Insanely Fast Whisper: proyecto de código abierto para la transcripción rápida y eficaz de voz a texto
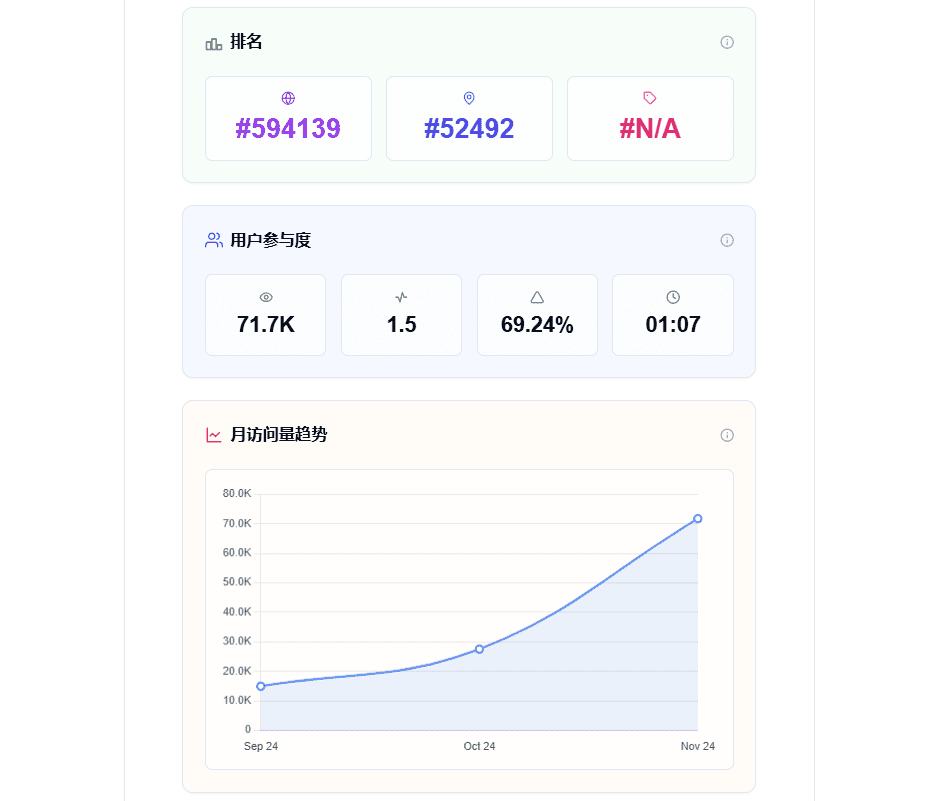
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 69.7K 00

Introducción general
insanely-fast-whisper es una herramienta de transcripción de audio que combina el modelo Whisper de OpenAI con varias técnicas de optimización (por ejemplo, Transformers, Optimum, Flash Attention) para proporcionar una interfaz de línea de comandos (CLI) diseñada para transcribir grandes cantidades de audio de forma rápida y eficiente. Utiliza el modelo Whisper Large v3 y es capaz de transcribir 150 minutos de contenido de audio en menos de 98 segundos. Los usuarios pueden conocer más detalles, guías de instalación y ayuda de uso a través del repositorio de GitHub.
reconocimiento de varios altavoces
pyannote.audio es un conjunto de herramientas de código abierto para la diarización de hablantes escrito en Python. Basado en el marco de aprendizaje automático PyTorch, cuenta con modelos preentrenados de última generación y canalizaciones para afinar aún más sus propios datos para un mejor rendimiento.
faster-whisper + pyannote.audio implementa el reconocimiento de locutor, de hecho, simplemente combinando los resultados de los dos
Almacén oficial: https://github.com/pyannote/pyannote-audio
Lista de funciones
Transcripción de audio con el modelo Whisper Large v3
Adopción de Transformers, Optimum, Flash Attention y otras tecnologías
Proporciona una interfaz CLI
Admite distintos tipos de optimización y muestra valores de referencia
Utilizar la ayuda
Instalación: Instalación y configuración con pip
Uso: Pase parámetros y ejecute tareas de transcripción directamente desde la línea de comandos
Obtén ayuda: Visita el repositorio de GitHub para leer la documentación y hablar con la comunidad.
https://github.com/SYSTRAN/faster-whisper项目编写的código google colab
# Instalación de las bibliotecas necesariasget_ipython().system('pip install faster-whisper')# Importar las bibliotecas necesariasfrom faster_whisper import modelos_disponiblesantorcha de importaciónimportar ipywidgets como widgetsfrom IPython.display import display, clear_outputimport os # Importar librerías del sistema operativo para el manejo de operaciones con ficherosimport gc # import biblioteca de recogida de basuras# Detecta automáticamente el tipo de dispositivo y selecciona GPU o CPU.device = "cuda" if torch.cuda.is_available() else "cpu"model_size = "large-v2" # Selección por defecto del tamaño del modelocompute_type = "float16" if device == "cuda" else "float32" # Cambiar a float32 si se usa CPU# Obtener una lista de modelos disponiblesmodels_list = modelos_disponibles()# Lista de idiomas por defectosupported_languages = ['en', 'fr', 'de', 'zh', '...'] # utiliza la lista de idiomas por defectodefault_language = 'zh' if 'zh' in supported_languages else supported_languages[0] # Si 'zh' está en la lista, utilícelo por defecto; en caso contrario, utilice el primer valor de la lista.
# Creación de una interfaz GUImodel_label = widgets.Label('Seleccionar modelo:')model_dropdown = widgets.Dropdown(options=lista_modelos, value=tamaño_modelo)language_label = widgets.Label('Idioma:')language_dropdown = widgets.Dropdown(options=idiomas_soportados, value=idioma_por_defecto)beam_size_label = widgets.Label('Tamaño del haz:')beam_size_slider = widgets.IntSlider(value=5, min=1, max=10, step=1)compute_type_label = widgets.Label('Tipo de cálculo:')si dispositivo == "cuda".compute_type_options = ['float16', 'int8']si no.compute_type_options = ['float32'] # Si CPU, bloquear a float32compute_type_dropdown = widgets.Dropdown(options=opciones_tipo_computadora, value=tipo_computadora)mode_label = widgets.Label('Modo de formato:')mode_dropdown = widgets.Dropdown(options=['normal', 'timeline', 'subtitle'], value='normal')initial_prompt_label = widgets.Label('Mensaje inicial:') # Nueva etiqueta de mensaje inicial añadidainitial_prompt_text = widgets.Text(value='') # Cuadro de entrada inicial añadidonombre_archivo_text = widgets.Text(description='Nombre_archivo:', value='/contenido/') # Permitir al usuario introducir el nombre del archivotranscribe_button = widgets.Button(description='Transcribir')área_de_salida = widgets.Salida()
# Definición de la función de traduccióndef transcribir_audio(b).con área_de_salida.clear_output()print("Iniciando transcripción...")from faster_whisper import WhisperModel # Importación dinámica de WhisperModel: importar cuando sea necesario para ahorrar RAMInténtalo.nombre_archivo = nombre_archivo_texto.valor # Utilizar el nombre de archivo introducido por el usuarioinitial_prompt = initial_prompt_text.value # Pregunta inicial utilizando la entrada del usuario# Garantizar la existencia del documentoif not os.path.exists(nombre_archivo):: if not os.path.exists(nombre_archivo).print(f "El archivo {nombre_archivo} no existe, por favor compruebe que el nombre y la ruta del archivo son correctos.")devolver# Adquisición de modelos seleccionadosmodelo_seleccionado = valor_desplegable_modelotipo_computación_seleccionado = valor_desplegable_tipo_computaciónidioma_seleccionado = idioma_desplegable.valor# Crea una nueva instancia del modelo y realiza la traducciónmodel = WhisperModel(selected_model, device=dispositivo, compute_type=tipo_de_computación_seleccionado)Inténtalo.# Audio traducidosegments, info = model.transcribe(file_name, beam_size=valor_beam_size_slider.value, language=idioma_seleccionado, initial_prompt=prompta_inicial ) Parámetros del aviso inicial añadidos a ## Resultados de impresiónprint("Detectado idioma '%s' con probabilidad %f" % (info.idioma, info.idioma_probabilidad))para segmento en segmentos:si mode_dropdown.value == 'normal'.print("%s " % (segmento.texto))elif mode_dropdown.value == 'timeline'.print("[%.2fs -> %.2fs] %s" % (segmento.inicio, segmento.fin, segmento.texto))si no: subtítulo #start_time = "{:02d}:{:02d}:{:02d},{:03d}".format(int(segmento.inicio // 3600), int((segmento.inicio % 3600) // 60), int(segmento.inicio % 60), int((segmento.inicio % 1) * 1000))end_time = "{:02d}:{:02d}:{:02d},{:03d}".format(int(segmento.end // 3600), int((segmento.end % 3600) // 60), int(segmento.end % 60), int((segmento. segmento.end % 1) * 1000))print("%d\n%s --> %s\n%s\n" % (segment.id, start_time, end_time, segment.text))finalmente.# Borrar instancia de modelo para liberar RAMdel modeloexcepto Excepción como e.print("Se ha producido un error durante la transcripción:")print(str(e))finalmente.# Llamada a la recogida de basuragc.collect()print("Transcripción completa.")
Interfaz GUI del conjunto #display(model_label, model_dropdown, language_label, language_dropdown, beam_size_label, beam_size_slider, compute_type_label, compute_ type_dropdown, mode_label, mode_dropdown, initial_prompt_label, initial_prompt_text, file_name_text, transcribe_button, output_area)transcribe_button.on_click(transcribe_audio)
Ejemplo de reconocimiento del código multihablante
from pyannote.core import Segmento
def get_text_with_timestamp(transcribe_res).
timestamp_texts = []for item in transcribe_res.
inicio = item.inicio
end = item.end
text = item.text.strip()
timestamp_texts.append((Segmento(inicio, fin), texto))
return timestamp_textsdef add_speaker_info_to_text(timestamp_texts, ann)::
spk_text = []for seg, text in timestamp_texts:
spk = ann.crop(seg).argmax()
spk_text.append((seg, spk, text))
return spk_textdef fusion_cache(text_cache).
sentence = ''.join([item[-1] for item in text_cache])
spk = text_cache[0][1]start = round(text_cache[0][0].start, 1)
end = round(text_cache[-1][0].end, 1)
return Segmento(inicio, fin), spk, frasePUNC_SENT_END = [',', '.' , '? , '!' , ",", "." , "?" , "!"]
def fusionar_sentencia(texto_esp).
merged_spk_text = []pre_spk = None
text_cache = []for seg, spk, text in spk_text:
¡si spk ! = pre_spk y pre_spk no es None y len(text_cache) > 0:.
merged_spk_text.append(merge_cache(text_cache))
text_cache = [(seg, spk, text)]pre_spk = spkelif texto y len(texto) > 0 y texto[-1] en PUNC_SENT_END:
text_cache.append((seg, spk, text))
merged_spk_text.append(merge_cache(text_cache))
text_cache = []pre_spk = spk
si no.
text_cache.append((seg, spk, text))
pre_spk = spk
si len(text_cache) > 0.
merged_spk_text.append(merge_cache(text_cache))
return texto_spk_fusionadodef diarizar_texto(transcribir_res, diarizar_resultado)::
timestamp_texts = get_text_with_timestamp(transcribe_res)
spk_text = add_speaker_info_to_text(timestamp_texts, diarisation_result)
res_processed = fusionar_sentencia(spk_texto)
return res_processeddef write_to_txt(spk_sent, file).
con open(file, 'w') como fp.
para seg, spk, frase en spk_sent.
line = f'{seg.inicio:.2f} {seg.fin:.2f} {spk} {sentencia}\n'
fp.write(línea)
antorcha de importación
importar susurro
importar numpy como np
from pydub import AudioSegment
from loguru import logger
from faster_whisper import WhisperModel
from pyannote.audio import Pipeline
from pyannote.audio import Audiofrom common.error.import ErrorCode
model_path = config["asr"]["faster-whisper-large-v3"]
# Audio de prueba: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_speaker_demo.wav
audio = ". /test/asr/data/asr_speaker_demo.wav"
asr_model = WhisperModel(model_path, device="cuda", compute_type="float16")
spk_rec_pipeline = Pipeline.from_pretrained("pyannote/speaker-diarisation-3.1", use_auth_token="su cara de abrazo ficha")
spk_rec_pipeline.to(torch.device("cuda"))asr_result, info = asr_model.transcribe(audio, language="zh", beam_size=5)
diarización_resultado = spk_rec_pipeline(audio)resultado_final = diarizar_texto(resultado_asr, resultado_diarización)
para segmento, spk, enviado en resultado_final:
print("[%.2fs -> %.2fs] %s %s" % (segment.start, segment.end, sent, spk))
Recursos relacionados
Proyecto principal: https://github.com/SYSTRAN/faster-whisper
Código corto: https://www.letswrite.tw/colab-faster-whisper/
Tubo de vídeo a subtítulos: https://github.com/lewangdev/faster-whisper-youtube
Transcripción de voz en tiempo real Fast Whisper: https://www.kaggle.com/code/xiu0714/faster-whisper
Paquete de instalación con un solo clic
https://pan.quark.cn/s/1b74d4cec6d6
Código de desencriptación 1434
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...