliza el mismo mecanismo de anticipación y la misma estrategia de enmascaramiento causal para garantizar la coherencia entre la formación y el procesamiento en tiempo real.PM procesa el texto entrante de forma continua, actualizando la entrada teléfono por teléfono para las características de tasa telefónica, y bloque por bloque para las características de tasa etiquetada. Las entradas de nuevos bloques sólo se actualizan cuando el primer teléfono del bloque es actual, manteniendo así la alineación y la anticipación durante el entrenamiento.
Para predecir los objetivos de rima, utilizamos un enfoque de modo retardado (Kharitonov et al., 2021), que mejora la capacidad del modelo para captar y reproducir las dependencias de rima de largo alcance. Este enfoque contribuye a la naturalidad y expresividad del habla sintetizada, garantizando una baja latencia y una salida de alta calidad.
8.4 Resultados de la comprensión verbal
Evaluamos las capacidades de comprensión del habla de la interfaz de habla de Llama 3 para tres tareas: (1) Reconocimiento automático del habla (2) Traducción del habla (3) Preguntas y respuestas del habla. Comparamos el rendimiento de la interfaz de habla de Llama 3 con tres modelos de comprensión del habla de última generación: Whisper (Radford et al., 2023), SeamlessM4T (Barrault et al., 2023) y Gemini.
Reconocimiento de voz. Evaluamos el rendimiento de ASR en Multilingual LibriSpeech (MLS; Pratap et al., 2020), LibriSpeech (Panayotov et al., 2015), VoxPopuli (Wang et al., 2021a) y un subconjunto del conjunto de datos multilingüe FLEURS (Conneau et al. 2023) en el conjunto de datos en inglés para evaluar el rendimiento de ASR. En la evaluación, el uso de Susurro El procedimiento de normalización del texto procesa posteriormente los resultados de descodificación para garantizar la coherencia con los resultados de otros modelos. En todas las pruebas, medimos la tasa de error de palabra de la interfaz de voz Llama 3 en el conjunto de pruebas estándar de estas pruebas, excepto en chino, japonés, coreano y tailandés, donde informamos de las tasas de error de caracteres.
La Tabla 31 muestra los resultados de la evaluación ASR. Demuestra el buen rendimiento de Llama 3 (y de los modelos de base multimodal en general) en tareas de reconocimiento del habla: nuestro modelo supera a modelos específicos del habla como Whisper20 y SeamlessM4T en todas las pruebas. En el caso del inglés MLS, el rendimiento de Llama 3 es similar al de Gemini.
Traducción de voz. También evaluamos el rendimiento de nuestro modelo en una tarea de traducción de voz en la que se le pedía que tradujera voz no inglesa a texto inglés. En estas evaluaciones utilizamos los conjuntos de datos FLEURS y Covost 2 (Wang et al., 2021b) y medimos las puntuaciones BLEU para el inglés traducido. La tabla 32 muestra los resultados de estos experimentos. El rendimiento de nuestro modelo en la traducción de voz pone de manifiesto las ventajas de los modelos de base multimodal en tareas como la traducción de voz.
Cuestionario de voz. La interfaz de habla de Llama 3 demuestra una capacidad asombrosa para responder preguntas. El modelo es capaz de entender sin esfuerzo el habla codificada sin haber sido expuesto previamente a este tipo de datos. Cabe destacar que, aunque el modelo sólo se entrenó con una única ronda de diálogo, es capaz de realizar sesiones de diálogo extensas y coherentes de varias rondas. En la figura 30 se muestran algunos ejemplos que ponen de relieve estas capacidades multilingües y multirronda.
Seguridad. Evaluamos el rendimiento de seguridad de nuestro modelo de voz en MuTox (Costa-jussà et al., 2023), un conjunto de datos multilingües basados en audio que contiene 20.000 segmentos en inglés y español, y 4.000 segmentos en otros 19 idiomas, cada uno etiquetado con toxicidad. El audio se pasa como entrada al modelo y se evalúa la toxicidad de la salida tras eliminar algunos caracteres especiales. Aplicamos el clasificador MuTox (Costa-jussà et al., 2023) a Gemini 1.5 Pro y comparamos los resultados. Evaluamos el porcentaje de toxicidad añadida (AT) cuando la entrada sugiere seguro y la salida es tóxico, y el porcentaje de toxicidad perdida (LT) cuando la entrada sugiere tóxico y la respuesta es seguro. La tabla 33 muestra los resultados en inglés y los resultados medios en las 21 lenguas. El porcentaje de toxicidad añadida es muy bajo: nuestro modelo de voz tiene el porcentaje más bajo de toxicidad añadida para el inglés, menos de 11 TP3T. Elimina mucha más toxicidad de la que añade.

8.5 Resultados de la generación de voz
En el contexto de la generación de voz, nos centramos en evaluar la calidad de los modelos de entrada de flujo basados en marcadores que utilizan vectores Llama 3 para tareas de normalización de texto y modelado de rimas. La evaluación se centra en comparaciones con modelos que no utilizan vectores Llama 3 como entrada adicional.
Normalización de textos. Para medir el impacto del vector Llama 3, intentamos variar la cantidad de contexto lateral derecho utilizado por el modelo. Entrenamos el modelo utilizando un contexto lateral derecho de 3 tokens de normalización de texto (TN) (separados por categorías Unicode). Este modelo se comparó con modelos que no utilizaban el vector Llama 3 y empleaban el contexto lateral derecho de 3 etiquetas o el contexto bidireccional completo. Como era de esperar, la Tabla 34 muestra que el uso del contexto completo del lado derecho mejora el rendimiento del modelo sin vectores Llama 3. Sin embargo, el modelo que contiene vectores Llama 3 supera a todos los demás modelos, ya que permite el flujo de entrada/salida de velocidad de marca sin tener que depender de contextos largos en la entrada. Comparamos modelos con y sin vectores Llama 3 8B y utilizando distintos valores de contexto en el lado derecho.
Modelado rítmico. Para evaluar el rendimiento de nuestro modelo de rima (PM) con Llama 3 8B, realizamos dos conjuntos de valoraciones humanas comparando modelos con y sin vectores Llama 3. Los evaluadores escucharon muestras de distintos modelos e indicaron sus preferencias.
Para generar la forma de onda final del habla, utilizamos un modelo acústico interno basado en Transformer (Wu et al., 2021), que predice características espectrales, y un vocoder neural WaveRNN (Kalchbrenner et al., 2018) para generar la forma de onda final del habla.
En la primera prueba, compararemos directamente la Llama 3 8B PM con un modelo de referencia de streaming que no utiliza los vectores de Llama 3. En la segunda prueba, se comparó la Llama 3 8B PM con un modelo de referencia de no streaming que no utiliza los vectores Llama 3. Como se muestra en la Tabla 35, se prefirió el Llama 3 8B PM durante 60% de tiempo (en comparación con el modelo de referencia de streaming) y 63,6% de tiempo (en comparación con el modelo de referencia de no streaming), lo que indica una mejora significativa de la calidad perceptiva. La principal ventaja de la Llama 3 8B PM es su capacidad de streaming basada en marcadores (sección 8.2.2), que mantiene una baja latencia durante el proceso de inferencia. Esto reduce los requisitos de espera del modelo, lo que le permite lograr una síntesis del habla más sensible y en tiempo real en comparación con el modelo de referencia sin streaming. En conjunto, el modelo de rima Llama 3 8B supera sistemáticamente al modelo de referencia, lo que demuestra su eficacia para mejorar la naturalidad y expresividad del habla sintetizada.




9 Trabajos relacionados
El desarrollo de Llama 3 se basa en un amplio conjunto de investigaciones previas sobre modelos fundamentales del lenguaje, la imagen, el vídeo y el habla. El alcance de este artículo no incluye una descripción exhaustiva de este trabajo; remitimos al lector a Bordes et al. (2024); Madan et al. (2024); Zhao et al. (2023a) para obtener dicha descripción. A continuación, ofrecemos un breve resumen de los trabajos fundamentales que influyeron directamente en el desarrollo de Llama 3.
9.1 Lengua
Alcance. Llama 3 sigue la tendencia perdurable de aplicar métodos sencillos a escalas cada vez mayores que caracterizan al modelo base. Las mejoras se deben al aumento de la potencia de cálculo y la calidad de los datos, y el modelo 405B utiliza casi cincuenta veces el presupuesto de cálculo previo al entrenamiento de Llama 2, 70B. Aunque nuestro modelo más grande, Llama 3, contiene 405B parámetros, en realidad tiene menos parámetros que modelos anteriores y de peor rendimiento como PALM (Chowdhery et al., 2023), debido a una mejor comprensión de las leyes de escalado (Kaplan et al., 2020; Hoffmann et al., 2022). Existen otros modelos de frontera en tamaños como Claude 3 o GPT 4 (OpenAI, 2023a), con información pública limitada, pero con un rendimiento general comparable.
Modelos a pequeña escala. El desarrollo de modelos a pequeña escala ha ido de la mano del desarrollo de modelos a gran escala. Los modelos con menos parámetros pueden mejorar significativamente los costes de inferencia y simplificar el despliegue (Mehta et al., 2024; Team et al., 2024). El modelo Llama 3, más pequeño, lo consigue superando con creces los puntos de entrenamiento óptimos desde el punto de vista computacional, lo que supone un trueque entre el cálculo de entrenamiento y la eficiencia de la inferencia. Otra vía consiste en destilar modelos más grandes en otros más pequeños, como Phi (Abdin et al., 2024).
Arquitectura. En comparación con Llama 2, Llama 3 presenta modificaciones arquitectónicas mínimas, pero otros modelos base recientes han explorado diseños alternativos. En particular, las arquitecturas híbridas expertas (Shazeer et al. 2017; Lewis et al. 2021; Fedus et al. 2022; Zhou et al. 2022) pueden utilizarse como una forma de aumentar eficientemente la capacidad de un modelo, como en Mixtral (Jiang et al. 2024) y Arctic (Snowflake 2024). El rendimiento de Llama 3 supera al de estos modelos, lo que sugiere que las arquitecturas densas no son un factor limitante, pero que sigue habiendo muchas compensaciones en términos de eficiencia del entrenamiento y la inferencia, y de estabilidad del modelo a gran escala.
Fuente abierta. Los modelos de base de código abierto han evolucionado rápidamente en el último año, y Llama3-405B está ahora a la par con el estado actual de la técnica de código cerrado. Recientemente se han desarrollado varias familias de modelos, como Mistral (Jiang et al., 2023), Falcon (Almazrouei et al., 2023), MPT (Databricks, 2024), Pythia (Biderman et al., 2023), Arctic (Snowflake, 2024), OpenELM (Mehta y otros, 2024), OLMo (Groeneveld y otros, 2024), StableLM (Bellagente y otros, 2024), OpenLLaMA (Geng y Liu, 2023), Qwen (Bai y otros, 2023), Gemma (Team y otros, 2024), Grok (Biderman y otros, 2023) y Gemma (Biderman y otros, 2024). 2024), Grok (XAI, 2024) y Phi (Abdin et al., 2024).
Después de la formación. El postentrenamiento de Llama 3 sigue una estrategia establecida de alineación de instrucciones (Chung et al., 2022; Ouyang et al., 2022), seguida de una alineación con opiniones humanas (Kaufmann et al., 2023). Aunque algunos estudios han mostrado resultados inesperados con procedimientos de alineación ligeros (Zhou et al., 2024), Llama 3 utiliza millones de juicios de instrucciones y preferencias humanas para mejorar los modelos preentrenados, incluido el muestreo de rechazo (Bai et al., 2022), el ajuste fino supervisado (Sanh et al., 2022) y la optimización directa de preferencias (Rafailov et al., 2023). Para curar estos ejemplos de instrucciones y preferencias, desplegamos versiones anteriores de Llama 3 para filtrar (Liu et al., 2024c), reescribir (Pan et al., 2024) o generar pistas y respuestas (Liu et al., 2024b), y aplicamos estas técnicas a través de múltiples rondas de post-entrenamiento.
9.2 Multimodalidad
Nuestros experimentos de capacidad multimodal de Llama 3 forman parte de un estudio a largo plazo de modelos fundamentales para modelar conjuntamente múltiples modalidades. Nuestro enfoque Llama 3 combina ideas de varios trabajos para lograr resultados comparables a Gemini 1.0 Ultra (Google, 2023) y GPT-4 Vision (OpenAI, 2023b); véase la sección 7.6.
vídeoLa investigación sobre el modelado conjunto de vídeo y lenguaje: A pesar del creciente número de modelos de base que admiten la entrada de vídeo (Google, 2023; OpenAI, 2023b), no se ha investigado mucho sobre el modelado conjunto de vídeo y lenguaje. Al igual que Llama 3, la mayor parte de la investigación actual utiliza métodos de adaptación para alinear las representaciones de vídeo y lenguaje y desentrañar preguntas y respuestas y razonamientos sobre vídeo (Lin et al. 2023; Li et al. 2023a; Maaz et al. 2024; Zhang et al. 2023; Zhao et al. 2022). Encontramos que estos métodos producen resultados que son competitivos con el estado de la técnica; véase la sección 7.7.
pronunciación coloquial (más que literaria) de un carácter chinoNuestro trabajo también se inscribe en un conjunto más amplio de trabajos que combinan el modelado del lenguaje y del habla. Entre los primeros modelos conjuntos de texto y habla se encuentran AudioPaLM (Rubenstein et al., 2023), VioLA (Wang et al., 2023b), VoxtLM Maiti et al. (2023), SUTLM (Chou et al., 2023) y Spirit-LM (Nguyen et al., 2024). . Nuestro trabajo se basa en enfoques compositivos anteriores para combinar el habla y el lenguaje, como el de Fathullah et al. (2024). A diferencia de la mayoría de estos trabajos previos, hemos optado por no ajustar el modelo lingüístico para la tarea del habla, ya que ello podría provocar la competencia de tareas no lingüísticas. Hemos comprobado que, incluso sin un ajuste tan preciso, se puede obtener un buen rendimiento con modelos de mayor tamaño; véase la sección 8.4.
10 Conclusiones
El desarrollo de modelos de base de alta calidad está aún en sus primeras fases. Nuestra experiencia en el desarrollo de Llama 3 sugiere que hay mucho margen para mejorar estos modelos en el futuro. En el desarrollo de la familia de modelos Llama 3, hemos comprobado que centrarnos en los datos de alta calidad, la escala y la simplicidad conduce sistemáticamente a los mejores resultados. En experimentos preliminares, exploramos arquitecturas de modelos y escenarios de entrenamiento más complejos, pero no encontramos que los beneficios de estos enfoques compensaran la complejidad adicional que introducían en el desarrollo del modelo.
Desarrollar un modelo de base tan emblemático como Llama 3 requiere no sólo superar muchas cuestiones técnicas profundas, sino también tomar decisiones organizativas con conocimiento de causa. Por ejemplo, para garantizar que Llama 3 no se sobreajuste accidentalmente a las pruebas de referencia más utilizadas, nuestros datos de preentrenamiento son obtenidos y procesados por un equipo independiente que está fuertemente incentivado para evitar contaminar las pruebas de referencia externas con datos de preentrenamiento. Otro ejemplo es que garantizamos la credibilidad de las evaluaciones humanas permitiendo que sólo un pequeño grupo de investigadores no implicados en el desarrollo de modelos realice estas evaluaciones y acceda a ellas. Aunque estas decisiones organizativas rara vez se comentan en los documentos técnicos, nos han parecido fundamentales para el éxito del desarrollo de la familia de modelos Llama 3.
Compartimos los detalles de nuestro proceso de desarrollo, ya que creemos que ayudará a la comunidad investigadora en general a comprender los elementos clave del desarrollo de modelos base y contribuirá a un debate público más perspicaz sobre el futuro desarrollo de los modelos base. También compartimos los resultados experimentales preliminares de la integración de la funcionalidad multimodal en Llama 3. Aunque estos modelos aún están en fase de desarrollo activo y no están listos para su publicación, esperamos que compartir nuestros resultados con antelación acelere la investigación en esta dirección.
Dados los resultados positivos de los análisis de seguridad detallados en este documento, estamos publicando nuestro modelo de lenguaje Llama 3 para acelerar el proceso de desarrollo de sistemas de IA para una amplia gama de casos de uso socialmente relevantes, y para permitir a la comunidad investigadora revisar nuestros modelos y encontrar formas de hacerlos mejores y más seguros. Creemos que la publicación de los modelos subyacentes es fundamental para el desarrollo responsable de dichos modelos, y esperamos que la publicación de Llama 3 anime a la industria en su conjunto a adoptar un desarrollo de IA abierto y responsable.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...