



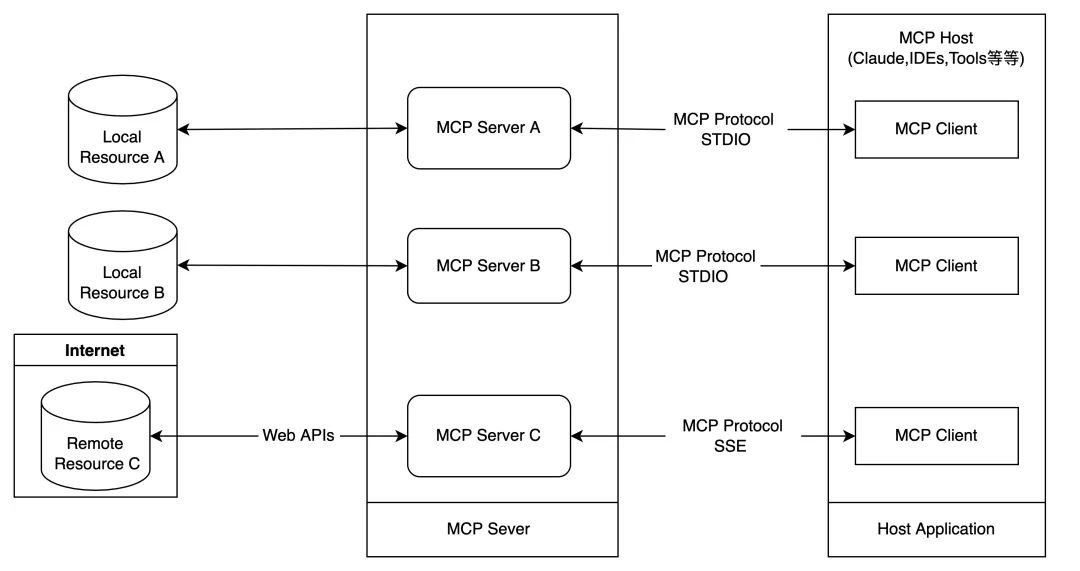
Resolviendo la confusión o1, ¿los modelos de inferencia como DeepSeek-R1 piensan o no?
Base de conocimientos de IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 43K 00

Encontré un divertido artículo en TheLos pensamientos están por todas partes: sobre la infravaloración de los LLM similares a o1", el tema es analizar el modelo de razonamiento de tipo o1 Cambio frecuente de vías de pensamiento y falta de focalización del pensamiento, lo que se denomina"subpensar".También se ofrecen métodos de mitigación. Este artículo responde simultáneamente a la pregunta de si el modelo de inferencia vuelve a pensar o no, y es de esperar que el lector encuentre su propia respuesta.
I. Antecedentes:
En los últimos años, los grandes modelos lingüísticos (LLM), representados por el modelo o1 de OpenAI, han demostrado una capacidad superior en tareas de razonamiento complejas, en las que imitan la profundidad del pensamiento humano aumentando la cantidad de cálculo implicada en el proceso de razonamiento. Sin embargo, los estudios existentes han cuestionado la profundidad del pensamiento de los LLM:¿Estos modelos piensan realmente en profundidad?
Para responder a esta pregunta, los autores de este trabajo proponen"Subpensar".del concepto y lo analiza sistemáticamente. Los autores sostienen que elno es suficiente para reflexionares la clase o1 de LLM en la resolución de problemas complejos.Abandonar demasiado pronto vías de inferencia prometedoras conduce a una insuficiente profundidad de pensamiento y, en última instancia, afecta al rendimiento del modelo. Este fenómeno es especialmente destacado en los acertijos matemáticos.
II. Métodos de reflexión e investigación:
Para profundizar en el fenómeno del subpensamiento, los autores llevaron a cabo la siguiente investigación:
1. Definición y observación del fenómeno del déficit de reflexión
- Definir el pensamiento: Los autores definen "pensar" como un paso cognitivo intermedio en el proceso de razonamiento del modelo, y utilizan términos como "alternativamente" como señal de un cambio en el pensamiento.
- Ejemplo: En la Figura 2, los autores muestran un ejemplo del resultado de un modelo que contiene 25 pasos de pensamiento y lo comparan con el resultado del pensamiento excesivo.
- Diseño experimental:
- Conjuntos de pruebas: Los autores eligieron tres desafiantes conjuntos de pruebas:
- MATH500. Contiene preguntas de concursos de matemáticas de secundaria con un grado de dificultad de 1 a 5.
- Diamante GPQA. Contiene preguntas tipo test de nivel universitario sobre física, química y biología.
- AIME2024. Los temas del Concurso Invitacional de Matemáticas de Estados Unidos abarcan una amplia gama de áreas, como álgebra, cálculo, geometría, teoría de números y probabilidad.
- Selección de modelo: Los autores eligieron dos modelos de código abierto de la clase o1 con cadenas de pensamiento largas visibles: el QwQ-32B-Preview y el DeepSeek-R1-671B, y utilizaron el DeepSeek-R1-Preview como complemento para mostrar el desarrollo de la familia de modelos R1.
- Conjuntos de pruebas: Los autores eligieron tres desafiantes conjuntos de pruebas:
2. Analizar las manifestaciones de una reflexión inadecuada
- Pensar en la frecuencia de cambio y la dificultad del problema:
- Los autores descubrieron que el número de reflexiones de inferencia generadas y el número de tokens generados aumentaban para todos los modelos a medida que aumentaba la dificultad del problema (véase la Figura 3).
- Esto sugiere que los LLM de clase o1 son capaces de adaptar dinámicamente el proceso de razonamiento para hacer frente a problemas más complejos.

- Pensando en la conmutación y la respuesta de error:
- En todos los conjuntos de pruebas, los LLM de la clase o1 mostraron cambios de pensamiento más frecuentes al generar respuestas incorrectas (véanse las figuras 1 y 4).
- Esto sugiere que, aunque el modelo pretende adaptar dinámicamente los procesos cognitivos para resolver problemas, los cambios de pensamiento más frecuentes no conducen necesariamente a una mayor precisión.
3. Investigación en profundidad de la naturaleza del déficit de pensamiento
- Evaluar la corrección del pensamiento:
- Los autores utilizaron dos modelos basados en Llama y Qwen (DeepSeek-R1-Distill-Llama-70B y DeepSeek-R1-Distill-Qwen-32B) para evaluar si cada paso del pensamiento era correcto.
- Los resultados muestran queUna parte significativa de los primeros pasos del pensamiento en la respuesta de error son correctos pero no se exploran completamente(véase la figura 5).
- Esto sugiere que el modelo, cuando se enfrenta a un problema complejoTendencia a abandonar prematuramente vías de razonamiento prometedoras, lo que conduce a una falta de profundidad de pensamiento..
- Piensa en la distribución de la corrección:
- Los autores descubrieron que más de 701 respuestas de error TP3T contenían al menos un paso de pensamiento correcto (véase la Figura 6).
- Esto respalda aún más la opinión anterior:o Los modelos de la clase 1 son capaces de iniciar los caminos correctos de razonamiento, pero puede resultar difícil continuar estos caminos hasta la conclusión correcta..
4. Cuantificar la falta de reflexión: proponer nuevos indicadores para la evaluación
- Pensar en subindicadores (UT):
- Esta métrica cuantifica el grado de subpensamiento midiendo la eficacia de la ficha a la hora de generar una respuesta de error.
- En concreto, la métrica UT calcula la respuesta de error en la que elNúmero de fichas pensadas correctamente desde el principio hasta el principio en proporción al número total de fichas.
- Los valores UT más altos indican niveles más altos de infravaloraciónes decir, una mayor proporción del token generado por el modelo en respuesta a un error no contribuye eficazmente a generar un pensamiento correcto.
5. Impacto de la falta de reflexión en el rendimiento del modelo:
- Los autores constataron queEl fenómeno del subpensamiento se comporta de forma diferente según los conjuntos de datos y las tareas::
- En los conjuntos de datos MATH500-Hard y GPQA Diamond, el modelo DeepSeek-R1-671B, aunque más preciso, también tuvo un valor UT más alto, lo que sugiere más infravaloración en su respuesta de error.
- En el conjunto de pruebas AIME2024, el modelo DeepSeek-R1-671B no sólo tiene una mayor precisión, sino también un valor UT más bajo, lo que indica un proceso de inferencia más centrado y eficiente.
III. Conclusiones importantes:
- El pensamiento insuficiente es un factor importante en el bajo rendimiento de los o1 LLM en problemas complejos. Los frecuentes cambios de pensamiento dan lugar a modelos incapaces de explorar en profundidad vías de inferencia prometedoras, lo que en última instancia afecta a su precisión.
- El fenómeno del subpensamiento está relacionado con la dificultad del problema y la capacidad de modelización. Los problemas más difíciles exacerban el subpensamiento, y los modelos más potentes no siempre reducen el subpensamiento.
- Pensar poco es diferente de pensar demasiado. El exceso de reflexión se produce cuando un modelo malgasta recursos computacionales en problemas sencillos, mientras que la falta de reflexión se produce cuando un modelo abandona prematuramente vías de inferencia prometedoras en problemas complejos.
- El indicador de infravaloración (UT) puede cuantificar eficazmente el grado de infravaloración. Esta métrica proporciona una nueva perspectiva para evaluar la eficiencia de razonamiento de los LLM de la clase o1.
IV. Estrategias de respuesta:
Para paliar el problema del pensamiento inadecuado, los autores proponen unaEstrategia de descodificación con penalización por cambio de idea (TIP)::
- Ideas centrales: Durante el proceso de descodificación, se aplican penalizaciones a la ficha asociada al conmutador think, elAnimar a los modelos a profundizar en el pensamiento actual antes de pasar a un nuevo pensamiento..
- Resultados: La estrategia TIP mejora la precisión del modelo QwQ-32B-Preview en todos los conjuntos de pruebas, lo que demuestra su eficacia para aliviar el problema del subpensamiento.
V. Perspectivas de futuro:
Los autores sugieren futuras líneas de investigación:
- Desarrollo de mecanismos adaptativos que permitan a los modelos autorregular los interruptores del pensamiento.
- Mejorar aún más la eficacia de inferencia de los LLM de clase o1.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...