
Chunking tardío x Milvus: cómo mejorar la precisión del GAR
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 52.2K 00


01.contextos
En el desarrollo de aplicaciones RAG, el primer paso es trocear el documento, un troceado eficiente del documento puede mejorar eficazmente la precisión del contenido de la recuperación posterior. La forma de trocear de manera eficiente es un tema candente de discusión, existen métodos como el troceado de tamaño fijo, el troceado de tamaño aleatorio, el remuestreo de ventana deslizante, el troceado recursivo, el troceado basado en el contenido del troceado semántico y otros métodos. El Late Chunking propuesto por Jina AI trata el problema del chunking desde otra perspectiva, echémosle un vistazo.
02.¿Qué es la fragmentación tardía?
El chunking tradicional puede perder las dependencias contextuales a larga distancia en los documentos al procesar documentos largos, lo que supone un escollo importante para la recuperación y comprensión de la información. Es decir, cuando la información clave está dispersa en varios bloques de texto, es probable que el fragmento de texto troceado fuera de contexto pierda su significado original, con el consiguiente empeoramiento de la recuperación posterior.
Tomemos como ejemplo la nota de publicación de Milvus 2.4.13, si está dividida en dos bloques de documentos como se indica a continuación, y si queremos consultar el bloqueMilvus 2.4.13有哪些新功能?El contenido directamente relevante está en el fragmento 2, mientras que la información sobre la versión de Milvus está en el fragmento 1. En este punto, es difícil para el modelo de incrustación vincular correctamente estas referencias a las entidades, lo que da como resultado una incrustación de baja calidad.
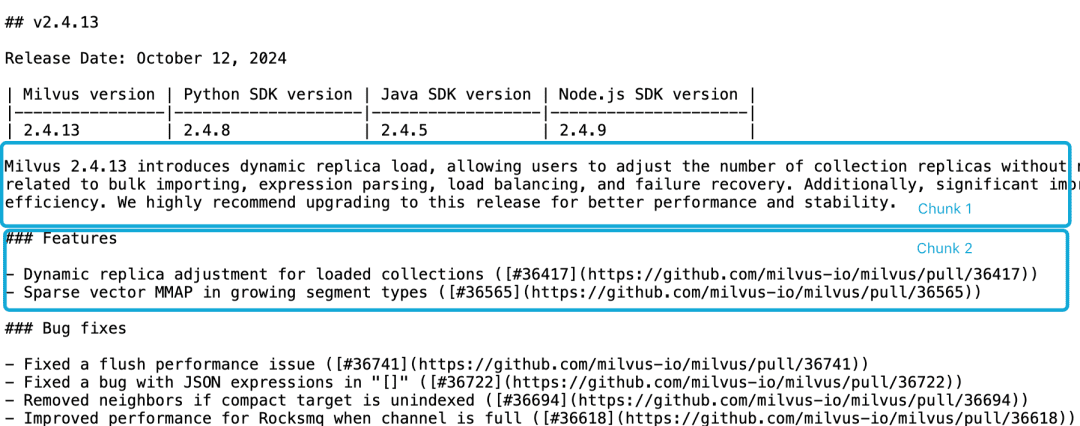
LLM tiene dificultades para resolver este problema de correlación debido a que la descripción funcional no se encuentra en el mismo fragmento que la información de la versión y a la falta de un documento contextual más amplio. Aunque hay una serie de heurísticos que intentan paliar este problema, como el remuestreo de ventanas deslizantes, el solapamiento de longitudes de ventanas contextuales y el escaneo de múltiples documentos, como todos los heurísticos, estos métodos son impredecibles; pueden funcionar en algunos casos, pero no hay garantías teóricas.
El chunking tradicional utiliza una estrategia de prechunking, es decir, primero se trocea y luego se pasa por el modelo de incrustación. El texto se trocea primero en función de parámetros como la frase, el párrafo o la longitud máxima preestablecida. A continuación, el modelo de incrustación procesa estos trozos uno a uno, mediante métodos como la agrupación de promedios, el ficha Late Chunking es el proceso de pasar primero por el modelo Embedding y luego trocearlo (esto es lo que significa late). Late Chunking, por otro lado, consiste en pasar por el modelo Embedding antes de hacer el chunking (aquí es donde entra el significado de late, primero vectorización y luego chunking), primero tomamos el modelo Embedding de transformador La capa se aplica a todo el texto, generando una secuencia de representaciones vectoriales para cada token que contiene rica información contextual. A continuación, estas secuencias de vectores de tokens se agrupan de forma uniforme para obtener el bloque final Embedding que tiene en cuenta todo el contexto del texto.
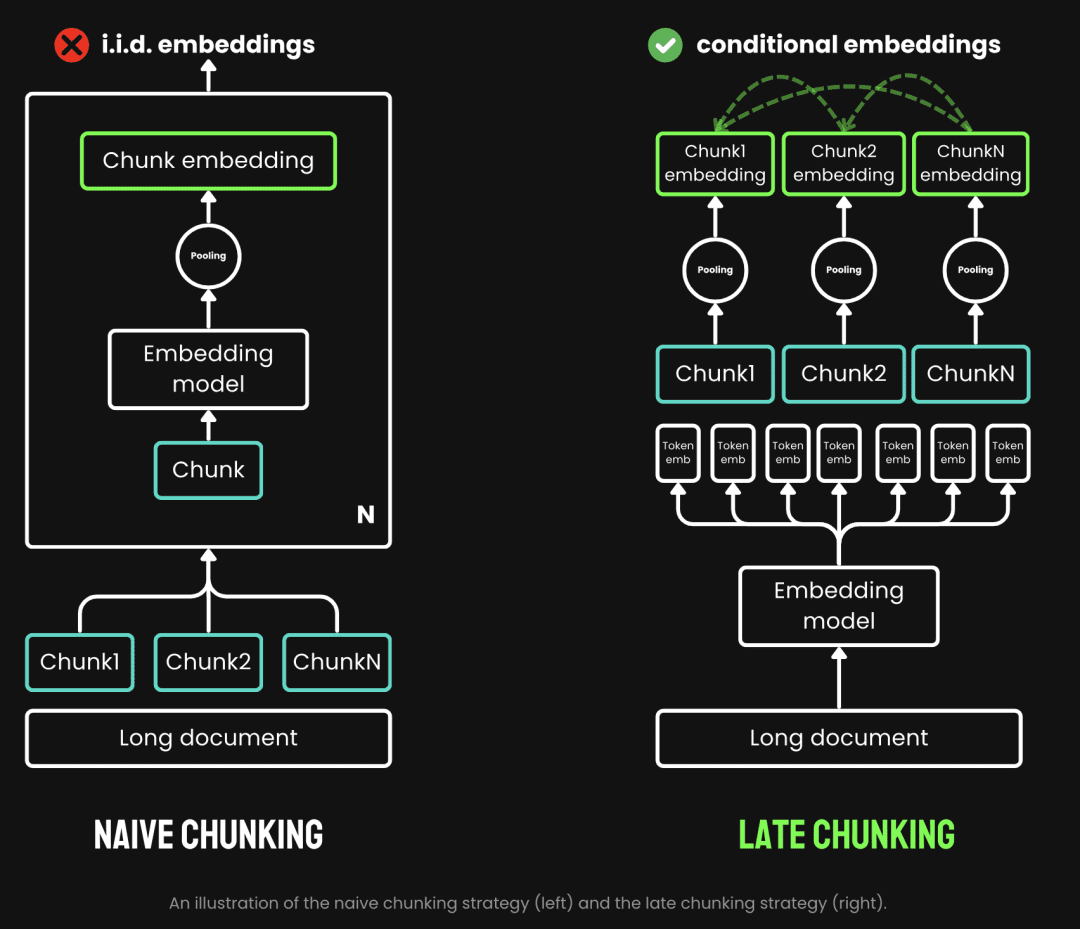
(Fuente de la imagen: https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
El Chunking tardío genera un Embedding de bloques en el que cada bloque codifica más información contextual, mejorando así la calidad y precisión de la codificación. Podemos admitir modelos de incrustación de contextos largos mediante contextos largos como jina-embeddings-v2-base-enPuede procesar hasta 8192 tokens de texto (equivalente a 10 páginas de papel A4), lo que básicamente cumple los requisitos contextuales de la mayoría de los textos largos.
En resumen, podemos ver las ventajas del Late Chunking en las aplicaciones RAG:
- Mayor precisión: al conservar la información contextual, la fragmentación tardía devuelve contenidos más pertinentes para las consultas que la fragmentación simple.
- Llamadas LLM eficientes: Late Chunking reduce la cantidad de texto que se pasa a LLM porque devuelve menos trozos y más relevantes.
03.Pruebas de fragmentación tardía
3.1. Aplicación de la base de fragmentación tardía
Función sentence_chunker para el chunking de documento original a párrafo, devuelve el contenido de los chunks y la información de marcado de chunk span_annotations (es decir, el inicio y el final del marcado de chunk)
def sentence_chunker(document, batch_size=10000):
nlp = spacy.blank("en")
nlp.add_pipe("sentencizer", config={"punct_chars": None})
doc = nlp(document)
docs = []
for i in range(0, len(document), batch_size):
batch = document[i : i + batch_size]
docs.append(nlp(batch))
doc = Doc.from_docs(docs)
span_annotations = []
chunks = []
for i, sent in enumerate(doc.sents):
span_annotations.append((sent.start, sent.end))
chunks.append(sent.text)
return chunks, span_annotations
La función document_to_token_embeddings pasa el modelo jinaai/jina-embeddings-v2-base-en así como el tokenizador, que devuelve la incrustación de todo el documento.
def document_to_token_embeddings(model, tokenizer, document, batch_size=4096): tokenized_document = tokenizer(document, return_tensors="pt") tokens = tokenized_document.tokens() outputs = [] for i in range(0, len(tokens), batch_size): start = i end = min(i + batch_size, len(tokens)) batch_inputs = {k: v[:, start:end] for k, v in tokenized_document.items()} with torch.no_grad(): model_output = model(**batch_inputs) outputs.append(model_output.last_hidden_state) model_output = torch.cat(outputs, dim=1) return model_output
La función late_chunking trocea el Embedding del documento completo, así como la información de marcado span_annotations de los trozos originales.
def late_chunking(token_embeddings, span_annotation, max_length=None): outputs = [] for embeddings, annotations in zip(token_embeddings, span_annotation): if ( max_length is not None ): annotations = [ (start, min(end, max_length - 1)) for (start, end) in annotations if start < (max_length - 1) ] pooled_embeddings = [] for start, end in annotations: if (end - start) >= 1: pooled_embeddings.append( embeddings[start:end].sum(dim=0) / (end - start) ) pooled_embeddings = [ embedding.detach().cpu().numpy() for embedding in pooled_embeddings ] outputs.append(pooled_embeddings) return outputs
Si se utiliza un modelojinaai/jina-embeddings-v2-base-enRealizar la fragmentación tardía
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
# First chunk the text as normal, to obtain the beginning and end points of the chunks.
chunks, span_annotations = sentence_chunker(document)
# Then embed the full document.
token_embeddings = document_to_token_embeddings(model, tokenizer, document)
# Then perform the late chunking
chunk_embeddings = late_chunking(token_embeddings, [span_annotations])[0]
3.2. Comparación con los métodos de incrustación tradicionales
Tomemos como ejemplo la nota de lanzamiento de milvus 2.4.13.
Milvus 2.4.13 introduce la carga dinámica de réplicas, permitiendo a los usuarios ajustar el número de réplicas de la colección sin necesidad de liberar y recargar la colección.
Esta versión también soluciona varios errores críticos relacionados con la importación masiva, el análisis sintáctico de expresiones, el equilibrio de carga y la recuperación de fallos.
Además, se han introducido mejoras significativas en el uso de los recursos MMAP y en el rendimiento de las importaciones, aumentando la eficiencia general del sistema.
Recomendamos encarecidamente actualizar a esta versión para mejorar el rendimiento y la estabilidad.
El Embedding tradicional, es decir, el chunking seguido del Embedding, y el Embedding con enfoque de chunking tardío, es decir, el Embedding seguido del chunking, se realizan respectivamente. A continuación, el milvus 2.4.13 Compare los resultados con estos dos enfoques de incrustación respectivamente
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
milvus_embedding = model.encode('milvus 2.4.13')
for chunk, late_chunking_embedding, traditional_embedding in zip(chunks, chunk_embeddings, embeddings_traditional_chunking):
print(f'similarity_late_chunking("milvus 2.4.13", "{chunk}")')
print('late_chunking: ', cos_sim(milvus_embedding, late_chunking_embedding))
print(f'similarity_traditional("milvus 2.4.13", "{chunk}")')
print('traditional_chunking: ', cos_sim(milvus_embedding, traditional_embeddings))
A partir de los resultados, las palabras milvus 2.4.13 La similitud de los resultados del Late Chunking con los documentos fragmentados es mayor que la del Embedding tradicional porque el Late Chunking realiza primero el Embedding de todo el pasaje de texto, de modo que todo el pasaje de texto recibe milvus 2.4.13 información, lo que a su vez mejora significativamente la similitud en posteriores comparaciones de textos.
similarity_late_chunking("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
late_chunking: 0.8785206
similarity_traditional("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
traditional_chunking: 0.8354263
similarity_late_chunking("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
late_chunking: 0.84828955
similarity_traditional("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
traditional_chunking: 0.7222632
similarity_late_chunking("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
late_chunking: 0.84942204
similarity_traditional("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
traditional_chunking: 0.6907381
similarity_late_chunking("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
late_chunking: 0.85431844
similarity_traditional("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
traditional_chunking: 0.71859795
3.3. Pruebas de fragmentación tardía en Milvus
Importación de datos de fragmentación tardía a Milvus
batch_data=[]
for i in range(len(chunks)):
data = {
"content": chunks[i],
"embedding": chunk_embeddings[i].tolist(),
}
batch_data.append(data)
res = client.insert(
collection_name=collection,
data=batch_data,
)
Pruebas de consulta
Definimos el método de consulta por similitud coseno, así como el uso del método de consulta nativo Milvus para Late Chunking respectivamente.
def late_chunking_query_by_milvus(query, top_k = 3):
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
res = client.search(
collection_name=collection,
data=[query_vector.tolist()],
limit=top_k,
output_fields=["id", "content"],
)
return [item.get("entity").get("content") for items in res for item in items]
def late_chunking_query_by_cosine_sim(query, k = 3):
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
results = np.empty(len(chunk_embeddings))
for i, (chunk, embedding) in enumerate(zip(chunks, chunk_embeddings)):
results[i] = cos_sim(query_vector, embedding)
results_order = results.argsort()[::-1]
return np.array(chunks)[results_order].tolist()[:k]
A partir de los resultados, los dos métodos devuelven el mismo contenido, lo que indica que los resultados de la búsqueda de Late Chunking en Milvus son precisos.
> late_chunking_query_by_milvus("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
> late_chunking_query_by_cosine_sim("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
04.resúmenes
Presentamos los antecedentes, los conceptos básicos y la implementación subyacente de Late Chunking tal y como surgió, y a continuación comprobamos que Late Chunking funciona bien probándolo en Mivlus. En general, la combinación de precisión, eficacia y facilidad de aplicación hace del Late Chunking un enfoque eficaz para las aplicaciones RAG.
Referencia.
- https://stackoverflow.blog/2024/06/06/breaking-up-is-hard-to-do-chunking-in-rag-applications
- https://jina.ai/news/late-chunking-in-long-context-embedding-models/
- https://jina.ai/news/what-late-chunking-really-is-and-what-its-not-part-ii/
Código de ejemplo:
Enlace: https://pan.baidu.com/s/1cYNfZTTXd7RwjnjPFylReg?pwd=1234 Extraer código: 1234 código se ejecuta en aws g4dn.xlarge máquina
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...