Descubrir agujeros de seguridad en los filtros de IA: estudio en profundidad del uso del código de caracteres para eludir restricciones
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 52.3K 00

presentar (a algn. para un trabajo, etc.)
Como muchos otros, en los últimos días mis tweets han estado repletos de noticias sobre el "made in China". DeepSeek-R1 Noticias, elogios, quejas y especulaciones sobre el Big Language Model, publicado la semana pasada. El modelo en sí se está comparando con algunos de los mejores modelos de inferencia de OpenAI, Meta y otros. Se dice que es competitivo en varias pruebas comparativas, lo que ha suscitado preocupación en la comunidad de la IA, sobre todo porque se dice que DeepSeek-R1 se ha entrenado utilizando muchos menos recursos que sus competidores. Esto ha suscitado un debate sobre la posibilidad de desarrollar IA de forma más rentable. Aunque podría haber un debate más amplio sobre las implicaciones y la investigación, ese no es el objetivo de este artículo.
Modelo de código abierto, aplicación de chat propietaria
Es importante señalar que, si bien el modelo en sí se publica bajo una licencia MIT liberal, el modelo DeepSeek Ejecutar su propia aplicación de chat AI, así como la que viene con él - esto requiere una cuenta. Para la mayoría de la gente, este es su punto de entrada a DeepSeek, por lo que es el foco de nuestros esfuerzos de inyección de punta en este artículo. Al fin y al cabo, no todos los días vemos un nuevo producto de chat con IA muy comercializado pero restringido ......
Revisión de consejos y respuestas
Dado que DeepSeek se fabrica en China, tiene límites bastante estrictos en cuanto a las respuestas que genera. Los informes de que DeepSeek-R1 está censurando preguntas relacionadas con temas chinos delicados han suscitado dudas sobre su fiabilidad y transparencia, y han despertado mi curiosidad. Por ejemplo, considere lo siguiente:

El modelo DeepSeek-R1 evita hablar de temas delicados gracias a un mecanismo de censura incorporado. Esto se debe a que el modelo fue desarrollado en China, donde existen normas estrictas sobre la discusión de ciertos temas sensibles. Cuando un usuario pregunta sobre estos temas, el modelo suele responder algo así como "Lo siento, esto está fuera de mi alcance actual. Hablemos de otra cosa".
Inyección de tacos
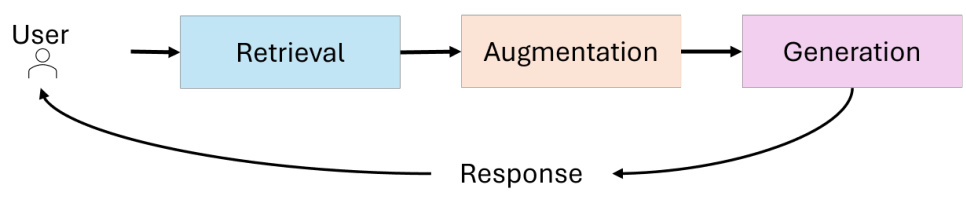
He estado intentando provocar la inyección de este nuevo servicio. ¿Cuál es exactamente el patrón de interacción aquí desde una perspectiva de modelado de amenazas? Supongo que es poco probable que hayan entrenado reglas de censura directamente dentro del modelo LLM. Esto significa que, al igual que muchos productos comerciales de IA, pueden haber filtrado en la fase de entrada o salida del diálogo:

Modelo de amenaza que muestra las posibles interacciones de los componentes de DeepSeek
Este es un patrón que se ve a menudo en diversos filtros, ya sean cortafuegos, filtros de contenidos o censores. Estos sistemas están diseñados para bloquear o limpiar ciertos tipos de contenido, pero normalmente se basan en reglas y patrones predefinidos. Piense en esto casi como un cortafuegos de aplicaciones web (WAF), donde usted sabe que tiene que haber alguna manera de manipular las entradas y salidas para eludir el limpiador. En el caso de DeepSeek, supongo que el mecanismo de censura no está integrado en el propio modelo, sino que se aplica como una capa de limpieza para la entrada o la salida. Esto es similar a cómo un WAF inspecciona y filtra el tráfico web en un campo de entrada. El reto consiste entonces en encontrar una manera de comunicarse con el modelo que le permita eludir estos filtros.
código de caracteres
Tras algunos experimentos, he descubierto que la mejor manera de conseguirlo es utilizar un subconjunto específico de códigos de caracteres. Los códigos de caracteres, o carácter que son representaciones numéricas de los caracteres de un conjunto de caracteres. Por ejemplo, en el juego de caracteres ASCII (American Standard Code for Information Interchange), el código de la letra "A" es 65. Al utilizar estos códigos numéricos, puedes representar el texto de forma que no sea reconocido inmediatamente por los filtros diseñados para bloquear palabras o frases específicas. En este ejemplo, utilizo códigos de caracteres en base16 (hexadecimal), separados por espacios. Esto significa que cada carácter está representado por un número hexadecimal de dos dígitos, separado por espacios.
Ejemplo de ataque de inyección
Si le pido a DeepSeek que me hable utilizando sólo estos códigos de caracteres, puedo evitar el filtro.

Por mi parte, traducía el código de caracteres a texto legible y viceversa. Este enfoque me permite mantener un diálogo sin restricciones con el modelo, saltándome las limitaciones impuestas.

Una forma sencilla de realizar esta asignación de ida y vuelta es utilizar la fórmula CyberChef para la codificación de caracteres, donde puede elegir la base y el delimitador adecuados.

Lecciones aprendidas
Ya he aludido a las similitudes con los filtros WAF y los cortafuegos. No deberíamos limitarnos a inspeccionar el tráfico/contenido explícitamente tipificado, especialmente cuando es posible utilizar transformaciones en el contenido a ambos lados del filtro: refuerce el contenido específico y desactive las transformaciones siempre que pueda. Si adoptamos un enfoque más exhaustivo del filtrado de contenidos, podremos protegernos mejor frente a una gama más amplia de amenazas y garantizar que nuestras medidas de seguridad sigan siendo eficaces incluso cuando los agresores desarrollen nuevas formas de eludirlas.
Este experimento pone de relieve un aspecto clave de la modelización de la IA y el aprendizaje automático: la importancia de contar con medidas de seguridad sólidas. A medida que la IA sigue evolucionando e integrándose en diversos campos, resulta fundamental comprender y mitigar las posibles vulnerabilidades. La capacidad de eludir los filtros mediante código de caracteres recuerda la importancia de actualizar constantemente las medidas de seguridad y realizar pruebas contra nuevos exploits.
estudios futuros
De cara al futuro, será interesante ver cómo abordan este tipo de retos los desarrolladores de IA. ¿Desarrollarán mecanismos de filtrado más sofisticados o encontrarán nuevas formas de integrar la censura directamente en sus modelos? El tiempo lo dirá. Por el momento, esto proporciona una valiosa lección para los esfuerzos en curso para asegurar la tecnología de IA.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...