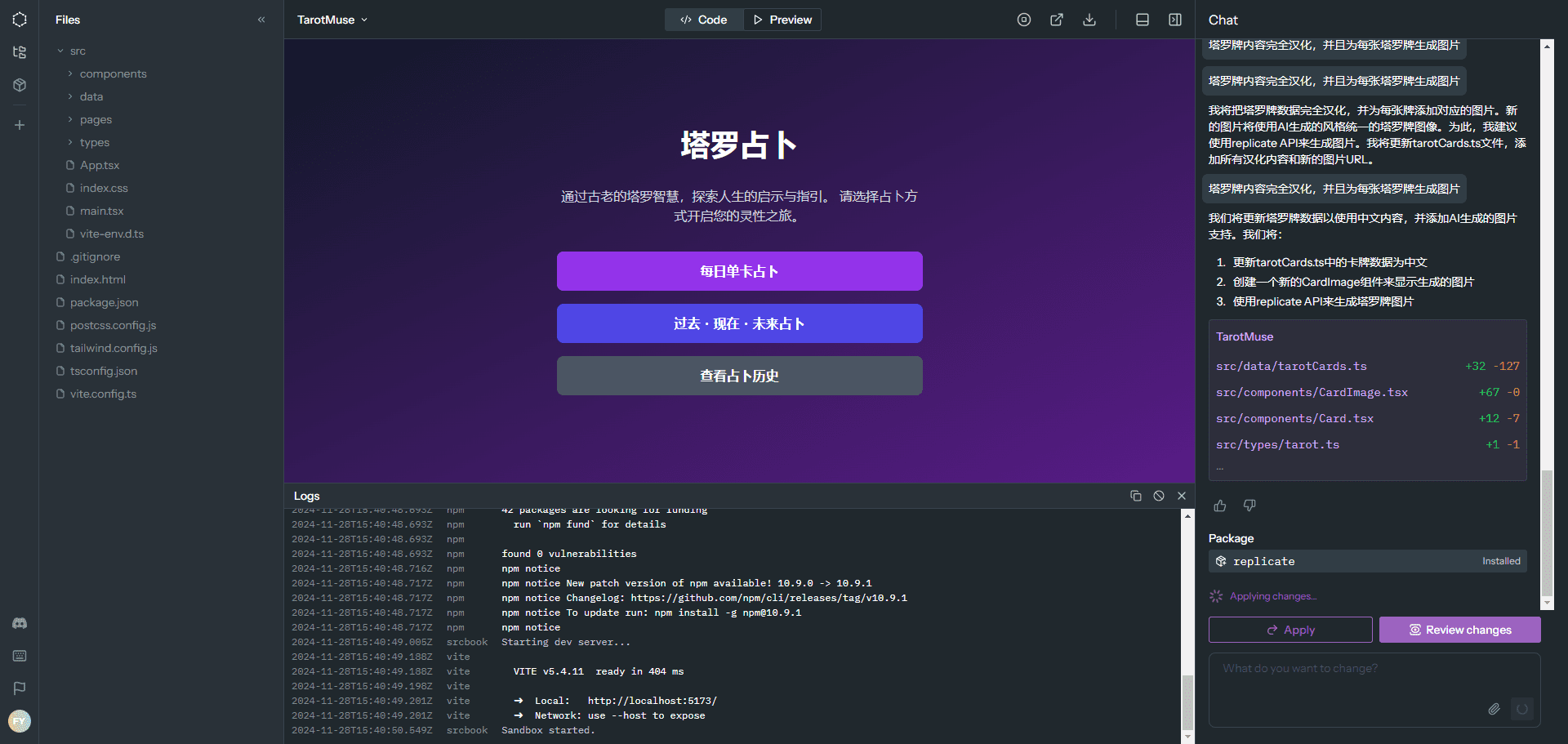
GLM-TTS - Sistema de síntesis de voz industrial de código abierto de Smart Spectrum AI
Últimos recursos sobre IAPublicado hace 3 meses Círculo de intercambio de inteligencia artificial 26.9K 00

Qué es GLM-TTS
GLM-TTS es un sistema de síntesis de voz industrial de código abierto con potentes funciones de síntesis de voz. Adopta una arquitectura de generación en dos etapas: la primera convierte el texto en secuencias de tokens del habla, y la segunda, las secuencias de tokens en audio de alta calidad. GLM-TTS alcanza el máximo nivel de los modelos de código abierto en cuanto a precisión de pronunciación, similitud tímbrica y expresión emocional. Por ejemplo, en el conjunto de pruebas seed-tts-eval, el índice de error de carácter (CER) es tan bajo como 0,89%, y la similitud tímbrica (Sim) es del 76,4%. (GLM-TTS es compatible con diversas aplicaciones, como la clonación de dialectos, la expresión multiemocional y el control preciso de la pronunciación en la evaluación educativa. Las aplicaciones interactivas en tiempo real admiten la inferencia en tiempo real. Los usuarios pueden experimentarlo en línea a través de audio.z.ai y Wisdom Spectrum Clear Speech APP, o acceder al negocio a través de la plataforma abierta API.Los pesos del modelo, los scripts de inferencia y otros recursos de GLM-TTS han sido de código abierto en GitHub, Hugging Face y la comunidad Magic Hitch, que es conveniente para los desarrolladores para implementar y desarrollo secundario.

GLM-TTS Características funcionales
- clonación del habla con muestra cero: Sólo se necesitan 3 segundos de muestras de voz para replicar el timbre y los hábitos de habla del interlocutor, generando rápidamente una voz personalizada.
- Aprendizaje por refuerzo con recompensas múltiples: Mejorar significativamente la naturalidad y la expresividad emocional del habla incorporando mecanismos de recompensa multidimensionales como la tasa de error de los caracteres, la similitud del timbre, la expresión emocional y la risa.
- Síntesis de voz de alta calidadEl habla generada es natural y fluida, con una pronunciación precisa y una calidad de sonido comparable a la de los sistemas comerciales, y resulta adecuada para la lectura en voz alta, el doblaje y muchos otros escenarios.
- Multilingüismo y apoyo emocionalPermite mezclar texto en chino e inglés y adaptar automáticamente el estilo emocional al contenido del texto para satisfacer distintas necesidades.
- Razonamiento por flujos e interacción en tiempo real: Admite la generación de audio streaming en tiempo real, lo que resulta idóneo para aplicaciones interactivas en línea, como el servicio de atención al cliente inteligente y los asistentes de voz.
- Código abierto e implantación flexibleLos pesos del modelo, los scripts de inferencia y otros recursos son de código abierto en GitHub, Hugging Face y la comunidad Magic Hitch, lo que facilita la rápida implantación y el desarrollo secundario para los desarrolladores.
- Control perfeccionado de la pronunciaciónSolución del problema de la pronunciación de caracteres polifónicos y poco comunes mediante la entrada híbrida de "fonema + texto", y mejora de la precisión de la pronunciación.
Principales ventajas de GLM-TTS
- Reproducción eficaz de los tonos: Sólo se necesitan 3 segundos de muestras de voz para replicar con precisión el tono y el estilo del orador, generando rápidamente una voz personalizada.
- Rica en expresión emocionalMejora significativa de la expresión emocional y la naturalidad del habla mediante el aprendizaje por refuerzo con recompensas múltiples, compatible con múltiples estilos emocionales.
- Salida de voz de alta calidadLa voz generada es natural y fluida, con una pronunciación precisa y una calidad de sonido comparable a la de los sistemas comerciales, y es adecuada para una amplia gama de escenarios profesionales.
- Soporte multilingüe: Admite texto mixto en chino e inglés para satisfacer las necesidades de las aplicaciones internacionalizadas.
- Funciones interactivas en tiempo real: Admite el razonamiento en flujo y es adecuado para aplicaciones interactivas en tiempo real, como el servicio de atención al cliente inteligente y los asistentes de voz.
- Código abierto y facilidad de usoFuente abierta de pesos del modelo y scripts de inferencia para una rápida implantación y desarrollo secundario por parte de los desarrolladores.
- Control perfeccionado de la pronunciación: Resolver el problema de la pronunciación de palabras polifónicas y raras mediante la entrada a nivel de fonema para mejorar la precisión de la pronunciación.
- formación con pocos datos: Sólo se necesitan 100.000 horas de datos para obtener excelentes resultados y reducir significativamente los costes de formación.
- Personalización flexible del tono: Utilización de la tecnología de ajuste fino LoRA para personalizar rápidamente tonos de alta calidad y reducir los costes de desarrollo.
¿Cuál es el sitio web oficial de GLM-TTS?
- Repositorio GitHub:: https://github.com/zai-org/GLM-TTS
- Biblioteca de modelos HuggingFace:: https://huggingface.co/zai-org/GLM-TTS
Personas a las que va dirigido el GLM-TTS
- Desarrolladores de tecnologías del hablaLa tecnología de síntesis de voz de alta calidad es necesaria para el desarrollo de aplicaciones como los asistentes de voz inteligentes y los sistemas de interacción por voz.
- creador de contenidos: Produzca audiolibros, podcasts y contenidos de audio que requieran una generación rápida de habla personalizada.
- Profesionales del sector educativo: Se utiliza en software educativo, cursos en línea, para proporcionar explicaciones de voz vívidas y comentarios de voz personalizados.
- Atención al clienteSoluciones de voz: construya un sistema inteligente de atención al cliente que proporcione una experiencia de interacción de voz natural y fluida.
- industria del espectáculo: Produzca doblajes de animación, juegos, películas y televisión, y genere rápidamente múltiples estilos de contenidos de voz.
- Investigadores de dialectos y pequeñas lenguasUtiliza su capacidad de clonación dialectal para estudiar y preservar dialectos y lenguas minoritarias.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...