

KAG: un marco profesional de preguntas y respuestas sobre bases de conocimiento para la recuperación híbrida de vectores y grafos de conocimiento
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 100.1K 00

Introducción general
KAG (Knowledge Augmented Generation) es un marco de recuperación y razonamiento lógico guiado por formas basado en el motor OpenSPG y en grandes modelos lingüísticos (LLM). El marco está diseñado específicamente para construir soluciones de razonamiento lógico y cuestionamiento de hechos para bases de conocimiento de dominio profesional, superando eficazmente las deficiencias del modelo tradicional de cálculo de similitud vectorial RAG (Retrieval Augmented Generation).KAG mejora los LLM y los grafos de conocimiento a través de las fortalezas complementarias de Knowledge Graph y Vector Retrieval de cuatro maneras en ambas direcciones: representaciones de conocimiento amigables con LLM, inter-indexación entre Knowledge Graphs y fragmentos de texto sin procesar, solucionador de razonamiento híbrido, y solucionador de razonamiento híbrido. indexación, solucionadores de inferencia híbridos y mecanismos de evaluación de la verosimilitud. El marco es especialmente adecuado para tratar problemas complejos de lógica del conocimiento, como el cálculo numérico, las relaciones temporales y las reglas expertas, proporcionando capacidades de respuesta a preguntas más precisas y fiables para aplicaciones de dominio profesional.

Lista de funciones
- Capacidad para fundamentar razonamientos lógicos complejos
- Proporcionar un mecanismo de búsqueda híbrido de grafos de conocimiento y recuperación vectorial
- Conversión de la representación del conocimiento para LLM
- Admite la indexación bidireccional de estructuras de conocimiento y bloques de texto
- Integración del razonamiento LLM, el razonamiento intelectual y el razonamiento lógico matemático
- Proporcionar mecanismos de evaluación y validación de la credibilidad
- Admite preguntas y respuestas multisalto y procesamiento de consultas complejas
- Proporcionar soluciones personalizadas para bases de conocimiento especializadas
Utilizar la ayuda
1. Preparación medioambiental
Lo primero que tienes que hacer es asegurarte de que tu sistema cumple los siguientes requisitos:
- Python 3.8 o superior
- Entorno del motor OpenSPG
- Interfaces API compatibles con grandes modelos lingüísticos
2. Pasos de la instalación
- Almacén de proyectos de clonación:
git clone https://github.com/OpenSPG/KAG.git
cd KAG
- Instale los paquetes de dependencia:
pip install -r requirements.txt
3. Proceso de utilización del marco
3.1 Preparación de la base de conocimientos
- Importación de datos de conocimientos especializados
- Configuración del modelo de grafos de conocimiento
- Creación de un sistema de indexación de textos
3.2 Tratamiento de las consultas
- Entrada de preguntas: el sistema recibe preguntas en lenguaje natural del usuario.
- Conversión de formas lógicas: conversión de problemas en expresiones lógicas normalizadas.
- Recuperación mixta:
- Realizar búsquedas en el grafo de conocimiento
- Realizar una búsqueda de similitud vectorial
- Integración de los resultados de búsqueda
3.3 Proceso de razonamiento
- Razonamiento lógico: Razonamiento en varios pasos con solucionadores de razonamiento mixto
- Fusión de conocimientos: combinación de los resultados del razonamiento LLM y del razonamiento de grafos de conocimiento
- Generación de respuestas: formación de la respuesta final
3.4 Garantía de credibilidad
- Verificación de respuestas
- Trazado de rutas de razonamiento
- evaluación de la confianza (matemáticas)
4. Utilización de funciones avanzadas
4.1 Representación personalizada del conocimiento
El formato de representación del conocimiento puede personalizarse en función de las necesidades de su área de especialización, garantizando la compatibilidad con LLM:
# 示例代码
knowledge_config = {
"domain": "your_domain",
"schema": your_schema_definition,
"representation": your_custom_representation
}
4.2 Configuración de las reglas de razonamiento
Se pueden configurar reglas de inferencia especializadas para manejar la lógica específica del dominio:
# 示例代码
reasoning_rules = {
"numerical": numerical_processing_rules,
"temporal": temporal_reasoning_rules,
"domain_specific": your_domain_rules
}
5. Buenas prácticas
- Garantizar la calidad e integridad de los datos de la base de conocimientos
- Optimizar las estrategias de búsqueda para mejorar la eficacia
- Actualización y mantenimiento periódicos de la base de conocimientos
- Supervisar el rendimiento y la precisión del sistema
- Recoger las opiniones de los usuarios para mejorar continuamente
6. Resolución de problemas comunes
- Si encuentra problemas de eficacia en la recuperación, puede ajustar los parámetros del índice adecuadamente
- Para consultas complejas, puede utilizarse una estrategia de razonamiento por etapas
- Compruebe la representación del conocimiento y la configuración de las reglas cuando los resultados de la inferencia sean imprecisos.
Presentación del proyecto KAG
1. Introducción
Hace unos días, Ant lanzó oficialmente un marco de servicio de conocimiento de dominio profesional, llamado Knowledge Augmented Generation (KAG: Generación Aumentada de Conocimiento), que pretende aprovechar al máximo las ventajas de Knowledge Graph y Vector Retrieval para resolver el problema de la existente RAG Algunos retos con la pila tecnológica.
De las hormigas de este marco de calentamiento, he estado más interesado en algunas de las funciones básicas de KAG, especialmente el razonamiento simbólico lógico y la alineación de los conocimientos, en la corriente principal existente RAG sistema, estos dos puntos de discusión no parece ser demasiado, aprovechar esta fuente abierta, y se apresuran a estudiar una ola.
- Dirección de la tesis KAG: https://arxiv.org/pdf/2409.13731
- Dirección del proyecto KAG: https://github.com/OpenSPG/KAG
2. Visión general del marco
Antes de leer el código, echemos un breve vistazo a los objetivos y el posicionamiento del framework.
2.1 ¿Qué y por qué?
De hecho, cuando veo el marco KAG, creo que la primera pregunta que le viene a la mente a mucha gente es por qué no se llama RAG sino KAG. Según los artículos y documentos relacionados, el marco KAG está diseñado principalmente para resolver algunos de los retos actuales a los que se enfrentan los grandes modelos en los servicios de conocimiento de dominio profesional:
- LLM no tiene capacidad de pensamiento crítico y carece de capacidad de razonamiento
- Errores de hecho, lógica, precisión, incapacidad de utilizar estructuras de conocimiento del dominio predefinidas para restringir el comportamiento del modelo.
- Las GAR genéricas también tienen dificultades para abordar las ilusiones del LLM, especialmente la información engañosa encubierta
- Retos y requisitos de los servicios de expertos, falta de un proceso de toma de decisiones riguroso y controlado
Por ello, el equipo de Ant considera que un marco profesional de servicios del conocimiento debe reunir las siguientes características:
- Es importante garantizar la exactitud de los conocimientos, incluida la integridad de sus límites y la claridad de su estructura y semántica;
- Se requiere rigor lógico, sensibilidad temporal y sensibilidad numérica;
- También se necesita información contextual completa para facilitar el acceso a información de apoyo completa a la hora de tomar decisiones basadas en el conocimiento;
El posicionamiento oficial de KAG por parte de Ant es: Professional Domain Knowledge Augmentation Service Framework, específicamente para la combinación actual de grandes modelos lingüísticos y grafos de conocimiento para mejorar las cinco áreas siguientes
- Mayor conocimiento de la facilidad de acceso al LLM
- Estructura de interindexación entre grafos de conocimiento y fragmentos de texto originales
- Motor de razonamiento híbrido guiado por símbolos lógicos
- Mecanismo de alineación de conocimientos basado en el razonamiento semántico
- Modelo KAG
Esta versión de código abierto cubre las cuatro primeras funciones básicas en su totalidad.
Volviendo a la cuestión de la denominación de KAG, personalmente especulo que todavía puede ser para fortalecer el concepto de ontología del conocimiento. Desde la descripción oficial y la implementación real del código, el marco KAG, ya sea en la etapa de construcción o de razonamiento, están constantemente haciendo hincapié desde el propio conocimiento, para construir un enlace lógico completo y riguroso, con el fin de mejorar algunos de los problemas conocidos de la pila de tecnología RAG tanto como sea posible.
2.2 ¿Qué (cómo) se está consiguiendo?
El marco KAG consta de tres partes: KAG-Builder, KAG-Solver y KAG-Model:
- KAG-Builder se utiliza para la indexación fuera de línea e incluye las características 1 y 2 mencionadas anteriormente: mejora de la representación del conocimiento, estructura de indexación mutua.
- El módulo KAG-Solver cubre las características 3 y 4: motor de razonamiento híbrido lógico-simbólico, mecanismo de alineación del conocimiento.
- KAG-Model, por su parte, intenta construir un modelo KAG de extremo a extremo.
3. Análisis del código fuente
Este código abierto incluye principalmente dos módulos, KAG-Builder y KAG-Solver, que corresponden directamente al código fuente de los dos subdirectorios builder y solver.
Durante el estudio propiamente dicho del código, se recomienda empezar por el examples Lo primero que hay que hacer es empezar por un directorio para entender el flujo de todo el framework, y luego profundizar en módulos específicos. Las rutas a los archivos de entrada de varias demos son similares, como por ejemplo kag/examples/medicine/builder/indexer.py demasiado kag/examples/medicine/solver/evaForMedicine.pyEstá claro que el constructor combina diferentes módulos, mientras que el verdadero punto de entrada para el solucionador se encuentra en el módulo kag/solver/logic/solver_pipeline.py.
3.1 Constructor KAG
Publiquemos primero la estructura completa del catálogo
❯ tree .
.
├── __init__.py
├── component
│ ├── __init__.py
│ ├── aligner
│ │ ├── __init__.py
│ │ ├── kag_post_processor.py
│ │ └── spg_post_processor.py
│ ├── base.py
│ ├── extractor
│ │ ├── __init__.py
│ │ ├── kag_extractor.py
│ │ ├── spg_extractor.py
│ │ └── user_defined_extractor.py
│ ├── mapping
│ │ ├── __init__.py
│ │ ├── relation_mapping.py
│ │ ├── spg_type_mapping.py
│ │ └── spo_mapping.py
│ ├── reader
│ │ ├── __init__.py
│ │ ├── csv_reader.py
│ │ ├── dataset_reader.py
│ │ ├── docx_reader.py
│ │ ├── json_reader.py
│ │ ├── markdown_reader.py
│ │ ├── pdf_reader.py
│ │ ├── txt_reader.py
│ │ └── yuque_reader.py
│ ├── splitter
│ │ ├── __init__.py
│ │ ├── base_table_splitter.py
│ │ ├── length_splitter.py
│ │ ├── outline_splitter.py
│ │ ├── pattern_splitter.py
│ │ └── semantic_splitter.py
│ ├── vectorizer
│ │ ├── __init__.py
│ │ └── batch_vectorizer.py
│ └── writer
│ ├── __init__.py
│ └── kg_writer.py
├── default_chain.py
├── model
│ ├── __init__.py
│ ├── chunk.py
│ ├── spg_record.py
│ └── sub_graph.py
├── operator
│ ├── __init__.py
│ └── base.py
└── prompt
├── __init__.py
├── analyze_table_prompt.py
├── default
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── medical
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── oneke_prompt.py
├── outline_prompt.py
├── semantic_seg_prompt.py
└── spg_prompt.py
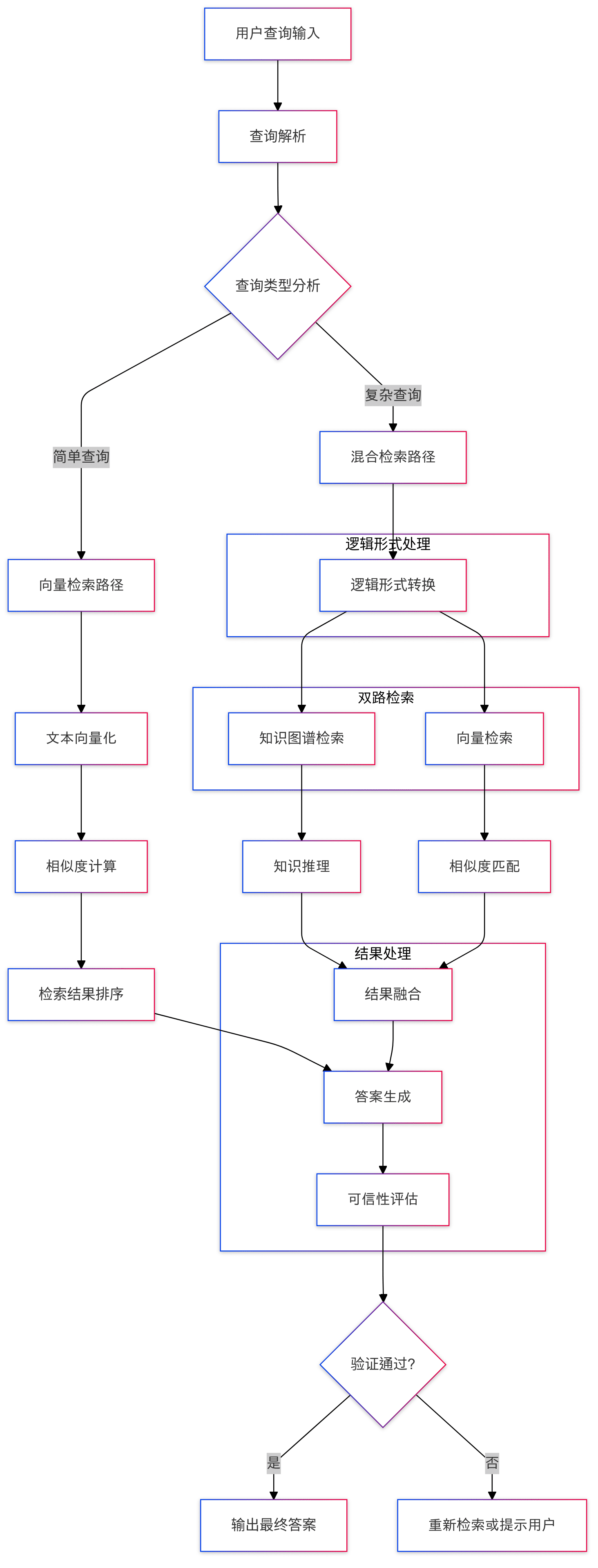
La sección Constructor cubre una amplia gama de funcionalidades, por lo que aquí sólo veremos uno de los componentes más críticos. KAGExtractor A continuación se muestra el diagrama de flujo básico:

Lo principal que se hace aquí es la creación automática de un grafo de conocimiento a partir de texto no estructurado a conocimiento estructurado utilizando un gran modelo, con una breve descripción de algunos de los pasos importantes implicados.
- En primer lugar, está el módulo de reconocimiento de entidades, en el que se realizará primero el reconocimiento de entidades específicas para tipos de grafos de conocimiento predefinidos, seguido del reconocimiento de entidades genéricas con nombre. Este mecanismo de identificación a dos niveles debería garantizar que se capturan tanto las entidades específicas del dominio como las genéricas.
- En realidad, el proceso de construcción de la cartografía lo lleva a cabo el
assemble_sub_graph_with_spg_recordsy tiene la particularidad de que el sistema convierte los atributos de tipo no básico en nodos y aristas del grafo, en lugar de seguir manteniéndolos como atributos originales de la entidad. Honestamente, este cambio no se entiende muy bien, y hasta cierto punto se supone que simplifica la complejidad de la entidad, pero en la práctica no está muy claro cuánto beneficio aporta esta estrategia, la complejidad de la construcción ha aumentado definitivamente. - Normalización de entidades mediante
named_entity_standardizationresponder cantandoappend_official_nameLos dos enfoques se realizan conjuntamente. En primer lugar, se normalizan los nombres de las entidades y, a continuación, estos nombres normalizados se asocian a la información original de la entidad. Este proceso es similar a la resolución de entidades.
En general, la funcionalidad del módulo Builder es bastante parecida a la actual pila tecnológica común de construcción de gráficos, y los artículos y el código relacionados no son demasiado difíciles de entender, por lo que no los repetiré aquí.
3.2 Solucionador KAG
Solver parte del marco implica una gran cantidad de puntos funcionales básicos, especialmente la lógica del razonamiento simbólico relacionados con el contenido, primero mira la estructura general:
❯ tree .
.
├── __init__.py
├── common
│ ├── __init__.py
│ └── base.py
├── implementation
│ ├── __init__.py
│ ├── default_generator.py
│ ├── default_kg_retrieval.py
│ ├── default_lf_planner.py
│ ├── default_memory.py
│ ├── default_reasoner.py
│ ├── default_reflector.py
│ └── lf_chunk_retriever.py
├── logic
│ ├── __init__.py
│ ├── core_modules
│ │ ├── __init__.py
│ │ ├── common
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── one_hop_graph.py
│ │ │ ├── schema_utils.py
│ │ │ ├── text_sim_by_vector.py
│ │ │ └── utils.py
│ │ ├── config.py
│ │ ├── lf_executor.py
│ │ ├── lf_generator.py
│ │ ├── lf_solver.py
│ │ ├── op_executor
│ │ │ ├── __init__.py
│ │ │ ├── op_deduce
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deduce_executor.py
│ │ │ │ └── module
│ │ │ │ ├── __init__.py
│ │ │ │ ├── choice.py
│ │ │ │ ├── entailment.py
│ │ │ │ ├── judgement.py
│ │ │ │ └── multi_choice.py
│ │ │ ├── op_executor.py
│ │ │ ├── op_math
│ │ │ │ ├── __init__.py
│ │ │ │ └── math_executor.py
│ │ │ ├── op_output
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── get_executor.py
│ │ │ │ └── output_executor.py
│ │ │ ├── op_retrieval
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── get_spo_executor.py
│ │ │ │ │ └── search_s.py
│ │ │ │ └── retrieval_executor.py
│ │ │ └── op_sort
│ │ │ ├── __init__.py
│ │ │ └── sort_executor.py
│ │ ├── parser
│ │ │ ├── __init__.py
│ │ │ └── logic_node_parser.py
│ │ ├── retriver
│ │ │ ├── __init__.py
│ │ │ ├── entity_linker.py
│ │ │ ├── graph_retriver
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dsl_executor.py
│ │ │ │ └── dsl_model.py
│ │ │ ├── retrieval_spo.py
│ │ │ └── schema_std.py
│ │ └── rule_runner
│ │ ├── __init__.py
│ │ └── rule_runner.py
│ └── solver_pipeline.py
├── main_solver.py
├── prompt
│ ├── __init__.py
│ ├── default
│ │ ├── __init__.py
│ │ ├── deduce_choice.py
│ │ ├── deduce_entail.py
│ │ ├── deduce_judge.py
│ │ ├── deduce_multi_choice.py
│ │ ├── logic_form_plan.py
│ │ ├── question_ner.py
│ │ ├── resp_extractor.py
│ │ ├── resp_generator.py
│ │ ├── resp_judge.py
│ │ ├── resp_reflector.py
│ │ ├── resp_verifier.py
│ │ ├── solve_question.py
│ │ ├── solve_question_without_docs.py
│ │ ├── solve_question_without_spo.py
│ │ └── spo_retrieval.py
│ ├── lawbench
│ │ ├── __init__.py
│ │ └── logic_form_plan.py
│ └── medical
│ ├── __init__.py
│ └── question_ner.py
└── tools
├── __init__.py
└── info_processor.py
Ya he mencionado antes el archivo de entrada del solucionador, así que publicaré aquí el código correspondiente:
class SolverPipeline:
def __init__(self, max_run=3, reflector: KagReflectorABC = None, reasoner: KagReasonerABC = None,
generator: KAGGeneratorABC = None, **kwargs):
"""
Initializes the think-and-act loop class.
:param max_run: Maximum number of runs to limit the thinking and acting loop, defaults to 3.
:param reflector: Reflector instance for reflect tasks.
:param reasoner: Reasoner instance for reasoning about tasks.
:param generator: Generator instance for generating actions.
"""
self.max_run = max_run
self.memory = DefaultMemory(**kwargs)
self.reflector = reflector or DefaultReflector(**kwargs)
self.reasoner = reasoner or DefaultReasoner(**kwargs)
self.generator = generator or DefaultGenerator(**kwargs)
self.trace_log = []
def run(self, question):
"""
Executes the core logic of the problem-solving system.
Parameters:
- question (str): The question to be answered.
Returns:
- tuple: answer, trace log
"""
instruction = question
if_finished = False
logger.debug('input instruction:{}'.format(instruction))
present_instruction = instruction
run_cnt = 0
while not if_finished and run_cnt < self.max_run:
run_cnt += 1
logger.debug('present_instruction is:{}'.format(present_instruction))
# Attempt to solve the current instruction and get the answer, supporting facts, and history log
solved_answer, supporting_fact, history_log = self.reasoner.reason(present_instruction)
# Extract evidence from supporting facts
self.memory.save_memory(solved_answer, supporting_fact, instruction)
history_log['present_instruction'] = present_instruction
history_log['present_memory'] = self.memory.serialize_memory()
self.trace_log.append(history_log)
# Reflect the current instruction based on the current memory and instruction
if_finished, present_instruction = self.reflector.reflect_query(self.memory, present_instruction)
response = self.generator.generate(instruction, self.memory)
return response, self.trace_log
total SolverPipeline.run() La metodología consta de 3 módulos principales:Reasoner, Reflector responder cantando GeneratorLa lógica general sigue siendo muy clara: primero se intenta responder a la pregunta, luego se reflexiona sobre si se ha resuelto el problema y, si no, se sigue pensando en profundidad hasta obtener una respuesta satisfactoria o alcanzar el número máximo de intentos. Básicamente, imita la forma general de pensar de los seres humanos a la hora de resolver problemas complejos.
En la sección siguiente se analizan con más detalle los tres módulos mencionados.
3.3 Razonador
El módulo de inferencia es probablemente la parte más compleja de todo el marco, y su código clave es el siguiente:
class DefaultReasoner(KagReasonerABC):
def __init__(self, lf_planner: LFPlannerABC = None, lf_solver: LFSolver = None, **kwargs):
def reason(self, question: str):
"""
Processes a given question by planning and executing logical forms to derive an answer.
Parameters:
- question (str): The input question to be processed.
Returns:
- solved_answer: The final answer derived from solving the logical forms.
- supporting_fact: Supporting facts gathered during the reasoning process.
- history_log: A dictionary containing the history of QA pairs and re-ranked documents.
"""
# logic form planing
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
# logic form execution
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
# Generate supporting facts for sub question-answer pair
supporting_fact = '\n'.join(sub_qa_pair)
# Retrieve and rank documents
sub_querys = [lf.query for lf in lf_nodes]
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs([question] + sub_querys, recall_docs)
else:
logger.info("DefaultReasoner not enable chunk retriever")
docs = []
history_log = {
'history': history_qa_log,
'rerank_docs': docs
}
if len(docs) > 0:
# Append supporting facts for retrieved chunks
supporting_fact += f"\nPassages:{str(docs)}"
return solved_answer, supporting_fact, history_log
Esto da como resultado un diagrama de flujo general del módulo de razonamiento: (se ha omitido la lógica como el tratamiento de errores)

Es fácil ver queDefaultReasoner.reason() La metodología se divide a grandes rasgos en tres etapas:
- Planificación lógico-formal (PLF): consiste principalmente en
LFPlanner.lf_planing - Ejecución de la forma lógica (LFE): implica principalmente
LFSolver.solve - Recalificación de documentos: consiste principalmente en
LFSolver.chunk_retriever.rerank_docs
A continuación se analiza detalladamente cada uno de los tres pasos.
3.3.1 Planificación lógica de formularios
DefaultLFPlanner.lf_planing() se utiliza principalmente para descomponer una consulta en una serie de formas lógicas independientes (lf_nodes: List[LFPlanResult]).
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
La lógica de aplicación se encuentra en kag/solver/implementation/default_lf_planner.pyLa atención se centra en llm_output Realiza un análisis sintáctico regularizado, o llama a LLM para generar una nueva forma lógica si no se proporciona.
Aquí hay algo que no hay que perder de vista kag/solver/prompt/default/logic_form_plan.py asuntos pertinentes LogicFormPlanPrompt El diseño detallado del proyecto se centra en cómo descomponer un problema complejo en múltiples subconsultas y sus correspondientes formas lógicas.
3.3.2 Ejecución de formularios lógicos
LFSolver.solve() Los métodos se utilizan para resolver problemas específicos de forma lógica, devolviendo respuestas, pares de respuestas de subproblemas, documentos de recuerdo asociados e historial, etc.
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
en profundidadkag/solver/logic/core_modules/lf_solver.pyLa sección de código fuente, que se puede encontrar LFSolver La clase (Logical Form Solver) es la clase central de todo el proceso de razonamiento y es responsable de ejecutar la forma lógica (LF) y generar la respuesta:
- Los principales métodos son
solveque recibe una consulta y un conjunto de nodos de forma lógica (List[LFPlanResult]). - utilizar
LogicExecutorpara realizar formularios lógicos que generen respuestas, rutas del grafo del conocimiento e historiales. - Procesa subconsultas y pares de respuestas, así como la documentación relacionada.
- Tratamiento de errores y estrategia alternativa: si no se encuentra una respuesta o la documentación pertinente, se intenta utilizar la función
chunk_retrieverRecuperar documentos relacionados.
Los principales procesos son los siguientes:

incluidos entre estos LogicExecutor es una de las clases más críticas, así que aquí está el código principal:
executor = LogicExecutor(
query, self.project_id, self.schema,
kg_retriever=self.kg_retriever,
chunk_retriever=self.chunk_retriever,
std_schema=self.std_schema,
el=self.el,
text_similarity=self.text_similarity,
dsl_runner=DslRunnerOnGraphStore(...),
generator=self.generator,
report_tool=self.report_tool,
req_id=generate_random_string(10)
)
kg_qa_result, kg_graph, history = executor.execute(lf_nodes, query)
- lógica de aplicación
LogicExecutorEl código correspondiente a la clase se encuentra en la secciónkag/solver/logic/core_modules/lf_executor.py. suexecuteA continuación se muestra el flujo de ejecución principal del método.
Este flujo de ejecución demuestra una estrategia de recuperación dual: dar prioridad al uso de datos de grafos estructurados para la recuperación y la inferencia, y recurrir a la recuperación de información textual no estructurada cuando el grafo no tiene respuesta.
En primer lugar, el sistema intenta responder a la pregunta a través del grafo de conocimiento, para cada nodo de expresión lógica, por medio de diferentes actuadores (que implican eldeduceymathysortyretrievalyoutputetc.), y el proceso de recuperación recopila triples SPO (sujeto-predicado-objeto) para la posterior generación de respuestas; cuando el gráfico no proporciona una respuesta satisfactoria (devolviendo "no lo sé"), el sistema vuelve a la recuperación de bloques de texto: utilizando los resultados de entidades con nombre (NER) obtenidos previamente como punto de anclaje de la recuperación, y combinándolos con los registros históricos de preguntas y respuestas para construir una consulta mejorada por el contexto, que se pasa a continuación por elchunk_retrieverVuelva a generar la respuesta basándose en el documento recuperado.
Todo el proceso puede considerarse una elegante estrategia de degradación, y al combinar grafos de conocimiento estructurados con datos textuales no estructurados, esta recuperación híbrida es capaz de proporcionar respuestas lo más completas y contextualmente coherentes posible, manteniendo la precisión. - componente básico
Además de la lógica de aplicación específica descrita anteriormente, tenga en cuenta que la funciónLogicExecutorLa inicialización requiere pasar varios componentes. Limitado al espacio, aquí es sólo una breve descripción de la función central de cada componente, la implementación específica puede referirse al código fuente.- kg_retriever: Recuperador de grafos de conocimiento
consultakag/solver/implementation/default_kg_retrieval.pymedioKGRetrieverByLlm(KGRetrieverABC)que implementa la recuperación de entidades y relaciones, implicando múltiples métodos de correspondencia como el exacto/fuzzy y los subgrafos de un salto. - chunk_retriever: recuperador de trozos de texto
consultakag/common/retriever/kag_retriever.pymedioDefaultRetriever(ChunkRetrieverABC)El código aquí es digno de estudio, en primer lugar, está estandarizado en términos de procesamiento de Entidades, y además, la recuperación aquí se refiere a HippoRAG, adoptando una estrategia de recuperación híbrida que combina DPR (Dense Passage Retrieval) y PPR (Personalized PageRank), y posteriormente se basa en la fusión de DPR y PPR Score. Además, aquí se adopta una estrategia de recuperación híbrida que combina DPR (Dense Passage Retrieval) y PPR (Personalised PageRank), y la posterior fusión de las puntuaciones basadas en DPR y PPR consigue además la asignación dinámica de pesos de los dos métodos de recuperación. - entity_linker (el): enlazador de entidades
consultakag/solver/logic/core_modules/retriver/entity_linker.pymedioDefaultEntityLinker(EntityLinkerBase)Aquí se utiliza la idea de construir características antes de paralelizar el procesamiento de los enlaces de entidades. - dsl_runner: consultor de bases de datos gráficas
consultakag/solver/logic/core_modules/retriver/graph_retriver/dsl_executor.pymedioDslRunnerOnGraphStore(DslRunner)responsable de la información de consulta estructurada en una declaración de consulta de base de datos gráfica específica, esta pieza implicará la base de datos gráfica específica subyacente, los detalles son relativamente complejos, pero no demasiado involucrados.
- kg_retriever: Recuperador de grafos de conocimiento
Repasando el código y el diagrama de flujo anteriores, puede verse que todo el bucle de ejecución de formularios lógicos (LFE) adopta una arquitectura de procesamiento jerárquica:
- la cima de un edificio
LFSolverResponsable del proceso global - mesosfera
LogicExecutorResponsable de la aplicación de formas lógicas específicas (LF) - fondo (de un montón)
DSL RunnerResponsable de interactuar con la base de datos gráfica
3.3.3 Recalificación de documentos
Si el chunk_retrievertambién reordenará los documentos retirados.
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs(
[question] + sub_querys, recall_docs
)
3.4 Reflector
Reflector implementa principalmente la clase _can_answer junto con _refine_query Dos métodos, el primero para determinar si se puede responder a una pregunta y el segundo para optimizar los resultados intermedios de una consulta multisalto para guiar la generación de la respuesta final.
Referencias de aplicación relacionadas kag/solver/prompt/default/resp_judge.py junto con kag/solver/prompt/default/resp_reflector.py Estos dos archivos Prompt son más fáciles de entender.
3,5 Generador
grapa LFGenerator selecciona dinámicamente plantillas de palabras de consulta en función de distintos escenarios (con o sin gráficos de conocimiento, con o sin documentos, etc.) y genera respuestas a las preguntas correspondientes.
Las implementaciones pertinentes se encuentran en kag/solver/logic/core_modules/lf_generator.pyEl código es relativamente intuitivo y no se repetirá.
4. Algunas reflexiones
Ant este marco KAG de código abierto, centrándose en los servicios de mejora de los conocimientos de dominio profesional, que abarca el razonamiento simbólico, la alineación de los conocimientos y una serie de puntos innovadores, estudio exhaustivo, siento que el marco es especialmente adecuado para la necesidad de estrictas restricciones en el esquema de los conocimientos profesionales del escenario, ya sea en la etapa de indexación o consulta, todo el flujo de trabajo se refuerza repetidamente un punto de vista: debe ser a partir de las limitaciones de la base de conocimientos, para construir el gráficos o hacer razonamientos lógicos. Esta mentalidad debería aliviar en cierta medida el problema de la falta de conocimiento del dominio, así como la ilusión de los grandes modelos.
Desde que el marco GraphRAG de Microsoft es de código abierto, la comunidad ha reflexionado más sobre la integración de los grafos de conocimiento y la pila tecnológica de GraphRAG, como los recientes trabajos de LightRAG, StructRAG, etc., que han realizado una gran cantidad de exploraciones útiles.KAG, aunque existen algunas diferencias entre la ruta técnica y GraphRAG, puede considerarse hasta cierto punto como una práctica en la dirección de los servicios de mejora del conocimiento en el dominio profesional de GraphRAG, especialmente para compensar las deficiencias en la alineación del conocimiento y el razonamiento. Aunque existen algunas diferencias entre KAG y GraphRAG en términos de tecnología, KAG puede considerarse una práctica de GraphRAG en la dirección de los servicios de mejora del conocimiento en dominios profesionales, especialmente para compensar las deficiencias en la alineación del conocimiento y el razonamiento. Desde esta perspectiva, personalmente prefiero llamarlo GraphRAG restringido al conocimiento.
El GraphRAG nativo, con un resumen jerárquico basado en diferentes comunidades, puede responder a preguntas de alto nivel relativamente abstractas, pero también debido a su excesivo enfoque en el resumen centrado en consultas (QFS), el marco puede no funcionar bien en preguntas factuales de grano fino, y teniendo en cuenta la cuestión del coste, el GraphRAG nativo tiene muchos retos en el dominio pendiente. GraphRAG tiene muchos retos en el dominio pendiente, mientras que el marco KAG ha realizado más optimizaciones desde la etapa de construcción del grafo, como la alineación de Entidades y las operaciones de estandarización basadas en Esquemas específicos, y en la etapa de consulta, también introduce el razonamiento de grafos de conocimiento basado en la lógica simbólica, aunque el razonamiento simbólico se ha investigado en el campo de los grafos durante bastante tiempo, aunque todavía no se ha aplicado realmente a escenarios RAG. El refuerzo de la capacidad de razonamiento RAG es una dirección de investigación sobre la que el autor se muestra más optimista, y hace algún tiempo Microsoft resumió las cuatro capas de capacidad de razonamiento de la pila tecnológica RAG:
- Hechos explícitos de nivel 1, Hechos explícitos
- Nivel 2 Hechos implícitos, hechos ocultos
- Razonamientos interpretables de nivel 3, Razonamientos interpretables (colgantes)
- Fundamentos ocultos de nivel 4, fundamentos invisibles (dominio colgante)
En la actualidad, la capacidad de razonamiento de la mayoría de los marcos RAG se limita todavía al nivel 1, y los niveles superiores de nivel 3 y 4 subrayan la importancia del razonamiento vertical, y la dificultad radica en la falta de conocimiento de grandes modelos en el dominio vertical, y la introducción del razonamiento simbólico en la fase de consulta del marco KAG puede considerarse hasta cierto punto una exploración de esta dirección, y cabe prever que en los próximos años se lleve a cabo una oleada de nuevas investigaciones en el ámbito del razonamiento RAG. Es previsible que el razonamiento RAG desencadene una nueva ola de investigación, como una mayor fusión de la capacidad de razonamiento propia del modelo, como RL o CoT, etc. En esta fase, se han hecho algunos intentos en la escena aterrizando todavía hay más o menos limitaciones.
Además de la sesión de razonamiento, las referencias del KAG en Recuperación HippoRAG La adopción de una estrategia híbrida de recuperación DPR y PPR y el uso eficiente de PageRank demuestran las ventajas de los grafos de conocimiento sobre la recuperación vectorial tradicional, y se cree que en el futuro se integrarán más algoritmos de recuperación de grafos en la pila tecnológica de la RAG.
Por supuesto, se estima que el marco KAG se encuentra todavía en una fase temprana y de iteración rápida, y todavía debe haber algún espacio para la discusión sobre la aplicación concreta de las funciones, tales como si la Planificación de la Forma Lógica y la Ejecución de la Forma Lógica existentes tienen un soporte teórico completo en el nivel de diseño, y si habrá una descomposición insuficiente y el fracaso de la ejecución frente a problemas complejos. Si habrá una descomposición insuficiente, el fracaso de la ejecución, pero esta definición de los límites y las cuestiones de robustez son generalmente muy difíciles de tratar, pero también requiere una gran cantidad de costos de ensayo y error, si toda la cadena de razonamiento es demasiado complejo, la tasa de fracaso final puede ser mayor, después de todo, una variedad de degradación de nuevo a la estrategia es sólo un cierto grado de alivio del problema. Además, me di cuenta de que el GraphStore en la parte inferior del marco en realidad ha reservado una interfaz de actualización incremental, pero la aplicación de la capa superior no mostró las capacidades pertinentes, que es también una característica que personalmente entiendo que la comunidad GraphRAG pide más altamente.
En general, el marco KAG se considera un trabajo muy duro en el pasado reciente, que contiene muchos puntos innovadores, y el código realmente ha pulido muchos detalles, lo que se cree que es un impulso importante para el proceso de aterrizaje de la pila tecnológica RAG.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...