Perfeccionamiento del modelo DeepSeek R1 para hacer posible la medicina de precisión Q&A: liberar el potencial de la IA de código abierto
Tutoriales prácticos sobre IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 48.9K 00

DeepSeek Presentó una serie de modelos de inferencia avanzados que desafían la posición de OpenAI en el sector, yCompletamente gratis, sin restricciones de usoEl programa está diseñado para beneficiar a todos los usuarios.
En este artículo describimos cómo afinar el modelo DeepSeek-R1-Distill-Llama-8B utilizando el conjunto de datos Medical Mind Chain de Hugging Face. Esta versión lite del DeepSeek-R1 obtenido ajustando el modelo Llama 3 8B a los datos generados por DeepSeek-R1, muestra una inferencia superior similar a la del modelo original.

Descifrado DeepSeek R1
DeepSeek-R1 y DeepSeek-R1-Zero superan al modelo o1 de OpenAI en tareas matemáticas, de programación y de razonamiento lógico.Cabe mencionar que tanto R1 como R1-Zero son modelos de código abierto..
DeepSeek-R1-Cero
DeepSeek-R1-Zero es el primer modelo de código abierto entrenado exclusivamente mediante aprendizaje por refuerzo (RL) a gran escala, a diferencia de los modelos tradicionales que utilizan el ajuste fino supervisado (SFT) como paso inicial. Este enfoque innovador permite a los modelos explorar de forma independiente el razonamiento CoT (Chain-of-Thought), lo que les permite resolver problemas complejos y optimizar iterativamente el resultado. Sin embargo, este enfoque también plantea algunos retos, como la posible duplicación de pasos de razonamiento, la menor legibilidad y los estilos de lenguaje incoherentes, lo que a su vez afecta a la claridad y utilidad del modelo.
DeepSeek-R1
El lanzamiento de DeepSeek-R1 pretende superar las deficiencias de DeepSeek-R1-Zero. Mediante la introducción de datos de arranque en frío antes del aprendizaje por refuerzo, DeepSeek-R1 establece una base más sólida para las tareas de inferencia y no inferencia. Esta estrategia de entrenamiento multietapa permite a DeepSeek-R1 alcanzar un nivel de rendimiento líder frente a OpenAI-o1 en pruebas de matemáticas, programación e inferencia, y mejora significativamente la legibilidad y la coherencia del resultado.
Modelo de destilación DeepSeek
DeepSeek también ha introducido una familia de modelos de destilación. Estos modelos son más pequeños y eficientes, pero mantienen un excelente rendimiento de inferencia. Aunque el tamaño de los parámetros oscila entre 1,5B y 70B, todos estos modelos conservan una gran capacidad de inferencia. Entre ellos, DeepSeek-R1-Distill-Qwen-32B supera al modelo OpenAI-o1-mini en varias pruebas de referencia. Los modelos de menor escala heredan los patrones de inferencia de los modelos más grandes, lo que demuestra plenamente la eficacia de la técnica de destilación.
-1")
El ajuste de DeepSeek R1 en acción
1. Configuración medioambiental
En este ejercicio de ajuste del modelo, se eligió Kaggle como IDE en la nube debido a los recursos de GPU gratuitos que proporciona Kaggle. Inicialmente se eligieron dos GPU T4, pero sólo se utilizó una. Si los usuarios desean realizar el ajuste fino del modelo en un ordenador local, necesitan tener al menosUna tarjeta gráfica RTX 3090 con 16 GB de memoria..
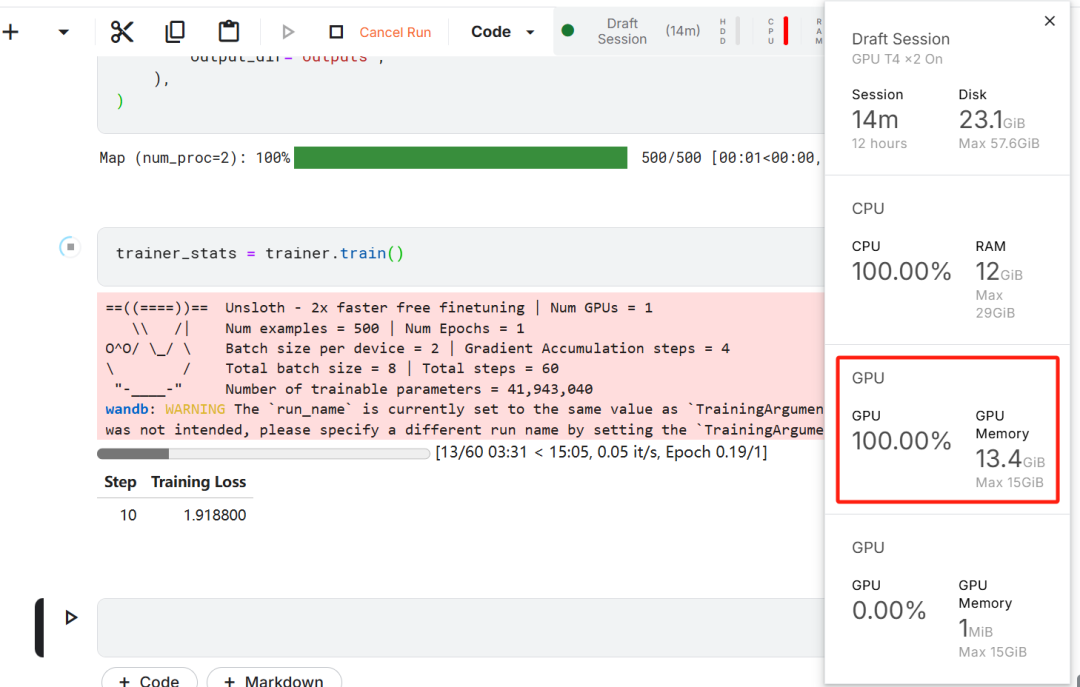
En primer lugar, inicie un nuevo cuaderno Kaggle con la Cara de Abrazo del usuario ficha responder cantando Pesas & Se añade el token Biases como clave.
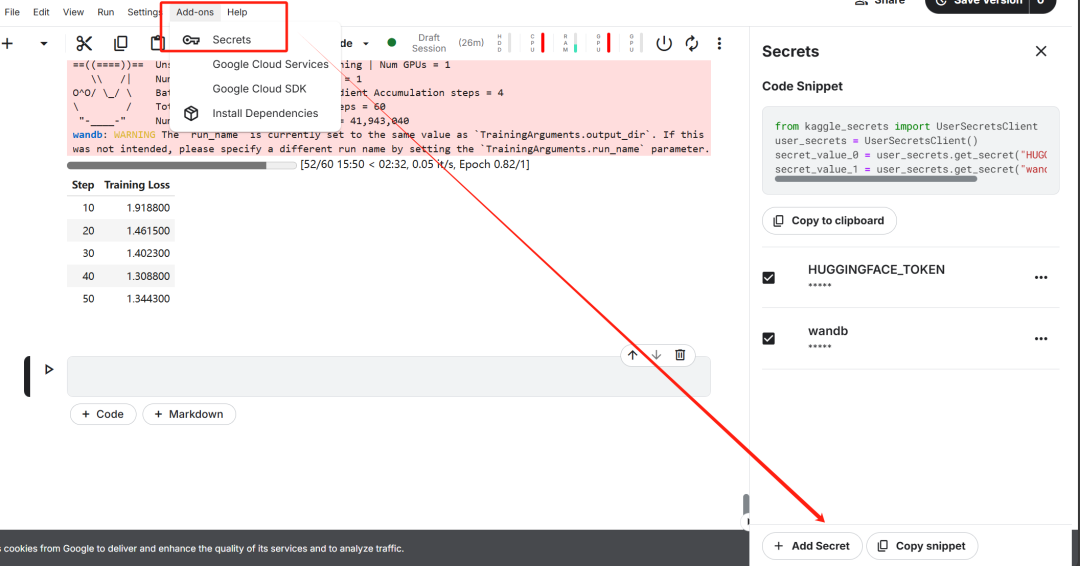
Una vez completada la configuración de la llave, instale el antipático Unsloth es un marco de código abierto diseñado para duplicar la velocidad de ajuste de grandes modelos lingüísticos (LLM) y mejorar significativamente la eficiencia de la memoria.
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
A continuación, inicie sesión en la CLI de Hugging Face. Este paso es fundamental para las posteriores descargas del conjunto de datos y la carga del modelo perfeccionado.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)
A continuación, inicie sesión en Pesos y sesgos (wandb) y cree un nuevo proyecto para seguir el curso del experimento y afinar el progreso.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)
2. Carga de modelos y tokenizadores
En la práctica de este trabajo, se cargó la versión Unsloth del modelo DeepSeek-R1-Distill-Llama-8B.
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B
Para optimizar el uso de memoria y mejorar el rendimiento, se optó por cargar el modelo de forma cuantificada en 4 bits.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
token=hf_token,
)
3. Cartilla de capacidad de razonamiento del modelo de preafinamiento
Con el fin de construir una plantilla de instrucciones para el modelo, se definió un sistema de instrucciones con marcadores de posición para la generación de preguntas y respuestas. El objetivo es guiar al modelo a través de un proceso de pensamiento paso a paso y, en última instancia, generar respuestas lógicamente rigurosas y precisas.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
En este ejemplo, se envía un mensaje a la dirección prompt_style proporcionó un problema médico y lo transformó en fichas, y posteriormente estas fichas pasado al modelo para generar la respuesta.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
El núcleo de la pregunta médica anterior es:
Mujer de 61 años con una larga historia de pérdidas involuntarias de orina durante actividades como toser o estornudar, pero sin pérdidas nocturnas. Se sometió a una exploración ginecológica y a una prueba de Q-tip. Basándose en estos hallazgos, ¿qué información revelaría probablemente la cistometría sobre su volumen de orina residual y el estado de contracción del detrusor?
Incluso sin un ajuste fino, el modelo genera con éxito cadenas de pensamiento y realiza un razonamiento riguroso antes de dar la respuesta final, quedando todo el proceso de razonamiento encapsulado en el <think></think> Etiquetado en.
Entonces, ¿por qué sigue siendo necesario afinar? Aunque el modelo muestra un proceso de razonamiento detallado, su representación es ligeramente larga y poco concisa. Además, las respuestas finales se presentan como listas con viñetas, lo que se desvía de la estructura y el estilo del conjunto de datos que se espera afinar.
4. Carga y preprocesamiento de conjuntos de datos
El modelo de consulta se adaptó a las necesidades de procesamiento del conjunto de datos añadiendo un tercer marcador de posición para la columna Cadena de pensamiento compleja en el modelo de consulta.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
Se escribió una función en Python para crear una columna de "texto" en el conjunto de datos. El contenido de la columna consiste en una plantilla de preguntas de entrenamiento con marcadores de posición rellenados con preguntas, cadenas de pensamiento y respuestas, respectivamente.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
Las primeras 500 muestras del conjunto de datos FreedomIntelligence/medical-o1-reasoning-SFT se cargaron desde el Hugging Face Hub.
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT?row=46
Posteriormente, utilizando el formatting_prompts_func asigna la columna "texto" del conjunto de datos.
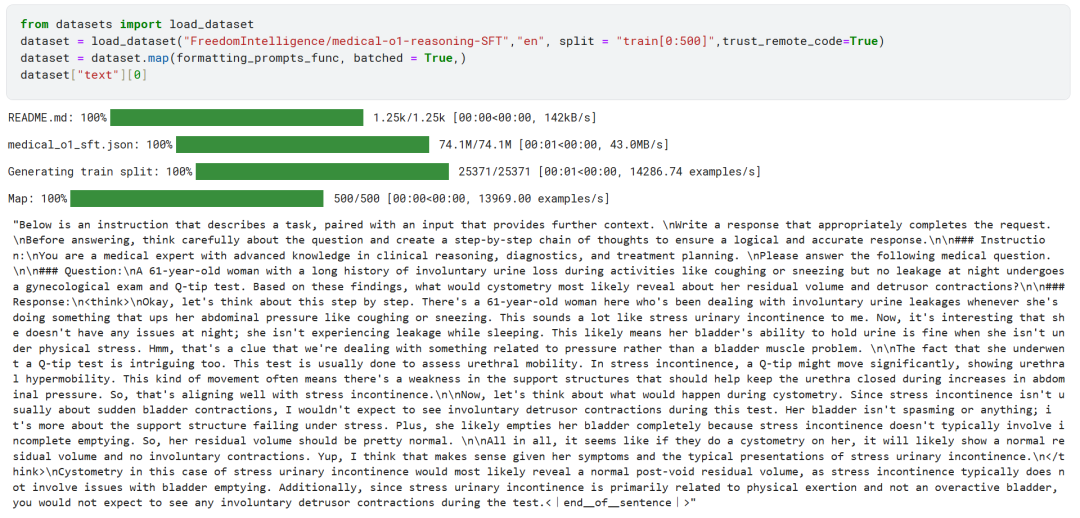
Como puede ver arriba, la columna "texto" ha integrado con éxito las pistas del sistema, las instrucciones, las cadenas de pensamiento y las respuestas finales.
5. Configuración del modelo
El modelo se configura mediante la técnica del adaptador de bajo rango fijando el módulo de destino.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
A continuación, se configuraron los parámetros de entrenamiento y el entrenador (Trainer). El modelo, el tokenizador, el conjunto de datos y otros parámetros clave de entrenamiento se proporcionaron al entrenador para optimizar el proceso de ajuste del modelo.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
6. Formación de modelos
trainer_stats = trainer.train()
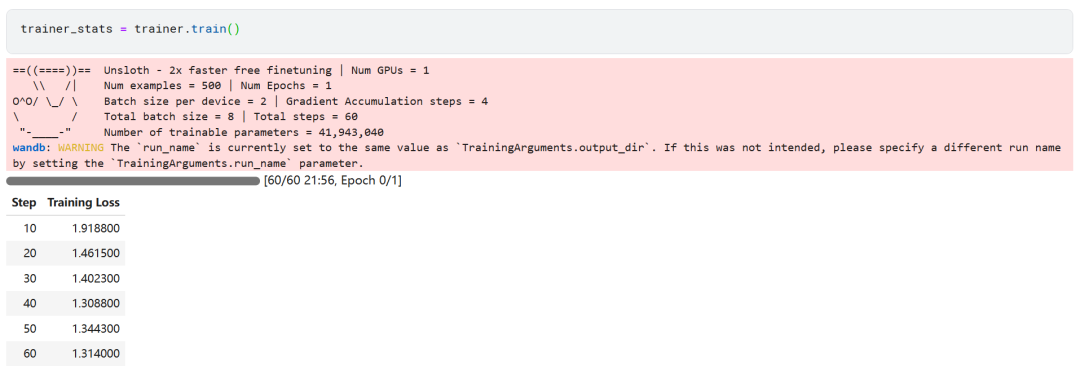
El proceso de entrenamiento del modelo duró 22 minutos. La pérdida de entrenamiento (pérdida) disminuye gradualmente, lo que es un signo positivo de que el rendimiento del modelo ha mejorado.
Los usuarios pueden visitar el sitio web de Weights & Biases para consultar el informe completo de evaluación del modelo.
7. Evaluación de la capacidad de razonamiento del modelo afinado
Para el análisis comparativo, se volvieron a plantear al modelo ajustado las mismas preguntas que antes del ajuste para observar el cambio en el rendimiento del modelo.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Los resultados experimentales muestran que la calidad de la salida del modelo afinado ha mejorado notablemente y las respuestas son más precisas. La cadena de pensamientos se presentó de forma más concisa y la respuesta final fue más directa y clara en un solo párrafo, lo que indica el éxito de este ajuste fino del modelo.

8. Almacenamiento local de modelos
Ahora, guarda el adaptador, el modelo completo y el tokenizador localmente para utilizarlos en otros proyectos.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")
9. Modelo subido a Hugging Face Hub
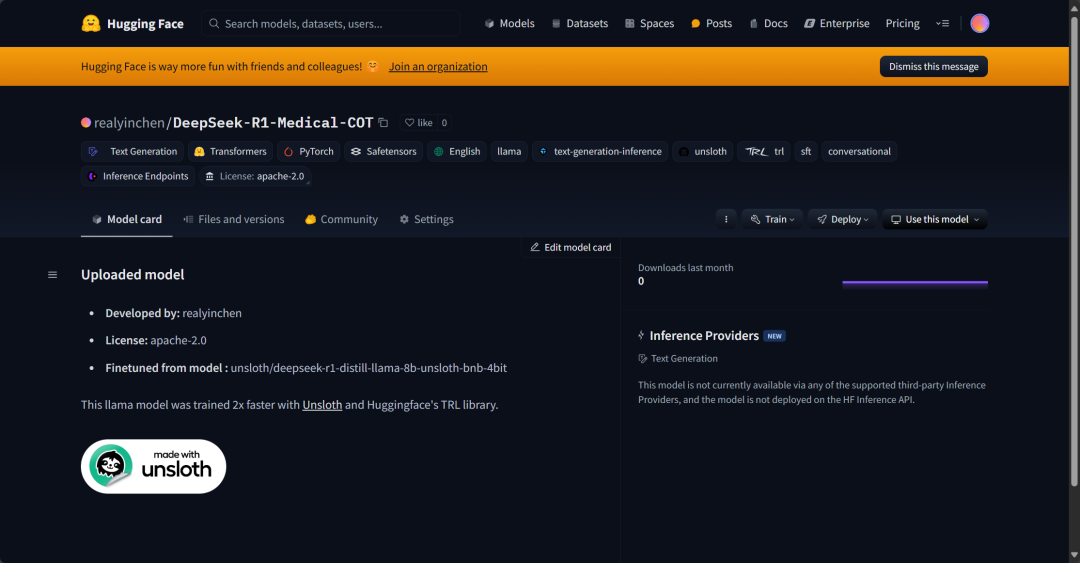
También se enviaron al Hugging Face Hub adaptadores, tokenizadores y modelos completos, con el objetivo de permitir a la comunidad de IA hacer pleno uso de este modelo perfeccionado e integrarlo fácilmente en sus sistemas.
new_model_online = "realyinchen/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method="merged_16bit")
resúmenes
El campo de la inteligencia artificial (IA) está experimentando rápidos cambios. El auge de la comunidad de código abierto plantea un fuerte desafío al panorama de la IA, dominado desde hace tres años por modelos propietarios. Los Large Language Models (LLM) de código abierto son cada vez más rápidos y eficaces, lo que facilita más que nunca su puesta a punto con menos recursos informáticos y de memoria.
Este documento analiza en profundidad la DeepSeek R1 y detalla cómo su versión lite puede ajustarse para su aplicación en escenarios de preguntas y respuestas médicas. El modelo de inferencia perfeccionado no solo ofrece mejoras significativas de rendimiento, sino que también lo hace práctico para su uso en ámbitos clave como la medicina, los servicios de urgencias y la asistencia sanitaria.
En respuesta al lanzamiento de DeepSeek R1, OpenAI también introdujo rápidamente dos herramientas importantes: un modelo de inferencia más avanzado, o3, y el Operador AI Agent. Este último se basa en el nuevo Agente de Uso del Ordenador (CUA, el Ordenador Use Agent) que demuestra la capacidad de navegar de forma autónoma por sitios web y realizar tareas complejas.
Código fuente:
https://www.kaggle.com/code/realyinchen/deepseek-r1-medical-cot
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...