KAG: análisis en profundidad y tutoriales de instalación del marco de trabajo de la base de conocimientos de IA de código abierto de uso doméstico
Tutoriales prácticos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 101.7K 00

Hace poco descubrí un llamativo marco de base de conocimientos de IA de código abierto nacional: KAG (Knowledge Augmented Generation).
KAG Lanzado conjuntamente por Ant Group, la Universidad de Zhejiang y muchas otras organizaciones, se centra en la creación de bases de conocimiento en campos verticales. Los datos del documento muestran que la KAG en el campo de la administración electrónica alcanza el Impresionante índice de precisión de 91.6%también destaca en escenarios como la atención sanitaria electrónica de preguntas y respuestas.
Este artículo le llevará a conocer en profundidad KAG principio, escenarios de aplicación, comparar RAG El artículo también proporciona tutoriales de instalación local y demostraciones para ofrecerte una experiencia de inmersión en el marco KAG de código abierto de Ant. Si estás pensando en utilizar la IA para construir tu propia base de conocimientos, ¡no te puedes perder este artículo!
¿Qué es KAG? Conceptos básicos para una nueva generación de marcos de bases de conocimiento
KAG (Knowledge Augmented Generation) es un marco inferencial de preguntas y respuestas basado en el motor OpenSPG y en grandes modelos lingüísticos (LLM). Sus conceptos básicos sonCombinando las ventajas duales del grafo de conocimiento y la recuperación vectorial, pretende ofrecer a los usuarios un apoyo más riguroso a la toma de decisiones y unos servicios de recuperación de información más precisos.

KAG consigue una fusión profunda y una mejora de LLM y Knowledge Graph mediante las cuatro tecnologías clave siguientes:
- Conocimiento de la representación favorable al LLM: Optimizar la estructura de los grafos de conocimiento para facilitar su comprensión y explotación por parte de grandes modelos lingüísticos.
- Indexación cruzada entre grafos de conocimiento y fragmentos de texto originales: Establecer vínculos bidireccionales entre entidades y relaciones en el grafo de conocimiento y los fragmentos de texto originales para mejorar la eficacia y la precisión de la recuperación.
- Motor de razonamiento híbrido guiado por formas lógicasCombina el poder de razonamiento lógico del grafo de conocimiento con el poder de comprensión semántica del LLM para conseguir cuestionarios de razonamiento más complejos.
- Alineación de conocimientos con razonamiento semánticoEl objetivo es garantizar que el conocimiento en el grafo de conocimiento esté alineado con el espacio semántico del modelo lingüístico para mejorar la eficacia de la utilización del conocimiento.
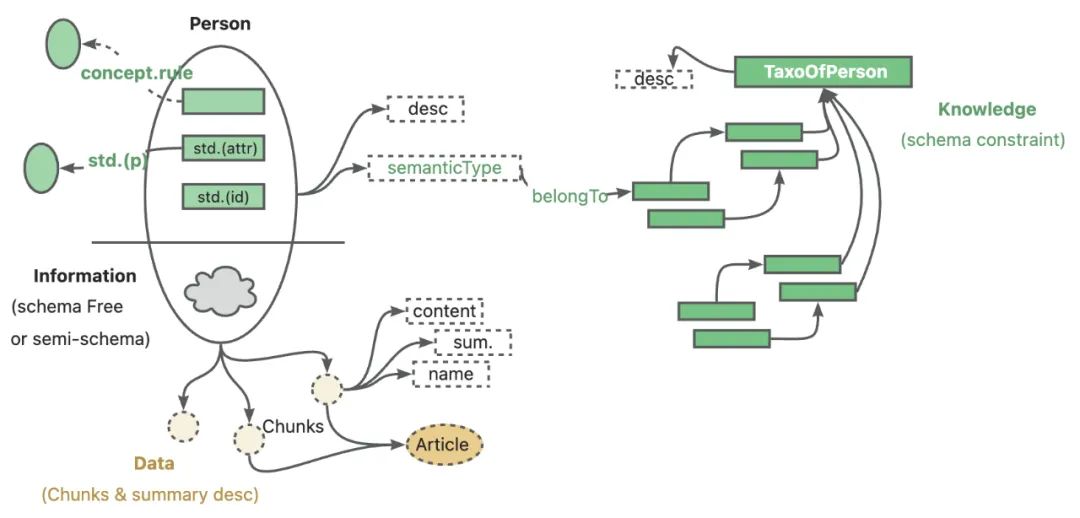
En resumen, KAG combina de forma innovadora las ventajas del grafo de conocimiento y la recuperación vectorial para construir un potente marco de base de conocimiento. No sólo puede utilizar la capacidad de razonamiento lógico de LLM, sino también combinarla con el grafo de conocimiento para profundizar en el razonamiento y completar tareas complejas de recuperación de información. Y lo que es más importante, cuando la información del grafo de conocimiento es insuficiente, KAG también puede utilizar inteligentemente la tecnología de recuperación vectorial para complementar los fragmentos de texto relevantes y garantizar la exhaustividad y precisión de las respuestas.
Arquitectura general de KAG
El marco KAG consta de dos módulos básicos: construcción de conocimientos (kg-builder) y resolución de problemas (kg-solver).
- kg-builder El módulo se centra en la construcción eficiente del conocimiento, optimizando la representación del conocimiento para LLM y apoyando el modelado flexible del conocimiento y la indexación bidireccional.
- kg-solver A continuación, el módulo se encarga de la resolución eficaz de problemas, lo que se consigue mediante un motor de razonamiento híbrido que integra múltiples capacidades, como la recuperación, el razonamiento gráfico, el razonamiento lingüístico y el cálculo numérico, para resolver problemas complejos.
- El tercer módulo, kag-model, será de código abierto para seguir mejorando el marco KAG.

KAG frente a RAG tradicional: diferencias y ventajas explicadas
RAG (Retrieval-Augmented Generation) ha sido ampliamente utilizada como tecnología común de bases de conocimiento. Entonces, ¿cuáles son las diferencias y ventajas de KAG sobre RAG? Las comparamos y analizamos a través de las siguientes dimensiones:
1. Representación del conocimiento:
- RAG. Se basa principalmente en la similitud vectorial para la recuperación, y la representación del conocimiento es relativamente simple, lo que dificulta el tratamiento de problemas complejos que requieren razonamiento multisalto.
- KAG. Adoptando una representación del conocimiento más amigable con LLM, compatible con el conocimiento sin esquema y con esquema restringido, que soporta la estructura inter-índice del conocimiento estructurado en grafos y el conocimiento textual, la representación del conocimiento es más rica y estructurada.
2. Capacidad de razonamiento:
- RAG. Insensibilidad a las relaciones lógicas de los conocimientos y falta de capacidad de razonamiento lógico para afrontar problemas en ámbitos especializados que requieren un razonamiento complejo.
- KAG. Introduce un motor de razonamiento híbrido guiado por símbolos lógicos con potentes funciones de razonamiento lógico y comprobación de hechos en varios saltos para tratar problemas profesionales más complejos.
3. Rendimiento:
- RAG. Su rendimiento es deficiente en las tareas multisalto y en las de pasaje cruzado, generando textos relativamente poco coherentes y lógicos.
- KAG. Obtiene buenos resultados en tareas multisalto y de paso cruzado, mejorando significativamente la precisión del razonamiento y la cobertura de la información, y generando respuestas más precisas y completas.
4. Escenarios aplicables:
- RAG. Es más adecuado para tareas generales de generación y recuperación de textos, pero su rendimiento será limitado en ámbitos especializados como el derecho, la medicina y la ciencia, donde se requiere un razonamiento complejo.
- KAG. Especialmente adecuado para aplicaciones que requieren un razonamiento complejo y cuestionarios factuales de varios saltos. Área de especializaciónLa empresa puede ofrecer servicios de conocimiento más profesionales y precisos, como asuntos financieros, médicos, jurídicos y gubernamentales.
En definitiva, al fusionar el grafo de conocimiento y la recuperación vectorial, y optimizar en profundidad la representación del conocimiento y las capacidades de razonamiento, KAG muestra potencial para superar a la tecnología RAG tradicional en el tratamiento de problemas complejos y el cuestionamiento de conocimientos específicos de un dominio.
Despliegue local de tutoriales "a nivel de alimentación": instalación de KAG, uso, efecto de la demostración
Los análisis teóricos deben probarse en la práctica. A continuación, te mostraré cómo instalar, desplegar y utilizar KAG localmente de forma manual, con una sencilla demostración de los resultados.
Recursos relacionados con KAG:
- Dirección de Github.https://github.com/OpenSPG/KAG
- Página web oficial.https://spg.openkg.cn/
Recomendaciones para la configuración del hardware:
- CPU ≥ 8 núcleos
- Memoria RAM ≥ 32 GB
- Disco duro ≥ 100 GB
La configuración oficial recomendada es alta, pero según mi prueba real, puede funcionar básicamente sin problemas en un PC Windows con 16 GB de RAM. Por lo tanto, este tutorial demostrará la instalación y el uso de KAG en un entorno Windows.
Paso 1: Instalar Docker Desktop
La instalación y despliegue de KAG se basa en un entorno Docker, así que asegúrese de tener instalado Docker Desktop en su ordenador.
Paso 2: Crear el archivo docker-compose.yml
- Crea una carpeta llamada KAG en el directorio raíz de la unidad D (u otro disco).
- Dentro de la carpeta KAG, crea un nuevo archivo llamado docker-compose.yml.
- Copia y pega el siguiente código YAML en el archivo docker-compose.yml y guárdalo.
version: "3.7"
services:
server:
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-server:latest
container_name: release-openspg-server
ports:
- "8887:8887"
depends_on:
- mysql
- neo4j
- minio
# volumes:
# - /etc/localtime:/etc/localtime:ro
environment:
TZ: Asia/Shanghai
LANG: C.UTF-8
command: [
"java",
"-Dfile.encoding=UTF-8",
"-Xms2048m",
"-Xmx8192m",
"-jar",
"arks-sofaboot-0.0.1-SNAPSHOT-executable.jar",
'--server.repository.impl.jdbc.host=mysql',
'--server.repository.impl.jdbc.password=openspg',
'--builder.model.execute.num=5',
'--cloudext.graphstore.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j',
'--cloudext.searchengine.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j'
]
mysql:
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-mysql:latest
container_name: release-openspg-mysql
volumes:
- mysql_data:/var/lib/mysql
environment:
TZ: Asia/Shanghai
LANG: C.UTF-8
MYSQL_ROOT_PASSWORD: openspg
MYSQL_DATABASE: openspg
ports:
- "3306:3306"
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_general_ci'
]
neo4j:
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-neo4j:latest
container_name: release-openspg-neo4j
ports:
- "7474:7474"
- "7687:7687"
environment:
- TZ=Asia/Shanghai
- NEO4J_AUTH=neo4j/neo4j@openspg
- NEO4J_PLUGINS=["apoc"]
- NEO4J_server_memory_heap_initial__size=1G
- NEO4J_server_memory_heap_max__size=4G
- NEO4J_server_memory_pagecache_size=1G
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_dbms_security_procedures_unrestricted=*
- NEO4J_dbms_security_procedures_allowlist=*
volumes:
- neo4j_logs:/logs
- neo4j_data:/data
minio:
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-minio:latest
container_name: release-openspg-minio
command: server --console-address ":9001" /data
restart: always
environment:
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio@openspg
TZ: Asia/Shanghai
ports:
- 9000:9000
- 9001:9001
volumes:
- minio_data:/data
volumes:
mysql_data:
neo4j_logs:
neo4j_data:
minio_data:
Paso 3: Iniciar el servicio KAG
- Abra un símbolo del sistema y cambie al directorio de la carpeta KAG (escriba cmd en el campo de dirección de la carpeta KAG e introduzca).
- Escriba docker-compose up -d en la línea de comandos e introduzca para iniciar la instalación y el despliegue automatizados de KAG.
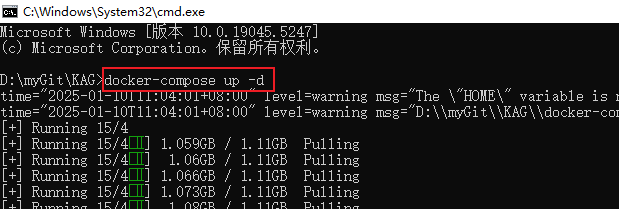
- Espere algún tiempo, cuando vea mysql, neo4j, openspg-server, minio cuatro servicios se muestran Creado o Iniciado estado, significa que el servicio KAG se ha iniciado correctamente.

Paso 4: Visite la página de administración del backend de KAG
- Abra su navegador e introduzca la dirección 127.0.0.1:8887 para acceder a la página de funcionamiento en segundo plano de KAG.
- Inicie sesión en el sistema utilizando el nombre de usuario por defecto openspg y la contraseña por defecto openspg@kag.

Paso 5: Configurar el sistema KAG
- Tras iniciar sesión, haga clic primero en el menú Configuración global.

- Configuración común: Realice la siguiente configuración
- Figura Configuración de almacenamiento
- base de datos:neo4j
- contraseña: neo4j@openspg
- uri:neo4j://liberar-openspg-neo4j:7687
- usuario:neo4j
- Cues en inglés y chino
- biz_scene: por defecto
- Idioma: zh
- configuración vectorial (informática) (utilizando la API gratuita de modelización vectorial)
- tipo: openai
- modelo: BAAI/bge-large-zh-v1.5
- base_url:https://api.siliconflow.cn/v1
- api_key: ir a Flujo basado en silicio para obtener una clave API gratuita.

- Flujo basado en silicio Tras registrarte e iniciar sesión en la plataforma, puedes encontrar el modelo vectorial gratuito y crear una clave API siguiendo las directrices de la siguiente imagen.


- Configuración del modelo: Click Añadir modelo maas (compatible con la interfaz openai)Configure el modelo de lengua grande que desea utilizar.
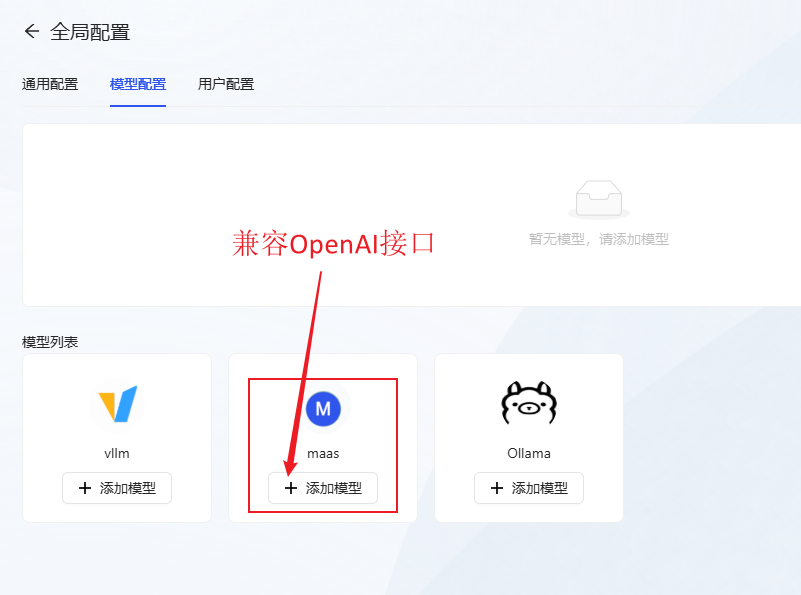
- Toma gpt-4o como ejemplo, rellena la información del modelo y pulsa OK para guardar.
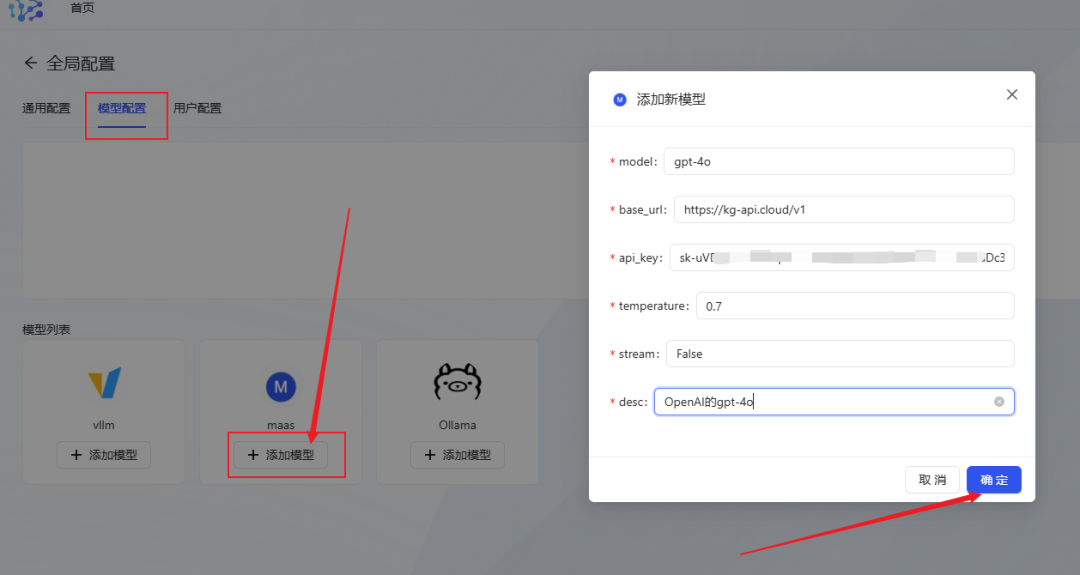
- Modelo de recomendación de estación repetidora APISi necesita una variedad de llamadas a la API de grandes modelos, puede utilizar el servicio de tránsito de API, que es compatible con la interfaz OpenAI, admite el cambio con un solo clic entre grandes modelos nacionales y extranjeros, y proporciona MJ, SD, y Suno y otras interfaces de dibujo y creación musical. El precio también es más favorable.
Paso 6: Crear una base de conocimientos e importar documentos
- Vuelva a la página de inicio y haga clic en Crear base de conocimientos.

- Asigne un nombre a la base de conocimientos y haga clic en Guardar.
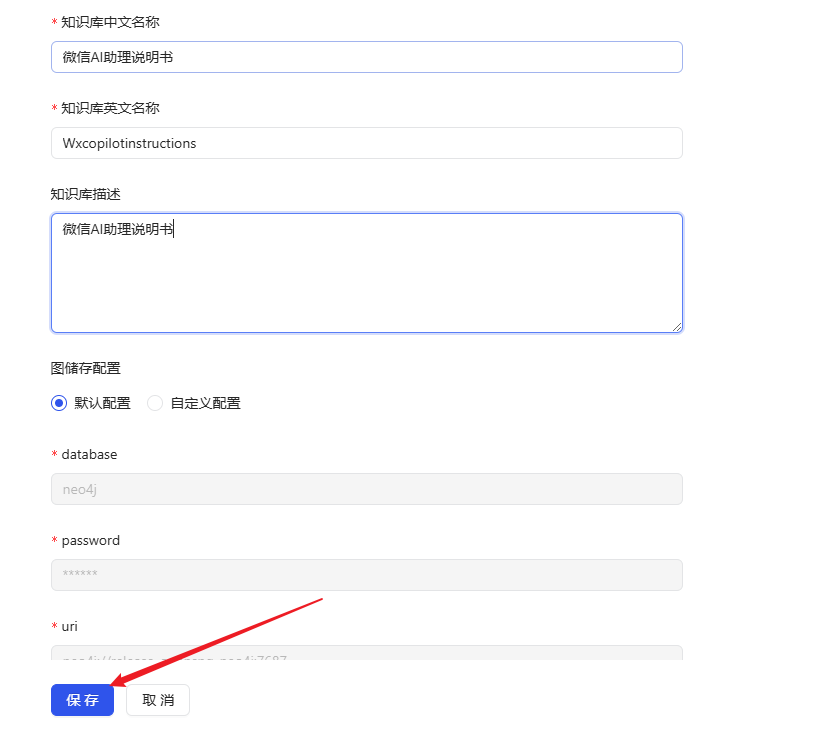
- Una vez creada, busque la base de conocimientos recién creada en la página de inicio y haga clic en Crear base de conocimientos.

- Haga clic en Crear tarea para comenzar a importar documentos.

- Sube tus documentos de la base de conocimientos (actualmente KAG sólo admite la carga de un documento a la vez, si tienes varios documentos tienes que subirlos por lotes). Aquí he subido documentos relacionados con mi último producto, WeChat AI Assistant.
- Convocatoria para compartir herramientas de fusión de archivosSi tienes una buena herramienta gratuita de fusión de archivos, compártela en la sección de comentarios para facilitar el procesamiento por lotes de documentos.

- En el siguiente paso de la configuración, se recomienda marcar la casilla para cortar párrafos según la semántica del documento con el fin de preservar la coherencia contextual de los párrafos.
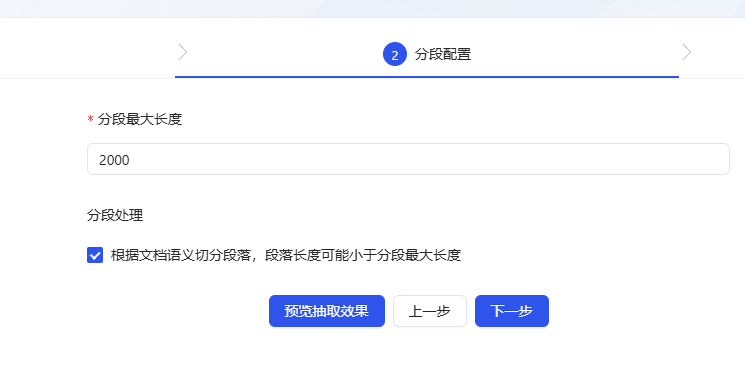
- modelo de extracción opción por defecto (la configuración por defecto está bien). pista Se puede personalizar según sea necesario, aquí simplemente lo puse en "Q&A Split" (la comprensión no siempre es exacta, bienvenido a corregirme).

- Haga clic en Finalizar y el KAG comenzará a extraer y analizar los documentos, un proceso que puede llevar algún tiempo.
- El proceso de análisis sintáctico de documentos se divide en 6 pasos, como se muestra en la siguiente figura:

- Espere a que el estado de la tarea cambie a Completado, lo que indica que el documento se ha importado correctamente en la Base de conocimientos. (Si el estado no se ha actualizado durante mucho tiempo, pruebe a actualizar la página).

Paso 7: Demostración
- Diagrama de correlación de extracción de conocimientosVisualización de las asociaciones de conocimiento extraídas por KAG del documento.

- Prueba de eficacia de preguntas y respuestas::
- Pregunta 1: "Presente brevemente el Asistente Personal Micro AI".
KAG realiza un proceso de pensamiento y razonamiento antes de recuperar y dar la respuesta. Se observa que las respuestas dadas por KAG son relativamente precisas y completas. Sin embargo, el tiempo de respuesta es lento, de unos 40 segundos (por lo que KAG puede no ser adecuado para escenarios sencillos de preguntas y respuestas).


- Pregunta 2: "¿Cómo configurar la clave secreta de AI Family Bucket para Personal Micro AI Assistant?"
KAG también puede dar una respuesta, pero aún tarda más.
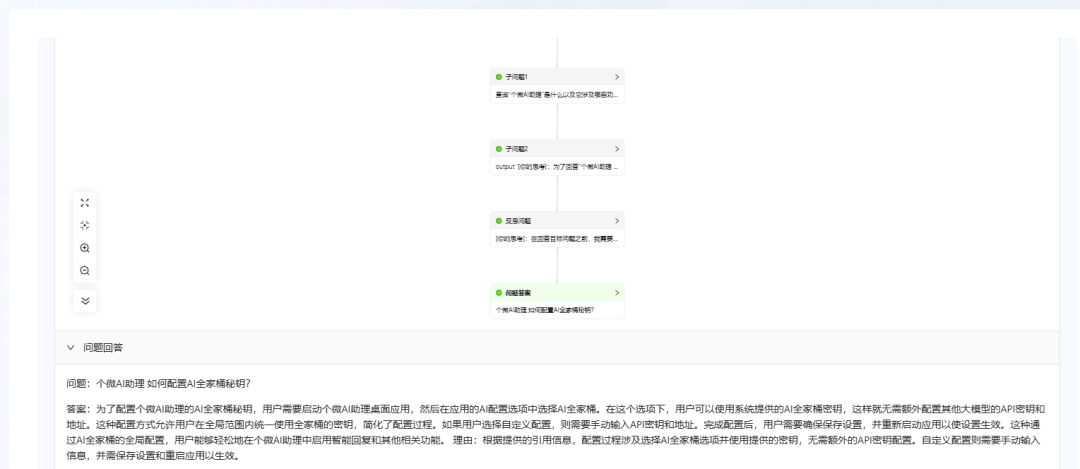
Resumen y perspectivas
A través de la experiencia anterior, podemos ver que la hormiga de código abierto KAG marco de base de conocimientos se encuentra todavía en la etapa de desarrollo rápido, algunas características y la experiencia del usuario está todavía por mejorar (como el ajuste de los parámetros de la base de conocimientos, la edición de la base de conocimientos y la modificación de la función no es perfecta, el uso de la utilización de algunos errores también pueden ser encontrados). Sin embargo, a partir de los registros de actualización de Github, el equipo de KAG está llevando a cabo activamente la iteración del código y la optimización funcional.
La dirección técnica de la KAG, que fusiona el grafo de conocimiento y la recuperación vectorial, es muy prometedora. Al igual que la tecnología RAG requiere datos de base de conocimiento de alta calidad, aumento del modelo y ajuste de los parámetros para obtener resultados óptimos, el desarrollo de KAG también requiere una mejora y optimización continuas.
Como se mencionaba al principio del artículo, KAG es más adecuado para campos especializados como la sanidad, las finanzas, el derecho, la administración pública, etc., que requieren un razonamiento complejo, en lugar de simples escenarios cotidianos de preguntas y respuestas (en los que la capacidad de respuesta es un defecto).
En la actualidad, KAG aún no ha abierto la API, y se espera que tras su apertura en el futuro, pueda integrarse en la aplicación del Agente, y mediante el mecanismo de identificación de problemas, se puedan derivar problemas simples y complejos para dar juego a las ventajas de KAG en el procesamiento de problemas complejos.
En definitiva, este artículo pretende darte una idea de la tecnología punta que es KAG. Aunque KAG puede no ser perfecto todavía, ha demostrado un gran potencial como marco de base de conocimiento de código abierto. Creemos que con los esfuerzos conjuntos de la comunidad y la continua iteración de la tecnología, KAG traerá más posibilidades al campo de las bases de conocimiento de IA.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...