LitServe: despliegue rápido de servicios de inferencia de modelos de IA de uso general para empresas
Últimos recursos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 47.6K 00

Introducción general
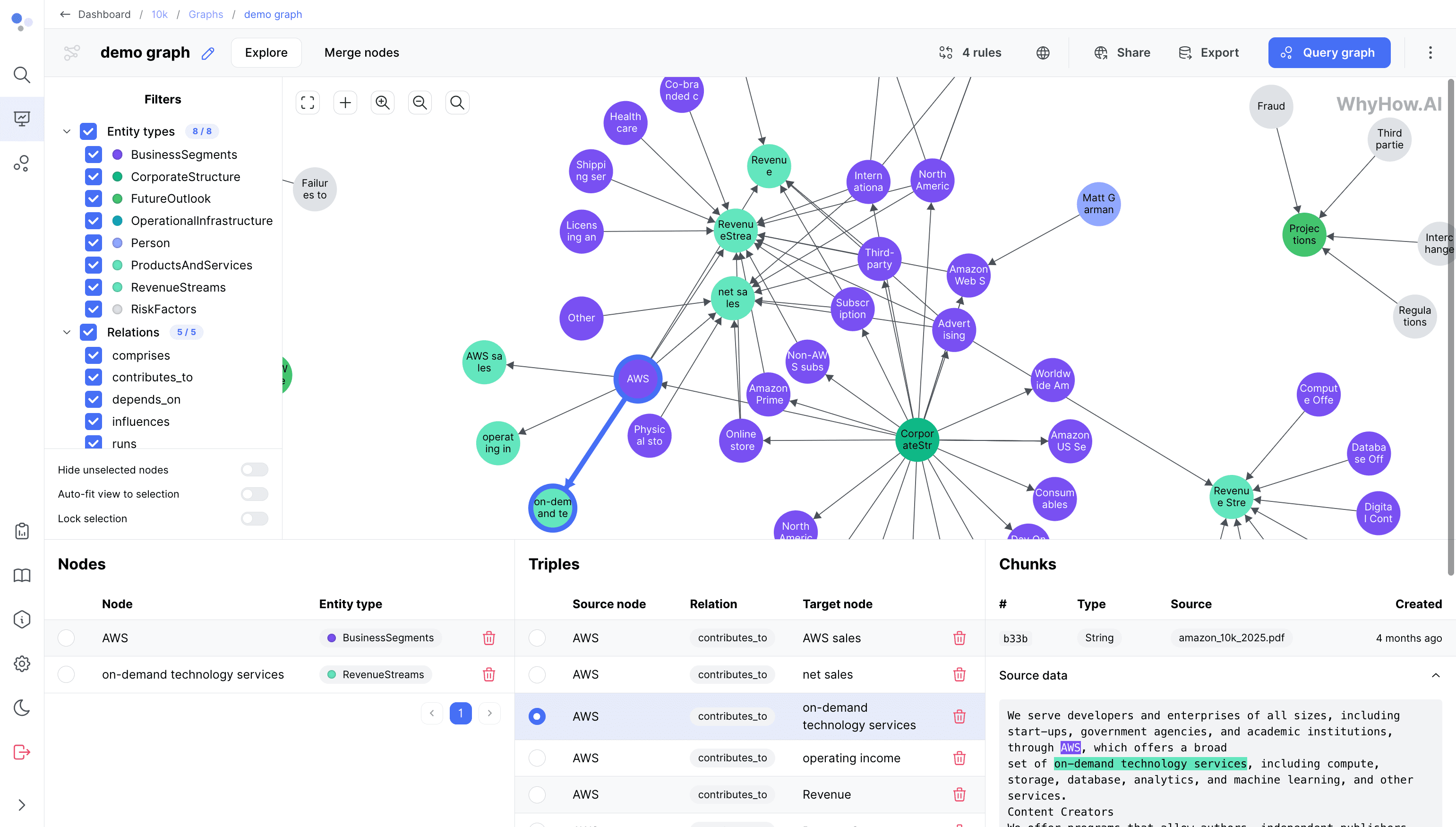
LitServe es rayo AI ha lanzado un motor de servicios de modelos de IA de código abierto, basado en FastAPI, centrado en el despliegue rápido de servicios de inferencia para modelos de IA de propósito general. Es compatible con una amplia gama de escenarios, desde grandes modelos de lenguaje (LLM), modelos visuales, modelos de audio hasta modelos clásicos de aprendizaje automático, y ofrece procesamiento por lotes, streaming y escalado automático de GPU, con un aumento del rendimiento de al menos el doble respecto a FastAPI. LitServe es fácil de usar y muy flexible, y puede alojarse por sí mismo o totalmente a través de Lightning Studios. LitServe es fácil de usar y muy flexible, y puede alojarse de forma autónoma o completa a través de Lightning Studios, por lo que resulta ideal para que investigadores, desarrolladores y empresas construyan rápidamente API de inferencia de modelos eficientes. Los responsables de LitServe hacen hincapié en las características empresariales, como la seguridad, la escalabilidad y la alta disponibilidad, para garantizar que los entornos de producción estén listos para funcionar desde el primer momento.

Lista de funciones
- Despliegue rápido de servicios de inferenciaSoporte para la conversión rápida de modelos desde frameworks como PyTorch, JAX, TensorFlow, etc. a APIs.
- archivo por lotesFusión de varias solicitudes de inferencia en un lote para mejorar el rendimiento.
- streamingSoporte de salida de resultados de inferencia en tiempo real, adecuado para escenarios de respuesta continua.
- Escalado automático de la GPUOptimiza el rendimiento ajustando dinámicamente los recursos de la GPU en función de la carga de inferencia.
- Sistema compuesto de IAPermite que varios modelos razonen en colaboración para crear servicios complejos.
- Alojamiento propio vs. alojamiento en la nube: Admite la implantación local o la gestión a través de la nube de Lightning Studios.
- Integración con vLLMOptimización del rendimiento de la inferencia en modelos lingüísticos de gran tamaño.
- Compatible con OpenAPI: Genera automáticamente documentación estándar de la API para facilitar las pruebas y la integración.
- Soporte completo de modelos: Cubre las necesidades de inferencia de varios modelos como LLM, visión, audio, incrustación, etc.
- Optimización de servidores: Proporciona procesamiento multiproceso e inferencia más de 2 veces más rápido que FastAPI.
Utilizar la ayuda
Proceso de instalación
LitServe es fácil de instalar con la herramienta de Python pip La herramienta hará el trabajo. A continuación se detallan los pasos:
1. Preparar el entorno
Asegúrese de que Python 3.8 o posterior está instalado en su sistema; se recomienda un entorno virtual:
python -m venv venv
source venv/bin/activate # Linux/Mac
venv\Scripts\activate # Windows
2. Instalación de LitServe
Ejecute el siguiente comando para instalar la versión estable:
pip install litserve
Si necesitas las últimas funciones, puedes instalar la versión de desarrollo:
pip install git+https://github.com/Lightning-AI/litserve.git@main
3. Inspección de las instalaciones
Compruebe que se ha realizado correctamente:
python -c "import litserve; print(litserve.__version__)"
La salida correcta del número de versión completa la instalación.
4. Dependencias opcionales
Si necesitas soporte para GPU, instala la versión para GPU del framework correspondiente, por ejemplo:
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
Cómo utilizar LitServe
LitServe convierte los modelos de IA en servicios de inferencia mediante un código limpio. He aquí cómo funciona en detalle:
1. Creación del Servicio de Razonamiento Simple
A continuación se muestra un ejemplo de servicio de razonamiento compuesto con dos modelos:
import litserve as ls
class SimpleLitAPI(ls.LitAPI):
def setup(self, device):
# 初始化,加载模型或数据
self.model1 = lambda x: x ** 2 # 平方模型
self.model2 = lambda x: x ** 3 # 立方模型
def decode_request(self, request):
# 解析请求数据
return request["input"]
def predict(self, x):
# 复合推理
squared = self.model1(x)
cubed = self.model2(x)
return squared + cubed
def encode_response(self, output):
# 格式化推理结果
return {"output": output}
if __name__ == "__main__":
server = ls.LitServer(SimpleLitAPI(), accelerator="auto")
server.run(port=8000)
- estar en movimiento: Guardar como
server.pyAplicaciónpython server.py. - prueba (maquinaria, etc.): Uso de
curlEnvía una solicitud de razonamiento:curl -X POST "http://127.0.0.1:8000/predict" -H "Content-Type: application/json" -d '{"input": 4.0}'Salida:
{"output": 80.0}(16 + 64).
2. Permitir el razonamiento masivo
Modificar el código para que admita el procesamiento por lotes:
server = ls.LitServer(SimpleLitAPI(), max_batch_size=4, accelerator="auto")
- Instrucciones de uso::
max_batch_size=4Indica que se procesan hasta 4 solicitudes de inferencia al mismo tiempo y se fusionan automáticamente para mejorar la eficacia. - Métodos de ensayoEnvía la solicitud varias veces y observa la mejora del rendimiento:
curl -X POST "http://127.0.0.1:8000/predict" -H "Content-Type: application/json" -d '{"input": 5.0}'
3. Configuración del razonamiento de streaming
Para escenarios de razonamiento en tiempo real:
class StreamLitAPI(ls.LitAPI):
def setup(self, device):
self.model = lambda x: [x * i for i in range(5)]
def decode_request(self, request):
return request["input"]
def predict(self, x):
for result in self.model(x):
yield result
def encode_response(self, output):
return {"output": output}
server = ls.LitServer(StreamLitAPI(), stream=True, accelerator="auto")
server.run(port=8000)
- Instrucciones de uso::
stream=TruePermitir el razonamiento en flujo.predictutilizaryieldDevuelve los resultados uno a uno. - Métodos de ensayoUtilice un cliente que admita respuestas en tiempo real:
curl --no-buffer -X POST "http://127.0.0.1:8000/predict" -H "Content-Type: application/json" -d '{"input": 2}'
4. Ampliación automática de la GPU
Si se dispone de una GPU, LitServe optimiza automáticamente la inferencia:
- Instrucciones de uso::
accelerator="auto"Detectar y priorizar GPUs. - validar (una teoría)Comprueba los registros después de la ejecución para confirmar el uso de la GPU.
- Requisitos medioambientalesAsegúrese de que la versión GPU del framework (por ejemplo, PyTorch) está instalada.
5. Despliegue del razonamiento de modelos complejos (utilizando el BERT como ejemplo)
Despliegue el servicio de inferencia de modelos BERT de Hugging Face:
from transformers import BertTokenizer, BertModel
import litserve as ls
class BertLitAPI(ls.LitAPI):
def setup(self, device):
self.tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
self.model = BertModel.from_pretrained("bert-base-uncased").to(device)
def decode_request(self, request):
return request["text"]
def predict(self, text):
inputs = self.tokenizer(text, return_tensors="pt").to(self.model.device)
outputs = self.model(**inputs)
return outputs.last_hidden_state.mean(dim=1).tolist()
def encode_response(self, output):
return {"embedding": output}
server = ls.LitServer(BertLitAPI(), accelerator="auto")
server.run(port=8000)
- estar en movimientoDespués de ejecutar la secuencia de comandos, acceda a
http://127.0.0.1:8000/predict. - prueba (maquinaria, etc.)::
curl -X POST "http://127.0.0.1:8000/predict" -H "Content-Type: application/json" -d '{"text": "Hello, world!"}'
6. Integrar vLLM para desplegar el razonamiento LLM
Razonamiento eficiente para modelos lingüísticos de gran tamaño:
import litserve as ls
from vllm import LLM
class LLMLitAPI(ls.LitAPI):
def setup(self, device):
self.model = LLM(model="meta-llama/Llama-3.2-1B", dtype="float16")
def decode_request(self, request):
return request["prompt"]
def predict(self, prompt):
outputs = self.model.generate(prompt, max_tokens=50)
return outputs[0].outputs[0].text
def encode_response(self, output):
return {"response": output}
server = ls.LitServer(LLMLitAPI(), accelerator="auto")
server.run(port=8000)
- Instalación de vLLM::
pip install vllm. - prueba (maquinaria, etc.)::
curl -X POST "http://127.0.0.1:8000/predict" -H "Content-Type: application/json" -d '{"prompt": "What is AI?"}'
7. Consultar la documentación de la API
- Instrucciones de uso: Acceso
http://127.0.0.1:8000/docsServicio interactivo de pruebas de razonamiento. - Consejos de funcionamiento: Basado en el estándar OpenAPI y contiene todos los detalles del endpoint.
8. Opciones de alojamiento
- autoalojadoEjecuta el código localmente o en el servidor.
- alojamiento en nubeDesplegado a través de Lightning Studios, requiere registro de cuenta, ofrece equilibrio de carga, autoescalado y mucho más.
Consejos operativos
- ajustar los componentes durante las pruebas: Ajustes
timeout=60Evita los tiempos muertos de razonamiento. - log (cálculo)Compruebe los registros del terminal al inicio para solucionar el problema.
- optimizaciónConsulte la documentación oficial para activar funciones avanzadas como la autenticación y la implementación de Docker.
LitServe es compatible con toda la gama de requisitos de procesos, desde la creación de prototipos hasta las aplicaciones empresariales, gracias a la rápida implantación y optimización de los servicios de inferencia.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...