Dominio de Crawl4AI: preparación de datos web de alta calidad para LLM y RAG
Tutoriales prácticos sobre IAActualizado hace 12 meses Círculo de intercambio de inteligencia artificial 86.1K 00

Los marcos de rastreo web tradicionales son versátiles, pero a menudo requieren una limpieza y un formateo adicionales a la hora de procesar los datos, lo que hace que su integración con los grandes modelos lingüísticos (LLM) sea relativamente compleja. El resultado de muchas herramientas (por ejemplo, los datos en bruto HTML o no estructurados JSON) contiene mucho ruido y no es adecuado para su uso directo en escenarios como la Generación Aumentada de Recuperación (RAG), ya que degradaría LLM Eficacia y precisión del tratamiento.
Crawl4AI ofrece una solución diferente. Se centra en generar directamente Markdown Contenido formateado. Este formato conserva la estructura semántica del texto original (por ejemplo, encabezados, listas, bloques de código) al tiempo que elimina de forma inteligente elementos extraños como la navegación, la publicidad, los pies de página, etc., lo que lo hace ideal para utilizarlo como un LLM insumos o para construir RAG Conjunto de datos.Crawl4AI es un proyecto completamente de código abierto que no utiliza API La clave tampoco está fijada en un umbral de pago por visión.
Instalación y configuración
Uso recomendado uv Crear y activar un Python entorno virtual para gestionar las dependencias del proyecto.uv Se basa en un Rust Desarrollados Emergentes Python gestor de paquetes, con su importante ventaja de velocidad (normalmente sobre el pip (de 3 a 5 veces más rápido) y una eficaz resolución paralela de dependencias.
# 创建虚拟环境
uv venv crawl4ai-env
# 激活环境
# Windows
# crawl4ai-env\Scripts\activate
# macOS/Linux
source crawl4ai-env/bin/activate
Una vez activado el entorno, utilice el botón uv montaje Crawl4AI Biblioteca central:
uv pip install crawl4ai
Una vez finalizada la instalación, ejecute el comando de inicialización, que se encargará de instalar o actualizar el archivo Playwright Controladores de navegador necesarios (por ejemplo Chromium) y realizar inspecciones medioambientales.Playwright Es una de esas cosas que está hecha de Microsoft desarrollado bibliotecas de automatización de navegadores.Crawl4AI Utilícelo para simular las interacciones reales de los usuarios y poder manejar el contenido cargado dinámicamente del JavaScript Página web pesada.
crawl4ai-setup
Si encuentra problemas relacionados con el controlador del navegador, puede intentar instalarlo manualmente:
# 手动安装 Playwright 浏览器及依赖
python -m playwright install --with-deps chromium
En caso necesario, puede hacerse uv Instalación de paquetes de ampliación con funciones adicionales:
# 安装文本聚类功能 (依赖 PyTorch)
uv pip install "crawl4ai[torch]"
# 安装 Transformers 支持 (用于本地 AI 模型)
uv pip install "crawl4ai[transformer]"
# 安装所有可选功能
uv pip install "crawl4ai[all]"
Ejemplo básico de rastreo
esa cantidad o menos Python El script demuestra la Crawl4AI El uso básico del Markdown.
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
# 初始化异步爬虫
async with AsyncWebCrawler() as crawler:
# 执行爬取任务
result = await crawler.arun(
url="https://www.sitepoint.com/react-router-complete-guide/"
)
# 检查爬取是否成功
if result.success:
# 输出结果信息
print(f"标题: {result.title}")
print(f"提取的 Markdown ({len(result.markdown)} 字符):")
# 仅显示前 300 个字符作为预览
print(result.markdown[:300] + "...")
# 将完整的 Markdown 内容保存到文件
with open("example_content.md", "w", encoding="utf-8") as f:
f.write(result.markdown)
print(f"内容已保存到 example_content.md")
else:
# 输出错误信息
print(f"爬取失败: {result.url}")
print(f"状态码: {result.status_code}")
print(f"错误信息: {result.error_message}")
if __name__ == "__main__":
asyncio.run(main())
Después de ejecutar este script, elCrawl4AI activará Playwright Acceso controlado del navegador a los datos especificados URLPágina de ejecución JavaScriptEl sistema de gestión de contenidos, que se basa en la tecnología de la información, identifica y extrae de forma inteligente las principales áreas de contenido, filtra los elementos de distracción y, en última instancia, genera un contenido limpio. Markdown Documentación.
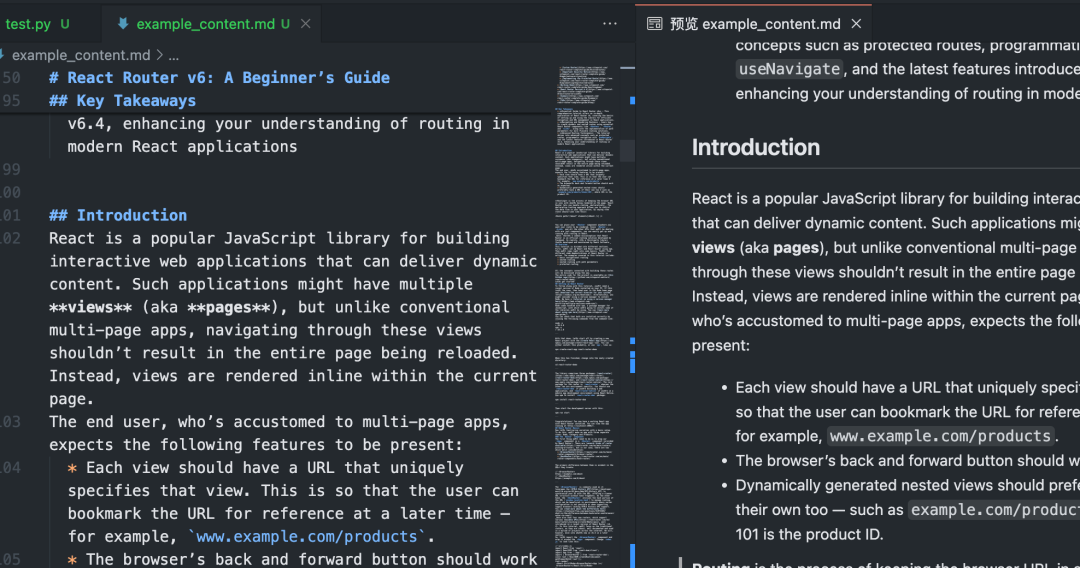
Rastreo por lotes y en paralelo
proceso múltiple URL cuandoCrawl4AI de procesamiento paralelo puede aumentar drásticamente la eficiencia. Configurando el CrawlerRunConfig ha dado en el clavo concurrency que controla el número de páginas procesadas simultáneamente.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
async def main():
urls = [
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
# 添加更多 URL...
]
# 浏览器配置:无头模式,增加超时
browser_config = BrowserConfig(
headless=True,
timeout=45000, # 45秒超时
)
# 爬取运行配置:设置并发数,禁用缓存以获取最新内容
run_config = CrawlerRunConfig(
concurrency=5, # 同时处理 5 个页面
cache_mode=CacheMode.BYPASS # 禁用缓存
)
results = []
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
# 使用 arun_many 进行批量并行爬取
# 注意:arun_many 需要将 run_config 列表传递给 configs 参数
# 如果所有 URL 使用相同配置,可以创建一个配置列表
configs = [run_config.clone(url=url) for url in urls] # 为每个URL克隆配置并设置URL
# arun_many 返回一个异步生成器
async for result in crawler.arun_many(configs=configs):
if result.success:
results.append(result)
print(f"已完成: {result.url}, 获取了 {len(result.markdown)} 字符")
else:
print(f"失败: {result.url}, 错误: {result.error_message}")
# 将所有成功的结果合并到一个文件
with open("combined_results.md", "w", encoding="utf-8") as f:
for i, result in enumerate(results):
f.write(f"## {result.title}\n\n")
f.write(result.markdown)
f.write("\n\n---\n\n")
print(f"所有成功内容已合并保存到 combined_results.md")
if __name__ == "__main__":
asyncio.run(main())
tenga en cuentaEl código anterior utiliza la función arun_many que es la forma recomendada de manejar grandes listas de URLs, en lugar de hacer un bucle a través de una llamada al método arun Más eficiente.arun_many Se requiere una lista de configuraciones, cada una de las cuales corresponde a un URL. Si todos URL Utilizando la misma configuración básica, el clone() crea una copia y establece un URL.
Extracción de datos estructurados (basada en selectores)
aparte de Markdown(matemáticas) géneroCrawl4AI También disponible CSS Selector o XPath Extrae datos estructurados, ideal para sitios con formatos de datos regulares.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, ExtractorConfig
async def main():
# 定义提取规则 (CSS 选择器)
extractor_config = ExtractorConfig(
strategy="css", # 明确指定策略为 CSS
rules={
"products": {
"selector": "div.product-card", # 主选择器
"type": "list",
"properties": {
"name": {"selector": "h2.product-title", "type": "text"},
"price": {"selector": ".price span", "type": "text"},
"link": {"selector": "a.product-link", "type": "attribute", "attribute": "href"}
}
}
}
)
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://example-shop.com/products",
extractor_config=extractor_config
)
if result.success and result.extracted_data:
extracted_data = result.extracted_data
with open("products.json", "w", encoding="utf-8") as f:
json.dump(extracted_data, f, ensure_ascii=False, indent=2)
print(f"已提取 {len(extracted_data.get('products', []))} 个产品信息")
print("数据已保存到 products.json")
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("未提取到数据或提取规则匹配失败")
if __name__ == "__main__":
asyncio.run(main())
Este enfoque no requiere LLM La intervención, de bajo coste y rápida, es adecuada para escenarios en los que el elemento objetivo está claro.
Extracción de datos mejorada por IA
Para páginas con estructuras complejas o sin un patrón fijo, puede utilizar la función LLM Realiza una extracción inteligente.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, BrowserConfig, AIExtractorConfig
async def main():
# 配置 AI 提取器
ai_config = AIExtractorConfig(
provider="openai", # 或 "local", "anthropic" 等
model="gpt-4o-mini", # 使用 OpenAI 的模型
# api_key="YOUR_OPENAI_API_KEY", # 如果环境变量未设置,在此提供
schema={
"type": "object",
"properties": {
"article_summary": {"type": "string", "description": "A brief summary of the article."},
"key_topics": {"type": "array", "items": {"type": "string"}, "description": "List of main topics discussed."},
"sentiment": {"type": "string", "enum": ["positive", "negative", "neutral"], "description": "Overall sentiment of the article."}
},
"required": ["article_summary", "key_topics"]
},
instruction="Extract the summary, key topics, and sentiment from the provided article text."
)
browser_config = BrowserConfig(timeout=60000) # AI 处理可能需要更长时间
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
result = await crawler.arun(
url="https://example-news.com/article/complex-analysis",
ai_extractor_config=ai_config
)
if result.success and result.ai_extracted:
ai_extracted = result.ai_extracted
print("AI 提取的数据:")
print(json.dumps(ai_extracted, indent=2, ensure_ascii=False))
# 也可以选择保存到文件
# with open("ai_extracted_data.json", "w", encoding="utf-8") as f:
# json.dump(ai_extracted, f, ensure_ascii=False, indent=2)
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("AI 未能提取所需数据。")
if __name__ == "__main__":
asyncio.run(main())
La extracción mediante IA ofrece una gran flexibilidad para comprender contenidos y generar resultados estructurados a demanda, pero incurre en costes adicionales. API Coste de la llamada (si se utiliza un servicio en la nube) LLM) y el tiempo de procesamiento. Seleccione el modelo local (por ejemplo Mistral, Llama) pueden reducir costes y proteger la privacidad, pero tienen requisitos de hardware locales.
Configuraciones avanzadas y consejos
Crawl4AI Ofrece numerosas opciones de configuración para hacer frente a situaciones complejas.
Configuración del navegador (BrowserConfig)
BrowserConfig Controla el inicio y el comportamiento del propio navegador.
from crawl4ai import BrowserConfig
config = BrowserConfig(
browser_type="firefox", # 使用 Firefox 浏览器
headless=False, # 显示浏览器界面,方便调试
user_agent="MyCustomCrawler/1.0", # 设置自定义 User-Agent
proxy_config={ # 配置代理服务器
"server": "http://proxy.example.com:8080",
"username": "proxy_user",
"password": "proxy_password"
},
ignore_https_errors=True, # 忽略 HTTPS 证书错误 (开发环境常用)
use_persistent_context=True, # 启用持久化上下文
user_data_dir="./my_browser_profile", # 指定用户数据目录,用于保存 cookies, local storage 等
timeout=60000, # 全局浏览器操作超时 (毫秒)
verbose=True # 打印更详细的日志
)
# 在初始化 AsyncWebCrawler 时传入
# async with AsyncWebCrawler(browser_config=config) as crawler:
# ...
Rastrear la configuración en tiempo de ejecución (CrawlerRunConfig)
CrawlerRunConfig Control Individual arun() tal vez arun_many() El comportamiento específico de la llamada.
from crawl4ai import CrawlerRunConfig, CacheMode
run_config = CrawlerRunConfig(
cache_mode=CacheMode.READ_ONLY, # 只读缓存,不写入新缓存
check_robots_txt=True, # 检查并遵守 robots.txt 规则
wait_until="networkidle", # 等待网络空闲再提取,适合JS动态加载内容
wait_for="css:div#final-content", # 等待特定 CSS 选择器元素出现
js_code="window.scrollTo(0, document.body.scrollHeight);", # 页面加载后执行 JS 代码 (例如滚动到底部触发加载)
scan_full_page=True, # 尝试自动滚动页面以加载所有内容 (用于无限滚动)
screenshot=True, # 截取页面截图 (结果在 result.screenshot,Base64编码)
pdf=True, # 生成页面 PDF (结果在 result.pdf,Base64编码)
word_count_threshold=50, # 过滤掉少于 50 个单词的文本块
excluded_tags=["header", "nav", "footer", "aside"], # 从 Markdown 中排除特定 HTML 标签
exclude_external_links=True # 不提取外部链接
)
# 在调用 arun() 或创建配置列表给 arun_many() 时传入
# result = await crawler.arun(url="...", config=run_config)
Manejo de JavaScript y contenido dinámico
gracias a Playwright(matemáticas) géneroCrawl4AI Gestiona bien las dependencias JavaScript Sitio web renderizado. Configuración clave:
wait_untilFijar en"networkidle"tal vez"load"Suele ser un poco más eficiente que el predeterminado"domcontentloaded"Más adecuado para páginas dinámicas.wait_for: espera un elemento específico oJavaScriptCondiciones cumplidas.js_codeEjecutar la personalización tras la carga de la páginaJavaScriptcomo pulsar botones y desplazarse por las páginas.scan_full_page:: Manejar automáticamente las páginas comunes de desplazamiento infinito.delay_before_return_html: Añade un breve retardo antes de la extracción para garantizar que se ejecutan todos los scripts.
Tratamiento de errores y depuración
- sonda
result.success: Asegúrese de comprobar esta propiedad después de cada rastreo. - comprobar
result.status_coderesponder cantandoresult.error_message:: Obtener el motivo del fallo. - establecer
headless=FalseEnBrowserConfigPuede observar el funcionamiento del navegador y diagnosticar el problema visualmente. - comisión
verbose=TrueEnBrowserConfigen la configuración para obtener un registro más detallado del tiempo de ejecución. - utilizar
try...exceptParcelaarun()tal vezarun_many()que captura una posiblePythonExcepción.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig
async def debug_crawl():
# 启用调试模式:显示浏览器,打印详细日志
debug_browser_config = BrowserConfig(headless=False, verbose=True)
async with AsyncWebCrawler(browser_config=debug_browser_config) as crawler:
try:
result = await crawler.arun(url="https://problematic-site.com")
if not result.success:
print(f"Crawl failed: {result.error_message} (Status: {result.status_code})")
else:
print("Crawl successful.")
# ... process result ...
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
asyncio.run(debug_crawl())
observancia robots.txt
Cuando realice un rastreo web, respete la robots.txt La documentación es una norma básica de etiqueta de la red y evita el bloqueo de IP.Crawl4AI Puede procesarse automáticamente.
existe CrawlerRunConfig establecer check_robots_txt=True::
respectful_config = CrawlerRunConfig(
check_robots_txt=True
)
# result = await crawler.arun(url="https://example.com", config=respectful_config)
# if not result.success and result.status_code == 403:
# print("Access denied by robots.txt")
Crawl4AI Descarga, almacenamiento en caché y análisis automáticos robots.txt si la regla prohíbe el acceso al archivo de destino URL(matemáticas) géneroarun() fallará.result.success debido a False(matemáticas) génerostatus_code Esto suele ser 403 con el mensaje de error apropiado.
Gestión de sesiones (Session Management)
Para operaciones de varios pasos que requieren iniciar sesión o mantener el estado (por ejemplo, envío de formularios, navegación paginada), se puede utilizar la gestión de sesiones. Esto puede lograrse añadiendo un nuevo gestor de sesiones al módulo CrawlerRunConfig Especifique lo mismo en el session_idEl sistema puede utilizarse en más de un arun() La misma instancia de página del navegador se reutiliza entre llamadas, preservando la cookies responder cantando JavaScript Estado.
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig, CacheMode
async def session_example():
async with AsyncWebCrawler() as crawler:
session_id = "my_unique_session"
# Step 1: Load login page (hypothetical)
login_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
await crawler.arun(url="https://example.com/login", config=login_config)
print("Login page loaded.")
# Step 2: Execute JS to fill and submit login form (hypothetical)
login_js = """
document.getElementById('username').value = 'user';
document.getElementById('password').value = 'pass';
document.getElementById('loginButton').click();
"""
submit_config = CrawlerRunConfig(
session_id=session_id,
js_code=login_js,
js_only=True, # 只执行 JS,不重新加载页面
wait_until="networkidle" # 等待登录后跳转完成
)
await crawler.arun(config=submit_config) # 无需 URL,在当前页面执行 JS
print("Login submitted.")
# Step 3: Crawl a protected page within the same session
protected_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
result = await crawler.arun(url="https://example.com/dashboard", config=protected_config)
if result.success:
print("Successfully crawled protected page:")
print(result.markdown[:200] + "...")
else:
print(f"Failed to crawl protected page: {result.error_message}")
# 清理会话 (可选,但推荐)
# await crawler.crawler_strategy.kill_session(session_id)
if __name__ == "__main__":
asyncio.run(session_example())
Una gestión de sesiones más avanzada incluye la exportación e importación del estado de almacenamiento del navegador (cookies, localStorage), lo que permite mantener el inicio de sesión entre ejecuciones de script.
Crawl4AI Proporciona un conjunto de funciones potentes y flexibles que, cuando se configuran correctamente, pueden extraer de forma eficaz y fiable la información necesaria de diversos sitios web y preparar datos de alta calidad para aplicaciones de IA posteriores.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...