LangExtract - Biblioteca Python de código abierto de Google para extraer información estructurada
Últimos recursos sobre IAPublicado hace 8 meses Círculo de intercambio de inteligencia artificial 51.4K 00

¿Qué es LangExtract?
LangExtract es una biblioteca Python de código abierto de Google que utiliza grandes modelos lingüísticos (LLM) para extraer información estructurada de texto no estructurado. Con comandos definidos por el usuario y un pequeño número de ejemplos, puede identificar y organizar eficazmente detalles clave, como nombres de medicamentos de notas clínicas o relaciones entre personajes de la literatura, etc. Los principales puntos fuertes de LangExtract son su posicionamiento preciso del texto de origen, que asigna cada extracción a la ubicación exacta del texto original, y su compatibilidad con el resaltado visual, que facilita el rastreo y la verificación. LangExtract es compatible con varios modelos lingüísticos, incluidos modelos en la nube y modelos locales de código abierto, lo que le permite gestionar documentos extensos y optimizar la eficacia de la extracción. LangExtract ofrece funciones de visualización interactiva y puede generar archivos HTML independientes, lo que facilita a los usuarios la visualización y revisión de los resultados de la extracción en su contexto original. LangExtract puede utilizarse en diversos campos, como la sanidad, la literatura, las finanzas, etc., ayudando a los usuarios a extraer rápidamente información valiosa de textos complejos.
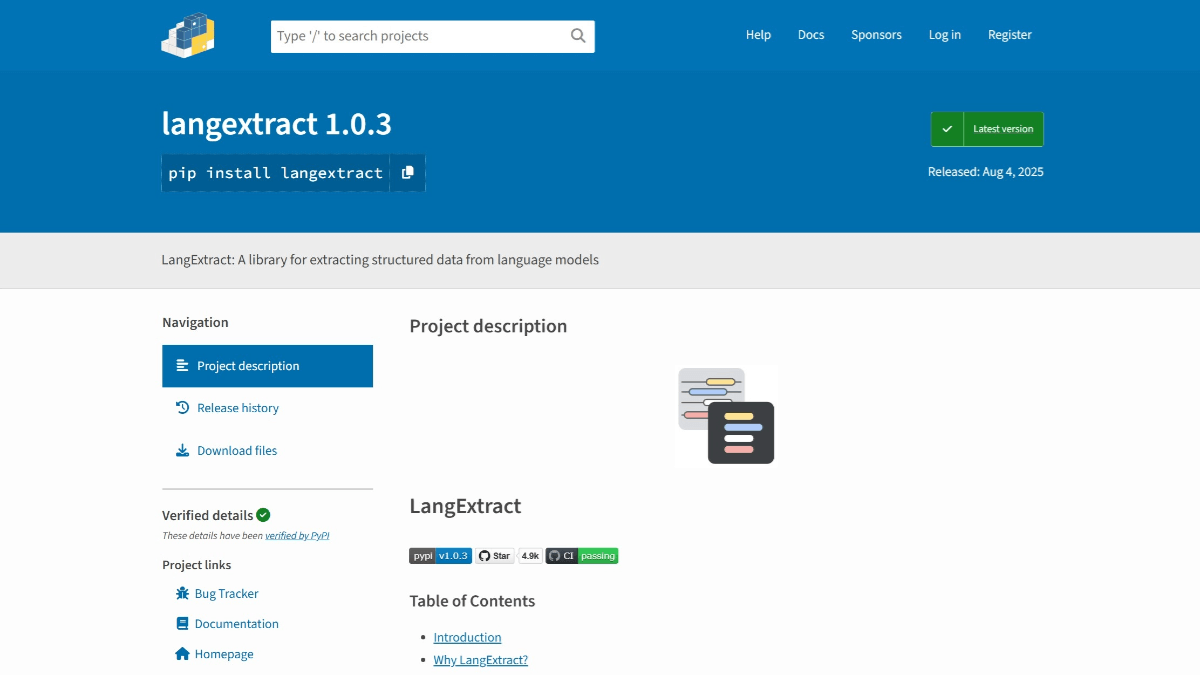
Principales funciones de LangExtract
- extracción de texto: Extrae información clave de texto no estructurado y admite muchos tipos de datos, como notas clínicas, informes, etc.
- posicionamiento preciso: Asigna con precisión el contenido extraído a las ubicaciones del texto de origen y admite el resaltado visual para la trazabilidad y la verificación.
- Salida estructuradaSalida de la información extraída en un formato estructurado (por ejemplo, JSONL) para facilitar su posterior procesamiento y análisis.
- Optimización de documentos largosProcesamiento eficiente de documentos ultralargos y mejora de la recuperación mediante estrategias de fragmentación de texto y extracción multirronda.
- Visualización interactivaGenerar archivos HTML interactivos que permitan a los usuarios ver y revisar los resultados de la extracción en su contexto original.
- Soporte flexible de modelos: Se admiten varios modelos lingüísticos, incluidos modelos basados en la nube (por ejemplo, Google Gemini) y modelos locales de código abierto.
- Adaptación del dominioLa extracción de datos: las tareas de extracción para cualquier dominio pueden definirse con un pequeño número de ejemplos, sin necesidad de afinar el modelo, para múltiples dominios como la sanidad, la literatura, las finanzas, etc.
- Tratamiento eficaz: Admite el procesamiento en paralelo, mejora la eficacia de la extracción y es adecuado para tareas de procesamiento de texto a gran escala.
Dirección del proyecto LangExtract
- Página web del proyecto:: https://pypi.org/project/langextract/
- Repositorio GitHub:: https://github.com/google/langextract
Cómo utilizar LangExtract
- Instalación de LangExtractInstale la biblioteca LangExtract con pip, la herramienta de gestión de paquetes de Python.
- Definir la tarea de extracciónInstrucciones de extracción: elabore instrucciones de extracción basadas en los requisitos, especifique el tipo de información que debe extraerse y prepare una pequeña cantidad de datos de muestra.
- modelo de configuraciónElija un modelo lingüístico adecuado, ya sea un modelo en la nube (por ejemplo, Google Gemini) o un modelo local (por ejemplo, a través de la aplicación Ollama (Interfaz).
- Escribir códigoFunción de extracción: escriba código utilizando la API proporcionada por LangExtract para cargar el modelo y llamar a la función de extracción.
- Extracción operativaLangExtract: Ejecute el código para realizar la operación de extracción en el texto de destino, LangExtract realizará la extracción de información de acuerdo con la tarea y el modelo definidos.
- Guardar resultadosGuardar los resultados de la extracción en un formato estructurado (por ejemplo, un archivo JSONL) para facilitar su procesamiento posterior.
- Generar informes de visualizaciónUtilice las herramientas proporcionadas por LangExtract para generar informes de visualización HTML interactivos que faciliten la visualización y validación de los resultados de la extracción.
- Optimización y ajuste: Ajuste las instrucciones de extracción o los parámetros del modelo para optimizar los resultados de extracción en función de la precisión y la exigencia de los resultados de extracción.
Puntos fuertes de LangExtract
- Posicionamiento preciso del texto originalPermite asignar con precisión cada extracción a su posición en el texto original, admite el resaltado visual y facilita la trazabilidad y la verificación.
- Adaptación flexible del modelo: Se admiten múltiples modelos lingüísticos, incluidos modelos en la nube (por ejemplo, Google Gemini) y modelos locales de código abierto (por ejemplo, a través de la interfaz Ollama), adaptándose a las necesidades de diferentes escenarios.
- Tratamiento optimizado de documentos largosOptimizado para documentos muy largos con el fin de mejorar la eficacia de la extracción y la recuperación mediante estrategias de fragmentación de texto, procesamiento paralelo y extracción multirronda.
- Visualización interactiva: Proporciona informes de visualización HTML interactivos generados con un solo clic, lo que facilita a los usuarios la visualización y revisión de los resultados de extracción en su contexto original.
- Salida estructurada eficienteLa imposición de un patrón de salida coherente basado en un pequeño número de ejemplos garantiza que los resultados de la extracción sean estructurados y sólidos.
- Gran adaptabilidad al terrenoDefinir tareas de extracción para cualquier dominio con sólo unos pocos ejemplos, sin ajustar el modelo, para una amplia gama de dominios como la sanidad, la literatura, las finanzas, etc.
Para quién es LangExtract
- Analista de datosLa necesidad de extraer información valiosa de grandes cantidades de datos textuales para el análisis de datos y la generación de informes.
- Profesionales de la industria médicapor ejemplo, médicos, enfermeros, investigadores médicos, para procesar textos médicos como notas clínicas, historiales médicos, etc.
- Profesionales del Derechopor ejemplo, abogados, personal jurídico, para analizar documentos jurídicos, contratos, etc. y extraer términos e información clave.
- Personal del sector financiero: por ejemplo, analistas financieros, gestores de riesgos, para procesar informes financieros y registros de transacciones.
- Investigadores universitarios: Los datos y las conclusiones deben extraerse de la literatura académica para la investigación y la síntesis.
- investigador literario: Se utiliza para analizar obras literarias y extraer información sobre personajes, argumento, temas, etc.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...